1. Introduction
Most hospitals are now equipped with two-dimensional endoscopes to assist doctors in minimally invasive surgery of the abdominal cavity, thoracic cavity, and throat. The advantage is that doctors no longer need to cut the abdominal cavity and can operate only through a tiny incision in the abdomen. Compared to traditional surgery or earlier minimally invasive surgery, modern minimally invasive surgery has the advantages of smaller incisions, less bleeding, and faster recovery of patients after surgery, all of which reduce patient trauma and pain. Therefore, it is increasingly popular and widely used in surgery [
1]. However, surgeons are prone to disorientation and hand–eye dissonance while finding targets and performing complex procedures through the 2D visual display of the endoscopic video stream, making it difficult to empirically match the laparoscopic field of view with the preoperative images to determine the site of the lesion. The main reason for this is the relatively incomplete or poor visual feedback, which does not allow direct observation of the overall environment of the internal cavity. Reconstructing the three-dimensional (3D) image of the lesion site from the acquired images enables the surgeon to make a more accurate diagnosis.
Minimally invasive surgery is gradually merging with computer vision techniques, and the use of computers for image processing to extend the surgical field of view has broken the limitations of traditional surgery [
2,
3,
4]. Three-dimensional models allow a more intuitive view of the surgical scene and simplify the localization process. There are some solutions for the three-dimensional imaging methods based on computer vision in the lumen environment. For example, time-of-flight and structured light-based solutions have also been used for dense scene reconstruction, but they are less commonly used in the endocavity environment due to hardware constraints such as size and cost [
5,
6,
7]. Structure-from-Motion (SFM) has been widely used in studies relating to camera motion tracking and 3D reconstruction [
8,
9], but it is ineffective for low-resolution, weakly textured images such as internal cavities and requires offline processing; hence, it has a limited application in internal cavities. Shape-from-Shading (SFS) performs 3D reconstruction of internal cavity organs based on light and dark changes in image grayscale information [
10], but there are multiple mappings between 2D images and surface shapes, resulting in relatively higher errors in the results obtained by SFS.
In recent years, simultaneous localization and mapping, such as Simultaneous Localization and Mapping from Visual sensor (VSLAM), used only the camera as an external sensor for robotics self-localization in unknown environments and reconstructing maps of the surroundings [
11]. VSLAM has also been gradually applied to the medical field to provide new solutions for 3D reconstruction of internal cavities by moving the endoscope and using the features of each image frame for incremental composition of soft tissues and organ structures. Such methods have been used for endoscopic image reconstruction in [
12,
13,
14,
15].
Nonetheless, in VSLAM, if dynamic objects are present in the real scene, the moving objects cause degradation in the performance and robustness of the SLAM system and may lead to errors in image feature matching, camera pose estimation, map construction, and loop closure detection, thereby making the algorithm fail. Therefore, recognition and removal of dynamic objects in the scene needs to be considered. The first system to successfully fuse SLAM with moving object detection and tracking in a normal scene was proposed by Wang [
16], and subsequently several researchers have investigated SLAM in dynamic environments. For example, Kundu [
17] detected dynamic features by using epipolar geometric constraints and flow vector bound (FVB) constraints, but the effect of rejecting dynamic feature points is affected by the accuracy of the visual odometry, and it is not able to properly handle a moving object that stops in the middle. Wang [
18] implemented moving object segmentation based on optical flow computation followed by sparse point trajectory clustering and densification, but the optical flow method works on the basis of constant light brightness, so it is easily affected by light changes. Moreover, some researchers have also tried to combine deep learning to remove potential dynamic objects by methods such as semantic segmentation, e.g., a complete semantic SLAM system in dynamic environments (DS-SLAM) [
19] used a deep convolutional encoder-decoder architecture for image segmentation (SegNet) combined with a movement consistency detection method in order to filter out moving people in the scene, but the improvements in low dynamic sequences were small and humans were the only dynamic objects targeted. Tracking, mapping and inpainting by SLAM in dynamic scenes (DynaSLAM) [
20] removes dynamic objects, such as people and cars, by performing pixel-by-pixel segmentation of a-priori dynamic objects in images using the instance segmentation network called region-based masked convolutional network (Mask R-CNN). This method chooses to remove all potentially moving objects, which may leave too few static feature points available to affect the camera’s pose estimation. The method is also computationally intensive and time-consuming.
