1. Introduction
The gamma distribution is one of the most popular models used for analyzing constant and non-constant failure rate data. It includes the exponential, Erlang, and chi-square distributions as special cases. In recent years, using exponential and/or gamma as the parent distribution (among others), several new models have been developed to provide richness that makes them accurate and suitable to fit complex datasets. New statistical models, created based on a finite mixture of probability distributions, played a vital role in modeling the real-life phenomenon. Further, finite mixture densities have been widely used to model various data, for example, see [
1,
2]. However, gamma distribution does not exhibit a bathtub or upside-down bathtub shaped hazard rate function and, thus, it cannot be used to model the complex lifetime of a system.
For this reason, Reference [
3] proposed a new one-parameter xgamma distribution, denoted by
, as a special finite mixture of exponential and gamma distributions. They derived various mathematical, structural, and survival properties, with inference to the XGD. Moreover, they showed that the XGD was useful in modeling the dataset with a monotone failure rate, and that it had applicability in analyzing lifetime data.
Suppose that the lifetime random variable
X of an experimental unit(s) follows
, then, the probability density function (PDF)
and cumulative distribution function (CDF)
of
X, are given, respectively, by
and
where
is the scale parameter. The reliability characteristics of any lifetime model are the main features for evaluating the capacity of any electronic system that a reliability practitioner frequently uses. Therefore, some survival parameters of the XGD are also investigated as unknown parameters; reliability function (RF)
and failure rate function (FRF)
at mission time
t are given, respectively, by
and
Moreover, Reference [
3] indicates that the XGD belongs to the exponential family of distributions and it has more flexibility than the exponential distribution. Reference [
4] studied the estimation procedures of the XGD parameter and some related important survival characteristics under type-II progressively censoring (PCS-T2). Furthermore, they showed that the xgamma random variates are stochastically larger than that of the exponential and Lindley distributions. Reference [
5] discussed the estimating problem of the parameter and reliability characteristics of XGD under hybrid type-II censored data. Recently, Reference [
6] derived both classical and Bayes estimates of some parameters of life for XGD under complete sampling.
The adaptive type-II progressive hybrid censoring scheme (APHCS-T2), introduced by [
7], saves the total time test and increases the efficiency of statistical inference. It can be described in the context of a life testing experiment as follows: suppose that
n identical units are placed on the test at time zero;
is the pre-fixed number of failures and the experimental time is allowed to run over time
T, which is an ideal total test. In this case, the progressive censoring
is provided, but the values of some of
may change accordingly during the experiment. If
, the experiment proceeds with
and stops at
. In this situation, APHCS-T2 degenerates into usual PCS-T2 and the experiment stops at the time of observe
m-th failure. Otherwise, if
does not occur before time
T, i.e.,
, where
and
is the
d-th failure, occur before time
T, then no items will be withdrawn from the experiment by setting
for
, and the experiment stops at the time of the
m-th failure occurring, and all remaining surviving items are removed, i.e.,
. The main advantage of APHCS-T2 is it enables us to get the effective number of failures
m and assures that the total test time will not be too far away from the pre-specified time
T.
If
n units put on a life test are from a continuous population with CDF
and PDF
, and
m effective number of failures have been observed, hence, the joint PDF for the ordered failure times of APHCS-T2 out of the experiment
where
is parameter vector, is given by
where
and
.
Several works based on APHCS-T2 have investigated the problem of estimating the unknown parameters of different lifetime models, e.g., see [
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22].
