1. Introduction
Multicollinearity occurs when independent variables in the regression model are highly correlated to each other. As a result of multicollinearity, the standard error of the ordinary least squares (OLS) estimate becomes inflated, which weakens the statistical power of the regression model, especially when confronting high dimensional data (HDD). Hence, one may be unable to declare an individual independent variable significant even if it has a strong relationship with the response variable. Moreover, an independent variables’ coefficient may change its signs and renders it more difficult to specify the correct model. Additionally, multicollinearity can cause the correlation matrix of X variables to become singular; thus, OLS fails to produce estimates, and no predictions of the y-variable can be made. These problems become severe when dealing with high dimensional data where . The rapid advancement of computer technology and statistics allows for the generation of data on thousands of variables. Classical multivariate statistical methods are no longer capable of effectively analyzing such high-dimensional data. As a result, Partial Least Squares (PLS) was developed to address this issue, and its applications have gained popularity in a wide variety of natural science fields. For example, PLS is used to quantify genes in genomic and proteomic data. In neuroinformatics, PLS is used to investigate brain function. It is also used in computer science for image recognition and in the engineering industry for process control. PLS was originally designed to solve a problem in chemometrics, but it has since become a standard tool in spectroscopy, magnetic resonance, atomic omission, and chromatography experiments.
Partial Least Squares Regression (PLSR) is introduced with the main aim to build a regression model for multicollinear and high dimensional data with one or several response variables [
1]. This method is very popular in chemometrics [
2], genomic and proteomic analysis [
3], and neural network study [
4] and is widely applied in engineering areas. When dealing with one or multivariate responses, the partial least squares regression is commonly referred to as PLS1 or PLS2, respectively. In general, the PLSR method is used to form a relationship between dependent variables and independent variables by constructing new independent explanatory variables called PLS factors, latent variables, or PLS components. The PLS components describe maximum correlations between predictors and response variables. The concept of the PLS method is similar to the Principal Component Regression (PCR) method. As in PCR, a set of uncorrelated components is formed to make a prediction. The major difference between these two procedures is, in the PLS procedure, the PLS components are chosen based on the maximum covariance of
and
variables while in PCR, the components are chosen with a maximum variance of
variables solely.
There are numerous PLS approaches in the literature, such as NIPALs which was introduced by Wold around 1975 [
5]. NIPALS requires deflation of
and
in order to compute components that are very time consuming for a huge dataset [
5]. Lindgren et al. [
6] proposed the Kernel Algorithm, and the result is identical to NIPALS but in the Kernel Algorithm, deflation is carried out only for the matrix
in the next computation of components. The latter method also requires much time since the procedure works based on eigen decomposition. The SIMPLS technique was introduced by S. De Jong [
7]. In SIMPLS, no deflation of the centered data matrices
and
is made, but the deflation is carried out based on the covariance matrix,
. Hoskuldson [
8] suggested a method similar to the Kernel Algorithm named the Eigenvector algorithm. The idea is to compute all eigenvectors to the largest eigenvalues, where
is the desired number of PLS components. Orthogonal Projections to Latent Structures (O-PLS) was introduced by Trygg et al. [
9] in order to maximize both correlation and covariance between the x and y scores in order to achieve both good prediction and interpretation.
However, it is now evident that PLS is not robust in the sense that its estimate is easily affected by outliers. In regression, outliers can be categorized into vertical outliers, residual outliers, and high leverage points (HLPs) or simply called leverage points [
10]. Vertical outliers are outlying observations in the
-space, while residual outliers are observations that have large residuals. HLPs are the outlying observations in the
-space. It has the most detrimental effect on the computed values of various estimates, which results in incorrect statistical model development and instills impacts on decision making. Therefore, accurate HLPs detection using reliable methods is vital. In general, classical approaches typically fail to correctly identify outliers in the dataset. As a result, the estimated model will be affected by the masking and swamping problems. ‘Masking’ refers to a situation where outliers are incorrectly declared as inliers, while ‘swamping’ refers to normal observations incorrectly declared as outliers.
Since outliers have an unduly effects on the computed values of various classical estimates, robust methods that are not easily affected by outliers are put forward. Robustness refers to the ability of a method to remain unaffected or less affected by outliers. Several robust alternatives to conventional or classical PLS have been suggested in several literature. The key objective of the robust PLS is to discover contaminated data and reduce their effects by assigning smaller weights to them when estimating a regression model. There are two approaches of robust PLS: down weighting of outliers and robustifying the covariance matrix. For instance, Wakeling et al. [
11] used nonrobust initial weights to replace the univariates OLS regression. Cummin et al. [
12] proposed iteratively reweighted algorithms, but the weights were not resistant to high leverage points. For the second approach, Gil et al. [
13] proposed a method based on constructing robust covariance matrices by using the Stahel–Donoho estimator. However, this method cannot be applied to high-dimensional datasets since it uses a resampling technique by drawing subsets of size p + 2. Hubert and Branden [
14] developed robust SIMPLS by constructing a robust covariance matrix using the minimum covariance determinant (MCD) and the idea of projection pursuit to perform on low and high dimensional data. Then in 2005, Serneels et al. [
15] proposed partial robust M-regression (PRM) in order to reduce the effect of outliers in
-space and
-space of predictor variables. In 2017, Aylin and Agostinelli [
16] developed a robust iteratively reweighted SIMPLS (RWSIMPLS) by employing the weight function of Markatou et al. [
17]. The weakness of this weight function is that there is no clear discussion on how the effects of outliers or HLPs are reduced since they did not employ any method of identification of outliers or HLPs. It is possible to incorrectly detect and minimize non-outlier observations.
The work of [
16] has motivated us to improvise their method, i.e., the robust weighted SIMPLS based on a new robust weighting function. The weight is formulated based on the minimally regularized covariance determinant and principal component analysis (MRCD-PCA) algorithm for the identification of HLPs in HDD. MRCD-PCA is the extension work of MRCD [
18], which incorporates the PCA method in the algorithm of MRCD. MRCD-PCA is used for the detection of high leverage points. A simulation study and two real datasets are used to assess the performance of our proposed method compared to SIMPLS and RWSIMPLS. All analyses were performed using R program [
16].
