
Human Decision Time in Uncertain Binary Choice


Abstract
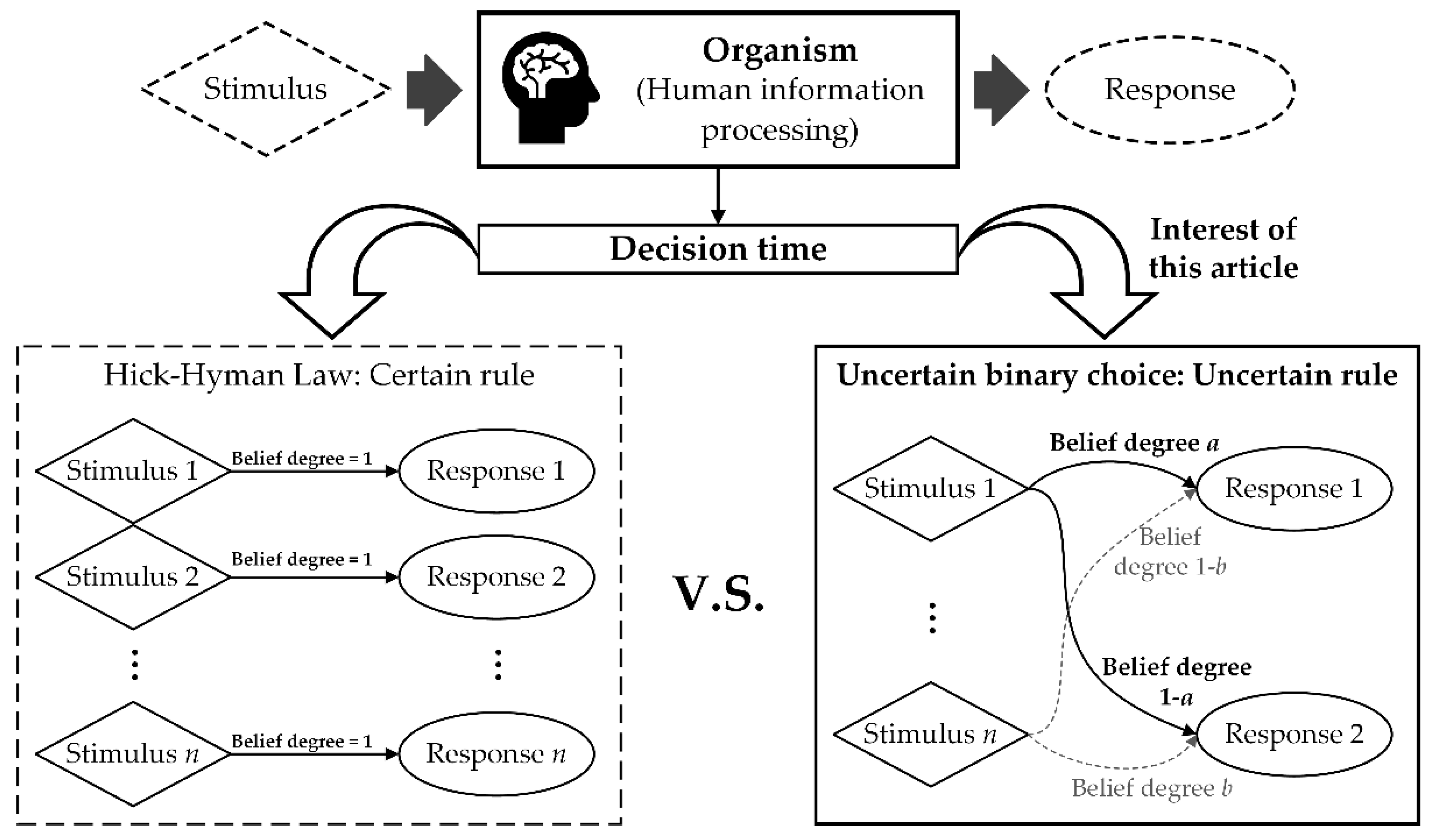
:1. Introduction
2. Preliminaries
2.1. Hick–Hyman Law
