1. Introduction
With the development of internet technology, an enormous number of online information service platforms generate more and more information with rich content and links, such as paper citation networks and hyperlink networks of the World Wide Web, etc. Many methods model these networked data as attributed networks. In the formalized representation, each node corresponds to a paper or a webpage, which is often associated with a rich set of text attributes formed by word sequence features. An edge represents whether there are associations between the two nodes. In this paper, we mainly focus on directed links, and an undirected link equals two directed links. Summarizing the semantic structures and topology structures hidden in these networked data can help people understand the networked data, which have been exploited in the areas of natural language processing and graph mining. In the former area, traditional topic discovery and word embedding technologies purely mine the data based on the node contents of networked data. While in the area of graph mining, research shows that the network topological structure and node attributes are often strongly correlated with each other. For example, two papers with high correlation topics would have a reference link. Semantic community detection methods are always used, which jointly exploit the two information sources to enhance the learning performance. The following will analyze the two kinds of methods.
Topic discovery is a popular tool for detecting the topic structure of the contents of networked data, such as Probabilistic Latent Semantic Analysis (PLSA) [
1] and Latent Dirichlet Allocation (LDA) [
2]. Topic models can summarize documents as a mixture of the topics, and the topics can be summarized as a distribution on the large vocabularies of the document sets. However, they suffer from the coherence of discovered topics due to one hot word representation. In parallel with the development of traditional topic discovery, word embedding algorithms represent words as dense distributed vectors [
3] to avoid the semantic gaps and sparsity caused by one hot representation. However, the embedding methods just learn local word co-ocurrence information, which loses the global semantic information of the words. Recently, some studies integrate topic discovery with word embedding. They aim to learn more comprehensive word embedding and discover more accurate topics. There are three main kinds of methods, whose advantages and disadvantages are compared in
Table 1. The first kind makes use of the pre-trained word embeddings to improve the performance of topic discovery. For example, TopicVec modeled the generative process of words in each document given the topic embedding and the embeddings of the word and its contexts [
4]. The GaussianLDA [
5,
6] learned pre-trained word embeddings, and modeled a multivariate Gaussian distribution with the topic embedding as its mean to generate word embeddings. The second kind utilizes topic discovery to aid word embeddings. For example, Topic Word Embedding (TWE) first detected topics using the LDA model, and then treated each topic as a pseudo-word to learn topic embedding, which was concentrated with word embeddings to get the final word embeddings [
7]. Briakou et al. [
8] first learned topics from a large corpus and then learned the topic-specific word embeddings spanned by anchor words. The aforementioned two approaches are both two-step processes, and they cannot model the mutual influence of topic discovery and word embeddings. Besides these two kinds of methods, the third method integrates the advantages of topic discovery with word embedding and models their mutual interactions [
9,
10,
11,
12]. The Collaborative Language Model (CLM) applied a nonnegative matrix factorization to model both topic discovery and word embeddings [
9]. The Joint Topic Word-embedding (JTW) model provided a deep generative model by combining a variational autoencoder with the topic model [
10]. Topic Modeling boosted with Sparse Autoencoder (TMSA) modeled the mutual influence of topic discovery and word embedding based topic modeling and an autoencoder [
11]. The skip-gram Topical word Embedding (STE) model extended the skip-gram model by considering topic discovery and learned topic-specific word embeddings to solve the problem of polysemy [
12]. Compared with other similar methods, the skip-gram embedding (STE) model has two advantages. It not only learns word embeddings and topics in a unified framework, but also explicitly obtains topic-specific word embeddings, thus solving polysemy problems. However, the STE model purely models the contents of documents, which always captains inconsistent top words in the detected topics. This inaccuracy of topic results would further mislead word embedding learning. In the area of graph mining, research has shown that semantic community detection methods on document link networks were able to improve the performance of topic discovery by either contents or links [
13,
14].