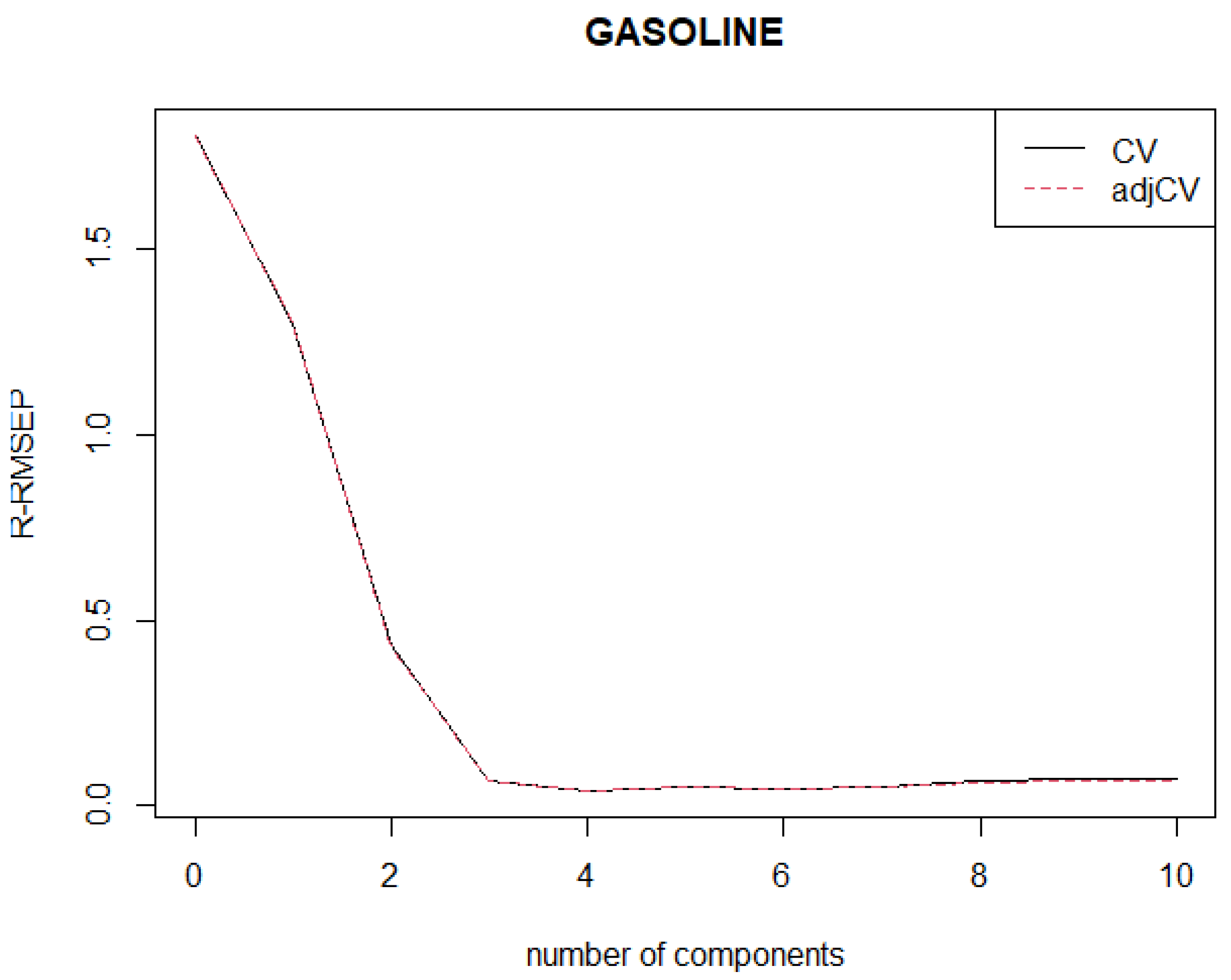
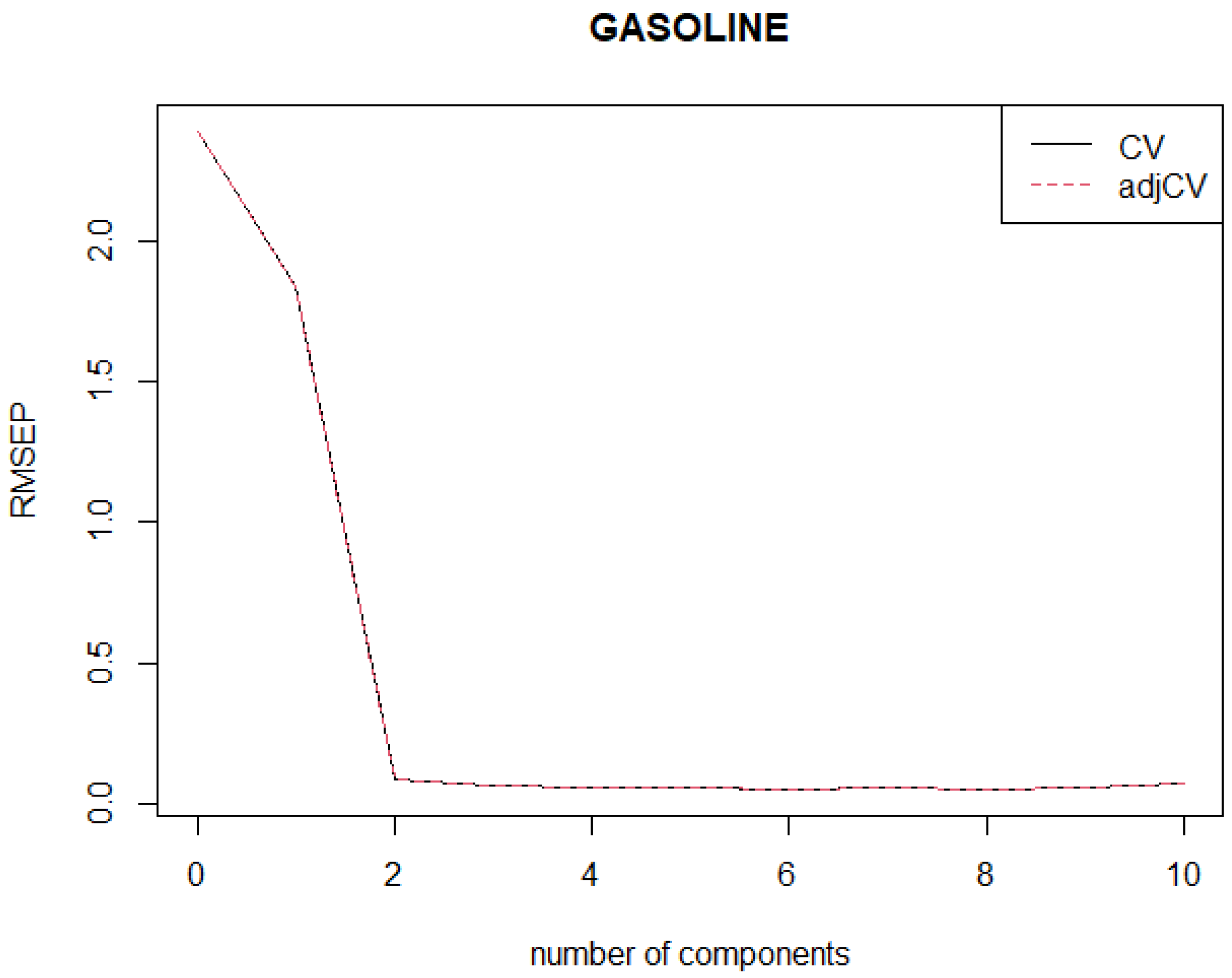
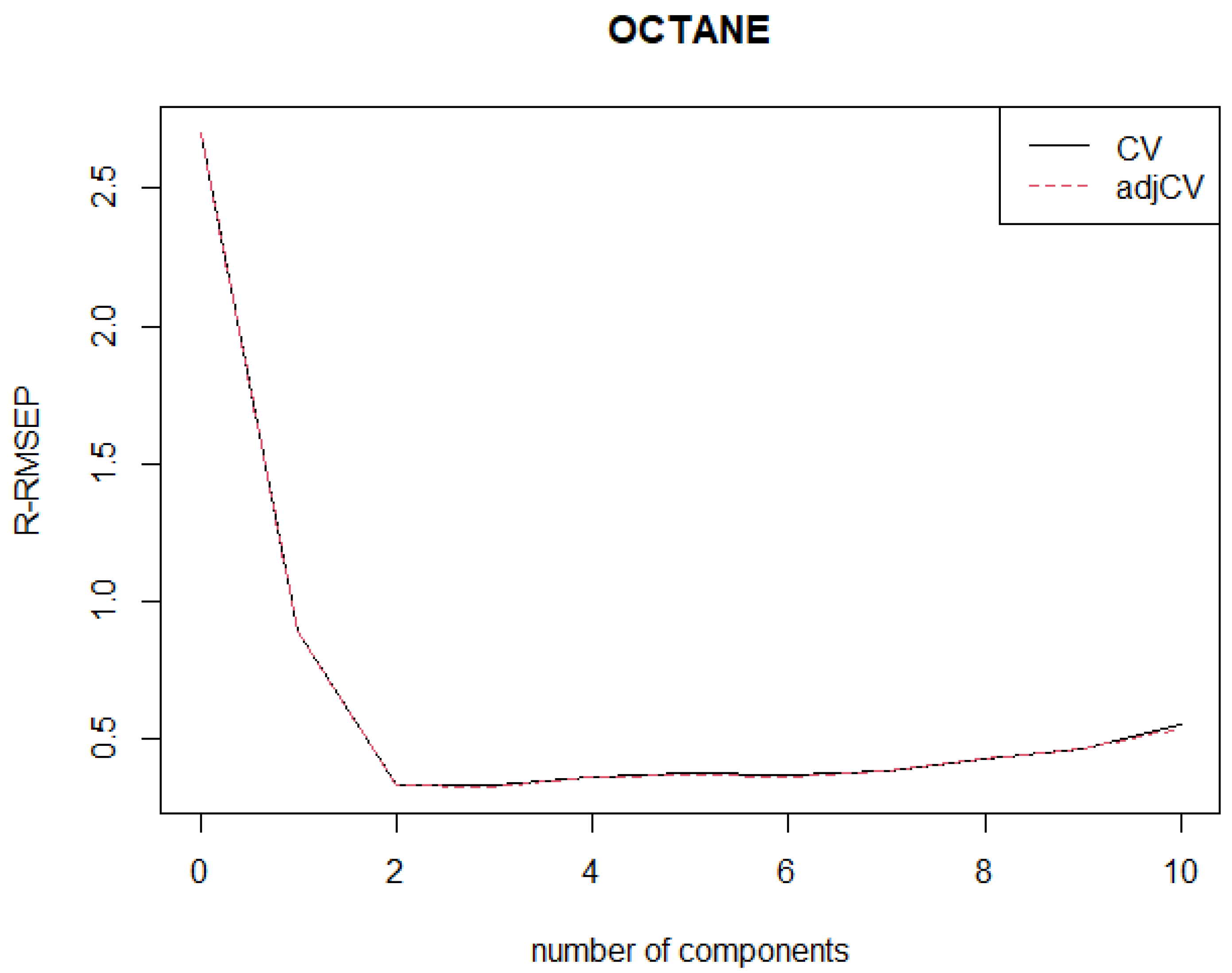
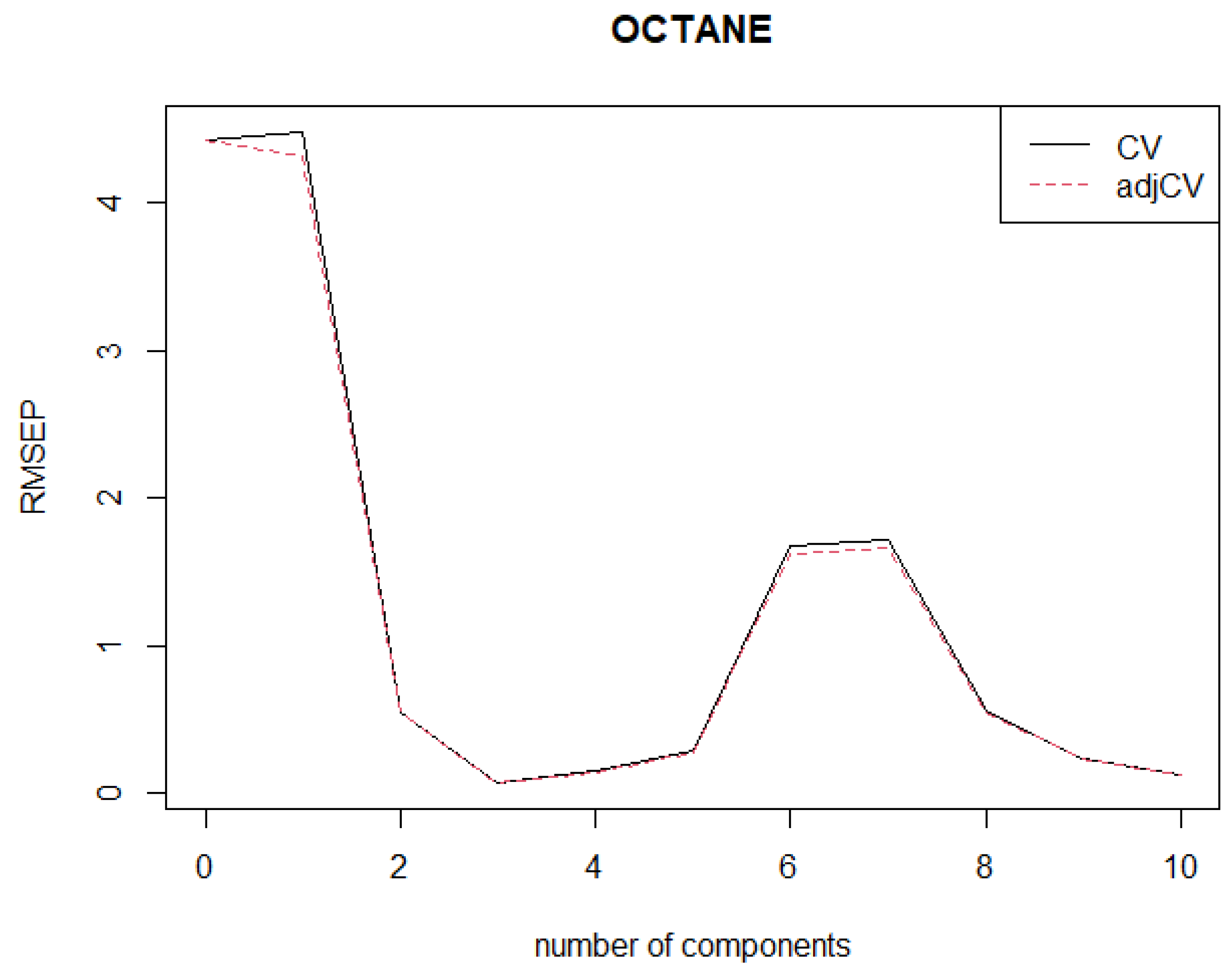
The objectives of this study are as follows: (1) to develop a new robust weighted SIMPLS by incorporating a new weight function based on our newly proposed MRCD-PCA algorithm for identifying HLPs; (2) to establish a new algorithm of classifying observations into four categories including regular or good observations, good leverage points (outlying observations in -space), vertical outliers (outlying observations in -space), and bad leverage points (outlying observations in both -space and -space); (3) to determine the optimum number of PLS components, denoted as , where is determined based on the proposed robust root mean squared error prediction, i.e., R-RMSEP; and (4) to evaluate the performance of the proposed method compared to the existing methods, namely SIMPLS and RWSIMPLS. This paper focusses only on PLS1 regression and SIMPLS.
In the next section, we describe the classical SIMPLS algorithm and some existing robust algorithms. In
Section 3, we present our proposed MRCD-PCA-RWSIMPLS. In
Section 4, we demonstrate the performance of our proposed technique on some simulated data and two real datasets. We compare our method with conventional SIMPLS and the RWSIMPLS methods. We also illustrate our proposed robust diagnostic plots and compute the influence function of real datasets.
2. The SIMPLS Algorithm
The algorithm of SIMPLS maximizes the problem of under the orthogonal constraints of and . The first SIMPLS component is identical to the NIPALS result or the Kernel algorithm, but the following components are different. In the SIMPLS approach, there is no deflation of the data-centered matrices and , but deflation is executed in a covariance matrix or cross-product matrix of and , given as . Thus, the computation of SIMPLS algorithm is much simpler and less complicated than other PLS algorithms.
2.1. Classical SIMPLS
The multiple linear regression or multivariate regression can be written as follows:
where
is a
matrix, containing
values of explanatory variables at
points.
is a p-dimensional column vector containing regression coefficients, and
is
matrix of random errors, and response variable
is a
matrix, where
is a dimension of response variables at
observations.