2.2. Uncertainty Theory and Uncertain Regression Analysis
3. Methods
3.1. Experiment 1: Hick–Hyman Law
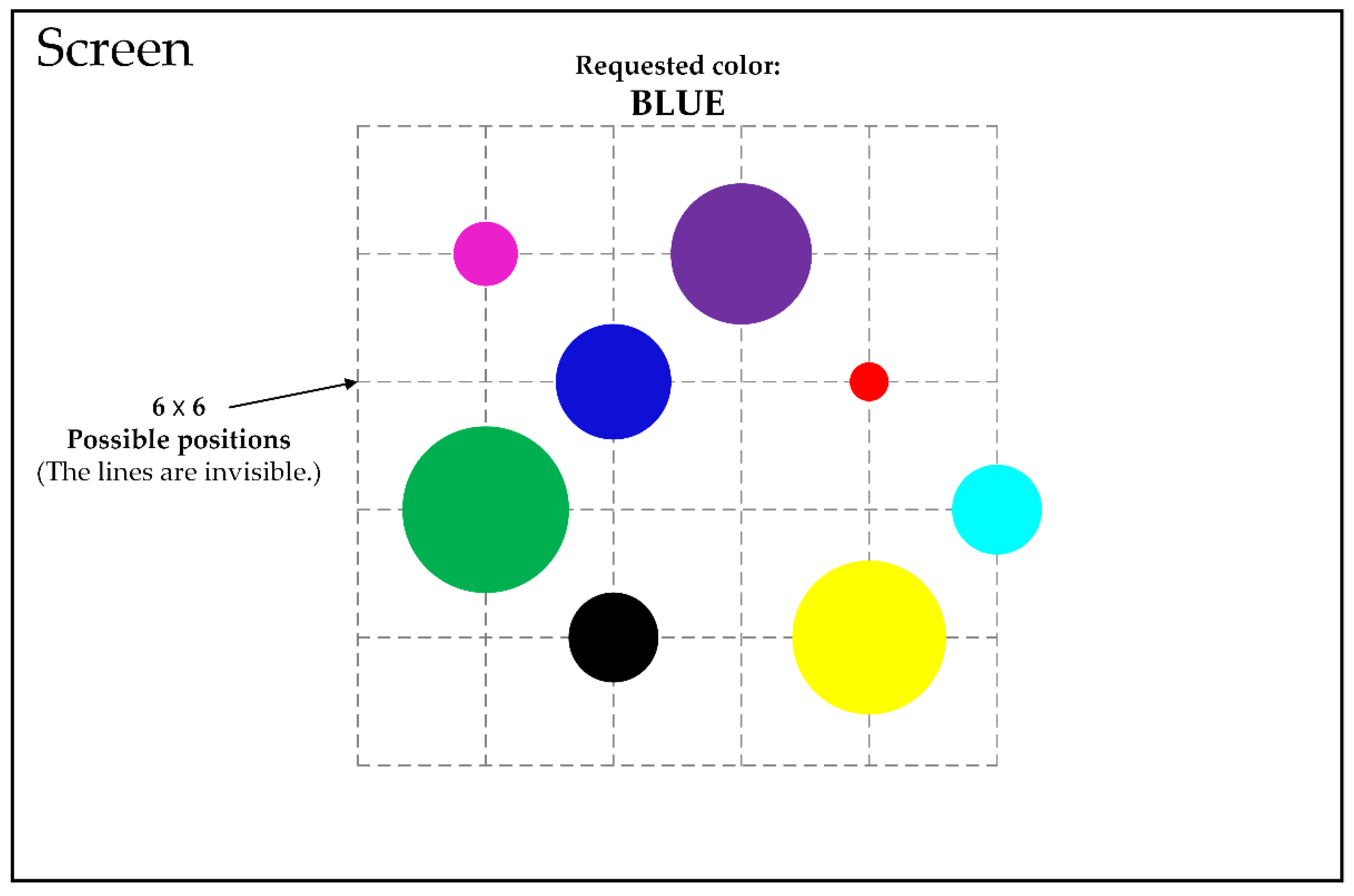
