1. Introduction
Spatial regression models are used to deal with spatially dependent data which widely exist in many fields, such as economics, environmental science and geography. According to the different types of spatial interaction effects, spatial regression models can be sorted into three basic categories (see [
1]). The first category is spatial autoregressive (SAR) models, which include endogenous interaction effects among observations of response variables at different spatial scales (see [
2]). The second category is spatial durbin models (SDM), which include exogenous interaction effects among observations of covariates and endogenous interaction effects among observations of response variables at different spatial scales (see [
3,
4]). The third category is spatial error models (SEM), which include interaction effects among disturbance terms of different spatial scales (see [
5]). Among them, the SAR models proposed by [
6] may be the most popular. The developments in the testing and estimation of SAR models for sectional data were summarized in the books by [
7,
8,
9] and the surveys by [
10,
11,
12,
13,
14,
15,
16], among others. Compared to sectional data models, panel data models exhibit an excellent capacity for capturing the complex situations by using abundant datasets built up over time and adding individual-specific or time-specific fixed or random effects. Their theories, methods and applications can be found in the books by [
17,
18,
19,
20] and the surveys by [
21,
22,
23,
24,
25,
26], among others.
The above mentioned research literature mainly focuses on linear parametric models. Although the estimations and properties of these models have been well established, they are often unrealistic in application, for the reason that they are unable to accommodate sufficient flexibility to accommodate complex structures (e.g., nonlinearity). Moreover, mis-specification of the data generation mechanism by a linear parametric model could lead to excessive modeling biases or even erroneous conclusions.
Ref. [
27] pointed out that the relationship between variables in space usually exhibits highly complexity in reality. Therefore, researches have proposed a number of solution methods. In video coding systems, transmission problems are usually dealt with wavelet-based methods. Ref. [
28] proposed a low-band-shift method which avoids the shift-variant property of the wavelet transform and performs the motion compensation more precisely and efficiently. Ref. [
29] obtained a wavelet-based lossless video coding scheme that switches between two operations based on the different amount of motion activities between two consecutive frames. More theories and applications can be found in [
30,
31,
32]. In econometrics, some nonparametric and semiparametric spatial regression models have been developed to relax the linear parametric model settings. For sectional spatial data, ref. [
33] studied the GMM estimation of a nonparametric SAR model; Ref. [
34] investigated the PQMLE of a partially linear nonparametric SAR model. However, such nonparametric SAR models may cause the “curse of dimensionality” when the dimension of covariates is higher. In order to overcome this drawback, ref. [
35] studied two-step SGMM estimators and their asymptotic properties for spatial models with space-varying coefficients. Ref. [
36] proposed a semiparametric series-based least squares estimating procedure for a semiparametric varying coefficient mixed regressive SAR model and derived the asymptotical normality of the estimators. Some other related research works can be found in [
37,
38,
39,
40,
41,
42]. For panel spatial data, ref. [
43] obtained PMLE and its asymptotical normality of varying the coefficient SAR panel model with random effects; Ref. [
44] applied instrumental variable estimation to a semiparametric varying coefficient spatial panel data model with random effects and the investigated asymptotical normality of the estimators.
In this paper, we extend the varying coefficient spatial panel model with random effects given in [
43] to a PLVCSARPM with random effects. By adding a linear part to the model of [
43], we can simultaneously capture linearity, non-linearity and the spatial correlation relationships of exogenous variables in a response variable. By using the profile quasimaximum likelihood method to estimate PLVCSARPM with random effects, we proved the consistency and asymptotic normality of the estimators under some regular conditions. Monte Carlo simulations and real data analysis show that our estimators perform well.
This paper is organized as follows:
Section 2 introduces the PLVCSARPM with random effects and constructs its PQMLE.
Section 3 proves the asymptotic properties of estimators.
Section 4 presents the small sample estimates using Monte Carlo simulations.
Section 5 analyzes a set of asymmetric real data applications for illustrating the performance of the proposed method. A summary is given in
Section 6. The proofs of some important theorems and lemmas are given in
Appendix A.
