
Khalil New Generalized Weibull Distribution Based on Ranked Samples: Estimation, Mathematical Properties, and Application to COVID-19 Data


Abstract
:1. Introduction
| (1) | … | → | ||||
| (2) | … | → | ||||
| . | ||||||
| . | ||||||
| . | ||||||
| (n) | … | → |
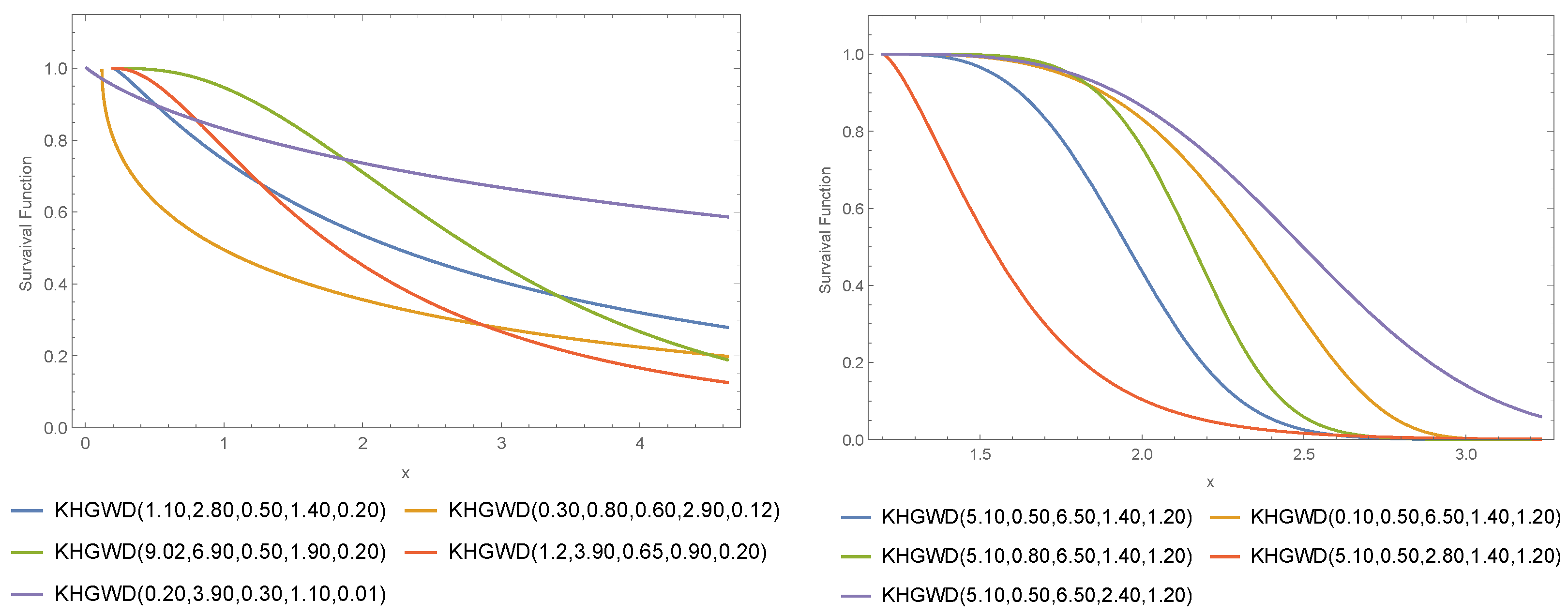
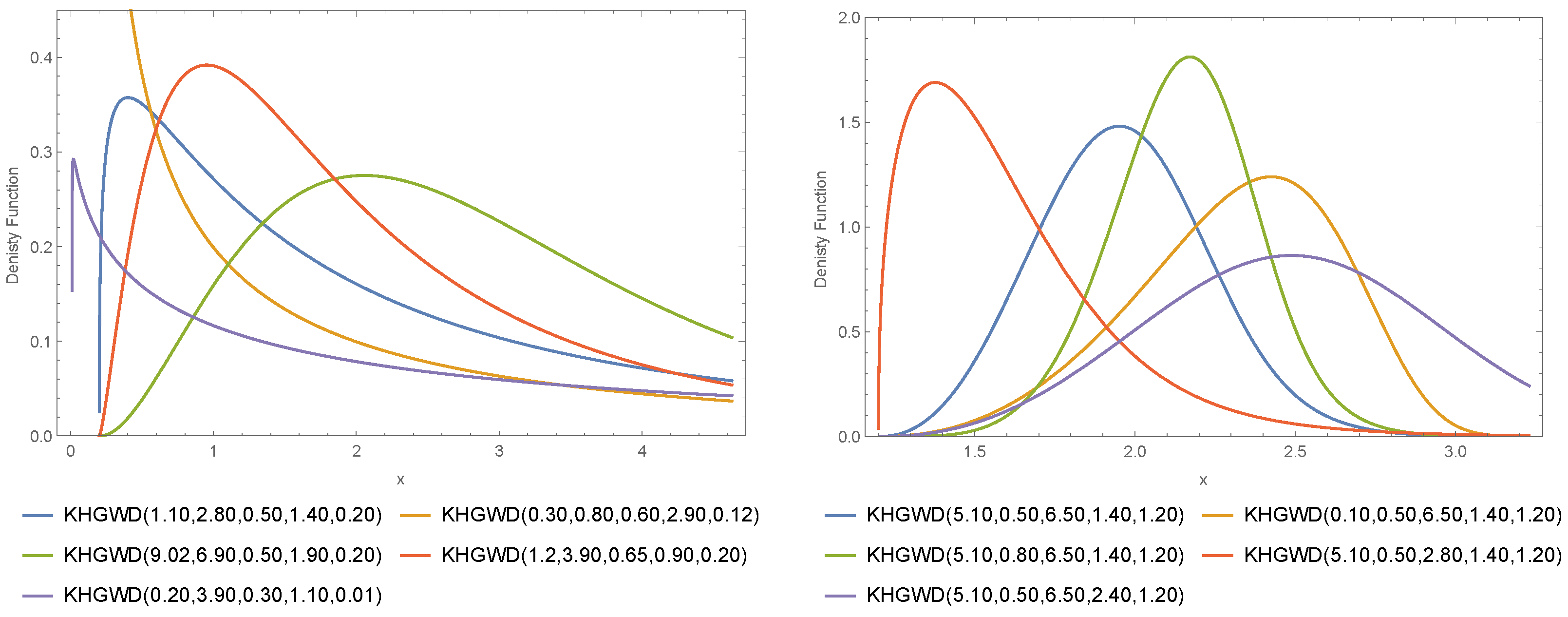
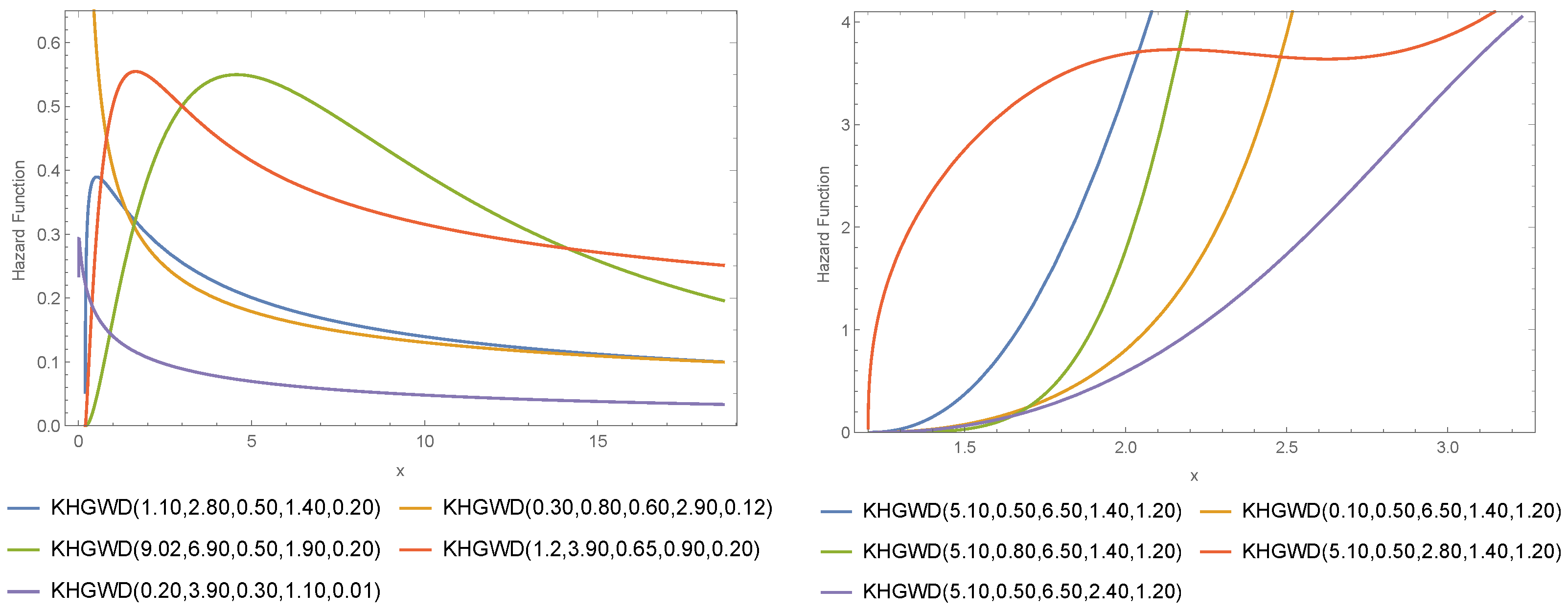
2. The Khalil New Generalized Family-Weibull Distribution (KHGWD)
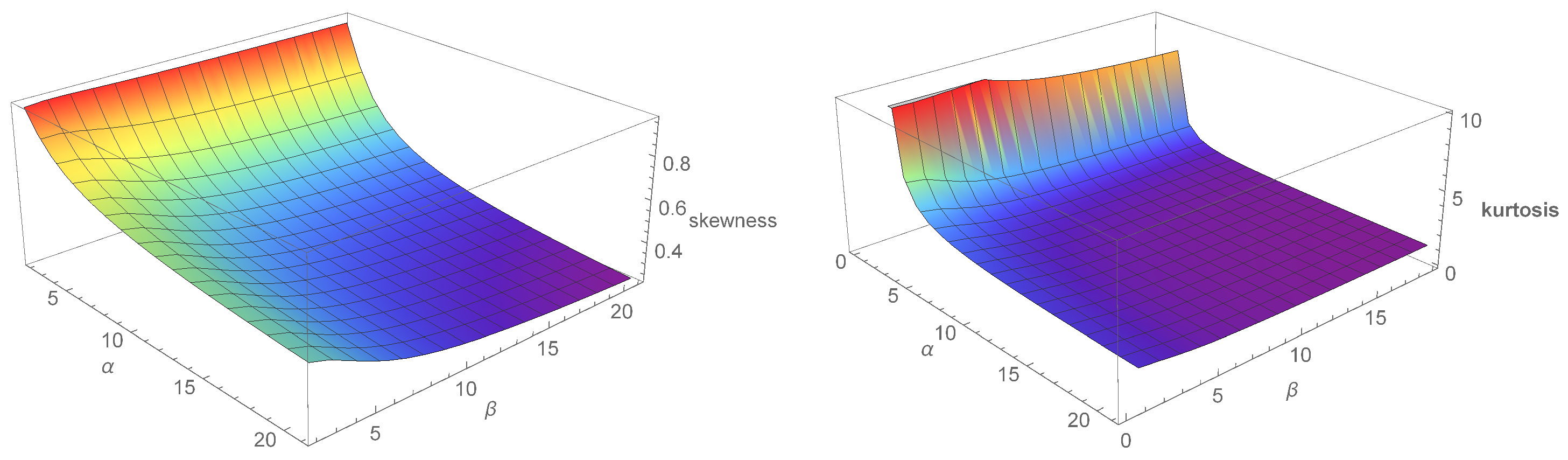
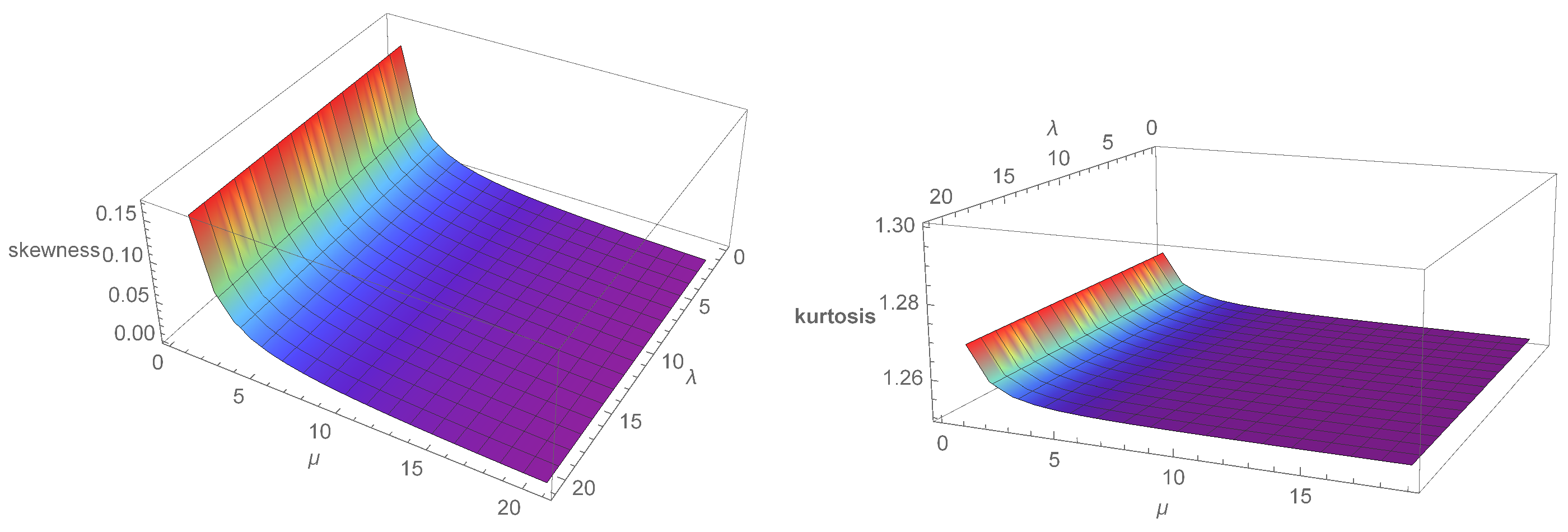
3. Mathematical Properties