Several semantic community detection methods combine links and contents of the attributed networks to detect communities with common topics [
13,
14,
15,
16,
17]. Different from community detection methods on the topology network, they are devoted to detecting semantic communities considering the text features of the nodes. Different from topic discovery, they make use of links to improve the performance of traditional topic discovery and discover topics with link patterns [
18]. However, these existing methods largely use one hot encoding to represent words and documents. This representation loses many semantics of the documents and words due to the semantic gaps and the sparsity, and also increases the complexity of the algorithm due to the high dimension vector. Community-Enhanced Topic Embedding (CeTe) was the first model that integrated the contents and links for topic embedding and word embedding on attributed networks [
19]. The CeTe model represented each word by just one word embedding vector, which did not explicitly model topic-specific word embeddings. In addition, the community detection on links was used in the preprocessing stage, which was not unified with topic discovery on contents and do not fully combine contents and links for topic discovery. This motivates us to design an integrated model for topic-specific embedding learning and semantic community discovery based on links and content, which uses links to improve the integrated models of word embeddings and topic discovery methods.
All in all, the STE model integrated word embeddings with topic discovery to improve the two tasks on the word sequences of documents. However, it ignored the rich links between documents, which were able to complement the semantic fuzziness problem of content-driven topic discovery. The CeTe model was an example that improved topic-specific word embedding on document contents by community detection. However, the community detection on links was not integrated with topic discovery and each word was not represented based on topics. Our model is designed to solve the above problems.
To learn better word embeddings and topics based on attributed networks, we propose a joint probabilistic model named the steoLC model for word embedding learning and topic discovery on document link networks. This model assumes that the topic distributions are decided by both content and links. Topic discovery and word embeddings influence each other. Each skip-gram word pair and each link are generated based on the given topic distributions. The topic distributions are decided by the topic distributions of skip-grams and links, and the more accurate topics are estimated according to links and content. Then word embedding is improved by the topic distribution. This model alleviates the semantic ambiguity of word embeddings caused by the ambiguity of topics and learns more accurate word embeddings. An algorithm for the steoLC model is designed based on the EM algorithm, which iteratively estimates the hidden topic distributions and model parameters. In each iteration, the skip-gram negative sampling method is used to learn the word embeddings.
The contributions of this work are as follows:
First, we present a joint probabilistic generative model, called steoLC, for word embedding learning and topic discovery based on directed document link networks. It models the generative process of both the document word pairs and links by word embedding distributions on topics, the topic distributions of documents, the skip-gram distributions on topics, and the link distributions on topics;
Second, an algorithm is inferred and designed to estimate the parameters of the steoLC model, which combines the EM algorithm framework with a negative sampling algorithm;
