
DGAN-KPN: Deep Generative Adversarial Network and Kernel Prediction Network for Denoising MC Renderings


Abstract
:1. Introduction
- In the first part of this paper, we propose a new end-to-end Monte Carlo denoising rendered image based on the deep learning network structure, and we use the kernel prediction network to optimize the generalization ability of the denoising method for better scene structure and detail retention capabilities.
- We introduce a loss function based on adversarial training to make network training more stable and effective, to improve the clarity and contrast of the denoised image, and to retain more image details.
- We prove that a few auxiliary features can improve the noise reduction effect and solve the loss of high-frequency details of our approach to some extent.
- Our approach is applied to the deep convolutional neural network and makes the learning ability of the network more powerful, with less time-consuming processing.
2. Related Work
3. The Method
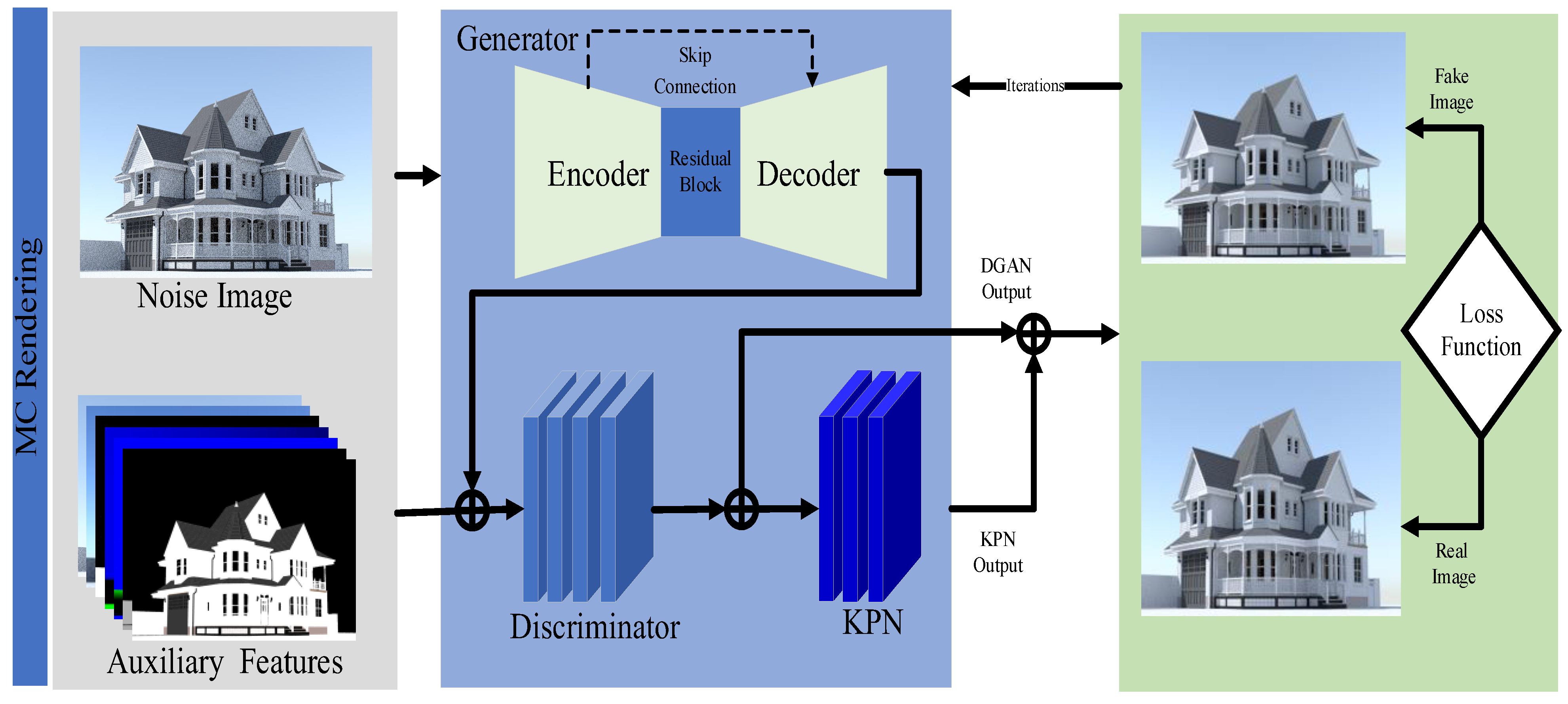
3.1. Model Architecture
3.1.1. Deep Generation Adversarial Network (DGAN)
3.1.2. The Kernel Prediction Network (KPN)
3.1.3. Image Reconstruction
3.1.4. Loss Function Design
3.2. Auxiliary Feature
3.3. Dataset and Training
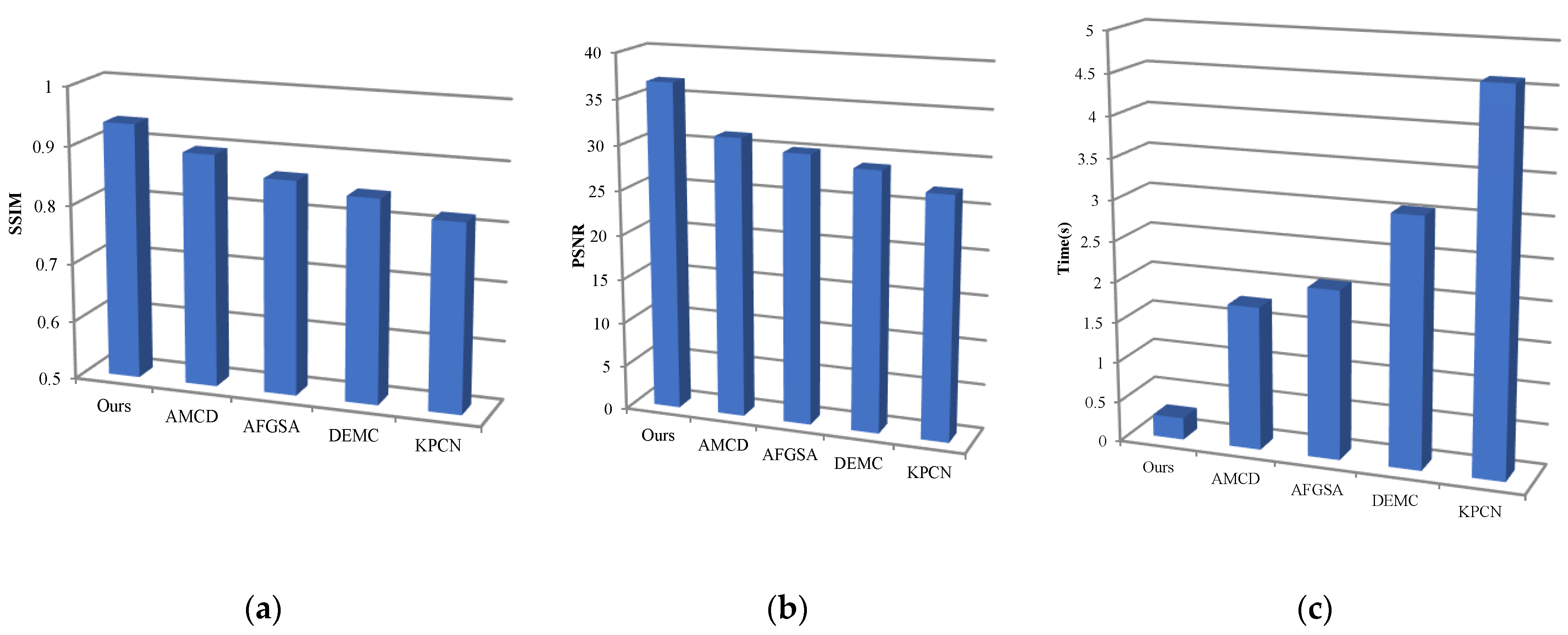
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MC | Monte Carlo Method |
| DGAN | Deep Generative Adversarial Network |
| AFGSA | Auxiliary Feature Guided Self-Attention Module |
| KPCN | Kernel Predicting Convolutional Network |
| spp | Samples Per Pixel |
| SSIM | The Structural Similarity Index |
| PSNR | Peak Signal-To-Noise Ratio |
References
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context Encoders: Feature Learning by Inpainting. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 2, pp. 2536–2544. Available online: https://doi.ieeecomputersociety.org/10.1109/CVPR.2016.278 (accessed on 25 November 2021).