In the SIMPLS method,
and
variables are modeled by linear latent variables based on regression models as in (2) and (3):
where
is a matrix of predictors with size
, and
is a matrix of response variables with size
.
and
are the error terms, assumed to be independent and identically distributed random normal variables for
and
, respectively.
and
are the score matrices or latent variables of
and
, respectively, and they are formulated as follows:
for
and
. The
matrix
and the
matrix
are the weight matrices that can be computed by singular value decomposition (SVD). The optimal
-weight vector,
, is the first eigenvector of the eigenvalue problem, and the optimal
-weight vector,
, is proportional to
.
and
are the first left and right singular vectors of the cross-product matrix of
.
is the number of PLS component that is less than or equal to
.
and
are the
and
orthogonal loading matrices for
and
, respectively.
The fundamental goal of the SIMPLS is to maximize the covariance between the
(
-scores) and
(
-scores). In conventional SIMPLS, the covariance between vectors t and u is estimated by sample covariance
. The constraint of score vectors,
is needed to solve a problem of maximization. The unique maximization under the constraint of length 1 is given in Equation (6),
The first score vectors and are the solutions to the maximization problem for and spaces, respectively. The subsequent score vectors are maximized in the same manner as in Equation (6) with additional constraints that the subsequent score vectors are orthogonal to previous score vectors, i.e., and for . Instead of the original and matrices, orthogonality is provided by finding the subsequent score vectors on the residual matrices. Different algorithms of PLS provide a different method of calculating residual matrices.
Below is the algorithm of the classical SIMPLS approach [
5].
Step 1: Compute the centered data matrix,
and
, by subtracting the mean of each column, respectively.
Step 2: Based on the centered matrix and in Step 1, determine the initial empirical covariance matrix .
Step 3: Iterate steps 3 to 9 for .
If , .
If , .
This step accounts for the orthogonal scores on all previous score vectors, as the search is performed in the orthogonal complement of .
Step 4: Perform SVD on and obtain the first left singular vector of where is the dominant eigenvector of .
Step 5:
is normalized to possess a Euclidean length of 1.
Step 6: The score matrices
are obtained by projecting matrix
on the optimal direction
, and it can be calculated as follows.
Step 7: Then,
is normalized to possess a Euclidean length of 1.
Step 8: The loading vector of
,
, is determined by regressing the matrix
on
.
Step 9: Next, the loading vector of
,
is calculated as follows.
Note that steps 3 to 9 are iteratively repeated for all extracted
components. Then, the model
can be estimated by computing the final estimated regression coefficient
by using the algorithm above. The parameter estimate
is calculated as described in Equation (14):
where
is the vector of
,
is the vectors of
, and
is the vector of
. The conventional OLS is applied in step 8 and 9. As already mentioned, the conventional methods such as the OLS method is not robust, i.e., it is easily affected by outlying observations particularly to high leverage points. Subsequently, the empirical covariance matrix is not reliable as it is extremely affected by outlying points. Hence, the SIMPLS algorithm produces non-robust estimates, resulting in inefficient estimates and misleading conclusions about the fitted regression model. These drawbacks have inspired researchers to develop many robust SIMPLS algorithms.
2.2. Robust Iteratively Reweighted SIMPLS (RWSIMPLS)
Aylin and Agostinelli [
16] proposed Robust Iteratively Reweighted SIMPLS, which is an improvement of the SIMPLS algorithm where they integrated the weight function suggested by [
17] as in Equation (15) in the SIMPLS algorithm in order to reduce the influence of outlying observations in the dataset:
where
is the residual of the estimate
. This weight function depends on the residual, the chosen model distribution density,
, and the sample empirical distribution,
. For the RWSIMPLS procedure, the components are extracted by deflating a weighted covariance matrix as described in Equation (16):
where
and
are the weighted matrices obtained by multiplying each
row by square root of the following:
where
is the weight of residual corresponding to the
response,
is a dimension of response variables, and
is the number of observations.
The algorithm of RWSIMPLS can be summarized as follows.
Step 1: Center each of the observation in
and
matrices by subtracting the median of each column.
is the dimension of variables, and m is the dimension of .
Step 2: Scale the response variable observations in column
by using median absolute deviation (MAD).
Step 3: Compute the weights for each by using the formula in Equations (13) and (15) and substitute by .
Step 4: Determine the weighted predictor variables
and response variables
by multiplying each row by the squared root of weights.
