

Co-Saliency Detection of RGBD Image Based on Superpixel and Hypergraph
Abstract
:1. Introduction
- (1)
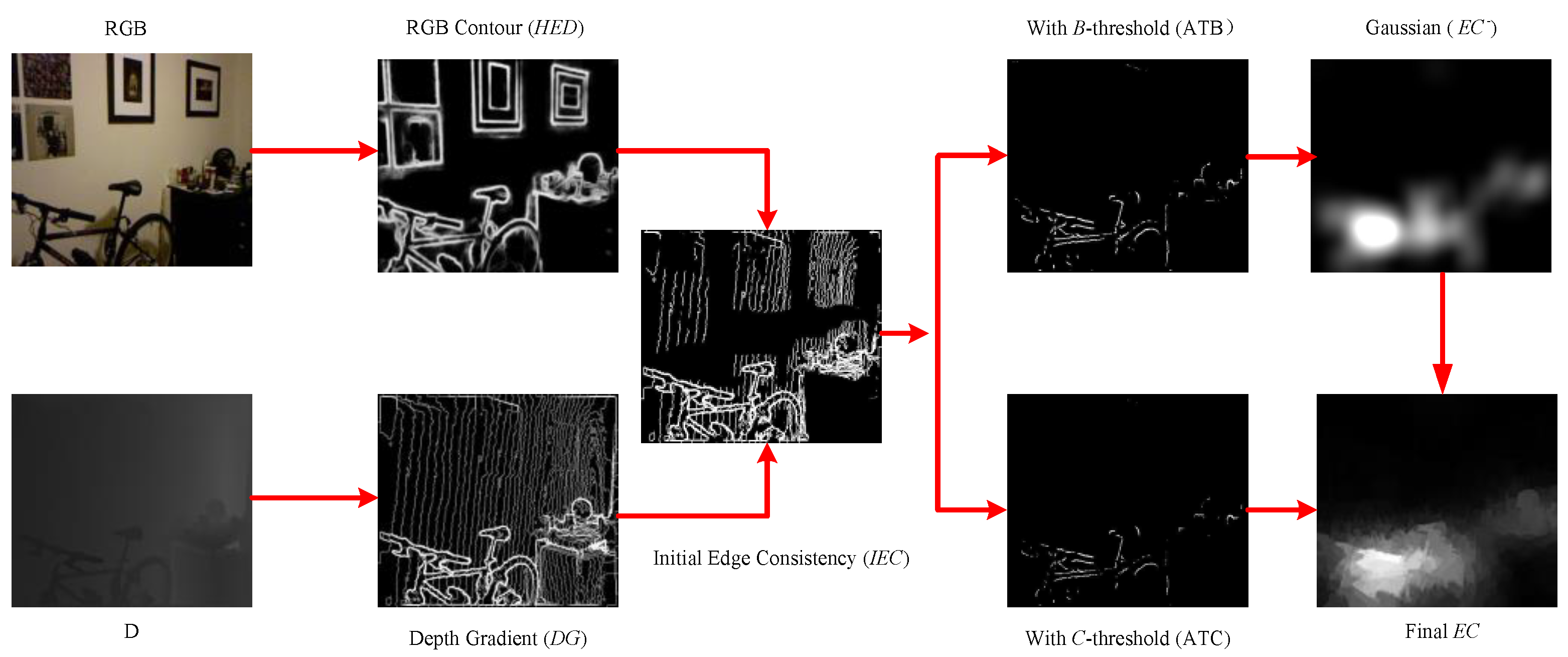
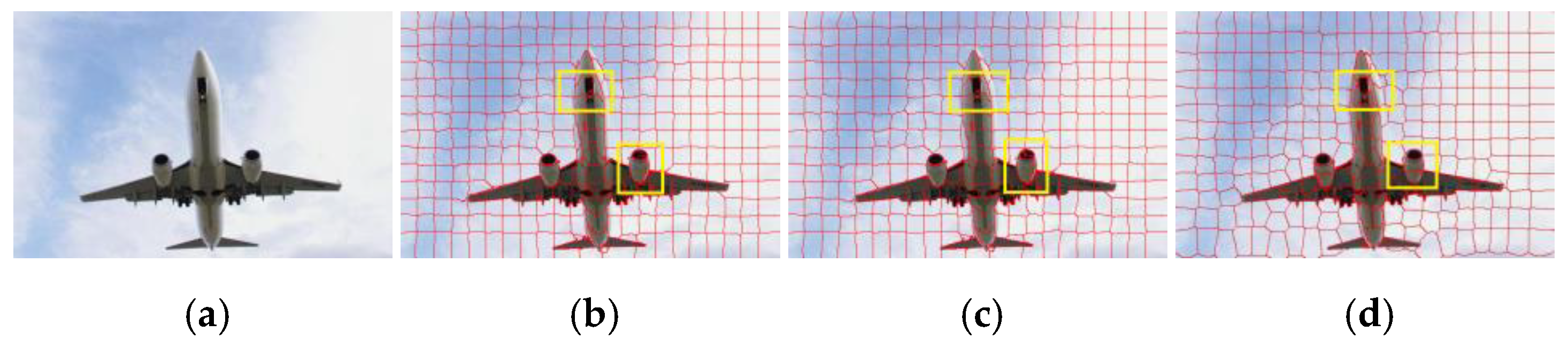
- A fusion depth–quality RGBD image superpixel segmentation was proposed. We optimized the depth map based on the edge consistency between the RGB contour map and the depth gradient map, and clustered adjacent pixels to generate superpixels by integrating the color information, pixel position information and optimized depth information.
- (2)
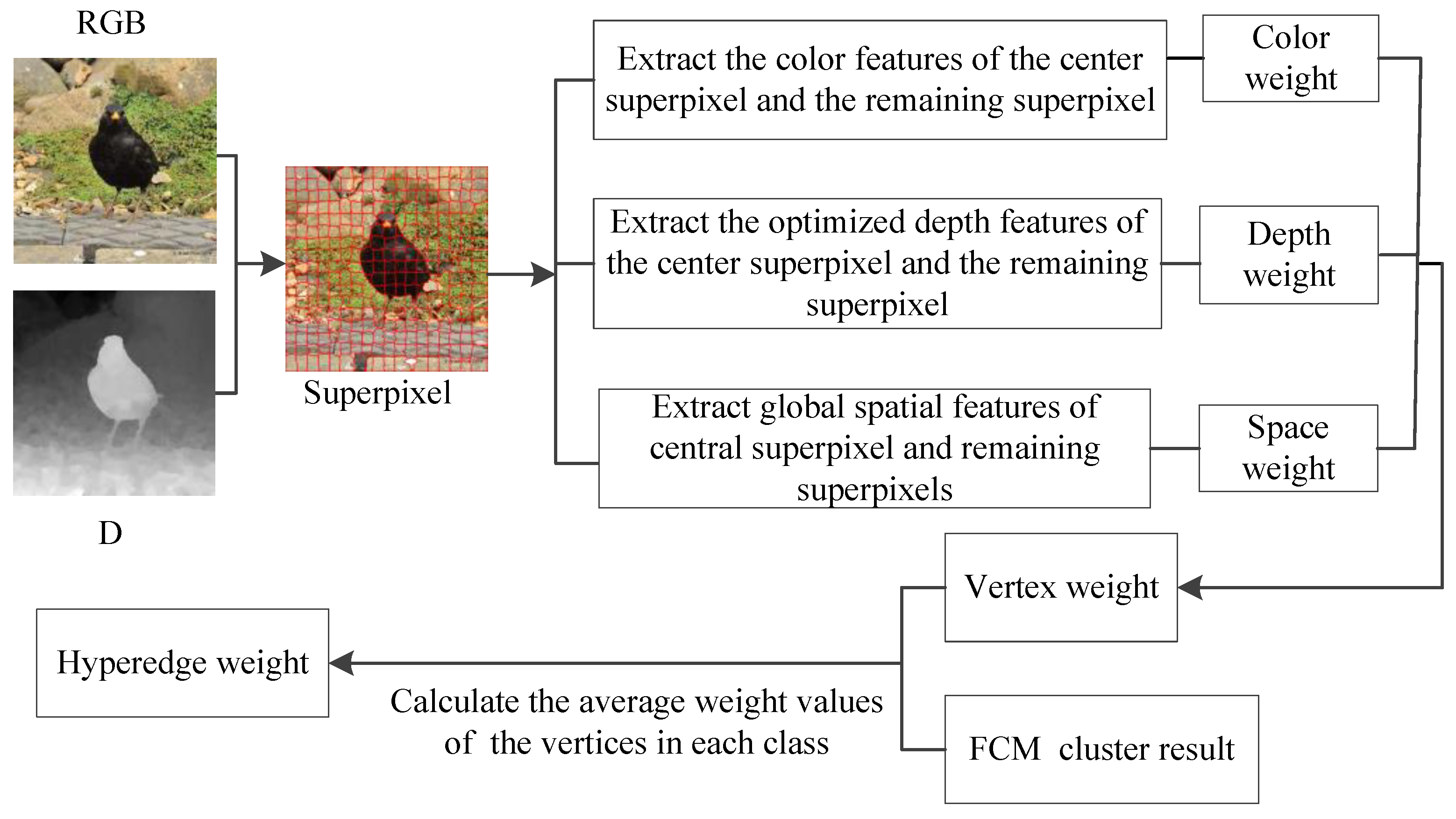
- A weighted hypergraph model for saliency detection was proposed. The general hypergraph model was established by using a Fuzzy C-Means (FCM) clustering algorithm. The number of categories in the clustering result was the edge of the hypergraph, and the number of superpixels in each category was the vertex of the hypergraph. Then, the weighted hypergraph model was constructed by using global spatial feature similarity, color feature similarity and optimized depth feature similarity.
- (3)
- We proposed a novel weighted hypergraph model for co-saliency detection. The general hypergraph model was established by using the FCM clustering algorithm, and then the weighted hypergraph model was constructed by using the relationships of color features, global spatial features, optimized depth features and saliency features among images.
