7.1. Insurance-Claims Application
In this section, we analyze the insurance-claims payment triangle from a U.K. motor non-comprehensive account; see [
18]. We set the origin period as being from 2007 to 2013. The insurance-claims payment data frame presents the claims data in its typical form as it would be stored in a database. The first column presents the origin year from 2007 to 2013, the second column presents the development year and the third column has the incremental payments. It is worth mentioning that this insurance-claims data are first analyzed under a probability-based distribution. However, many other interesting insurance data can be analyzed using the new model; see, for example, [
19] (for extreme value theory as a risk management tool with useful applications), [
20] (for a review in skewed distributions in finance and actuarial science), [
21] (for details about modeling claims data with composite Stoppa models), [
22] (for more right censored medical and reliability data sets), [
23] (for the jointly modeling area-level crash rates by severity with Bayesian multivariate random-parameters spatiotemporal Tobit regression), [
24] (for the investigating the impacts of real-time weather conditions on freeway crash severity), [
25] (for more copulas and a modified right censored test for validation) and [
26] (for an alternative four-parameter exponentiated Weibull model with Copula, properties and real data modeling). For modeling the claims data, we first need to explore it. A real data set can be explored either numerically, graphically or both. In this section, we consider the numerical technique (see
Table 5) and many graphical techniques such as the Cullen–Frey plot for exploring initial fit to the theoretical common distributions such as uniform, normal, exponential, beta, lognormal, logistic and Weibull models. The bootstrapping method is also applied and plotted in the same plot. Note that the Cullen–Frey plot is used just to compare the models in the space of squared skewness and kurtosis. Many other graphical plots are used, such as the NKDE plot, the Q–Q plot, the TTT plot and the box plot. For exploring the autocorrelation between any two claims value, the autocorrelation function (ACF) plots are presented. The theoretical ACF and the partial ACF (Lag
) are also presented.
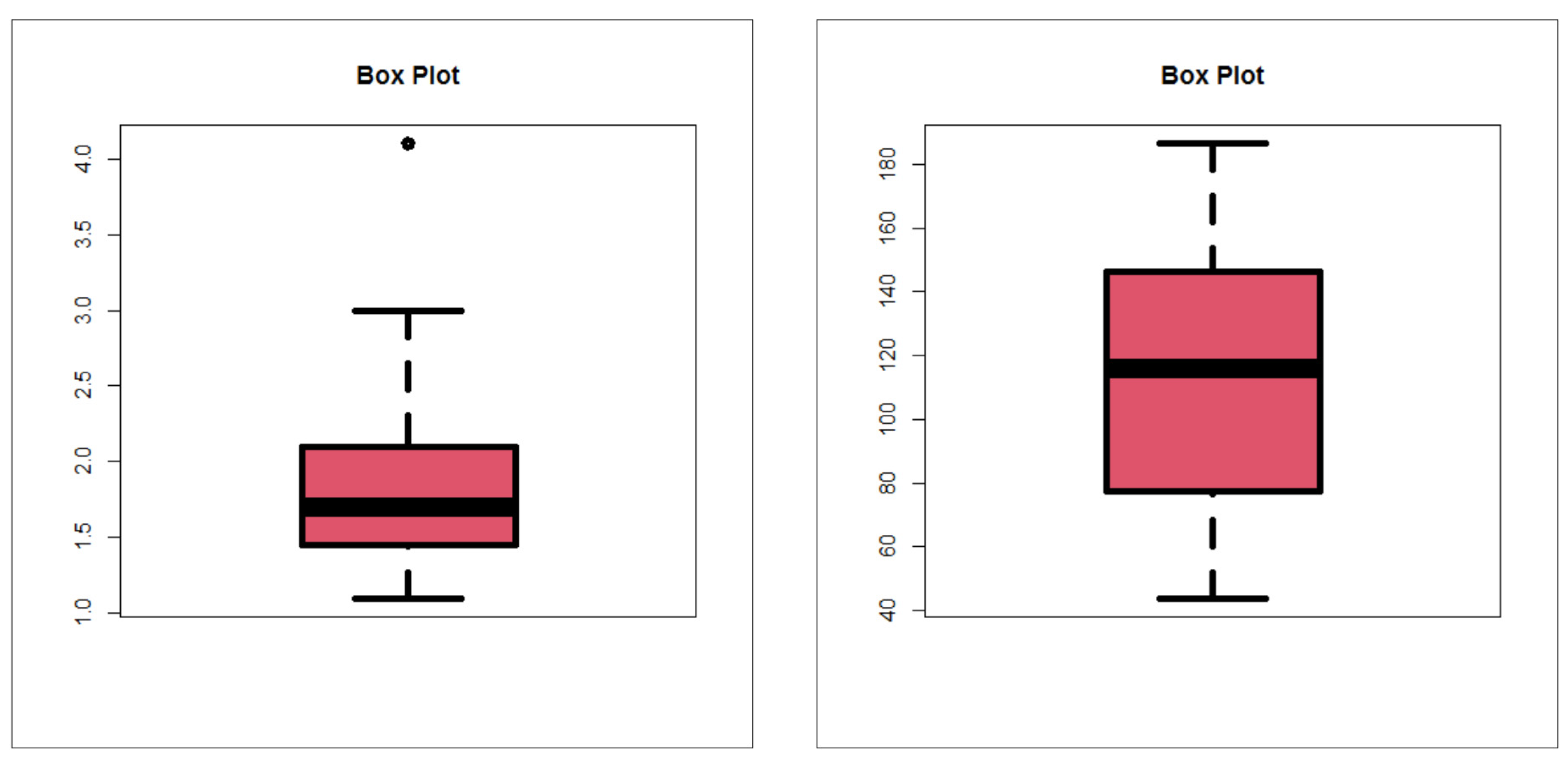
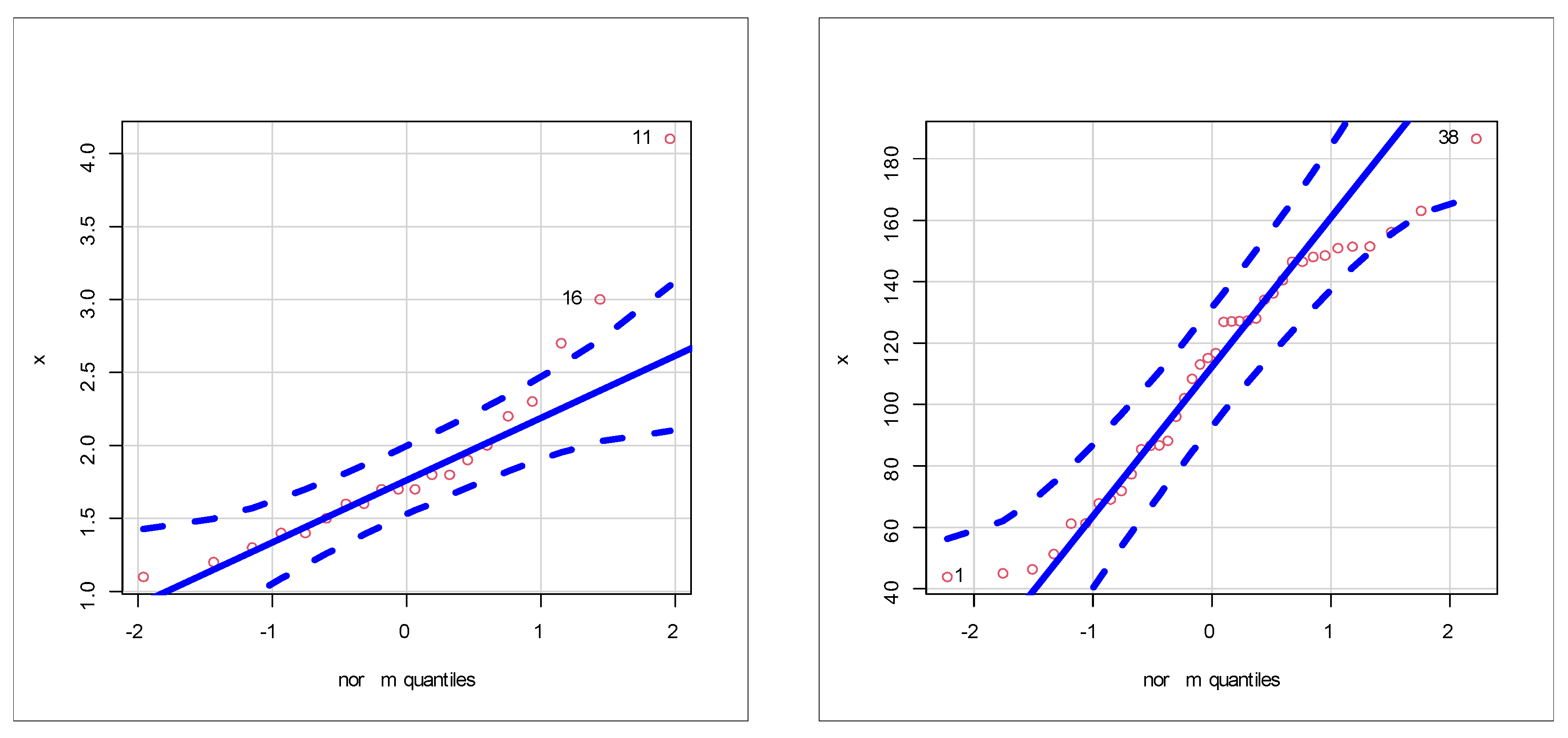
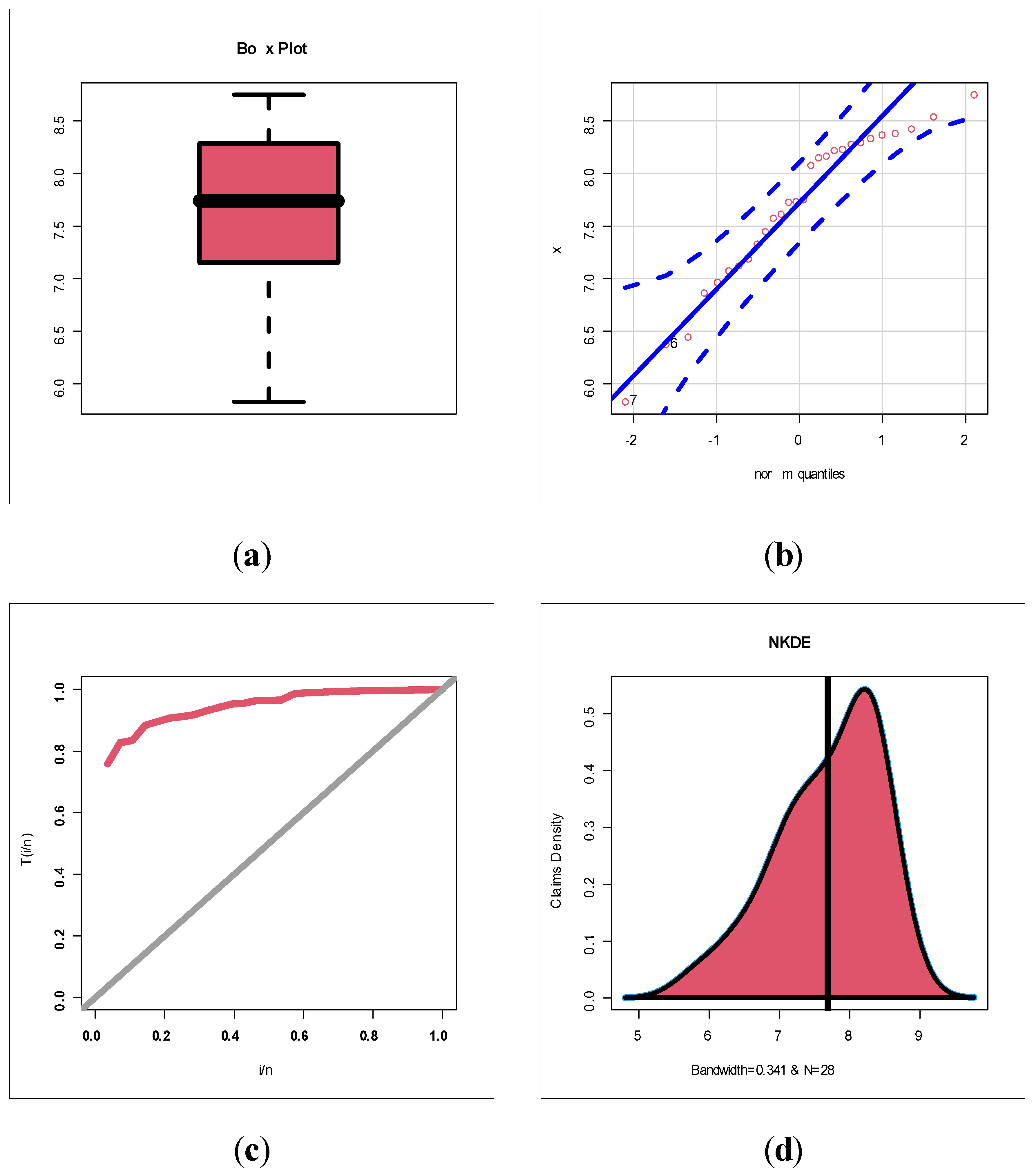
Figure 10 (top left) gives the box plot for the insurance claims.