In minimally invasive surgery, the only typically dynamic objects that have an impact are surgical instruments, such as surgical forceps and scissors, without fear of sudden movement of other potential objects. Nevertheless, due to the change of light in the lumen and the complexity and dynamics of the background tissue, the segmentation of surgical instruments is more difficult. Related applications of deep-learning-based methods to robotic instrument segmentation proved their excellent performance in internal cavity binary and multiclass segmentation [
21,
22]. Therefore, we considered combining deep learning for surgical instrument segmentation in the SLAM process to prevent the mismatching of extracted features and other situations.
In medical image segmentation, U-Net [
23] shows very excellent performance, as it is able to build more feature channels in the upsampling phase while associating feature maps from the downsampling phase due to the presence of skip connections. In addition, the model training requires fewer datasets and is able to converge on a small amount of data. U-Net has now become a cornerstone in the field of medical image segmentation [
24] and is the most popular and effective technique for dealing with medical image segmentation. For example, Francia et al. added residual blocks to the U-Net network to achieve accurate segmentation of retinal blood vessels [
25]. Ding et al. proposed a U-Net-based deep attention network with a color normalization operation to implement end-to-end segmentation of the glottal region [
26]. Siddique et al. reviewed the application of U-Net in the field of medical image segmentation and in other medical image analyses and pointed out that the U-Net based architecture is quite innovative and valuable to medical image diagnosis and is one of the most important deep learning techniques [
27].
In this paper, we note that although visual SLAM is widely used in medical scenarios, it is fragile and difficult to use stably under dynamic environments. Especially in the minimally invasive surgery setting, the impact of moving surgical instruments is a problem that needs to be considered for medical robots facing complex environments in internal cavities. Deep learning allows intelligent segmentation of images in order to understand what is in them and makes analysis of each part easier. Detecting and processing dynamic objects is necessary for SLAM to estimate a stable map, which is helpful for its application. From this perspective, we hypothesize that the use of application-specific CNN networks in SLAM systems to reject dynamic objects can reduce the false association information when the SLAM system works. For neural networks, better performance can be obtained by using pretrained encoders, which also help to avoid overfitting.
Accordingly, we propose the use of a neural network based on the U-Net architecture to distinguish dynamic features on surgical instruments from static features in the background by segmenting the surgical instruments, rejecting the dynamic features as outliers, and using only the static features to track the endoscope position as well as to complete the subsequent SLAM process. Thus, semantic SLAM based on deep learning in the endocavity environment is proposed in this paper. By incorporating semantic segmentation, a dynamic SLAM system is constructed that can operate in complex internal cavity environments. The moving surgical instruments are masked out using semantic information. This solves the problem of feature extraction, localization, and 3D reconstruction in the case of moving surgical instruments in the internal cavity. Avoiding errors caused by incorrect matching and system crashes during internal cavity SLAM enables more robust SLAM performance in an inner cavity environment.
The rest of this paper is organized as follows:
Section 2 introduces the proposed SLAM and deep learning work.
Section 3 gives the experimental results and analysis. Finally, the conclusion is made in
Section 4.
2. Materials and Methods
The overall framework of the proposed dynamic SLAM system for the internal cavity is shown in
Figure 1. The SLAM system based on the Oriented FAST and Rotated Brief (ORB-SLAM) [
28] consists of four main modules: instrument segmentation, tracking, local mapping, and loop closing. We introduced semantic segmentation based on convolutional neural networks into the SLAM process to construct binary masks from RGB images, ensuring dynamic feature points on the surgical instruments were eliminated in the tracking module to avoid incorrect data association information. Then, only the feature points extracted from the regions other than the surgical instruments were used for localization and map construction of the internal cavity scene. Thus, the SLAM system could estimate the endoscope motion more consistently, as well as obtain accurate soft tissue reconstruction of the internal cavity. It is possible to give the surgeon more intuitive visual feedback in the endoscopic SLAM system, which can assist the surgeon in making judgements. In order to facilitate the possible manipulation of surgical instruments while visualizing the endoscopic scene, the influence of dynamic objects, i.e., surgical instruments, on the system was significantly reduced by combining segmentation networks.
