1. Introduction
The Dagum distribution offered by Dagum [
1] has an essential role in modeling income distributions that could be utilized instead of some popular models including log-normal and Pareto models. Recently, authors have also considered the Dagum distribution in the context of reliability and survival analysis due to its flexibility for modeling lifetime data; see for example Domma et al. [
2] and Emam and Sultan [
3]. Presume that
X is a lifetime random variable of an experimental item follows the three-parameter Dagum distribution, denoted by
, where
is the vector of the unknown parameters, with scale parameter
and shape parameters
and
. Hence, the related probability density function (PDF) and the cumulative distribution function (CDF) of
X, are given by
and
respectively. One can see that the Dagum distribution can be considered as a mixture model in terms of inverse Weibull and generalized gamma models. Kleiber and Kotz [
4] and Kleiber [
5] furnished a detailed appraisal of the core of the Dagum model as well as its applications. Further, two reliability indices of the Dagum distribution can be considered as unknown parameters, namely, reliability function (RF)
and hazard rate function (HRF)
at distinct time
t which can be provided, respectively, by
and
The HRF of the Dagum distribution is either decreasing, upside-down, or a bathtub then upside-down bathtub. This appealing flexibility makes the HRF of the Dagum distribution meet appropriately even non-monotone HRF behaviors that are probable to be seen in a variety of domains. Different studies using the Dagum distribution have been achieved. Arif et al. [
6] investigated the Bayesian estimation based on the Markov chain Monte Carlo (MCMC) technique. Naqash et al. [
7] studied the Bayesian estimation of the scale parameter using different loss functions. Dey et al. [
8] addressed different frequentist estimation methods for the unknown parameters. Alotaibi et al. [
9] studied the Bayesian estimation using progressively type-I interval censored data. Kumari et al. [
10] studied the classical and Bayesian estimation of the stress strength reliability using progressively type-II censored data.
Various censoring plans are known in the literature, which can be categorized into single-stage and multistage censoring schemes. Single-stage censoring schemes include type-I, type-II, and hybrid censoring. On the other hand, the most popular multistage censoring scheme is the progressive type-II censoring in which
n units are placed on a test and
m is a prefixed number of items to be failed with prefixed progressive censoring plan
. At the time of the
failure
,
surviving units are randomly removed from the test. At the time of the last failure
, all the surviving units are removed. For further information about the progressive type-II censoring scheme, see Balakrishnan [
11]. Kundu and Joarder [
12] proposed a progressive type-I hybrid censoring scheme that has the same schematic representation as the progressive type-II censoring scheme but in this case, the test is stopped at
, where
T is a prefixed time.
The main drawback of this scheme is that the desired sample size is random and might turn out to be a very small number. As a consequence, the statistical deduction methods will be inadequate. To overpower this weakness, a more flexible censoring plan is proposed, namely an adaptive progressive type-II hybrid censoring (APT-II HC) scheme by Ng et al. [
13]. In the APT-II HC, the experiment time is allowed to run over the time
T and some values of
conceivably revised during the test. If
, the test stops at
and we will retain the standard progressive type-II censoring. Otherwise, if
, where
and
is the
failure time occur before time
T, then we will not remove any surviving units from the test by placing
, and at the time of the last failure
, all the remaining units are removed, i.e.,
. This adaption guarantees the ending of the test when we gather the desired number of failures
m, and the total test time will not be too outlying from the ideal time
T. Suppose that
are an observed APT-II HC sample from a continuous population with PDF
and CDF
, then the likelihood function can be expressed as follows
where
C is a constant that is independent of the parameters. Many works have been performed based on the APT-II HC scheme. Hemmati and Khorram [
14] addressed the estimation of the competing risks model for the exponential distribution. Al Sobhi and Soliman [
15] investigated the estimation issues of the exponentiated Weibull distribution. Nassar et al. [
16] studied the classical and Bayesian estimation methods for the Weibull distribution. Panahi and Moradi [
17] considered some estimations method for the inverted exponentiated Rayleigh distribution. Elshahhat and Nassar [
18] studied the Bayesian estimation for the Hjorth distribution. See also the work of Kohansal and Shoaee [
19], Panahi and Asadi [
20], Ahmad et al. [
21], Du and Gui [
22], Ateya et al. [
23], Alotaibi et al. [
24,
25], and Nassar et al. [
26]. Recently, Elshahhat and Nassar [
27] extended the APT-II HC scheme to binomial random removals.