3.1.1. Apparatus and Participants
3.1.2. Procedure
3.2. Experiment 2: Uncertain Binary Choice
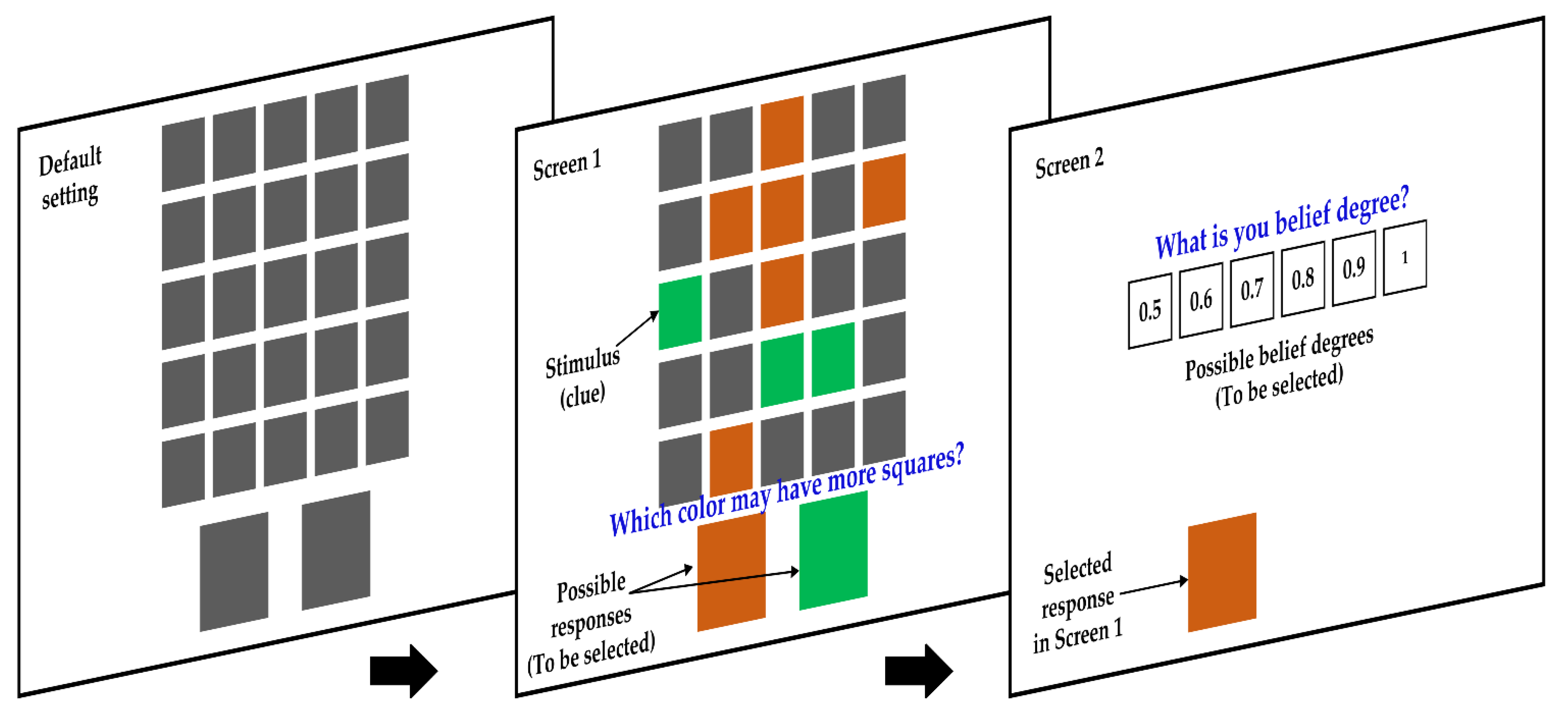
3.2.1. Apparatus and Participants