The endoscope is first used to observe the environment of the inflated internal cavity, and the acquired sequence of internal cavity images is transmitted to the SLAM tracking thread and the semantic segmentation network based on the U-Net architecture. Since it is in a minimally invasive surgery scene, moving medical instruments are considered in the image frames, and the surgical instruments are segmented by pixel through the semantic segmentation network to obtain a binary mask. In the tracking thread, for each new frame, ORB feature points with stable geometric features are extracted. The mask obtained from the segmentation is also used to judge whether the current feature point is a dynamic feature point. If so, it is identified as an outlier and eliminated. Otherwise, it can be classified as a static candidate feature point. The static feature points are then used for the subsequent tracking and mapping steps of SLAM, including estimating the camera pose using the matching correspondence of adjacent frames, obtaining the depth estimation using the triangulation method, and jointly optimizing the map and camera pose using local and global bundle adjustments.
2.1. Surgical Instrument Segmentation
In addition to the moving surgical instruments in the endocavity scene, the surrounding environment is not completely rigid and the organs or soft tissues are also subject to certain deformations, making it very difficult to distinguish moving objects from the scene using only the geometric approach in SLAM. To separate the surgical instruments from the soft tissue background, we used a neural network based on the U-Net architecture to segment the surgical instruments using semantic information.
U-Net is a fully convolutional network with a symmetric encoder–decoder structure. This encoder–decoder structure of U-Net containing skip connections is able to fuse features from different layers to obtain accurate pixel-level localization with excellent segmentation results and was shown to perform well for segmentation problems with limited data [
29], making it well-suited for segmentation of surgical instruments in medical scenarios. To improve its binary segmentation performance, we used a pretrained VGG16 encoder on the U-Net infrastructure, which is called TernausNet-16 [
30], and then integrated it into SLAM as the semantic segmentation network of the system.
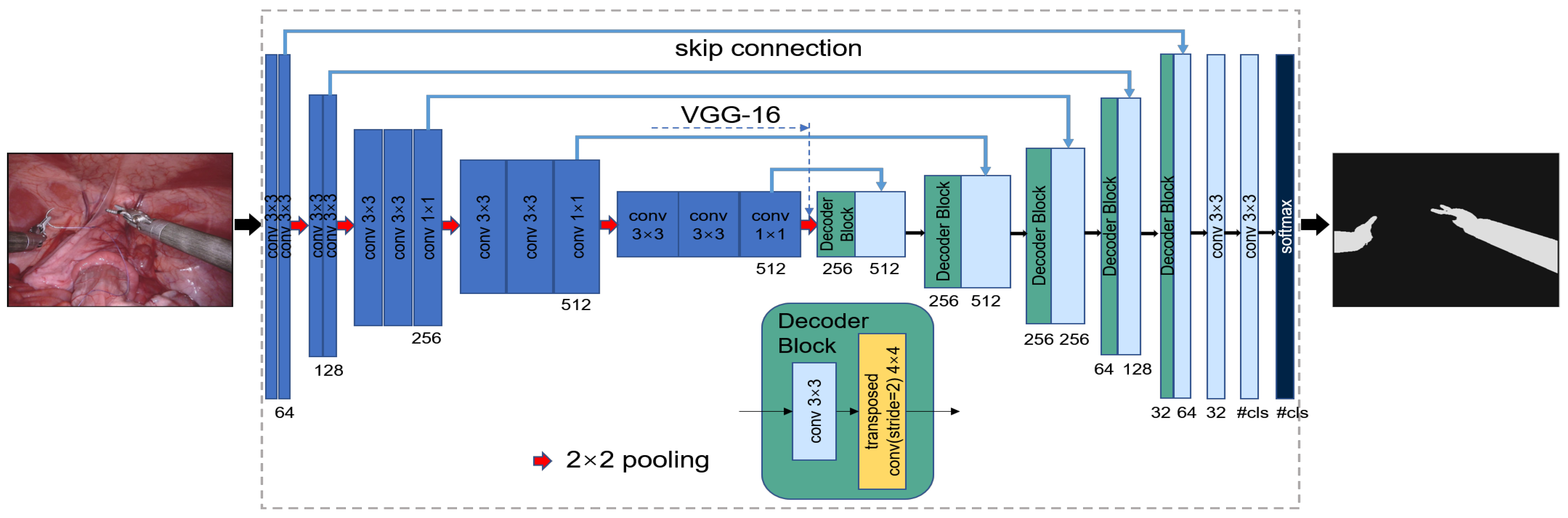
Figure 2 illustrates the TernausNet-16 network model used in the proposed segmentation algorithm, which is a classical full convolution network. Each rectangular box represents a transformed multichannel feature map. The number of channels is below the rectangular box. The height of the box corresponds to the resolution of the different feature maps. The blue arrows indicate skip connections, where information is transferred from the encoder to the decoder. The lumen image is used as the input. The left side is the encoder for downsampling, also known as the contracting path, and the right side is the decoder for upsampling, also known as the expansive path. The two are associated through skip connection.