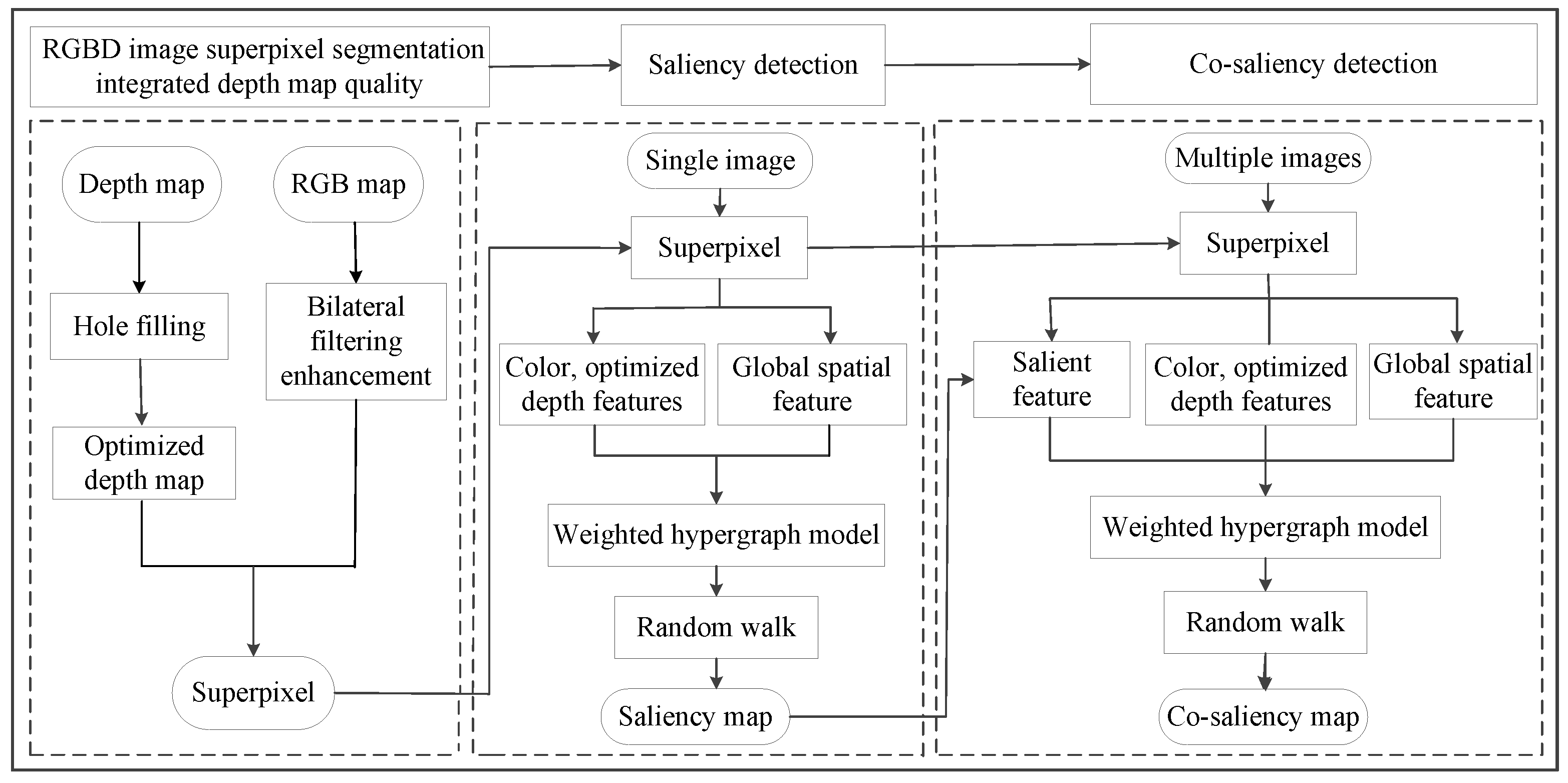
2. Materials and Methods
2.1. Fusion Depth–Quality RGBD Image Superpixel Segmentation
2.2. RGBD Image Saliency Detection Based on Superpixel and Hypergraph
2.2.1. Similarity of Color Feature
2.2.2. Similarity of Depth Feature
2.2.3. Global Spatial Feature Similarity
2.2.4. A Weighted Hypergraph Model Was Constructed for Saliency Detection
2.3. RGBD Image Co-Saliency Detection Based on Superpixel and Hypergraph
2.3.1. Vertex Weight
2.3.2. Hyperedge Weight
3. Experimental Results
3.1. Dataset and Evaluation Metrics
3.2. Visual Comparison with Different Methods
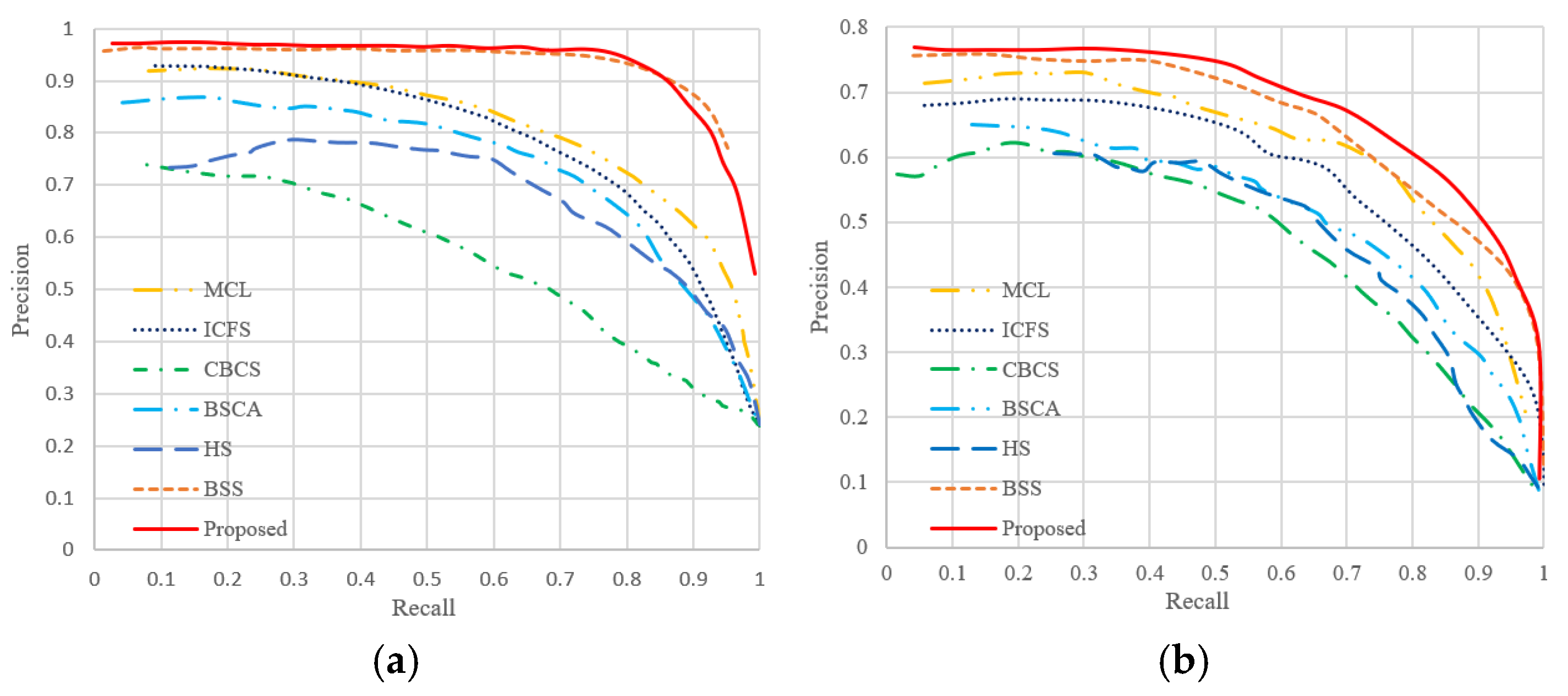
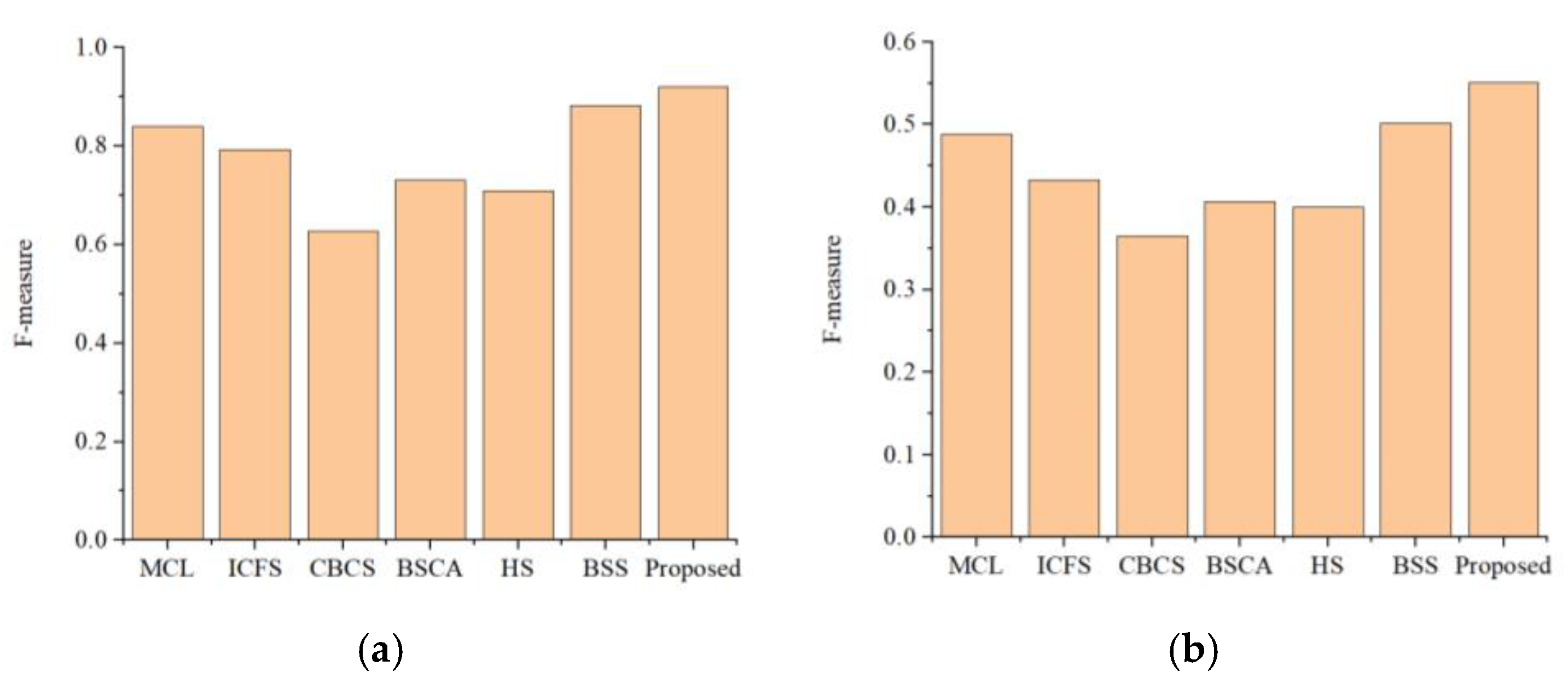
3.3. Quantitative Comparison with Different Methods
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nie, G.Y.; Cheng, M.M.; Liu, Y.; Liang, Z.; Fan, D.P.; Liu, Y.; Wang, Y. Multi-level context ultra-aggregation for stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3283–3291. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L. Joint learning of saliency detection and weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 7223–7233. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for polyp segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2020; pp. 263–273. [Google Scholar]