- Brabandere, B.D.; Jia, X.; Tuytelaars, T.; Gool, L.V. Dynamic filter networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 667–675. Available online: https://dl.acm.org/doi/10.5555/3157096.3157171 (accessed on 25 November 2021).
- Bako, S.; Vogels, T.; McWilliams, B.; Meyer, M.; Novák, J.; Harvill, A.; Sen, P.; Derose, T.; Rousselle, F. Kernel-predicting convolutional networks for denoising Monte Carlo renderings. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Vogels, T.; Rousselle, F.; Mcwilliams, B.; Röthlin, G.; Harvill, A.; Adler, D.; Meyer, M.; Novák, J. Denoising with kernel prediction and asymmetric loss functions. ACM Trans. Graph. 2018, 37, 1–15. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Mildenhall, B.; Barron, J.T.; Chen, J.; Sharlet, D.; Ng, R.; Carroll, R. Burst Denoising with Kernel Prediction Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2502–2510. Available online: https://arxiv.org/abs/1712.02327 (accessed on 25 November 2021).
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. Comput. Vis. Pattern Recognit. 2016, 2, 1–9. Available online: https://arxiv.org/abs/1603.09056 (accessed on 25 November 2021).
- Gharbi, M.; Li, T.-M.; Aittala, M.; Lehtinen, J.; Durand, F. Sample-based Monte Carlo denoising using a kernel-splatting network. ACM Trans. Graph. 2019, 38, 125. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv 2016, arXiv:1701.00160. Available online: http://arxiv.org/pdf/1701.00160.pdf (accessed on 25 November 2021).
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Chen, Q.; Koltun, V. Photographic Image Synthesis with Cascaded Refinement Networks. In Proceedings of the International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 1–10. Available online: https://arxiv.org/abs/1707.09405 (accessed on 26 November 2021).
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 658–666. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. Comput. Vis. Pattern Recognit. 2016, 9906, 694–711. Available online: https://arxiv.org/abs/1603.08155 (accessed on 15 November 2021).
- Bui, G.; Le, T.; Morago, B.; Duan, Y. Point-based rendering enhancement via deep learning. Vis. Comput. 2018, 34, 829–841. [Google Scholar] [CrossRef]
- Xu, B.; Zhang, J.; Wang, R.; Xu, K.; Yang, Y.-L.; Li, C.; Tang, R. Adversarial Monte Carlo Denoising with Conditioned Auxiliary Feature Modulation. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Wang, D.; Hu, W.; Zhao, L.-J.; Yin, B.-C.; Zhang, Q.; Wei, X.-P.; Fu, H. DEMC: A Deep Dual-Encoder Network for Denoising Monte Carlo Rendering. J. Comput. Sci. Technol. 2019, 34, 1123–1135. [Google Scholar] [CrossRef] [Green Version]
- Munkberg, J.; Hasselgren, J. Neural Denoising with Layer Embeddings. Comput. Graph. Forum 2020, 39, 1–12. [Google Scholar] [CrossRef]
- Lu, Y.; Xie, N.; Shen, H.T. DMCR-GAN: Adversarial Denoising for Monte Carlo Renderings with Residual Attention Networks and Hierarchical Features Modulation of Auxiliary Buffers. In Proceedings of the SIGGRAPH Asia 2020 Technical Communications, Virtual Event, Korea, 1–9 December 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Yu, J.; Nie, Y.; Long, C.; Xu, W.; Zhang, Q.; Li, G. Monte Carlo denoising via auxiliary feature guided self-attention. ACM Trans. Graph. 2021, 40, 1–13. [Google Scholar] [CrossRef]
- Marinč, T.; Srinivasan, V.; Gül, S.; Hellge, C.; Samek, W. Multi-Kernel Prediction Networks for Denoising of Burst Images. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 2404–2408. [Google Scholar] [CrossRef] [Green Version]
- Chaitanya, C.R.A.; Kaplanyan, A.S.; Schied, C.; Salvi, M.; Lefohn, A.; Nowrouzezahrai, D.; Aila, T. Interactive reconstruction of Monte Carlo image sequences using a recurrent denoising autoencoder. ACM Trans. Graph. 2017, 36, 1–12. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. Available online: https://dl.acm.org/doi/10.5555/2969033.2969125 (accessed on 26 December 2021).
