When actually solving the probability density function, it is difficult to directly know the probability density function. To estimate the probability distribution, a histogram is constructed using a symmetric bin process that divides the variable values into discrete values. However, in practice, this value depends on the number of histogram bins, and the bin width for a given data range. Drawing on this idea, the two-dimensional space is divided into mutually disjointed bins. The bins are defined as follows:
Approximately solve the two-dimensional probability density function using Equations (
4) and (
5)
where
is the probability density function,
is the frequency,
is the number of datapoints in the bin
, and
is the total number of datasets. According to Equations (
4) and (
5), the two-dimensional probability density function of the sampling set is defined as Equations (
6) and (
7).
where
is the probability density function of the sampling set,
is the number of sampling points for the histogram bucket
.
3.1. Selection of Bin Size
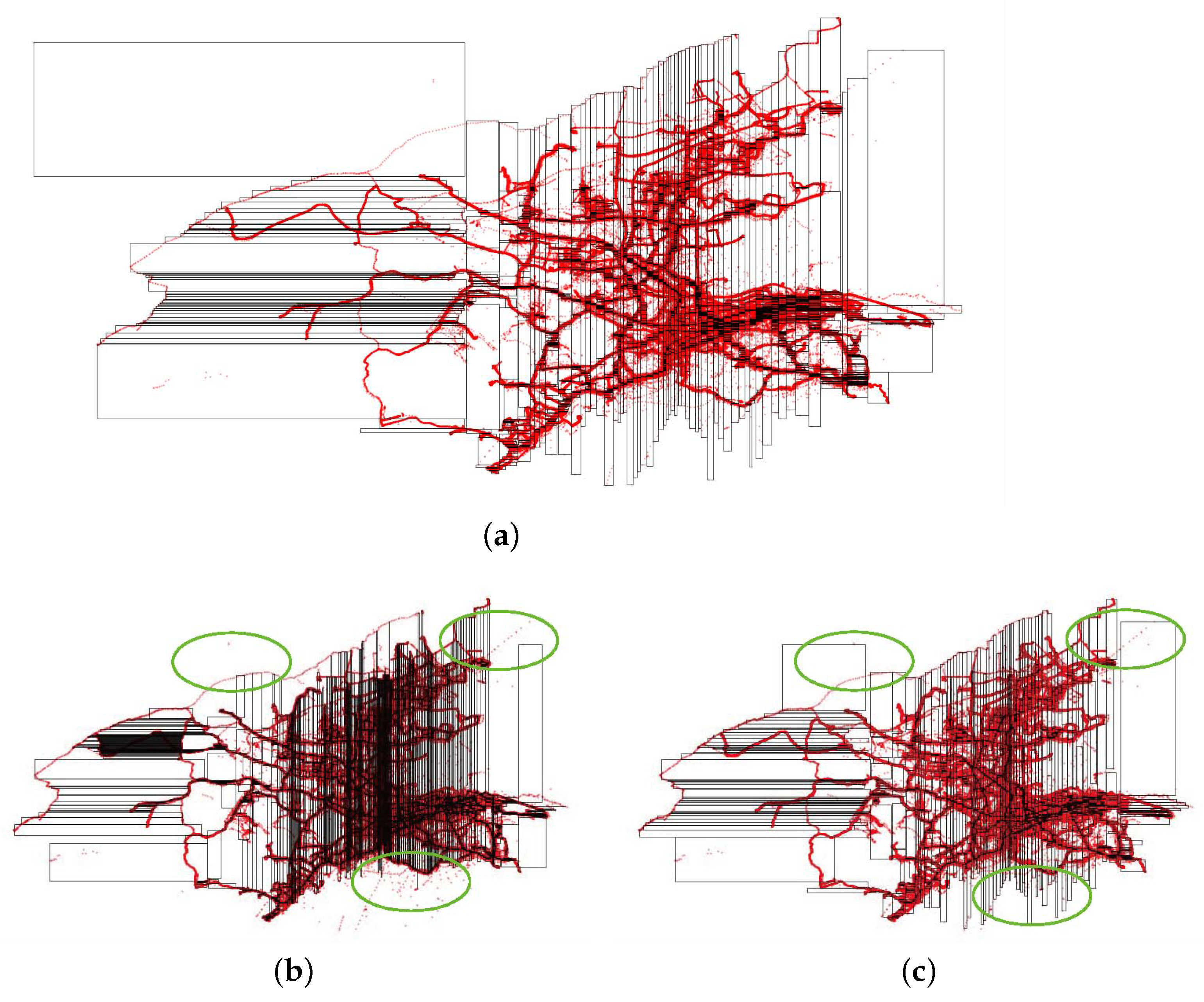
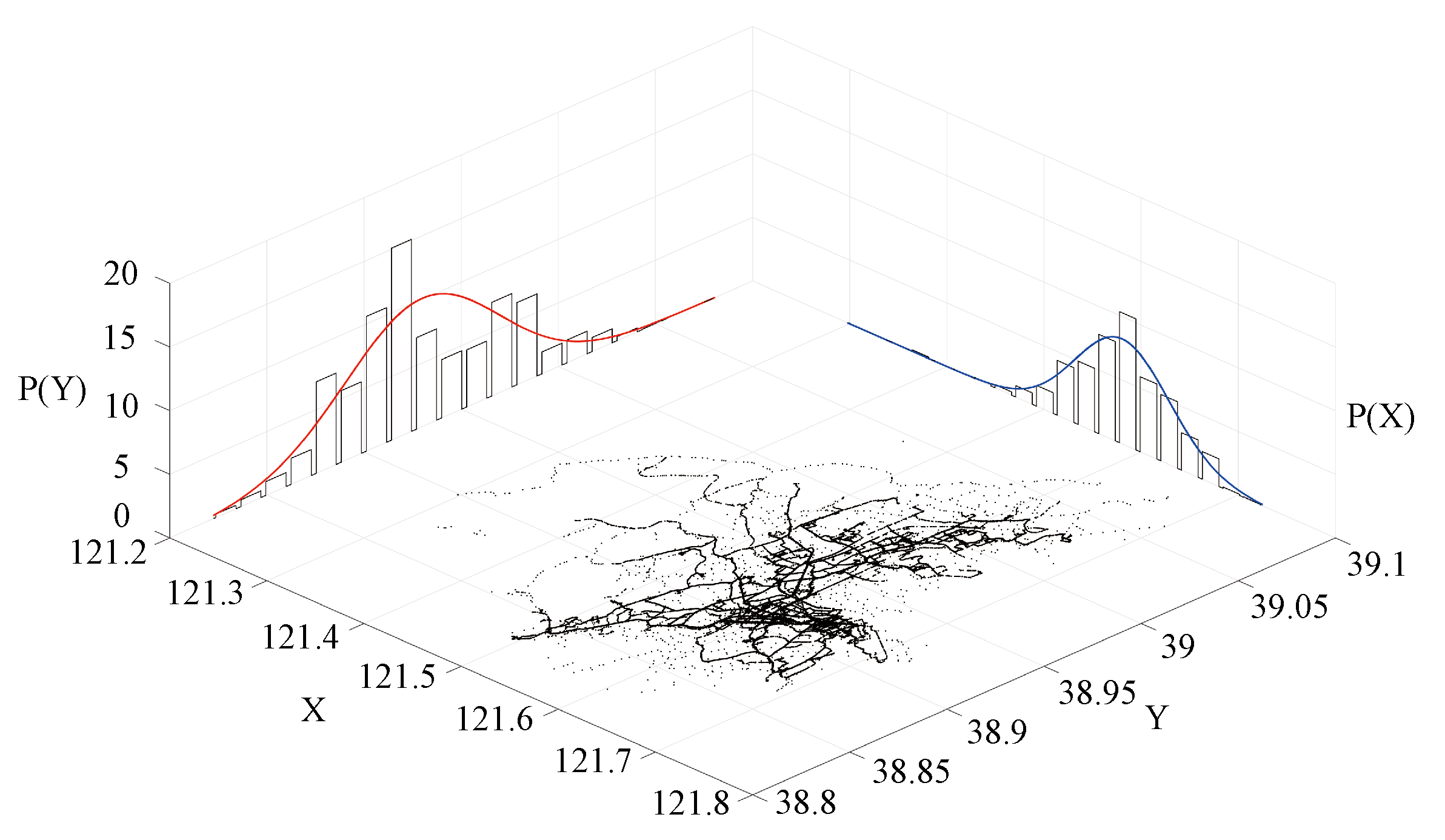
In our research environment, the amount of spatial data is huge, and the results of a parametric analysis of spatial distribution are not available. Therefore, we used a nonparametric modeling approach. In addition, as shown in
Figure 2, the trajectory points in
Figure 2 are typical spatial big data, and the black dots represent the trajectory points of the bus. It is observed that the trajectory points in low-longitude areas (such as Ganjingzi District) are sparse, most of the trajectory points are concentrated in the high-longitude part, and the spatial data present a skewed distribution. The widely adopted bucket width selection rule is to use Sturges’ rule [
3] with bucket width
.