- Fan, D.P.; Wang, W.; Cheng, M.M.; Shen, J. Shifting more attention to video salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8554–8564. [Google Scholar]
- Song, H.; Wang, W.; Zhao, S.; Shen, J.; Lam, K.M. Pyramid dilated deeper convlstm for video salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 715–731. [Google Scholar]
- Gu, K.; Wang, S.; Yang, H.; Lin, W.; Zhai, G.; Yang, X.; Zhang, W. Saliency-guided quality assessment of screen content images. IEEE Trans. Multimed. 2016, 18, 1098–1110. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient graph-based image segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. Turbopixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Agoes, A.S.; Hu, Z.; Matsunaga, N. DSLIC: A superpixel based segmentation algorithm for depth image. In Proceedings of the Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 77–87. [Google Scholar]
- Li, X.; Wan, L.; Li, H.; Wang, S. RGBD image co-segmentation via saliency detection and graph cut. J. Syst. Simul. 2018, 30, 2558. [Google Scholar]
- Shi, J.; Yan, Q.; Xu, L.; Jia, J. Hierarchical image saliency detection on extended CSSD. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 717–729. [Google Scholar] [CrossRef]
- Li, X.; Song, D.; Dong, Y. Hierarchical feature fusion network for salient object detection. IEEE Trans. Image Process. 2020, 29, 9165–9175. [Google Scholar] [CrossRef]
- Abouelregal, A.E.; Marin, M. The size-dependent thermoelastic vibrations of nanobeams subjected to harmonic excitation and rectified sine wave heating. Mathematics 2020, 8, 1128. [Google Scholar] [CrossRef]
- Zhang, L.; Bhatti, M.; Michaelides, E.E.; Marin, M.; Ellahi, R. Hybrid nanofluid flow towards an elastic surface with tantalum and nickel nanoparticles, under the influence of an induced magnetic field. Eur. Phys. J. Spec. Top. 2022, 231, 521–533. [Google Scholar] [CrossRef]
- Qin, Y.; Lu, H.; Xu, Y.; Wang, H. Saliency detection via cellular automata. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 110–119. [Google Scholar]
- Li, H.; Lu, H.; Lin, Z.; Shen, X.; Price, B. Inner and inter label propagation: Salient object detection in the wild. IEEE Trans. Image Process. 2015, 24, 3176–3186. [Google Scholar] [CrossRef] [Green Version]
- Ji, Y.; Zhang, H.; Tseng, K.K.; Chow, T.W.; Wu, Q.J. Graph model-based salient object detection using objectness and multiple saliency cues. Neurocomputing 2019, 323, 188–202. [Google Scholar] [CrossRef]
