
Fuzzy Interpolation with Extensional Fuzzy Numbers



Abstract
:1. Introduction
2. Preliminaries—Arithmetical Operations on Extensional Fuzzy Numbers
2.1. Motivation and the Main Concepts
- (i)
- (ii)
- (iii)
2.2. Arithmetic of Extensional Fuzzy Numbers
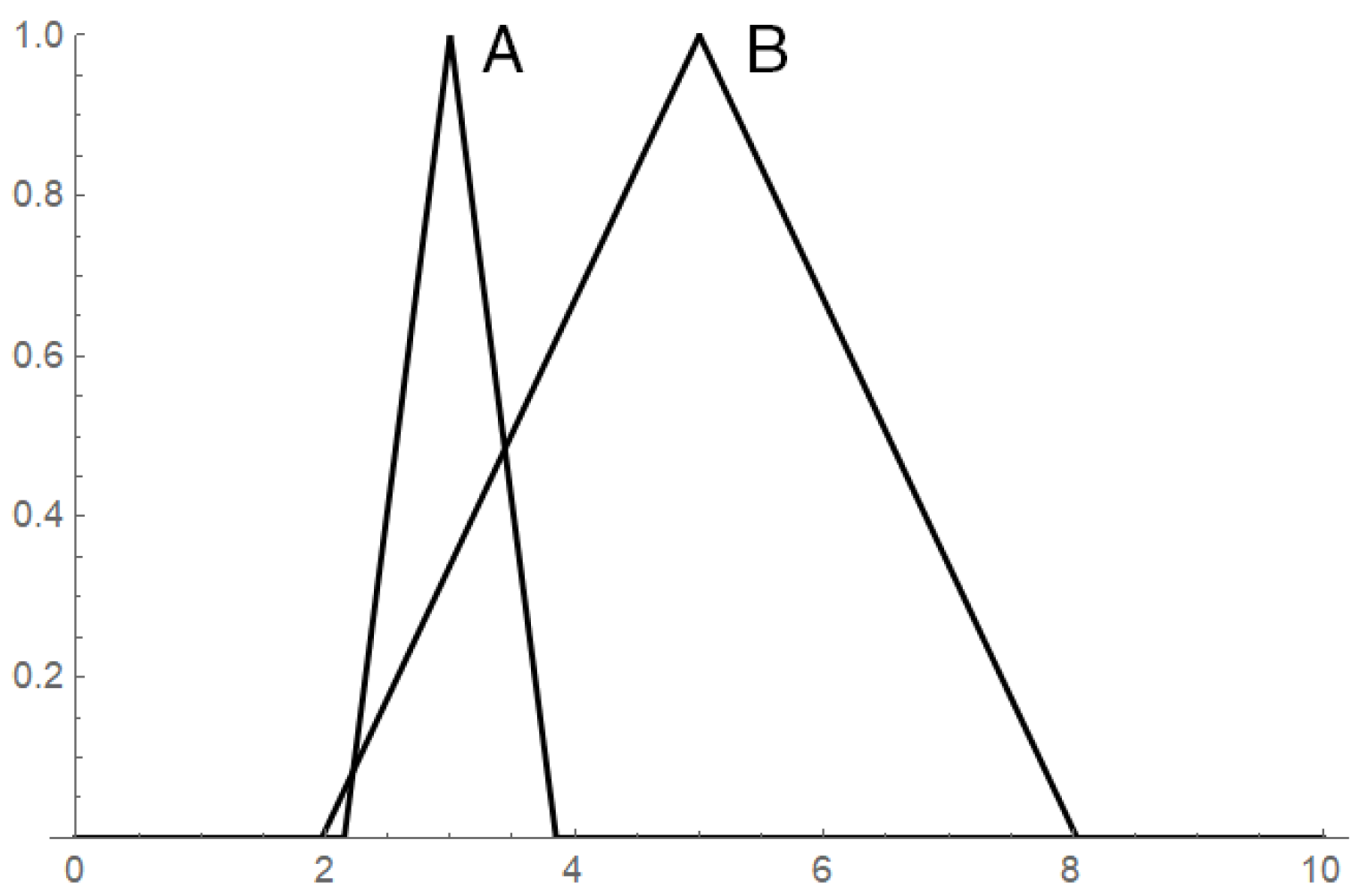
3. Orderings of Extensional Fuzzy Numbers
3.1. Motivation
- (1)
- ,
- (2)
- for any and , there exists such that , and vice versa, for any , there exists such that .
- (3)
- for any , there exists such that and , and vice versa, for any , there exists such that and .
3.2. Definitions and Examples
- (O1)
- , (reflexivity)
- (O2)
- (O3)
- (O1)
- , (reflexivity)
- (O2)
- (O3)
- .
4. Properties of -Orderings
4.1. Wang–Kerre Properties of Orderings of Fuzzy Numbers
- A1:
- , for ;
- A2:
- , for ;
- A3:
- , for ;
- A4:
- , for ;
- A5:
- Let . Then ;
- A6:
- Let . Then ;
- A7:
- Let and .Then .
4.2. Wang–Kerre Properties for -Orderings and Their Preservation
- A1’:
- ;
- A2’:
- ;
- A3’:
- ;
- A4’:
- ;
- A6’:
- ;
- A7’:
- and ;
- (P1)
- ,
- (P2)
- and .
- (H1)
- , and for any ;
- (H2)
- , and for any ;
- (H3)
- for any .