2. The Model and Estimators
Consider the following partially linear varying coefficient spatial autoregressive panel model (PLVCSARPM) with random effects:
where
i refers to a spatial unit;
t refers to a given time period;
are observations of a response variable;
;
and
are observations of p-dimensional and q-dimensional covariates, respectively;
is an unknown univariate varying coefficient function vector;
are unknown smoothing functions of
u;
is an unknown spatial correlation coefficient;
is a regression coefficient vector of
;
is an
predetermined spatial weight matrix;
is the ith component of
;
are i.i.d. error terms with zero means and variance
;
are i.i.d. variables with zero means and variance
,
are independent of
. Let
be the true parameter vector of
and
be the true varying coefficient function of
.
The model (
1) can be simplified as the following matrix form:
where
;
;
;
;
;
;
;
is an
identity matrix;
is a
identity matrix; ⊗ denotes the Kronecker product;
is a
vector consisting of 1.
Define
; then the model (
2) can be rewritten as:
where
I is an
unit matrix. For the model (
3), it is easy to get the following facts:
According to [
12], the quasi-log-likelihood function of the model (
3) can be written as follows:
where
, and
c is a constant.
By maximizing the above quasi-log-likelihood function with respect to
, the quasi-maximum likelihood estimators of
,
and
can be easily obtained as
By substituting (
5)–(
7) into (
4), we have the concentrated quasi-log-likelihood function of
as
It is obvious that we cannot directly obtain the quasi-maximum likelihood estimator of
by maximizing the above formula because
is an unknown function. In order to overcome this problem, we use the PQMLE method and working independence theory ([
45,
46]) to estimate the unknown parameters and varying coefficient functions of the model (
1).
The main steps are as follows:
Step 1 Suppose that
is known.
can be approximated by the first-order Taylor expansion
for
in a neighborhood of
u, where
is the first order derivative of
. Let
and
; then estimators of
and
can be obtained by
where
,
,
is a kernel function and
h is the bandwidth. Therefore, the feasible initial estimator of
can be obtained by
.
Denote
,
,
and
then we have
Let
,
and
. It is easy to know that
where
. Consequently, the initial estimator of
is given by
where
Step 2 Replacing
of (
4) with
, the estimator
of
can be obtained by maximizing approximate quasi-log-likelihood function:
In the real estimation of , the procedure is realized by following steps:
Firstly, assume
is known. The initial estimators of
,
and
are obtained by maximizing (
9). Then, we find
Secondly, with the estimated
,
and
, update
by maximizing the concentrated quasi-log-likelihood function of
:
Therefore, the estimator of
is obtained by:
Step 3 By substituting
into (
10), (
11) and (
12), respectively, the final estimators of
,
and
are computed as follows:
Step 4 By replacing
with
in (
8), we get the ultimate estimator of
:
where
,
.
3. Asymptotic Properties for the Estimators
In this section, we focus on studying consistency and asymptotic normality of the PQMLEs given in
Section 2. To prove these asymptotic properties, we need the following assumptions to hold.
To provide a rigorous analysis, we make the following assumptions.
Assumption 1. - (i)
and are uncorrelated to and , and satisfy , , , , , , and , where represents the Euclidean norm. Moreover, and for some .
- (ii)
, are random sequences. The density function of is non-zero, uniformly bounded and second-order continuously differentiable on , where is the supporting set of . exists, and it has a second-order continuous derivative; and are second-order continuously differentiable on ; , and for ; , and .
- (iii)
Real valued function is second-order, continuously differentiable and satisfies the first order Lipschitz condition, at any u, , where and are positive and constant.
- (iv)
are i.i.d. random variables from the population. Moreover, and for .
Assumption 2. - (i)
As a normalization, the diagonal elements of are 0 for all i and are at most of order , denoted by .
- (ii)
The ratio as N goes to infinity.
- (iii)
is nonsingular for any .