- Lu, Y.; Zhou, K.; Wu, X.; Gong, P. A novel multi-graph framework for salient object detection. Vis. Comput. 2019, 35, 1683–1699. [Google Scholar] [CrossRef]
- Li, X.; Li, Y.; Shen, C.; Dick, A.; Van Den Hengel, A. Contextual hypergraph modeling for salient object detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3328–3335. [Google Scholar]
- Han, F.; Han, A.; Hao, J. Saliency detection method using hypergraphs on adaptive multiscales. IEEE Access 2018, 6, 29444–29451. [Google Scholar] [CrossRef]
- Zhang, J.; Fang, S.; Ehinger, K.A.; Wei, H.; Yang, W.; Zhang, K.; Yang, J. Hypergraph optimization for salient region detection based on foreground and background queries. IEEE Access 2018, 6, 26729–26741. [Google Scholar] [CrossRef]
- Chen, B.; Yang, J.; Jeon, B.; Zhang, X. Kernel quaternion principal component analysis and its application in RGB-D object recognition. Neurocomputing 2017, 266, 293–303. [Google Scholar] [CrossRef]
- Huang, R.; Xing, Y.; Zou, Y. Triple-complementary network for RGB-D salient object detection. IEEE Signal Process. Lett. 2020, 27, 775–779. [Google Scholar] [CrossRef]
- Chen, C.; Wei, J.; Peng, C.; Zhang, W.; Qin, H. Improved saliency detection in RGB-D images using two-phase depth estimation and selective deep fusion. IEEE Trans. Image Process. 2020, 29, 4296–4307. [Google Scholar] [CrossRef]