Figure 10 (top right) gives the Q–Q plot for the insurance claims.
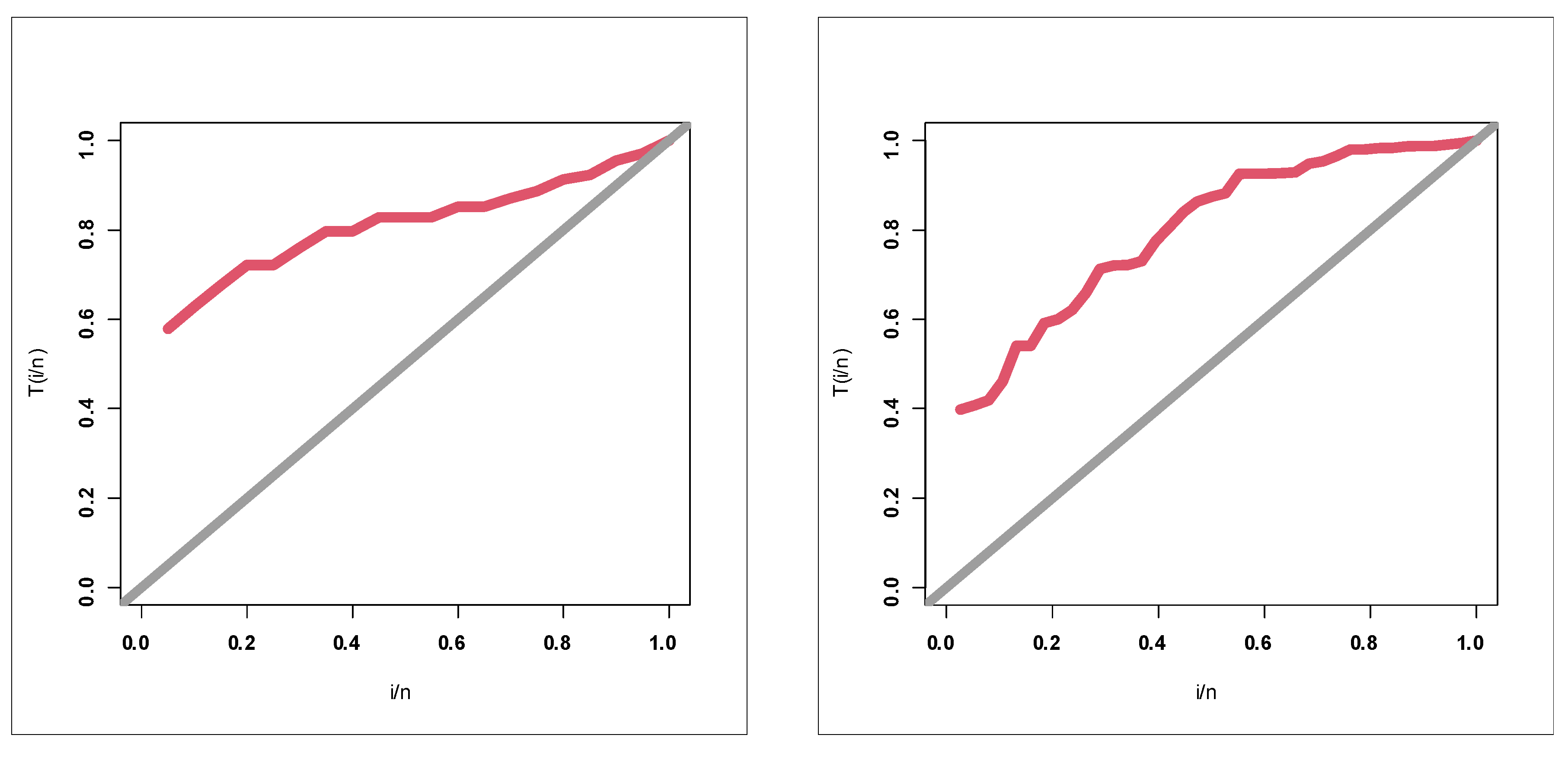
Figure 10 (bottom left) gives the TTT plot for the insurance claims.
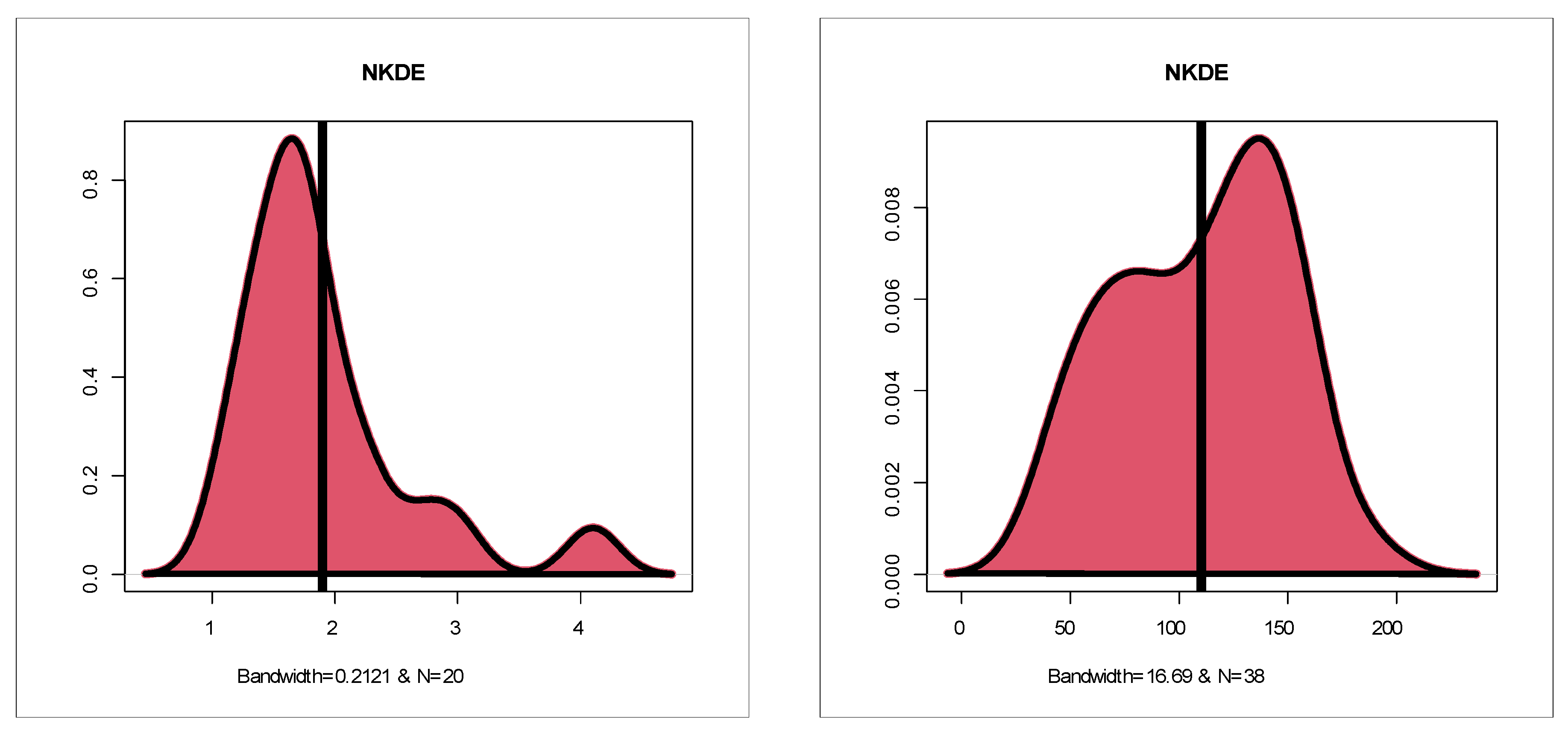
Figure 10 (bottom right) gives the NKDE plot for the insurance claims.
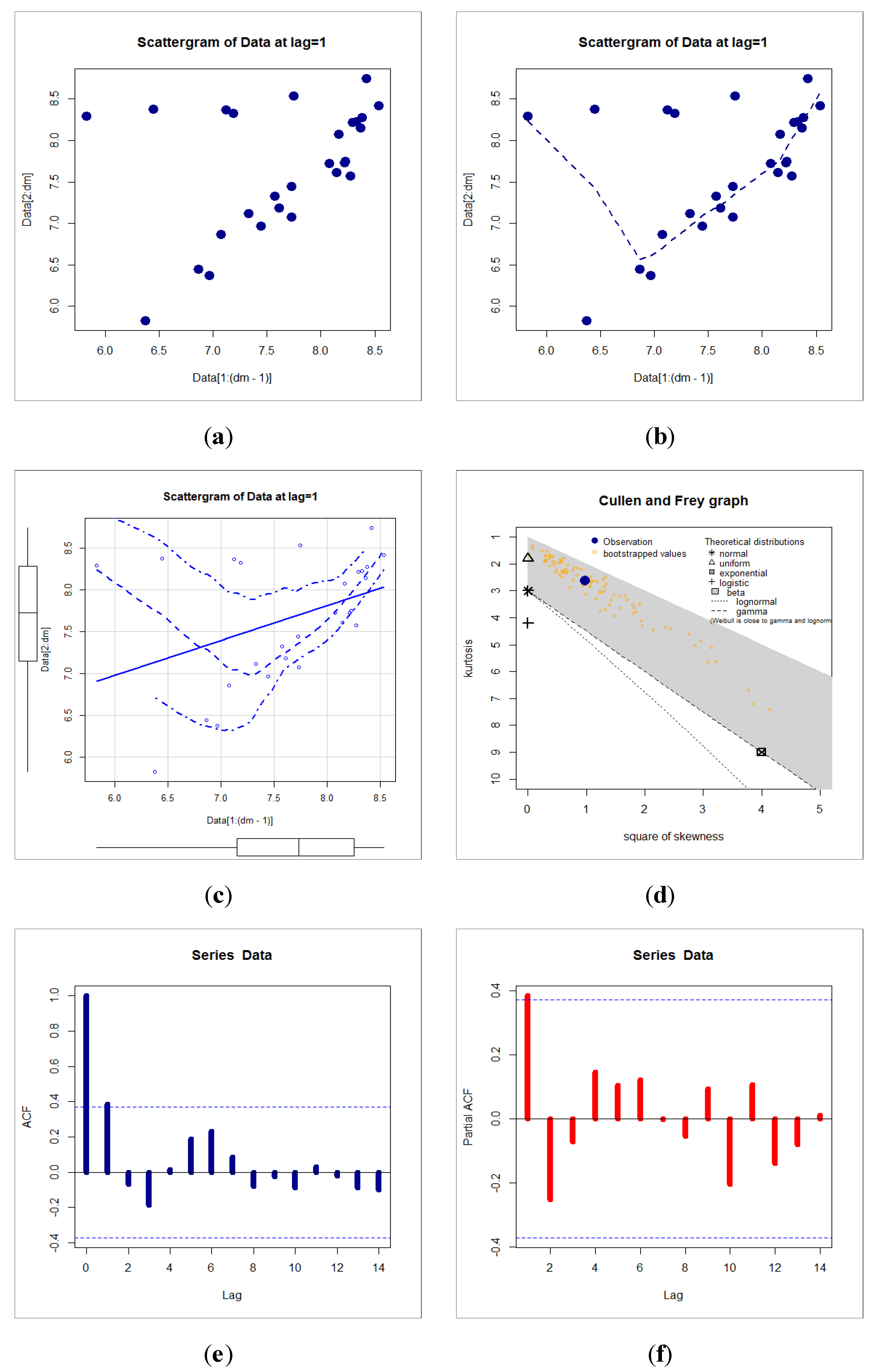
Figure 11 (first, second and third plots) shows the scattergrams for insurance claims (Lag
).