To the best of our knowledge, we have not come across any work related to the estimation of distribution parameters and/or reliability characteristics of the XGD under adaptive progressive censoring. Thus, by demonstrating that the XGD may be used as a survival model utilizing APHCS-T2, the purpose of this study is to close this gap. Thus, our objectives in this study are: first, to drive both point and interval estimators of the unknown parameter and survival characteristics, the XGD using both maximum likelihood and Bayesian approaches in the present data collected under the APHCS-T2 life test. Using gamma density prior under the squared-error loss (SEL) function, the Bayes estimators (BEs) for the unknown parameter and the survival characteristics are obtained. When the informative prior density is taken into account, an approach used to determine the hyperparameter values is proposed. Second, the proposed estimators cannot be obtained in explicit expressions, we apply some numerical procedures to evaluate them, such as the Newton–Raphson (N–R) iterative method, Lindley’s approximation, and Metropolis–Hastings (M–H) algorithm. Presently, Bayesian statistics that are developed based on Markov chain Monte Carlo (MCMC) techniques are widely used in many fields. Using normal approximation of the MLE (NA) and of the log-transformed MLE (NL), approximate confidence intervals (ACIs) for the unknown parameters, and any function of them, are constructed. Moreover, using MCMC simulated samples, two-sided BCI/HPD credible intervals are also constructed. Extensive numerical comparisons have been made to compare the performance of the classical and Bayesian estimates. The point estimates have been compared in terms of their estimated root mean squared errors (RMSEs) and relative absolute biases (RABs). Further, the interval estimates have been compared in terms of their average confidence widths (ACWs). Lastly, two datasets from industrial and chemical fields are analyzed to illustrate our proposed estimators.
The rest of the paper is organized as follows: maximum likelihood and Bayesian inferential procedures of the unknown parameter and the reliability characteristics are provided in
Section 2 and
Section 3, respectively. In
Section 4, asymptotic and credible intervals are constructed. Monte Carlo simulation results are presented in
Section 5. Two practical examples using real datasets are analyzed and investigated in
Section 6. Finally, some concluding remarks are provided in
Section 7.
3. Bayes Procedure
In this section, the Bayes estimators of the unknown parameters
,
and
are developed under the SEL function,
, which is defined as
Using (
9), the Bayes estimator
(say) of the unknown parameter or any function of
,
(say), is given by the posterior mean of
. However, any other loss function can be easily incorporated. It is known that the family of gamma distributions is flexible enough to cover a large variety of prior beliefs of the experimenter, see [
23]. Therefore, we assume that the unknown parameter
is stochastically independently distributed with conjugate gamma prior, as
Combining (
10) with (
6) and substituting in the continuous Bayes’ theorem, the posterior PDF of
becomes
where
C is the normalizing constant of (
11) and is given by
.
Hence, using (
11), the Bayes estimate of any parameter of life
(say) against the SEL function is given by
It is clear that the posterior PDF (
11) is not easily tractable due to its implicit mathematical expression, so the BEs (
12) cannot be developed in a closed-form. To overcome this problem, two approximation techniques, namely: Lindley and MCMC procedures, are used.
3.1. Lindley’s Approximation
Reference [
24] suggested procedure is to approximate the desired Bayes estimator by reducing the posterior ratio to finite values. According to this procedure, the approximated value
of
as in (
12) for any function of
for a sufficiently large sample size
n is given by
where
and
. All terms of (
13) are evaluated at
.
Now, to approximate the Bayes estimators using (
13), the following quantities must be obtained as
and
where
and
are the second- and third-derivatives, with respect to
as
,
,
and
The approximate BEs
of
, using the Lindley’s approximation method, can be easily obtained. Unfortunately, in literature, we have not yet come up with a method that can be used to construct the associate credible intervals of the unknown parameters
using Lindley’s procedure. In view of this, we propose to use the M–H algorithm in order to generate MCMC samples from the posterior distribution and then to compute the Bayes estimators and also to construct the associated credible intervals.
3.2. M–H Algorithm
The M–H algorithm, a useful one of MCMC techniques, is used for generating random samples from the posterior distribution by an independent proposal distribution. However, from a practical point of view, this method provides a chain form of the Bayesian estimate, which is easy to apply in practice. One may refer to [
25] and [
26] for more applications related to this algorithm. To implement the M–H algorithm procedure, conduct the following steps for the sample generation process:
Step 1: Start with an initial guess .
Step 2: Set .
Step 3: Generate from with the normal proposal density distribution as
- (a)
Obtain a candidate value from .
- (b)
Obtain a sample point u from uniform distribution .
