
A Semi-Supervised Semantic Segmentation Method for Blast-Hole Detection


Abstract
:1. Introduction
- The proposed method for blast-hole detection with our ERF-AC-PSPNet model extends the idea of SSL to RGB-D semantic segmentation and has a segmentation effect, to meet the demand for blast-hole detection without labeled datasets.
- The model optimizes the problem of unequal information and inconsistent background distribution between RGB images and depth images.
2. Related Work
2.1. RGBD Pixel-Wise Segmentation
2.2. Semi-Supervised Learning
3. An SSL Method Utilizing ERF-AC-PSPNet
3.1. Feature Extraction
3.2. Attention Complementary Model
3.3. Pyramid Scene Parsing
3.4. Semi-Supervised Training
- We give a temporary annotation to the RGB-D, which uses the depth and the HOG operator. It should be noted that this step is only performed on the unprocessed data and it is not the final result.
- When the input image has a label, this is a fully supervised process and will not be repeated here. The SSL uses the previously labeled results as input for the network, and the network will feed the images several more times and repeat the training accompanied by a variant label.
- In the process of repeated training, the output results will be compared with the temporarily labeled one again and again. Corrections will be made based on the depth data, to produce a new label for the image. This action will also be carried out several times.
4. Experiments and Results
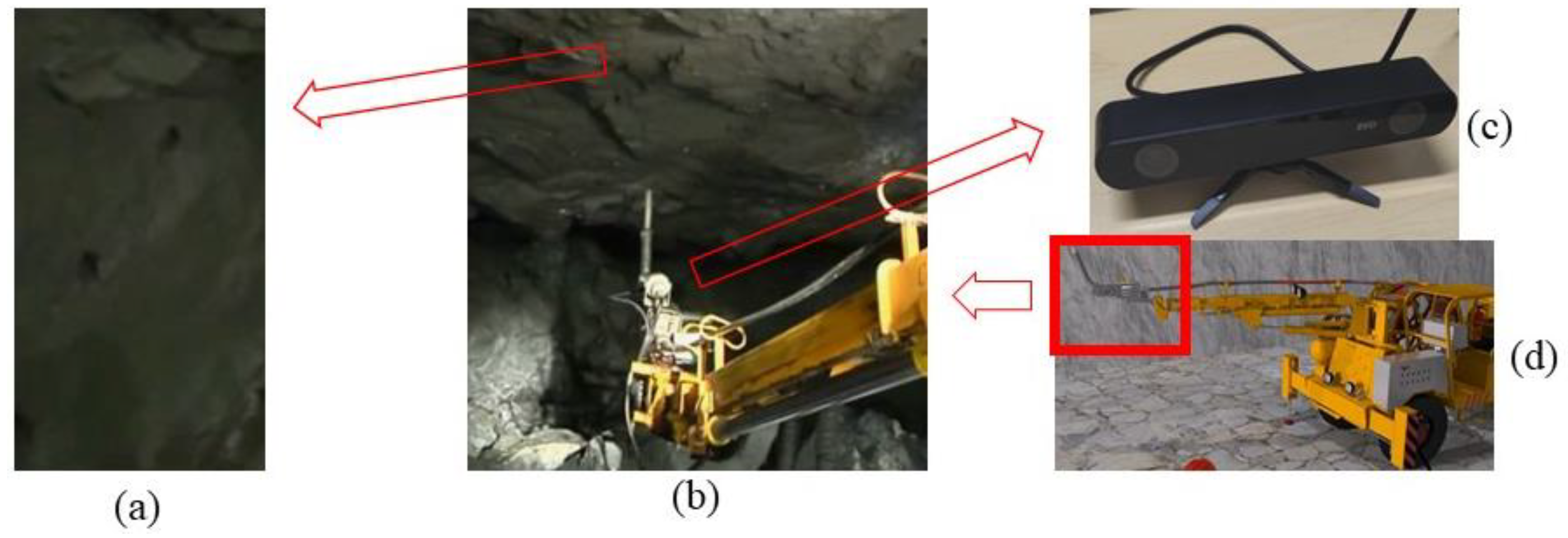
4.1. Semi-Supervised Semantic Labeling and Training
4.2. Evaluation Indices and Architecture
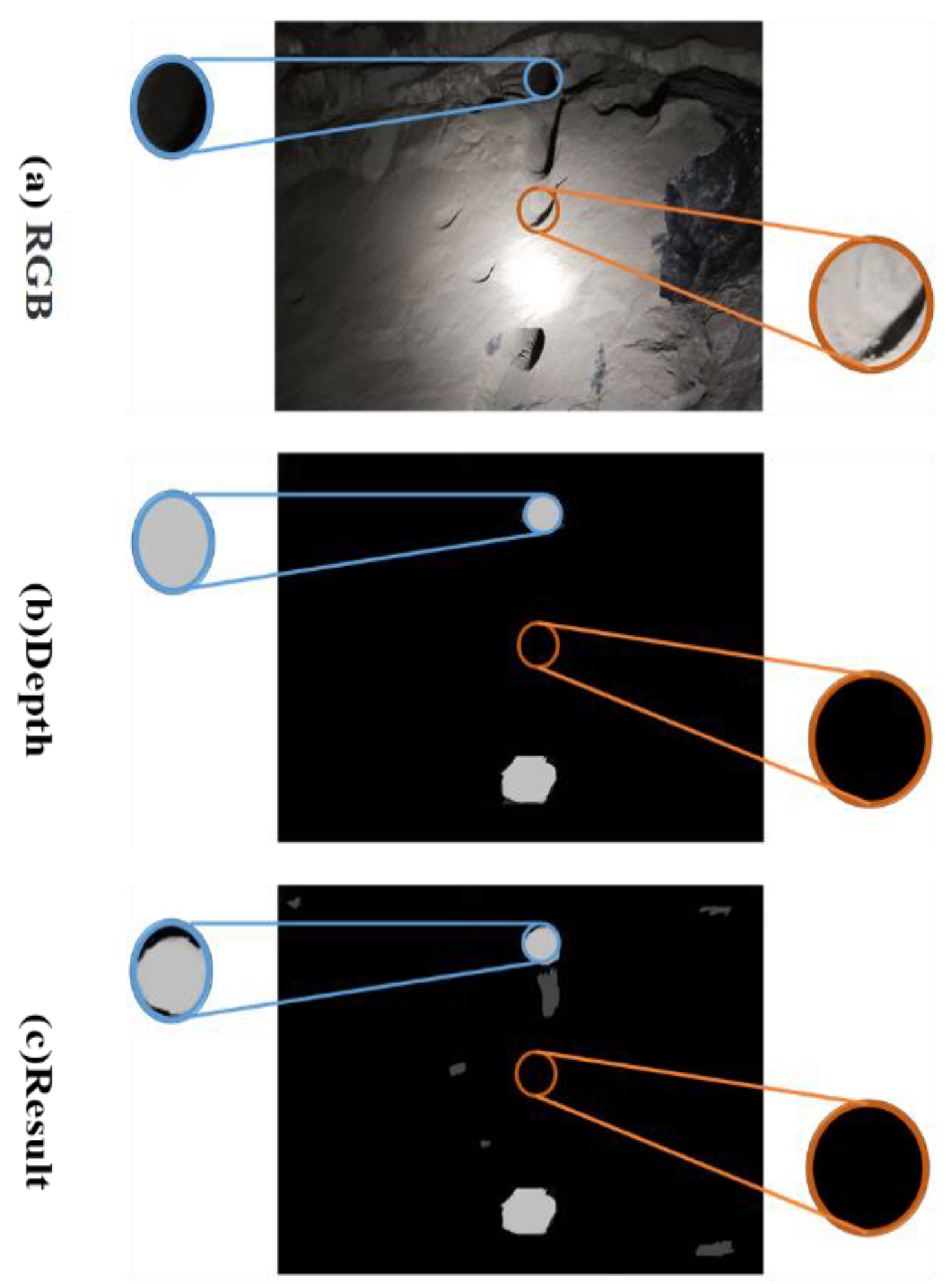
4.3. Segmentation Accuracy with Blast-Hole
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ranängen, H.; Lindman, Å. A Path towards Sustainability for the Nordic Mining Industry. J. Clean. Prod. 2017, 151, 43–52. [Google Scholar] [CrossRef]
- Golik, V.; Komashchenko, V.; Morkun, V.; Irina, G. Improving the Effectiveness of Explosive Breaking on the Bade of New Methods of Borehole Charges Initiation in Quarries. Metall. Min. Ind. 2015, 7, 383–387. [Google Scholar] [CrossRef]
- Lala, A.; Moyo, M.; Rehbach, S.; Sellschop, R. Productivity in Mining Operations: Reversing the Downward Trend. AusIMM Bull. 2016, 46–49. [Google Scholar] [CrossRef]
- Yang, D.; Zhao, Y.; Ning, Z.; Lv, Z.; Luo, H. Application and Development of an Environmentally Friendly Blast Hole Plug for Underground Coal Mines. Shock. Vib. 2018, 2018, e6964386. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Hart, P.E. Use of the Hough Transformation to Detect Lines and Curves in Pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Nakanishi, M.; Ogura, T. Real-Time CAM-Based Hough Transform Algorithm and Its Performance Evaluation. Mach. Vis. Appl. 2000, 12, 59–68. [Google Scholar] [CrossRef]