Figure 11 (fourth plot) gives the Cullen–Frey plot for the insurance claims. Based on
Figure 11 (fourth plot), it is noted that we have left-skewed data and do not follow any of the above theoretical models.
Figure 11 (fifth and sixth plots) gives the ACF (Lag
) and partial ACF (Lag
), respectively. Based on
Figure 10 (top left and top right), we see that no extreme observations were spotted. Based on
Figure 10 (bottom left), it is noted that the HRF of the claims is “monotonically increasing”.
Figure 10 (bottom right) shows that the initial NKDE is an asymmetric function with a left tail. Based on
Figure 11 (fifth and sixth plots), we note that that the first lag value (Lag
) is statistically significant, whereas the other partial autocorrelations for all other lags are not significant. Thus, the AR(1) model is suggested for the claims distribution.
Table 5 below lists a statistical summary for the claims payment. Based on
Table 5, it is noted that the Kurtosis of claims = 2.788464
3, skewness of claims =
0.748278 (left-skewed claims data) and dispersion index of claims (Dis.Ix) = 0.0708352 (under dispersed claims data).
For modeling the insurance-claims data using a probability distribution, we consider some competitive potential probability distribution and hence compare those models with our new model under some goodness-of-fit test statistics. For this purpose, we consider some Chen extensions such as reduced Rayleigh Chen (RRC), the standard exponentiated distribution, the Burr X exponentiated Chen (BXEC) distribution, Burr XII Chen (BXIIC) distribution, Marshall–Olkin generalized Chen (MOGC) distribution, exponential Chen (EC), reduced Burr X Chen (RBXC), Weibull Chen (WC) and Lomax Chen (LxC) among others. The results of the statistical analysis for the insurance-claims data are presented in
Table 2 and
Table 3.
Table 6 gives the competitive models, estimates and standard error (SEs) for insurance-claims data.
Table 7 lists the test statistics for insurance-claims data.
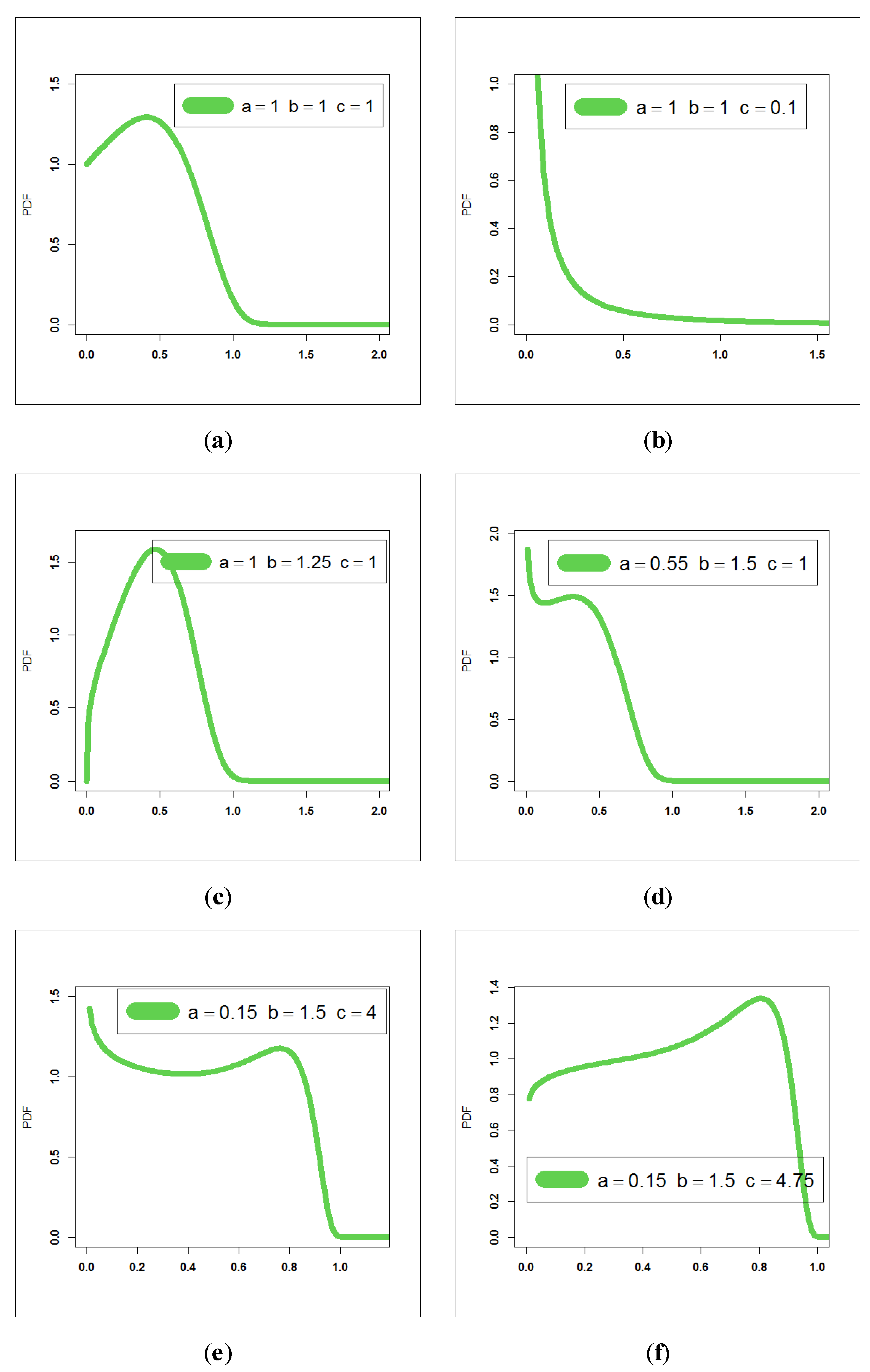
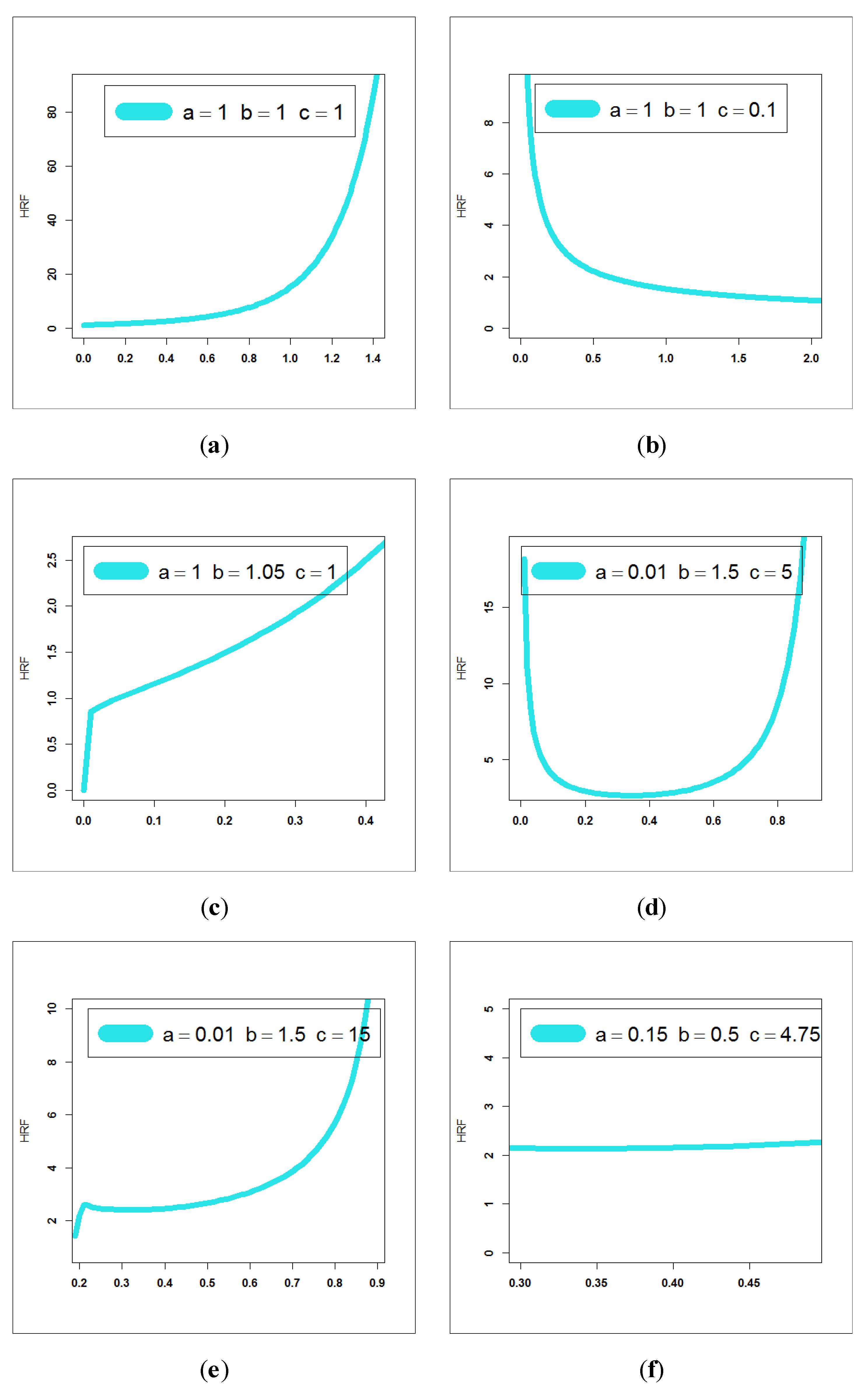
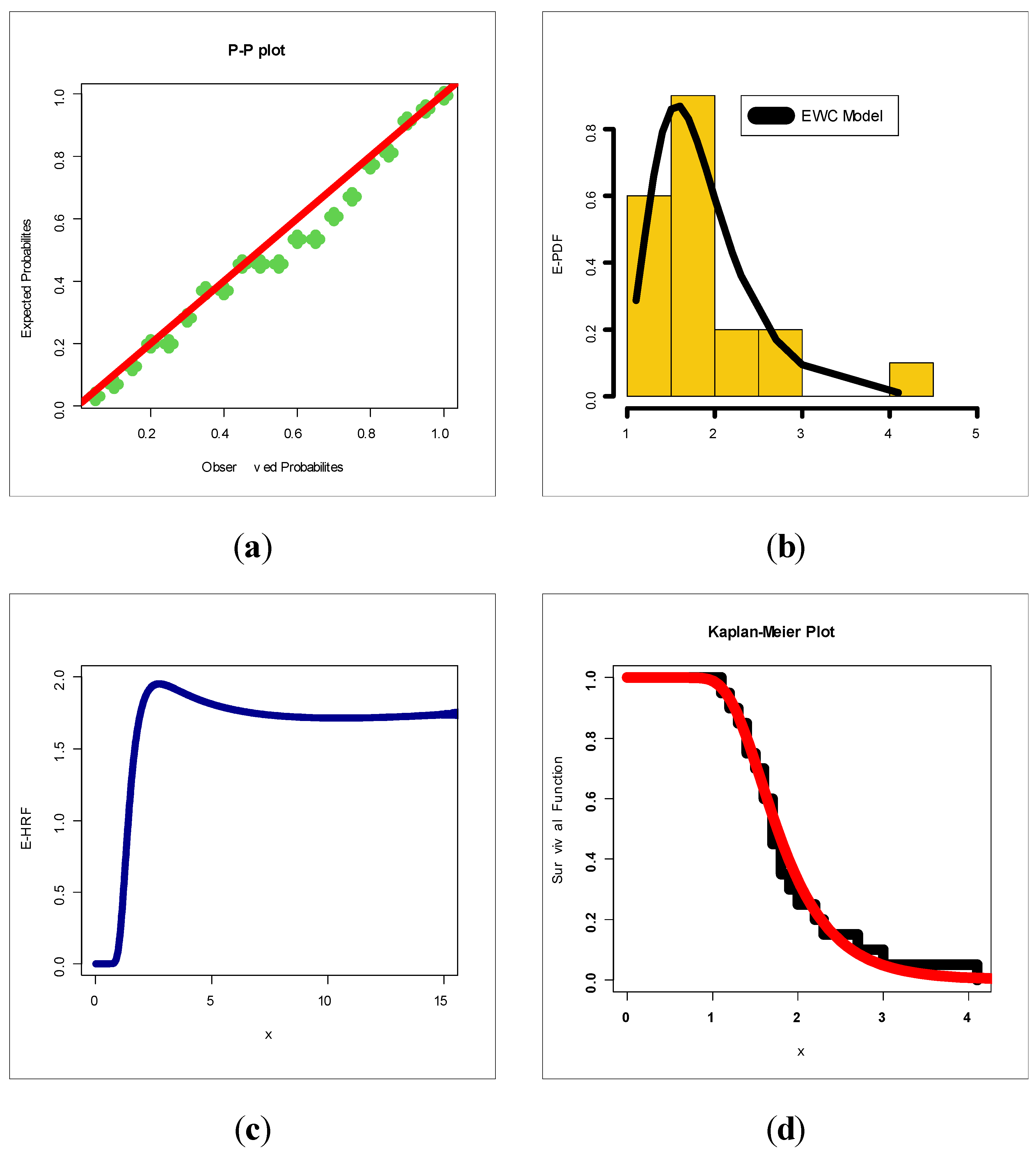
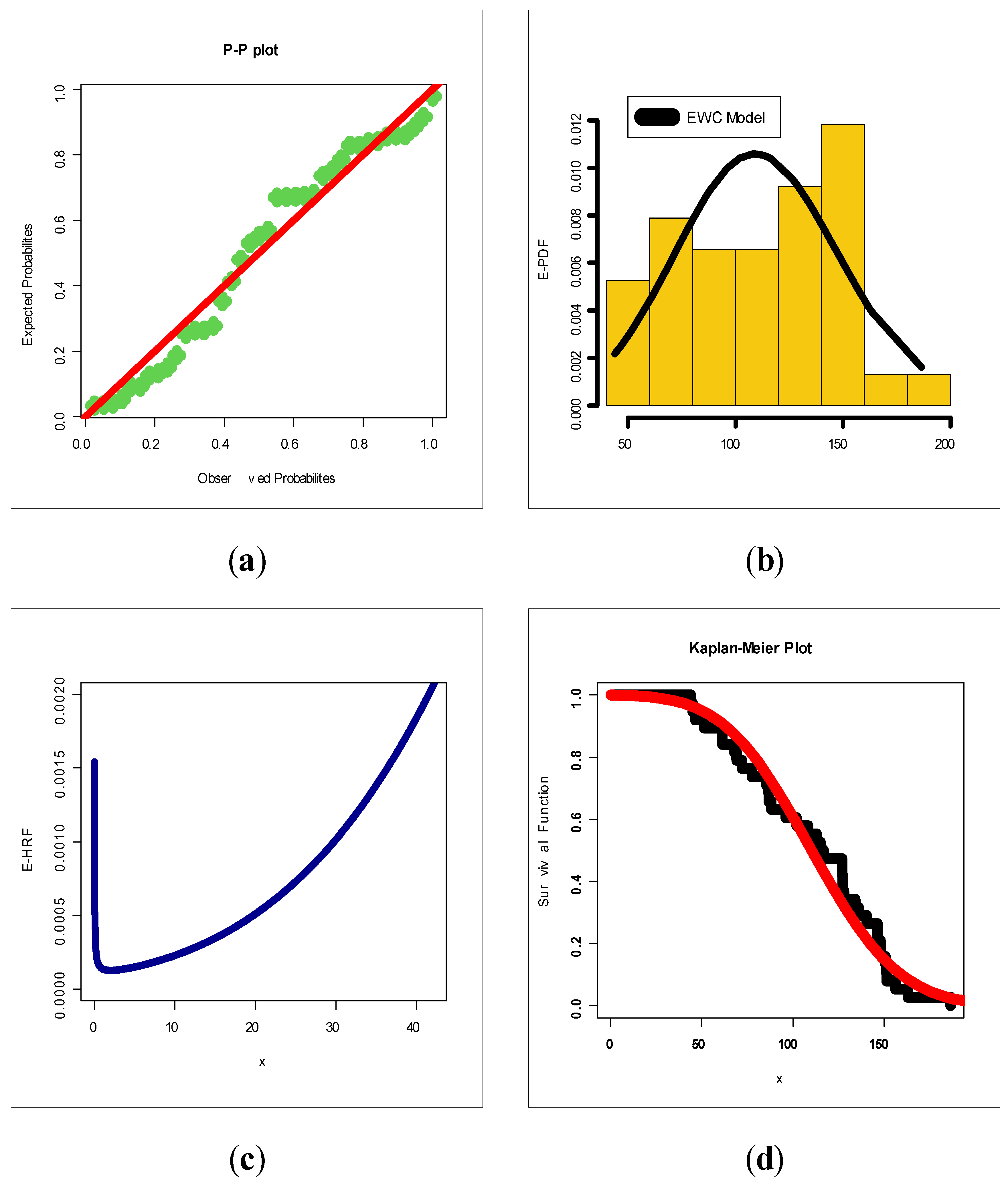
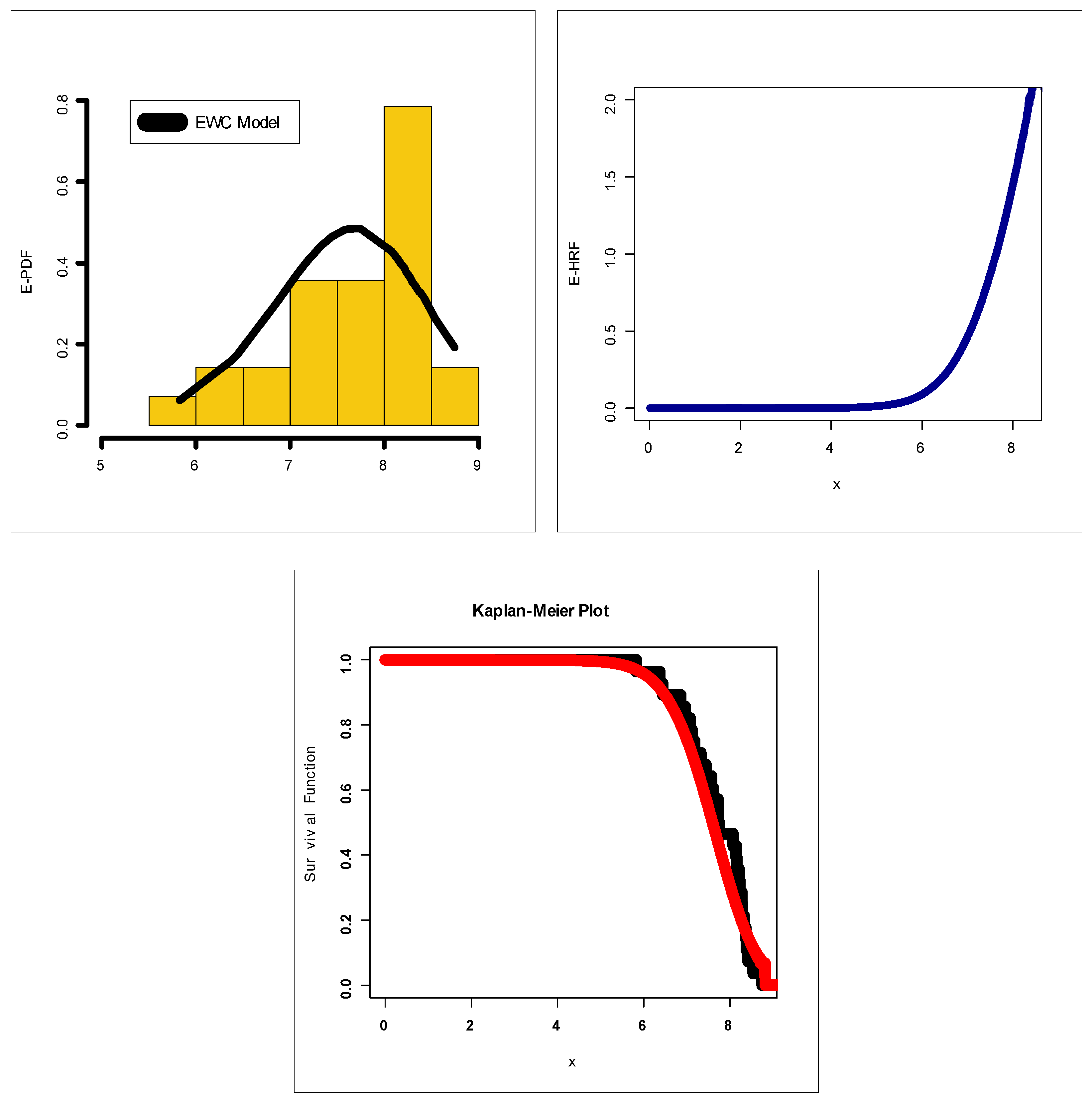
Figure 7 presents estimated PDF (E-PDF), estimated HRF (E-HRF) and Kaplan–Meier survival plots for insurance-claims data.
