
A Review of Interpretable ML in Healthcare: Taxonomy, Applications, Challenges, and Future Directions



Abstract
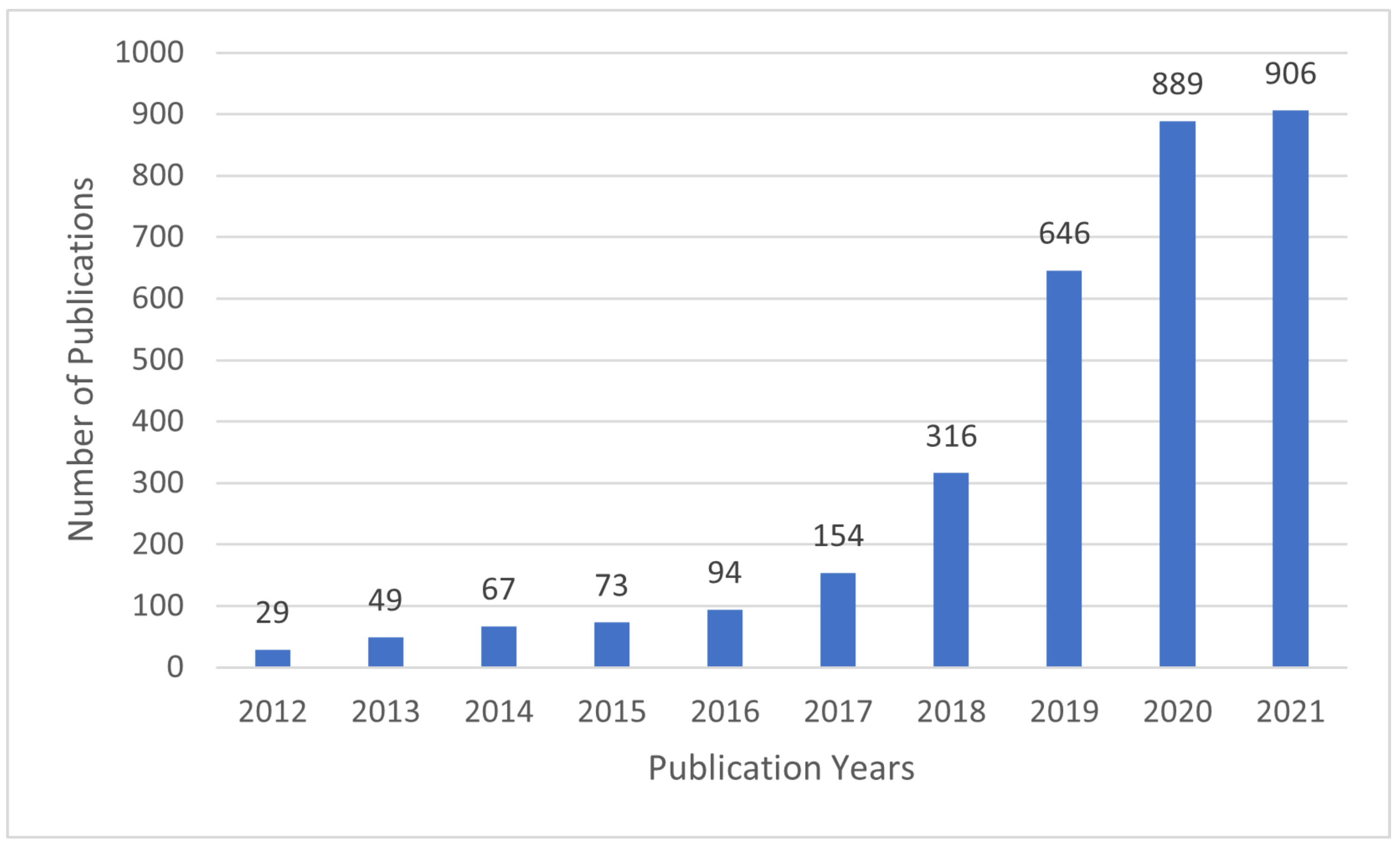
:1. Introduction
- An overview on the field of interpretable machine learning, its proprieties, and outcomes, providing the reader the knowledge needed to understand the field.
- The taxonomy of IML is proposed to provide a structured overview that can serve as reference material to stimulate future research.
- Details of the existing IML models and methods applied in healthcare are provided.
- The main challenges that impact application of IML models in healthcare and sensitive domains are identified.
- The key points of IML and its application in healthcare, the field’s future direction, and potential trends are discussed.
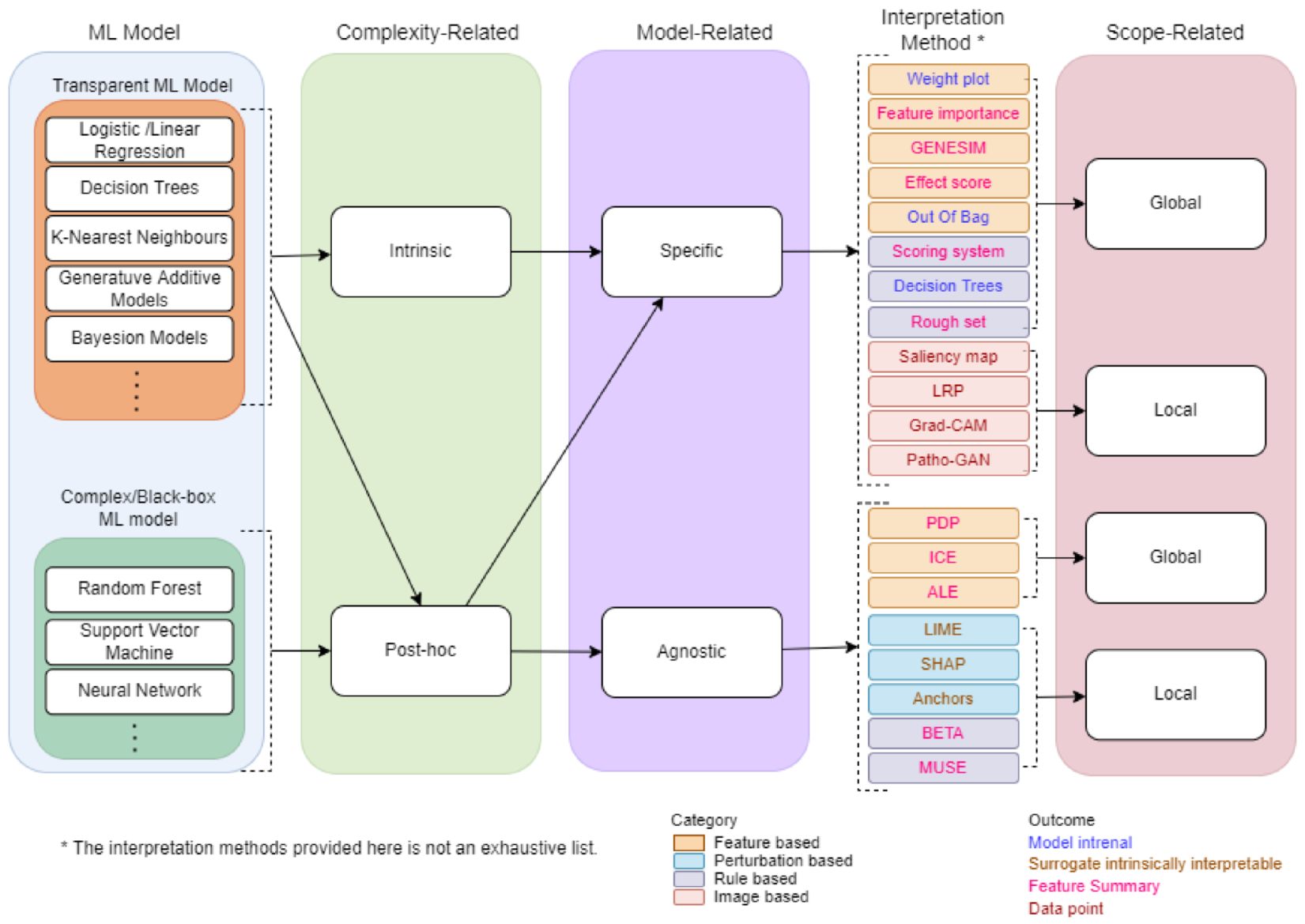
2. Taxonomy of IML
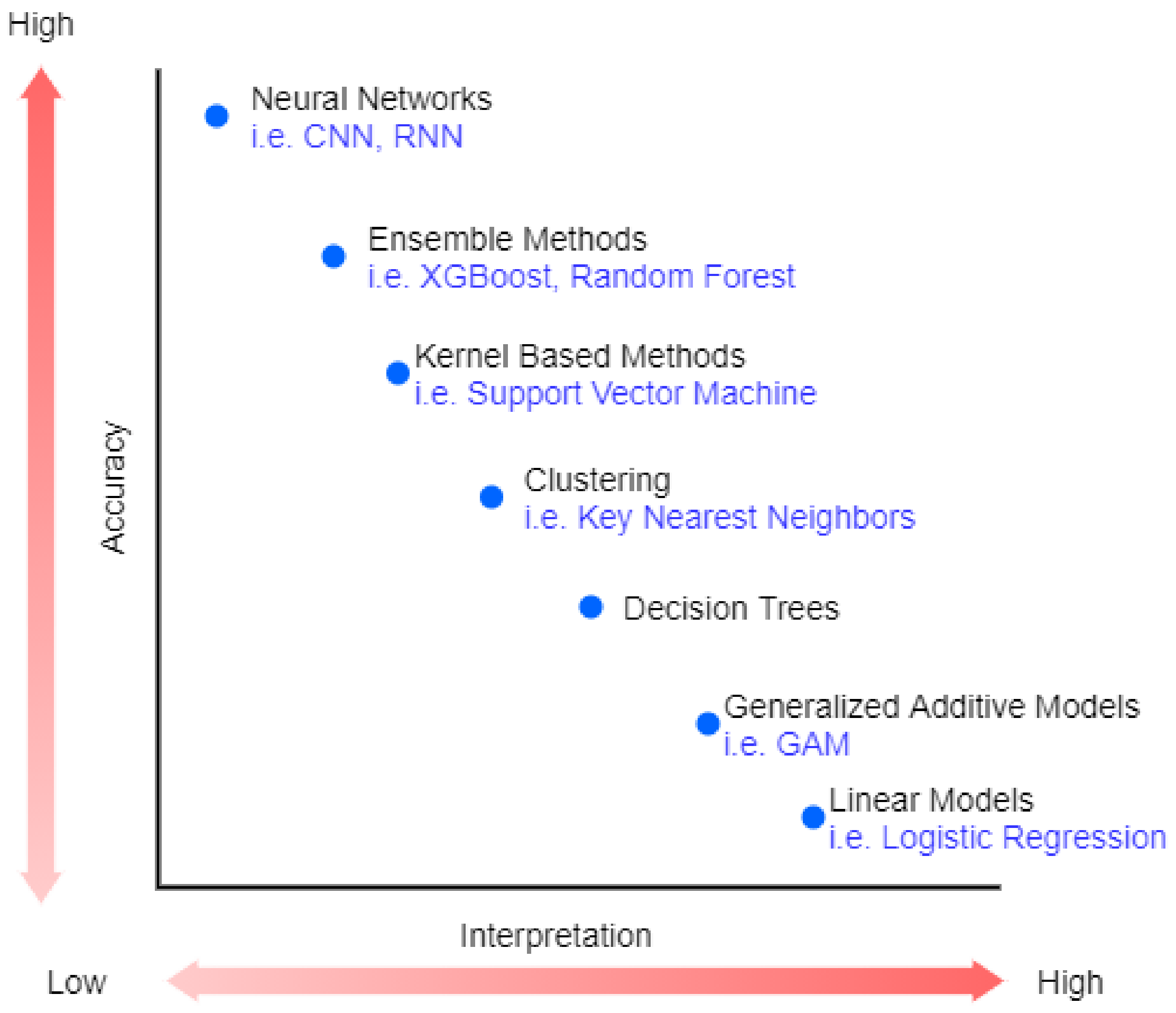
2.1. Complexity-Related
2.2. Model-Related
2.3. Scope-Related
2.4. Summary on Interpretable Machine Learning Taxonomy
3. Interpretability in Machine Learning
3.1. Overview
3.2. Properties of Interpretation Methods
3.2.1. Fidelity
3.2.2. Comprehensibility
3.2.3. Generalizability
3.2.4. Robustness
3.2.5. Certainty
3.3. Outcomes of IML
- Feature summary: Explaining ML model outcome by providing a summary (statistic or visualization) for each feature extracted from ML model.
- -
- Feature summary statistics: ML model outcomes describing statistic summary for each feature. The statistic summary contains a single number for each feature, such as feature importance, or a single number for each couple of features, such as pairwise feature interaction strengths.
