
On the Exiting Patterns of Multivariate Renewal-Reward Processes with an Application to Stochastic Networks


Abstract
:1. Introduction
1.1. Goals and Structure of the Paper
1.2. The Mathematical Setting of the Problem
2. Preliminary Results
3. The Main Result
4. Applications and Special Case Results
4.1. Application to Stochastic Networks
4.2. 2D Exponential Model
4.3. 3D Exponential Model
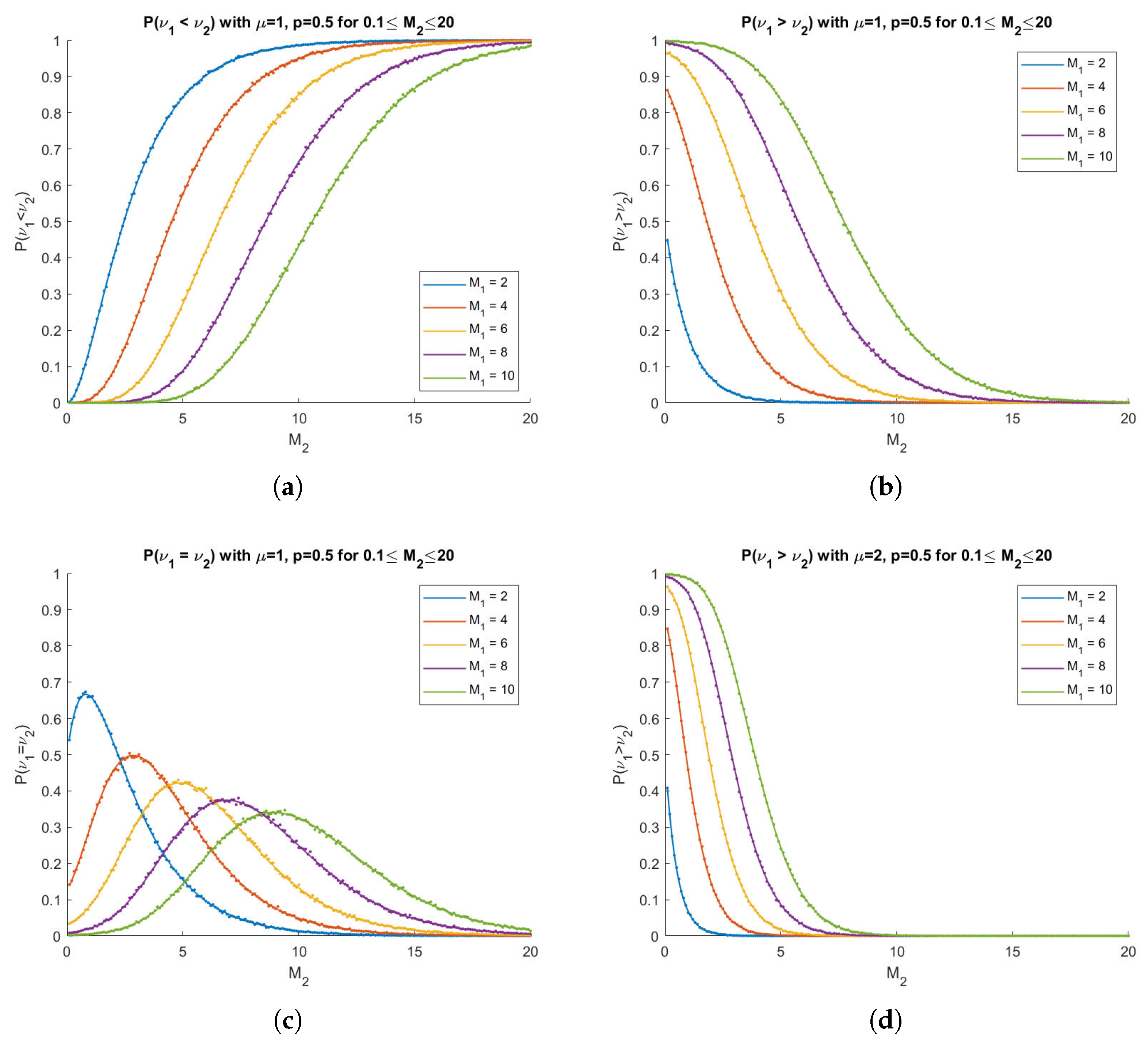
Computational and Simulated Results
- In parameter sets (1)–(4), we have and , so, in each line of the results for each set, the probabilities are the same since there is symmetry between the dimensions such that they are indistinguishable.
- In parameter sets (1)–(4), the s are 1 and the s are equal but increasing. Since the process must travel further to cross thresholds while the distribution of the jumps is fixed, simultaneously crossing multiple thresholds (lines 2–4) becomes less probable.