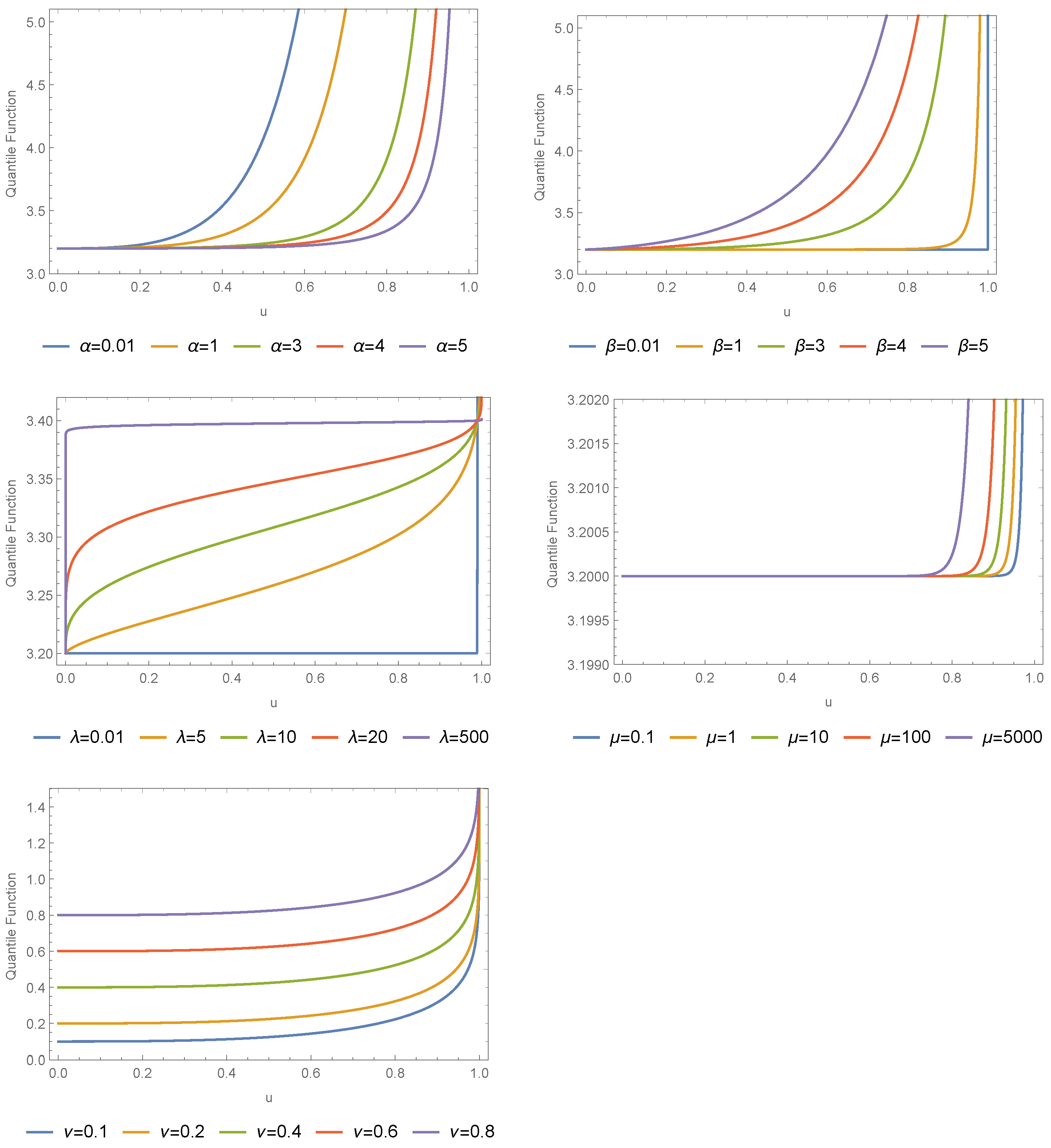
3.1. Quantile Function
3.2. The Expansion for KHGWD Density Function
3.3. The Expansion for the KHGWD Distribution Function
4. Estimation of the Parameters Based on the Ranked Set Samples
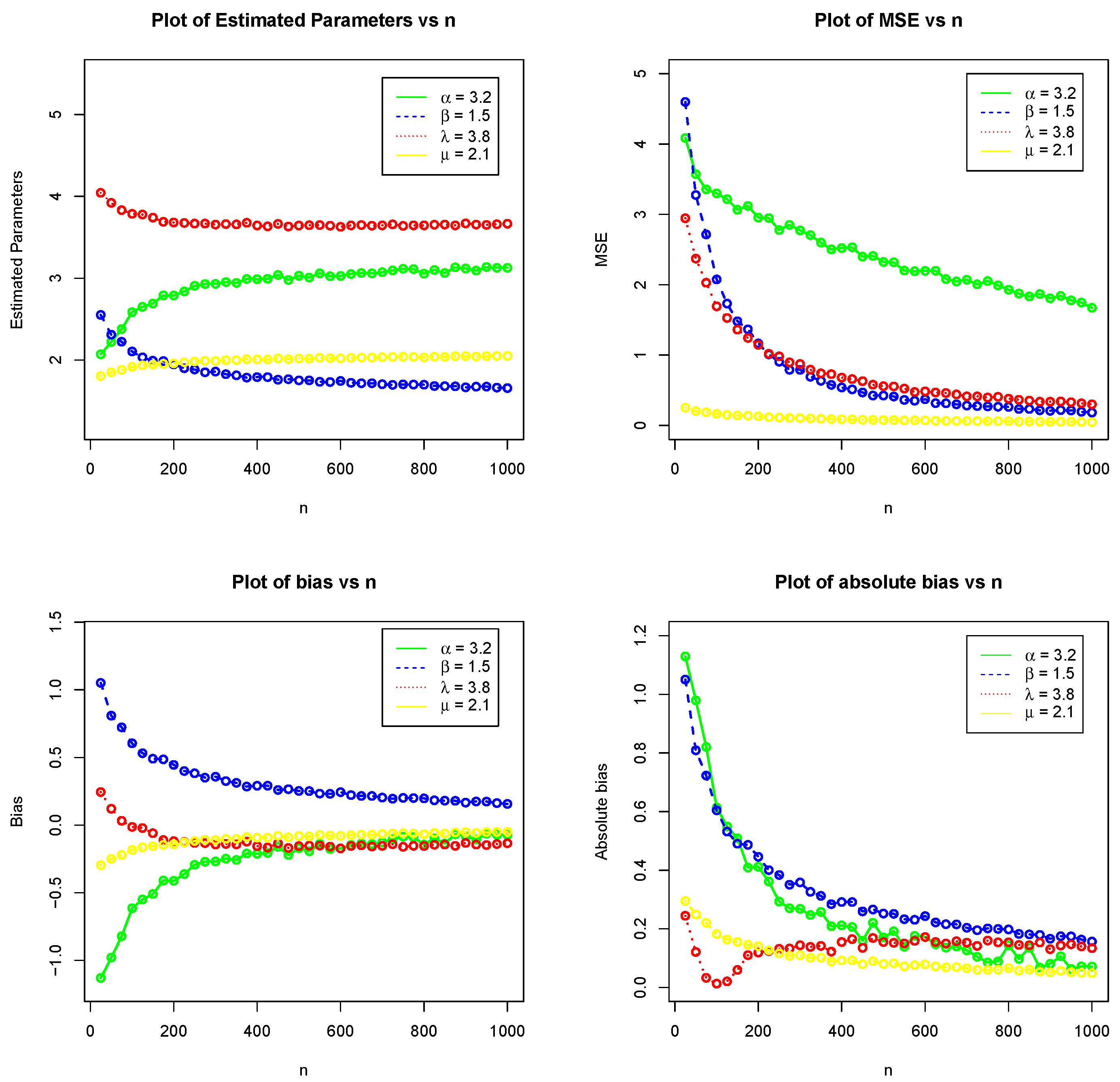