- -
- Feature summary visualization: Visualizing the feature summary is one of the most popular methods. It provides a visualization in form of graphs representing the impact of the feature to the ML model prediction.
- Model internals: The model outcomes are presented in model intrinsic form such as the learned tree structure of decision trees and the weights of linear models.
- Data point: Data point results explain a sample’s prediction by locating a comparable sample and modifying some of the attributes for which the expected outcome changes in a meaningful way, i.e., counterfactual explanations. Interpretation techniques that generate new data points must be validated by interpreting the data points themselves. This is great for images and text, but not so much for tabular data with a lot of features.
- Surrogate intrinsically interpretable model: Surrogate models are another way to interpret the ML model by approximating them with the intrinsically interpretable model and then providing the internal model parameters or feature summary.
4. Interpretation Methods of IML
4.1. Feature Based
- Feature importance
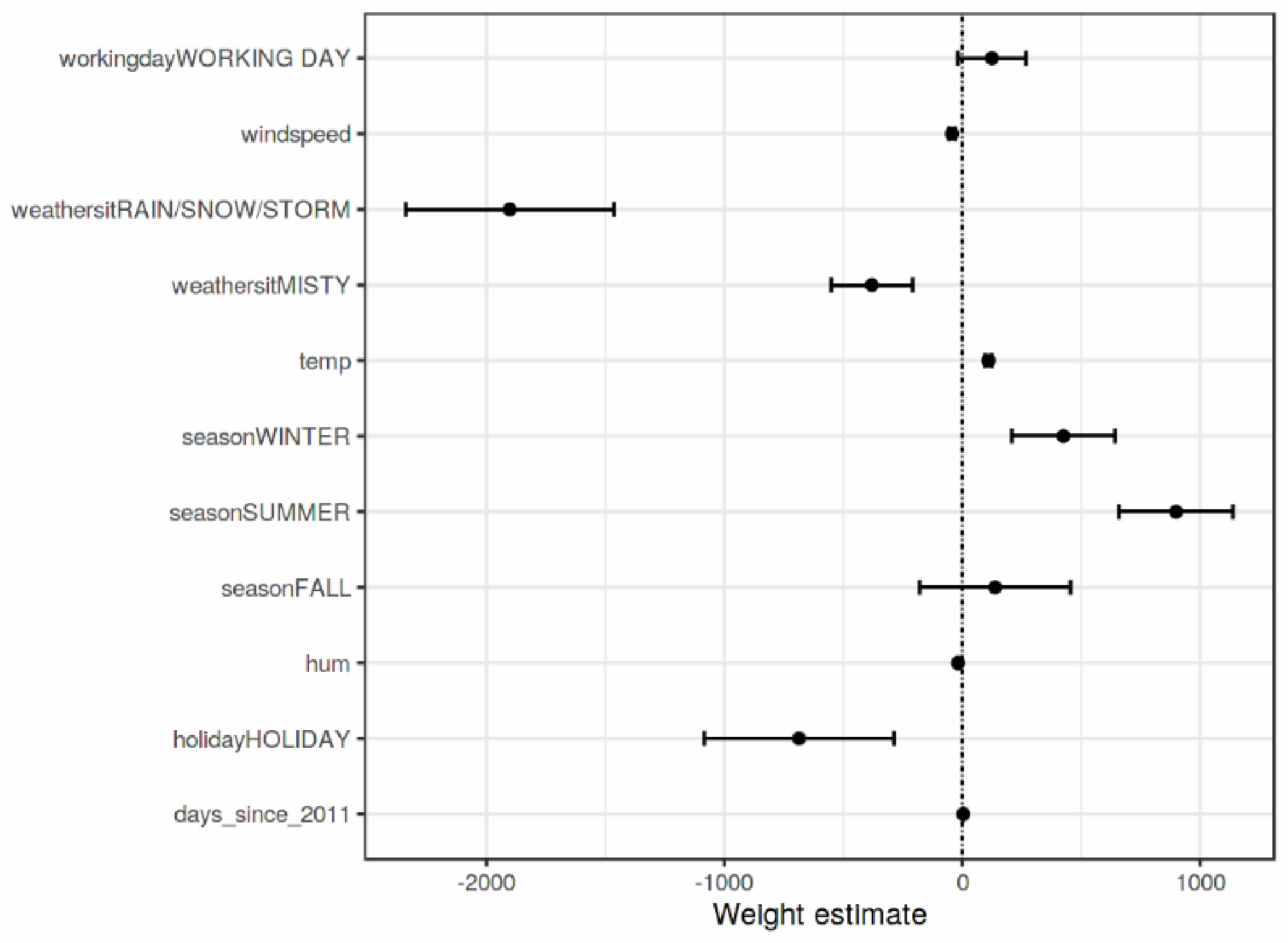
- Weight Plot
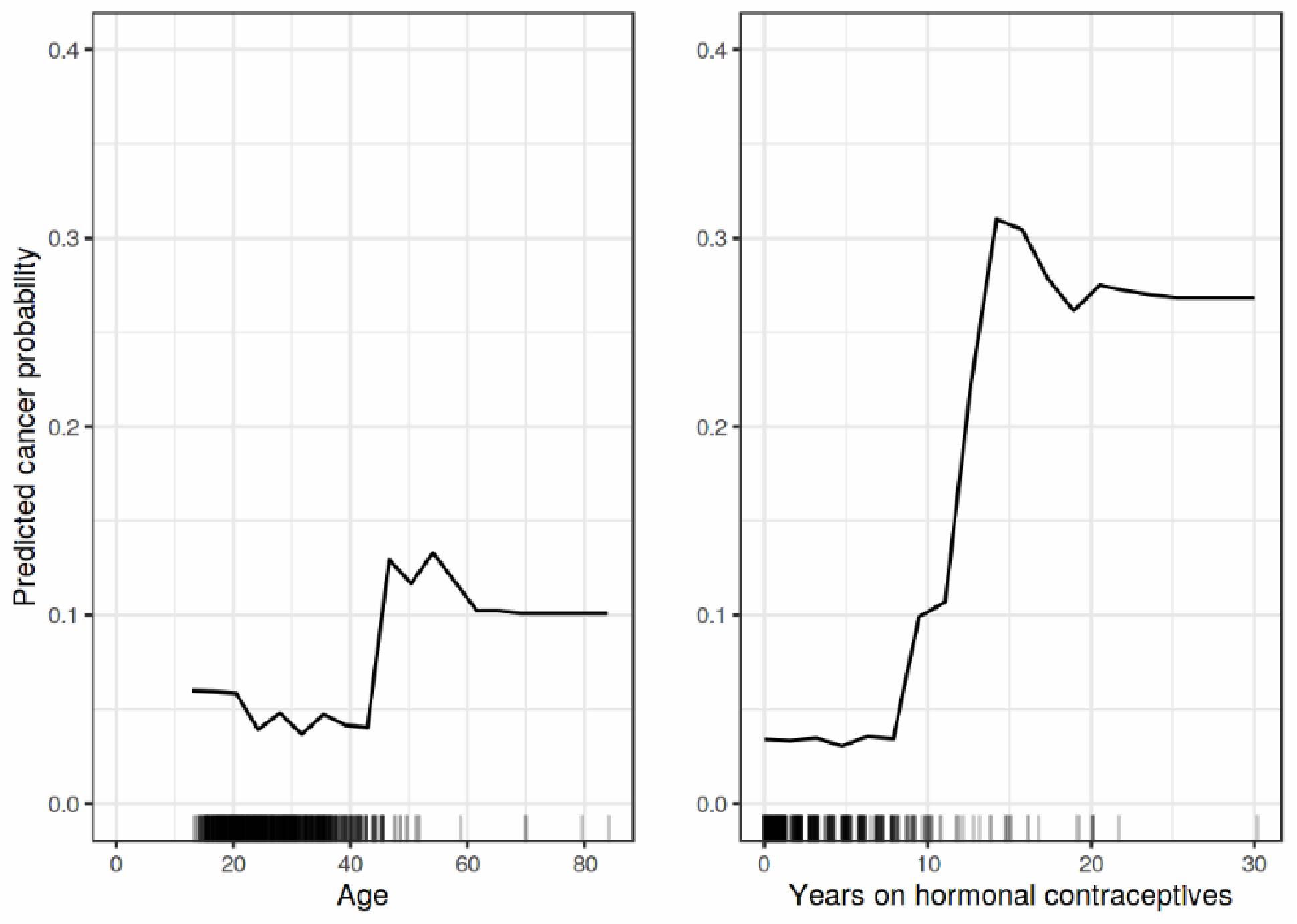
- PDP
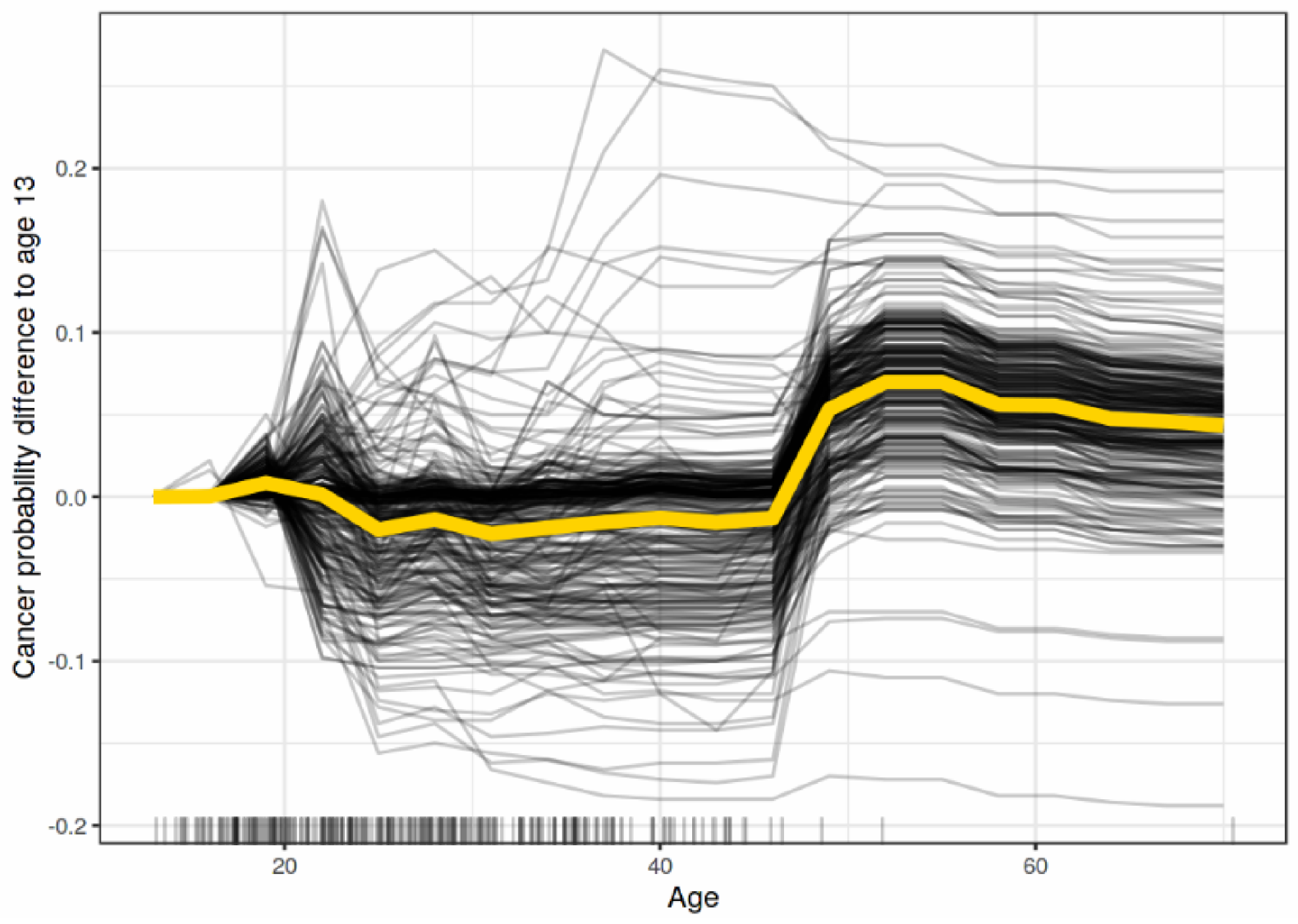
- ICE
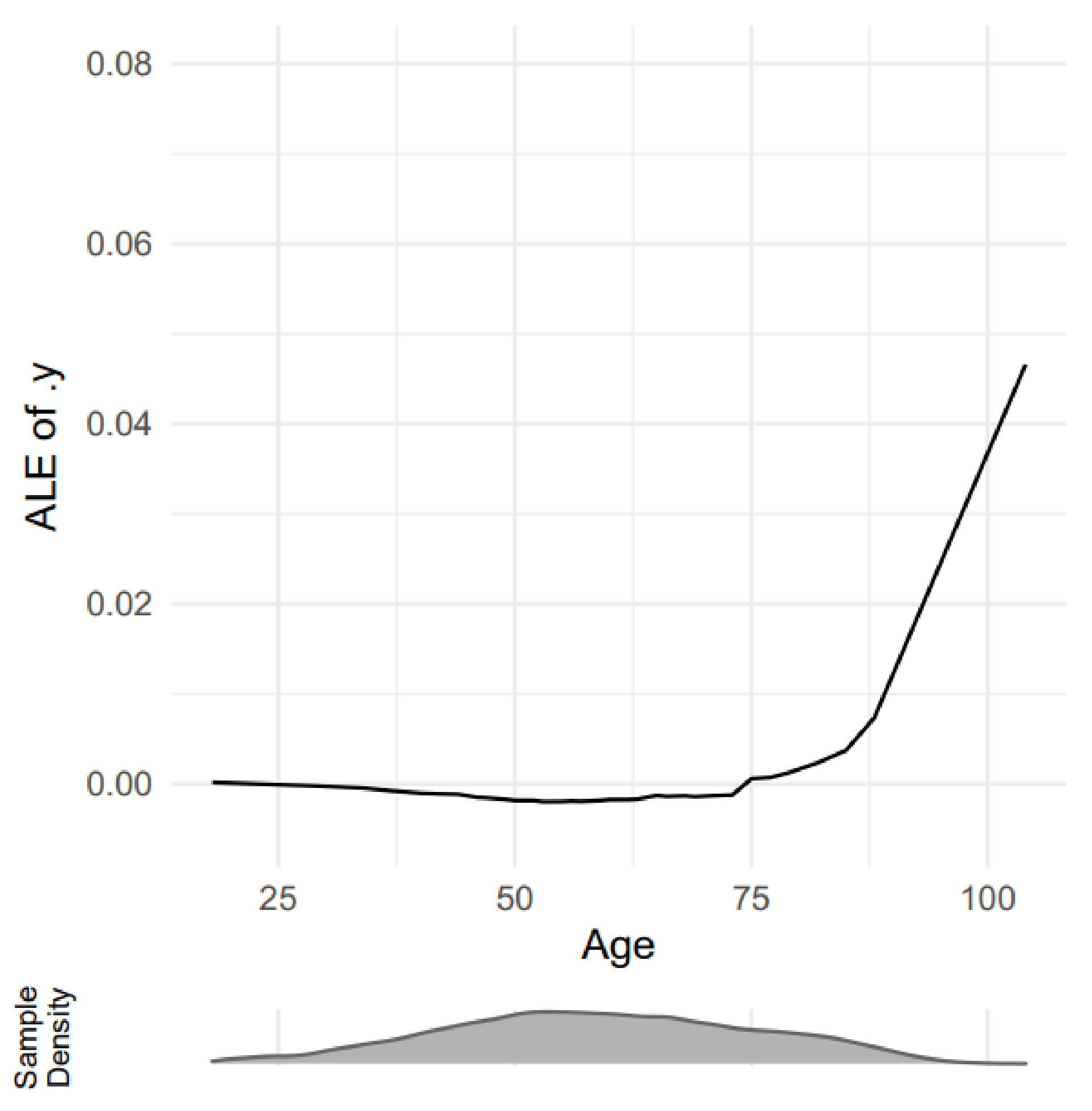
- ALE
- Effect score
- GENESIM
- Out Of Bag
4.2. Perturbation Based