- Huang, Z.; Chen, H.X.; Zhou, T.; Yang, Y.Z.; Liu, B.Y. Multi-level cross-modal interaction network for RGB-D salient object detection. Neurocomputing 2021, 452, 200–211. [Google Scholar] [CrossRef]
- Wang, X.; Li, S.; Chen, C.; Hao, A.; Qin, H. Depth quality-aware selective saliency fusion for RGB-D image salient object detection. Neurocomputing 2021, 432, 44–56. [Google Scholar] [CrossRef]
- Liu, Z.; Zou, W.; Li, L.; Shen, L.; Le Meur, O. Co-saliency detection based on hierarchical segmentation. IEEE Signal Process. Lett. 2013, 21, 88–92. [Google Scholar] [CrossRef] [Green Version]
- Jiang, R.; Crookes, D. Deep salience: Visual salience modeling via deep belief propagation. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Lee, M.; Park, C.; Cho, S.; Lee, S. Superpixel Group-Correlation Network for Co-Saliency Detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), IEEE, Bordeaux, France, 16–19 October 2022; pp. 806–810. [Google Scholar]
- Tan, Z.; Gu, X. Co-saliency detection with intra-group two-stage group semantics propagation and inter-group contrastive learning. Knowl.-Based Syst. 2022, 252, 109356. [Google Scholar] [CrossRef]
- Zhang, D.; Han, J.; Li, C.; Wang, J. Co-saliency detection via looking deep and wide. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2994–3002. [Google Scholar]