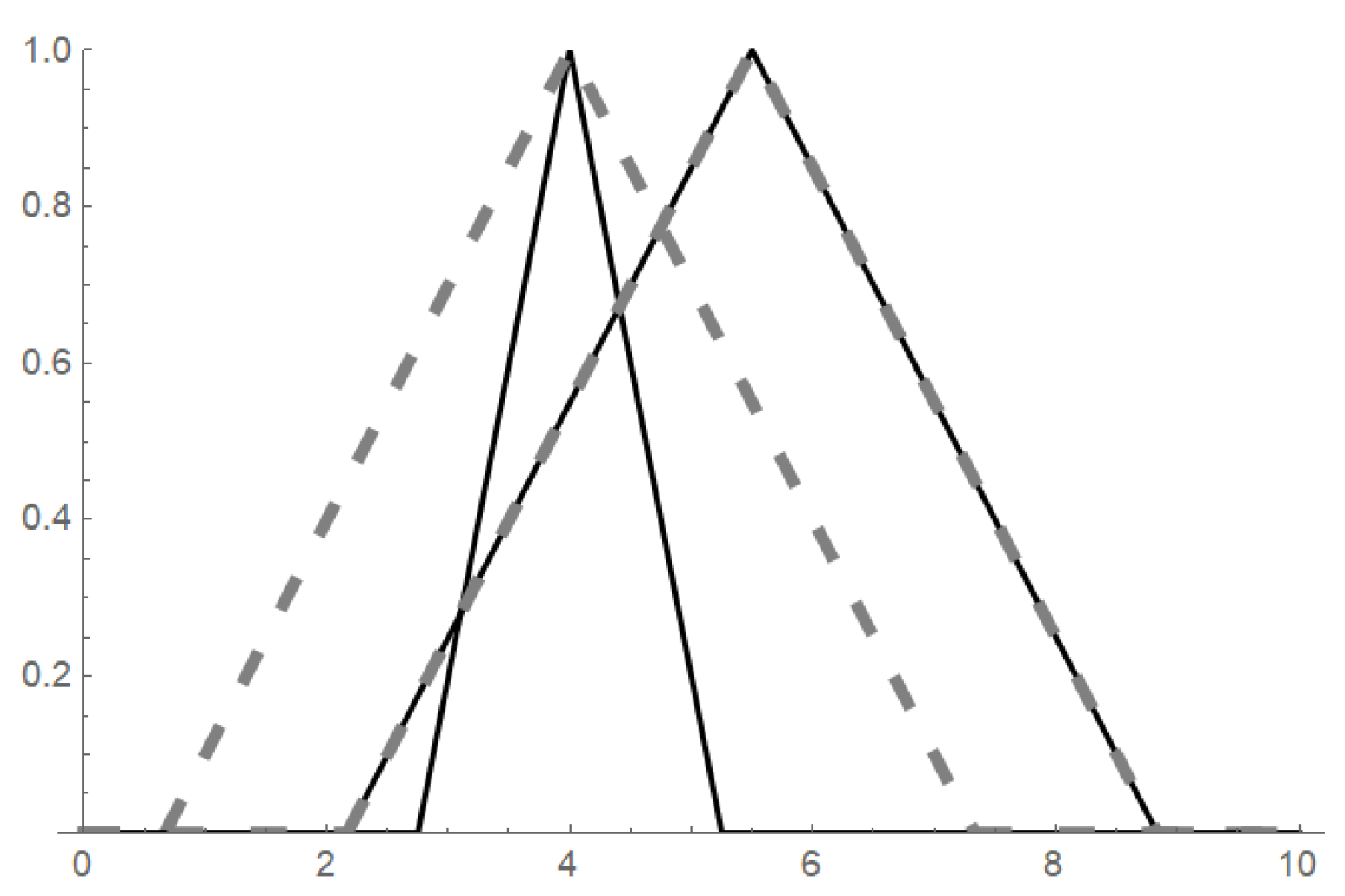
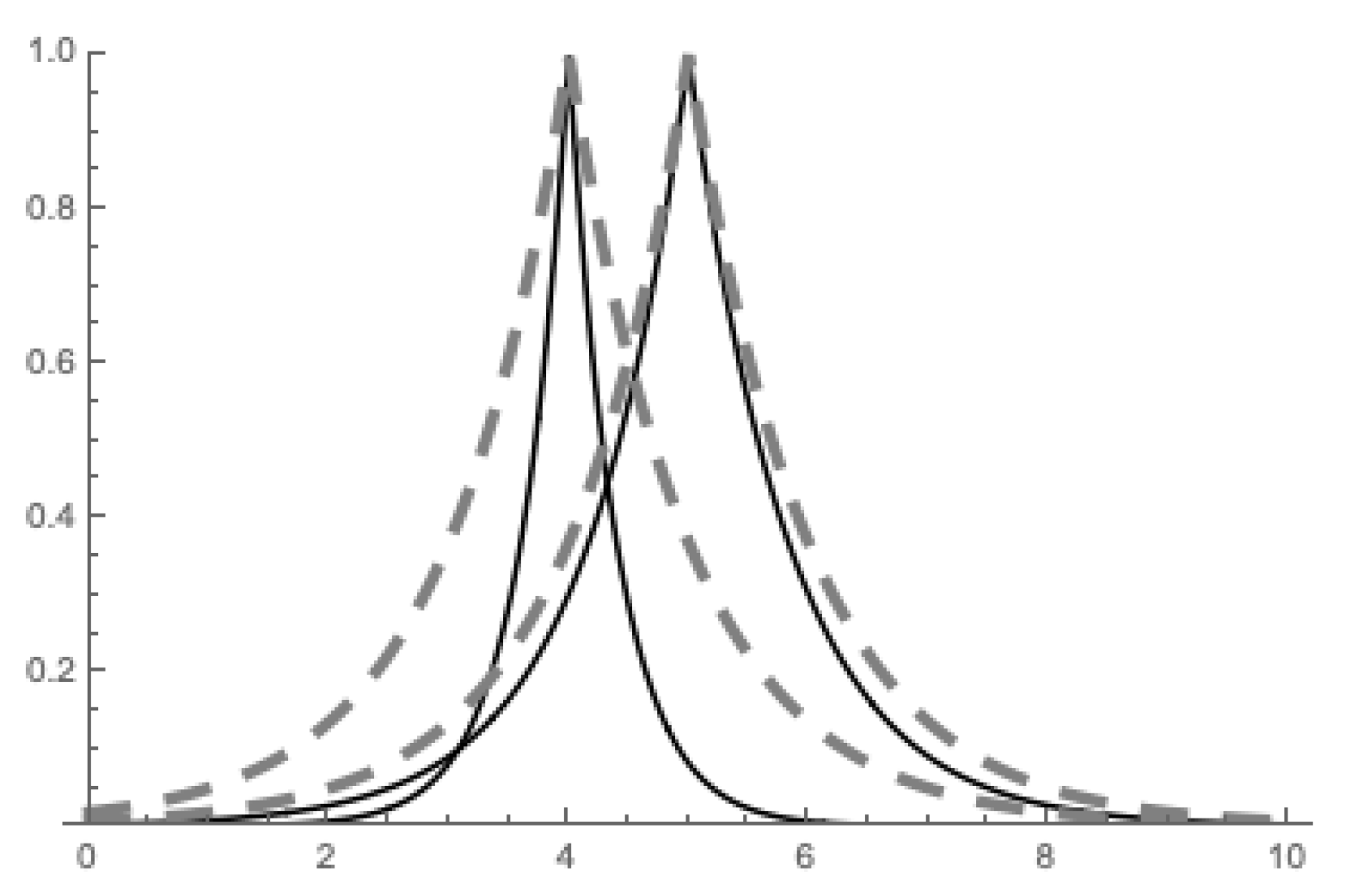
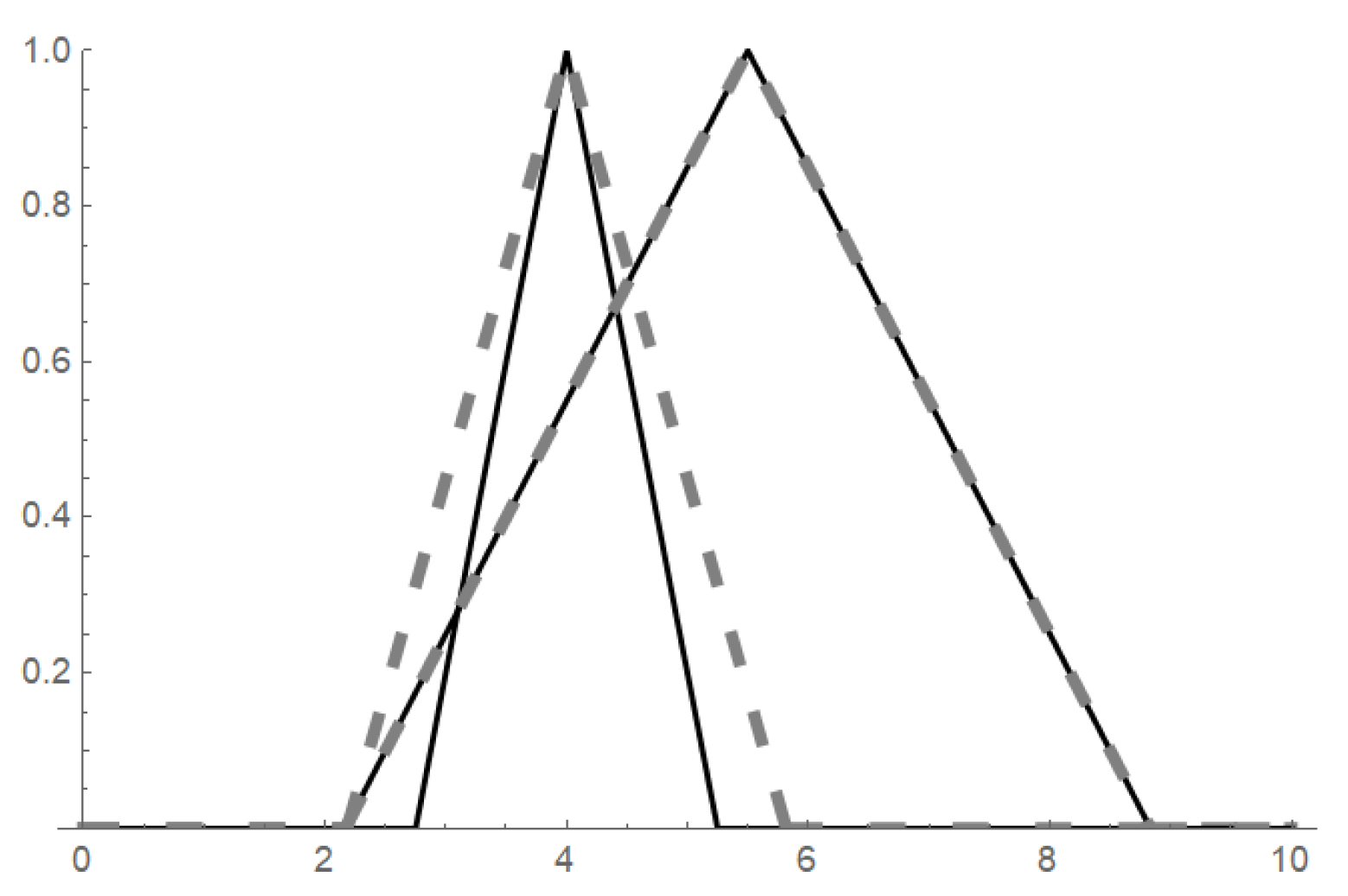
5. Application to Fuzzy Interpolation
5.1. The Concept of -Function
5.2. -interpolation
5.3. Properties
- (a)
- -interpolates the given pairs of extensional fuzzy numbers;
- (b)
- preserves uncertainty monotonicity condition (19).