3.2.2. Procedure
4. Results
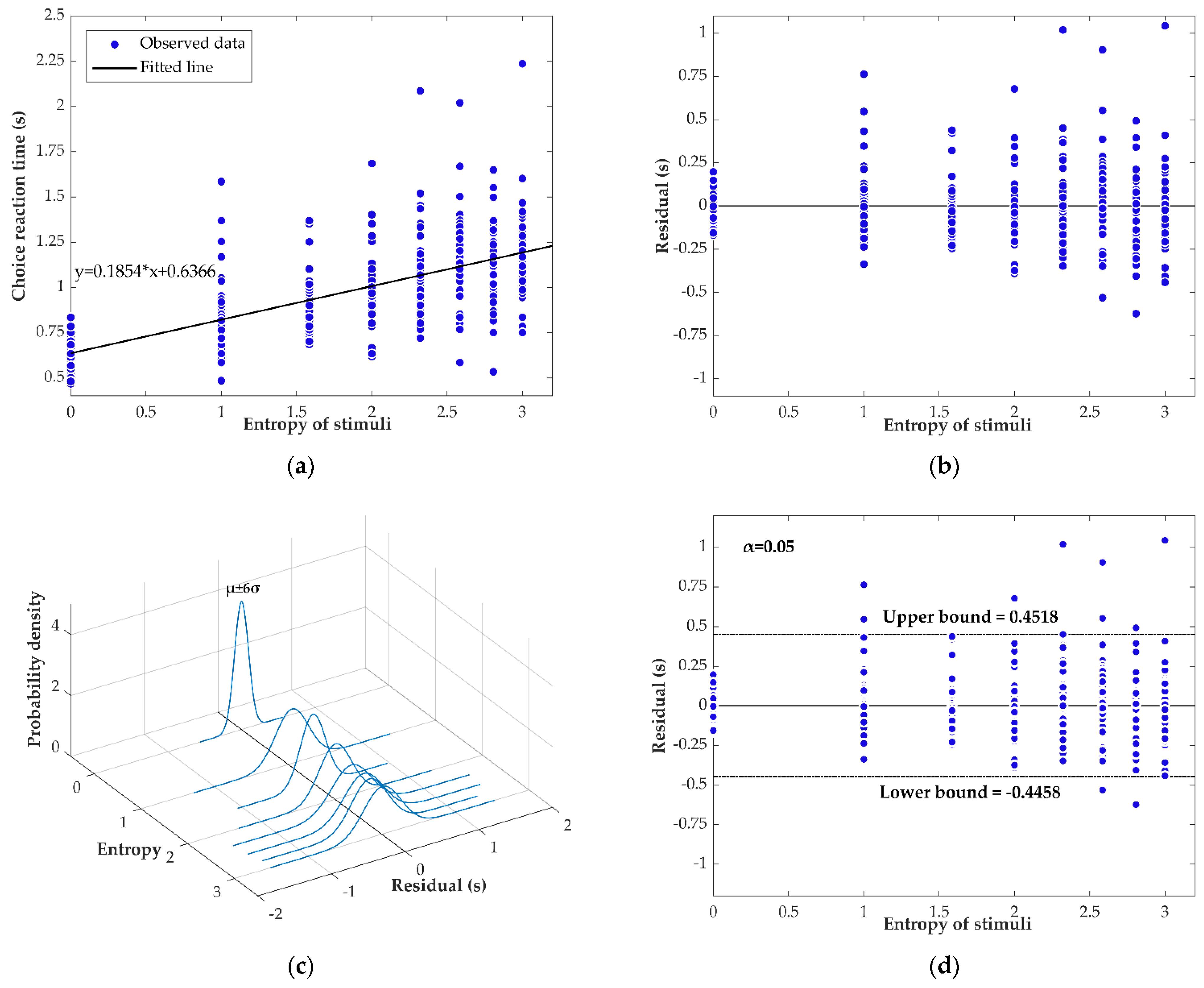
4.1. Experiment 1
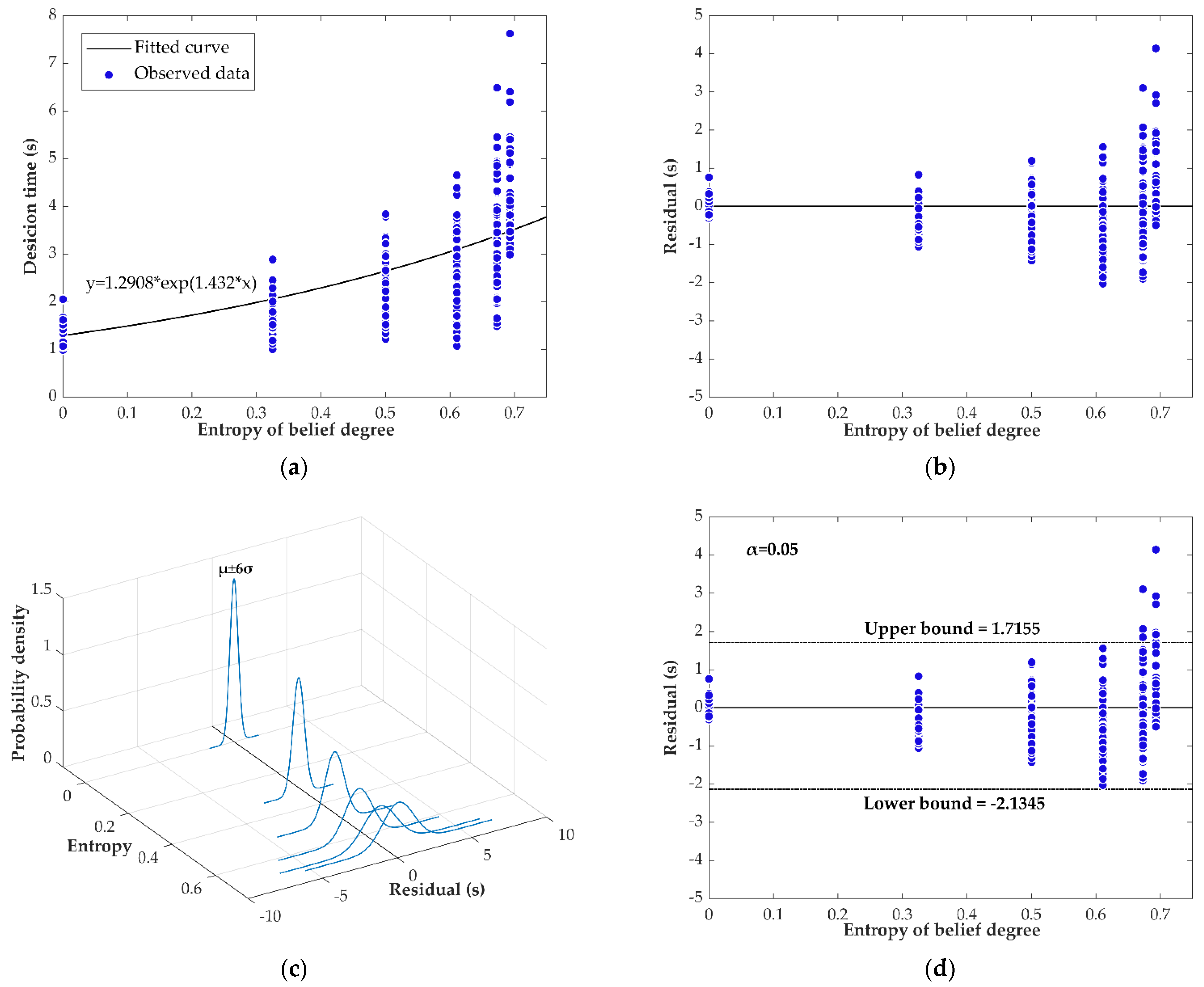
4.2. Experiment 2
5. Discussion
6. Conclusions
- (1)
- Two experiments were designed and conducted: one for verifying the HHL and the other for exploring uncertain binary choice.