- (c)
Obtain .
- (d)
Set if , otherwise set .
Step 4: Set .
Step 5: Repeat steps 2–4 for a large N times to obtain
Step 6: Using the outputs of Step 5, compute the parameters of life of
, such as
and
, for a distinct time
as
and
respectively.
To remove the affection of the initial guess and to guarantee the convergence of the sampler, the first simulated varieties,
(say), usually discarded in the beginning of the analysis implementation (burn-in period). Hence, the selected MCMC samples
for
can be used to develop the Bayesian inferences. However, the Bayes MCMC estimates of a parametric function
based on the SEL function are given by
3.3. Hyper-Parameter Value Selection
The elicitation procedure used to determine the hyperparameter value, when an informative prior of the density parameter is taken into account, is the main issue in Bayesian analysis. In the literature, this problem has been discussed by [
27,
28]. Moreover, the values of hyperparameters for the unknown parameters under interest are made by assuming two independent types of information, namely prior mean and prior variance of the unknown parameter of the model under consideration. In this regard, we propose the following steps to determine the values of hyperparameters
a and
b, based on past samples as
Step 1: Set the parameter value of .
Step 2: Set the complete sample size n.
Step 3: Draw a random sample of size n from .
Step 4: Compute the MLE of .
Step 5: Repeat Steps 2–4 B times to get .
Step 6: Set the sample mean and sample variance of
equal to the mean and variance of the gamma density prior, respectively, as
and
where
B is the number of samples generated from the distribution under consideration.
Step 7: Solve (
15) and (
16) simultaneously, the estimated hyperparameters
and
of
a and
b can be turn out directly by
respectively.
5. Monte Carlo Simulation
To examine the behavior of considered estimators of the model parameter, as well as associated reliability and hazard rate functions of XGD based on APHCS-T2, various Monte Carlo simulations are conducted by considering two different true values of the xgamma parameter as
. Using the algorithm described in [
7], a large number, 1000 of APHCS-T2 samples based on different combinations of
n (number of total test units) and
m (effective sample size) are generated from
.
For each setting, the MLEs and Bayes MCMC estimates of the unknown parameter and the reliability characteristics and are computed. Approximate Bayes computations are developed using both Lindley and M–H algorithm methods. Now, to generate APHCS-T2 samples from the XGD model, conduct the following steps:
Step 1: generate an ordinary PCS-T2 sample
by using the algorithm described by [
36] as
- (a)
Generate W independent observations of size m as .
- (b)
For given values of n, m, T and , set for
- (c)
Set for . Hence, is a PCS-T2 sample of size m from distribution.
- (d)
Invert (
2) for a given value of
, i.e.,
the PCS-T2 sample from
is carried out.
Step 2: Determine d-th failure, where , and discard the remaining sample .
Step 3: Generate the first order statistics from a truncated distribution with sample size as .