- Comparing parameter sets (5)–(7) to (1) reveals that increasing a single decreases the mean jump length in coordinate j so that is likely to be crossed later than others. Here, we increase , and the probabilities of , , and , precisely where is crossed last, grow.
- Comparing parameter sets (8)–(10) to (1) reveals that increasing a single has a similar effect as increasing a single :
- −
- Parameter set (8) doubles (doubling the distance to cross ) and parameter set (6) halves (doubling mean jump length in dimension 1), which have the precisely same impact on the probabilities.
- −
- Parameter sets (7) and (9) exhibit an analogous relationship.
4.4. Further Applications of
4.4.1. Applications to Insurance
4.4.2. Reliability Theory
4.4.3. Versatility of Theorem 1
5. Significance and Future Work
Funding
Data Availability Statement
Conflicts of Interest
References
- Wald, A. On cumulative sums of random variables. Ann. Math. Stat. 1944, 15, 283–296. [Google Scholar] [CrossRef]
- Andersen, E.S. On sums of symmetrically dependent random variables. Scand. Actuar. J. 1953, 1953, 123–138. [Google Scholar] [CrossRef]
- Takács, L. On a problem of fluctuations of sums of independent random variables. J. Appl. Probab. 1975, 12, 29–37. [Google Scholar] [CrossRef]
- Takács, L. On fluctuations of sums of random variables. In Sudies in Probability and Ergodic Theory. Advances in Mathematics. Supplementary Studies; Rota, G.C., Ed.; Academic Press: New York, NY, USA, 1978; Volume 2, pp. 45–93. [Google Scholar]
- Erdös, P.; Kac, M. On the number of positive sums of independent random variables. Bull. Am. Math. Soc. 1947, 53, 1011–1021. [Google Scholar] [CrossRef] [Green Version]
- Feller, W. On the fluctuations of sums of independent random variables. Proc. Natl. Acad. Sci. USA 1969, 63, 637–639. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chung, K.L. On the maximum partial sum of independent random variables. Proc. Natl. Acad. Sci. USA 1947, 33, 132–136. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teicher, H. On random sums of random vectors. Ann. Math. Stat. 1965, 36, 1450–1458. [Google Scholar] [CrossRef]
- Iglehart, D.L. Weak Convergence of Probability Measures on Product Spaces with Applications to Sums of Random Vectors; Technical Report 109; Department of Operations Research, Stanford University: Stanford, CA, USA, 1968. [Google Scholar]
- Osipov, L. On large deviations for sums of random vectors in Rk. J. Multivar. Anal. 1981, 11, 115–126. [Google Scholar] [CrossRef] [Green Version]
- Borovkov, A.; Mogulskii, A. Chebyshev-type exponential inequalities for sums of random vectors and for trajectories of random walks. Theory Probab. Its Appl. 2012, 56, 21–43. [Google Scholar] [CrossRef]
- Dshalalow, J.H. On the level crossing of multi-dimensional delayed renewal processes. J. Appl. Math. Stoch. Anal. 1997, 10, 355–361. [Google Scholar] [CrossRef] [Green Version]
- Dshalalow, J.H. Time dependent analysis of multivariate marked renewal processes. J. Appl. Probab. 2001, 38, 707–721. [Google Scholar] [CrossRef]
- Dshalalow, J.H.; Liew, A. On exit times of a multivariate random walk and its embedding in a quasi Poisson process. Stoch. Anal. Appl. 2006, 24, 451–474. [Google Scholar] [CrossRef]
- Dshalalow, J.H.; Liew, A. Level crossings of an oscillating marked random walk. Comput. Math. Appl. 2006, 52, 917–932. [Google Scholar] [CrossRef] [Green Version]
- Novikov, A.; Melchers, R.E.; Shinjikashvili, E.; Kordzakhhia, N. First pasage time of filtered Poisson process with exponential shape function. Probabilistic Eng. Mech. 2005, 20, 57–65. [Google Scholar] [CrossRef]
- Jacobsen, M. The time to ruin for a class of Markov additive risk processes with two-sided jumps. Adv. Appl. Probab. 2005, 37, 963–992. [Google Scholar] [CrossRef] [Green Version]
- Crescenzo, A.D.; Martinucci, B. On a first-passage-time problem for the compound power-law process. Stoch. Model. 2009, 25, 420–435. [Google Scholar] [CrossRef]
- Bo, L.; Lefebre, M. Mean first passage times of two-dimensional processes with jumps. Stat. Prob. Lett. 2011, 81, 1183–1189. [Google Scholar] [CrossRef]
- Coutin, L.; Dorobantu, D. First passage time law for some Lévy processes with compound Poisson: Existence of a density. Bernoulli 2011, 17, 1127–1135. [Google Scholar] [CrossRef]