- (2)
- In the experiment of uncertain binary choice, uncertainty theory was used to express subjects’ belief degrees, and correspondingly, the difficulty of choice was evaluated by the entropy defined in uncertainty theory.
- (3)
- The advantage of entropy of uncertainty theory is well reflected by its property of symmetry that replaces the original guessing question of uncertain binary choice because its complementary question does not essentially change the difficulty of choice.
- (4)
- The main finding of this work is that there is an exponential relationship existing between decision time and entropy of belief degree in uncertain binary choice. Based on this, we also provided a reasonable model for evaluating human decision time in more general cases.
- (5)
- Data obtained from both experiments showed that the disturbance term of decision time should not be seen as probabilistic as existing studies have assumed, which highlighted the necessity and advantage of uncertain regression analysis.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wickens, C.D.; Hollands, J.G.; Banbury, S.; Parasuraman, R. Engineering Psychology and Human Performance, 4th ed.; Pearson Education, Inc.: Hoboken, NJ, USA, 2012; ISBN 978-0-205-02198-7. [Google Scholar]
- Hick, W.E. On the rate of gain of information. Q. J. Exp. Psychol. 1952, 4, 11–26. [Google Scholar] [CrossRef]
- Hyman, R. Stimulus information as a determinant of reaction time. J. Exp. Psychol. 1953, 45, 188–196. [Google Scholar] [CrossRef] [Green Version]
- Mordkoff, J.T. Effects of average uncertainty and trial-type frequency on choice response time: A hierarchical extension of Hick/Hyman Law. Psychon. Bull. Rev. 2017, 24, 2012–2020. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wifall, T.; Hazeltine, E.; Toby Mordkoff, J. The roles of stimulus and response uncertainty in forced-choice performance: An amendment to Hick/Hyman Law. Psychol. Res. 2016, 80, 555–565. [Google Scholar] [CrossRef]
- Dildine, T.C.; Necka, E.A.; Atlas, L.Y. Confidence in subjective pain is predicted by reaction time during decision making. Sci. Rep. 2020, 10, 21373. [Google Scholar] [CrossRef]
- Hanks, T.D.; Mazurek, M.E.; Kiani, R.; Hopp, E.; Shadlen, M.N. Elapsed decision time affects the weighting of prior probability in a perceptual decision task. J. Neurosci. 2011, 31, 6339–6352. [Google Scholar] [CrossRef] [Green Version]
- Rita, S.-M.; Temprado, J.J.; Berton, E. Age-related dedifferentiation of cognitive and motor slowing: Insight from the comparison of Hick-Hyman and Fitts’ laws. Front. Aging Neurosci. 2013, 5, 62. [Google Scholar] [CrossRef] [Green Version]
- Michmizos, K.P.; Krebs, H.I. Reaction time in ankle movements: A diffusion model analysis. Exp. Brain Res. 2014, 232, 3475–3488. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Large, D.R.; Burnett, G.; Crundall, E.; van Loon, E.; Eren, A.L.; Skrypchuk, L. Developing predictive equations to model the visual demand of in-vehicle touchscreen HMIs. Int. J. Hum. Comput. Interact. 2018, 34, 1–14. [Google Scholar] [CrossRef]