where
n is the total sample size,
and
represent the maximum and minimum values of the data range, respectively. The data are assumed to be normally distributed. However, when the data are not normally distributed, additional operations are required to address skewness. Scott’s rule [
4] is based on the gradual theory,
. This rule also assumes that the data are normally distributed. Freedman and Diaconis [
18] extended Scott’s rule to give the bin width optimum
for a non-normal distribution. For a set of empirical measurements sampled from some probability distribution, the Freedman–Diaconis rule is designed to minimize the integral of the squared difference between the histogram (that is, the relative frequency density) and the theoretical probability distribution density.
where
is the 75th quantile value of the data,
is the 25th quantile value of the data, and
n is the number of samples, this paper uses the Freedman–Diaconis rule to calculate the bin length
and width
values of skewed data, such as Equations (
8) and (
9)
where
and
represent the 75th quantile and 25th quantile of
.
3.2. Histogram Bucket Data Point Calculation
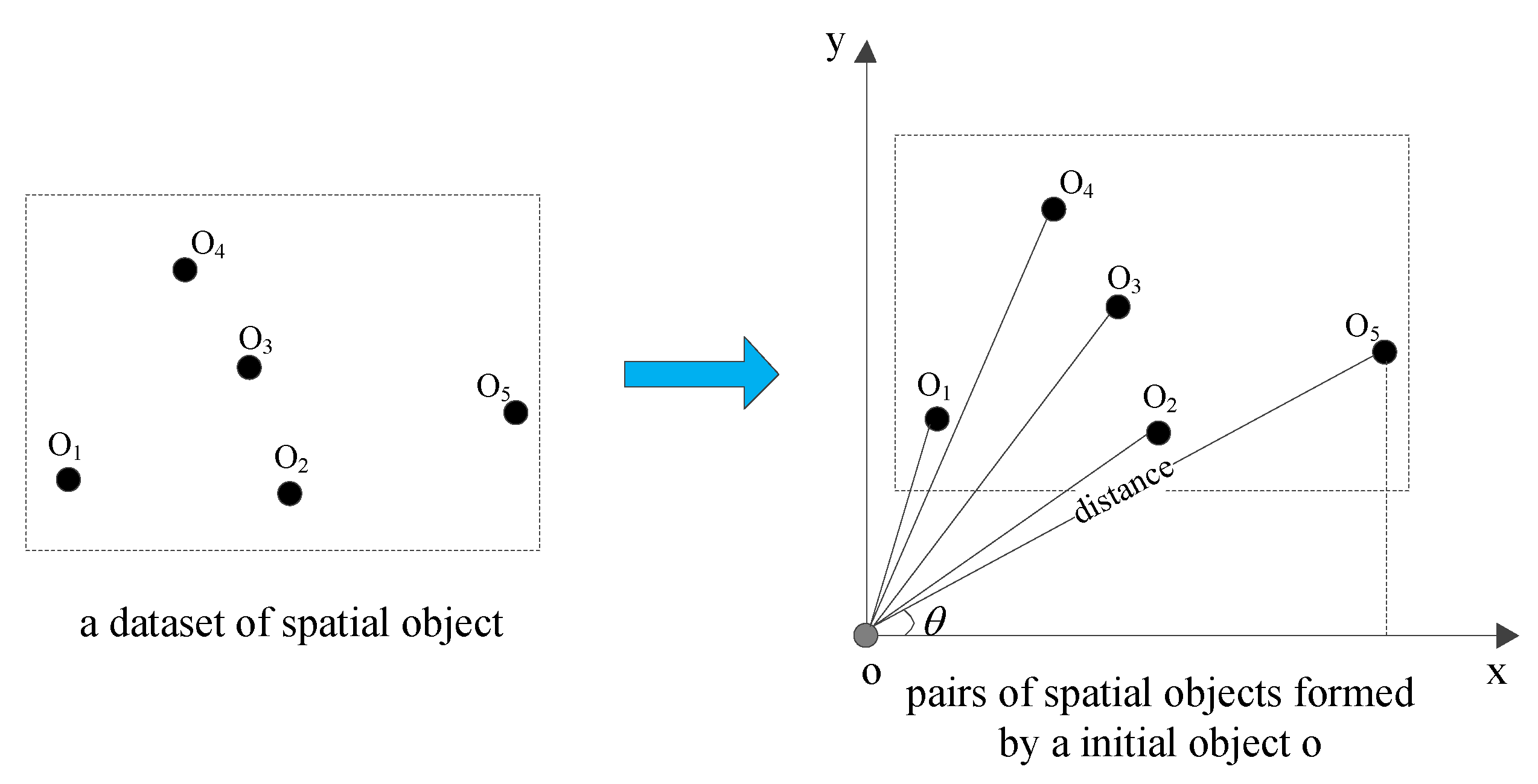
This section proposes a framework for fast computation of histogram bucket ; by establishing a functional relationship between the spatial offset and the number of spatial pairs, the approximate calculation of the value is realized within a certain error range. A description of space offset and space pair is given below.