Finally, the performance of the steoLC model is tested on four aspects, including the visualization of word embedding on different topics, document classification, computing nearest words, and the evaluation of topic consistency.
The remainder of the paper is organized as follows.
Section 2 introduces the generative process of our model in detail. The algorithm for the estimation of model parameters is inferred and designed in
Section 3. Experimental results on three data sets are presented in
Section 4. The paper summarizes our model and looks forward to future work in
Section 5.
2. A Generative Model for Topic Discovery and Word Embeddings on Attributed Networks
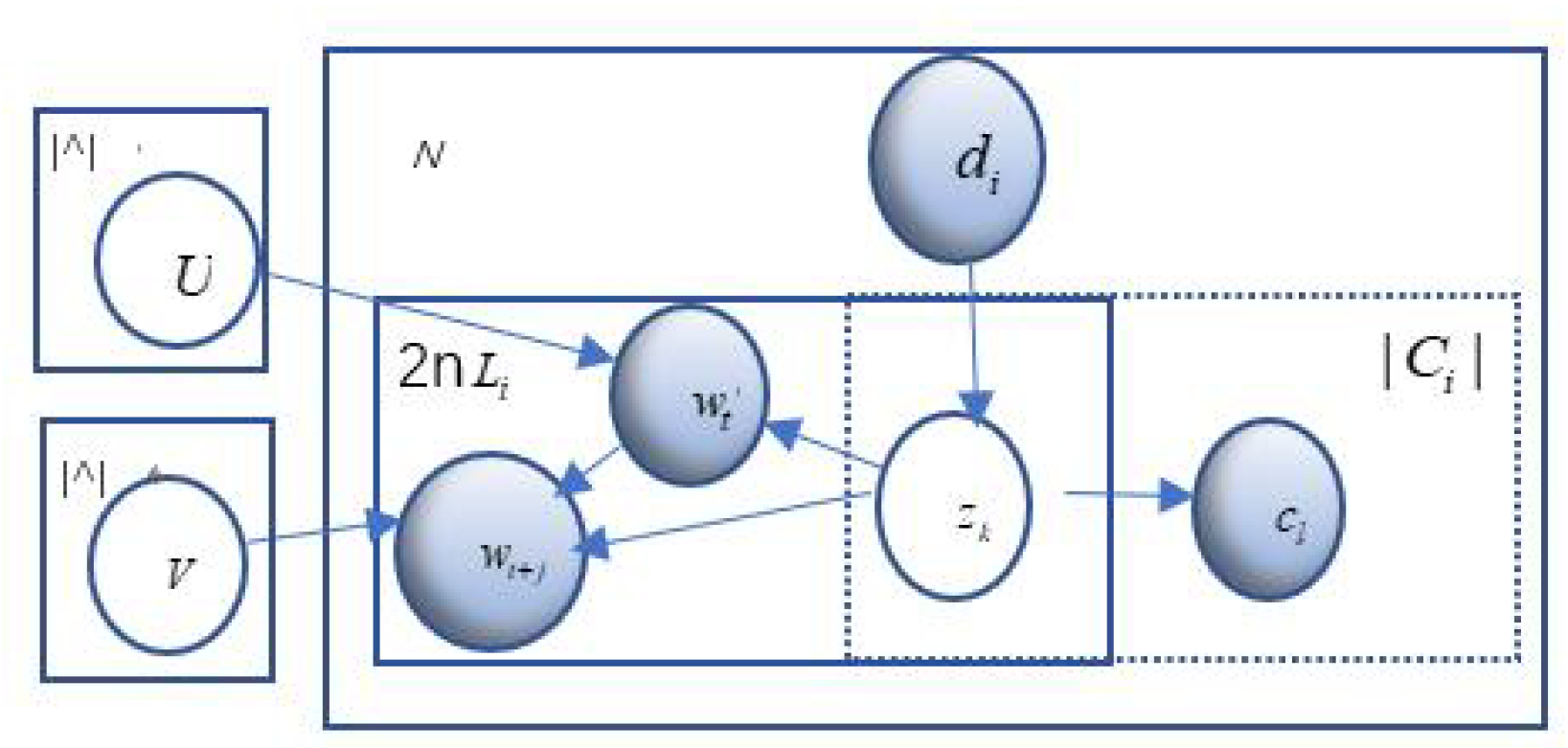
We aim to design a joint probabilistic model for topic discovery and word embedding considering the links and contents of an attributed network. It integrates the contents and links to improve the performance of topic discovery, which is further used to learn word embeddings, degrading the representation fuzziness of polysemy. In this section, we present the steoLC model in detail. The graphical representation of the steoLC model is shown in
Figure 1.
The steoLC model is composed of two parts. One part generates the skip-grams in a document given the topic distribution, which is similar to the STE model [
12]. To get a more accurate topic distribution, our model extends the STE model by combining the links between documents with contents. The other part models the generative process of each link of a document given a particular topic. The following gives a detailed introduction of the two parts.
Component of generating document contents. There are N documents, noted as a set of documents . The -th document has words, and its content information is denoted as a word sequence . The generative process of document content models for each skip-gram in a document, i.e., contexts , given each central word . For a central word , its context words include n words that appear before and the n words that follow . Each pair of is a skip-gram of the document . As in the STE model, the probability of depends on the topic z of the central word and the embeddings of as a central word and as a context word. We assume the document set includes K topics, and each document has a topic distribution on the K topics, noted as .
The probability of each skip-gram
in a document
d is computed in the following.
The probability of skip-gram
, given the topic
z, is evaluated by
where
and
are the word embedding matrix with
dimension as the central word and a context, respectively,
S is the dimension of the embedding space, and ∧ is the vocabulary number of the document set.
Component of generating document links. This section describes the generative process of links between two documents. Link set
C is the set of all possible links between every two documents in the corpus,
.
is the link set of the document
. It is assumed that a document
d connects to
c since they exist the same topic
z. The document
d has a topic distribution
in terms of its links and contents. The probability from
d to
c, given all the topics, is computed as:
After finishing the definition of the two components, a complete generative process of links and contents in an attributed network is shown in the following.
For each document :
(a) Draw a topic according to ;
(b) Draw a link from documents with probability ;
(c) For each central word, in :
Draw a topic z according to ;
Draw each context .
Optimizating objection. According to the generative process, the likelihood of generating links and contents on an attributed network is defined in the following.
where
is shared by link modeling and content modeling, which integrates the document contents and document links by a common probabilistic distribution for more accurate topic discovery.