We can motivate this study via (1) the significance of the APT-II HC scheme in increasing the efficiency of the statistical inference by avoiding getting small observed sample sizes. (2) The flexibility of the Dagum distribution in modeling different types of data sets with different HRF shapes including decreasing, upside-down, or a bathtub then an upside-down bathtub. As a result, we can list our objectives in this study as:
- (1)
To explore the maximum likelihood estimators (MLEs) of the unknown parameters including the reliability measures as well as the associated approximate confidence intervals (ACIs).
- (2)
To investigate the Bayes estimators and the highest posterior density (HPD) credible intervals. The Bayes estimators are acquired by using the MCMC method and by employing two loss functions, namely, squared error (SE) and general entropy (GE) loss functions.
- (3)
It is not possible to judge which procedure provides the best estimates theoretically. Therefore, an extensive simulation study is implemented to study the behavior of the different estimates and make the comparison achievable.
- (4)
To construct a guideline for picking the most appropriate estimation procedure for the Dagum distribution based on APT-II HC.
- (5)
To determine the optimal progressive sampling plane for APT-II HC scheme in the case of Dagum distribution.
- (6)
Because the applicability of the proposed methods is an important issue. The proposed methods are applied to investigate two real data sets.
The remainder of the paper is arranged as follows: The MLEs and ACIs are discussed in
Section 2. The Bayes estimators and HPD credible intervals are considered in
Section 3.
Section 4 displays the outcomes of the simulation study. In
Section 5, we provide various methods for choosing the best censoring plan.
Section 6 investigates two applications for real data. Finally,
Section 7 concludes the paper.
2. Frequentist Inference
Assume that
are an APT-II HC sample of size
m with
taken from the Dagum distribution with PDF and CDF given, respectively, by (
1) and (
2). In this case, one can derive the likelihood function based on (
1), (
2), and (
5), after ignoring the constant term, as follows
where
for simplicity of notation. Practically, it is more convenient to work with the log-likelihood function rather than the likelihood function itself. Therefore, by taking the natural logarithm of the likelihood function in (
6), the log-likelihood function can be written as
Let
and
denote MLEs of the unknown parameters
, and
, respectively. These estimators can be acquired by maximizing the objective function
with respect to
, and
. An alternative approach to obtain the needed estimators is by solving the following three normal equations simultaneously
and
where
. It is evident from the nonlinear equations in (
8)–(
10) that the MLEs of the unknown parameters
and
can not be obtained in explicit expressions. To overcome this problem, some numerical techniques can be implemented to obtain the MLEs in this case. Once the MLEs
, and
are obtained, we can utilize the invariance property of the MLEs to estimate the RF and HRF at a distinct time
t. Employing the invariance property, the MLEs of the RF and HRF can be obtained using (
3) and (
4) as follow
Aside from obtaining the point estimates of the unknown parameters
, and
, it is also of interest to obtain the confidence intervals for these parameters. Here, we utilize the asymptotic properties of the MLEs to construct the ACIs of the unknown parameters as well as the reliability measures. It is known that based on the theory of large samples the asymptotic distribution of
, where
is the MLE of
, is normal distribution with mean
and variance–covariance matrix
. Due to the complicated expressions of the Fisher information matrix, it is not easy to obtain such a variance–covariance matrix. In this case, we can consider
to estimate
, which can be acquired using the observed Fisher information matrix and given by
where
and
where
Presently, the
ACIs of
, and
can be obtained as follows
where
, and
are the values obtained from (
11), respectively, and
is the upper
percentile point of the standard normal distribution.