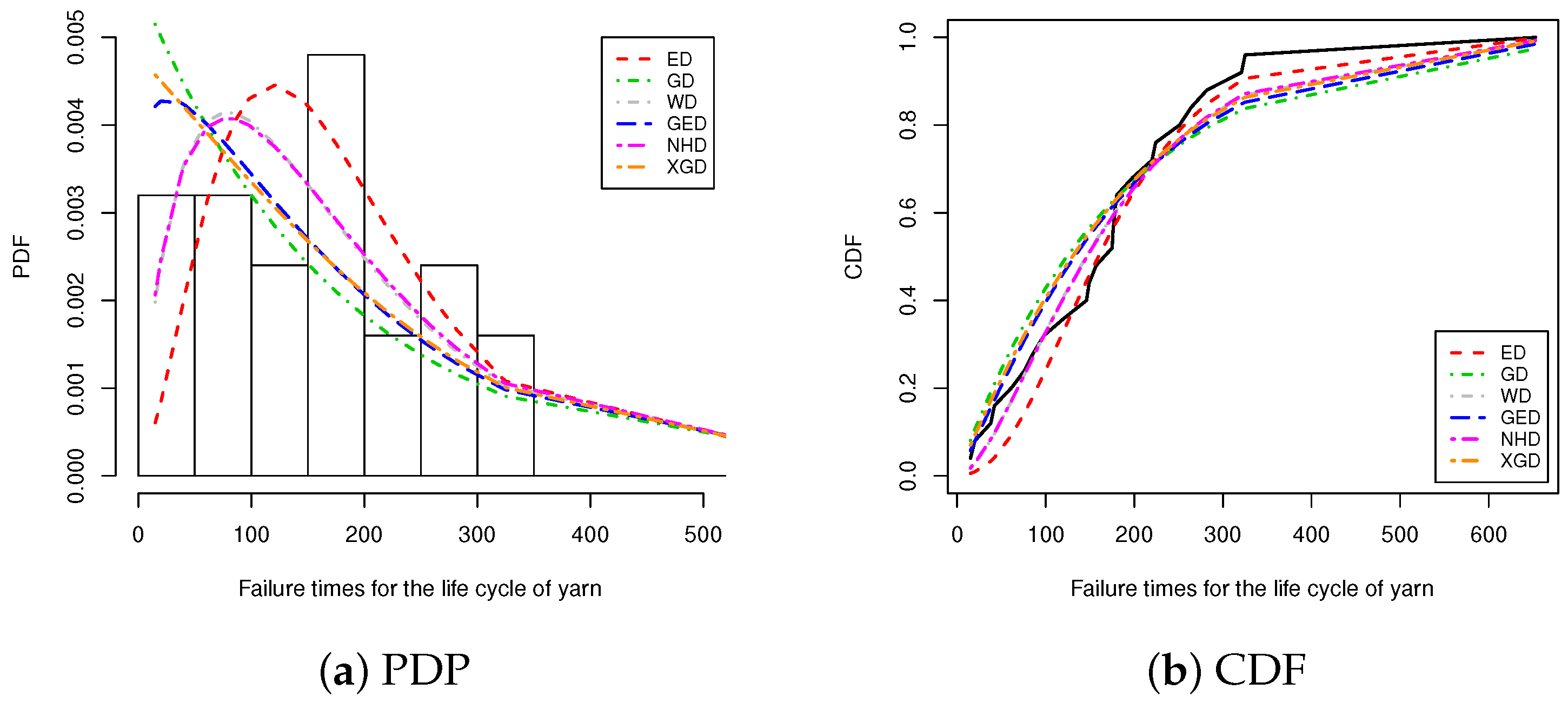
This numerical comparison is performed based on different combinations of , such as: for each pre-determined time . The test is terminated when the number of failed subjects achieves or exceeds a certain value m, where the percentage of failure information is taken as 50 and 80%.
To assign values for the hyperparameters of the conjugate gamma prior (
10), we propose using the procedure of past sample data described in
Section 3.3. In view of this, we generated 1000 complete samples of a large size 50 (say) from the xgamma lifetime model as past samples when the plausible values of an unknown parameter
were taken as 1 and 3. Consequently, the values of the hyperparameters
a and
b, which are plugged-in to the computation of the desired Bayes estimates, are taken as
and
for
and
, respectively. If one does not have any prior information on the unknown parameter of interest, the posterior PDF (
11) becomes proportional to the likelihood function (
6). In this case, it is better to use the MLEs instead of the BEs, as the later are computationally more expensive.