6. Experimental Demonstration
6.1. Ice-Cream Sales Modeling
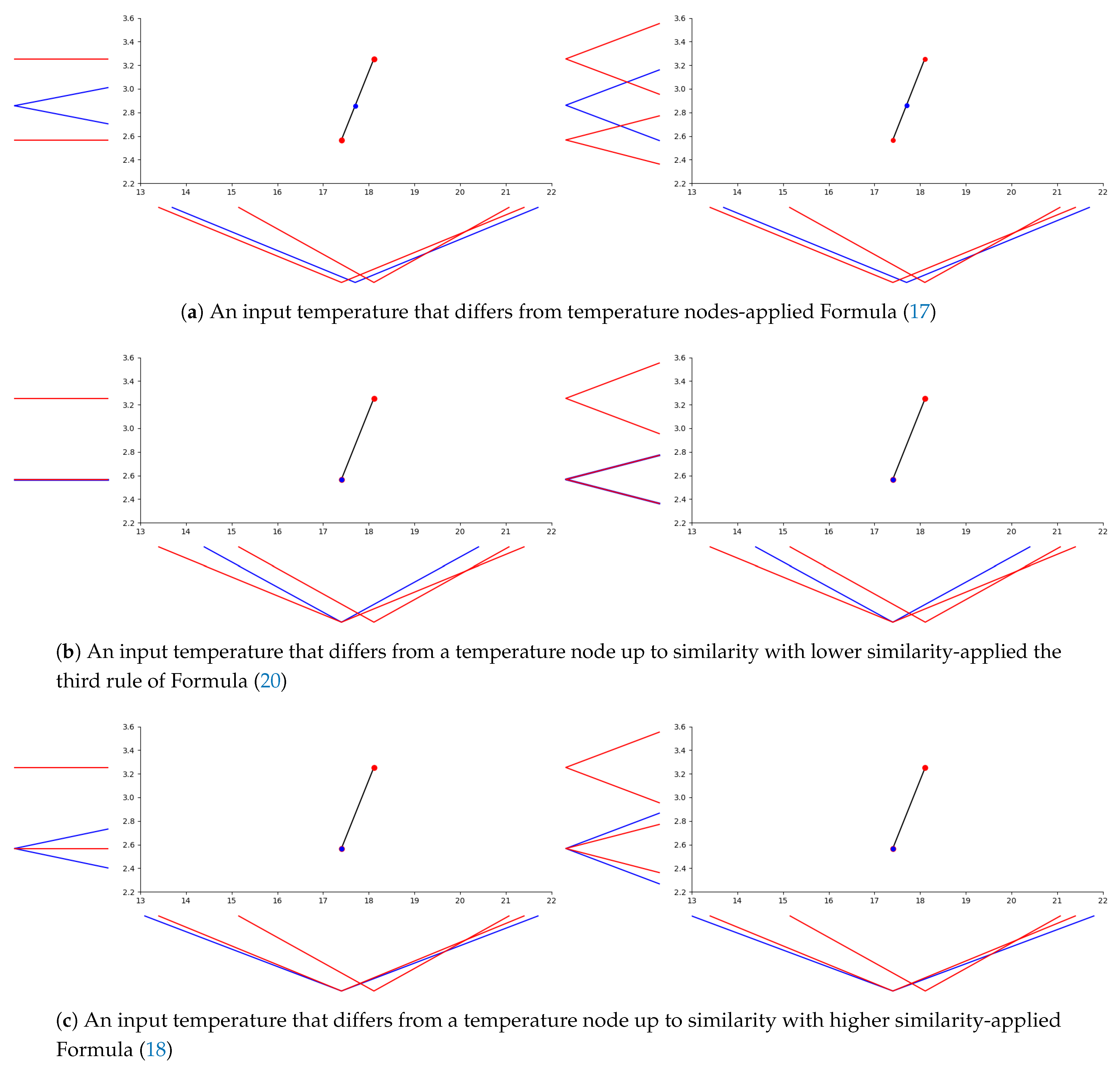
6.2. General Description of -Interpolation Procedure
- Input:
- extensional fuzzy number from
- Step 1:
- normalize with respect to to get
- Step 2:
- find such that
- Step 3:
- compute from and by Formula (20)
- Step 4:
- compute (a denormalization procedure)
- Output:
- extensional fuzzy number from
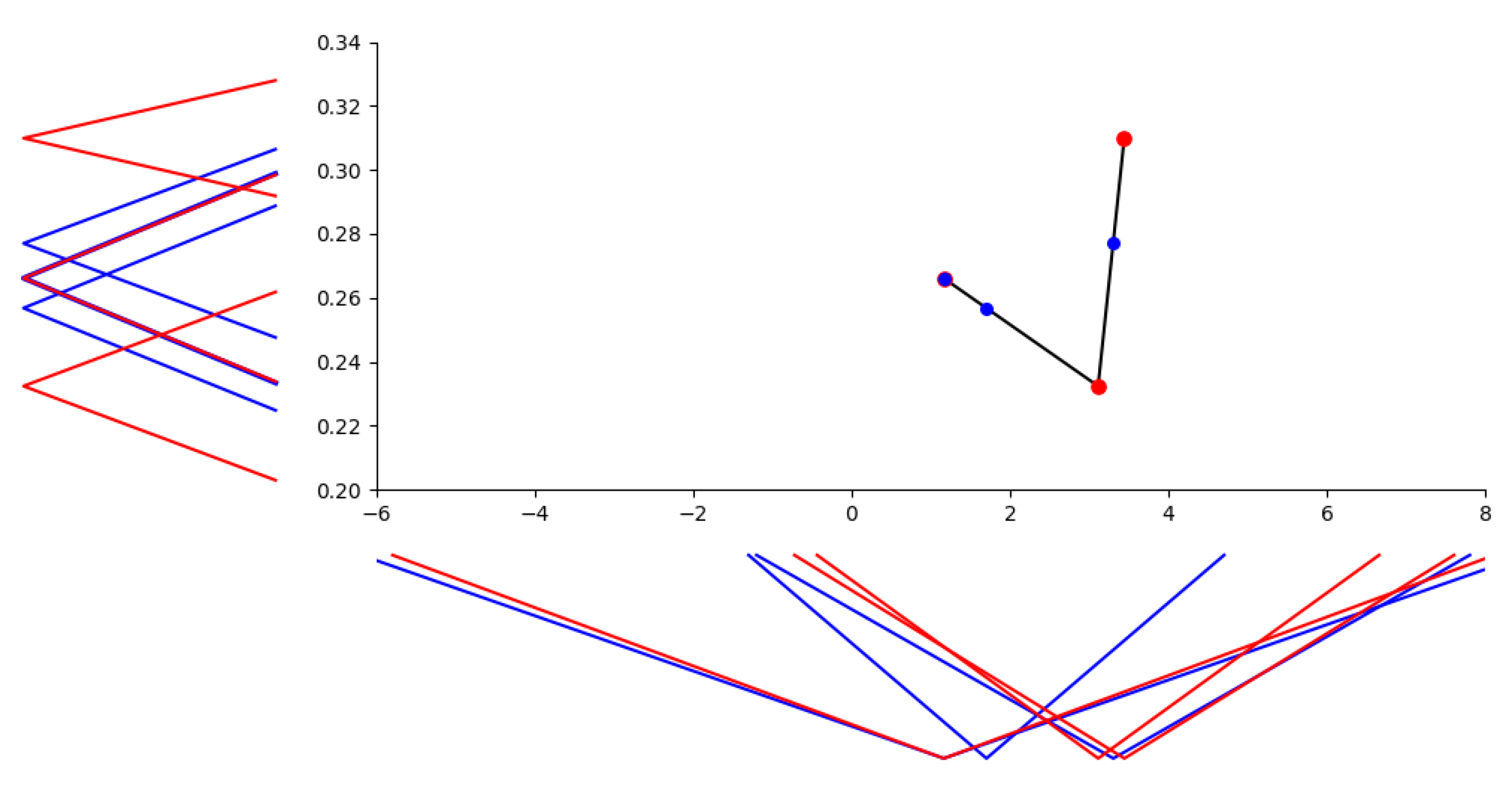
6.3. Experimental Results
- (a)
- the ice-cream sales are crisp fuzzy numbers, i.e., extensional fuzzy numbers , where is the equality relation and only the first parameter in each pair is considered in Table 1;
- (b)
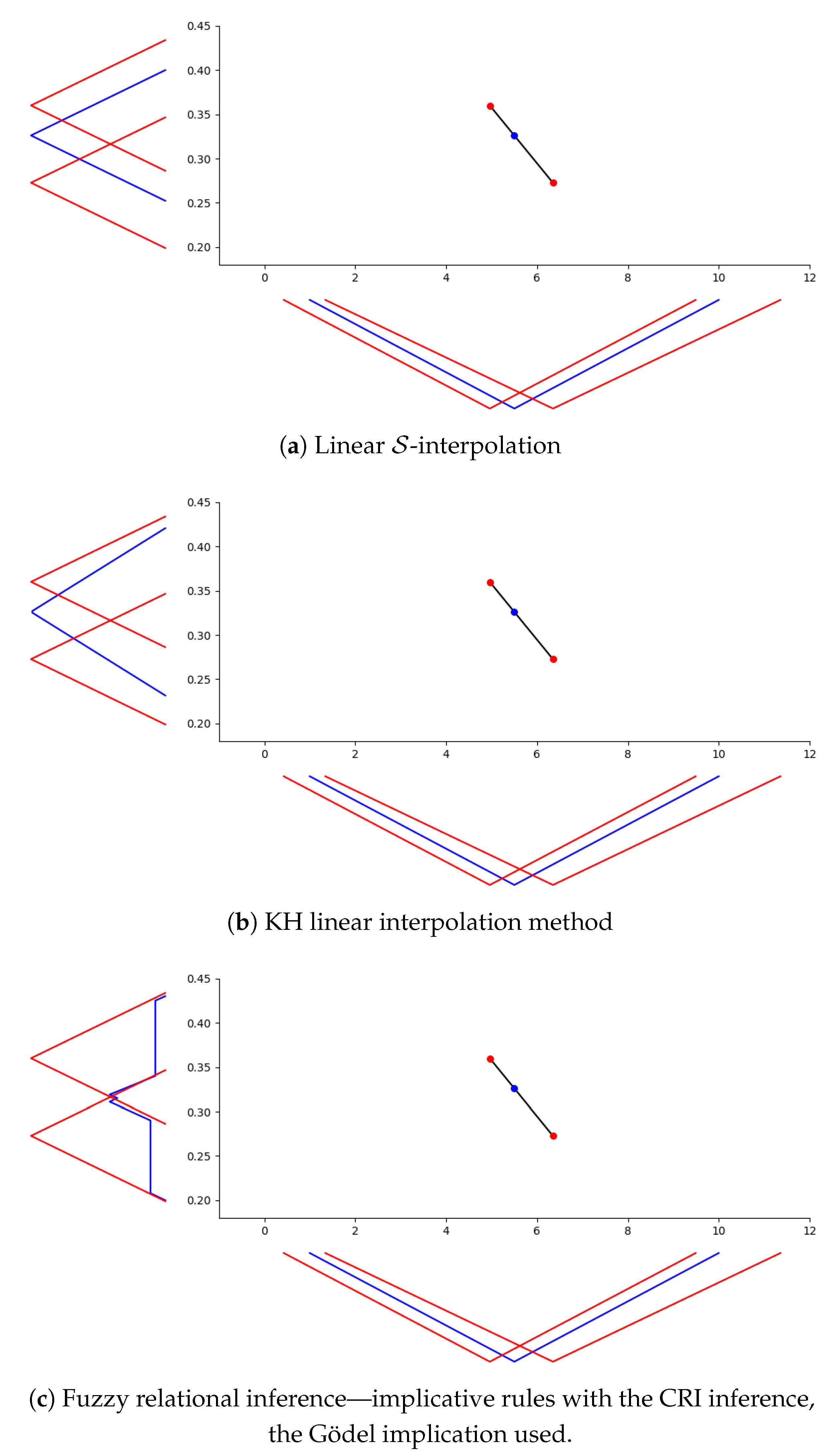
6.4. Comparing with Other Approaches—Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Perfilieva, I. Finitary Solvability Conditions for Systems of Fuzzy Relation Equations. Inf. Sci. 2013, 234, 29–43. [Google Scholar] [CrossRef]
- Di Nola, A.; Sessa, S.; Pedrycz, W.; Sanchez, E. Fuzzy Relation Equations and Their Applications to Knowledge Engineering; Kluwer: Boston, MA, USA, 1989. [Google Scholar]
- Pedrycz, W. Applications of fuzzy relational equations for methods of reasoning in presence of fuzzy data. Fuzzy Sets Syst. 1985, 16, 163–175. [Google Scholar] [CrossRef]
- De Baets, B. Analytical solution methods for fuzzy relational equations. In The Handbook of Fuzzy Set Series Vol. 1; Dubois, D., Prade, H., Eds.; Academic Kluwer Publ.: Boston, MA, USA, 2000; pp. 291–340. [Google Scholar]
- Perfilieva, I.; Lehmke, S. Correct models of fuzzy IF-THEN rules are continuous. Fuzzy Sets Syst. 2006, 157, 3188–3197. [Google Scholar] [CrossRef]
- Cornejo, M.E.; Lobo, D.; Medina, J. On the solvability of bipolar max-product fuzzy relation equations with the product negation. J. Comput. Appl. Math. 2018, 354, 520–532. [Google Scholar] [CrossRef]
- Štěpnička, M.; De Baets, B. Interpolativity of at-least and at-most models of monotone single-input single-output fuzzy rule bases. Inf. Sci. 2013, 234, 16–28. [Google Scholar] [CrossRef]
- Štěpnička, M.; Jayaram, B. Interpolativity of at-least and at-most models of monotone fuzzy rule bases with multiple antecedent variables. Fuzzy Sets Syst. 2016, 297, 26–45. [Google Scholar] [CrossRef]
- Kóczy, L.; Hirota, K. Approximate reasoning by linear rule interpolation and general approximation. Int. J. Approx. Reason. 1993, 9, 197–225. [Google Scholar] [CrossRef] [Green Version]
- Vetterlein, T.; Štěpnička, M. Completing fuzzy if-then rule bases by means of smoothing. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2006, 14, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Kóczy, L.; Hirota, K. Interpolative reasoning with insufficient evidence in sparse fuzzy rule bases. Inf. Sci. 1993, 71, 169–201. [Google Scholar] [CrossRef]