In addition to this, to construct the ACIs of the RF and HRF we need to obtain the variance of their estimators
and
. One of the most popular ways to approximate these variances is to apply the so-called delta method; see Greene [
28] for more details. For example, to approximate the variance of
, the delta method stated that, under some regularity conditions, the distribution of the statistics
can be approximated by the normal distribution with mean
and variance
, where
with the following elements
Thus, one can obtain the approximate estimate of variance of
as
, which is evaluated at the MLEs
, and
. Similarly, we can acquire the approximate estimate of variance of
. Let
, where
and
Hence, we can obtain the approximate estimate of variance of
as
, which is evaluated at the MLEs of the unknown parameters. Using the mentioned results, the two-sided ACIs for
and
at the confidence level
are expressed, respectively, as
3. Bayesian Inference
This section derives the Bayesian estimators for the unknown parameters
, and
, as well as the
and
. In addition to the point estimates, the HPD credible intervals are studied. In the statistical investigation, the Bayesian technique has influential benefits over the maximum likelihood method because it delivers a natural path of combining prior information about the unknown parameters with new data within a solid theoretical framework.. The Bayesian technique is particularly usable in dependability studies and numerous other disciplines where data availability is a key barrier. This analysis explores the Bayesian estimation beneath the premise that the unknown parameters are independent and have gamma distributions, i.e.,
,
, and
. Based on these assumptions, the joint prior distribution of
, and
can be expressed as
where
and
, are the hyper-parameters and are always greater than zero. Combining the sample information provided by the likelihood function with the prior knowledge about the unknown parameters presented through the joint prior distribution and by applying the Bayes theorem, one can derive the posterior distribution of the unknown parameters
, and
. Therefore, from (
6) and (
12), the joint posterior distribution of
and
takes the form
where
and
A is the normalized constant. The loss function plays a critical role in Bayesian estimation because it can be used to identify overestimation and underestimation in the investigation. Here, we take into account the SE and GE loss functions. The SE loss function is one of the most often used symmetric loss functions, whereas the GE loss function is asymmetric. It is well known that the Bayes estimator in the case of the SE loss function is the posterior mean where the overestimation and underestimation are treated equally. Conversely, the GE loss function delivers diverse importance for overestimation and underestimation. The GE loss function introduced by Calabria and Pulcini [
29] and defined as
