
Cross-Project Defect Prediction Considering Multiple Data Distribution Simultaneously


Abstract
:1. Introduction
- (1)
- We conducted an experimental exploration of two CPDP experimental setups, comparing the experimental results of single-source CPDP and multi-source merged CPDP. We confirmed two shortcomings of single-source CPDP, one is that it is impossible to know in advance which source project is used to build the model to obtain the best prediction performance, the other is the lower limit of performance. We pointed out that the problem that affects the performance of multi-source defect prediction is the data distribution differences between multiple source projects and target project, and the differences between multiple source projects.
- (2)
- In response to the above-mentioned shortcomings and problems, this paper proposes a cross-project defect prediction method considering multiple data distribution simultaneously, called MSCPDP. This method can use the data information of multiple source pro-jects to construct a model at the same time, and conducted large-scale experimental research on the AEEEM dataset and PROMISE dataset. Experimental results show that MSCPDP can indeed avoid the two short-comings of single-source CPDP and achieve performance comparable to the current advanced CPDP methods.
2. Related Work
2.1. Cross-Project Defect Prediction
2.2. Multi-Source Cross-Project Defect Prediction Method
3. Experimental Investigation
3.1. Experimental Setup
3.2. Experimental Datasets
3.3. Evaluation Indicators
4. Experimental Investigation
5. Cross-Project Defect Prediction Method Based on Multiple Sources
5.1. Symbol Definition
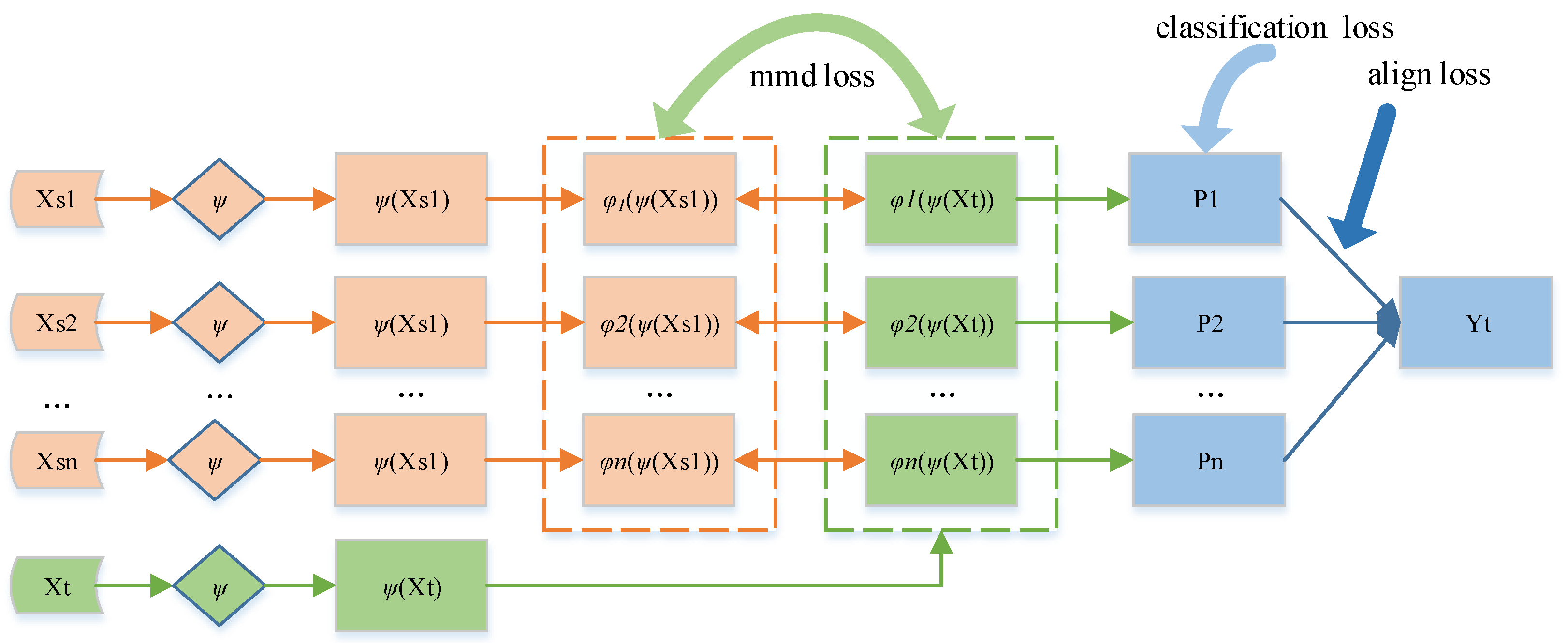
5.2. Method Framework and Implementation Details
5.3. Experimental Parameter Setting
6. Experimental Research
6.1. Experimental Parameter Setting
6.2. Analysis of Experimental Results
6.3. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gotlieb, A. Exploiting symmetries to test programs. In Proceedings of the 14th International Symposium on Software Reliability Engineering, Denver, CO, USA, 17–21 November 2003. [Google Scholar]
- Gomez-Jauregui, V.; Hogg, H.; Manchado, C. GomJau-Hogg’s Notation for automatic generation of k-uniform tessellations with ANTWERP v3.0. Symmetry 2021, 13, 2376. [Google Scholar] [CrossRef]
- Chen, X.; Gu, Q.; Liu, W.; Ni, C. Survey of static software defect prediction. J. Softw. 2016, 27, 1–25. [Google Scholar]
- Jin, C. Software defect prediction model based on distance metric learning. Soft Comput. 2021, 25, 447–461. [Google Scholar] [CrossRef]