The specific operation of the encoder for this network is given in
Table 1; a simple pretrained VGG16 network is used as the encoder. VGG16 consists of 16 forward-propagating network layers, which contain 13 convolutional layers. The convolutional kernel size is 3 × 3, and each convolutional layer is immediately followed by an ReLU activation function. The convolution layer is also followed by five 2 × 2 max pooling layers, which perform dimensionality reduction on the feature map. The first convolutional layer has 64 channels, and each subsequent pooling operation doubles the number of channels up to 512.
The specific architecture of the decoder is given in
Table 2. The decoder section is a symmetrical structure to the encoder, and replaces the fully connected layer with a convolutional layer. The feature map size is enlarged by using transposed convolution. The output of the transposed convolution is used as the output feature map of the corresponding part of the decoder, which is then processed by direct convolution operations to keep the number of channels the same as the symmetric encoder term. At the end of the network, the feature maps of the background and target foreground are obtained, and then a probability map of the categories is obtained by the soft-max function.
Since the network combines low-resolution information in downsampling and high-resolution information in upsampling and shallow and deep features of the image, it is able to achieve excellent pixel-by-pixel localization and segmentation. As an output of the model, the surgical instruments are distinguished from the pixel values in the background area, and a binary mask can be obtained by binarizing the pixel probabilities finally.
2.2. Internal Cavity Vision SLAM
ORB-SLAM2 is an advanced visual SLAM system based on feature tracking that has reliable and excellent performance in most scenarios. There have been related works applying ORB-SLAM2 to 3D reconstruction of internal cavities [
31,
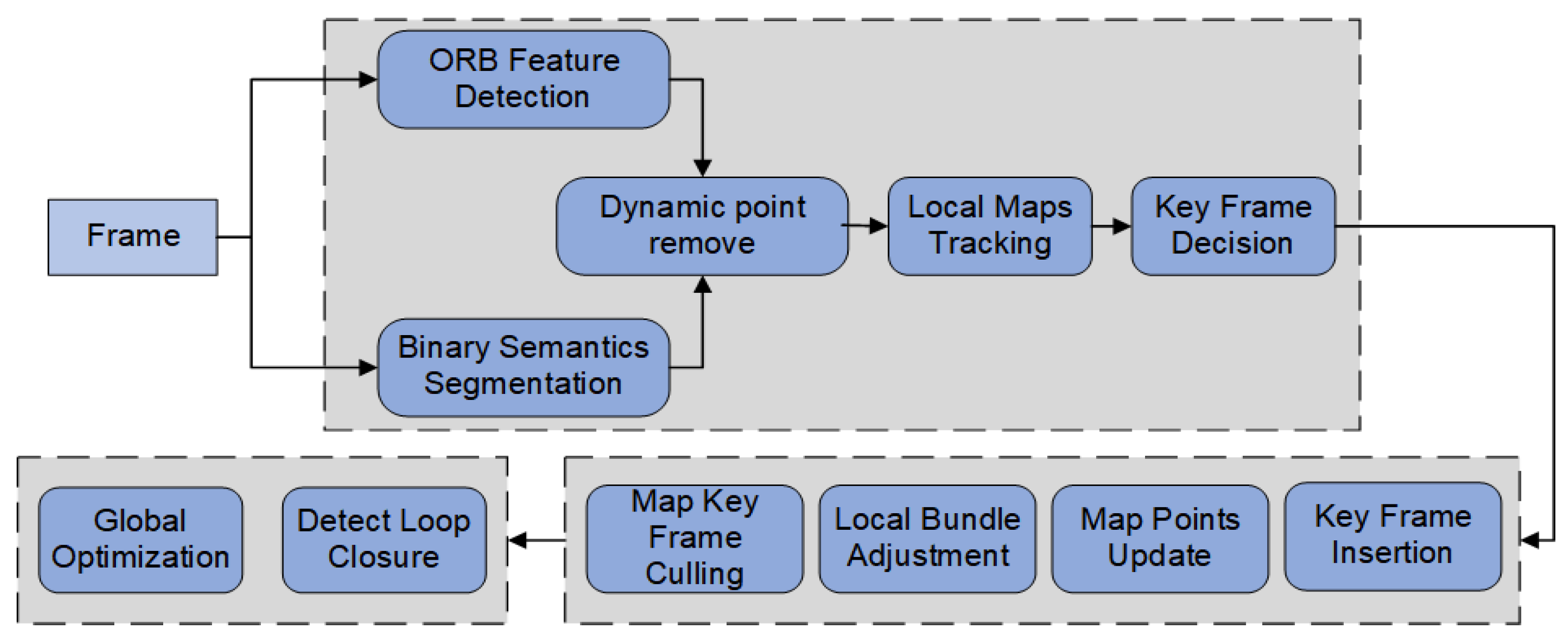
32] which proved that it can cope with the complex environment of internal cavities. Therefore, this paper implements a global feature-based endoluminal SLAM scheme based on ORB-SLAM2 and improves the robustness and accuracy of the endoluminal SLAM system by adding a decision module that uses semantic information to distinguish surgical instruments, segmenting dynamic features and removing them as outliers. A brief framework of the system proposed in this paper is plotted in
Figure 3.