Regarding the reliability characteristic functions of XGD, we also obtained the MLEs and BEs for
and
for a distinct time
. Hence, for each true parameter value of
, the actual value of them are taken as
and
for
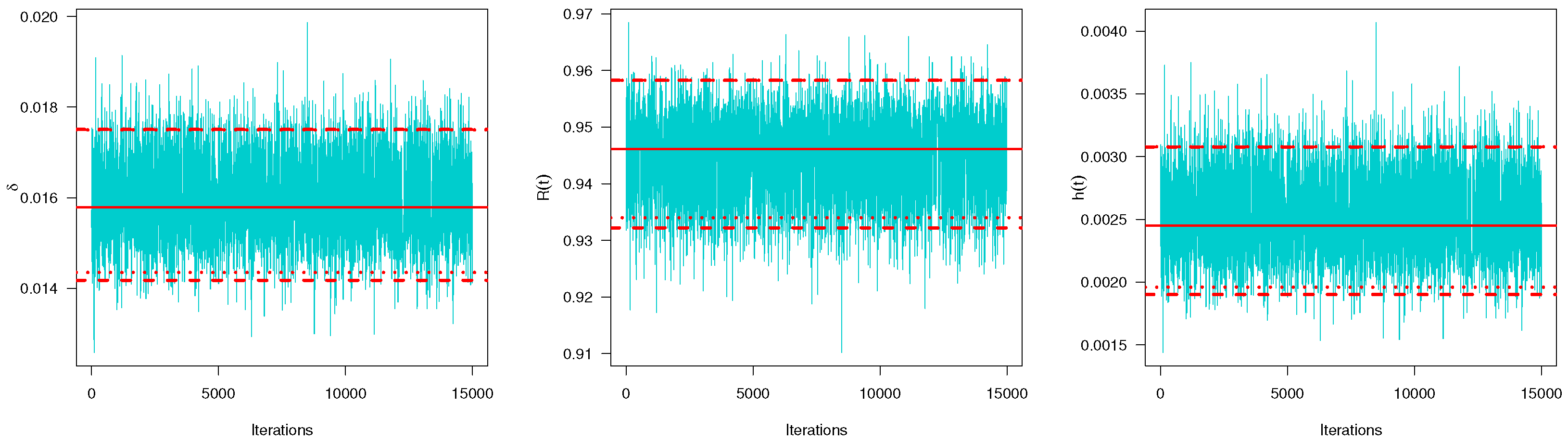
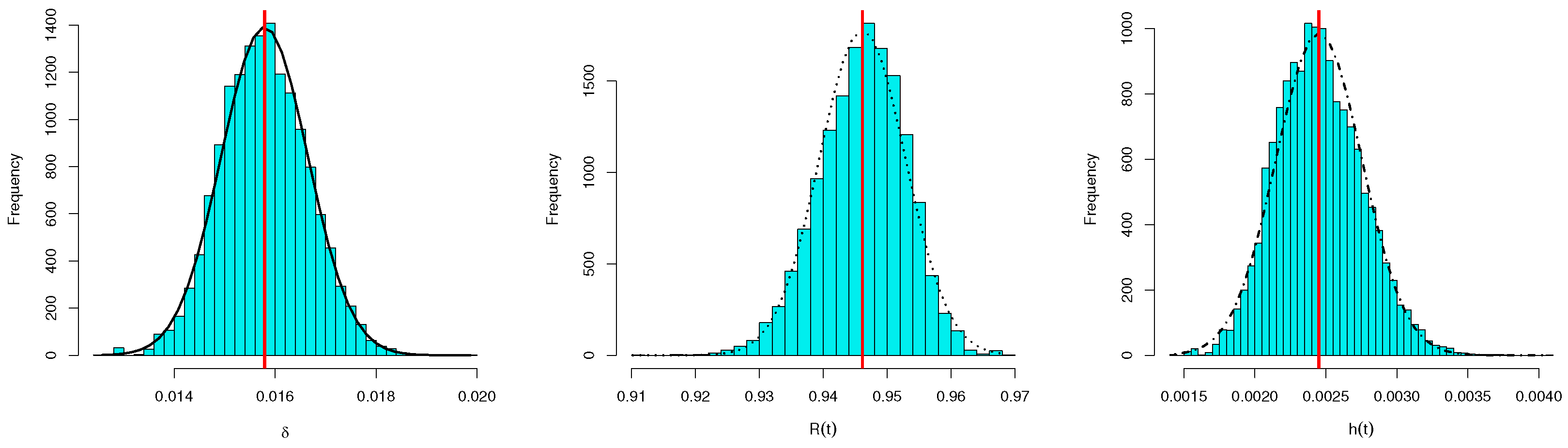
1 and 3, respectively. To develop the Bayesian computations, we generated 12,000 MCMC samples and then the first 2000 iterations were discarded from the generated sequence as burn-in to remove the affection of the selection of the initial value. Hence, the average BEs of the unknown parameters
,
and
are computed based on the SEL function using 10,000 MCMC samples. The initial value of
, for running the MCMC sampler algorithm, was taken to be its MLE. Moreover, for each
n and
m, different censoring schemes (CSs),
R, to remove survival units during the lifetime experiment, are used as
For each test, the average point estimates with their RMSEs and RABs as well as the ACWs of the interval estimates are given, respectively, by
and
where
G is the number of replicates,
is the MLE or BE of the parametric function
,
denote the
CI bounds, where
,
and
.