The above function is difficult to compute, and is always transformed as the log-likelihood as follows:
In real applications, content components and link components have different importance. The loglikelihoods of the two components in Equation (
5) are assigned with a weight
and a weight
, respectively, as follows:
3. Parameter Estimating Algorithm
In this section, we introduce how to learn the values of model parameters given a corpus, including the word embeddings , as well as the topic distribution of documents , the link distribution on topics , and the skip-gram distribution on topics . Next, the algorithm of estimating parameters is described and its complexity is analyzed.
3.1. EM Algorithm with Negative Sampling for the setoLC Model
Since the parameters of the steoLC model contain hidden variables
z, the EM algorithm is used to maximize the likelihood of Equation (
6). In addition, to estimate parameters
in Equation (
2), the negative sampling algorithm is used. The algorithm framework of the steoLC model combines the EM algorithm with the negative sampling algorithm. It is summarized in Algorithm 1.
| Algorithm 1. The algorithm for the steoLC model. |
Input: word sequence setDand link setC Output: - 1:
Initialize . - 2:
for iter=1 to Max_iteration do - 3:
for each document in D do - 4:
for each skip-gram in do - 5:
Sample negative instances from distribution P. - 6:
Update , by Equations ( 13) and ( 7). - 7:
Update U, V using the gradient decent method with Equations ( 14) and ( 15). - 8:
for each link in do - 9:
Update by Equation ( 8). - 10:
for each document in D do - 11:
Update using Equation ( 11). - 12:
for each link in do - 13:
Update using Equation ( 12)
|
The EM algorithm is an iterative algorithm, and each iteration includes an E step and an M step. In the E step, the distributions of hidden variables z, given each skip-gram and given each link , are estimated. At the same time, the expectation of the log-likelihood is computed in the E step. In the M step, by maximizing the expectation of the likelihood, the algorithm updates the word embeddings , as well as and . To update the word embedding matrices, the algorithm iterates over each skip-gram and several negative sampling instances with the gradient descent method. The algorithm is inferred in detail.
In the E-step, the posterior probability distribution of hidden variables given each skip-gram
in
is evaluated by the Bayes rule as follows:
Further, the posterior probability distribution of hidden variables given each link
from the document
is computed as:
Next, the hidden variable posterior distributions obtained from Equations (
7) and (
8) are used to compute the expectation of the log-likelihood, which is defined as:
The topic distribution given a document satisfies the constraint . The skip-gram distribution given a topic satisfies the constraint . The link distribution given a topic satisfies the constraints .
The Lagrange multiplier method is used to estimate model parameters. The Lagrange function combines the expectation of the log-likelihood function in Equation (
9) with the three constraint conditions defined as:
In order to maximize the Lagrange function, the partial derivatives with respect to
are computed. The updating equations of the topic distribution of a document and the link distribution for each topic are obtained by making partial derivatives equal to zero. The equations are as follows:
To update the word embeddings,
, the immediate method is to compute the partial derivatives of
in Equation (
2). However,
is intractible. The negative sampling method is used to compute
, in which the probability distribution of
is computed as follows:
where
represents the sigmoid function,
, and
is a negative instance which is sampled from the distribution
.
is a unigram distribution Unigram(w) raised to the
power [
12].
The negative sampling algorithm is a gradient algorithm. The gradient of the objective function concerning
U and
V is as follows:
where
is the negative instances corresponding to
,
d,
are step lengths, and
3.2. Complexity Analysis of the Algorithm
The process of steoLC is shown in Algorithm 1. In each iteration, the algorithm first computes the distributions of hidden variables
in line 3–9. Since
affects
in Equation (
7), it is computed before
in line 7. At the same time, the parameters of word embedding matrices
U and
V are updated by a gradient decent method in line 7, and the number of the iterations is set as a constant. The number of document words is
, which is simplified as
L. Next, all the skip-grams are
. The time complexity of line 3–7 is
, where
n is the length of left or right window sampling contexts,
represents the number of negative samples, and
K is the number of topics. The time complexity of
in line 8–9 is
, where
C is the number of links among the documents. The time complexities of
and
are, respectively,
and
. To summarized, the time complexity of the whole algorithm is
, where
is the iteration times.