- Hall, T.; Beecham, S.; Bowes, D.; Gray, D.; Counsell, S. A systematic literature review on fault prediction performance in software engineering. IEEE Trans. Softw. Eng. 2012, 38, 1276–1304. [Google Scholar] [CrossRef]
- Chen, X.; Mu, Y.; Liu, K.; Cui, Z.; Ni, C. Revisiting heterogeneous defect prediction methods: How far are we? Inf. Softw. Technol. 2021, 130, 106441. [Google Scholar] [CrossRef]
- Hosseini, S.; Turhan, B.; Mika, M. A benchmark study on the effectiveness of search-based data selection and feature selection for cross project defect prediction. Inf. Softw. Technol. 2018, 95, 296–312. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Wang, L.; Gu, Q.; Wang, Z.; Ni, C.; Liu, W.; Wang, Q. A survy on cross-project software defect prediction methods. Chin. J. Comput. 2018, 41, 254–274. [Google Scholar]
- Gong, L.; Jiang, S.; Jiang, L. Research progress of software defect prediction. J. Softw. 2019, 30, 3090–3114. [Google Scholar]
- Hosseini, S.; Turhan, B.; Gunarathna, D. A systematic literature review and meta-analysis on cross project defect prediction. IEEE Trans. Softw. Eng. 2019, 45, 111–147. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Xia, X.; Hassan, A.; David, L.; Yin, J.; Yang, X. Perceptions, expectations, and challenges in defect prediction. IEEE Trans. Softw. Eng. 2020, 46, 1241–1266. [Google Scholar]
- Li, Y.; Liu, Z.; Zhang, H. Review on cross-project software defects prediction methods. Comput. Technol. Dev. 2020, 30, 98–103. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.; Wu, G.Q.; Yuan, M.T. Transfer Learning for Software Defect Prediction. Acta Electron. Sin. 2016, 44, 115–122. [Google Scholar]
- He, Z.; Shu, F.; Yang, Y.; Li, M.; Wang, Q. An investigation on the feasibility of cross-project defect prediction. Autom. Softw. Eng. 2012, 19, 167–199. [Google Scholar] [CrossRef]
- Herbold, S. Training data selection for cross-project defect prediction. In Proceedings of the 9th International Conference on Predictive Models in Software Engineering, New York, NY, USA, 1–10 October 2013. [Google Scholar]
- Turhan, B.; Menzies, T.; Bener, A.B.; Stefano, J.D. On the relative value of cross-company and within-company data for defect prediction. Empir. Softw. Eng. 2009, 14, 540–578. [Google Scholar] [CrossRef] [Green Version]
- Peters, F.; Menzies, T.; Marcus, A. Better cross company defect prediction. In Proceedings of the 2013 10th Working Conference on Mining Software Repositories (MSR), San Francisco, CA, USA, 18–19 May 2013; pp. 409–418. [Google Scholar]
- He, P.; Li, B.; Zhang, D.; Ma, Y. Simplification of training data for cross-project defect prediction. arXiv 2014, arXiv:1405.0773. [Google Scholar]