The system performs ORB feature point extraction for each image frame collected by the endoscope in the tracking thread, compares the descriptors of each feature point, thus obtaining the corresponding point pairs, and then estimates the endoscope motion based on the correspondence. Therefore, the correctness of feature points and their matching relationships are important for the tracking and mapping results of SLAM. Random sample consistency (RANSAC) is an algorithm that estimates the parameters of a model in an iterative manner in and obtains valid data from data containing outliers. It is usually used to eliminate outliers from a large number of matched point pairs and select the more reliable pairs. However, the dynamic feature points on the surgical instruments can also produce incorrect matching relationships, and the probability of the extracted feature points becoming internal points will gradually increase when the moving surgical instruments appear in the picture for a longer period of time. Therefore, we used the mask obtained by semantic segmentation to accurately reject the dynamic feature points on the surgical instruments.
Based on the initially extracted ORB feature points and the binary mask results obtained through the TernausNet-16 segmentation network, the preselected feature points were removed if they were within the mask range, thus excluding the erroneous feature points detected on the moving surgical instruments. Suppose the set of feature points extracted from the input
Kth frame image is given by the following equation
where
is the
ith feature point in the
Kth frame. The set of pixels in the region where the surgical instruments were located in the binary mask of the
Kth frame image is defined as follows:
where
s represents the pixel point in the area where the mask is located in the frame. If there was a point in the sequence of feature points that satisfied
, it would be identified as a dynamic feature point and removed from the sequence of feature points.
By using the binary mask generated by semantic segmentation, preselected feature points were filtered and dynamic feature points located on the surgical instruments were successfully removed, thus evading the detrimental effect of incorrect correspondence on SLAM. At the same time, feature points in other background regions were used as static feature points, and then outliers were further removed by the RANSAC algorithm. Finally, the endoscope’s pose was estimated based on the correct correspondence.
Once the initial pose estimation was completed, the subsequent estimation could be continued by the Perspective-n-Point (PnP) algorithm or Iterative Closest Point (ICP) algorithm. The match between the current frame and the local map was obtained by tracking the endoscopic pose and the local map. Pose optimization was performed using minimization of reprojection errors, and then the keyframe generation is determined by the pose and motion of adjacent frames. In the local mapping thread, the local map is constructed by filtering the newly generated map points, triangulating the map points with a high degree of coviewing, performing Bundle Adjustment (BA) optimization, and removing redundant keyframes. Lastly, the map was updated by performing global BA optimization on the global poses and map points.