- Zheng, B.; Janmohamed, Z.; MacKenzie, C.L. Reaction times and the decision-making process in endoscopic surgery: An experimental study. Surg. Endosc. Other Interv. Tech. 2003, 17, 1475–1480. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.; Dufford, A.J.; Egan, L.J.; Mackie, M.A.; Chen, C.; Yuan, C.; Chen, C.; Li, X.; Liu, X.; Hof, P.R.; et al. Hick-hyman law is mediated by the cognitive control network in the brain. Cereb. Cortex 2018, 28, 2267–2282. [Google Scholar] [CrossRef]
- Burns, K.; Bonaceto, C. An empirically benchmarked human reliability analysis of general aviation. Reliab. Eng. Syst. Saf. 2020, 194, 106227. [Google Scholar] [CrossRef]
- Byrne, M.D.; Pew, R.W. A history and primer of human performance modeling. Rev. Hum. Factors Ergon. 2009, 5, 225–263. [Google Scholar] [CrossRef]
- Li, N.; Huang, J.; Feng, Y. Human performance modeling and its uncertainty factors affecting decision making: A survery. Soft Comput. 2020, 24, 2851–2871. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, J.; Park, J.; Choi, S.Y.; Kim, S.; Jung, W.; Kim, H.E.; Shin, S.K. An algorithm for evaluating time-related human reliability using instrumentation cues and procedure cues. Nucl. Eng. Technol. 2021, 53, 368–375. [Google Scholar] [CrossRef]
- Liu, B. Uncertainty Theory, 2nd ed.; Springer: Berlin, Germany, 2007; ISBN 9783540731658. [Google Scholar]
- Liu, B. Some research problems in uncertainty theory. J. Uncertain Syst. 2009, 3, 3–10. [Google Scholar]
- Apostolakis, G. The concept of probability in safety assessments of technological systems. Science 1990, 250, 1359–1364. [Google Scholar] [CrossRef] [Green Version]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Zadeh, L.A. Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets Syst. 1978, 100, 9–34. [Google Scholar] [CrossRef]
- Kang, R.; Zhang, Q.; Zeng, Z.; Zio, E.; Li, X. Measuring reliability under epistemic uncertainty: Review on non-probabilistic reliability metrics. Chin. J. Aeronaut. 2016, 29, 571–579. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Kang, R.; Wen, M. Belief reliability for uncertain random systems. IEEE Trans. Fuzzy Syst. 2018, 26, 3605–3614. [Google Scholar] [CrossRef]
- Hu, L.; Kang, R.; Pan, X.; Zuo, D. Uncertainty expression and propagation in the risk assessment of uncertain random system. IEEE Syst. J. 2021, 15, 1604–1615. [Google Scholar] [CrossRef]
- Hu, L.; Kang, R.; Pan, X.; Zuo, D. Risk assessment of uncertain random system—Level-1 and level-2 joint propagation of uncertainty and probability in fault tree analysis. Reliab. Eng. Syst. Saf. 2020, 198, 106874. [Google Scholar] [CrossRef]
- Allen, P.A.; Murphy, M.D.; Kaufman, M.; Groth, K.E.; Begovic, A. Age differences in central (semantic) and peripheral processing: The importance of considering both response times and errors. J. Gerontol. Sci. 2004, 59, 210–219. [Google Scholar] [CrossRef] [Green Version]
- Liu, B. Uncertainty Theory, 5th ed.; Uncertainty Theory Laboratory: Beijing, China, 2021; Available online: https://cloud.tsinghua.edu.cn/d/df71e9ec330e49e59c9c (accessed on 4 January 2022).