- LIME
- For a certain data point, LIME disturbs its characteristics repeatedly at random. For tabular data, this means adding to each function a small amount of noise.
- Get predictions for each disturbing instance of results. This allows us to establish a local image of the decision area at that point.
- The linear model’s coefficients are used as explanations to calculate an estimated linear explanation model using predictions.
- SHAP
- Anchors
4.3. Rule Based
- Scoring System
- MUSE
- BETA
- Rough Set Theory
- Decision Trees
4.4. Image Based
- Saliency map
- LRP
- Grad-CAM
- Patho-GAN
5. Applications of IML in Healthcare
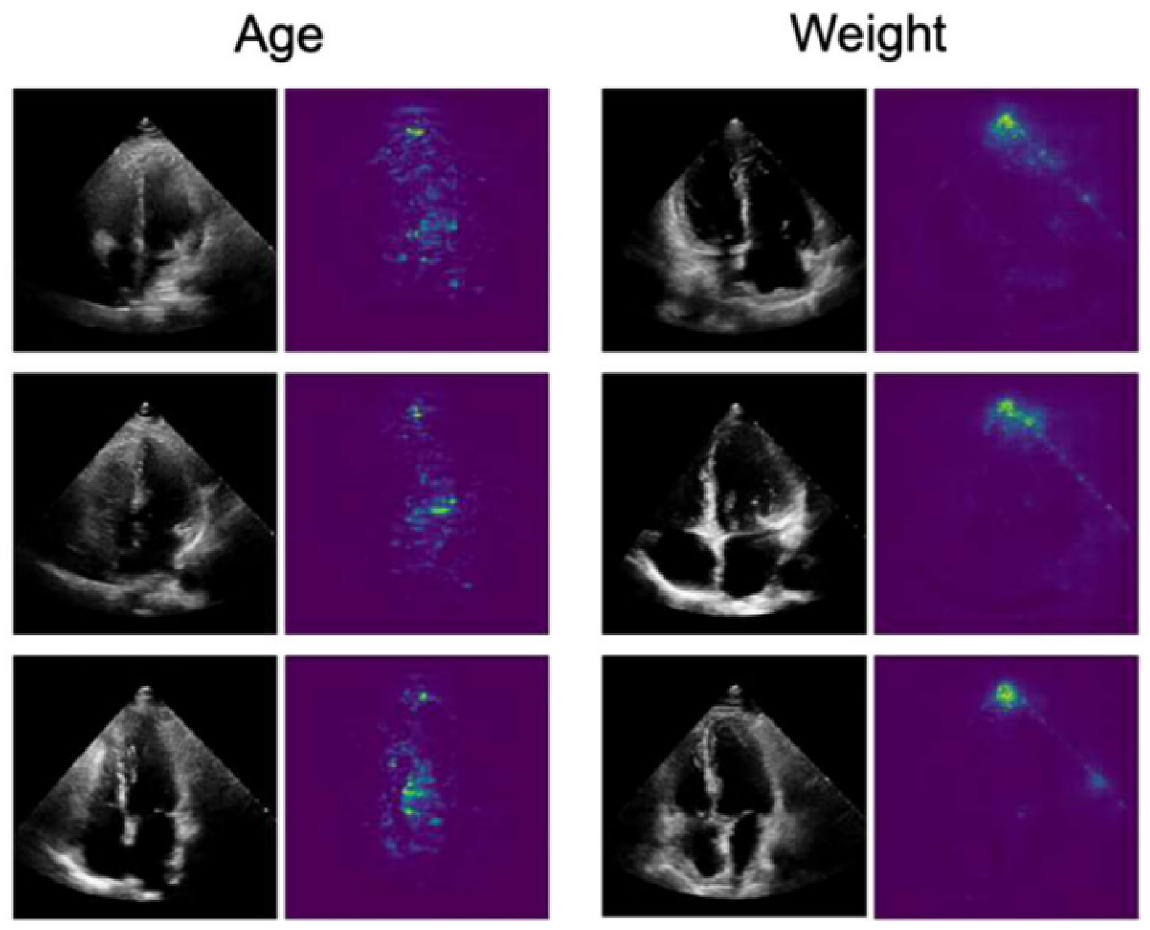
5.1. Cardiovascular Diseases
5.2. Eye Diseases
5.3. Cancer
5.4. Influenza and Infection Diseases
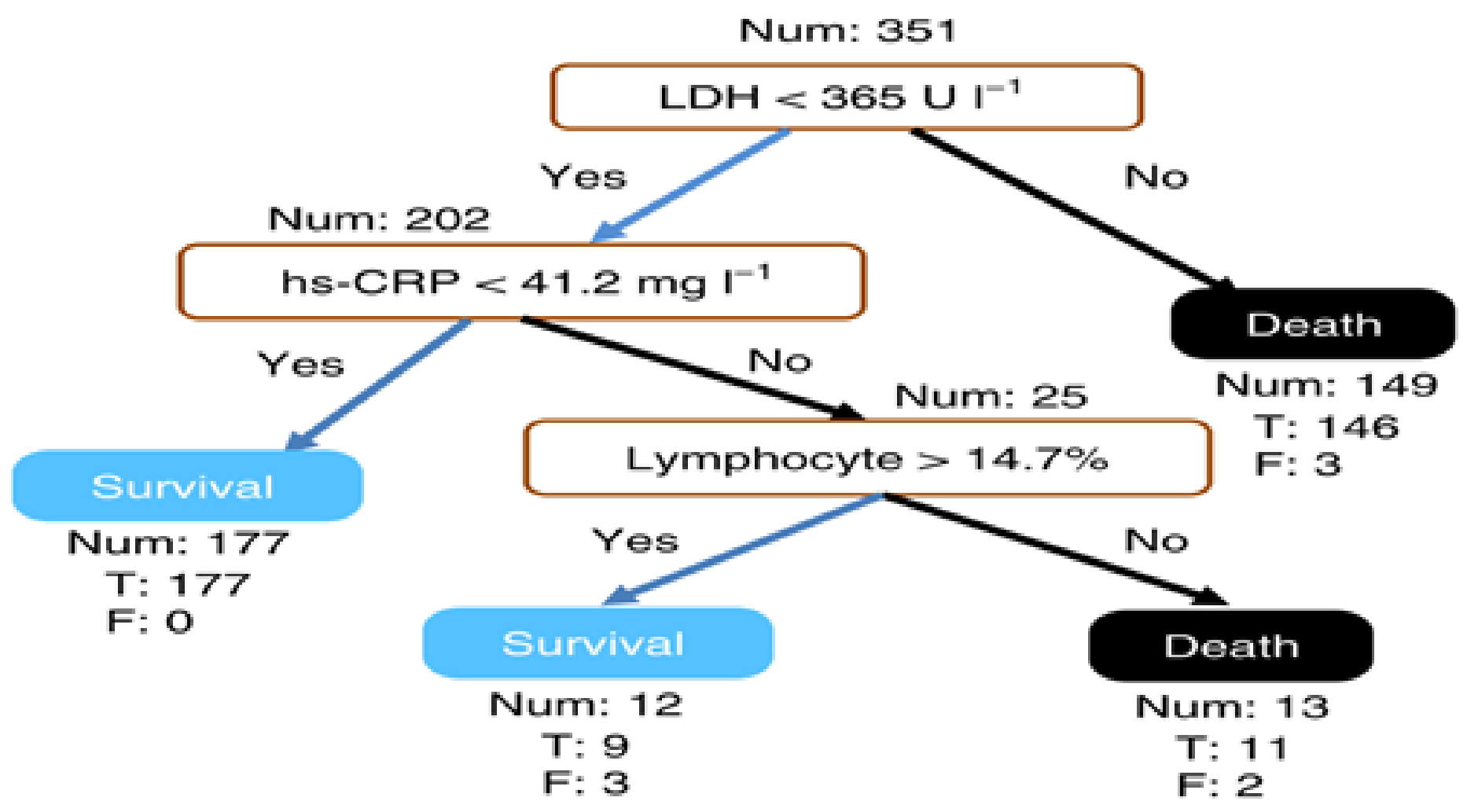
5.5. COVID-19
5.6. Depression Diagnosis
5.7. Autism
6. Challenges of IML
6.1. Challenges in the Development of IML Model
- Causal Interpretation
- Feature Dependence
6.2. Challenges of IML Interpretation Properties
- Uncertainty and Inference
- Robustness and Fidelity
6.3. Challenges of Interpretation Methods
- Feature-Based Methods
- Perturbation-Based Methods
- Rule-Based Methods
- Image-Based Methods
7. Discussion and Future Direction
- Interpretability is Important in Critical Applications
- Interpretability Cannot be Mathematically Measured.
- Different People Need Different Explanations
- Human Understanding is Limited
- Visual Interpretability is Promising
- Model Agnostic Interpretation is Trending