- Baranyi, P.; Kóczy, L.; Gedeon, T. A generalized concept for fuzzy rule interpolation. IEEE Trans. Fuzzy Syst. 2004, 12, 820–837. [Google Scholar] [CrossRef]
- Li, F.; Shang, C.; Li, Y.; Yang, J.; Shen, Q. Interpolation with Just Two Nearest Neighboring Weighted Fuzzy Rules. IEEE Trans. Fuzzy Syst. 2020, 28, 2255–2262. [Google Scholar] [CrossRef] [Green Version]
- Bouchon-Meunier, B.; Dubois, D.; Marsala, C.; Prade, H.; Ughetto, L. A comparative view of interpolation methods between sparse fuzzy rules. In Proceedings of the Annual Conference of the North American Fuzzy Information Processing Society-NAFIPS, Vancouver, BC, Canada, 25–28 July 2001; Volume 5, pp. 2499–2504. [Google Scholar]
- Perfilieva, I.; Dubois, D.; Prade, H.; Esteva, F.; Godo, L.; Hoďáková, P. Interpolation of fuzzy data: Analytical approach and overview. Fuzzy Sets Syst. 2012, 192, 134–158. [Google Scholar] [CrossRef]
- Mareš, M. Computation over Fuzzy Quantities; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Bělohlávek, R. Fuzzy Relational Systems: Foundations and Principles; Kluwer Academic, Plenum Press: Dordrecht, the Netherlands; New York, NY, USA, 2002. [Google Scholar]
- Klawonn, F. Fuzzy Points, Fuzzy Relations and Fuzzy Functions. In Discovering the World with Fuzzy Logic; Novák, V., Perfilieva, I., Eds.; Springer: Berlin, Germany, 2000; pp. 431–453. [Google Scholar]
- Holčapek, M.; Štěpnička, M. MI-algebras: A new framework for arithmetics of (extensional) fuzzy numbers. Fuzzy Sets Syst. 2014, 257, 102–131. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Operations on fuzzy numbers. Int. J. Syst. Sci. 1978, 9, 613–626. [Google Scholar] [CrossRef]
- Stefanini, L.; Sorini, L.; Guerra, M. Parametric representation of fuzzy numbers and application to fuzzy calculus. Fuzzy Sets Syst. 2006, 157, 2423–2455. [Google Scholar] [CrossRef]
- Mareš, M. Weak arithmetics of fuzzy numbers. Fuzzy Sets Syst. 1997, 91, 143–153. [Google Scholar] [CrossRef]
- Štěpnička, M.; Holčapek, M.; Škorupová, N. Orderings of Extensional Fuzzy Numbers. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2019, New Orleans, LA, USA, 23–26 June 2019. [Google Scholar]
- Štěpnička, M.; Škorupová, N.; Holčapek, M. On the properties of orderings of extensional fuzzy numbers. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2020, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Holčapek, M.; Štěpnička, M. Arithmetics of extensional fuzzy numbers–part I: Introduction. In Proceedings of the IEEE International Conference on Fuzzy Systems, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Holčapek, M.; Štěpnička, M. Arithmetics of extensional fuzzy numbers–part II: Algebraic framework. In Proceedings of the IEEE International Conference on Fuzzy Systems, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Ma, M.; Friedman, M.; Kandel, A. A new fuzzy arithmetic. Fuzzy Sets Syst. 1999, 108, 83–90. [Google Scholar] [CrossRef]