Given a dataset
, establish a spatial pair
,
, the spatial measure
d, spatial offset refers to the smallest bounding rectangle (MBR) containing the spatial pair
, MBR refers to the rectangle with the smallest perimeter L satisfying the relationship
, which is uniquely represented by
and
d. MBR with a smaller distance is preferred. When
d is equal, a smaller
is selected when
, and a larger
is selected when
.
Figure 3 is an example of space pair and MBR, as shown in Equation (
10).
Using the above concepts, define the spatial offset distribution histogram bucket, as follows:
Definition 3. Spatially offset distribution bins (SODB). Let be a 2D dataset with datapoints, given a spatial pair , the spatial measure d, is defined as a two-dimensional array of buckets, Covering the field, there are square buckets, is expressed as: , , all bins have the same and values.
A simple way to calculate SODB see Algorithm 1. Initialize the square bucket first, then traverse the space pair to calculate the maximum value
,
, the minimum value
,
and
,
of
on
,
, get the length and width of each square bucket, and store it in the square bucket array
. Then, traverse the space pair to make it uniquely correspond to a square bucket, and finally return the
function.
| Algorithm 1: SDOB() |
![Symmetry 14 01055 i001]() |
The time complexity of Algorithm 1 includes:(1) Calculate all space-to-space offset values, namely, , where represents the complexity of each space offset calculation; (2) Sort all spatial offsets, that is, ; (3) Initialize the histogram bucket , namely ; (4) Traverse the space pair and calculate the value of each histogram bucket, that is, . In general, the time complexity of this method is . Obviously, when is large, the time complexity of this method is large, and cannot meet the needs of practical applications. Therefore, this paper designs the cumulative spatial offset distribution function to speed up the calculation of the spatial offset distribution histogram bucket, and the distribution function returns a jump function with respect to the spatial offset , as Definition 4.
Definition 4. Cumulative Spatial Offset Distribution Function. Let be a 2D dataset with N datapoints, spatial pair , spatial measure d. For simplicity, we assume that the spatial domain is , , in the form of: The functional relationship between
and
is Equation (
11)
A simple way to calculate CSOD is shown in Algorithm 2. First initialize the MBR array, calculate the
d value of all space pairs, and insert into the MBR array. Then, sort from small to large according to the smallest MBR perimeter, and calculate the cumulative spatial offset distribution function
.
| Algorithm 2: CSOD() |
![Symmetry 14 01055 i002]() |
The time complexity of Algorithm 2 is as follows: (1) Calculate all space-to-space offset values, that is, , where represents the complexity of each spatial offset calculation; (2) Sort all spatial offsets, that is, ; (3) Calculate the cumulative spatial offset distribution , that is, . In general, the time complexity of this method is . Obviously, this method is less practical when is large.