- Local Explanations are More Accurate
8. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| [H] ML | Machine Learning |
| IML | Interpretable Machine Learning |
| DL | Deep Learning |
| GDPR | General Data Protection Regulation |
| EHR | Electronic Health Record |
| CVD | Cardiovascular Diseases |
| ANN | Neural Network |
| CNN | Convolutional Neural Network |
| 1D CNN | One Dimensional Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| XGBoost | eXtreme Gradient Boosting |
| Adaboost | Adaptive Boosting |
| GBoost | Gradient Boosted trees |
| RF | Random Forest |
| SVM | Support Vector Machine |
| KNN | Key Nearest Neighbors |
| DT | Decision Trees |
| GAM | Generalized Additive Model |
| LR | Logistic Regression |
| PDP | Partial Dependence Plot |
| ICE | Individual Conditional Expectation |
| ALE | Accumulated Local Effects plot |
| OOB | Out-Of-Bag |
| LIME | Local Interpretable Model-agnostic Explanation |
| SHAP | Shapley Additive exPlanation |
| LDH | Lactic DeHydrogenas |
| hs-CRP | High-Sensitivity C-Reactive Protein |
| EHR | Electronic Health Record |
| BETA | Black Box Explanations through Transparent Approximations |
| MUSE | Model Understanding through Subspace Explanations, |
| SLSE | SuperLearner Stacked Ensembling |
| SLIM | Supersparse Linear Integer Model |
| GENESIM | Genetic Extraction of a Single Interpretable Model |
| ALIME | Autoencoder Based Approach for Local Interpretability |
| OptiLIME | Optimized LIME |
| AUC | Area Under Curve |