- Fu, H.; Cao, X.; Tu, Z. Cluster-based co-saliency detection. IEEE Trans. Image Process. 2013, 22, 3766–3778. [Google Scholar] [CrossRef] [Green Version]
- Cong, R.; Lei, J.; Fu, H.; Lin, W.; Huang, Q.; Cao, X.; Hou, C. An iterative co-saliency framework for RGBD images. IEEE Trans. Cybern. 2017, 49, 233–246. [Google Scholar] [CrossRef] [Green Version]
- Cong, R.; Lei, J.; Fu, H.; Huang, Q.; Cao, X.; Hou, C. Co-saliency detection for RGBD images based on multi-constraint feature matching and cross label propagation. IEEE Trans. Image Process. 2017, 27, 568–579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Liu, J.; Zhao, P. RGBD Image Co-saliency Object Detection Based on Sample Selection. Electron. Inf. Technol. 2020, 42, 2277–2284. [Google Scholar]
- Zhang, Y.; Ding, L.; Sharma, G. Local-linear-fitting-based matting for joint hole filling and depth upsampling of RGB-D images. J. Electron. Imaging 2019, 28, 033019. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Sasaki, T.; Fukushima, N.; Maeda, Y.; Sugimoto, K.; Kamata, S.I. Constant-time gaussian filtering for acceleration of structure similarity. In Proceedings of the 2020 International Conference on Image Processing and Robotics (ICIP), IEEE, Negombo, Sri Lanka, 6–8 March 2020; pp. 1–6. [Google Scholar]