Step 5: Take a small sample of and out of and without replacement. Then, perform the classical SIMPLS on these selected data, and use to determine the initial coefficient estimates ( is a number of selected sample size).
Step 6: Calculate the residual of where , for and .
Step 7: Scale and center the residual,
, in step 6:
with
. Maronna et al. [
19] suggested the use of
to make
comparable to the standard deviation for normally distributed data.
Step 8: Compute the weights for each
, and then reweight each of the observations in
and
.
Step 9: Compute the reweighted covariance matrix .
Step 10: The classical SIMPLS is applied on to estimate the new coefficients.
Step 11: Repeat the steps 6–10 until convergence, where convergence is achieved when the maximum value of the absolute deviation for two consecutive coefficient estimates is less than .
Step 12: Steps 5–11 are repeated for a few c times, say c = 5 times. The final will be the coefficient with the least value of five absolute deviations.
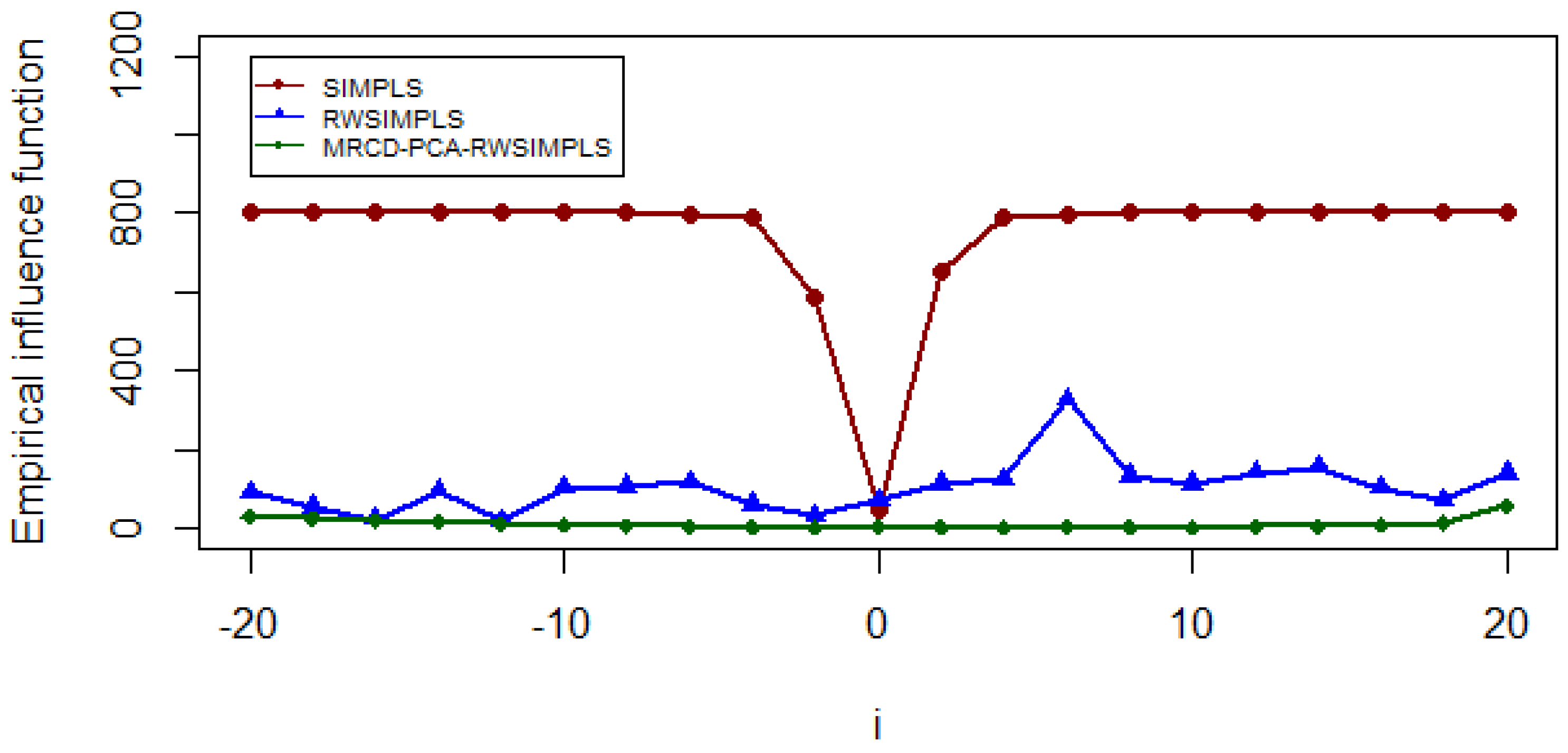
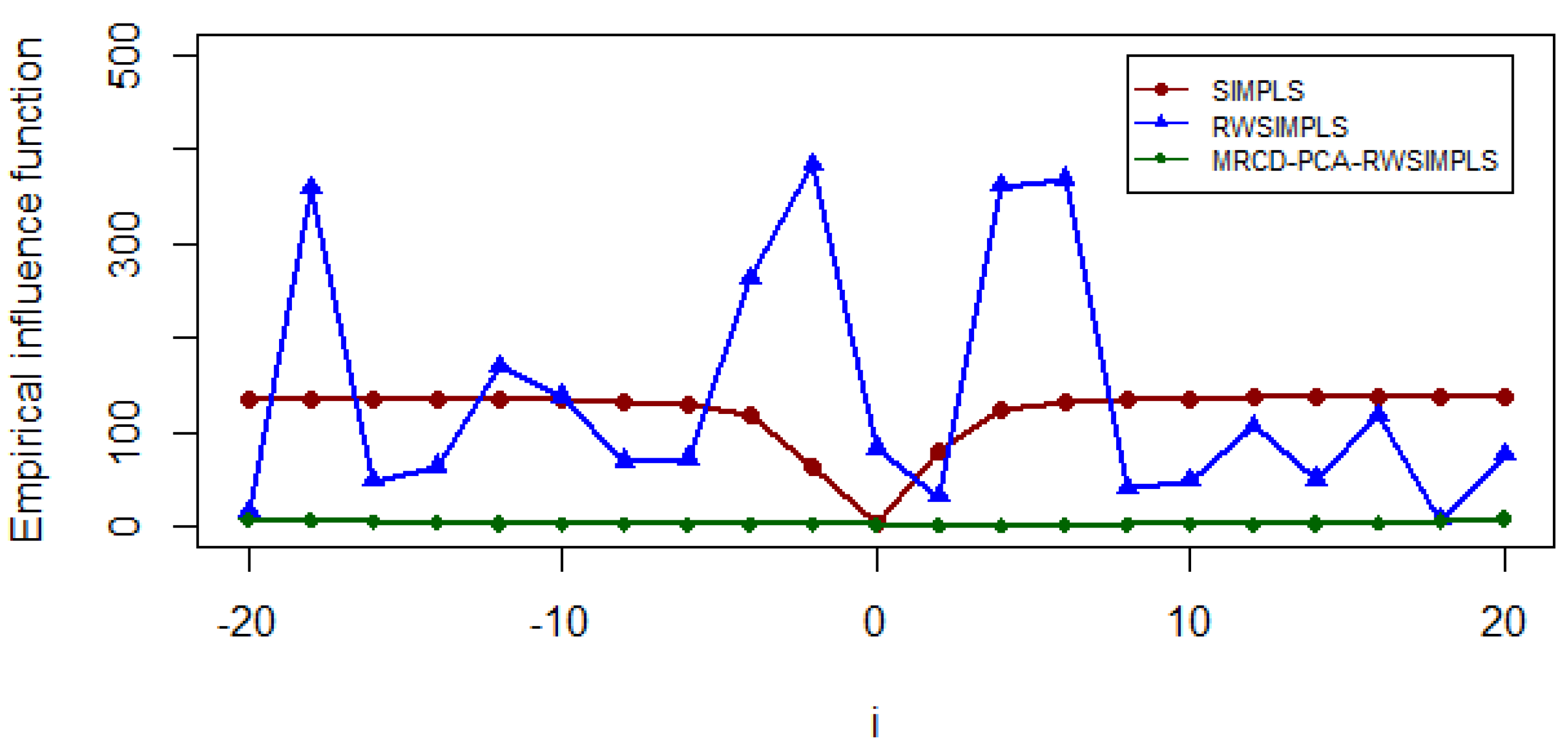
Although RWSIMPLS has been shown to be more efficient than the SIMPLS, it is suspected that it is not efficient enough due to using weighting functions in Equation (15) in the RWSIMPLS procedure. The main aim of using the weighting function in the RWSIMPLS algorithm is to reduce the effect of outliers, especially HLPs. However, no identification of HLPs method is considered when defining the weight function. Instead, [
16] employed weight function as in Equation (15), which is based on the residual, model density, and function distribution but is not based on any method of the identification of HLPs. As a result, there is no guarantee that the weight they proposed will lessen the impact of true HLPs on the parameter estimates, and this will produce a misleading conclusion. This limitation prompted us to propose a new version of RWSIMPLS, which is based on the MRCD-PCA method of identification of HLPs for HDD, denoted as MRCD-PCA-RWSIMPLS. We expect that this method will be more efficient than SIMPLS and RWSIMPLS.
3. The Proposed MRCD-PCA-RWSIMPLS Algorithm
In this section, we introduce our new proposed MRCD-PCA-RWSIMPLS procedure. We first describe how the weighting function is formulated. Then, the full algorithm of the proposed method is illustrated.
3.1. Formulating the Weighting Function
The diagnostic robust Mahalanobis distance based on the combination of minimum regularized covariance determinant and principal component analysis (RMD(MRCD-PCA)) method is expected to be very successful in the detection of multiple HLPs in high dimensional data with sparse structures.
The method consists of three steps whereby, in the first step, the dimension of a high dimensional sparse dataset will be reduced by using the PCA method. The idea to exploit PCA is to replace the original
matrix with k largest eigenvalues to the corresponding eigenvectors. In the second step, we generate a fitted
matrix in the original dimension
based on the chosen number of principal components such that its cumulative variance is at least 80%. In the third step, the fitted
matrix will be shrunk, and an invertible covariance matrix for HDD is yielded. The MRCD [
18] was then performed on these fitted
to determine the robust mean and robust covariance of HDD. By using these robust estimators, the distance of each observation was computed by employing the Robust Mahalanobis Distance (RMD) based on MRCD-PCA.
The advantage of this method is that data are transformed based on the orthogonal PCA components, and it can reduce noise and solve the multicollinearity issue without losing much information. We have the following estimated:
MRCD-PCA location estimates:
MRCD-PCA scatter estimates:
where
is a location estimate based on subset
,
is a diagonal matrix scale for each independent variables,
is vector mean for each independent variable,
is a regularization parameter,
is an eigenvector of identity matrix,
is an eigenvalue of identity matrix,
is an identity matrix,
is a subset of data points with smallest determinant, and
is a sample covariance of
.
Following [
20], after obtaining robust multivariate location and scale estimates given by MRCD, we compute the Robust Mahalanobis Distance (RMD) as follows:
where
and
are the estimates of the robust mean and robust covariance matrix of MRCD-PCA, respectively. Since the distribution of
is intractable, as per [
20], we use a confidence bound type cut-off point as follows.
Any observation that corresponds to
exceeding this cut-off point is considered as HLPs. Following [
21,
22], a weight function is formulated based on the diagnostic method of the detection of outliers with the main aim of reducing their effect on the parameter estimates. Thus, we formulate a new weight function based on
as follows:
where weight equals to
is given to leverage points, and a weight equal to 1 is given to regular observations. Subsequently, this weight is integrated in the establishment of the MRCD-PCA-RWSIMPLS algorithm.