| AC | Accuracy |
| F1 | F1-score |
| MSE | Mean Square Error |
| LRP | Layer wise Relevance Propagation |
| DNN | Deep Neural Networks |
| CXR | Chest Radiography Images |
| Grad-CAM | Gradient-weighted Class Activation Mapping |
| DTs | Decision Trees |
| MI | Model internal |
| FS | Feature Summary |
| SI | Surrogate intrinsically interpretable |
| N/A | Not Available |
References
- Chan, W.; Park, D.; Lee, C.; Zhang, Y.; Le, Q.; Norouzi, M. SpeechStew: Simply mix all available speech recognition data to train one large neural network. arXiv 2021, arXiv:2104.02133. [Google Scholar]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Comparison of full-reference image quality models for optimization of image processing systems. Int. J. Comput. Vis. 2021, 129, 1258–1281. [Google Scholar] [CrossRef] [PubMed]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- London, A.J. Artificial intelligence and black-box medical decisions: Accuracy versus explainability. Hastings Cent. Rep. 2019, 49, 15–21. [Google Scholar] [CrossRef]
- Scott, I.; Cook, D.; Coiera, E. Evidence-based medicine and machine learning: A partnership with a common purpose. BMJ Evid. Based Med. 2020, 2020 26, 290–294. [Google Scholar] [CrossRef]
- Amann, J.; Blasimme, A.; Vayena, E.; Frey, D.; Madai, V.I. Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Med. Inform. Decis. Mak. 2020, 20, 310. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. 2020. Lulu.com. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 2 November 2021).