- Stefanini, L.; Sorini, L.; Guerra, M. Simulation of fuzzy dynamical systems using the LU-representation of fuzzy numbers. Chaos Solitons Fractals 2006, 29, 638–652. [Google Scholar] [CrossRef]
- Fortin, J.; Dubois, D.; Fargier, H. Gradual Numbers and Their Application to Fuzzy Interval Analysis. IEEE Trans. Fuzzy Syst. 2008, 16, 388–402. [Google Scholar] [CrossRef] [Green Version]
- Boixader, D.; Jacas, J. Extensionality based approximate reasoning. Int. J. Approx. Reason. 1998, 19, 221–230. [Google Scholar] [CrossRef]
- Klawonn, F.; Castro, J.L. Similarity in Fuzzy Reasoning. Mathw. Soft Comput. 1995, 2, 197–228. [Google Scholar]
- Klawonn, F.; Kruse, R. Equality relations as a basis for fuzzy control. Fuzzy Sets Syst. 1993, 54, 147–156. [Google Scholar] [CrossRef]
- Holčapek, M.; Wrublová, M.; Bacovský, M. Quotient MI-groups. Fuzzy Sets Syst. 2016, 283, 1–25. [Google Scholar] [CrossRef]
- Holčapek, M. On generalized quotient MI-groups. Fuzzy Sets Syst. 2017, 326, 3–23. [Google Scholar] [CrossRef]
- Holčapek, M.; Škorupová, N. Topological MI-Groups: Initial Study. In IPMU 2018: Information Processing and Management of Uncertainty in Knowledge-Based Systems, Proceedings of the Applications-17th International Conference, Cádiz, Spain, 11–15 June 2018; Proceedings, Part III; Medina, J., Ojeda-Aciego, M., Galdeano, J.L.V., Perfilieva, I., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 855, Communications in Computer and Information Science; pp. 603–615. [Google Scholar]
- Aryal, B.; Bokati, L.; Godinez, K.; Ibarra, S.; Liu, H.; Wang, B.; Kreinovich, V. Common Sense Addition Explained by Hurwicz Optimism-Pessimism Criterion. J. Uncertain Syst. 2019, 13, 171–174. [Google Scholar]
- Hurwicz, L. Optimality Criteria for Decision Making Under Ignorance; Cowles Commission Discussion Paper, Statistics; Yale University: New Haven, CT, USA, 1951; pp. 171–174. [Google Scholar]
- Zadeh, L. Similarity relations and fuzzy orderings. Inf. Sci. 1971, 3, 177–200. [Google Scholar] [CrossRef]
- Bodenhofer, U. A Similarity-Based Generalization of Fuzzy Orderings Preserving the Classical Axioms. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2000, 8, 593–610. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Wang, Z. Total orderings defined on the set of all fuzzy numbers. Fuzzy Sets Syst. 2014, 243, 131–141. [Google Scholar] [CrossRef]
- Asady, B.; Zendehnam, A. Ranking fuzzy numbers by distance minimization. Appl. Math. Model. 2007, 31, 2589–2598. [Google Scholar] [CrossRef]
- De Hierro, A.F.R.L.; Roldán, C.; Herrera, F. On a new methodology for ranking fuzzy numbers and its application to real economic data. Fuzzy Sets Syst. 2018, 353, 86–110. [Google Scholar] [CrossRef]
- Van Broekhoven, E.; De Baets, B. A linguistic fuzzy model with a monotone rule base is not always monotone. In Proceedings of the EUSFLAT-LFA’05, Barcelona, Spain, 7–9 September 2005; pp. 530–535. [Google Scholar]