In our proposed algorithm, we scaled the dataset, , by using robust weighted mean, , and robust weighted standard deviation, . The empirical covariance in our algorithm is computed based on the robust scaled weighted dataset, and . Then, we extract PLS-components by deflating a robust scaled weighted covariance matrix, .
3.2. The Proposed Algorithm of MRCD-PCA-RWSIMPLS
Step 1: Calculate the weights as in Equation (31) and store them in a diagonal matrix.
Step 2: Compute the robust weighted mean and robust weighted standard deviation for each column of
and column of
matrices:
where
is a robust weighted mean of column
,
is a robust weighted standard deviation of column
,
is a robust weighted mean of column
, and
is a robust weighted standard deviation of column
.
Step 3: Center and scale each of the data,
and
, by using robust weighted mean and robust weighted standard deviation in Step 2.
Step 4: Determine the robust weighted covariance based on the weighted scaled observations in step 3.
Step 5: Perform ordinary SIMPLS as in
Section 2.1 on robust scaled weighted dataset,
and
, by using the robust weighted scaled covariance,
, in Step 4 to determine the estimated coefficients.
Step 6: Note that Steps 4 to 5 are repeated for all , i.e., the optimal number of components selected based on robust root mean squared error prediction . We call this algorithm a robust weighted SIMPLS based on MRCD-PCA (MRCD-PCA-RWSIMPLS).
3.3. The Proposed Diagnostic Plots Based on MRCD-PCA-RWSIMPLS
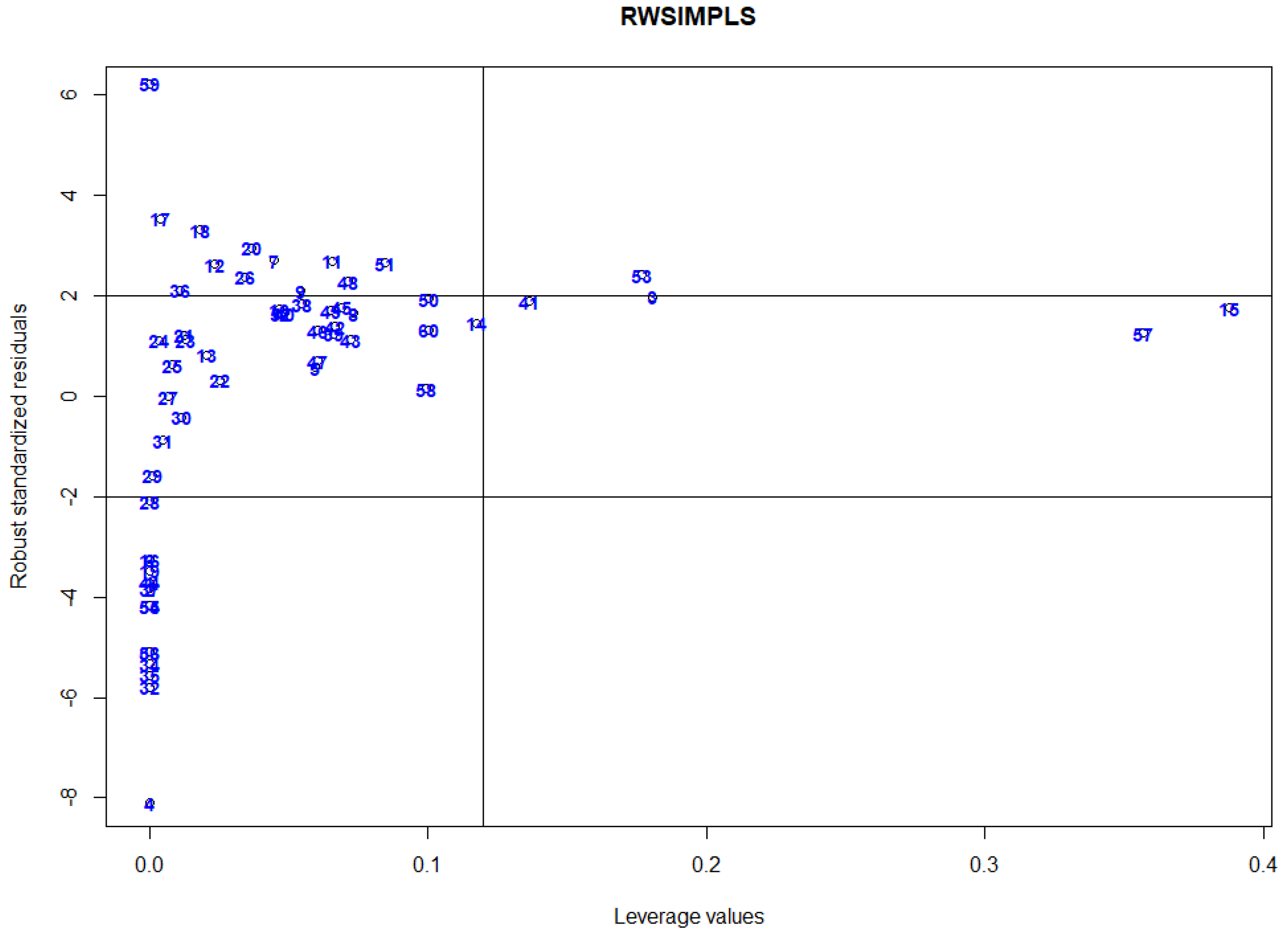
A diagnostic plot is very useful for practitioners to quickly capture abnormalities in data. Rousseeuw and Zomeren [