- Ahmad, M.A.; Eckert, C.; Teredesai, A. Interpretable machine learning in healthcare. In Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics, Washington, DC, USA, 29 August–1 September 2018; pp. 559–560. [Google Scholar]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning-based prediction models in healthcare. Wiley Interdiscip.-Rev.-Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef] [Green Version]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Interpretable machine learning: Definitions, methods, and applications. arXiv 2019, arXiv:1901.04592. [Google Scholar] [CrossRef] [Green Version]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Das, S.; Agarwal, N.; Venugopal, D.; Sheldon, F.T.; Shiva, S. Taxonomy and Survey of Interpretable Machine Learning Method. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020; pp. 670–677. [Google Scholar]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef]
- Payrovnaziri, S.N.; Chen, Z.; Rengifo-Moreno, P.; Miller, T.; Bian, J.; Chen, J.H.; Liu, X.; He, Z. Explainable artificial intelligence models using real-world electronic health record data: A systematic scoping review. J. Am. Med. Inform. Assoc. 2020, 27, 1173–1185. [Google Scholar] [CrossRef]
- Singh, A.; Sengupta, S.; Lakshminarayanan, V. Explainable deep learning models in medical image analysis. J. Imaging 2020, 6, 52. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Belle, V.; Papantonis, I. Principles and practice of explainable machine learning. arXiv 2020, arXiv:2009.11698. [Google Scholar] [CrossRef]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Interpretable & explorable approximations of black box models. arXiv 2017, arXiv:1707.01154. [Google Scholar]
- Salman, S.; Payrovnaziri, S.N.; Liu, X.; Rengifo-Moreno, P.; He, Z. DeepConsensus: Consensus-based Interpretable Deep Neural Networks with Application to Mortality Prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. ACM 2019, 63, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Lipton, Z.C. The Mythos of Model Interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Jiang, P.; Zhou, Q.; Shao, X. Surrogate Model-Based Engineering Design and Optimization; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Clinciu, M.A.; Hastie, H. A survey of explainable AI terminology. In Proceedings of the 1st Workshop on Interactive Natural Language Technology for Explainable Artificial Intelligence (NL4XAI 2019), Tokyo, Japan, 29 October 2019; pp. 8–13. [Google Scholar]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215. [Google Scholar]
- Gaur, M.; Faldu, K.; Sheth, A. Semantics of the Black-Box: Can knowledge graphs help make deep learning systems more interpretable and explainable? IEEE Internet Comput. 2021, 25, 51–59. [Google Scholar] [CrossRef]
- Rudin, C.; Ertekin, Ş. Learning customized and optimized lists of rules with mathematical programming. Math. Program. Comput. 2018, 10, 659–702. [Google Scholar] [CrossRef]
- Molnar, C.; Casalicchio, G.; Bischl, B. Interpretable Machine Learning—A Brief History, State-of-the-Art and Challenges. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Biran, O.; Cotton, C. Explanation and justification in machine learning: A survey. In Proceedings of the IJCAI-17 Workshop on Explainable AI (XAI), Melbourne, Australia, 20 August 2017; Volume 8, pp. 8–13. [Google Scholar]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. A roadmap for a rigorous science of interpretability. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Yang, F.; Du, M.; Hu, X. Evaluating explanation without ground truth in interpretable machine learning. arXiv 2019, arXiv:1907.06831. [Google Scholar]
- Ras, G.; van Gerven, M.; Haselager, P. Explanation methods in deep learning: Users, values, concerns and challenges. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018; pp. 19–36. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Considerations for evaluation and generalization in interpretable machine learning. In Explainable and Interpretable Models in Computer Vision and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–17. [Google Scholar]
- Yan, L.; Zhang, H.T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Yeh, C.K.; Hsieh, C.Y.; Suggala, A.S.; Inouye, D.I.; Ravikumar, P. How Sensitive are Sensitivity-Based Explanations? arXiv 2019, arXiv:1901.09392. [Google Scholar]
- Phillips, R.; Chang, K.H.; Friedler, S.A. Interpretable active learning. In Proceedings of the Conference on Fairness, Accountability and Transparency, New York, NY, USA, 23–24 February 2018; pp. 49–61. [Google Scholar]
- Ustun, B.; Spangher, A.; Liu, Y. Actionable recourse in linear classification. In Proceedings of the Conference on Fairness, Accountability, and Transparency, Atlanta, GA, USA, 29–31 January 2019; pp. 10–19. [Google Scholar]
- Lipton, Z.C. The Mythos of Model Interpretability. Commun. ACM 2018, 61, 36–43. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Casalicchio, G.; Molnar, C.; Bischl, B. Visualizing the feature importance for black box models. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 655–670. [Google Scholar]
- Apley, D.W.; Zhu, J.Y. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser.-Stat. Methodol. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Kennedy, C.J.; Mark, D.G.; Huang, J.; van der Laan, M.J.; Hubbard, A.E.; Reed, M.E. Development of an ensemble machine learning prognostic model to predict 60-day risk of major adverse cardiac events in adults with chest pain. medRxiv. 2021. Available online: https://www.medrxiv.org/content/10.1101/2021.03.08.21252615v2 (accessed on 8 March 2021).
- Miran, S.M.; Nelson, S.J.; Zeng-Treitler, Q. A model-agnostic approach for understanding heart failure risk factors. BMC Res. Notes 2021, 14, 184. [Google Scholar] [CrossRef]
- Vandewiele, G.; Janssens, O.; Ongenae, F.; De Turck, F.; Van Hoecke, S. Genesim: Genetic extraction of a single, interpretable model. arXiv 2016, arXiv:1611.05722. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you? ” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Dibia, V. ML Interpretability: LIME and SHAP in Prose and Code. Website. 2020. Available online: https://blog.cloudera.com/ml-interpretability-lime-and-shap-in-prose-and-code/ (accessed on 10 May 2021).
- Poduska, J. SHAP and LIME Python Libraries: Part 1–Great Explainers, with Pros and Cons to Both. Report. 2018. Available online: https://blog.dominodatalab.com/shap-lime-python-libraries-part-1-great-explainers-pros-cons (accessed on 20 May 2021).
