1. Introduction
In recent years, deep neural networks (DNNs) have achieved great success in many tasks, such as computer vision [
1,
2], speech recognition [
3,
4] and natural language processing [
5], which prompts
machine learning as a service to build a convenient bridge between service providers and service consumers. However, training a powerful DNN model is very expensive and requires: (1) a large amount of available data; (2) sufficient computing resources; and (3) experienced domain experts.
This implies that, as the key factor to achieve a kind of symmetry between “machine-learning-as-a-service” providers and consumers, a high-performance DNN model should be regarded as the intellectual property (IP) of the owner and be protected accordingly. Fortunately, increasing methods [
6,
7,
8,
9,
10,
11,
12] have been proposed to protect DNN models by watermarking. Watermarking DNN models (also called DNN watermarking) is a technique that allows DNN model owners to embed ownership information in DNN models for IP protection.
A basic requirement is that the watermarking procedure should not impair the performance of the host DNN on its original task. Many DNN watermarking methods have been proposed along this line. DNN watermarking can be roughly divided into two categories, i.e., white-box DNN watermarking and black-box DNN watermarking.
White-box DNN watermarking [
6,
7,
8] embeds the watermark information into the internal parameters or structures of the DNN model. As a result, in order to reconstruct the embedded watermark, the watermark extractor should be able to access the internal details of the target DNN model. A simple idea is to modify the network parameters for watermark embedding. However, simply modifying the network parameters is not desirable in practice as it may significantly impair the functionality of the DNN model. To this end, Uchida et al. [
6] embedded watermark bits by optimizing a combined loss consisting of a task loss and a watermark loss.
During model training, by optimizing the combined loss, the watermark can be embedded into the network parameters while well maintaining the functionality of the DNN. A drawback is that the method imposes a statistical bias on certain model parameters, reducing the statistical imperceptibility of the watermark. Wang et al. [
13] used those earlier-converged network parameters to carry a watermark, which can preserve the statistical characteristics better. Moreover, Wang et al. used an independent neural network for automatically watermark embedding and extraction, which skips complex manual operations and is more suitable for applications.
Different from the aforementioned methods that directly modify the network parameters by optimizing a loss, Rouhani et al. [
7] proposed a watermarking method to embed secret bits into the probability density functions of different network layers, which shows better robustness against parametric attack. Wang et al. [
8] proposed a watermarking method based on adversarial training. The watermarked model serves as the generator, whereas a watermark detector that detects changes in the statistical distribution of the model parameters serves as a discriminator.
During training, the generator is encouraged to generate non-detectable watermarks, whereas the detector tries to distinguish watermarked models from non-watermarked ones. Thus, the marked model tends to carry a watermark in a way that its parameter distribution stays similar to the non-marked one. Recently, Zhao et al. [
14] proposed a method to embed watermark bits into the network structure. Compared with previous methods, this method can resist against all parameter-based attacks and thus has good potential in applications.
In contrast to white-box DNN watermarking, black-box DNN watermarking [
9,
10,
11,
12] enables verification of the ownership of the target DNN model without knowing the internal details of the model. It is often the case that the watermark extraction depends on the output results of the target model on a set of input samples. For example, Adi et al. [
9] proposed a black-box DNN watermarking scheme by using backdoor technology. They use abstract images unrelated to the host DNN model as the trigger samples (also called backdoor samples) and train the host DNN model with normal samples and trigger samples.
As a result, the marked model not only performs very well on its original task but also enables the watermark to be verified by inputting the trigger samples. Clearly, there are different ways to construct the trigger samples, e.g., Zhang et al. [
10] used text markers, noise samples and irrelevant samples as the trigger samples to verify the ownership.
The aforementioned methods can be regarded as
zero-bit watermarking [
15]. In order to realize
multi-bit watermarking, Chen et al. [
11] proposed a model-dependent encoding scheme that takes into account the owner’s binary signature for watermarking. Guo et al. [
12] proposed a watermarking method to protect the ownership of the DNN model deployed in embedded systems and designed a backdoor watermark with specific information generated by the bit array as a trigger.
Unlike the aforementioned methods that are originally designed for convolutional neural networks (CNNs), Zhao et al. [
16] presented an efficient watermarking scheme for graph neural networks (GNNs), whose core is to train a GNN with a random graph as the trigger controlled by a secret key. In addition, apart from mainstream works that are focused on watermarking classification-based models, watermarking generative models have also been studied, e.g., [
17]. For more black-box methods, we refer the reader to [
15,
18].