- Li, Y.; Huang, Z.; Wang, Y.; Huang, B. New approach of cross-project defect prediction based on multi-source data. J. Jilin Univ. 2016, 46, 2034–2041. [Google Scholar]
- Asano, T.; Tsunoda, M.; Toda, K.; Tahir, A.; Bennin, K.E.; Nakasai, K.; Monden, A.; Matsumoto, K. Using Bandit Algorithms for Project Selection in Cross-Project Defect Prediction. In Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution (ICSME), Luxembourg, 27 September–1 October 2021; pp. 649–653. [Google Scholar]
- Wu, J.; Wu, Y.; Niu, N.; Zhou, M. MHCPDP: Multi-source heterogeneous cross-project defect prediction via multi-source transfer learning and autoencoder. Softw. Qual. J. 2021, 29, 405–430. [Google Scholar] [CrossRef]
- Briand, L.C.; Melo, W.L.; Wust, J. Assessing the applicability of fault-proneness models across object-oriented software projects. IEEE Trans. Softw. Eng. 2002, 28, 706–720. [Google Scholar] [CrossRef] [Green Version]
- Zimmermann, T.; Nagappan, N.; Gall, H.; Giger, E.; Murphy, B. Cross-project defect prediction: A large scale experiment on data vs. domain vs. process. In Proceedings of the 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering, Amsterdam, The Netherlands, 24–28 August 2009; pp. 91–100. [Google Scholar]
- Nam, J.; Pan, S.J.; Kim, S. Transfer defect learning. In Proceedings of the 2013 35th International Conference on Software Engineering (ICSE), San Francisco, CA, USA, 18–26 May 2013; pp. 382–391. [Google Scholar]
- Ma, Y.; Luo, G.; Zeng, X.; Chen, A. Transfer learning for cross-company software defect prediction. Inf. Softw. Technol. 2012, 54, 248–256. [Google Scholar] [CrossRef]
- Yu, Q.; Jiang, S.; Zhang, Y. A feature matching and transfer approach for cross-company defect prediction. J. Syst. Softw. 2017, 132, 366–378. [Google Scholar] [CrossRef]
- Yu, Q.; Jiang, S.; Qian, J. Which is more important for cross-project defect prediction: Instance or feature? In Proceedings of the 2016 International Conference on Software Analysis, Testing and Evolution (SATE), Kunming, China, 3–4 November 2016; pp. 90–95. [Google Scholar]
- Yu, Q.; Qian, J.; Jiang, S.; Wu, Z.; Zhang, G. An empirical study on the effectiveness of feature selection for cross-project defect prediction. IEEE Access 2019, 7, 35710–35718. [Google Scholar] [CrossRef]
- Xia, X.; Lo, D.; Pan, S.J.; Nagappan, N.; Wang, X. Hydra: Massively compositional model for cross-project defect prediction. IEEE Trans. Softw. Eng. 2016, 42, 977–998. [Google Scholar] [CrossRef]
- Wu, F.; Jing, X.Y.; Sun, Y.; Sun, J.; Huang, L.; Cui, F.; Sun, Y. Cross-project and within-project semi supervised software defect prediction: A unified approach. IEEE Trans. Reliab. 2018, 67, 581–597. [Google Scholar] [CrossRef]