- (iv)
The matrices and are uniformly bounded in both row and column sums in absolute value.
Assumption 3. is a nonnegative continuous even function. Let , ; then for any positive odd number. Meanwhile, , .
Assumption 4. If , and , then .
Assumption 5. There is an unique to make the model (1) tenable. Assumption 6. , where Remark 1. Assumption 1 provides the essential features of the regressors and disturbances for the model (see [47]). Assumption 2 concerns the basic features of the spatial weights matrix and the parallel Assumptions 2–5 of [12]. Assumption 2(i) is always satisfied if is a bounded sequence. We allow to be divergent, but at a rate smaller than N, as specified in Assumption 2(ii). Assumption 2(iii) guarantees that model (2) has an equilibrium given by (3). Assumption 2(iv) is also assumed in [12], and it limits the spatial correlation to some degree but facilitates the study of the asymptotic properties of the spatial parameter estimators. Assumptions 3 and 4 concern the kernel function and bandwidth sequence. Assumption 5 offers a unique identification condition, and Assumption 6 is necessary for proof of asymptotic normality. In order to prove large sample properties of estimators, we need introduce the following useful lemmas. Before that, we simplify the model (
2) and obtain reduced form equation of
Y as follows:
where
;
. The above equations are frequently used in a later derivation.
Lemma 1. Let be i.i.d. random vectors, where are scalar random variables. Further, assume that , where f denotes the joint density of . Let K be a bounded positive function with a bounded support, satisfying a Lipschitz condition. Given that for some , The proof can be found in [
48].
Lemma 2. Under Assumptions 1–4, we havewhere and , . Lemma 3. Under Assumptions 1–4, we have.
Lemma 4. Under Assumptions 1–4, we have
- (i)
;
- (ii)
, ;
- (iii)
, ;
- (iv)
,
The proof can be found in [
37].
Lemma 5. Under Assumptions 1–6, is a positive definite matrix and With the above lemmas, we state main results as follows. Their detailed proofs are given in the
Appendix A.
Theorem 1. Under Assumptions 1–5, we have and .
Theorem 2. Under Assumptions 1–5, we have .
Theorem 3. Under Assumptions 1–5, we have and .
Theorem 4. Under Assumptions 1–6, we havewhere “” represents convergence in distribution, is the average Hessian matrix (information matrix when ε and b are normally distributed, respectively), and . Theorem 5. Under Assumptions 1–5, we havewhere and satisfy and and is the second-order derivative of , . Furthermore, if , then we have 4. Monte Carlo Simulation
In this section, Monte Carlo simulations are presented, which were carried out to investigate the finite sample performance of PQMLEs. The sample standard deviation (
) and two root mean square errors (
and
) were used to measure the estimation performance.
and
are defined as:
where
is the number of iterations;
) are estimates of
for each iteration,
is the true value of
;
,
and
are the upper quartile, median and lower quartile of parametric estimates, respectively. For the nonparametric estimates, we took the mean absolute deviation error (
) as the evaluation criterion:
where
are
Q fixed grid points in the support set of
u. In the simulations, we applied the rule of thumb method of [
48] to choose the optimal width and let kernel function be an Epanechnikov kernel
(see [
33]).
We ran a small simulation experiment with
and generated the simulation data from following model:
where we assume that
,
,
,
,
,
,
,
and
and 0.75, respectively. Furthermore, we chose the Rook weight matrix (see [
7]) to investigate the influence of the spatial weight matrix on the estimates. Our simulation results for both cases
and
are presented in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6.
By observing the simulation results in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5 and
Table 6, one can obtain the following findings: (1) The
and
for
,
,
and
were fairly small for almost all cases, and they decreased as
N increased. The
and
for
are not negligible for small sample sizes, but they decreased as
N increased. (2) For fixed
T, as
N increased, the
for
,
,
,
and
decreased for all cases.
and
for
and
decreased rapidly, whereas the
for estimates of the others parameters did not change much. For fixed
N, as
T increased, the behavior of the estimates of parameters was similar to the case where
N changed under the fixed
T. (3) The
for
of varying coefficient functions
and
decreased as
T or
N increased. Combined with the above three findings, we conclude that the estimates of the parameter and unknown varying coefficient functions were convergent.