4. Results
In this section, we present a detailed analysis of the performance of our method. We first introduce several experimental settings, including the dataset, parameter settings, and the baselines used in the experiment. Next, document classification is used to evaluate the quality of document representations on the topic distribution estimated by the steoLC model. Subsequently, we explain whether word embedding results are able to model polysemous words on topics by qualitative analysis. Finally, we evaluate the topic coherence of the steoLC model.
4.1. Experiment Settings
Dataset description. To verify the performance of the steoLC model, we experiment on three public datasets as the CeTe model [
19], including the DBLP dataset [
20] and two different scale hep-th datasets. The DBLP dataset includes many papers on the computer field, and the five largest categories are used to construct attributed networks. The titles and abstracts are represented as the contents of papers, and the citation relationships correspond to the links of papers. The hep-th includes a large corpus of physics-related papers. The four largest categories form one subdataset, named large-hep. The three smaller categories form the other subdataset were called small-hep. The dataset details are shown in
Table 2.
Baselines. The algorithm of the steoLC model is compared with three state-of-the-art methods. The first model is a traditional topic model, i.e., Latent Dirichlet Allocation (LDA) [
2], which models topic discovery on one hot word space. The STE model [
12] integrates topic discovery with word embedding based on texts of documents and attempts to solve polysemy. The CeTe model also combines topic discovery with word embedding. In addition, it improves the performance by utilizing community detection on links as a pre-processing step of topic embedding modeling. The CeTe model has been compared with three kinds of state-of-the-art methods for specific-topic embedding modeling. If the performance of our algorithm is better than the CeTe model, our algorithm is superior to the three kinds of methods.
Parameter settings and Hardware specifications. In the experiments, the number of topics
K is set as 10, such that topical specific word embedding on a fine-grained topic is possible. The iteration number of the document set and the number of gradient descent for
are both set as 15. The dimension of the embedding space is 400. The size
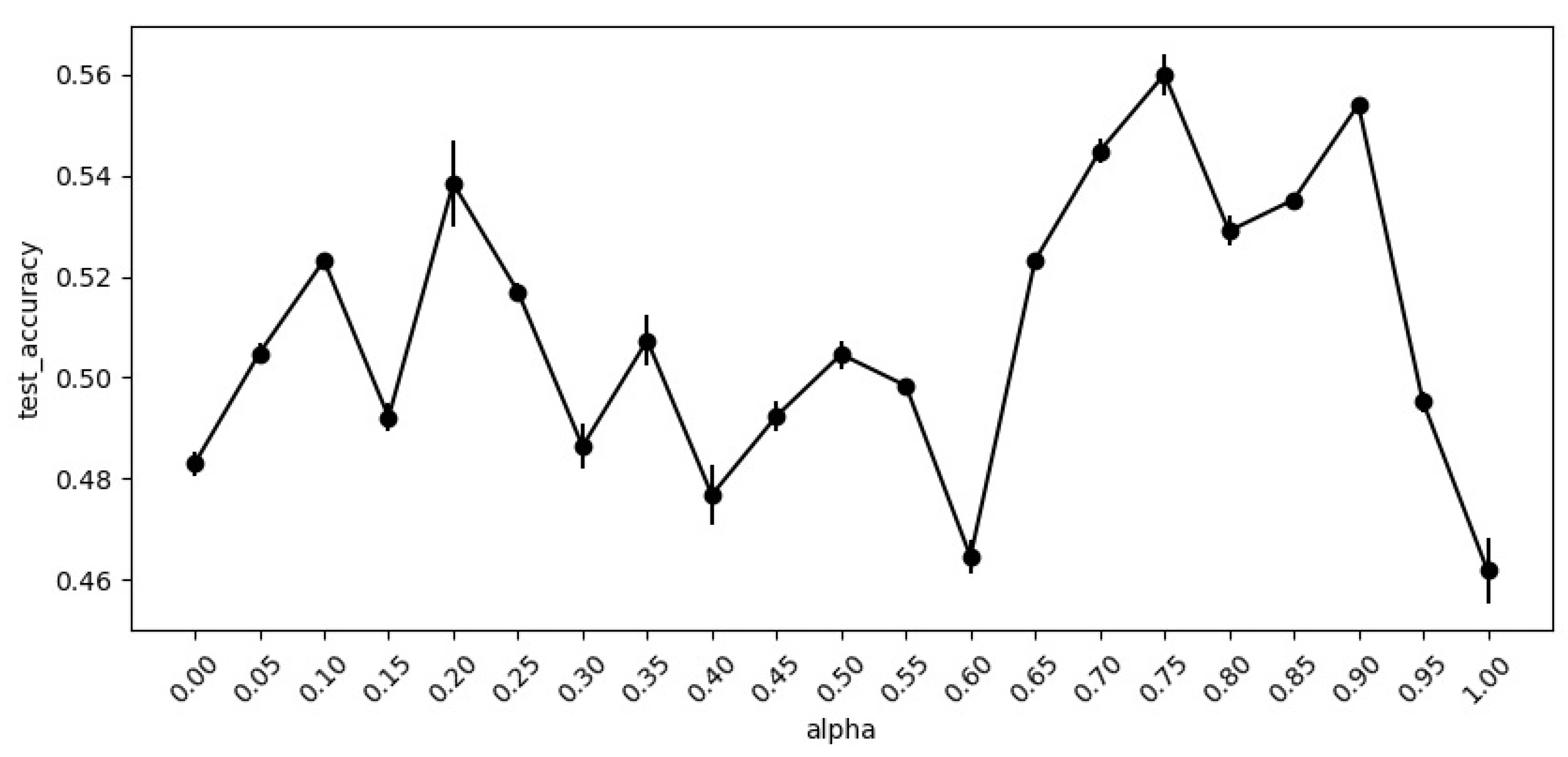