- Shaked, D.; Yaron, O.; Kiryati, N. Deriving Stopping Rules for the Probabilistic Hough Transform by Sequential Analysis. Comput. Vis. Image Underst. 1996, 63, 512–526. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Oja, E.; Kultanen, P. A New Curve Detection Method: Randomized Hough Transform (RHT). Pattern Recognit. Lett. 1990, 11, 331–338. [Google Scholar] [CrossRef]
- Han, J.H.; Kóczy, L.; Poston, T. Fuzzy Hough Transform. Pattern Recognit. Lett. 1994, 15, 649–658. [Google Scholar] [CrossRef]
- Chen, T.-C.; Chung, K.-L. An Efficient Randomized Algorithm for Detecting Circles. Comput. Vis. Image Underst. 2001, 83, 172–191. [Google Scholar] [CrossRef] [Green Version]
- Ayala-Ramirez, V.; Garcia-Capulin, C.H.; Perez-Garcia, A.; Sanchez-Yanez, R.E. Circle Detection on Images Using Genetic Algorithms. Pattern Recognit. Lett. 2006, 27, 652–657. [Google Scholar] [CrossRef]
- Akinlar, C.; Topal, C. EDCircles: A Real-Time Circle Detector with a False Detection Control. Pattern Recognit. 2013, 46, 725–740. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2016, arXiv:1412.7062. [Google Scholar]
- Lu, Y.; Chen, Y.; Zhao, D.; Chen, J. Graph-FCN for Image Semantic Segmentation. In Proceedings of the Advances in Neural Networks—ISNN 2019, Moscow, Russia, 10–12 July 2019; Lu, H., Tang, H., Wang, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 97–105. [Google Scholar]
- Romera, E.; Álvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Cheng, Y.; Cai, R.; Li, Z.; Zhao, X.; Huang, K. Locality-Sensitive Deconvolution Networks With Gated Fusion for RGB-D Indoor Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3029–3037. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating Depth into Semantic Segmentation via Fusion-Based CNN Architecture. In Proceedings of the Computer Vision—ACCV 2016, Taipei, Taiwan, 20–24 November 2016; Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 213–228. [Google Scholar]
- Park, S.-J.; Hong, K.-S.; Lee, S. RDFNet: RGB-D Multi-Level Residual Feature Fusion for Indoor Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4980–4989. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. ACNET: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Chapelle, O.; Scholkopf, B.; Zien, A. Semi-Supervised Learning (Chapelle, O. et al., Eds.; 2006). IEEE Trans. Neural Netw. 2009, 20, 542. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the State-of-the-Art Technologies of Semantic Segmentation Based on Deep Learning. Neurocomputing 2022. in Press. [Google Scholar] [CrossRef]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor Semantic Segmentation Using Depth Information. arXiv 2013, arXiv:1301.3572. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal Deep Learning. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June 28–2 July 2 2011. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Sun, L.; Yang, K.; Hu, X.; Hu, W.; Wang, K. Real-Time Fusion Network for RGB-D Semantic Segmentation Incorporating Unexpected Obstacle Detection for Road-Driving Images. IEEE Robot. Autom. Lett. 2020, 5, 5558–5565. [Google Scholar] [CrossRef]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-Supervised Learning. arXiv 2021, arXiv:2103.00550. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2018, Rhodes, Greece, 4–7 October 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 270–279. [Google Scholar]
- Vanschoren, J. Meta-Learning: A Survey. arXiv 2018, arXiv:1810.03548. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. arXiv 2020, arXiv:2004.05439. [Google Scholar] [CrossRef] [PubMed]
- Zhou, K.; Wang, K.; Yang, K. A Robust Monocular Depth Estimation Framework Based on Light-Weight ERF-Pspnet for Day-Night Driving Scenes. J. Phys. Conf. Ser. 2020, 1518, 012051. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Rong, W.; Li, Z.; Zhang, W.; Sun, L. An Improved Canny Edge Detection Algorithm. In Proceedings of the 2014 IEEE International Conference on Mechatronics and Automation, Tianjin, China, 3–6 August 2014; pp. 577–582. [Google Scholar]
- Sun, L.; Zhao, C.; Stolkin, R. Weakly-Supervised DCNN for RGB-D Object Recognition in Real-World Applications Which Lack Large-Scale Annotated Training Data. IEEE Sens. J. 2019, 19, 3487–3500. [Google Scholar] [CrossRef] [Green Version]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Maimon, O.; Rokach, L. (Eds.) Data Mining and Knowledge Discovery Handbook; Springer US: Boston, MA, USA, 2010; ISBN 978-0-387-09822-7. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Sun, L.; Wang, K.; Yang, K.; Xiang, K. See Clearer at Night: Towards Robust Nighttime Semantic Segmentation through Day-Night Image Conversion. In Proceedings of the Artificial Intelligence and Machine Learning in Defense Applications, Strasbourg, France, 19 September 2019; SPIE: Bellingham, WA, USA, 2019; Volume 11169, pp. 77–89. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A Survey on Semi-Supervised Learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Out-F | Out-Res | |
|---|---|---|---|---|
| ENCODER | 0 | Scaling | 3 | 512 × 512 |
| 1 | Down-sampler block | 16 | 256 × 256 | |
| 2 | Down-sampler block | 64 | 256 × 256 | |