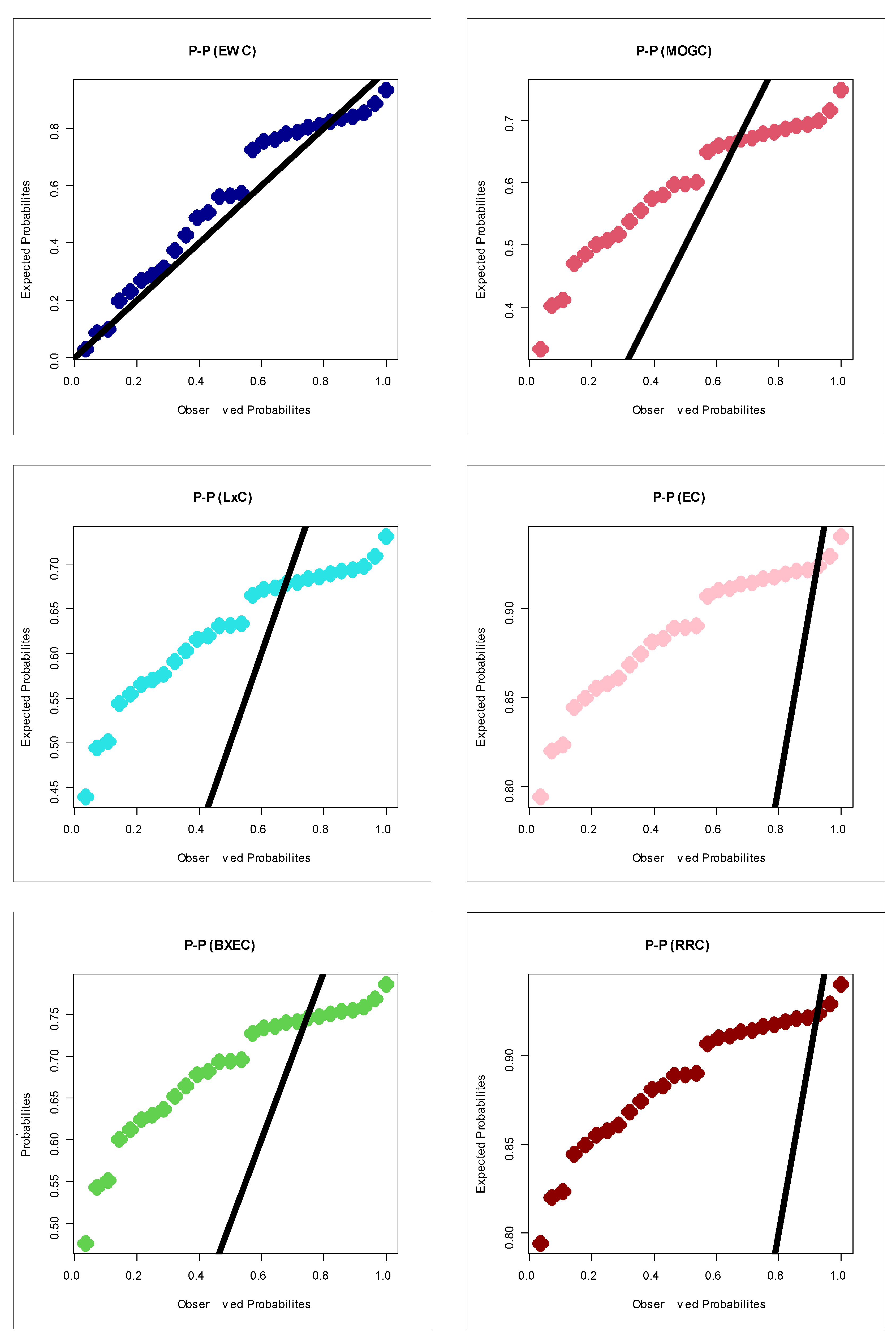
Figure 7 gives the probability–probability (P–P) plots for all of the competitive models. Based on
Figure 12 (left panel), it is seen that the E-PDF of the EWC fits the histogram of the insurance-claims payments and that the two shapes are negative skewed. Based on
Figure 12 (middle panel), it is seen that the E-HRF is increasing. Based on
Figure 12 (right panel), it is seen that the estimated survival function of the EWC fits the Kaplan–Meier survival plot of the insurance-claims data. Based on
Figure 12 (the E-PDF, E-HRF and the Kaplan–Meier survival plots), it is seen that the EWC model provided an adequate fit to the negative skewed claims payments. According to the P–P plots (see