- Van Broekhoven, E.; De Baets, B. On the monotonicity of Mamdani-Assilian models with two input variables. In Proceedings of the NAFIPS’06, Montreal, QC, Canada, 3–6 June 2006; pp. 102–107. [Google Scholar]
- Štěpnička, M.; De Baets, B. Implication-based models of monotone fuzzy rule bases. Fuzzy Sets Syst. 2013, 232, 134–155. [Google Scholar] [CrossRef]
- Bodenhofer, U. Orderings of Fuzzy Sets Based on Fuzzy Orderings Part I: The Basic Approach. Mathw. Soft Comput. 2008, 15, 201–218. [Google Scholar]
- Bodenhofer, U. Orderings of Fuzzy Sets Based on Fuzzy Orderings Part II: Generalizations. Mathw. Soft Comput. 2008, 15, 219–249. [Google Scholar]
- Štěpnička, M.; Škorupová, N.; Holčapek, M. From arithmetics of extensional fuzzy numbers to their distances. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) 2020, Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Wang, X.; Kerre, E.E. Reasonable properties for the ordering of fuzzy quantities (I). Fuzzy Sets Syst. 2001, 118, 375–385. [Google Scholar] [CrossRef]
- Wang, X.; Kerre, E.E. Reasonable properties for the ordering of fuzzy quantities (II). Fuzzy Sets Syst. 2001, 118, 387–405. [Google Scholar] [CrossRef]
- Van Broekhoven, E.; De Baets, B. Monotone Mamdani-Assilian models under mean of maxima defuzzification. Fuzzy Sets Syst. 2008, 159, 2819–2844. [Google Scholar] [CrossRef]
- Van Broekhoven, E.; De Baets, B. Only smooth rule bases can generate monotone Mamdani-Assilian models under Center-of-gravity defuzzification. IEEE Trans. Fuzzy Syst. 2009, 17, 1157–1174. [Google Scholar] [CrossRef]
- Štěpnička, M.; De Baets, B. Monotonicity of implicative fuzzy models. In Proceedings of the FUZZ-IEEE 2010, Barcelona, Spain, 18–23 July 2010; pp. 2334–2340. [Google Scholar]
- Mandal, S.; Jayaram, B. Monotonicity of SISO Fuzzy Relational Inference With an Implicative Rule Base. IEEE Trans. Fuzzy Syst. 2016, 24, 1475–1487. [Google Scholar] [CrossRef]
- Bodenhofer, U.; De Cock, M.; Kerre, E.E. Openings and closures of fuzzy preorderings: Theoretical basics and applications to fuzzy rule-based systems. Int. J. Gen. Syst. 2003, 32, 343–360. [Google Scholar] [CrossRef]
- Bodenhofer, U.; Bauer, P. Interpretability of Linguistic Variables: A Formal Account. Kybernetika 2005, 41, 227–248. [Google Scholar]
- Dvořáčková, H.; A., K.; Tichý, T. Sales Prediction in the Ice Category Applying Fuzzy Sets Theory. Ekon. Rev. Cent. Eur. Rev. Econ. Issues 2018, 21, 35–41. [Google Scholar]
- Das, S.; Chakraborty, D.; Kóczy, L. Linear fuzzy rule base interpolation using fuzzy geometry. Int. J. Approx. Reason. 2019, 112, 105–118. [Google Scholar] [CrossRef]