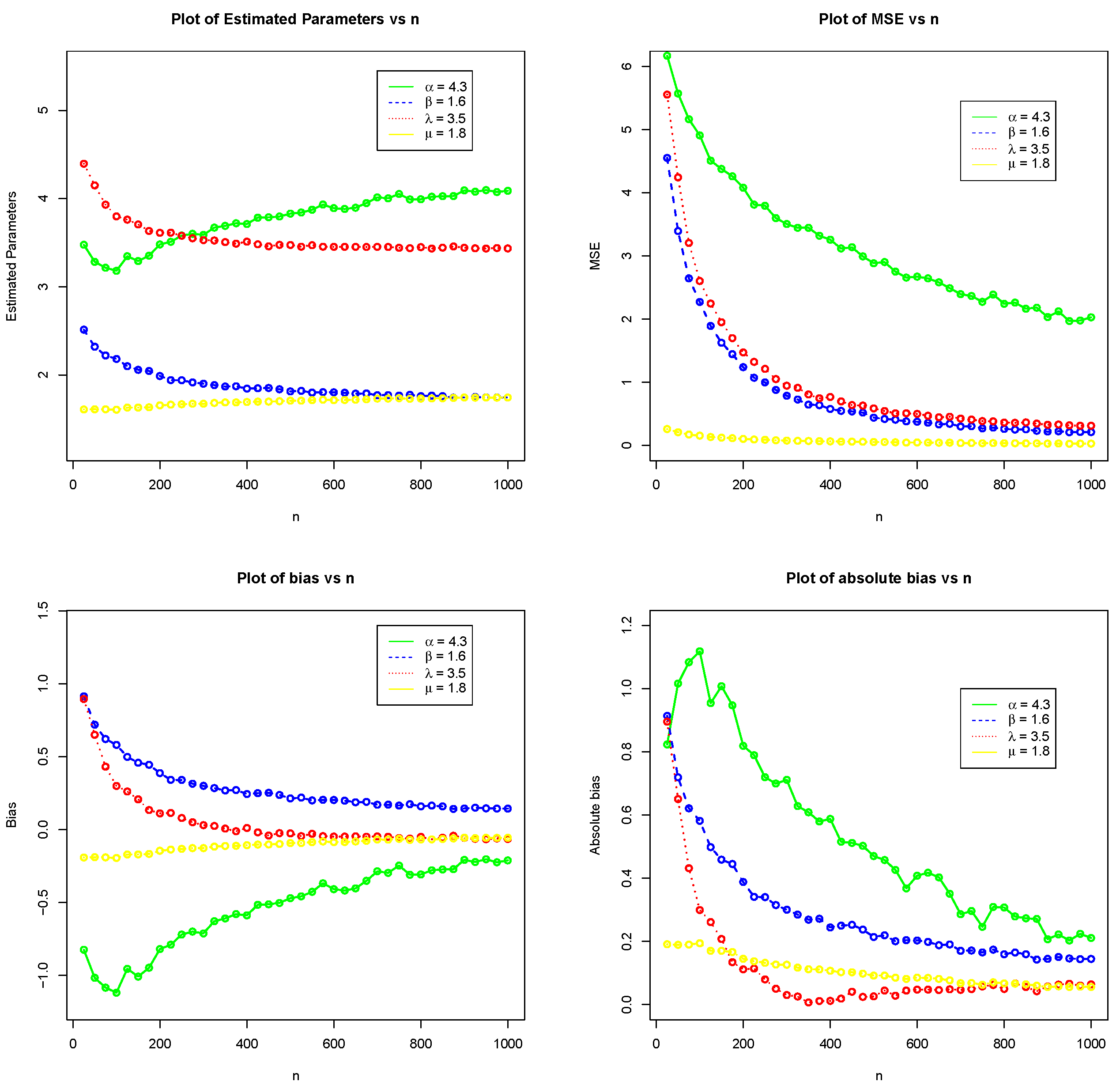
5. Monte Carlo Simulation Study
- Set 1:
- Set 2:
- Random samples of sizes are generated from KHGWD and are randomly divided into r groups of equal size m, where and 30, respectively.
- The model parameters have been estimated via the maximum likelihood method.
- Five-thousand repetitions are made to calculate these estimators’ biases, absolute biases, and mean square errors (MSEs).
- The formulas for obtaining the estimate, biases, and MSEs are given respectively, byandrespectively.
- Step (4) is also repeated for the parameters and .