- Lee, W.-H.; Ozger, M.; Challita, U.; Sung, K.W. Noise Learning Based Denoising Autoencoder. IEEE Commun. Lett. 2021, 25, 2983–2987. [Google Scholar] [CrossRef]
- Fan, L.; Zhang, F.; Fan, H.; Zhang, C. Brief review of image denoising techniques. Vis. Comput. Ind. Biomed. Art 2019, 2, 7. [Google Scholar] [CrossRef] [Green Version]
- Horé, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar] [CrossRef]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. ACM Trans. Graph. 2002, 21, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Bitterli, B. Rendering Resources. 2016, vol. 9. Available online: https://benedikt-bitterli.me/resources/ (accessed on 1 November 2021).
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. Found. Trends Mach. Learn. 2019, 12, 307–392. Available online: https://arxiv.org/abs/1906.02691 (accessed on 26 November 2021). [CrossRef]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. Available online: http://proceedings.mlr.press/v9/glorot10a.html (accessed on 27 November 2021).
- Bitterli, B. The Tungsten Renderer. 2014. Available online: https://benedikt-bitterli.me/tungsten.html (accessed on 1 November 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene | Ours | AMCD | KPCN | DEMC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | PSNR | Time(s) | SSIM | PSNR | Time(s) | SSIM | PSNR | Time(s) | SSIM | PSNR | Time(s) | |
| Automobile | 0.9326 | 34.26 | 0.124 | 0.8867 | 29.91 | 1.079 | 0.8061 | 27.75 | 2.034 | 0.8241 | 28.75 | 1.478 |
| House | 0.9113 | 31.88 | 0.329 | 0.8434 | 28.12 | 1.04 | 0.815 | 25.95 | 3.229 | 0.8314 | 26.45 | 2.145 |
| Living-room2 | 0.9405 | 34.39 | 0.1502 | 0.9282 | 32.05 | 1.004 | 0.8931 | 30.82 | 3.168 | 0.8747 | 29.25 | 1.455 |
| Scene | Ours | AMCD | AFGSA | DEMC | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | PSNR | Time(s) | SSIM | PSNR | Time(s) | SSIM | PSNR | Time(s) | SSIM | PSNR | Time(s) | |
| Material | 0.9487 | 36.75 | 0.221 | 0.9123 | 32.04 | 1.024 | 0.9044 | 30.26 | 2.054 | 0.8845 | 29.31 | 3.020 |
| Teapot | 0.9286 | 34.60 | 0.134 | 0. 910 | 31.01 | 0.984 | 0.902 | 30.76 | 1.947 | 0.8942 | 29.25 | 2.867 |
| Coffee | 0.9568 | 36.04 | 0.124 | 0.9364 | 34.14 | 1.133 | 0.8502 | 28.02 | 1.265 | 0.8293 | 25.50 | 3.170 |
| Model | PSNR(dB)  | SSIM  | Time(s)  |
|---|---|---|---|
| KPCN | 26.96 | 0.818 | 4.612 |
| DEMC | 28.63 | 0.845 | 3.055 |
| AFGSA | 30.07 | 0.863 | 2.083 |
| AMCD | 31.62 | 0.895 | 1.773 |
| Ours | 36.76 | 0.9361 | 0.2721 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzbier, A.M.T.; Chen, C. DGAN-KPN: Deep Generative Adversarial Network and Kernel Prediction Network for Denoising MC Renderings. Symmetry 2022, 14, 395. https://doi.org/10.3390/sym14020395
Alzbier AMT, Chen C. DGAN-KPN: Deep Generative Adversarial Network and Kernel Prediction Network for Denoising MC Renderings. Symmetry. 2022; 14(2):395. https://doi.org/10.3390/sym14020395
Chicago/Turabian StyleAlzbier, Ahmed Mustafa Taha, and Chunyi Chen. 2022. "DGAN-KPN: Deep Generative Adversarial Network and Kernel Prediction Network for Denoising MC Renderings" Symmetry 14, no. 2: 395. https://doi.org/10.3390/sym14020395
APA StyleAlzbier, A. M. T., & Chen, C. (2022). DGAN-KPN: Deep Generative Adversarial Network and Kernel Prediction Network for Denoising MC Renderings. Symmetry, 14(2), 395. https://doi.org/10.3390/sym14020395