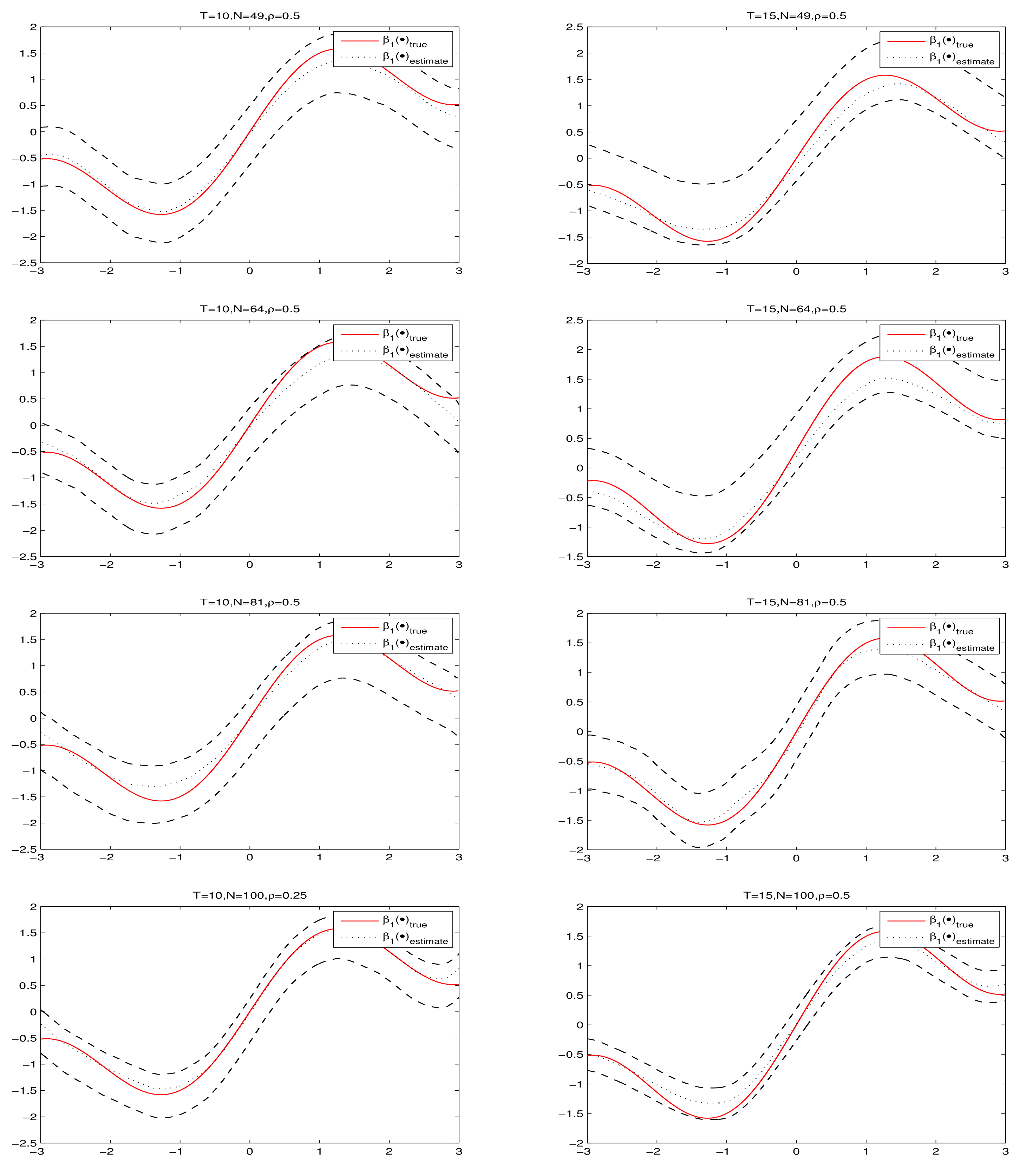
Figure 1 and
Figure 2 present the fitting results and 95% confidence intervals of
and
under
, respectively, where the short dashed curves are the average fits over 500 simulations
by PQMLE, the solid curves are the true values of
and the two long dashed curves are the corresponding 95% confidence bands. By observing every subgraph in
Figure 1 and
Figure 2, we can see that the short dashed curve is fairly close to solid curve and the corresponding confidence bandwidth is narrow. This illustrates that the nonparametric estimation procedure works well for small samples. To save space, we do not present the cases
and
because they had similar results as the case
.