where
is the estimator of
and
is a parameter that determines the degree of asymmetry. The Bayes estimator of
using GE loss function is given by
provided that
exists and is finite.
It can be seen that when
, the Bayes estimator in (
14) coincides with the Bayes estimator under the SE loss function. Now, let
any function of the unknown parameters, then the Bayes estimators based on the SE and GE loss functions can be obtained directly from (
13), respectively, as follow
and
Clearly, calculating the Bayes estimators using (
15) and (
16) analytically are unattainable. As a result, we advocate employing the MCMC technique to obtain the Bayes estimates of
, and
and the associated HPD credible intervals. To apply the MCMC technique, we should first derive the full conditional distributions of
, and
. The required full conditional distributions can be given from (
13) as follow
and
Nevertheless, it is noticeable that the full conditional posterior distributions of
, and
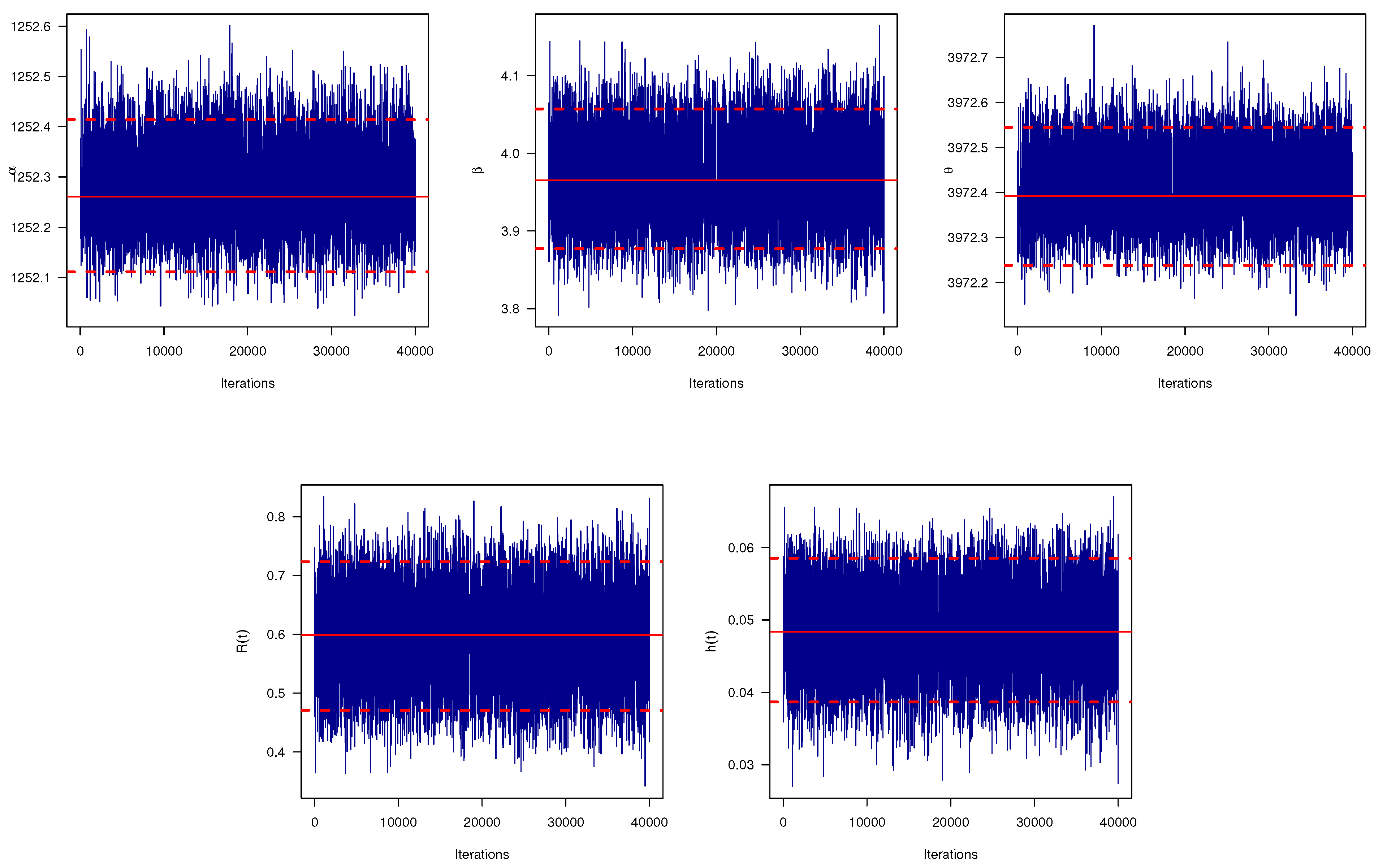
cannot be tended analytically to famous distributions. Consequently, it is not probable to generate samples straight by traditional techniques, whereas the plots of them indicate that they are equivalent to normal distribution. So, we need to induce the unknown parameters by employing Metropolis-–Hasting (MH) sampling. To involve the MH sampling, we assume the normal distribution as the proposal distribution to acquire the Bayesian estimates and to obtain the HPD credible intervals. The MH sampling functions as follows to generate samples from (
17)–(
19)
- Step 1.
Put .
- Step 2.
Set
- Step 3.
Generate
from the full conditional posterior distribution (
17) using normal distribution, i.e.,
, and by applying the MH steps.
- Step 4.
Repeat step 3 to generate
and
from (
18) and (
19), respectively.
- Step 5.
Use the generated sample to compute
and
from (
3) and (
4), respectively.
- Step 6.
Set .
- Step 7.
Redo steps 3–6,
B times to obtain
To assure convergence and to withdraw the affection of the choice of starting values, the first
Q generated variates are scrapped. In this case, we have
, and
. Based on large
B, the generated sample forms an approximate posterior sample which can be employed to obtain the Bayes estimates and the HPD credible intervals. Now, let
be the unknown parameter to be estimated. Then, the Bayes estimate of
based on the SE loss function can be obtained as
Similarly, the Bayes estimate of
based on the GE loss function can be computed as follows
On the other hand, to compute the HPD credible intervals of
,
,
and
, say
, we order
, as
. Then, the
two-sided HPD credible interval of
becomes
, where
is specified such that
where
denotes the largest integer less than or equal to
. It is noteworthy to mention here that the results of Arif et al. [
6] can be obtained as a special case of the results derived in this paper when
, with
, which is the complete sample case.