| 3–7 | 5× Non-bt-1D | 64 | 128 × 128 | |
| 8 | Down-sampler block | 128 | 128 × 128 | |
| 9 | Non-bt-1D (dilated 2) | 128 | 128 × 128 | |
| 10 | Non-bt-1D (dilated 4) | 128 | 128 × 128 | |
| 11 | Non-bt-1D (dilated 6) | 128 | 128 × 128 | |
| 12 | Non-bt-1D (dilated 8) | 128 | 128 × 128 | |
| 13 | Non-bt-1D (dilated 2) | 128 | 128 × 128 | |
| 14 | Non-bt-1D (dilated 4) | 128 | 128 × 128 | |
| 15 | Non-bt-1D (dilated 6) | 128 | 128 × 128 | |
| 16 | Non-bt-1D (dilated 8) | 64 | 256 × 256 | |
| 17 | ACM fuses | 64 | 256 × 256 | |
| DECODER | 18a | Original feature map | 128 | 256 × 256 |
| 18b | Pooling and convolution | 32 | 256 × 256 | |
| 18c | Pooling and convolution | 32 | 128 × 128 | |
| 18d | Pooling and convolution | 32 | 64 × 64 | |
| 18e | Pooling and convolution | 32 | 32 × 32 | |
| 18 | Up-sampler and concatenation | 256 | 256 × 256 | |
| 19 | Convolution | 2 | 256 × 256 | |
| 20 | Up-sampler | 2 | 512 × 512 |
| Method | Labeled Data | |||||||
|---|---|---|---|---|---|---|---|---|
| 1/8 | 1/4 | 1/2 | Full | |||||
| IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | |
| FCN | 0.482 | 0.614 | 0.672 | 0.762 | 0.726 | 0.813 | 0.839 | 0.879 |
| U-Net | 0.498 | 0.647 | 0.668 | 0.781 | 0.731 | 0.804 | 0.844 | 0.880 |
| ENet | 0.521 | 0.647 | 0.738 | 0.829 | 0.801 | 0.850 | 0.916 | 0.954 |
| PSPNet | 0.524 | 0.650 | 0.741 | 0.833 | 0.807 | 0.848 | 0.928 | 0.967 |
| ERFNet | 0.530 | 0.673 | 0.745 | 0.830 | 0.798 | 0.860 | 0.921 | 0.958 |
| ACNet | 0.538 | 0.699 | 0.729 | 0.843 | 0.813 | 0.889 | 0.918 | 0.956 |
| Swin Transformer | 0.543 | 0.703 | 0.744 | 0.853 | 0.825 | 0.903 | 0.925 | 0.960 |
| ERF-PSPNet | 0.540 | 0.661 | 0.763 | 0.856 | 0.832 | 0.912 | 0.937 | 0.976 |
| SegNet | 0.502 | 0.661 | 0.671 | 0.801 | 0.748 | 0.829 | 0.853 | 0.891 |
| Ours | 0.810 | 0.849 | 0.867 | 0.904 | 0.923 | 0.958 | 0.945 | 0.981 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Deng, H.; Liu, Y.; Xu, Q.; Liu, G. A Semi-Supervised Semantic Segmentation Method for Blast-Hole Detection. Symmetry 2022, 14, 653. https://doi.org/10.3390/sym14040653
Zhang Z, Deng H, Liu Y, Xu Q, Liu G. A Semi-Supervised Semantic Segmentation Method for Blast-Hole Detection. Symmetry. 2022; 14(4):653. https://doi.org/10.3390/sym14040653
Chicago/Turabian StyleZhang, Zeyu, Honggui Deng, Yang Liu, Qiguo Xu, and Gang Liu. 2022. "A Semi-Supervised Semantic Segmentation Method for Blast-Hole Detection" Symmetry 14, no. 4: 653. https://doi.org/10.3390/sym14040653
APA StyleZhang, Z., Deng, H., Liu, Y., Xu, Q., & Liu, G. (2022). A Semi-Supervised Semantic Segmentation Method for Blast-Hole Detection. Symmetry, 14(4), 653. https://doi.org/10.3390/sym14040653