5. Real Data Analysis
We applied the housing prices of Chinese city data to analyze the proposed model with real data. The data were obtained from the China Statistical Yearbook, the China City Statistical Yearbook and the China Statistical Yearbook for Regional Economies. Based on the panel data of related variables of 287 cities at/above the prefecture level (except the cities in Taiwan, Hong Kong and Macau) in China from 2011 to 2018, we explored the influencing factors of housing prices of Chinese cities by PLVCSARPM with random effects.
Taking [
49,
50,
51] as references, we collected nine variables related to housing prices of China cities, including each city’s average selling price of residential houses (denoted by HP, yuan/sq.m), the expectation of housing price trends (EHP, %), population density (POD, person), annual per capita disposable income of urban households (ADI, yuan), loan–to–GDP ratio (MON, %), natural growth rate of population (NGR, %), sulphur dioxide emission (SDE, 10,000 tons), area of grassland (AOG, 10,000 hectares) and the value of buildings completed (VBC, yuan/sq.m). According to result of non-linear regression, the established model is given by
where
represents the
ith observation of ln(HP) at time
t;
represents the
ith observation of EHP at time
t;
means the
ith observation of POD, ln(ADI), MON, NGR, SDE and AOG at time
t, respectively,
represents the
ith observation of ln(VBC) at time
t.
In order to transfer the asymmetric distribution of POD to nearly uniform distribution on (0,1), we set
The spatial weight matrix
we adopted is calculated as follows:
where
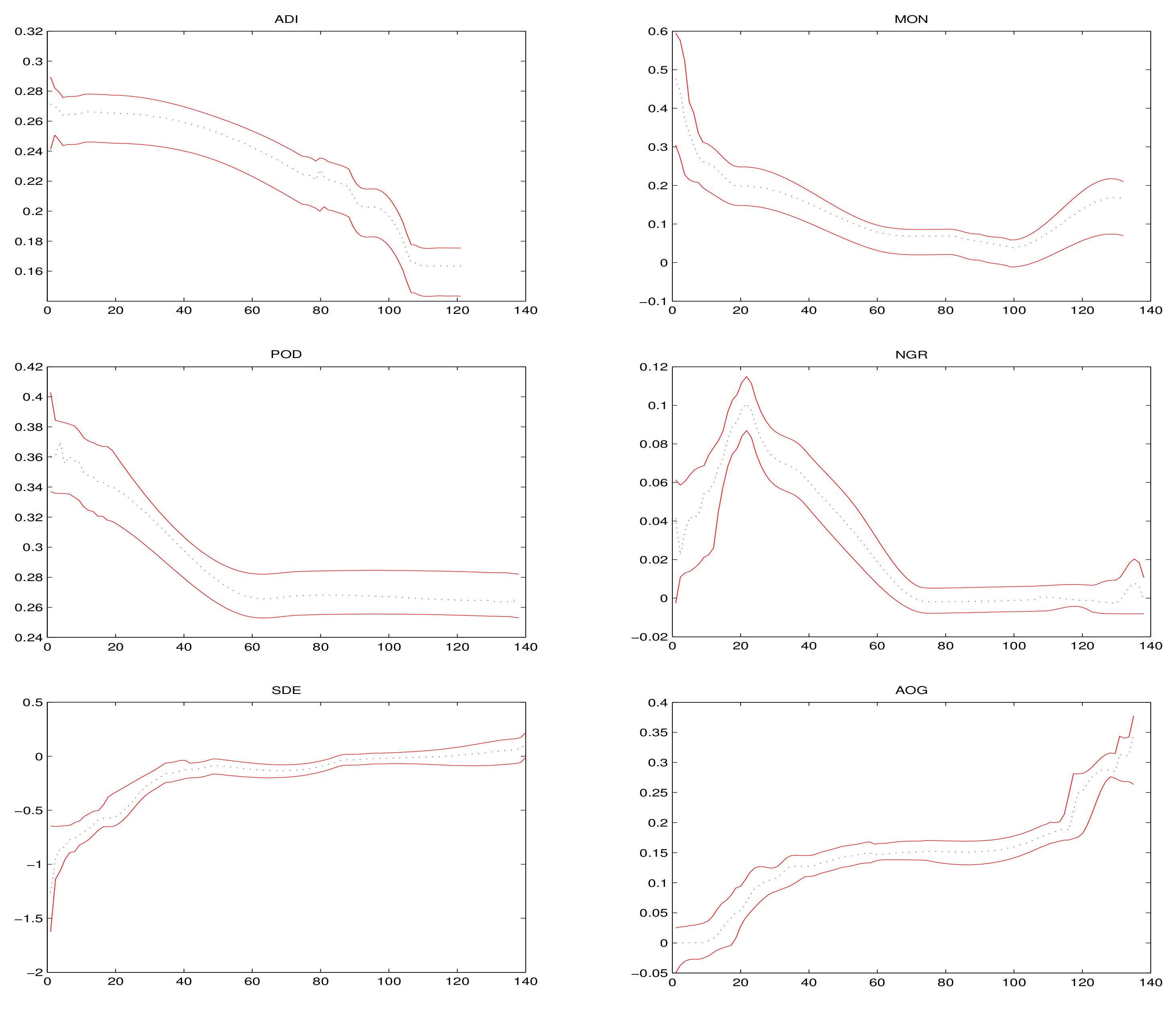
Figure 3 presents the estimation results and corresponding 95% confidence intervals of varying coefficient functions
, where the black dashed line curves are the average fits over 500 simulations and the red solid lines are the corresponding 95% confidence bands. It can be seen from