n of the context window equals 10. For each skip-gram, eight negative instances are sampled. These settings are similar to the ste model. The steoLC model aims to learn word embeddings, document embeddings, and topic embeddings. Thus, the component of content is more important, and the
is set as 0.75 experimentally. We compare the accuracy of detected topics for classification at the small-hep data set by varying
from 0 to 1, and the accuracy on the test is shown in
Figure 2. Computer configurations for the experiments are a CPU-Intel i7, with 16GB of internal storage and 1T of Hard Disk, etc.
4.2. Document Classification
To test whether our algorithm has learned accurate semantics for documents, a classification task is used. The document set is randomly divided into 80% as the training set and 20% as the test set [
19]. The document representation learned by all the algorithms by Equation (
11) is the input of the classifier. We use the
regularized linear SVM one-vs-all classifier. We compare the steoLC model with the LDA model and the STE model. All the models represent a document by the topic distribution of the document. The performance is measured by accuracy, recall, and the F1-Score.
Each model is run ten times, and the mean and standard deviation of the results are computed and shown in
Table 3. Our steoLC model performs the best among the three models. Compared with the distributed representation of the steoLC model, the LDA model discovers topics and learns word embeddings using only the contents represented by the one hot word vector, which suffers from sparsity and semantic gaps. Different from our steoLC model combining contents and links, the STE model only considers content information, although it represents words as dense embeddings. This method may captain vague topics. The CeTe model utilizes community detection on links to degrade the fuzziness of topic discovery, but the community detection is not integrated with topic discovery in a unified framework. Our steoLC model constructs a joint model for contents and links in a generative process, which discovers more accurate semantic topics. In addition, it combines topic modeling with word embedding modeling, such that the two tasks are improve each other. We also find that the results on the large-hep dataset are worse than the ones on the small-hep dataset. This is because each category in the large-hep dataset has more documents and is more noisy than each category in the small-hep dataset, which increases the difficulty of distinguishing the pattern of each category on the former dataset compared with the latter one.