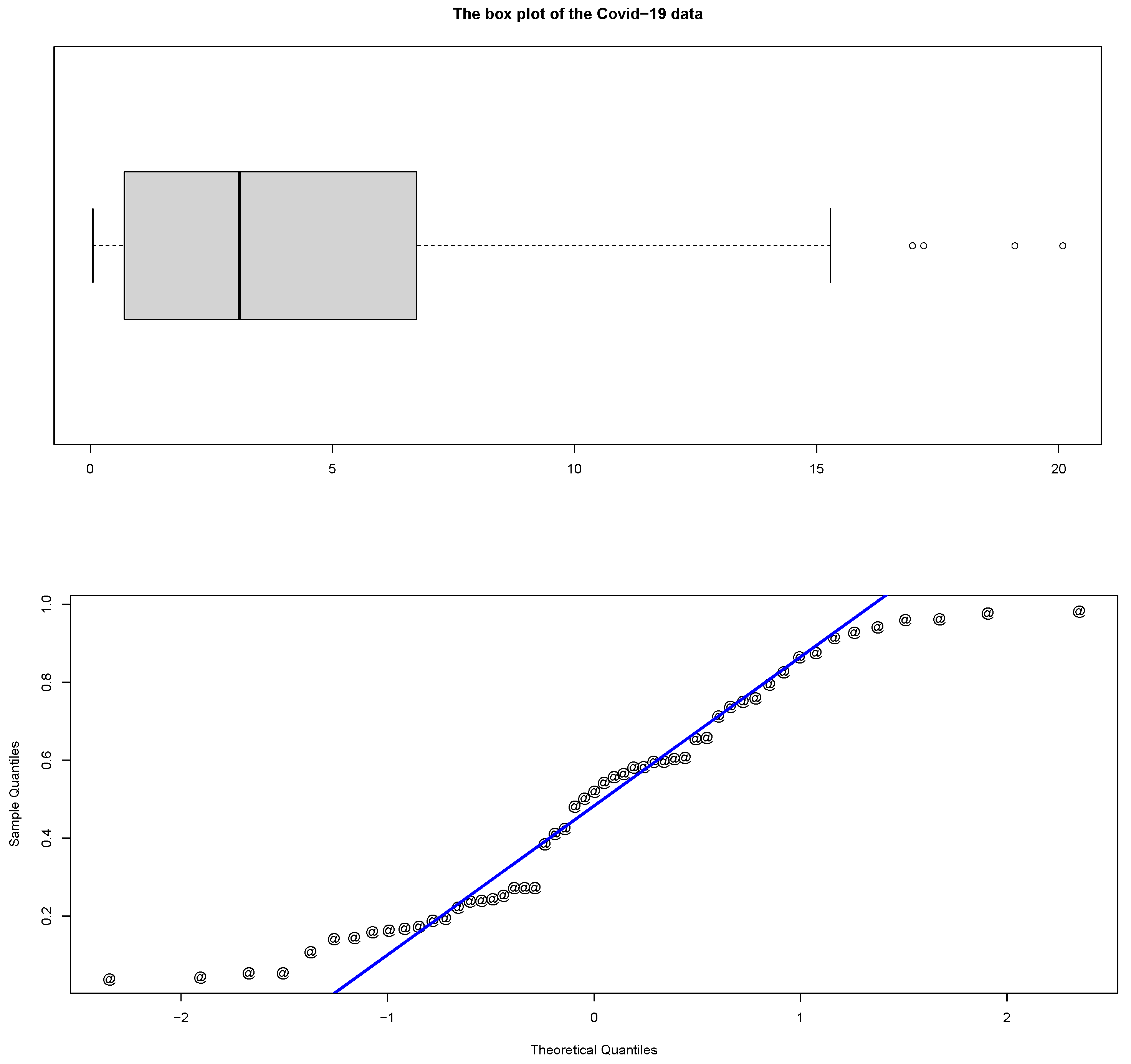
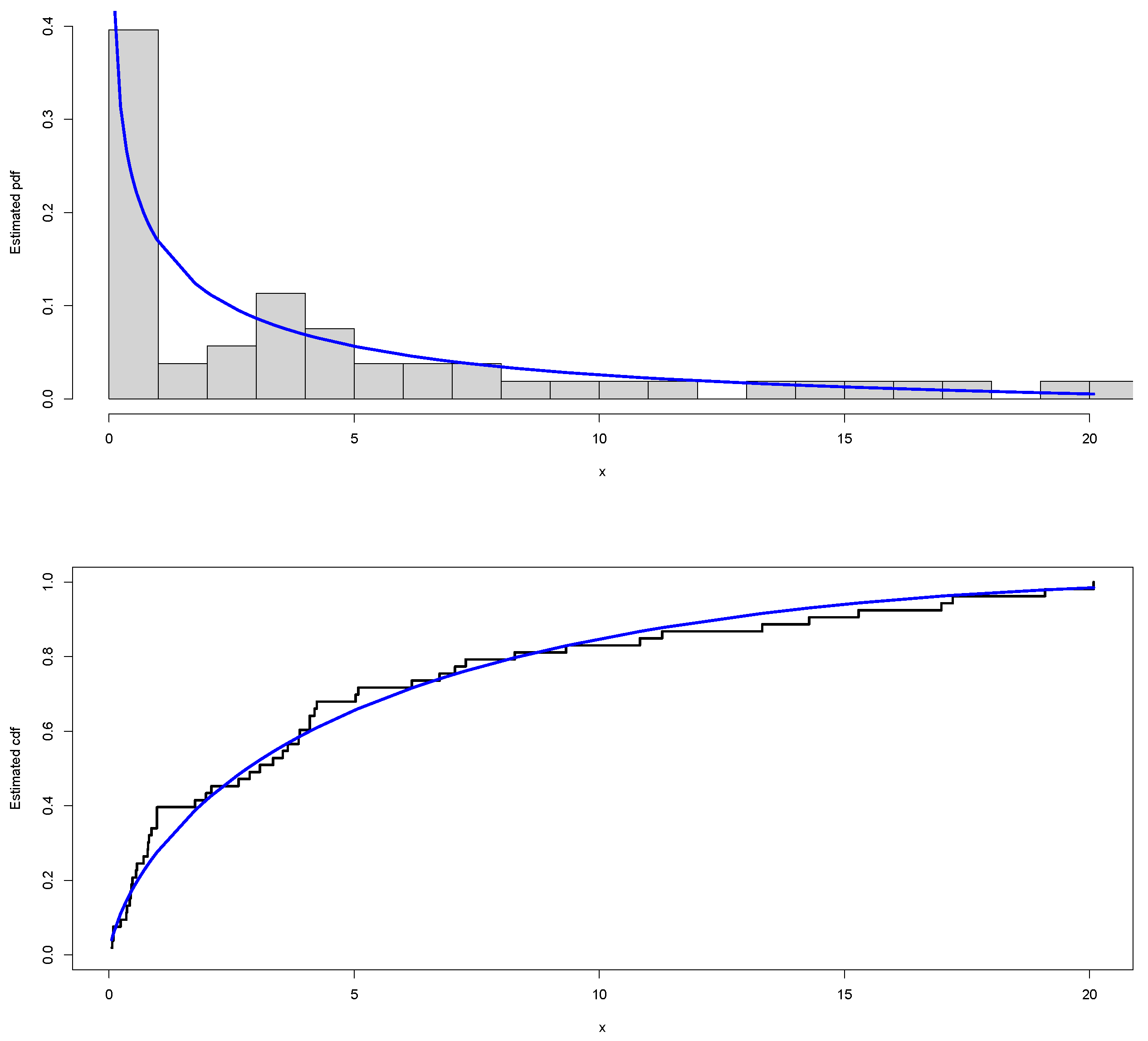
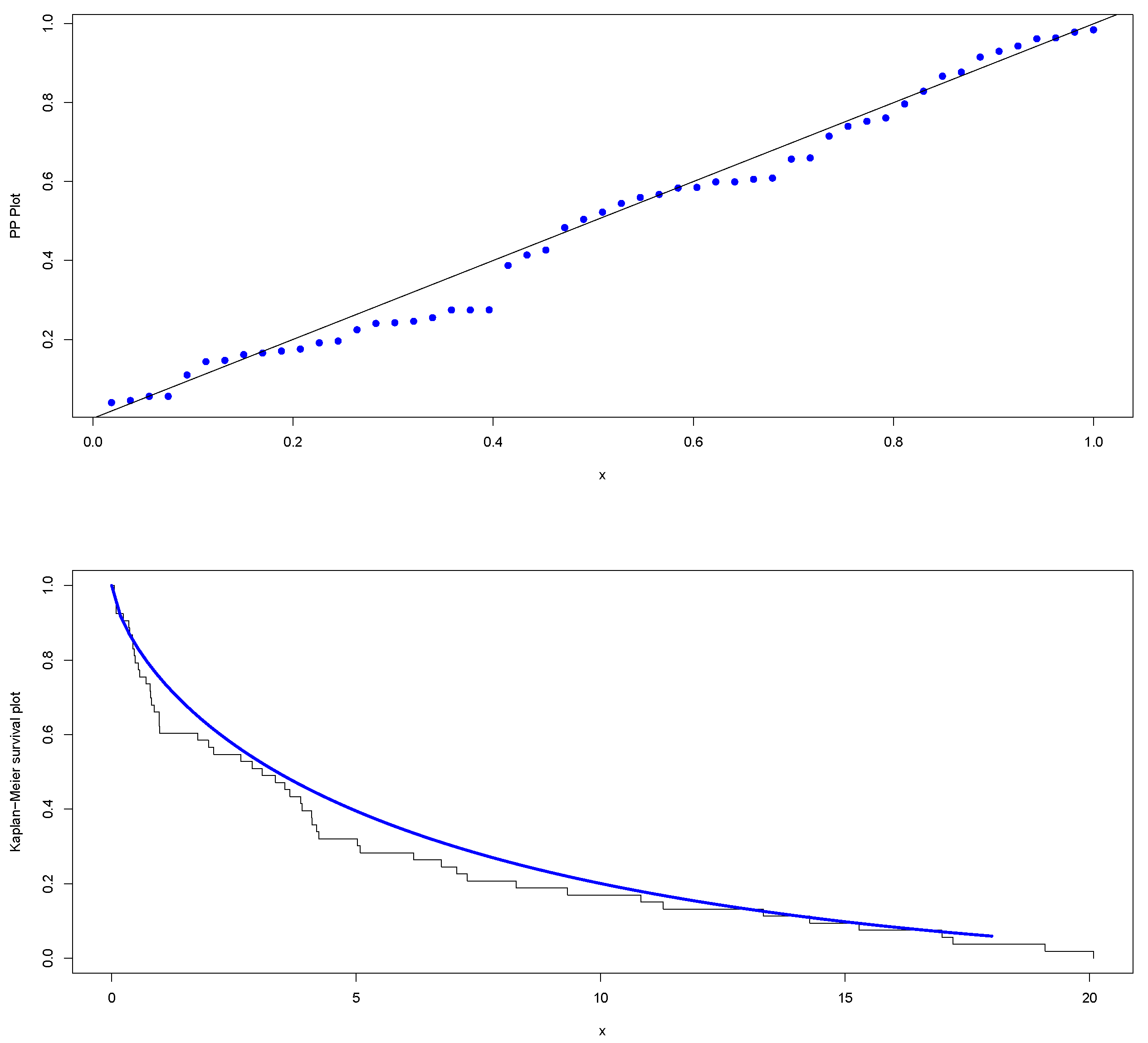
6. COVID-19 Data
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- Frey, J. A note on Fisher information and imperfect ranked-set sampling. Commun. Stat.-Theory Methods 2014, 43, 2726–2733. [Google Scholar] [CrossRef]
- Park, S.; Lim, J. On the effect of imperfect ranking on the amount of Fisher information in ranked set samples. Commun. Stat.-Theory Methods 2012, 413, 3608–3620. [Google Scholar] [CrossRef]
- Chen, Z.; Bai, Z.; Sinha, B. Ranked Set Sampling: Theory and Applications; Springer: New York, NY, USA, 2013. [Google Scholar]
- Tahmasebi, S.; Longobardi, M.; Kazemi, M.R.; Alizadeh, M. Cumulative Tsallis entropy for maximum ranked set sampling with unequal samples. Phys. A Stat. Mech. Appl. 2020, 556, 124763. [Google Scholar] [CrossRef]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; John Wiley & Sons: New York, NY, USA, 1992. [Google Scholar]
- Najma, S.; Alamgir, K.; Wali, K.; Habib, S.; Pijitra, J.; Thammarat, P. A Novel Generalized Family of Distributions for Engineering and Life Sciences Data Applications. Math. Probl. Eng. 2021, 2021, 9949999. [Google Scholar]
- Bowley, A.L. Elements of Statistics, 4th ed.; Charles Scribner’s Sons: New York, NY, USA, 1920. [Google Scholar]
- Moors, J.J.A. The meaning of kurtosis: Darlington re-examined. Am. Stat. 1986, 40, 283–284. [Google Scholar]