- Li, Z.; Jing, X.Y.; Wu, F.; Zhu, X.; Xu, B.; Ying, S. Cost-sensitive transfer kernel canonical correlation analysis for heterogeneous defect prediction. Autom. Softw. Eng. 2018, 25, 201–245. [Google Scholar] [CrossRef]
- Zhang, Y.; Lo, D.; Xia, X.; Sun, J. An empirical study of classifier combination for cross-project defect prediction. In Proceedings of the 2015 IEEE Computer Software & Applications Conference, Taichung, Taiwan, 1–5 July 2015; pp. 264–269. [Google Scholar]
- Chen, J.; Hu, K.; Yang, Y.; Liu, Y.; Xuan, Q. Collective transfer learning for defect prediction. Neurocomputing 2020, 416, 103–116. [Google Scholar] [CrossRef]
- Yu, X.; Wu, M.; Jian, Y.; Bennin, K.E.; Fu, M.; Ma, C. Cross-company defect prediction via semi-supervised clustering-based data filtering and MSTrA-based transfer learning. Soft Comput. 2018, 22, 3461–3472. [Google Scholar] [CrossRef]
- Lelis, L.; Sander, J. Semi-supervised density-based clustering. In Proceedings of the 2009 9th IEEE International Conference on Data Mining, Miami Beach, FL, USA, 6–9 December 2009; pp. 842–847. [Google Scholar]
- Peng, L.; Yang, B.; Chen, Y.; Abraham, A. Data gravitation based classification. Inf. Sci. 2009, 179, 809–819. [Google Scholar] [CrossRef]
- Yao, Y.; Doretto, G. Boosting for transfer learning with multiple sources. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1855–1862. [Google Scholar]
- Sun, Z.; Li, J.; Sun, H.; He, L. CFPS: Collaborative filtering based source projects selection for cross-project defect prediction. Appl. Soft Comput. 2021, 99, 106940. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- D’Ambros, M.; Lanza, M.; Robbes, R. Evaluating defect prediction approaches: A benchmark and an extensive comparison. Empir. Softw. Eng. 2012, 17, 531–577. [Google Scholar] [CrossRef]
- Jureczko, M.; Madeyski, L. Towards identifying software project clusters with regard to defect prediction. In Proceedings of the 6th International Conference on Predictive Models in Software Engineering, Timisoara, Romania, 12–13 September 2010; pp. 1–10. [Google Scholar]
- Chidamber, S.R.; Kemerer, C.F. A metrics suite for object oriented design. IEEE Trans. Softw. Eng. 1994, 20, 476–493. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Yang, Y.; Lu, H.; Chen, L.; Li, Y.; Zhao, Y.; Qian, J.; Xu, B. How far we have progressed in the journey? An examination of cross-project defect prediction. ACM Trans. Softw. Eng. Methodol. 2018, 27, 1–51. [Google Scholar] [CrossRef]