The average MLEs and BEs (Lindley’s and MCMC methods) of
,
and
with their RMSEs and RABs are calculated and reported in
Table 1,
Table 2 and
Table 3. In each table, the associated average estimate, RMSE and RAB, of any unknown parameter based on each test, are tabulated in the first, second, and third rows, respectively. Further, the ACWs of 95% asymptotic and credible intervals of
,
and
are computed and listed in
Table 4 and
Table 5.
All numerical computations are performed using
statistical programming language software version 4.0.4 by mainly three useful recommended packages; namely (i) ‘CODA’ package, proposed by [
37], used to carry out the Bayesian inference; (ii) ‘maxLik’ package, proposed by [
38], used to obtain the MLEs via the N–R iterative procedure; and (iii) ‘GoFKernel’ package, proposed by [
39], used to invert the xgamma distribution (
2). These packages were recently recommended by [
22,
40,
41,
42,
43].
From
Table 1,
Table 2 and
Table 3, it can be seen that the proposed estimators of the unknown parameter and the reliability characteristics of XGD are very good, in terms of their RMSEs, RABs, and ACWs. As
n (or
m) increases, the RMSEs, RABs, and ACWs of both point and interval estimates decrease as expected. Thus, to get better estimation results, one may tend to increase the effective sample size. It is also observed that, as the failure percentage
increases, the point estimates become even better. Since the Bayes estimates of any parametric function include gamma prior information than the classical estimates, consequently, they perform better than the other competing estimates in terms of their RMSEs and RABs. Hence, the MCMC method using the M–H algorithm is better than Lindley’s approximation method, with respect to their RMSEs and RABs.
Regarding the xgamma parameter
, RF
, FRF
, when
increases with fixed
T, the RMSEs and RABs associated with MLEs and BEs increase; moreover, they have similar behavior when
T increases with fixed
. When
T increases with fixed
, the RMSEs and RABs associated with MLE and Lindley estimates decrease, while those associated with the MCMC estimates increase. When
T increases with fixed
, the RMSEs and RABs associated with MCMC estimates increase, while those associated with MLEs and Lindley estimates decrease. From
Table 4,
Table 5 and
Table 6, in respect to the interval estimates, the ACWs of asymptotic and credible intervals narrow down when
n and
m increases, as expected. In addition, as
increases, the 95% ACWs of all of the proposed estimates narrow down. As
(or
T) increases, the ACWs of both asymptotic and credible intervals for
,
,
tend to increase. It can also be seen that the ACWs of asymptotic (NA/NL) intervals, as well as credible (BCI/HPD) intervals, are quite close to each other. Further, due to the gamma prior information, it is observed that the credible intervals perform better than the asymptotic intervals, with respect to the shortest ACWs, as expected.
Moreover, comparing schemes 1 and 3, it is clear that the RMSEs and RABs of all estimates for the unknown parameter , and are greater, based on scheme 3 than scheme 1. This is because the expected durations of the experiments using scheme 1, where the remaining units are withdrawn in the first stage, are greater than scheme 3, where the remaining units are withdrawn from the life test at the time of observed m-th failure. Finally, we recommend the Bayesian (point and interval) estimates of the unknown parameter and the reliability characteristics of the xgamma lifetime model using the M–H algorithm sampler.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}