Figure 13), one can clearly note that the EWC model is the most reasonable probability model out of all other competitive Chen models. Based on
Table 6 under the AIC, BIC, CvM, AD, the Kolmogorov–Smirnov test and its corresponding
p-value (under the chi-square goodness-of-fit test), the EWC model is the best among all competitive Chen models.
Based on
Figure 1 (fifth and sixth plots), the AR(1) model is suggested to present the insurance-claims payments.
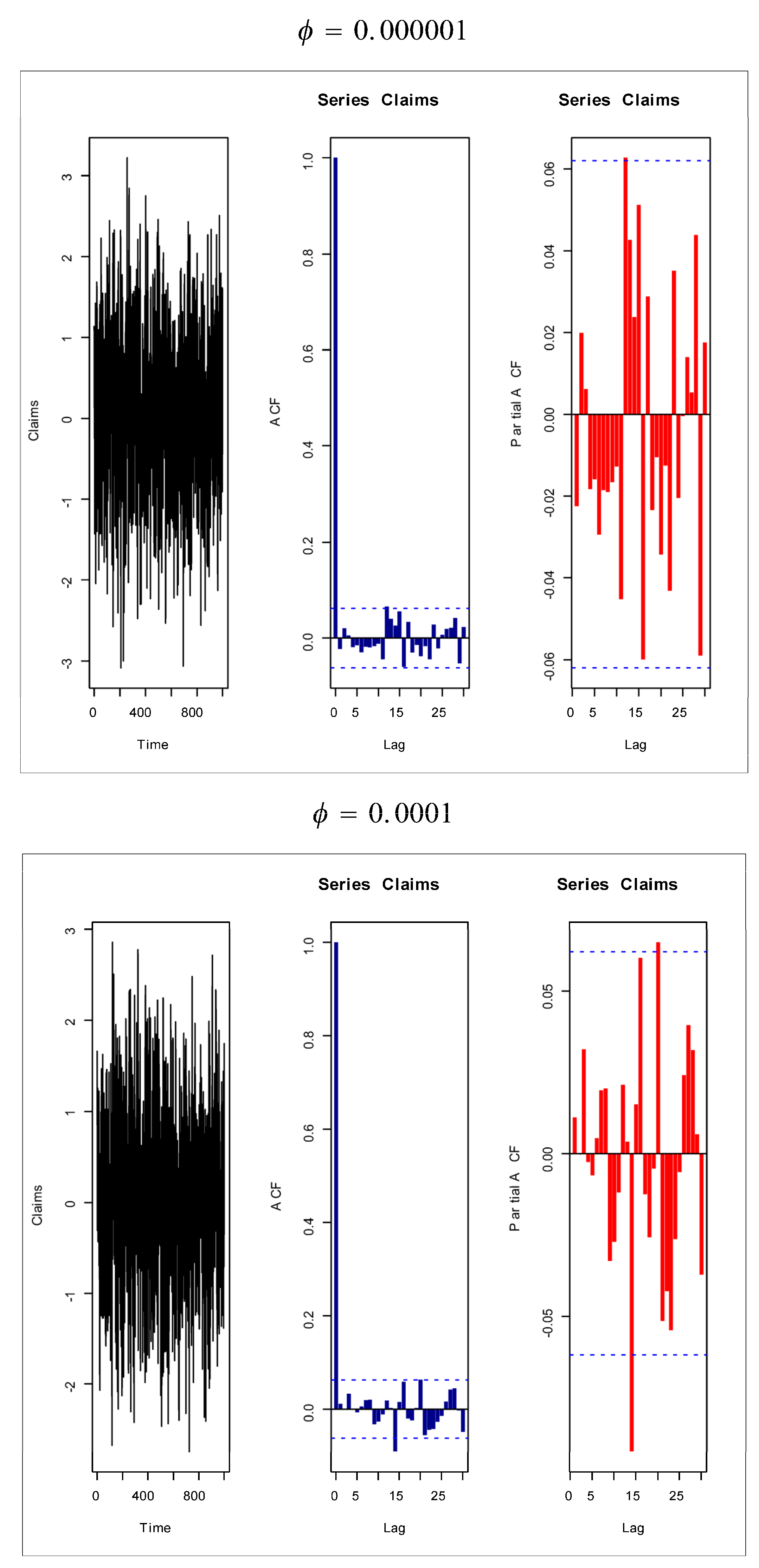
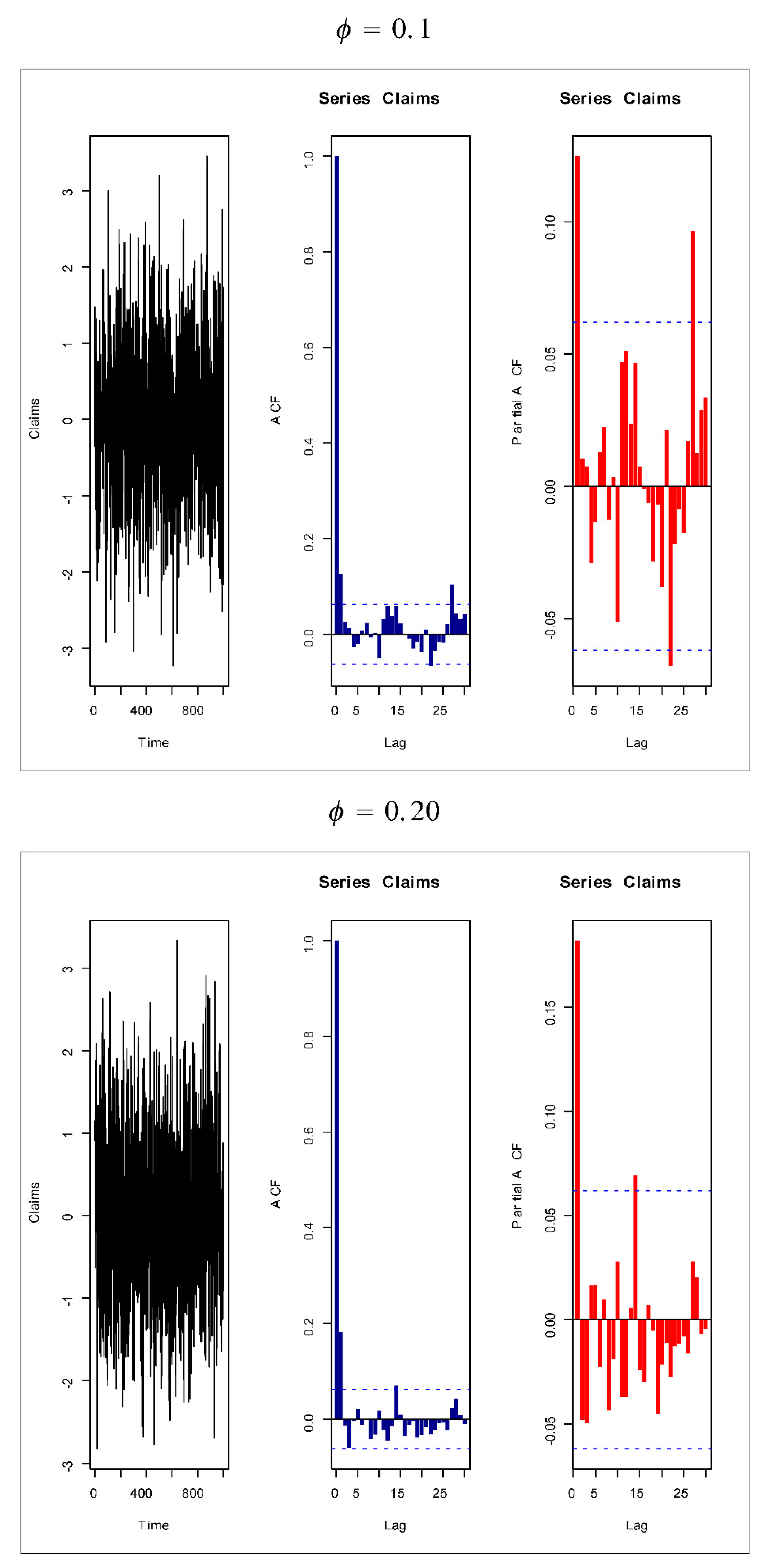
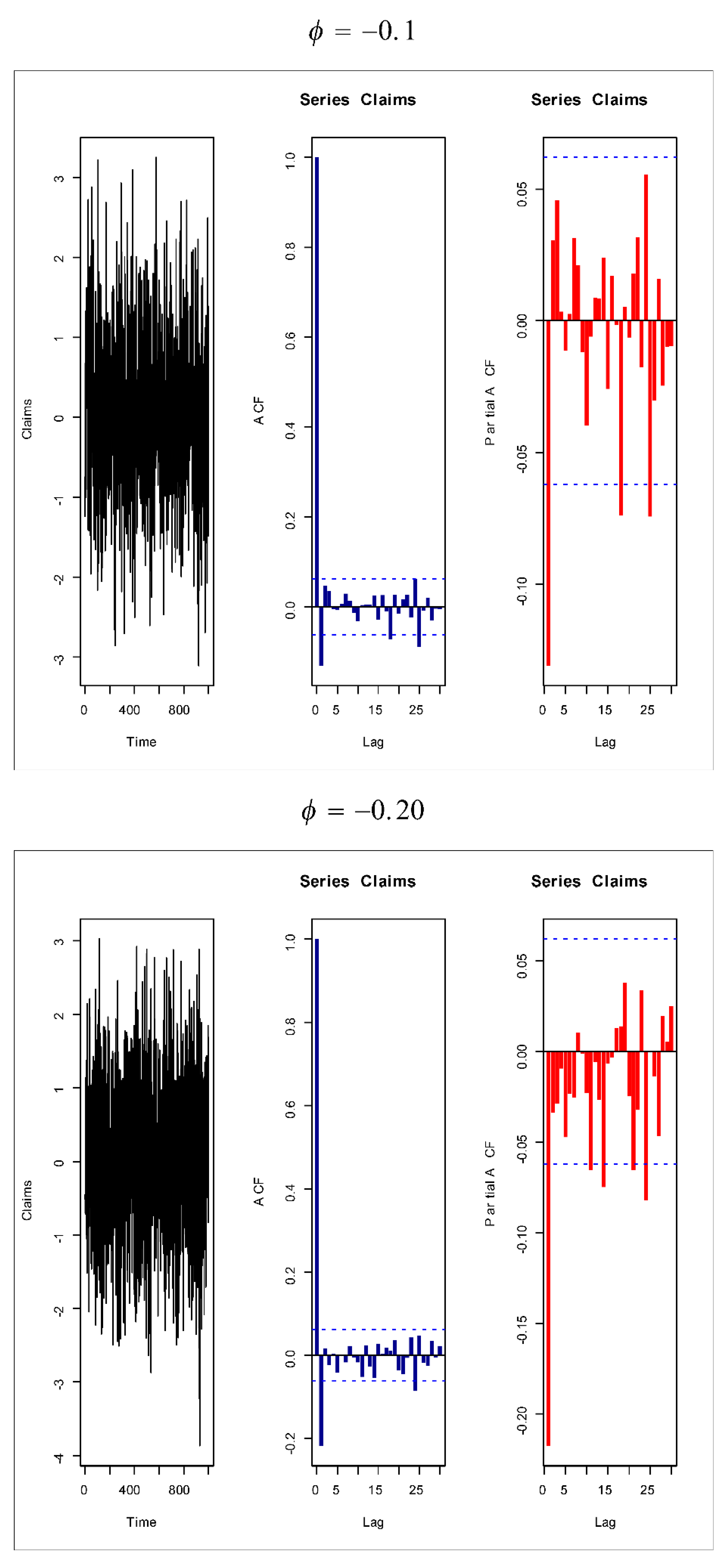
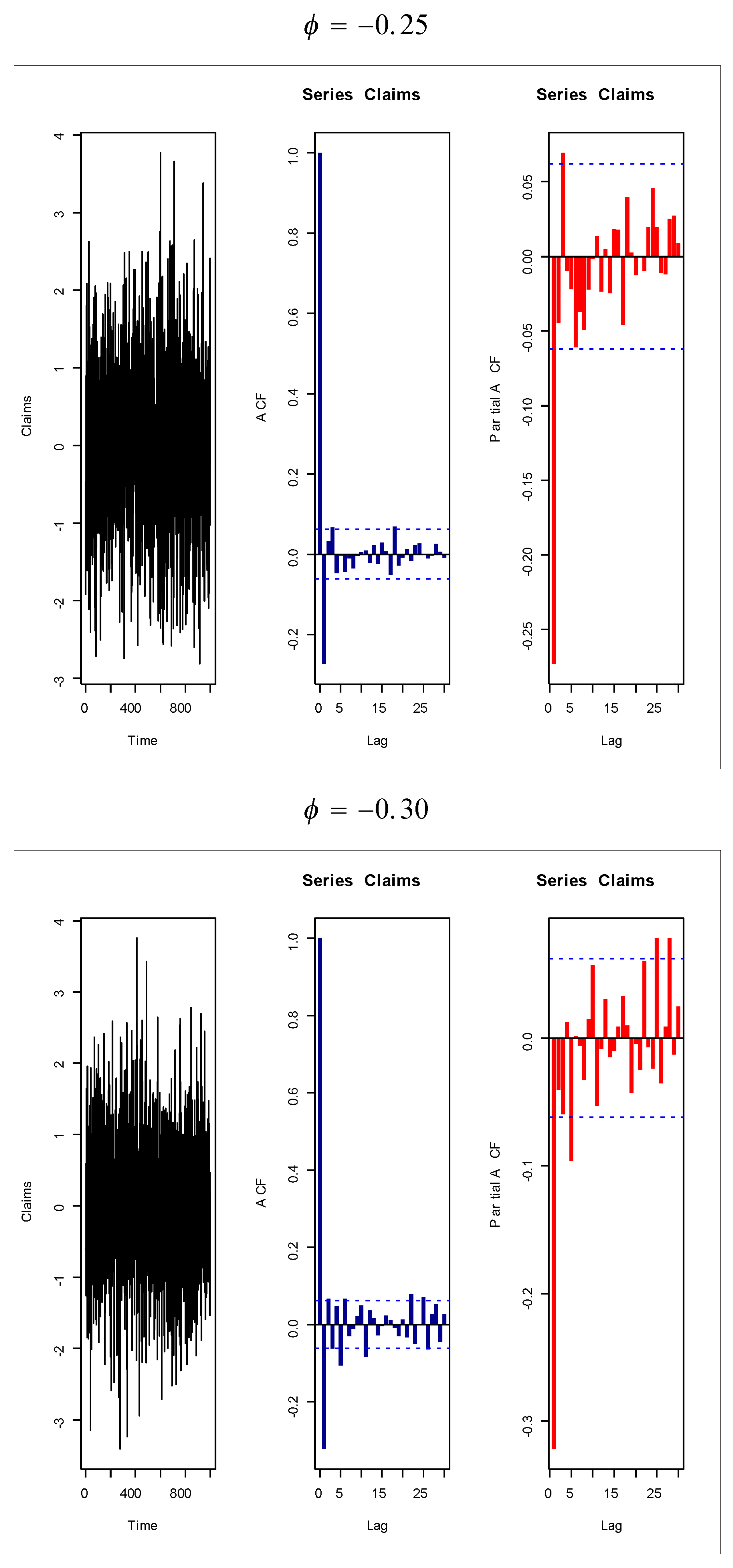
Figure 14,
Figure 15,
Figure 16 and
Figure 17 give some artificial claims payments with ACF (
) and partial ACF (
) generated based on some positive and negative values of the parameter