- Xu, R.; Chen, Z.; Zuo, W.; Yan, J.; Lin, L. Deep cocktail network: Multi-source unsupervised domain adaptation with category shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3964–3973. [Google Scholar]
- Zhao, H.; Zhang, S.; Wu, G.; Gordon, G.J. Multiple source domain adaptation with adversarial learning. In Proceedings of the 6th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 16 February 2018. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, D. Aligning domain-specific distribution and classifier for cross-domain classification from multiple sources. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 17 July 2019; Volume 33, pp. 5989–5996. [Google Scholar]
- Zeng, J.; Xie, P. Contrastive self-supervised learning for graph classification. arXiv 2020, arXiv:2009.05923. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4068–4076. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–10 October 2016; pp. 443–450. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the 32nd International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 1180–1189. [Google Scholar]
- Cruz, A.E.C.; Ochimizu, K. Towards logistic regression models for predicting fault-prone code across software projects. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, Lake Buena Vista, FL, USA, 15–16 October 2009; pp. 460–463. [Google Scholar]
- Herbold, S.; Trautsch, A.; Grabowski, J. A comparative study to benchmark cross-project defect prediction approaches. IEEE Trans. Softw. Eng. 2018, 44, 811–833. [Google Scholar] [CrossRef]


{kind=link}
| Projects | Modules | Features | Defects | Defect Ratio |
|---|---|---|---|---|
| EQ | 325 | 61 | 129 | 40% |
| JDT | 997 | 61 | 206 | 21% |
| LC | 399 | 61 | 64 | 9% |
| ML | 1862 | 61 | 245 | 13% |
| PDE | 1492 | 61 | 209 | 14% |
| Projects | Version | Modules | Features | Defects | Defect Ratio |
|---|---|---|---|---|---|
| ant | 1.7 | 745 | 20 | 166 | 22% |
| camel | 1.6 | 965 | 20 | 188 | 19% |
| ivy | 2.0 | 352 | 20 | 40 | 11% |
| jedit | 4.1 | 312 | 20 | 79 | 25% |
| lucene | 2.4 | 340 | 20 | 203 | 60% |
| poi | 3.0 | 442 | 20 | 281 | 64% |
| synapse | 1.2 | 256 | 20 | 86 | 34% |
| velocity | 1.6 | 229 | 20 | 78 | 34% |
| xalan | 2.6 | 885 | 20 | 411 | 46% |
| xerces | 1.3 | 453 | 20 | 69 | 15% |
| Single-Source | F1 | AUC | Multi-Source | F1 | AUC |
|---|---|---|---|---|---|
| PDE→EQ | 0.2338 | 0.5518 | {PDE, JDT, LC, ML}→EQ | 0.2716 | 0.5571 |
| JDT→EQ | 0.2667 | 0.5750 | |||
| LC→EQ | 0.3077 | 0.5853 | |||
| ML→EQ | 0.1622 | 0.5286 | |||
| PDE→ML | 0.2197 | 0.5581 | {PDE, JDT, LC, EQ}→ML | 0.2781 | 0.5823 |
| LC→ML | 0.2989 | 0.5904 | |||
| JDT→ML | 0.2598 | 0.5745 | |||
| EQ→ML | 0.2445 | 0.5578 | |||