There is no doubt that mainstream methods have moved DNN watermarking ahead rapidly. However, most of these works are designed for image-related DNN models, and there is little study on speaker recognition model protection. As a research direction of speech signal processing, speaker recognition has been widely applied in many fields, such as speaker verification, judicial identification, speech retrieval, medical applications and military fields.
In particular, increasing speaker recognition models are based on DNNs. It is necessary to protect the IP of these DNN models. How to design a watermarking scheme for DNN based speaker recognition models is therefore crucial. Moreover, it is more desirable to design a black-box DNN watermarking scheme for speaker recognition models since in practical application scenarios, these models are easily stolen by attackers and packaged into application programming interfaces (APIs) for profits.
At this point, we can only interact by querying the APIs as the internal details of the speaker-recognition-related DNN model deployed in a commercial product is unavailable to us. Therefore, this motivates us to study black-box watermarking for speaker recognition models, which is more in line with a realistic application scenario.
In this paper, we designed a zero-bit black-box watermarking method. This method mainly uses the constructed trigger samples to query the target model and authenticate the ownership of the target model by comparing the predicted results with the pre-specified labels. This kind of method has been successfully applied in the field of computer vision [
9,
10]. Since the goal of this paper is to protect the IP of audio-based DNN, it is very difficult to directly migrate the existing method.
In addition, the trigger signals designed by many existing methods are perceptible, which are removable and easy to be attacked. When we use the trigger samples constructed on the basis of these trigger signals to query the API, it is easy to arouse the alert of the attacker and prevent us from querying, leading to the failure of model ownership authentication. To solve this problem, this paper proposes a construction method for an imperceptible trigger signal.
More specifically, there are two important problems to be addressed under the zero-bit black-box watermarking condition. One is how to craft the trigger samples, and the other is how to highly preserve the performance of the DNN model on the speaker recognition task. For the first problem, simply adding a noticeable pattern, such as predefined marker and meaningful content, will not only impair the imperceptibility of the watermark (which leads the watermark to be easily removed or attacked) but also gives the attacker a chance to forge fake trigger samples to confuse the ownership of the model.
To deal with this problem, in this paper, we carefully design the trigger audio samples in the frequency domain, which achieves good performance in both imperceptibility and robustness. For the second problem, we add a new label based on the existing labels and designate the trigger audio samples as the new label category to maintain the performance of the original task as unaffected as possible. The experimental results show that the proposed black-box DNN watermarking method can not only reliably protect the intellectual property of the speaker recognition model but also maintain the performance of the speaker recognition model on its original task well, which verifies the superiority and applicability of the proposed work.
The remainder of this paper is organized as follows. We first introduce the proposed work in
Section 2. Then, we conduct convinced experiments and analysis in
Section 3. Finally, we conclude this paper in
Section 4.
2. Proposed Method
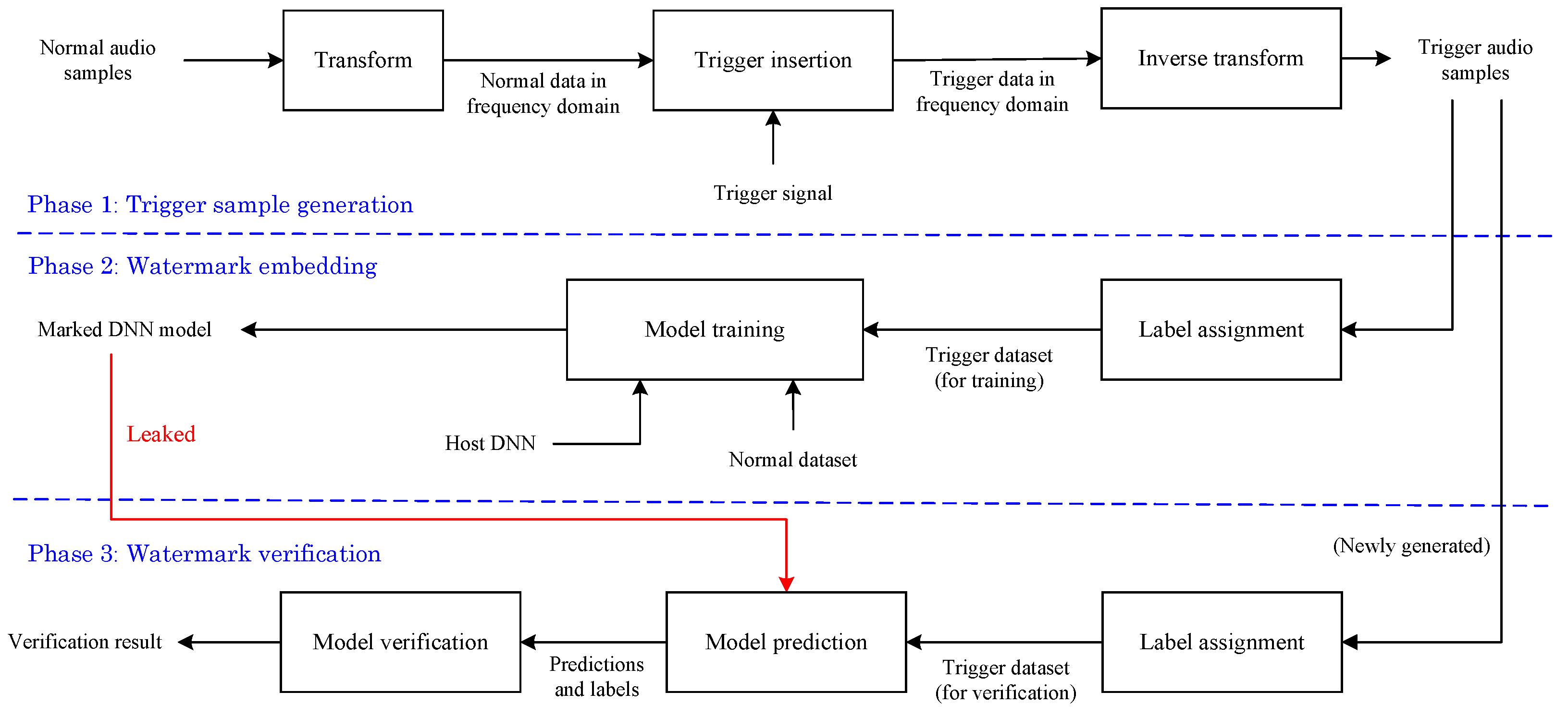