23] established a diagnostic plot to classify observations into four types of data points, namely regular observations, good leverage points, vertical outliers, and bad leverage points. The proposed plot plots the standardized residual versus squared robust Mahalanobis distance based on minimum volume ellipsoid (MVE) or minimum covariance determinant (MCD). In PLS regression analysis, orthogonal, score, and residual distance can be used to measure the degree of outlyingness of an observation [
14]. Aylin and Agostinelli [
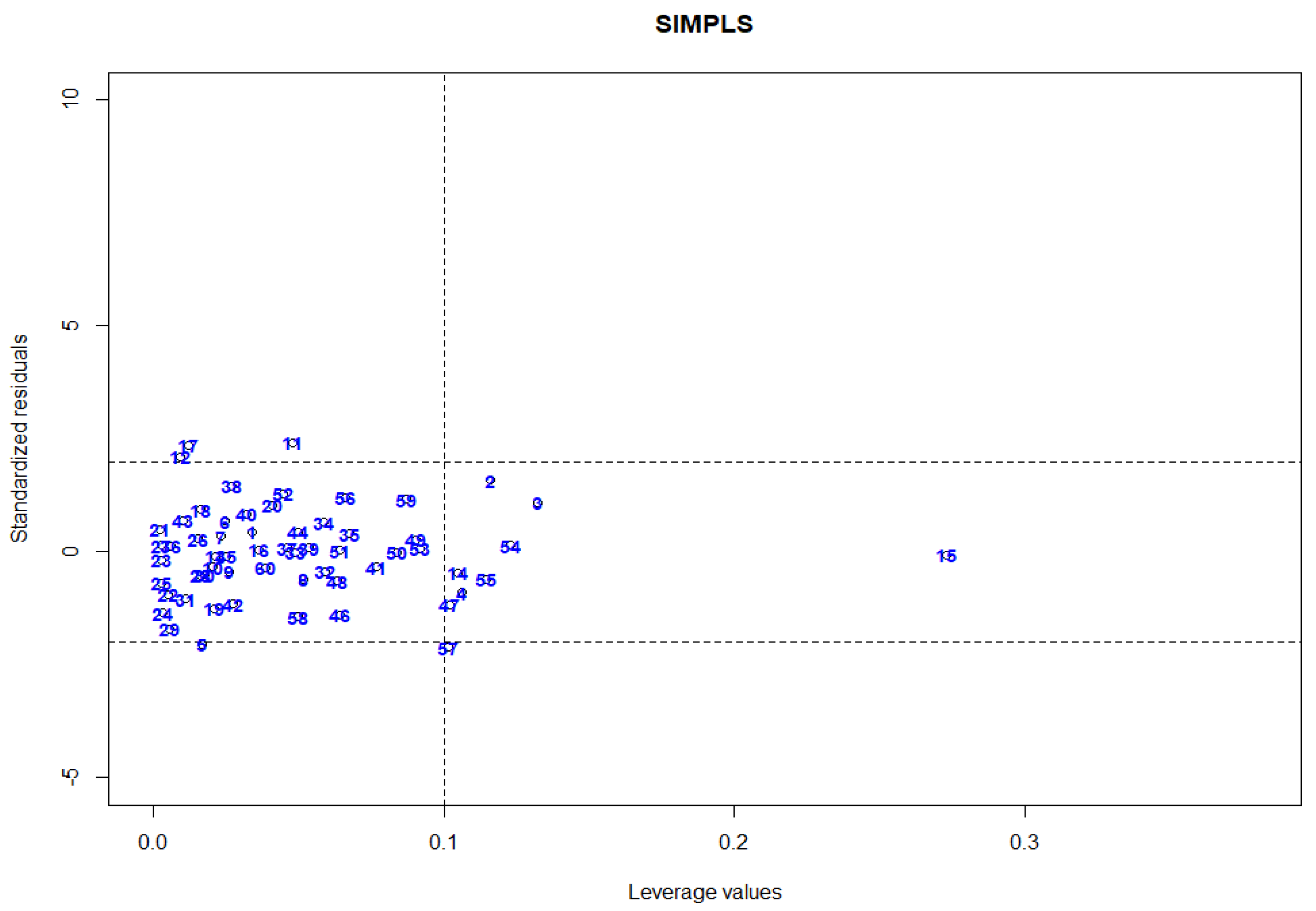
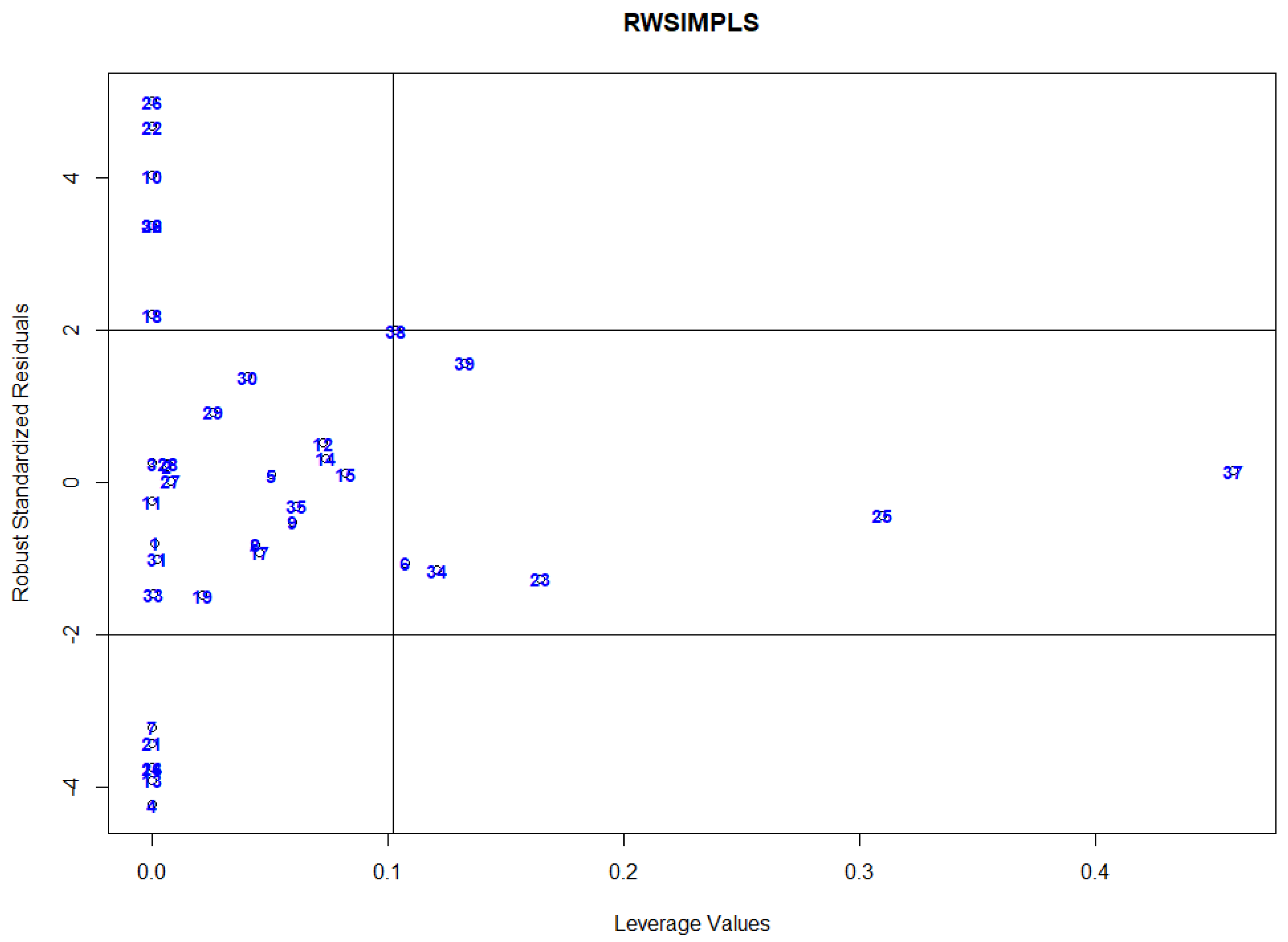
16] proposed a diagnostic plot to classify observations into four types of data points by plotting RWSIMPLS standardized residuals versus leverage values, i.e., the diagonal elements of the hat matrix that is used to identify HLPs. Any observation that corresponds to a leverage value larger than the cut-off points, 2p/n, is considered as HLPs. The disadvantage of this plot is that it employs leverage values that are proven to not be very successful in detecting multiple HLPs due to the masking effect [
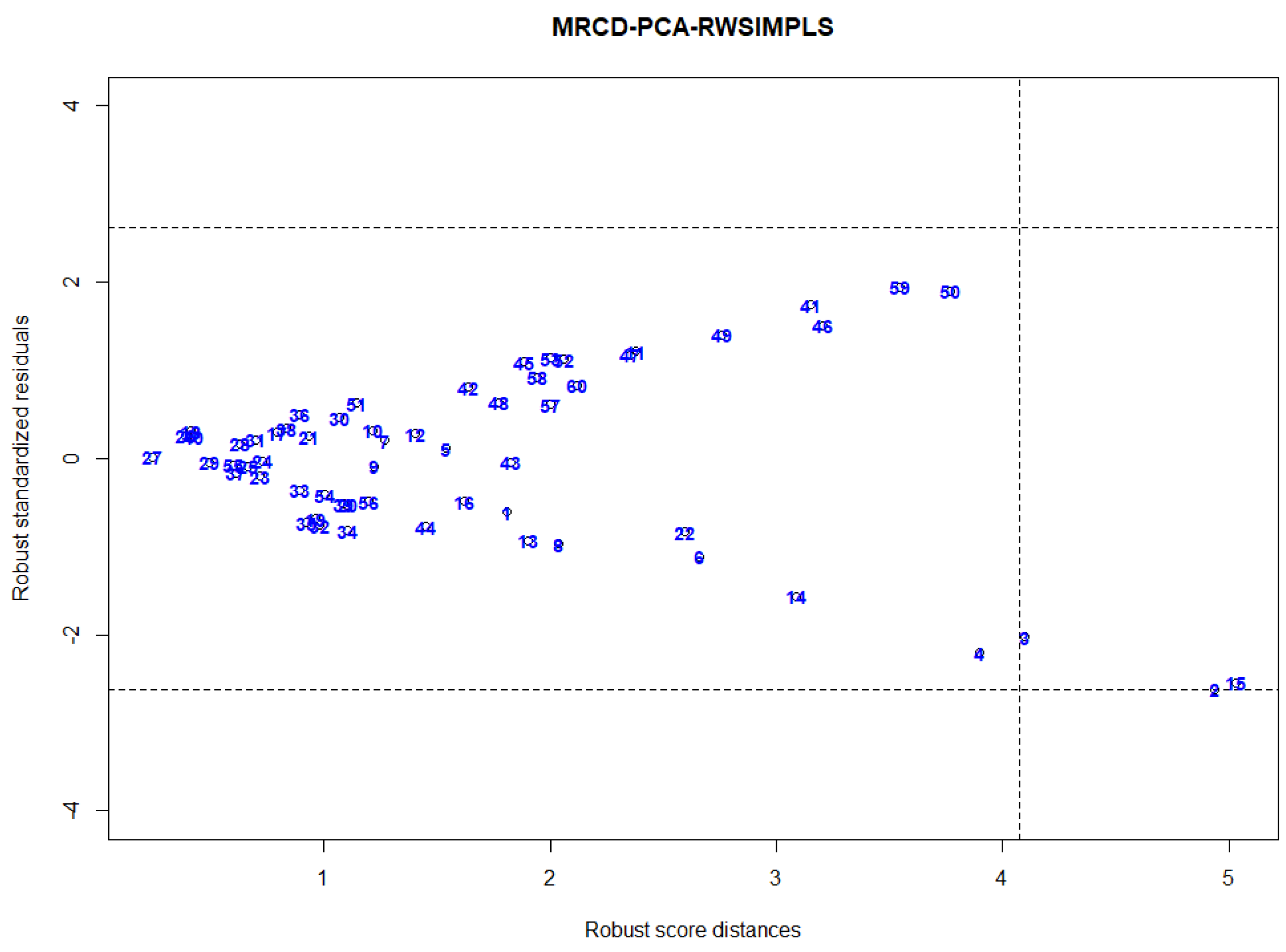
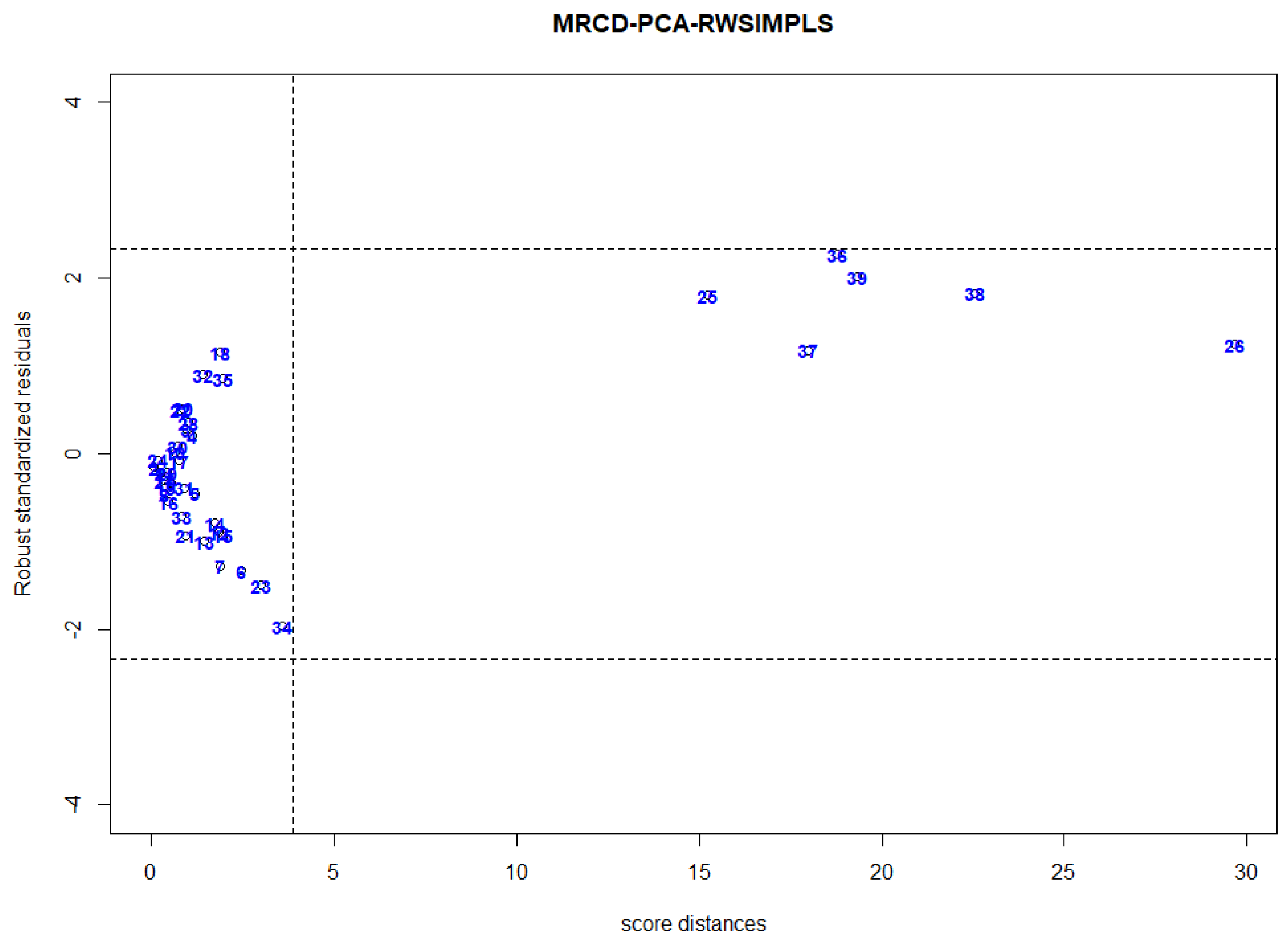
24]. Hence, using leverage values as diagnostic measure for identifying HLPs will produce unsatisfactory results. Thus, we propose a new diagnostic plot by plotting the MRCD-PCA-RWSIMPLS standardized residual against the robust Mahalanobis distance as in Equation (29) and cut-off point as in Equation (30).
The robust standardized residual-score distance plot is a scatter plot of the robust standardized residual versus the robust diagnostic measure for identifying HLPs. The vertical axis of the graph is the robust standardized residual, and the horizontal axis is the robust score distance, as described