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-Precision Model-Agnostic Explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 18, pp. 1527–1535. [Google Scholar]
- Ustun, B.; Traca, S.; Rudin, C. Supersparse linear integer models for interpretable classification. arXiv 2013, arXiv:1306.6677. [Google Scholar]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Faithful and customizable explanations of black box models. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 131–138. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. 9-Classification: Advanced Methods. In Data Mining, 3rd ed.; Han, J., Kamber, M., Pei, J., Eds.; The Morgan Kaufmann Series in Data Management Systems; Morgan Kaufmann: Boston, MA, USA, 2012; pp. 393–442. [Google Scholar] [CrossRef]
- Zhang, Q.; Xie, Q.; Wang, G. A survey on rough set theory and its applications. CAAI Trans. Intell. Technol. 2016, 1, 323–333. [Google Scholar] [CrossRef]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar]
- Niu, Y.; Gu, L.; Zhao, Y.; Lu, F. Explainable Diabetic Retinopathy Detection and Retinal Image Generation. arXiv 2021, arXiv:2107.00296. [Google Scholar] [CrossRef]
- Duarte, K.; Monnez, J.M.; Albuisson, E. Methodology for constructing a short-term event risk score in heart failure patients. Appl. Math. 2018, 9, 954–974. [Google Scholar] [CrossRef] [Green Version]
- Ghorbani, A.; Ouyang, D.; Abid, A.; He, B.; Chen, J.H.; Harrington, R.A.; Liang, D.H.; Ashley, E.A.; Zou, J.Y. Deep learning interpretation of echocardiograms. NPJ Digit. Med. 2020, 3, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Moreno-Sanchez, P.A. Development of an Explainable Prediction Model of Heart Failure Survival by Using Ensemble Trees. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 4902–4910. [Google Scholar]
- Athanasiou, M.; Sfrintzeri, K.; Zarkogianni, K.; Thanopoulou, A.C.; Nikita, K.S. An explainable XGBoost–based approach towards assessing the risk of cardiovascular disease in patients with Type 2 Diabetes Mellitus. In Proceedings of the 2020 IEEE 20th International Conference on Bioinformatics and Bioengineering (BIBE), Cincinnati, OH, USA, 26–28 October 2020; pp. 859–864. [Google Scholar]
- Zhang, D.; Yang, S.; Yuan, X.; Zhang, P. Interpretable deep learning for automatic diagnosis of 12-lead electrocardiogram. Iscience 2021, 24, 102373. [Google Scholar] [CrossRef]
- Dave, D.; Naik, H.; Singhal, S.; Patel, P. Explainable ai meets healthcare: A study on heart disease dataset. arXiv 2020, arXiv:2011.03195. [Google Scholar]
- Feng, X.; Hua, Y.; Zou, J.; Jia, S.; Ji, J.; Xing, Y.; Zhou, J.; Liao, J. Intelligible Models for HealthCare: Predicting the Probability of 6-Month Unfavorable Outcome in Patients with Ischemic Stroke. Neuroinformatics 2021, 1–11. [Google Scholar] [CrossRef]
- Visani, G.; Bagli, E.; Chesani, F. OptiLIME: Optimized LIME Explanations for Diagnostic Computer Algorithms. arXiv 2020, arXiv:2006.05714. [Google Scholar]
- Oh, S.; Park, Y.; Cho, K.J.; Kim, S.J. Explainable Machine Learning Model for Glaucoma Diagnosis and Its Interpretation. Diagnostics 2021, 11, 510. [Google Scholar] [CrossRef]
- Shankaranarayana, S.M.; Runje, D. ALIME: Autoencoder based approach for local interpretability. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Manchester, UK, 14–16 November 2019; pp. 454–463. [Google Scholar]
- Duell, J.; Fan, X.; Burnett, B.; Aarts, G.; Zhou, S.M. A Comparison of Explanations Given by Explainable Artificial Intelligence Methods on Analysing Electronic Health Records. In Proceedings of the 2021 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), Athens, Greece, 27–30 July 2021; pp. 1–4. [Google Scholar]
- Hu, C.A.; Chen, C.M.; Fang, Y.C.; Liang, S.J.; Wang, H.C.; Fang, W.F.; Sheu, C.C.; Perng, W.C.; Yang, K.Y.; Kao, K.C. Using a machine learning approach to predict mortality in critically ill influenza patients: A cross-sectional retrospective multicentre study in Taiwan. BMJ Open 2020, 10, e033898. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Ruan, W.; Wang, J.; Zheng, D.; Liu, B.; Geng, Y.; Chai, X.; Chen, J.; Li, K.; Li, S.; et al. Interpretable machine learning for covid-19: An empirical study on severity prediction task. IEEE Trans. Artif. Intell. 2021, 1–14. [Google Scholar] [CrossRef]
- Karim, M.R.; Döhmen, T.; Cochez, M.; Beyan, O.; Rebholz-Schuhmann, D.; Decker, S. DeepCOVIDExplainer: Explainable COVID-19 Diagnosis from Chest X-ray Images. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Korea, 16–19 December 2020; pp. 1034–1037. [Google Scholar] [CrossRef]
- Garbulowski, M.; Diamanti, K.; Smolińska, K.; Baltzer, N.; Stoll, P.; Bornelöv, S.; hrn, A.; Feuk, L.; Komorowski, J.R. ROSETTA: An interpretable machine learning framework. BMC Bioinform. 2021, 22, 110. [Google Scholar] [CrossRef]
- Molnar, C.; König, G.; Herbinger, J.; Freiesleben, T.; Dandl, S.; Scholbeck, C.A.; Casalicchio, G.; Grosse-Wentrup, M.; Bischl, B. Pitfalls to avoid when interpreting machine learning models. arXiv 2020, arXiv:2007.04131. [Google Scholar]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect. Basic Books. 2018. Available online: https://www.basicbooks.com/titles/judea-pearl/the-book-of-why/9780465097616/ (accessed on 3 October 2021).
- Gunnar, K.; Moritz, G.W. A Causal Perspective on Challenges for AI in Precision Medicine. 2019. Available online: https://koenig.page/pdf/koenig2019_pmbc.pdf (accessed on 1 November 2021).
- Saul, B.C.; Hudgens, M.G.; Halloran, M.E. Causal inference in the study of infectious disease. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2017; Volume 36, pp. 229–246. [Google Scholar]
- Weichwald, S.; Meyer, T.; Özdenizci, O.; Schölkopf, B.; Ball, T.; Grosse-Wentrup, M. Causal interpretation rules for encoding and decoding models in neuroimaging. NeuroImage 2015, 110, 48–59. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Q.; Hastie, T. Causal interpretations of black-box models. J. Bus. Econ. Stat. 2021, 39, 272–281. [Google Scholar] [CrossRef] [PubMed]
- Hooker, G.; Mentch, L. Please stop permuting features: An explanation and alternatives. arXiv 2019, arXiv:1905.03151. [Google Scholar]
- Scholbeck, C.A.; Molnar, C.; Heumann, C.; Bischl, B.; Casalicchio, G. Sampling, intervention, prediction, aggregation: A generalized framework for model-agnostic interpretations. arXiv 2019, arXiv:1904.03959. [Google Scholar]
- Molnar, C.; König, G.; Bischl, B.; Casalicchio, G. Model-agnostic Feature Importance and Effects with Dependent Features—A Conditional Subgroup Approach. arXiv 2020, arXiv:2006.04628. [Google Scholar]
- Larionov, M. Uncertainty in machine learning predictions: How to use the data we don’t completely trust. Medium. 2018. Available online: https://medium.datadriveninvestor.com/uncertainty-in-machine-learning-predictions-fead32abf717 (accessed on 13 October 2021).
- Curchoe, C.L. All Models Are Wrong, but Some Are Useful. J. Assist. Reprod. Genet. 2020, 37, 2389–2391. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Watson, D.S.; Wright, M.N. Testing conditional independence in supervised learning algorithms. Mach. Learn. 2021, 110, 2107–2129. [Google Scholar] [CrossRef]
- Williamson, B.; Feng, J. Efficient nonparametric statistical inference on population feature importance using Shapley values. In Proceedings of the International Conference on Machine Learning, Montréal, QC, Canada, 6–8 July 2020; pp. 10282–10291. [Google Scholar]
- Fabi, K.; Schneider, J. On feature relevance uncertainty: A Monte Carlo dropout sampling approach. arXiv 2020, arXiv:2008.01468. [Google Scholar]
- Kläs, M.; Vollmer, A.M. Uncertainty in machine learning applications: A practice-driven classification of uncertainty. In Proceedings of the International Conference on Computer Safety, Reliability, and Security, Västerås, Sweden, 19–21 September 2018; pp. 431–438. [Google Scholar]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 1–81. [Google Scholar]
- Ghorbani, A.; Abid, A.; Zou, J. Interpretation of neural networks is fragile. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3681–3688. [Google Scholar]
- Rudin, C. Please stop explaining black box models for high stakes decisions. Stat 2018, 1050, 26. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- O’neil, C. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. Crown. 2016. Available online: https://dl.acm.org/doi/10.5555/3002861 (accessed on 10 September 2021).