- Mamdani, E.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Jones, H.; Charnomordic, B.; Dubois, D.; Guillaume, S. Practical inference with systems of gradual implicative rules. IEEE Trans. Fuzzy Syst. 2009, 17, 61–78. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. What are fuzzy rules and how to use them. Fuzzy Sets Syst. 1996, 84, 169–185. [Google Scholar] [CrossRef]
- Štěpnička, M.; Mandal, S. Fuzzy inference systems preserving Moser–Navara axioms. Fuzzy Sets Syst. 2018, 338, 97–116. [Google Scholar] [CrossRef]
- Štěpnička, M.; Jayaram, B.; Su, Y. A short note on fuzzy relational inference systems. Fuzzy Sets Syst. 2018, 338, 90–96. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H.; Ughetto, L. Checking the Coherence and Redundancy of Fuzzy Knowledge Bases. IEEE Trans. Fuzzy Syst. 1997, 5, 398–417. [Google Scholar] [CrossRef]
- Rasmussen, C.; Williams, C. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Le, N.D.; Zidek, J.V. Statistical Analysis of Environmental Space-Time Processes; Springer: New York, NY, USA, 2006. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
|---|---|---|---|---|---|---|---|
| (0.23, 0.029) | (0.24, 0.053) | (0.25, 0.030) | (0.24, 0.048) | (0.27, 0.032) | (0.19, 0.047) | (0.31, 0.18) | |
| (1.54, 0.091) | (1.77, 0.094) | (1.53, 0.072) | (1.72, 0.082) | (1.66, 0.101) | (1.51, 0.118) | (1.60, 0.073) | |
| (2.53, 0.171) | (3.25, 0.299) | (2.59, 0.260) | (2.62, 0.433) | (2.57, 0.204) | (2.50, 0.399) | (2.22, 0.244) | |
| (0.32, 0.072) | (0.17, 0.106) | (0.35, 0.042) | (0.35, 0.075) | (0.22, 0.087) | (0.36, 0.064) | (0.27, 0.079) |
| 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
|---|---|---|---|---|---|---|---|
| (3.11, 3.55) | (0.09, 4.44) | (−0.75, 5.63) | (0.94, 5.30) | (1.16, 6.95) | (−0.97, 4.04) | (3.44, 4.16) | |
| (13.37, 5.09) | (14.09, 3.22) | (12.70, 4.74) | (14.46, 4.37) | (13.94, 5.95) | (12.32, 5.59) | (13.19, 4.34) | |
| (16.53, 4.60) | (18.12, 2.96) | (17.02, 4.85) | (17.05, 3.26) | (17.40, 3.99) | (17.02, 4.64) | (17.05, 3.60) | |
| (4.75, 4.68) | (4.53, 8.81) | (2.13, 6.67) | (4.84, 4.54) | (3.96, 4.80) | (4.96, 4.53) | (6.35, 5.01) |
| Quarters | Temperature st. Deviation | Ice-Cream Sale st. Deviation |
|---|---|---|
| 8.110 | 0.036 | |
| 8.063 | 0.010 | |
| 8.161 | 0.313 | |
| 8.034 | 0.072 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holčapek, M.; Škorupová, N.; Štěpnička, M. Fuzzy Interpolation with Extensional Fuzzy Numbers. Symmetry 2021, 13, 170. https://doi.org/10.3390/sym13020170
Holčapek M, Škorupová N, Štěpnička M. Fuzzy Interpolation with Extensional Fuzzy Numbers. Symmetry. 2021; 13(2):170. https://doi.org/10.3390/sym13020170
Chicago/Turabian StyleHolčapek, Michal, Nicole Škorupová, and Martin Štěpnička. 2021. "Fuzzy Interpolation with Extensional Fuzzy Numbers" Symmetry 13, no. 2: 170. https://doi.org/10.3390/sym13020170
APA StyleHolčapek, M., Škorupová, N., & Štěpnička, M. (2021). Fuzzy Interpolation with Extensional Fuzzy Numbers. Symmetry, 13(2), 170. https://doi.org/10.3390/sym13020170