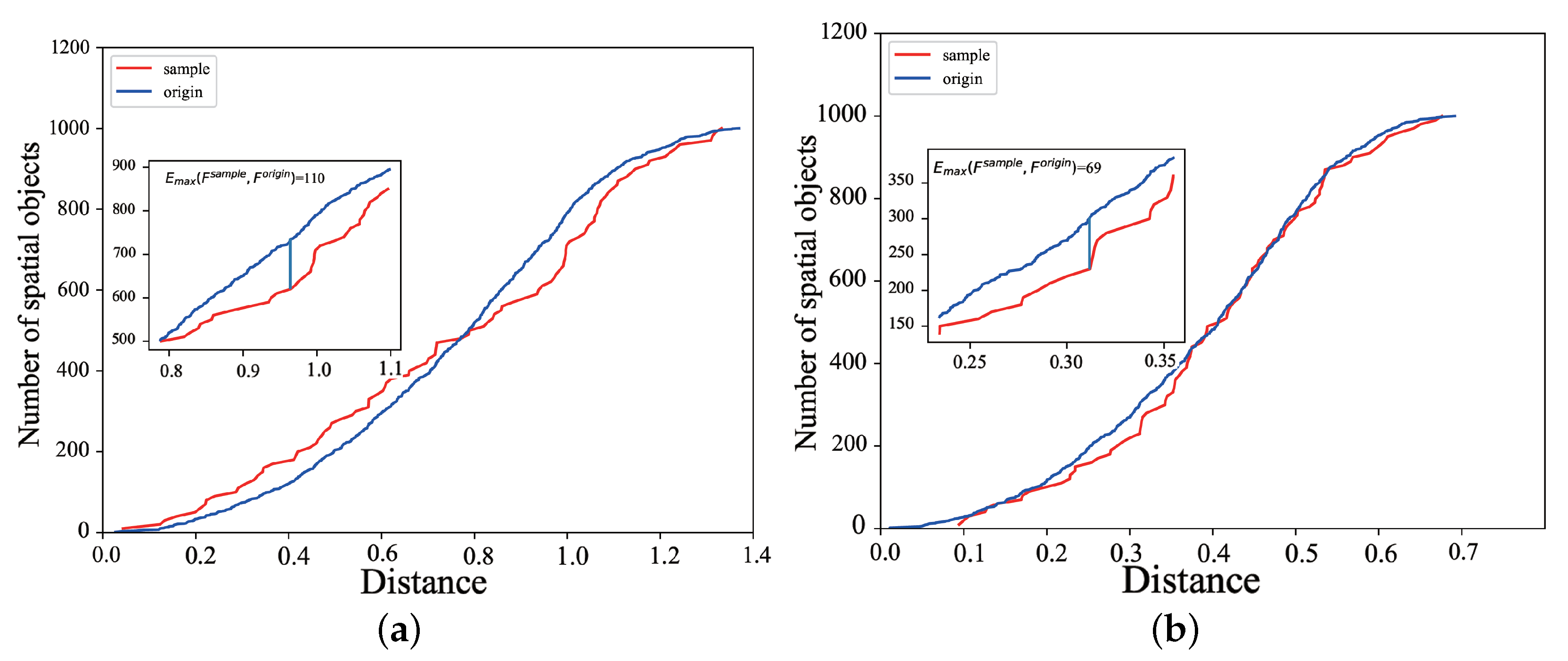
In the big data environment, it is difficult to calculate the value of quickly. Therefore, an approximate cumulative spatial offset distribution function with bounded error is designed in this paper to replace the value to speed up the sampling process, suppose the approximation is , as Definition 5.
Definition 5. Approximate Cumulative Spatial Offset Distribution Function. Given a set of space pairs and a distance measure d and a fault tolerance threshold δ, Approximate cumulative spatial offset distribution returns a jump function with respect to spatial offset , : For the calculation of
, we use the Euclidean distance-based upper and lower boundary calculation method in the paper, as in Equations (
12) and (
13), keep
unchanged, and the upper and lower boundaries of
d are
and
.
We define the upper and lower boundary functions
and
.
Lemma 2. If , then constant established.
Proof.
When
exists,
. Thence
, the same can be proved
. □
Lemma 3. Knowing the upper and lower boundary functions, let . If and , constantly holds.
Proof.
Let
, then
, So only need
, then
is established. □
According to Equation (
2) and Definition 4, we define the approximate spatial offset distribution histogram bucket as follows.
Definition 6. Approximate Spatial Offset Distribution Histogram Buckets. Given a set of space pairs and a distance measure d and a fault tolerance threshold τ, a histogram bucket with length and width , approximate cumulative spatial offset distribution returns a function over bucket such that For , is always true.
Lemma 4. Given , suppose is the return result of the input dataset and the distance measure d, can be calculated by in time complexity .
Proof. First prove that
. According to Equation (
6), the approximate spatial offset distribution histogram bucket
is transformed into
□
The time complexity analysis: we derive from the computational complexity of . Computing requires i from 1 to and j from 1 to , a nested for loop is executed; therefore, the time complexity is .















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}