- Chen, C.; Li, S.; Wang, Y.; Qin, H.; Hao, A. Video saliency detection via spatial-temporal fusion and low-rank coherency diffusion. IEEE Trans. Image Process. 2017, 26, 3156–3170. [Google Scholar] [CrossRef]
- Wei, W.; Chen, H. Salient object detection based on weighted hypergraph and random walk. Math. Probl. Eng. 2020, 2020, 2073140. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cosal150 Dataset | Coseg183 Dataset | |
|---|---|---|
| MCL | 0.137 | 0.098 |
| ICFS | 0.179 | 0.163 |
| CBCS | 0.215 | 0.116 |
| BSS | 0.089 | 0.081 |
| Proposed | 0.147 | 0.079 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, W.; Chen, W.; Xu, M. Co-Saliency Detection of RGBD Image Based on Superpixel and Hypergraph. Symmetry 2022, 14, 2393. https://doi.org/10.3390/sym14112393
Wei W, Chen W, Xu M. Co-Saliency Detection of RGBD Image Based on Superpixel and Hypergraph. Symmetry. 2022; 14(11):2393. https://doi.org/10.3390/sym14112393
Chicago/Turabian StyleWei, Weiyi, Wenxia Chen, and Mengyu Xu. 2022. "Co-Saliency Detection of RGBD Image Based on Superpixel and Hypergraph" Symmetry 14, no. 11: 2393. https://doi.org/10.3390/sym14112393
APA StyleWei, W., Chen, W., & Xu, M. (2022). Co-Saliency Detection of RGBD Image Based on Superpixel and Hypergraph. Symmetry, 14(11), 2393. https://doi.org/10.3390/sym14112393