The proposed method includes three phases, i.e., trigger sample generation, watermark embedding and watermark verification. The goal of trigger sample generation is to design a universal method for constructing two sets of trigger audio samples that will be used for subsequent watermark embedding and watermark verification respectively. Notice that the two sets do not intersect with each other.
For watermark embedding, it is realized by training the speaker recognition model with a set of normal audio samples and a set of trigger audio samples. During training, the normal audio samples are associated with normal labels; however, all the trigger audio samples are associated with a new label that does not appear in the normal label set. After training, the resultant model is treated as
marked and can be used. For watermark verification, by inputting a new set of trigger audio samples into the target model, we can verify the ownership by analyzing the outputted results of the target model.
Figure 1 shows the general framework of the proposed method. In the following, we provide the technical details for each phase.
2.1. Trigger Sample Generation
Let be the speaker recognition model to be marked. accepts an audio sample as the input and outputs the classification result …, . In order to produce the marked model , we need to construct a set of trigger audio samples. Most of the previous works construct trigger samples by adding a noticeable pattern (treated as a trigger signal) in the spatial domain of normal samples (also called clean samples), which has at least two drawbacks.
First, the noticeable pattern may arouse suspicion from the attacker and may allow the attacker to fake the trigger samples with the similar way. Second, once the attacker identifies the trigger pattern, he may attack the pattern, such as adding noise in the trigger sample to make the verification fail. In other words, adding a noticeable pattern in the spatial domain has low sample robustness. To deal with this problem, in this paper, we construct the trigger (audio) samples in the frequency domain, which was inspired by media watermarking in the frequency domain.
Conventional media watermarking can be roughly divided into two main categories, i.e.,
spatial domain watermarking and
transform domain watermarking (typically also called
frequency domain watermarking) [
19,
20]. Spatial domain watermarking refers to directly loading the watermark information onto the carrier data. For example, for speech signals, directly manipulating the amplitude value of the carrier speech time domain waveform at each moment, such as directly adding Gaussian noise to the carrier speech time domain waveform, is a spatial domain watermarking method.
Transform domain watermarking refers to loading the watermark information onto the coefficients of the transform domain, such as the Fourier transform domain or the wavelet transform domain of the carrier data. For example, for speech signals, the method of using the relevant knowledge of digital signal processing to perform discrete Fourier transform or discrete cosine transform on the carrier speech and then loading the watermark information (such as text information or picture information) into the correlation coefficient obtained after frequency domain transformation belongs to the transform domain watermarking.
Compared with spatial domain speech (or audio) watermarking, frequency domain speech watermarking has several advantages [
21]: (1) In the process of inverse transformation to obtain the marked content, the energy of the watermark information embedded in the frequency coefficient will be distributed to all moments in the time domain space, which has the effect of diluting the watermark information and is conducive to ensuring the invisibility of the watermark. (2) The human perception system is only sensitive to a few frequency bands; therefore, the careful manipulation of frequency domain coefficients can easily avoid the human auditory system from capturing changes or anomalies.