- Hong, H.G.; Li, Y. Estimation of time-varying reproduction numbers underlying epidemiological processes: A new statistical tool for the COVID-19 pandemic. PLoS ONE 2020, 15, e0236464. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | |
|---|---|
| 0.1 | 3.30459 |
| 0.2 | 3.54091 |
| 0.3 | 3.97569 |
| 0.4 | 4.74677 |
| 0.5 | 6.13344 |
| 0.6 | 8.75958 |
| 0.7 | 14.2517 |
| 0.8 | 28.0657 |
| 0.9 | 80.4795 |
| n | ||||
|---|---|---|---|---|
| 2.07 | 2.551 | 4.044 | 1.805 | |
| 25 | 4.087 | 4.598 | 2.946 | 0.255 |
| −1.13 | 1.051 | 0.244 | −0.295 | |
| 2.586 | 2.104 | 3.787 | 1.917 | |
| 100 | 3.3 | 2.076 | 1.692 | 0.165 |
| −0.614 | 0.604 | −0.013 | −0.183 | |
| 2.838 | 1.9 | 3.675 | 1.973 | |
| 225 | 2.949 | 1.01 | 1.019 | 0.12 |
| −0.361 | 0.4 | −0.124 | −0.127 | |
| 2.988 | 1.792 | 3.645 | 2.007 | |
| 400 | 2.523 | 0.54 | 0.681 | 0.089 |
| −0.212 | 0.292 | −0.155 | −0.093 | |
| 3.053 | 1.722 | 3.645 | 2.028 | |
| 625 | 2.199 | 0.317 | 0.469 | 0.069 |
| −0.147 | 0.222 | −0.155 | −0.072 | |
| 3.115 | 1.702 | 3.64 | 2.04 | |
| 900 | 2.053 | 0.271 | 0.397 | 0.061 |
| −0.085 | 0.202 | −0.16 | −0.06 |
| n | ||||
|---|---|---|---|---|
| 3.476 | 2.514 | 4.396 | 1.609 | |
| 25 | 6.169 | 4.551 | 5.554 | 0.26 |
| −0.824 | 0.914 | 0.895 | −0.1907 | |
| 3.182 | 2.182 | 3.799 | 1.606 | |
| 100 | 4.908 | 2.272 | 2.602 | 0.155 |
| −1.118 | 0.582 | 0.299 | −0.194 | |
| 3.511 | 1.941 | 3.614 | 1.663 | |
| 225 | 3.812 | 1.072 | 1.324 | 0.095 |
| −0.789 | 0.341 | 0.114 | −0.137 | |
| 3.712 | 1.844 | 3.512 | 1.693 | |
| 400 | 3.257 | 0.578 | 0.768 | 0.066 |