=
.
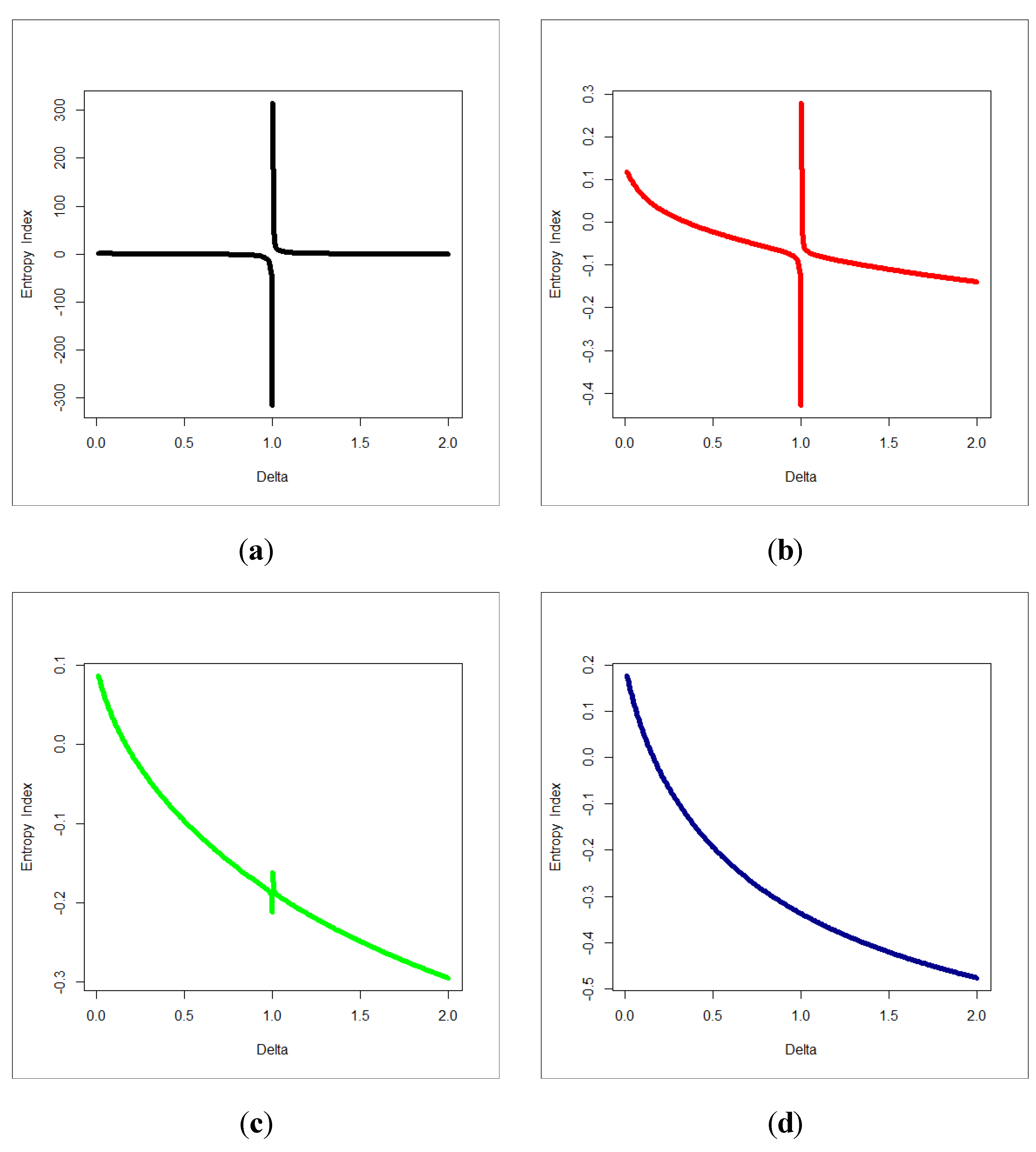
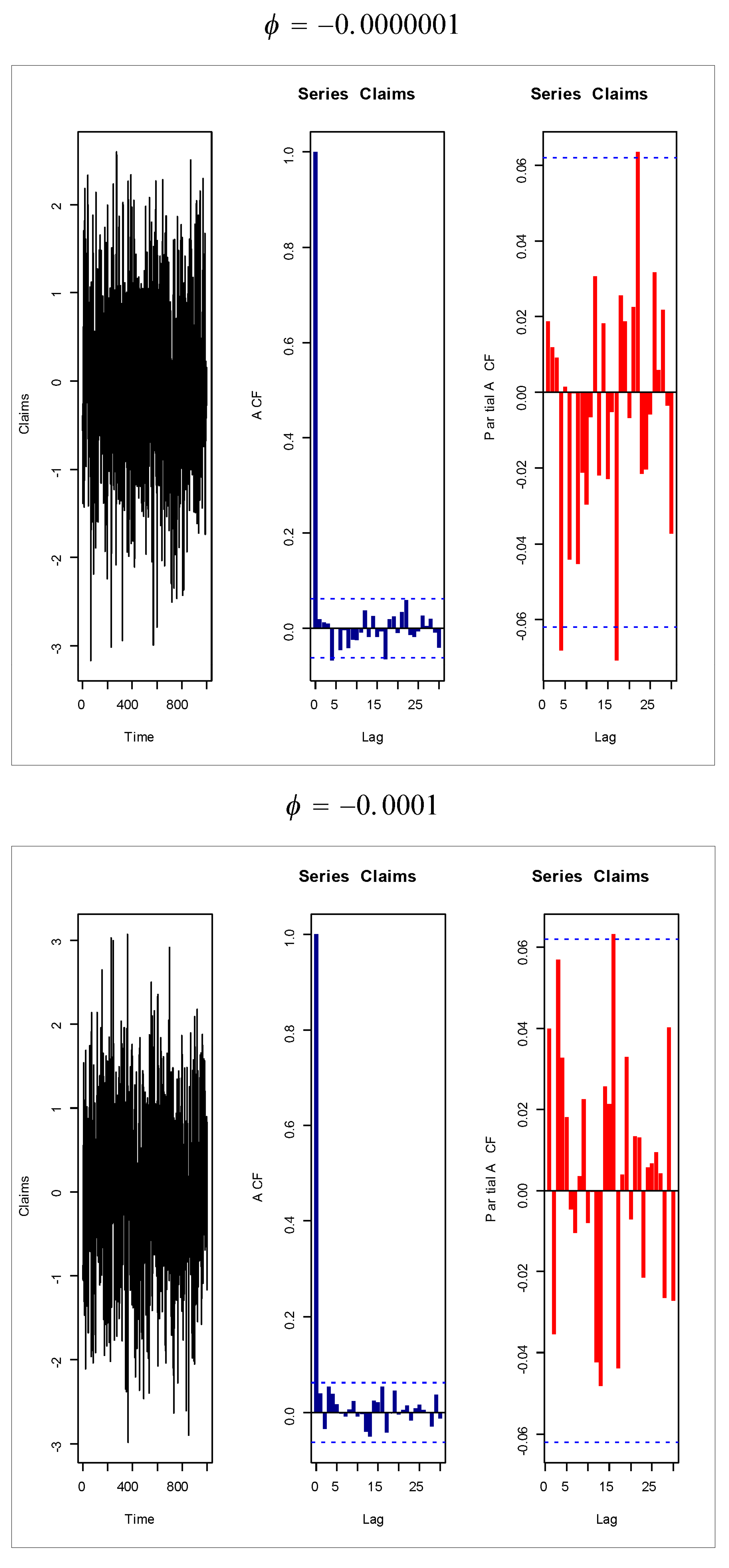
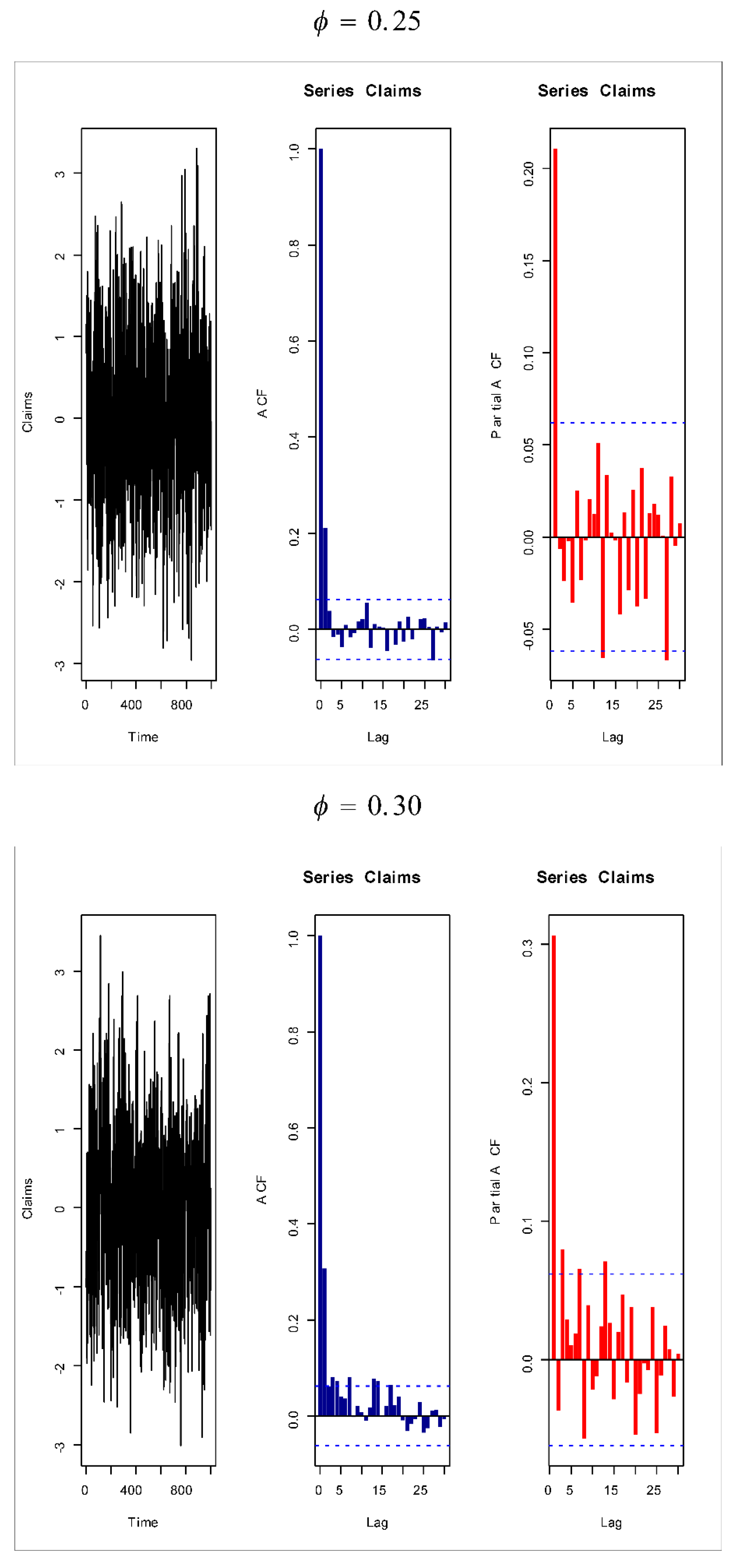
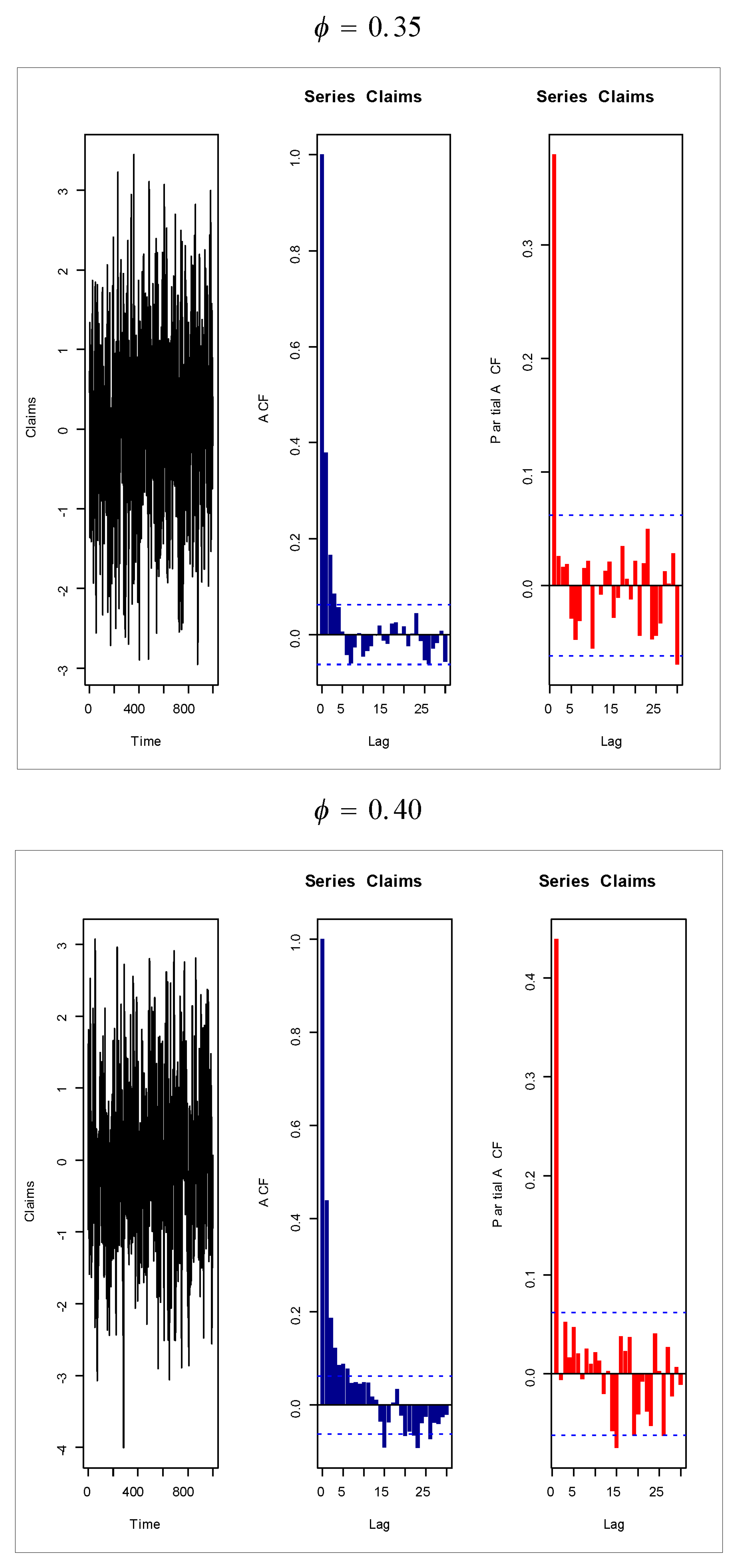
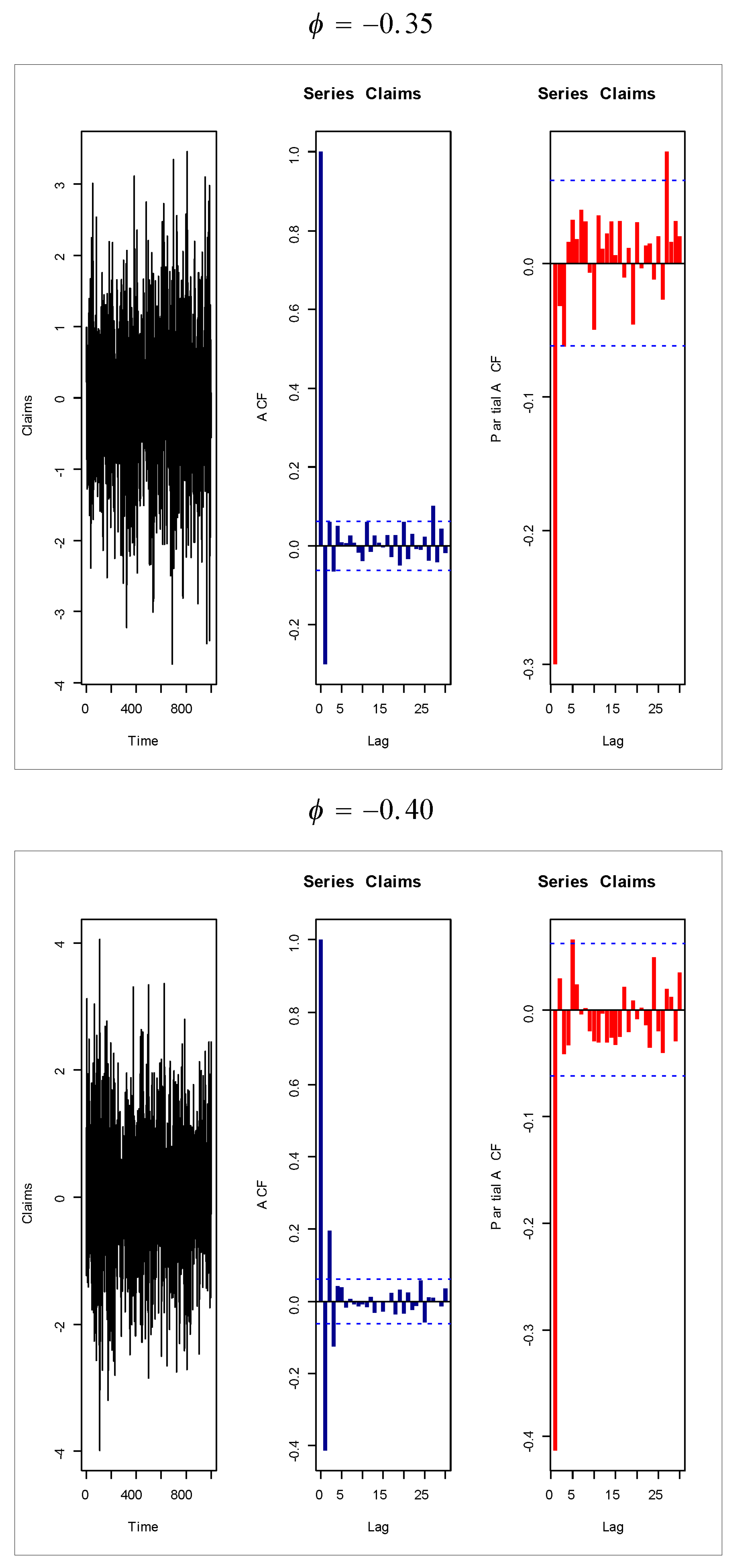
Figure 18,
Figure 19,
Figure 20 and
Figure 21 give some artificial claims payments with ACF (
) and partial ACF (
) generated based on some positive and negative values of the parameter
=
. For a positive value of the parameter
(
) the ACF
exponentially as lag
+
. For negative values of the parameter
(
), the ACF
exponentially as lag
+
. For a positive value of the parameter
, the partial ACF shuts off after the first lag since
. For negative values of the parameter
, the partial ACF shuts off after the first lag since
.