| ML→PDE | 0.2278 | 0.5586 | {EQ, JDT, LC, ML}→PDE | 0.303 | 0.5953 |
| JDT→PDE | 0.2838 | 0.5830 | |||
| EQ→PDE | 0.2591 | 0.5574 | |||
| LC→PDE | 0.2699 | 0.5769 | |||
| PDE→JDT | 0.3918 | 0.6207 | {PDE, EQ, LC, ML}→JDT | 0.4929 | 0.6732 |
| LC→JDT | 0.4863 | 0.6670 | |||
| ML→JDT | 0.3125 | 0.5858 | |||
| EQ→JDT | 0.4116 | 0.6282 | |||
| EQ→LC | 0.2609 | 0.6409 | {PDE, JDT, EQ, ML}→LC | 0.1684 | 0.5442 |
| PDE→LC | 0.16 | 0.5429 | |||
| ML→LC | 0.1235 | 0.5295 | |||
| JDT→LC | 0.2564 | 0.5749 | |||
| synapse→ant | 0.4619 | 0.6562 | {other projects}→ant | 0.4423 | 0.6407 |
| poi→ant | 0.4907 | 0.6950 | |||
| lucene→ant | 0.4516 | 0.6512 | |||
| jedit→ant | 0.5151 | 0.6836 | |||
| ivy→ant | 0.2292 | 0.5628 | |||
| camel→ant | 0.323 | 0.5742 | |||
| velocity→ant | 0.2627 | 0.5246 | |||
| xalan→ant | 0.4635 | 0.6595 | |||
| xerces→ant | 0.1778 | 0.5032 | |||
| xerces→camel | 0.1754 | 0.5202 | {other projects}→camel | 0.2577 | 0.5432 |
| xalan→camel | 0.3282 | 0.5746 | |||
| velocity→camel | 0.3139 | 0.5652 | |||
| synapse→camel | 0.2485 | 0.5422 | |||
| lucene→camel | 0.3616 | 0.5843 | |||
| poi→camel | 0.3465 | 0.5778 | |||
| jedit→camel | 0.2603 | 0.5586 | |||
| ivy→camel | 0.0796 | 0.5181 | |||
| ant→camel | 0.1712 | 0.5283 | |||
| xerces→ivy | 0.1846 | 0.5446 | {other projects}→ivy | 0.3478 | 0.6814 |
| ant→ivy | 0.4634 | 0.7006 | |||
| camel→ivy | 0.2526 | 0.5811 | |||
| jedit→ivy | 0.4421 | 0.7080 | |||
| lucene→ivy | 0.2759 | 0.6535 | |||
| poi→ivy | 0.2973 | 0.6737 | |||
| synapse→ivy | 0.4138 | 0.7167 | |||
| velocity→ivy | 0.2879 | 0.6205 | |||
| xalan→ivy | 0.3333 | 0.6897 | |||
| xalan→jedit | 0.5541 | 0.7162 | {other projects}→jedit | 0.4891 | 0.6561 |
| xerces→jedit | 0.2121 | 0.5049 | |||
| synapse→jedit | 0.4537 | 0.6213 | |||
| velocity→jedit | 0.2805 | 0.5125 | |||
| poi→jedit | 0.4604 | 0.6154 | |||
| lucene→jedit | 0.4778 | 0.6340 | |||
| ivy→jedit | 0.3137 | 0.5862 | |||
| camel→jedit | 0.3651 | 0.5941 | |||
| ant→jedit | 0.4242 | 0.6236 | |||
| xalan→lucene | 0.5576 | 0.5989 | {other projects}→lucene | 0.3233 | 0.5329 |
| xerces→lucene | 0.1826 | 0.4958 | |||
| velocity→lucene | 0.4625 | 0.5544 | |||
| synapse→lucene | 0.4983 | 0.6008 | |||
| poi→lucene | 0.6915 | 0.6633 | |||
| jedit→lucene | 0.251 | 0.5520 | |||
| ivy→lucene | 0.0478 | 0.5087 | |||
| camel→lucene | 0.3101 | 0.5438 | |||
| ant→lucene | 0.2241 | 0.5531 | |||
| xalan→poi | 0.4398 | 0.4951 | {other projects}→poi | 0.2849 | 0.5269 |
| xerces→poi | 0.0984 | 0.4987 | |||
| synapse→poi | 0.4643 | 0.5998 | |||
| lucene→poi | 0.7993 | 0.6830 | |||
| jedit→poi | 0.3027 | 0.5752 | |||
| ivy→poi | 0.0816 | 0.5182 | |||