4.3. Qalitative Analysis
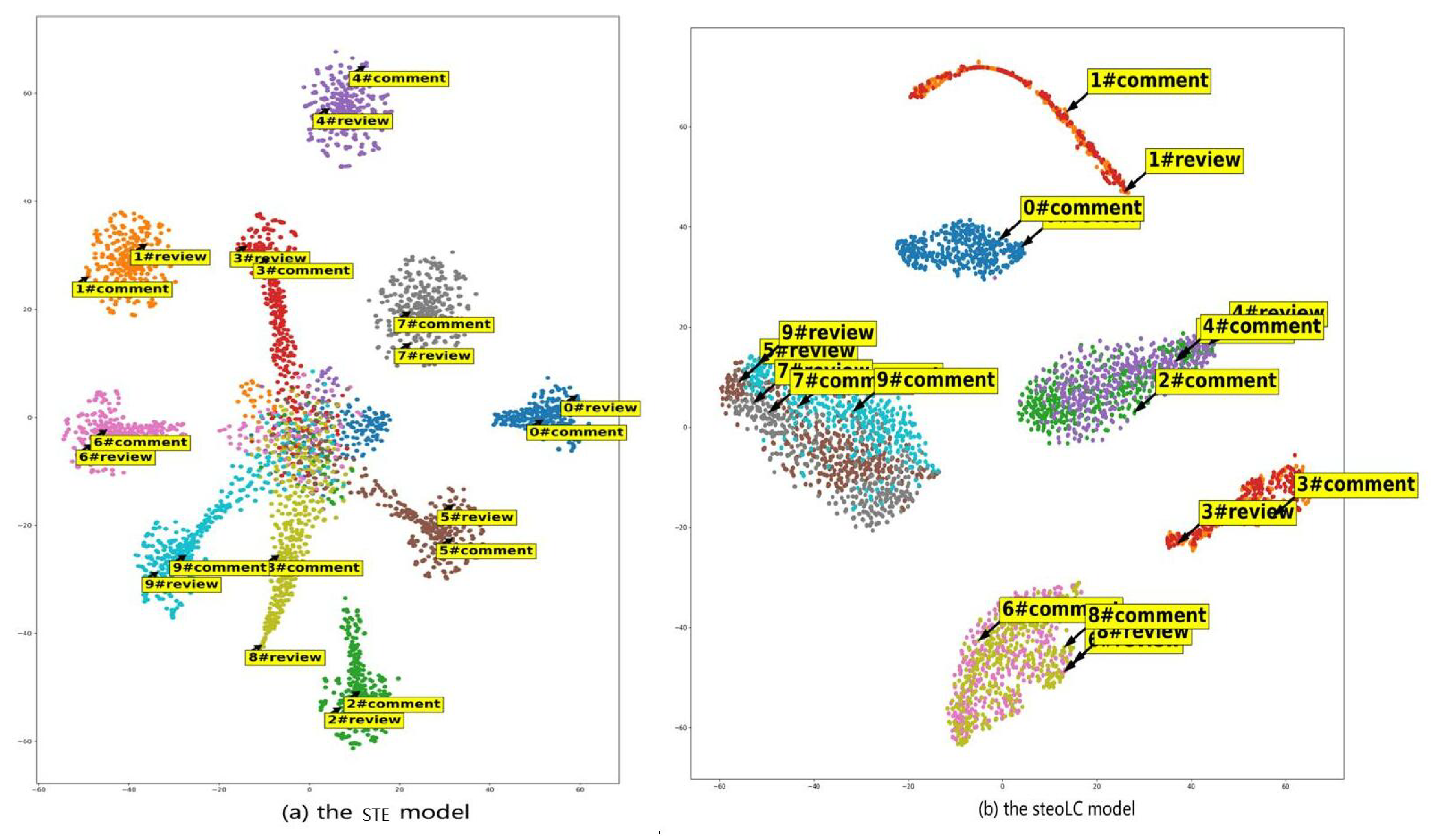
To illustrate the performance of integrating word embedding with topic discovery in our model, we use the t-SNE algorithm [
21] to visualize the vectors of the 500 most frequent words that are learned from the steoLC and STE models in the small-hep dataset in
Figure 3. Similar to the STE model [
12], the number of topics K is set as 10. The number of outer iterations and inner iterations are both set to 15. The dimension of the embedding vectors is set as 400. For each skip-gram, we set the window size to 10 and sample eight negative instances.
Each node in
Figure 3 denotes a topic-specific word vector. The algorithm of the steoLC model divides the whole space into 10 subspaces, and each subspace represents a topic. To illustrate the advantages of the steoLC model in dealing with polysemous words, we show labels for the word “review”, as an example of a polysemous word and the word “comment” as an example of a monosemous word. The labels show both the word and topic index, separated by “#”. In
Figure 3b, we find that the steoLC model divides the whole space into six disjoint subspaces, and each subspace corresponds to a topic. We set the topic number as 10, and our model detects just six topics clearly. This illustrates that several topics are difficult to divide, such as Topic 7,5,9, Topics 6,8, and Topics 2,4. This guides us to select a small topic number. Additionally, “review” and “comment” are close to each other in some subspaces, but far apart in others. For example, under Topic 1, the word “review” is far away from the word “comment”, which indicates that the word “review” does not mean “comment” under Topic 1. Under Topic 0, the word “review” is closer to the word “comment”, which indicates that the word “review” means “comment”. On the other hand,
Figure 3a illustrates that some word embeddings of different topics from the STE model are mixed together, which means that different topics are difficult to discriminate. However, the steoLC model can discover topics more accurately by combining the contents and links, such that the word embeddings in the same topic are similar and word embeddings in different topics are able to be distinguished.