- Liu, B. Uncertainty Theory: A Branch of Mathematics for Modeling Human Uncertainty; Springer: Berlin, Germany, 2010; ISBN 978-3-642-13959-8. [Google Scholar]
- Yao, K.; Liu, B. Uncertain regression analysis: An approach for imprecise observations. Soft Comput. 2018, 22, 5579–5582. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Residual and confidence interval for uncertain regression model with imprecise observations. J. Intell. Fuzzy Syst. 2018, 35, 2573–2583. [Google Scholar] [CrossRef]
- Ye, T.; Liu, B. Uncertain hypothesis test with application to uncertain regression analysis. Fuzzy Optim. Decis. Mak. 2021. [Google Scholar] [CrossRef]
- Hollnagel, G. Cognitive Reliability and Error Analysis Method (CREAM); Elsevier: Oxford, UK, 1998; ISBN 0-08-0428487. [Google Scholar]
- Reason, J.T. Human Error; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Kleiner, M.; Brainard, D.; Pelli, D.; Ingling, A.; Murray, R.; Broussard, C. What’s new in psychtoolbox-3. Perception 2007, 36, 1–16. [Google Scholar]
- Jung, W.; Park, J.; Kim, Y.; Choi, S.Y.; Kim, S. HuREX—A framework of HRA data collection from simulators in nuclear power plants. Reliab. Eng. Syst. Saf. 2020, 194, 106235. [Google Scholar] [CrossRef]
- Hogenboom, S.; Rokseth, B.; Vinnem, J.E.; Utne, I.B. Human reliability and the impact of control function allocation in the design of dynamic positioning systems. Reliab. Eng. Syst. Saf. 2020, 194, 106340. [Google Scholar] [CrossRef]
- Taylor, C.; Øie, S.; Gould, K. Lessons learned from applying a new HRA method for the petroleum industry. Reliab. Eng. Syst. Saf. 2020, 194, 106276. [Google Scholar] [CrossRef]
- Kim, Y.; Park, J.; Presley, M. Selecting significant contextual factors and estimating their effects on operator reliability in computer-based control rooms. Reliab. Eng. Syst. Saf. 2021, 213, 107679. [Google Scholar] [CrossRef]
- Cockburn, A.; Gutwin, C.; Greenberg, S. A predictive model of menu performance. In Proceedings of the Conference on Human Factors in Computing Systems, San Jose, CA, USA, 28 April–3 May 2007; pp. 627–636. [Google Scholar]
- Thakur, N.; Han, C.Y. An ambient intelligence-based human behavior monitoring framework for ubiquitous environments. Information 2021, 12, 81. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Belief Degree j | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
| Entropy | 0.6931 | 0.6730 | 0.6109 | 0.5004 | 0.3251 | 0 |
| Numbers of Stimuli | One | Two | Three | Four | Five | Six | Seven | Eight |
|---|---|---|---|---|---|---|---|---|
| Entropy | 0 | 1 | 1.5850 | 2 | 2.3219 | 2.5850 | 2.8074 | 3 |
| Amount of data | 40 | 38 | 36 | 38 | 36 | 38 | 34 | 40 |
| Belief Degree | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
| Entropy | 0.6931 | 0.6730 | 0.6109 | 0.5004 | 0.3251 | 0 |
| Amount of data | 40 | 57 | 63 | 76 | 44 | 20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, L.; Pan, X.; Ding, S.; Kang, R. Human Decision Time in Uncertain Binary Choice. Symmetry 2022, 14, 201. https://doi.org/10.3390/sym14020201
Hu L, Pan X, Ding S, Kang R. Human Decision Time in Uncertain Binary Choice. Symmetry. 2022; 14(2):201. https://doi.org/10.3390/sym14020201
Chicago/Turabian StyleHu, Lunhu, Xing Pan, Song Ding, and Rui Kang. 2022. "Human Decision Time in Uncertain Binary Choice" Symmetry 14, no. 2: 201. https://doi.org/10.3390/sym14020201
APA StyleHu, L., Pan, X., Ding, S., & Kang, R. (2022). Human Decision Time in Uncertain Binary Choice. Symmetry, 14(2), 201. https://doi.org/10.3390/sym14020201