Table 8 provides the point prediction (the future values
and
) for the claims payments in millions. In
Table 8,
and
are also calculated for each value of
.
The future values
and
are very important for the insurance companies for avoiding big losses under uncertainty, which may be produced from future claims.
Table 9 gives the deviations (Ds), sum of deviations (SDs), the mean of deviations (MDs), absolute deviations (ADs), sum of absolute deviations (SADs), mean absolute deviations (MADs), square deviations (SDs), sum of square deviations (SSDs) and mean square deviations (MSDs) for
.
Table 10 gives the Ds, SDs, MDs, ADs, SADs, MADs, SDs, SSDs and MSDs for
.
Table 11 gives the Ds, SDs, MDs, ADs, SADs, MADs, SDs, SSDs and MSDs for
. Based on
Table 9, the AR(1) model is suggested for obtaining future values
with
or
since deviation = absolute deviation = square deviation
. Based on
Table 10, the AR(1) model is suggested for obtaining future values
with
or
since deviation = absolute deviation = square deviation
. Based on
Table 11, the AR(1) model is suggested for obtaining future values
with
or
since deviation = absolute deviation = square deviation
.
Generally, a very small value of the parameter
is preferable for claims forecasting. Based on
Table 9,
Table 10 and
Table 11, it is noted that MDs for
= −3.885781 ×
, MDs for
= 0.064245 and MDs for
= −3.330669 ×
; MADs for
= 0.2119559, MADs for
= 0.064245 and MADs for
= 0.020996; and MSDs for
= 0.0680814, MSDs for
= 0.0076241 and MSDs for
= 0.00097875.
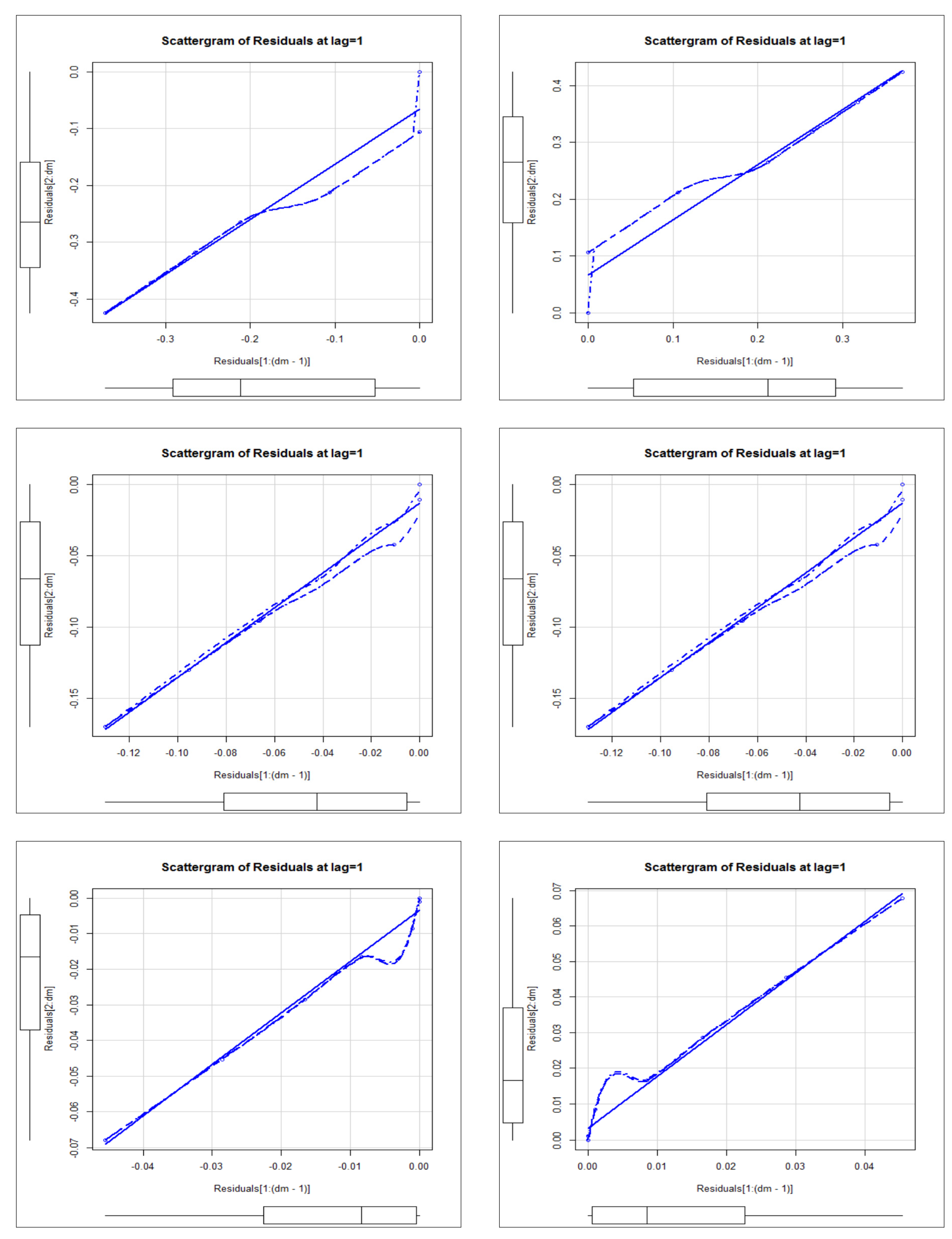
Figure 22 (first row-left panel) gives the scattergrams for the deviations under
for the future value
.
Figure 22 (first row, left panel) gives the scattergrams for the deviations for
for the future value
.
Figure 22 (second row, left panel) gives the scattergrams for the deviations under
for the future value
.
Figure 22 (second row, left panel) gives the scattergrams for the deviations for
for the future value
.
Figure 22 (third row, left panel) gives the scattergrams for the deviations under
for the future value
.
Figure 22 (third row, left panel) gives the scattergrams for the deviations for
for the future value
.
Figure 22 (first row) gives the deviations, absolute deviations and square deviations against
(the future value
(left), the future value
(middle) and the future value
right)).
Figure 16 (second row) gives the deviations, absolute deviations and square deviations against
(the future value
(left), the future value
(middel) and the future value
right)).
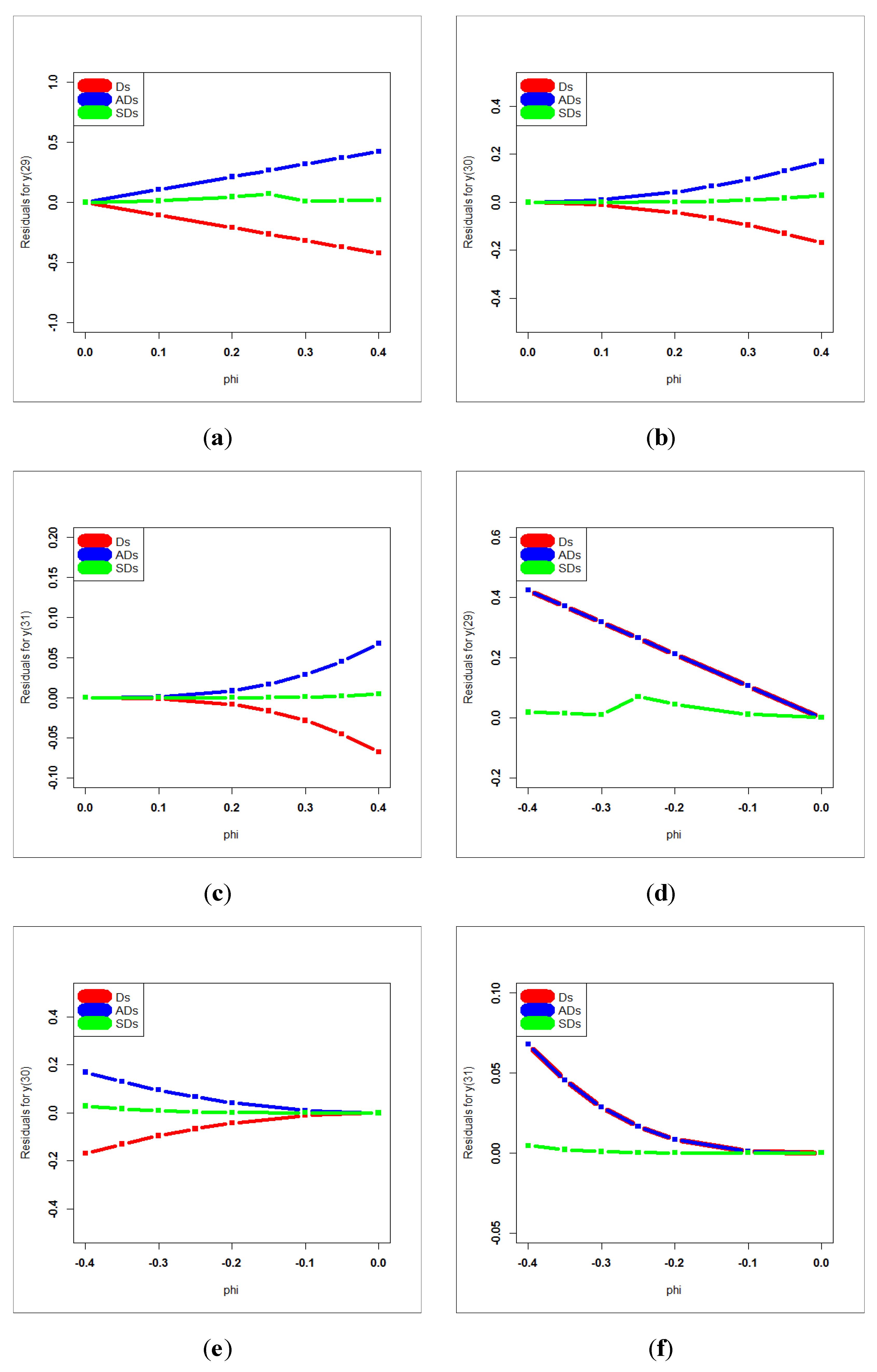
Figure 23 gives the deviations, absolute deviations and square deviations for
(((a),(b),(c))) and
((d),(e),(f)).
7.2. An Application for Risk Analysis under the Insurance-Claims Payment Data
In this subsection, we present an application for risk analysis under the VaR, TVaR, TV and TMV measures presented in (13), (15), (16) and (17) using the insurance-claims payment data. The risk analysis is performed using some confidence levels (). The four measures are estimates for the EWC and the MOGC models.
The MOGC model is considered the best competitive model.
Table 8 below gives the RIs for the EWC the MOGC models. For the EWC model, the VaR
for EWC ranges from 9.003261 to 11.999004, the TVaR
for EWC ranges from 11.999302 to 14.00635, the TV
for EWC ranges from 2.008071 to 2.9989921 and the TMV
for EWC ranges from 12.190242 to 16.450089. The VaR
for MOGC ranges from 6.004395 to 9.642490, the TVaR
for MOGC ranges from 6.721463 to 9.909357, the TV
for MOGC ranges from 1.011332 to 2.102319 and the TMV
MOGC ranges from 6.961463 to 12.909357. The following conclusion can be summarized:
VaR for EWC > VaR for MOGC and TVaR for EWC > TVaR for MOGC.
TV for EWC > TV for MOGC and TMV for EWC > TMV for MOGC.
VaR(X) < TVaR(X) < TMV(X) .




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}