| camel→poi | 0.2462 | 0.5388 | |||
| ant→poi | 0.225 | 0.5547 | |||
| velocity→poi | 0.2913 | 0.5180 | |||
| ant→synapse | 0.3817 | 0.5865 | {other projects}→synapse | 0.4966 | 0.6417 |
| camel→synapse | 0.3226 | 0.5633 | |||
| ivy→synapse | 0.0444 | 0.5057 | |||
| xalan→synapse | 0.5521 | 0.6523 | |||
| velocity→synaps | 0.358 | 0.5155 | |||
| jedit→synapse | 0.3594 | 0.5778 | |||
| xerces→synapse | 0.2655 | 0.5519 | |||
| poi→synapse | 0.5774 | 0.6541 | |||
| lucene→synapse | 0.5635 | 0.6334 | |||
| ant→velocity | 0.2626 | 0.5568 | {other projects}→velocity | 0.4167 | 0.6040 |
| camel→velocity | 0.3019 | 0.5628 | |||
| ivy→velocity | 0.0952 | 0.5190 | |||
| jedit→velocity | 0.2857 | 0.5699 | |||
| lucene→velocity | 0.4434 | 0.5132 | |||
| poi→velocity | 0.5155 | 0.6020 | |||
| xalan→velocity | 0.5217 | 0.6335 | |||
| synapse→velocity | 0.393 | 0.5876 | |||
| xerces→velocity | 0.2 | 0.5478 | |||
| ant→xalan | 0.2941 | 0.5659 | {other projects}→xalan | 0.4505 | 0.5717 |
| camel→xalan | 0.2644 | 0.5396 | |||
| ivy→xalan | 0.1685 | 0.5337 | |||
| velocity→xalan | 0.4349 | 0.5673 | |||
| synapse→xalan | 0.5493 | 0.6275 | |||
| poi→xalan | 0.5531 | 0.5602 | |||
| xerces→xalan | 0.3477 | 0.5197 | |||
| lucene→xalan | 0.5907 | 0.5527 | |||
| jedit→xalan | 0.3599 | 0.5853 | |||
| ivy→xerces | 0.2588 | 0.5732 | {other projects}→xerces | 0.3051 | 0.5902 |
| lucene→xerces | 0.2509 | 0.5239 | |||
| poi→xerces | 0.275 | 0.5594 | |||
| synapse→xerces | 0.4156 | 0.6629 | |||
| xalan→xerces | 0.3286 | 0.6117 | |||
| velocity→xerces | 0.3885 | 0.6397 | |||
| jedit→xerces | 0.3238 | 0.5984 | |||
| ant→xerces | 0.2712 | 0.5730 | |||
| camel→xerces | 0.1942 | 0.5412 |
| Project | CamargoCruz | CKSDL | TCA+ | CTKCCA | HYDRA | ManualDown | MSCPDP |
|---|---|---|---|---|---|---|---|
| EQ | 0.6592 | 0.2709 * | 0.4112 | 0.3530 | 0.5926 | 0.6742 | 0.3185 |
| JDT | 0.4732 | 0.3522 | 0.4093 | 0.3495 * | 0.5385 | 0.3976 | 0.4218 |
| LC | 0.2448 | 0.3467 | 0.3631 | 0.3326 | 0.3774 | 0.2046 * | 0.4355 |
| ML | 0.3238 | 0.3642 | 0.3581 | 0.3530 | 0.5385 | 0.2581 * | 0.3246 |
| PDE | 0.3249 | 0.3507 | 0.4209 | 0.3495 | 0.2000 * | 0.3009 | 0.3593 |
| ant | 0.4582 | 0.3497 | 0.4390 | 0.3177 * | 0.3774 | 0.4853 | 0.5688 |
| camel | 0.3420 | 0.4614 | 0.3986 | 0.2404 | 0.1734 * | 0.3333 | 0.3133 |
| ivy | 0.3477 | 0.3037 * | 0.4510 | 0.2961 | 0.4400 | 0.3188 | 0.4717 |
| jedit | 0.3992 | 0.3028 | 0.1444 * | 0.3588 | 0.4203 | 0.2843 | 0.5581 |
| lucene | 0.4022 | 0.2953 * | 0.4441 | 0.3749 | 0.3273 | 0.6454 | 0.3213 |
| poi | 0.3713 | 0.2895 | 0.4117 | 0.4040 | 0.3333 | 0.5729 | 0.2866 * |