Figure 3 that all covariates variables have obvious non-linear effects on housing prices of Chinese cities.
The estimation results of parameters in the model (
14) are reported in
Table 7. It can be seen from
Table 7: (1) all estimates of parameters are all significant; (2) spatial correlation coefficient
, which means there exists a spatial spill over effect for housing prices of Chinese cities; (3)
indicates that the expectation of housing price trends (EHP) has a promotional effect on housing prices of Chinese cities; (4)
shows that the growth of housing prices in different regions is relatively stable and is less affected by external fluctuations.
6. Conclusions
In this paper, we proposed PQMLE of PLVCSARPM with random effects. Our model has the following advantages: (1) It can overcome the “curse of dimensionality” in the nonparametric spatial regression model effectively. (2) It can simultaneously study the linear and non-linear effects of coveriates. (3) It can investigate the spatial correlation effect of response variables. Under some regular conditions, consistency and asymptotic normality of the estimators for parameters and varying coefficient functions were derived. Monte Carlo simulations showed the proposed estimators are well behaved with finite samples. Furthermore, the performance of the proposed method was also assessed on a set of asymmetric real data.
This paper only focused on the PQMLE of PLVCSARPM with random effects. In future research, we may try to extend our method to more general models, such as a partially linear varying coefficient spatial autoregressive model with autoregressive disturbances. In addition, we also need study the issues of Bayesian analysis, variable selection and quantile regression in these models.






{kind=link}
{kind=link}
{kind=link}