- Kadankov, V.F.; Kadankova, T.V. On the distribution of the first exit time from an interval and the value of the overjump across a boundary for processes with independent increments and random walks. Random Oper. Stoch. Equ. 2005, 13, 219–244. [Google Scholar] [CrossRef]
- Kadankova, T.V. Exit, passage, and crossing time and overshoots for a Poisson compound process with an exponential component. Theory Probab. Math. Stat. 2007, 75, 23–29. [Google Scholar] [CrossRef] [Green Version]
- Aurzada, F.; Iksanov, A.; Meiners, M. Exponential moments of first passage time and related quantities for Lévy processes. Math. Nachrichten 2015, 288, 1921–1938. [Google Scholar] [CrossRef] [Green Version]
- Bernyk, V.; Dalang, R.C.; Peskir, G. The law of the supremum of stable Lévy processes with no negative jumps. Ann. Probab. 2008, 36, 1777–1789. [Google Scholar] [CrossRef] [Green Version]
- White, R.T.; Dshalalow, J.H. Characterizations of random walks on random lattices and their ramifications. Stoch. Anal. Appl. 2019, 38, 307–342. [Google Scholar] [CrossRef]
- Chaumont, L.; Marolleau, M. Fluctuation theory for spectrally positive additive Lévy fields. arXiv 2019, arXiv:1912.10474. [Google Scholar] [CrossRef]
- Borovkov, K.A.; Dickson, D.C.M. On the ruin time distribution for a Sparre Andersen process with exponential claim sizes. Insur. Math. Econ. 2008, 42, 1104–1108. [Google Scholar] [CrossRef] [Green Version]
- Yin, C.; Shen, Y.; Wen, Y. Exit problems for jump processes with applications to dividend problems. J. Comput. Appl. Math. 2013, 245, 30–52. [Google Scholar] [CrossRef]
- Yin, C.; Wen, Y.; Zong, Z.; Shen, Y. The first passage problem for mixed-exponential jump processes with applications in insurance and finance. Abstr. Appl. Anal. 2014, 2014, 571724. [Google Scholar] [CrossRef] [Green Version]
- Dshalalow, J.; Liew, A. On fluctuations of a multivariate random walk with some applications to stock options trading and hedging. Math. Comput. Model. 2006, 44, 931–944. [Google Scholar] [CrossRef]
- Kyprianou, A.E.; Pistorius, M.R. Perpetual options and Canadization through fluctuation theory. Ann. Appl. Probab. 2003, 13, 1077–1098. [Google Scholar] [CrossRef] [Green Version]
- Mellander, E.; Vredin, A.; Warne, A. Stochastic trends and economic fluctuations in a small open economy. J. Appl. Econom. 1992, 7, 369–394. [Google Scholar] [CrossRef]
- Dshalalow, J.H. Random walk analysis in antagonistic stochastic games. Stoch. Anal. Appl. 2008, 26, 738–783. [Google Scholar] [CrossRef]
- Dshalalow, J.H.; Iwezulu, K.; White, R.T. Discrete operational calculus in delayed stochastic games. Neural Parallel Sci. Comput. 2016, 24, 55–64. [Google Scholar]
- Takács, L. Introduction to the Theory of Queues; Oxford University: Oxford, UK, 1962. [Google Scholar]
- Dshalalow, J.H.; Merie, A.; White, R.T. Fluctuation analysis in parallel queues with hysteretic control. Methodol. Comput. Appl. Probab. 2019, 22, 295–327. [Google Scholar] [CrossRef]
- Ali, E.; AlObaidi, A. On first excess level analysis of hysteretic bilevel control queue with multiple vacations. Int. J. Nonlinear Anal. Appl. 2021, 12, 2131–2144. [Google Scholar] [CrossRef]
- Dshalalow, J.H.; White, R.T. On reliability of stochastic networks. Neural Parallel Sci. Comput. 2013, 21, 141–160. [Google Scholar]
- Dshalalow, J.H.; White, R.T. On strategic defense in stochastic networks. Stoch. Anal. Appl. 2014, 32, 365–396. [Google Scholar] [CrossRef]
- Abolnikov, L.; Dshalalow, J.H. A first passage problem and its applications to the analysis of a class of stochastic models. Int. J. Stoch. Anal. 1992, 5, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Polyanin, A.; Manzhirov, A. Handbook of Integral Equations; Chapman and Hall/CRC: Boca Raton, FL, USA, 2008. [Google Scholar] [CrossRef]
- Talbot, A. The accurate numerical inversion of Laplace transforms. IMA J. Appl. Math. 1979, 23, 97–120. [Google Scholar] [CrossRef]
- McClure, T. Numerical Inverse Laplace Transform. MATLAB Central File Exchange. 2022. Available online: https://www.mathworks.com/matlabcentral/fileexchange/39035-numerical-inverse-laplace-transform (accessed on 5 June 2022).