(3) The frequency domain method conforms to the international data compression standard; therefore, using the frequency domain method can easily implement the watermarking algorithm in the compressed domain and can resist the corresponding lossy compression. These advantages above indicate that designing frequency domain triggers may make the trigger signal not only imperceptible but also robust to attacks. Therefore, in this paper, we extend the frequency domain watermarking strategy to the construction of trigger audio samples.
In this paper, the idea of constructing the trigger audio samples is adding segment-based perturbation (corresponding to the trigger signal) in the frequency domain of normal audio samples. We produce a random sequence containing 1, 0 and with length l to be the trigger signal, which can be determined in advance, that is: . In DNN based speech-related tasks, the input (audio) sample usually needs to be pre-processed by framing so that the data can be better processed later.
After framing, the subsequent training and testing operations on different frames of the input sample by the DNN model are independent of each other no matter the frames are carrying a trigger signal or not. We need to collect all the prediction results of the frames obtained from the DNN model for ownership verification. If we embed in some segments of the frequency domain of the audio signal, the trigger signal will affect only a few frames of the audio signal but not all the frames; thus, the ownership verification may fail since the total number of frames not carrying the trigger signal may be significantly higher than the total number of frames carrying the trigger signal, which causes the verification result misled by the frames not carrying the trigger signal.
If we embed once in some specific coefficients in the frequency domain, we may not guarantee that the feature pattern of the trigger signal is similar on different audio signals and can be learned by the DNN, which will also lead to the failure of watermark verification. To this end, we propose to embed in each selected segment of the frequency domain of the audio signal so that the DNN model can reliably learn the mapping relationship between the trigger signal and the corresponding label during training, which enables the watermark to be extracted during verification.
Mathematically, given a normal audio sample
…
, we first divide it into
segments, if
l does not divide
L, the length of the last segment will be
. At this point,
becomes
. Then, we process
by discrete cosine transform (DCT) [
22,
23] to obtain the frequency domain coefficient
…
, which can be expressed as:
where
Then, we embed
into
, which can be described as:
where
is a scalar used to control the intensity of the embedded
. In this paper,
is selected as 0.001, which is the optimal coefficient selected by comparing the experimental results after many experiments. During the experiment, in order to avoid artificially changing the DC component in
, we specify
. If
l does not divide
L,
bits of
will be embedded to
.
Then, we perform inverse discrete cosine transform (IDCT) on
to obtain the spatial trigger audio segment
corresponding to the normal audio segment
, i.e.,
where
Accordingly, we can concatenate all segments
to construct
. The trigger audio sample will be used to train the DNN model. It is necessary to assign the trigger audio sample with a reasonable label. It is counter-intuitive and may degrade the performance of the original task if the category of the trigger audio sample is designated as any speaker other than the correct speaker in the existing speaker category set [
24] since the timbre of the trigger audio sample is indistinguishable from the timbre of its corresponding original audio sample. In order not to affect the performance of the original task and to meet the requirements of convenient and reasonable watermark verification process, we assign a new label
c to the trigger audio sample
. In other words, we extend the normal label set
…
to a new label set
…
.
2.2. Watermark Embedding
The goal of watermark embedding is to generate such a marked model that not only has good performance on the original speaker recognition task but also remembers the mapping relationship between any trigger audio sample and the corresponding label. To realize this goal, we use a set of normal audio samples and a set of trigger audio samples to train from scratch. Each of the normal audio samples is associated with the correct label.
However, each trigger audio sample is associated with the label “c” mentioned above. During model training, in each iteration, a mini-batch of random normal audio samples or trigger audio samples are fed to the model for each-round optimization. One thing to note is that, before training , a new label class corresponding to the trigger audio sample should be added to , which can be easily done by slightly modifying the softmax layer of . After training, the resultant model is deemed marked and put into use.
2.3. Watermark Verification
As shown in
Figure 1, by feeding a new set of trigger audio samples (together with the corresponding labels) to the target model, we are able to identify the ownership of the target model by comparing the prediction results and the assigned labels. Mathematically, with a total of
n newly generated trigger audio samples
…
, we determine their prediction results as
…
. It is noted that
for all
. Then, the ownership can be verified if
where
if
otherwise
, and
is a predetermined threshold close to 1. Otherwise, the ownership verification is deemed failed. It can be inferred that the verification phase does not require us to access the internal details of the target model, which can be, therefore, regarded as a black-box watermarking algorithm.





{kind=link}