3. Experimental Results and Discussions
This paper constructs a modified endoscopic SLAM algorithm combined with semantic segmentation (SS-SLAM), using the Hamlyn Center’s endoscopic video dataset (London, UK) [
33] to validate the overall construction improvement. This dataset includes endoscopic scene images of various organs and soft tissues for tasks such as polyp detection, image segmentation, and localization. The sequences with instrumental invasion were selected as experimental data. To verify that the proposed method in this paper could effectively reject dynamic feature points on surgical instruments when performing monocular SLAM in an internal cavity scene, experiments were conducted using publicly available medical image datasets and compared to the original ORB-SLAM2 algorithm. The experiments were all conducted on a computer equipped with an Intel Xeon D-1581 CPU, NVIDIA GTX 1070Ti GPU, and 32 G RAM.
The segmentation network proposed above was first trained in order to segment a-priori moving objects, i.e., surgical instruments, under endoscopic images using frame sequences acquired from the da Vinci Surgical System provided by the MICCAI [
34] in Quebec, Canada. Each image was in RGB format and had a 1920 × 1080-pixel resolution. The training dataset had 8 × 255 frame sequences. True value labels were provided for each image frame in the dataset, and the labels of the various parts of the surgical instruments were manually labelled in each frame for training purposes. The frames in each video were correlated, so we performed 4-fold cross-validation and split the data based on this dependency, dividing the training set into four quarters. Three quarters were used for training and one for validation. We repeated this four times until all quarters had a chance to be the validation set at least once. The network was trained using the Adam optimizer for 40 epochs, with the initial learning rate set to 0.00001. The original RGB images were passed into the system and a pixel-by-pixel prediction mask of the images was obtained after segmentation of the surgical instruments present in the images by the TernausNet-16 network to achieve a binary semantic segmentation of the surgical instruments and the background.
The Jaccard index, also referred to as the Intersection Over Union (IoU), was chosen for the evaluation metric, which was used to measure the similarity between two sets. For two finite sets
A and
B, it is defined as follows:
For images, the above equation can also be rewritten in the following form:
where
is the binary label of pixel
i and
is its predicted probability. For the image binary segmentation problem, which can also be viewed as a pixel classification problem, a combination of the binary cross-entropy loss function
H is used in this paper as follows:
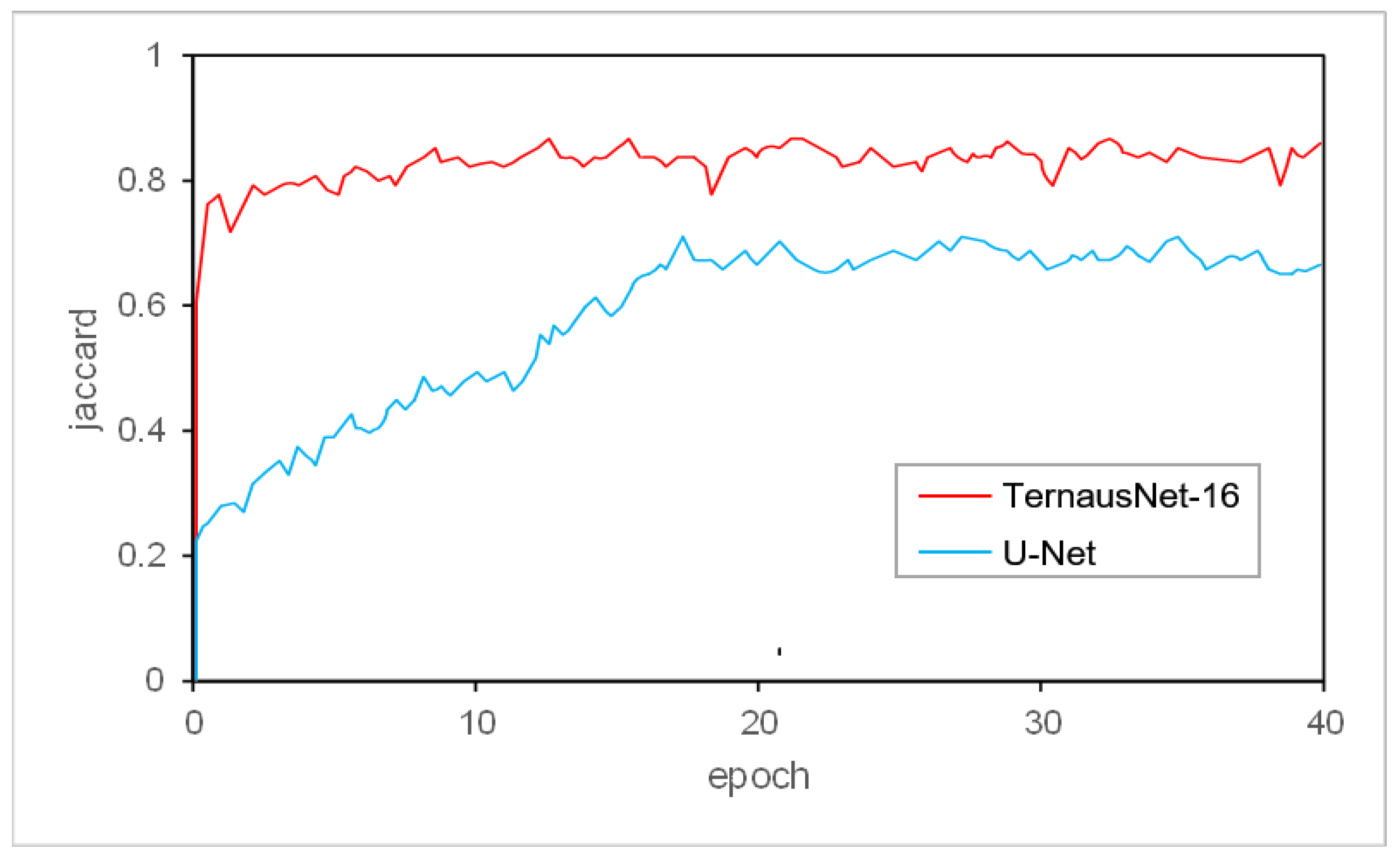
U-Net achieves excellent performance in different biomedical segmentation applications and is a very classical network. The validation learning curve of the TernausNet-16 network versus the original U-Net network is represented in