| −0.588 | 0.244 | 0.012 | −0.107 | |
| 3.883 | 1.799 | 3.453 | 1.716 | |
| 625 | 2.644 | 0.361 | 0.471 | 0.047 |
| −0.417 | 0.199 | −0.047 | −0.084 | |
| 4.054 | 1.765 | 3.443 | 1.737 | |
| 900 | 2.274 | 0.27 | 0.386 | 0.035 |
| −0.246 | 0.165 | −0.057 | −0.063 |
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max |
|---|---|---|---|---|---|
| 0.054 | 0.704 | 3.079 | 4.787 | 6.743 | 20.083 |
| Model | p-Value |
|---|---|
| KHGWD | 0.4347 |
| KHGEXP | 0.3776 |
| KHGGamma | 0.4056 |
| Weibull | 0.3776 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Emam, W.; Tashkandy, Y.A. Khalil New Generalized Weibull Distribution Based on Ranked Samples: Estimation, Mathematical Properties, and Application to COVID-19 Data. Symmetry 2022, 14, 853. https://doi.org/10.3390/sym14050853
Emam W, Tashkandy YA. Khalil New Generalized Weibull Distribution Based on Ranked Samples: Estimation, Mathematical Properties, and Application to COVID-19 Data. Symmetry. 2022; 14(5):853. https://doi.org/10.3390/sym14050853
Chicago/Turabian StyleEmam, Walid, and Yusra A. Tashkandy. 2022. "Khalil New Generalized Weibull Distribution Based on Ranked Samples: Estimation, Mathematical Properties, and Application to COVID-19 Data" Symmetry 14, no. 5: 853. https://doi.org/10.3390/sym14050853
APA StyleEmam, W., & Tashkandy, Y. A. (2022). Khalil New Generalized Weibull Distribution Based on Ranked Samples: Estimation, Mathematical Properties, and Application to COVID-19 Data. Symmetry, 14(5), 853. https://doi.org/10.3390/sym14050853