5. Optimal Progressive Censoring Plan
Choosing the optimal censoring plans has earned a lot of awareness in the statistical literature. For specified
n and
m, probable censoring schemes refer to all
mixtures such that
and picking the most suitable sample technique entails locating the progressive censoring scheme that delivers the most knowledge regarding the unknown parameters among all possible progressive censoring plans. For more details about optimal censoring plans, one can refer to Ng et al. [
33] and Pradhan and Kundu [
34]. In this study, we consider four optimality criteria that were widely used in the literature. Practically and as we mentioned before that we need to select the censoring scheme that provides us with the most information about the parameters.
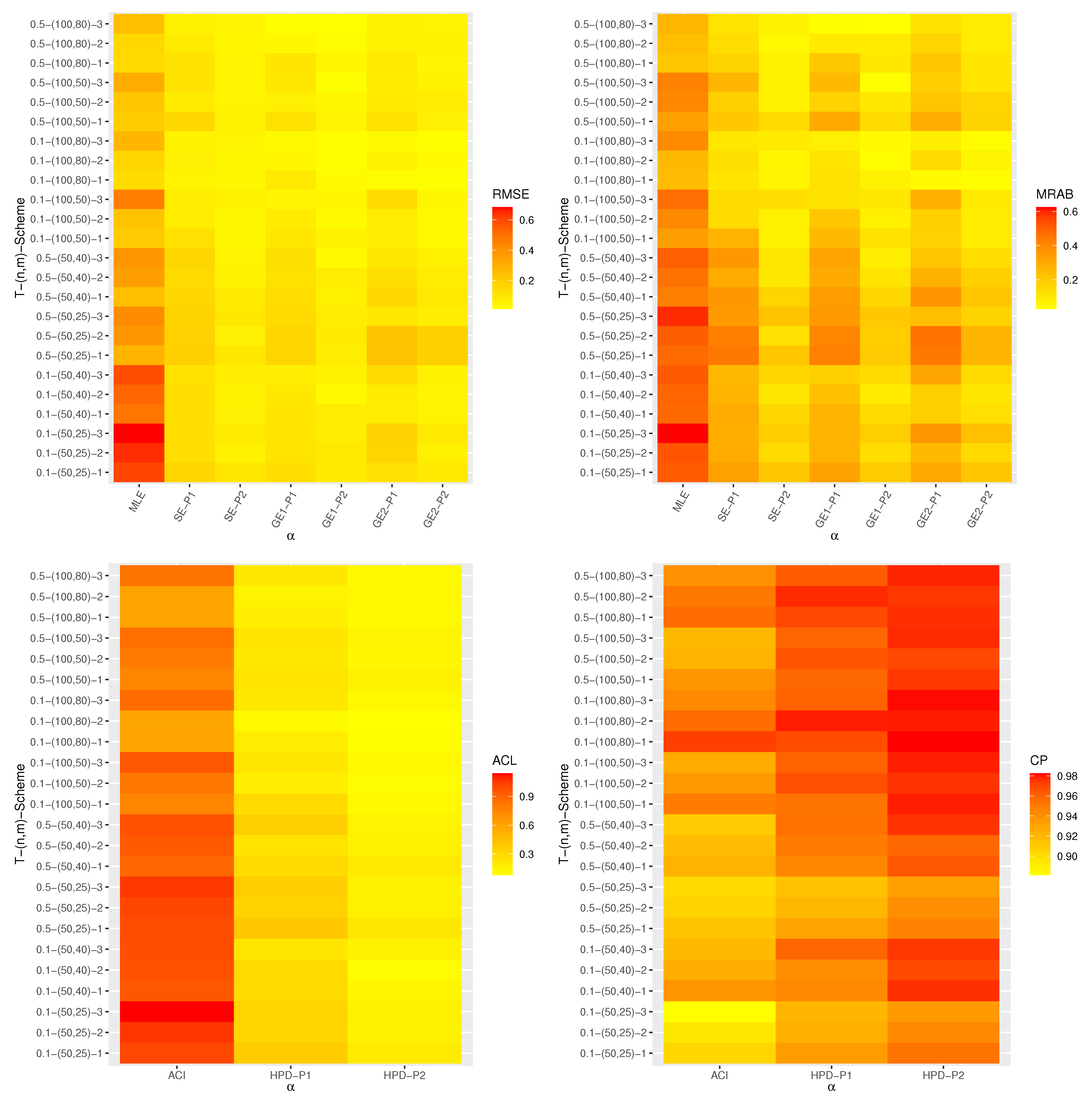
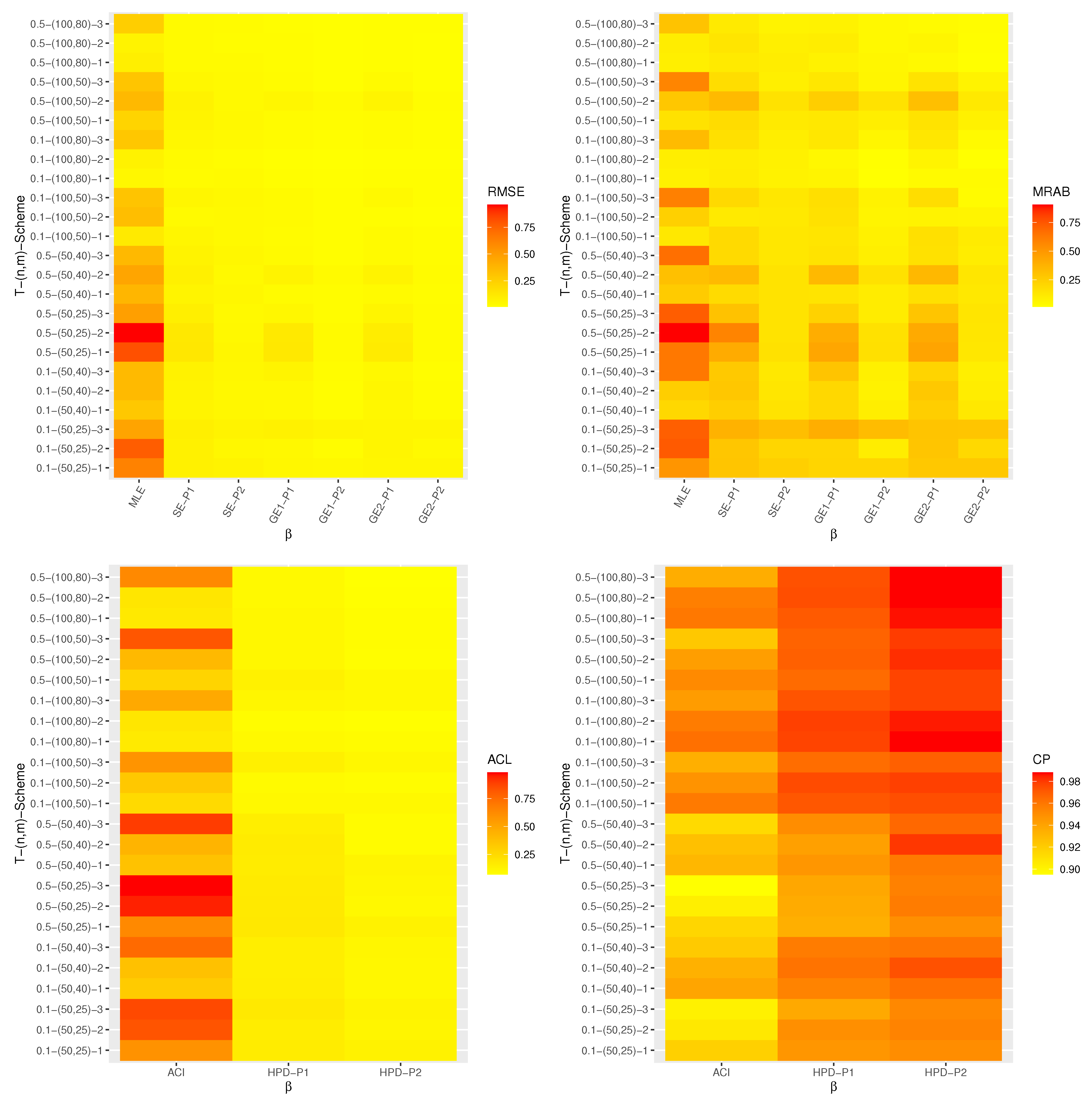