Table 4 shows the nearest neighbors of some polysemous words according to the skip-gram model, the STE model, and the steoLC model. Cosine similarity is used to compute the similarity between polysemous words and other words. We observe that these similar words, according to word embeddings learned by skip-gram, mix different senses of the given words. For example, the nearest neighbors of “present” are “show” and “recently”, which indicates that the skip-gram model cannot distinguish different meanings of words. In contrast, the STE and steoLC models can distinguish polysemy due to the consideration of topic modeling. Under Topic 1, the most similar words of “present” are “show”, “description”, and “action”, which clearly corresponds to the meaning of appearance. Under Topic 2, they are “recent” and “recently”, clearly referring to ’lately’. In addition,
Table 4 shows that similar words from the steoLC model are better than the ones from the STE model. For example, the most similar word to “argue” obtained by the steoLC model under Topic 1, namely “argue# 1”, has more meaning than the ones obtained by the STE model. The reason is that the steoLC model makes use of links to obtain more accurate topic distributions, which further aids in learning accurate word embeddings.
4.4. Topic Coherence Evaluation
Table 5 compares the top words produced by the STE and steoLC models on three topics detected from the small-hep dataset. In
Table 5, Topic 1 is about mathematics, Topic 2 is about cosmology, and Topic 3 is about physics. Both the STE and steoLC models produce words with similar themes. However, the STE model discovers fewer meaningful words related to these three topics. Some words from the STE model are not coherent. For example, for Topic 2, STE produces “conference” and “transition”, which are less related to cosmology, while the hot words produced by steoLC are all related to cosmology. This shows that the steoLC model is able to discover more coherent topics than the STE model.
In addition, a topic coherence measure is used to evaluate the models objectively. Coherence of a set of words measures the hanging and fitting together of single words or subsets of them. The method presented in [
22] can cover all existing measures and construct new measures, which demonstrates that the coherence measure (
) has the best performance among PMI, NPMI, UMass, etc. The higher the value, the better the coherence.
combines the indirect cosine measure with the NPMI and the boolean sliding window. For each top word
of a topic word set, its vector
is calculated based on context words, and the
-element
is the NMPI value with the
-context word
is as follows:
Probability, , is estimated based on word co-occurrence counts derived from virtual documents by a sliding window over Wikipedia. Each window position defines such a document.
Next, topic coherence is averaged on the cosine similarity summation of any two top words and as , where N is the number of top words of a topic, and and are the average function and the cosine similarity function, respectively. is realized by tool gensim.
Table 6 shows the coherence values of
for the STE and steoLC models on the small-hep datasets. We can see that our steoLC model generally improves the coherence of the learned topics. Compared with the STE model, our model incorporates link information to improve the quality of the detected topics.
5. Discussion and Conclusions
A novel joint probabilistic model, the steoLC model, is first provided for topic discovery and polysemy word embedding based on document link networks. An algorithm is then designed to learn the model parameters by the EM algorithm with a negative sampling algorithm. The algorithm of the steoLC model learns the topic distribution on documents, and the embedding distribution on topics for words as central words and context words, as well as the link distribution on topics. This method not only mines topics and word embeddings by integrating contents with links, but also solves the polysemous problem, reducing the fuzzy semantic of topics. Compared with the state-of-the-art methods on several tasks, the experimental results demonstrate the superiority of our model. However, the proposed algorithm is difficult to apply on large-scale data due to the complexity of our probabilistic model. It may be helpful to use a python library for probabilistic models, such as ZhuSuan. In addition, the steoLC model does not model multi-granularity texts in the same representation space, which will affect the performance and explainability of topic discovery and text representations. In the future, we will further use the graph convolutional neural network or the depth generation model to address these problems.







{kind=link}
{kind=link}
{kind=link}