Equation (29). The standardized robust residual and robust score distance threshold lines are also shown on the plot to indicate the existence and the types of outliers. Based on the robust standardized residual-score distance plot, we can categorize observations into four categories:
Observations in the lower-left corner are “regular observations”
In the upper left corner are the observations that are far away from the space and the observations that have large robust standardized residuals. These points are known as “vertical outliers”
Observations in the lower right corner are “good leverage points” The points are far from the PLS space but proceed in the direction of the fitted line. These observations have a large robust score distance with a small robust standardized residual.
Observations in the upper right corner are “bad leverage points” that have large robust standardized residual and large robust score distances.
![Symmetry 13 02211 i001]()
It is important to highlight the difference between Rousseeuw and Zomeren [
23] and our proposed diagnostic plots. The diagnostic plot proposed by Rousseeuw and Zomeren [
23] plots standardized least trimmed squares residuals on the Y-axis while the robust Mahalanobis distance based on minimum volume ellipsoid (MVE) or minimum covariance determinant (MCD) is plotted on the X-axis. This plot can only be used for low dimensional data. Our proposed MRCD-PCA-RWSIMPLS diagnostic plot plots the MRCD-PCA-RWSIMPLS standardized residuals against the robust score distance based on the MRCD-PCA diagnostic measure for identifying HLPs for HDD. Our proposed plot can be applied to both low and high dimensional data.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}