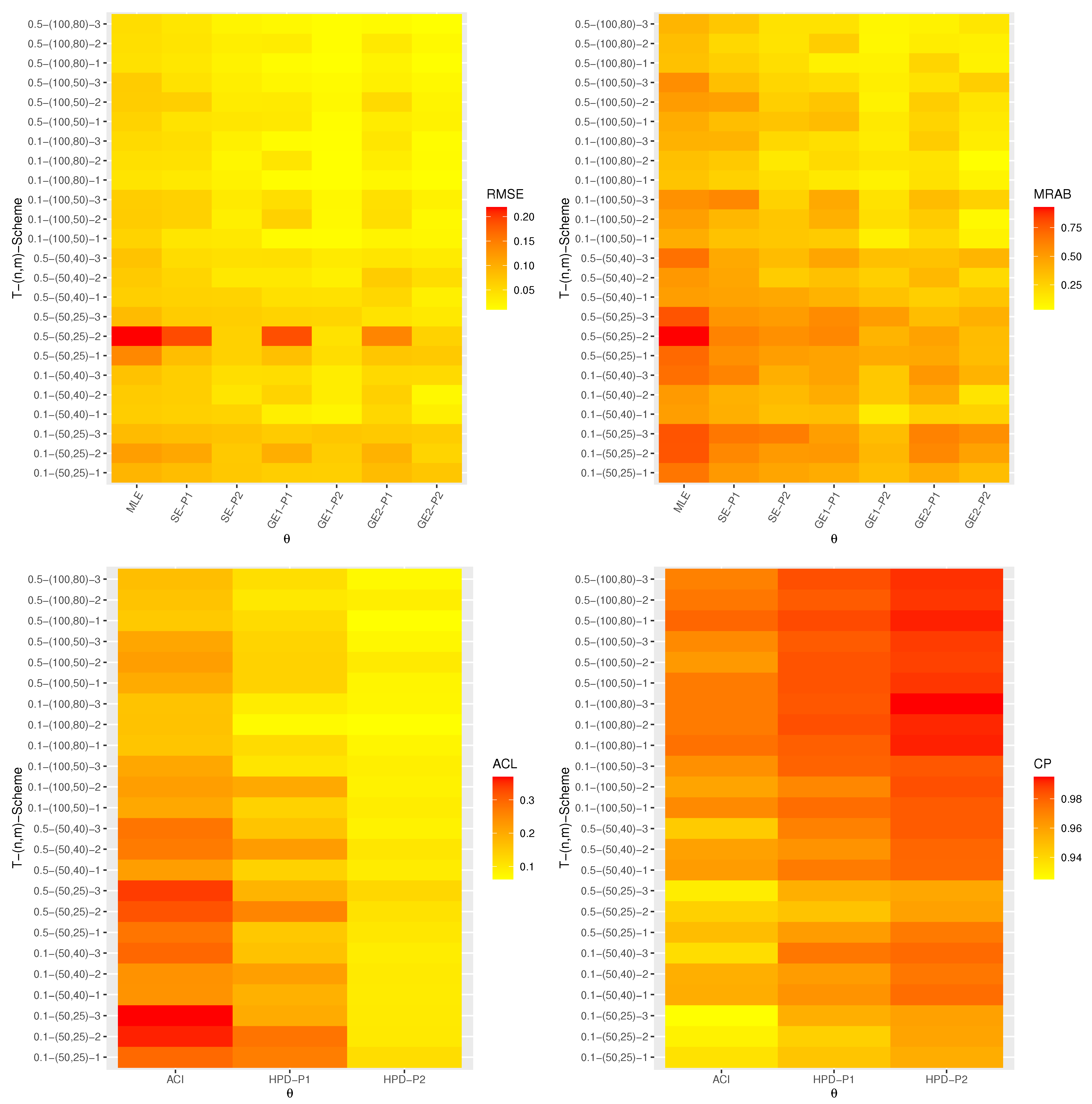
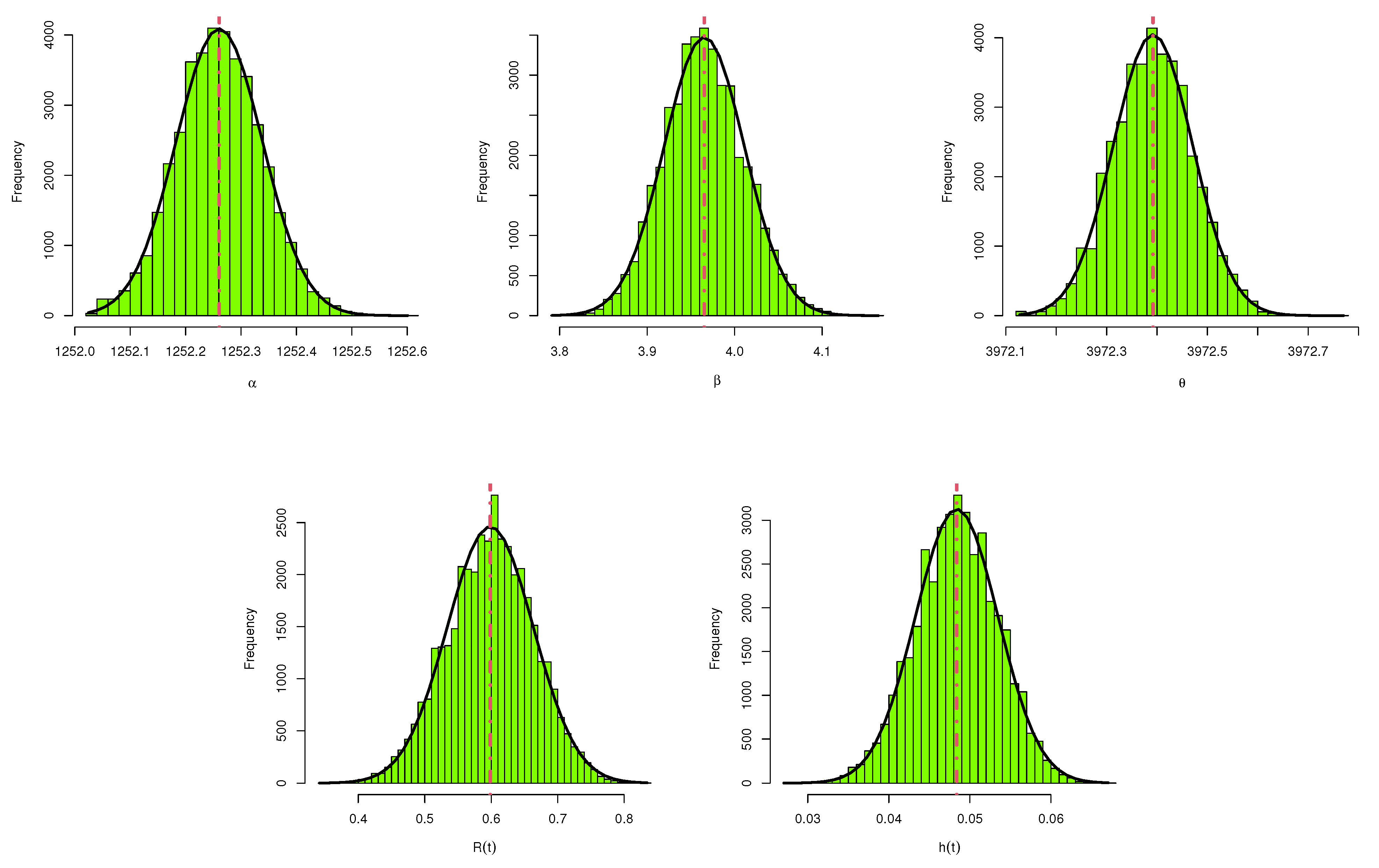
Table 1 furnishes some typically employed optimal criteria to aid us in choosing the most suitable progressive censoring scheme.
One can see from
Table 1 that the criteria I, II, and III are looking for the progressive censoring scheme that maximize the observed Fisher information matrix, minimize the determinant of
, and minimize the trace of
, respectively. On the other hand, the criterion IV tries to minimize the variance of logarithmic MLE of the
quantile, denoted by
, where
where the delta method can be used to approximate the variance of
. To pick the optimal progressive censoring plan, one should select the progressive censoring plan that gives the maximum value of criterion I and the smallest values of criteria II, III, and IV.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}