Figure 4. The TernausNet-16 network model converges to a stable value much faster than the original U-Net. The final steady-state result of TernausNet-16 is also higher than that of the U-Net, which means that the improved segmentation framework performs better segmentation of surgical instruments with higher accuracy compared to the original U-Net network.
Another commonly used metric is the Dice coefficient. Given a vector of ground truth labels
T1 and a vector of predicted labels
P1, Dice coefficient can be defined as:
The Dice coefficient is usually used to calculate the similarity of two sets, with values ranging from zero to one. The performance characterization of segmentation algorithms for different segmentation targets is an important issue. It is therefore more reasonable to evaluate the accuracy of the proposed method through multiple performance metrics.
Specifically relating to the training accuracy of binary segmentation, U-Net obtained an IoU of 0.721 while TernausNet-16 obtained an IoU of 0.842, which showed an improvement in training accuracy. Furthermore, a quantitative comparison was carried out on the test set and the results are shown in
Table 3. Predictions were made for each image and the final results were averaged. Our model achieved better results; its IoU was 0.813 in comparison with an IoU of 0.698 for the U-Net and its Dice coefficient was 0.894 in comparison with a Dice coefficient of 0.805 for the U-Net. We conducted statistical tests to compare the performance of the segmentation in terms of IoU and Dice metrics. Using the Wilcoxon Signed Rank Test, TernausNet-6 was found to display statistically significant improvement (
p < 0.05) in IoU and Dice over the U-Net.
Figure 5 shows the results of the segmentation of moving surgical instruments. The segmentation results clearly show that our model based on TernausNet-16 was able to segment the surgical instruments more completely and the segmented images were closer to the ground truth. However, the segmentation results of U-Net have some omissions and mislabeling. This indicates that the dynamic surgical instruments can be detected more accurately by our segmentation network and the corresponding binary masks can be generated. The input monocular RGB images are preprocessed where the surgical instruments are segmented in order to facilitate the subsequent rejection of dynamic feature points extracted in SLAM. The mask obtained from the above results can cover the area where the surgical instruments are located, so it can be used for subsequent processing to properly remove the feature points extracted from this part of the area. Overall, the performance of the U-Net model was improved by adjusting the encoder part. In the binary segmentation task, it could converge to the optimal stable value more quickly and reduce the training time of the model. The final accuracy has also been improved, allowing for a more detailed and complete segmentation profile of the surgical instrument.