- Abate, J.; Whitt, W. A unified framework for numerically inverting Laplace transforms. INFORMS J. Comput. 2006, 18, 408–421. [Google Scholar] [CrossRef] [Green Version]
- White, R.T. Random Walks on Random Lattices and Their Applications. Ph.D. Thesis, Florida Institute of Technology, Melbourne, FL, USA, 2015. [Google Scholar]
- Al-Matar, N.; Dshalalow, J.H. Time sensitive functionals in a queue with sequential maintenance. Stoch. Model. 2011, 27, 687–704. [Google Scholar] [CrossRef]
- Dshalalow, J.H.; Merie, A. Fluctuation analysis in queues with several operational modes and priority customers. TOP 2018, 26, 309–333. [Google Scholar] [CrossRef]
- Dshalalow, J.H.; White, R.T. Random walk analysis in a reliability system under constant degradation and random shocks. Axioms 2021, 10, 199. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Parameters | Signs | Predicted Probabilities | Errors |
|---|---|---|---|
| (1) | 0.125 0.125 0.125 0.125 0.125 0.125 | Sum = 0.003 | |
| 0.042 0.042 0.042 | Max | ||
| 0.039 0.039 0.039 | |||
| 0.009 | |||
| (2) | 0.137 0.137 0.137 0.137 0.137 0.137 | Sum = 0.002 | |
| 0.030 0.030 0.030 | Max | ||
| 0.029 0.029 0.029 | |||
| 0.005 | |||
| (3) | 0.147 0.147 0.147 0.147 0.147 0.147 | Sum = 0.003 | |
| 0.019 0.019 0.019 | Max | ||
| 0.019 0.019 0.019 | |||
| 0.002 | |||
| (4) | 0.153 0.153 0.153 0.153 0.153 0.153 | Sum = 0.002 | |
| 0.014 0.014 0.014 | Max | ||
| 0.014 0.014 0.014 | |||
| 0.001 | |||
| (5) | 0.358 0.358 0.048 0.008 0.048 0.008 | Sum = 0.002 | |
| 0.035 0.035 0.005 | Max | ||
| 0.082 0.007 0.007 | |||
| 0.004 | |||
| (6) | 0.002 0.002 0.018 0.422 0.018 0.422 | Sum = 0.002 | |
| 0.002 0.002 0.088 | Max | ||
| 0.001 0.011 0.011 | |||
| 0.001 | |||
| (7) | 0.000 0.000 0.000 0.455 0.000 0.455 | Sum = 0.002 | |
| 0.000 0.000 0.090 | Max | ||
| 0.000 0.000 0.000 | |||
| 0.000 | |||
| (8) | 0.002 0.002 0.018 0.422 0.018 0.422 | Sum = 0.001 | |
| 0.002 0.002 0.088 | Max | ||
| 0.001 0.011 0.011 | |||
| 0.001 | |||
| (9) | 0.000 0.000 0.000 0.455 0.000 0.455 | Sum = 0.002 | |
| 0.000 0.000 0.000 0.090 | Max | ||
| 0.000 0.000 0.000 | |||
| 0.000 | |||
| (10) | 0.000 0.000 0.000 0.455 0.000 0.455 | Sum | |
| 0.000 0.000 0.090 | Max | ||
| 0.000 0.000 0.000 | |||
| 0.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
White, R.T. On the Exiting Patterns of Multivariate Renewal-Reward Processes with an Application to Stochastic Networks. Symmetry 2022, 14, 1167. https://doi.org/10.3390/sym14061167
White RT. On the Exiting Patterns of Multivariate Renewal-Reward Processes with an Application to Stochastic Networks. Symmetry. 2022; 14(6):1167. https://doi.org/10.3390/sym14061167
Chicago/Turabian StyleWhite, Ryan T. 2022. "On the Exiting Patterns of Multivariate Renewal-Reward Processes with an Application to Stochastic Networks" Symmetry 14, no. 6: 1167. https://doi.org/10.3390/sym14061167
APA StyleWhite, R. T. (2022). On the Exiting Patterns of Multivariate Renewal-Reward Processes with an Application to Stochastic Networks. Symmetry, 14(6), 1167. https://doi.org/10.3390/sym14061167