- Card, D. The “Black Box” Metaphor in Machine Learning. Medium. 2021. Available online: https://dallascard.medium.com/the-black-box-metaphor-in-machine-learning-4e57a3a1d2b0 (accessed on 23 October 2021).
- Kwon, B.C.; Choi, M.J.; Kim, J.T.; Choi, E.; Kim, Y.B.; Kwon, S.; Sun, J.; Choo, J. Retainvis: Visual analytics with interpretable and interactive recurrent neural networks on electronic medical records. IEEE Trans. Vis. Comput. Graph. 2018, 25, 299–309. [Google Scholar] [CrossRef] [Green Version]
- Vellido, A. The importance of interpretability and visualization in machine learning for applications in medicine and health care. Neural Comput. Appl. 2020, 32, 18069–18083. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
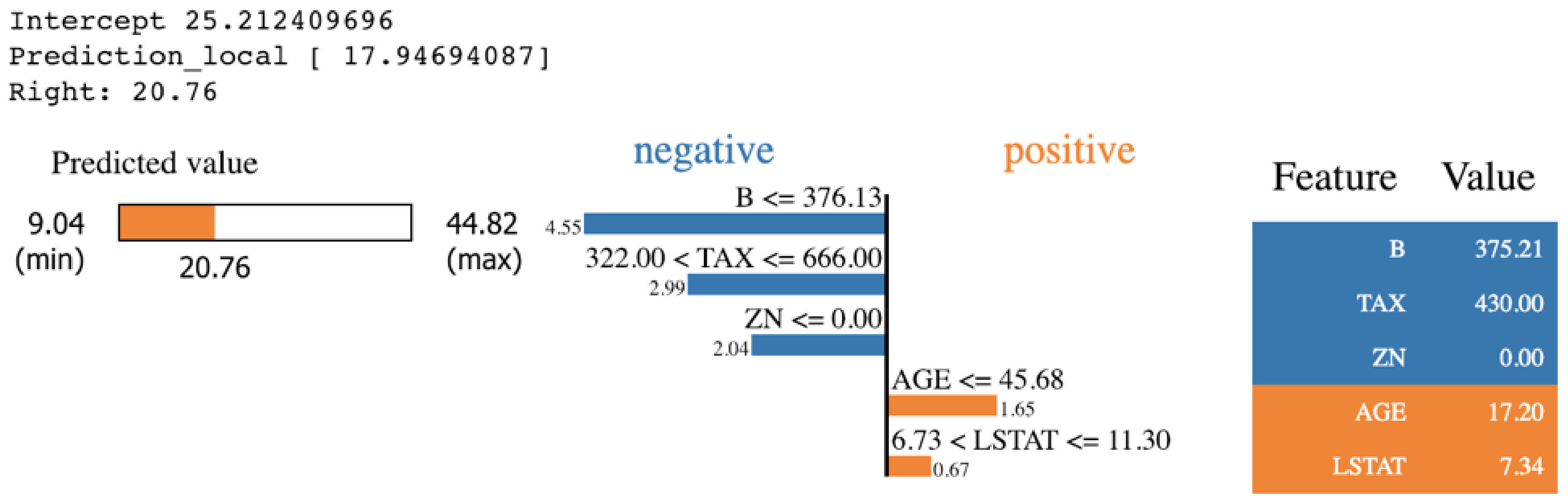{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Type | Pros | Cons |
|---|---|---|
| Model-specific | Most method explanations are intuitive. Very fast. Highly translucent. Interpretations are more accurate. | Limited to a specific model. High switching cost. Feature selection is required to reduce dimensionality and enhance the explanation. |
| Model-agnostic | Easy to switch to another model. Low switching cost. No restrictions on the ML model. Not limited to a specific model. | Cannot access model internals. Interpretations are less accurate. |
| Category | Approach | Complexity-Related | Model-Related | Scope-Related | Outcome | |||
|---|---|---|---|---|---|---|---|---|
| Intrinsic | Post-Hoc | Specific | Agnostic | Local | Global | |||
| Feature Based | Weight plot | √ | √ | √ | MI | |||
| Feature selection | √ | √ | √ | FS | ||||
| PDP | √ | √ | √ | FS | ||||
| ICE | √ | √ | √ | FS | ||||
| ALE | √ | √ | √ | FS | ||||
| GENESIM | √ | √ | √ | FS | ||||
| Effect score | √ | √ | √ | FS | ||||
| Out Of Bag | √ | √ | √ | FS | ||||
| Perturbation Based | LIME | √ | √ | √ | SI | |||
| SHAP | √ | √ | √ | FS | ||||
| Anchors | √ | √ | √ | SI | ||||
| Rule Based | Scoring system | √ | √ | √ | FS | |||
| Rough set | √ | √ | √ | FS | ||||
| BETA | √ | √ | √ | FS | ||||
| MUSE | √ | √ | √ | FS | ||||
| Decision Trees | √ | √ | √ | FS | ||||
| Image Based | Saliency map | √ | √ | √ | FS | |||
| LRP | √ | √ | √ | FS | ||||
| Grad-CAM | √ | √ | √ | FS | ||||
| Disease | Reference | ML Algorithm | IML Method | Performance |
|---|---|---|---|---|
| Cardiovascular | [47], 2016 | Decision Trees | GENESIM | AC = 0.79 |
| [60], 2018 | Ensemble Predictor | Out-of-bag | AUC = 0.87 | |
| [61], 2020 | CNN | Saliency map | AUC = 0.89 | |
| [62], 2020 | XGBoost | SHAP | AC = 0.83 | |
| [63], 2020 | XGBoost | Tree SHAP | AUC = 0.71 | |
| [65], 2020 | XGBoost | Anchors, LIME, SHAP | AC = 0.98 | |
| [67], 2020 | XGBoost | OptiLIME | N/A | |
| [45], 2021 | SLSE | ALE | AUC = 0.87 | |
| [64], 2021 | 1D CNN | SHAP | AUC = 0.97 | |
| [46], 2021 | LR, RF, XGBoost | Effect score | AUC = 0.91 | |
| [59], 2021 | Patho-GAN | Patho-GAN | MSE = 0.01 | |
| [68], 2021 | XGboost | SHAP | AC = 0.95 | |
| [66], 2021 | RF | PDP | AUC = 0.90 | |
| Cancer | [53], 2013 | SLIM | Scoring System | AC = 0.97 |
| [69], 2019 | CNN | ALIME | AC = 0.95 | |
| [70], 2021 | XGBoos | Anchors, LIME, SHAP | AC = 0.78 | |
| Influenza and Infection | [71], 2020 | XGBoost | SHAP | AUC = 0.84 |
| [72], 2021 | DT, RF, ANN | ICE, PDP,ALE | F1 = 0.80 | |
| COVID-19 | [37], 2020 | XGBoost | Feature Importance | AC = 0.90 |
| [73], 2020 | DNN | Grad-CAM,LRP | F1 = 0.95 | |
| Depression | [54], 2017 | CNN | MUSE, BETA | AC= 0.98 |
| Autism | [74], 2021 | Rough set | Rule-based | AC = 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullah, T.A.A.; Zahid, M.S.M.; Ali, W. A Review of Interpretable ML in Healthcare: Taxonomy, Applications, Challenges, and Future Directions. Symmetry 2021, 13, 2439. https://doi.org/10.3390/sym13122439
Abdullah TAA, Zahid MSM, Ali W. A Review of Interpretable ML in Healthcare: Taxonomy, Applications, Challenges, and Future Directions. Symmetry. 2021; 13(12):2439. https://doi.org/10.3390/sym13122439
Chicago/Turabian StyleAbdullah, Talal A. A., Mohd Soperi Mohd Zahid, and Waleed Ali. 2021. "A Review of Interpretable ML in Healthcare: Taxonomy, Applications, Challenges, and Future Directions" Symmetry 13, no. 12: 2439. https://doi.org/10.3390/sym13122439
APA StyleAbdullah, T. A. A., Zahid, M. S. M., & Ali, W. (2021). A Review of Interpretable ML in Healthcare: Taxonomy, Applications, Challenges, and Future Directions. Symmetry, 13(12), 2439. https://doi.org/10.3390/sym13122439