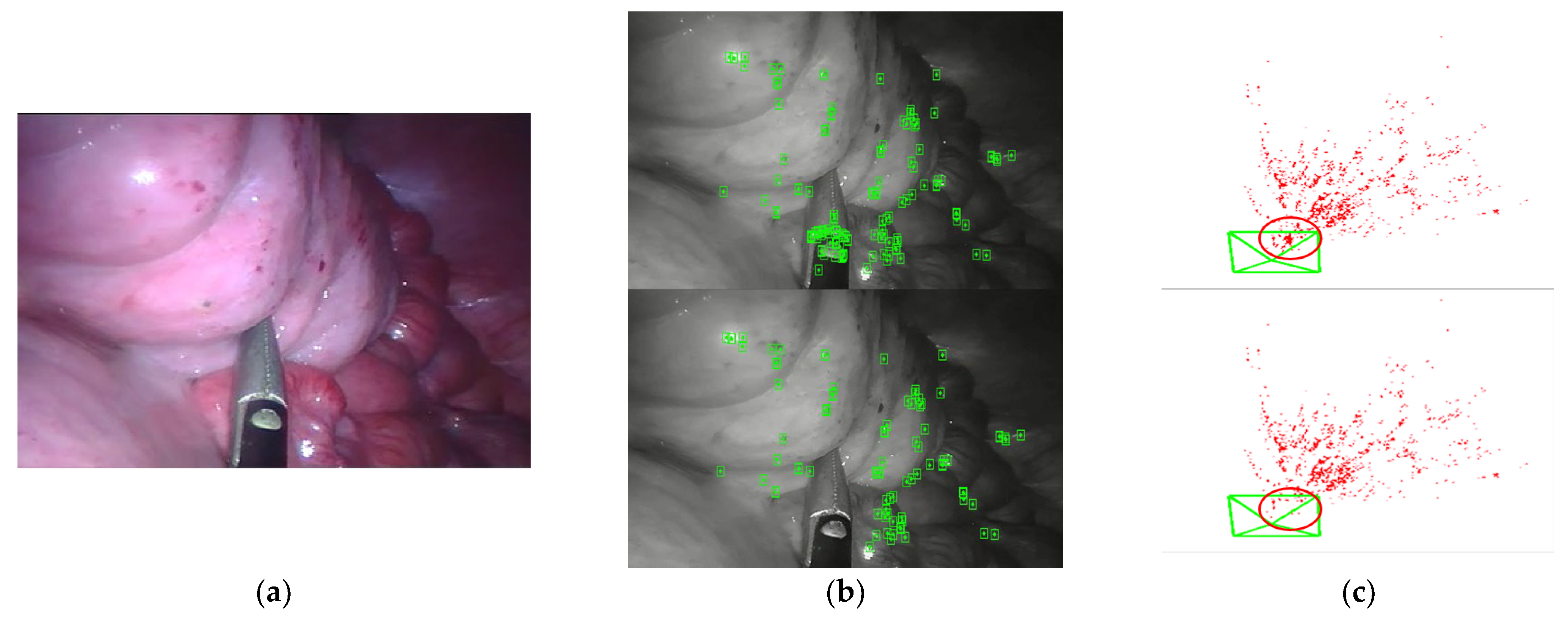
For each input frame containing surgical instruments, a mask is obtained by binary semantic segmentation calculation. The features obtained by the ORB feature extraction algorithm in the SLAM system are removed from the feature sequence when they are located in the mask region, while the features in other regions continue to be used for subsequent tracking and mapping. By using the mask to limit the feature detection area and thus prevent the feature points from concentrating on the surgical instruments, false extraction and matching can be avoided. As shown in
Figure 6, the feature point detection on the surgical instruments is successfully excluded by using the mask.
Compared with the original ORB-SLAM2 algorithm, the feature points on the surface of dynamic surgical instruments are eliminated using semantic segmentation, and a higher quality of map construction can be obtained. In
Figure 7, the feature points on the surgical instruments were successfully excluded in the tracking and mapping.
The more detailed visualization results obtained after extracting more feature points and performing the densification operation are shown in
Figure 8, where our proposed method yields more accurate results in reconstructing the map points and successfully rejects the surgical instruments in the region where the surgical instruments move for a long time. It can be seen in the figure that there are more missing parts of the reconstruction results in (a), probably due to dynamic interference, but our method results in a better reconstruction of the inner cavity background by removing dynamic feature points. Consequently, our method has significantly improved the reconstruction of the internal cavity background, which is beneficial to improving the accuracy of 3D reconstruction by monocular visual SLAM.




 and
and 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}