| synapse | 0.4056 | 0.2583 * | 0.3669 | 0.4099 | 0.5000 | 0.4933 | 0.5571 |
| velocity | 0.4635 | 0.2696 * | 0.4598 | 0.4156 | 0.3447 | 0.5609 | 0.4132 |
| xalan | 0.5186 | 0.2652 * | 0.4261 | 0.3967 | 0.3723 | 0.6225 | 0.4369 |
| xerces | 0.3000 | 0.3378 | 0.4033 | 0.3839 | 0.3200 | 0.2279 * | 0.3803 |
| mean | 0.4028 | 0.3212 * | 0.3938 | 0.3557 | 0.3904 | 0.4253 | 0.4113 |
| median | 0.3992 | 0.3976 | 0.3037 * | 0.4112 | 0.3530 | 0.3774 | 0.4132 |
| Project | CamargoCruz | CKSDL | TCA+ | CTKCCA | HYDRA | ManualDown | MSCPDP |
|---|---|---|---|---|---|---|---|
| EQ | 0.7406 | 0.5567 * | 0.6572 | 0.6437 | 0.7666 | 0.7137 | 0.5750 |
| JDT | 0.7359 | 0.6028 * | 0.5606 | 0.6430 | 0.7394 | 0.6212 | 0.6295 |
| LC | 0.7159 | 0.5660 * | 0.6631 | 0.6456 | 0.7337 | 0.5902 | 0.6790 |
| ML | 0.7065 | 0.5940 | 0.6164 | 0.6437 | 0.7394 | 0.5690 * | 0.6041 |
| PDE | 0.6964 | 0.5787 * | 0.6628 | 0.6430 | 0.6532 | 0.6343 | 0.6411 |
| ant | 0.6732 | 0.5644 * | 0.6442 | 0.5842 | 0.7331 | 0.6947 | 0.7287 |
| camel | 0.5743 | 0.5771 | 0.5794 | 0.5595 * | 0.6838 | 0.5611 | 0.5683 |
| ivy | 0.6797 | 0.5969 | 0.7088 | 0.5516 * | 0.7797 | 0.7119 | 0.7497 |
| jedit | 0.6198 | 0.6152 | 0.6439 | 0.6484 | 0.6763 | 0.4613 * | 0.6959 |
| lucene | 0.6284 | 0.5855 | 0.5911 | 0.6647 | 0.5746 * | 0.5980 | 0.5802 |
| poi | 0.6154 | 0.5371 * | 0.6235 | 0.6867 | 0.6935 | 0.6611 | 0.5579 |
| synapse | 0.6518 | 0.5556 * | 0.6211 | 0.6602 | 0.6762 | 0.5823 | 0.6826 |
| velocity | 0.5990 * | 0.6093 | 0.6010 | 0.6569 | 0.6550 | 0.6395 | 0.6042 |
| xalan | 0.5884 | 0.5707 * | 0.6821 | 0.6578 | 0.6743 | 0.5988 | 0.5918 |
| xerces | 0.6092 | 0.5838 | 0.6207 | 0.6392 | 0.6290 | 0.4873 * | 0.6404 |
| mean | 0.6556 | 0.5796 * | 0.6317 | 0.6352 | 0.6939 | 0.6083 | 0.6352 |
| median | 0.6518 | 0.5787 * | 0.6235 | 0.6437 | 0.6838 | 0.5988 | 0.6295 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhu, Y.; Yu, Q.; Chen, X. Cross-Project Defect Prediction Considering Multiple Data Distribution Simultaneously. Symmetry 2022, 14, 401. https://doi.org/10.3390/sym14020401
Zhao Y, Zhu Y, Yu Q, Chen X. Cross-Project Defect Prediction Considering Multiple Data Distribution Simultaneously. Symmetry. 2022; 14(2):401. https://doi.org/10.3390/sym14020401
Chicago/Turabian StyleZhao, Yu, Yi Zhu, Qiao Yu, and Xiaoying Chen. 2022. "Cross-Project Defect Prediction Considering Multiple Data Distribution Simultaneously" Symmetry 14, no. 2: 401. https://doi.org/10.3390/sym14020401
APA StyleZhao, Y., Zhu, Y., Yu, Q., & Chen, X. (2022). Cross-Project Defect Prediction Considering Multiple Data Distribution Simultaneously. Symmetry, 14(2), 401. https://doi.org/10.3390/sym14020401