
A Quadratic Surface Minimax Probability Machine for Imbalanced Classification


Abstract
:1. Introduction
2. Related Work
2.1. Minimax Probability Machine (MPM)
2.2. Soft Quadratic Surface Support Vector Machine (SQSSVM)
2.3. Value
3. A Quadratic Surface Minimax Probability Machine with a Mixed Performance Measure
3.1. The Proposed Model
3.2. Algorithm for QSMPMFA
| Algorithm 1: Training process of QSMPMFA |
Input: Training set , C, . Output: , , . 2. Calculate the mean and covariance matrices , according to formula (25). 3. Denote . 4. for t =1, 2, ⋯ do 5. Calculate by solving Problem (31). 6. Calculate the objective function of Problem (30), i.e., . 7. Let , . 8. While the condition (36) is not met 9. update by using formula (35). 10. End 11. Let , calculate the objective function of Problem (30), i.e., . 12. If 13. terminate 14. End 15. End |
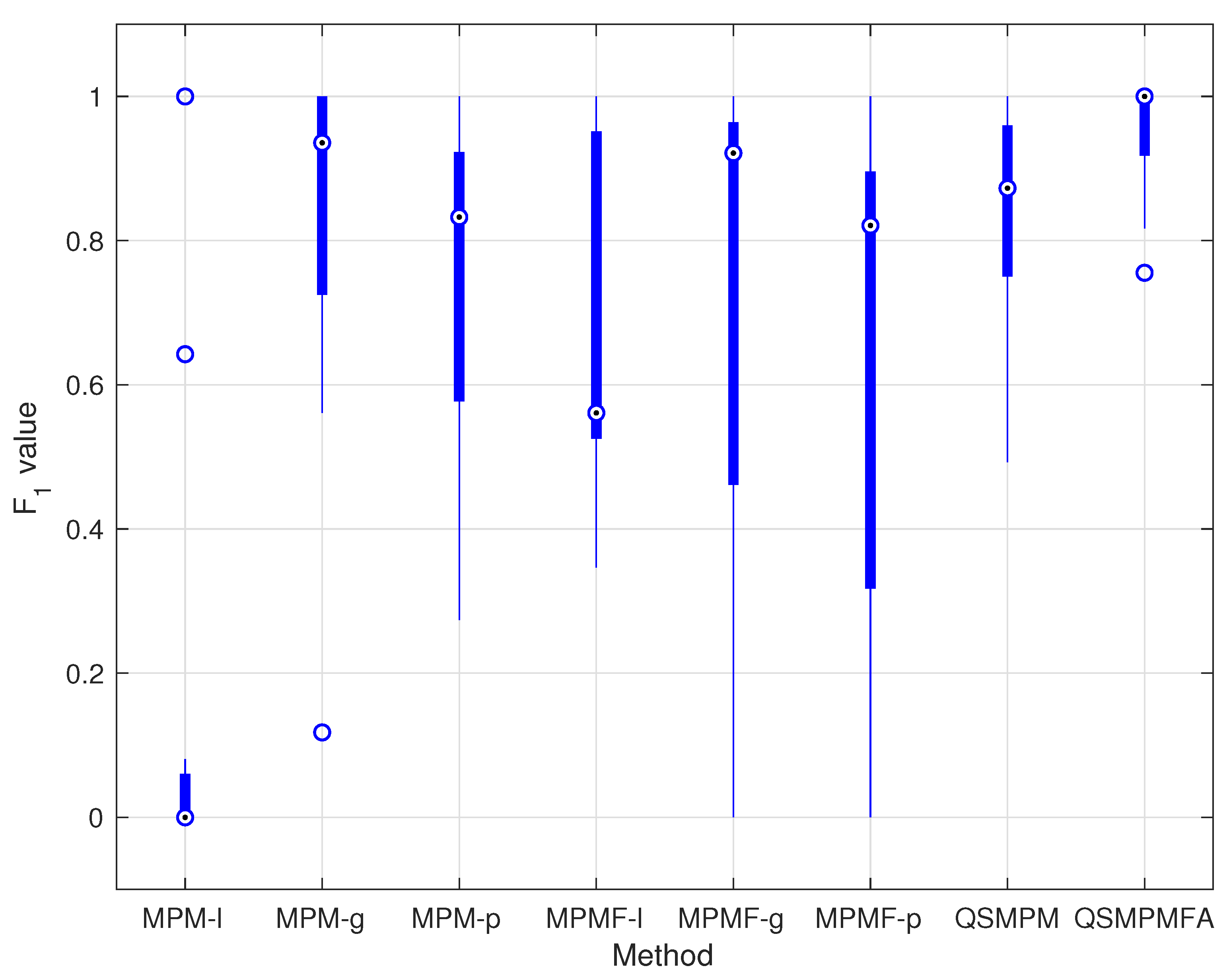
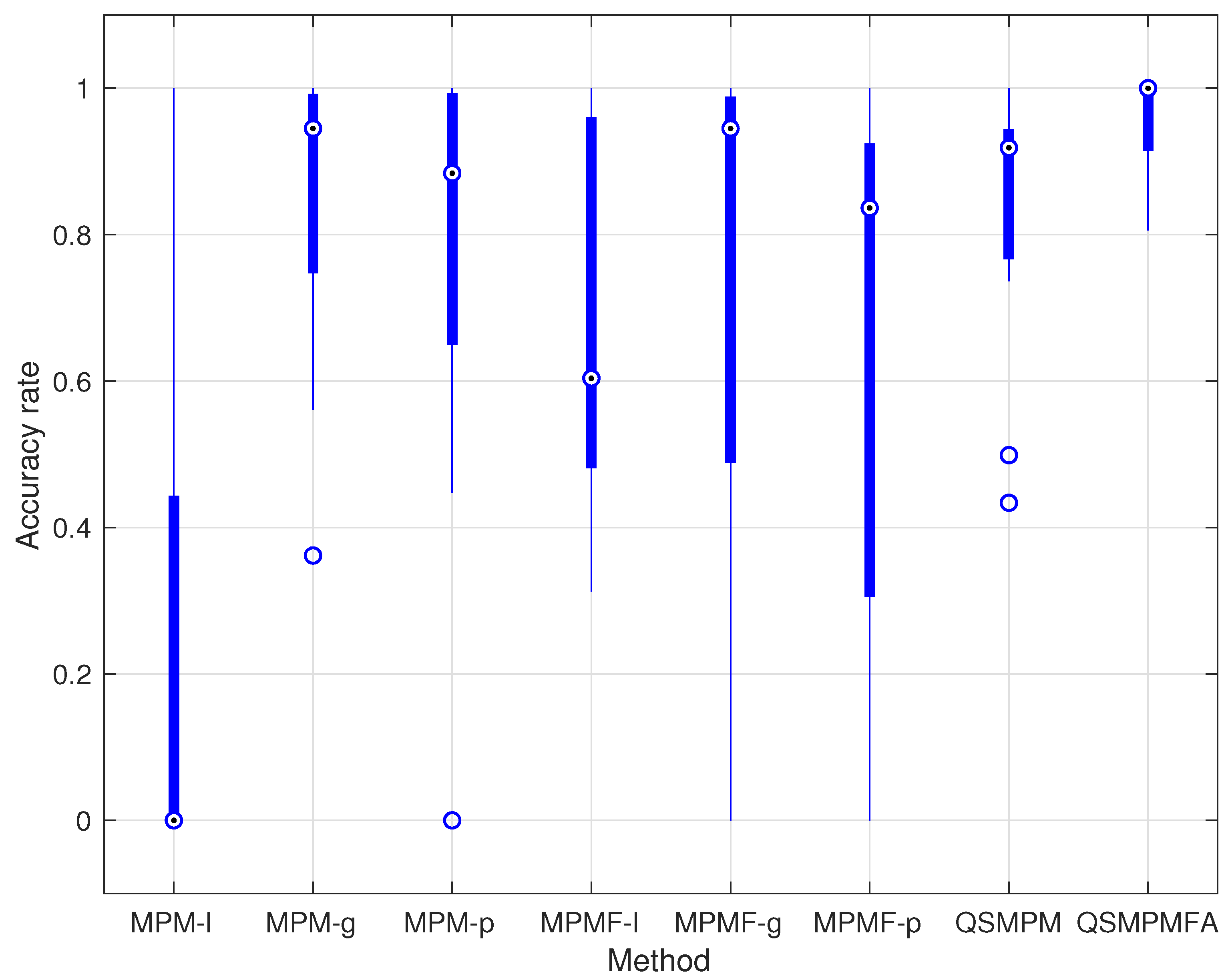
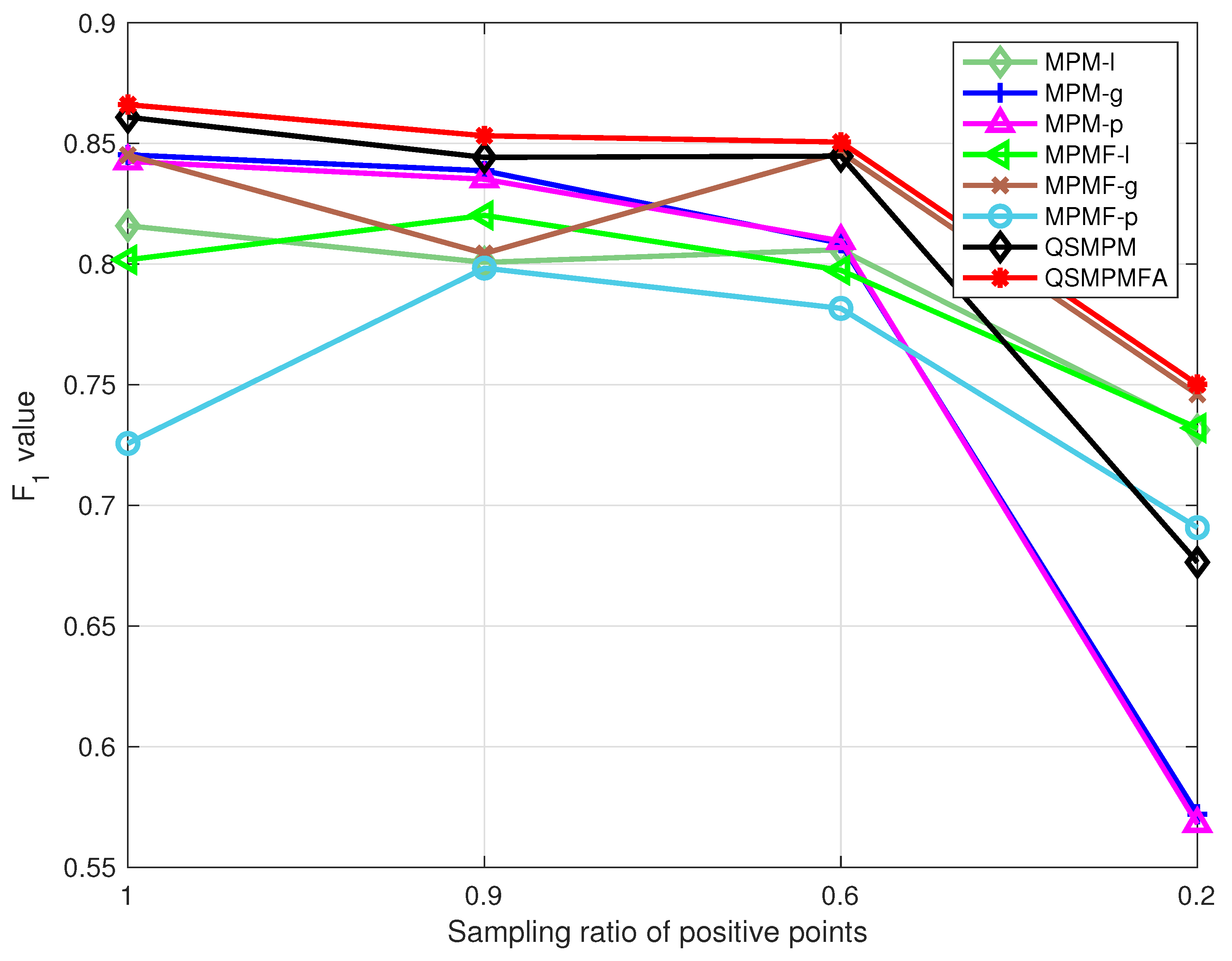
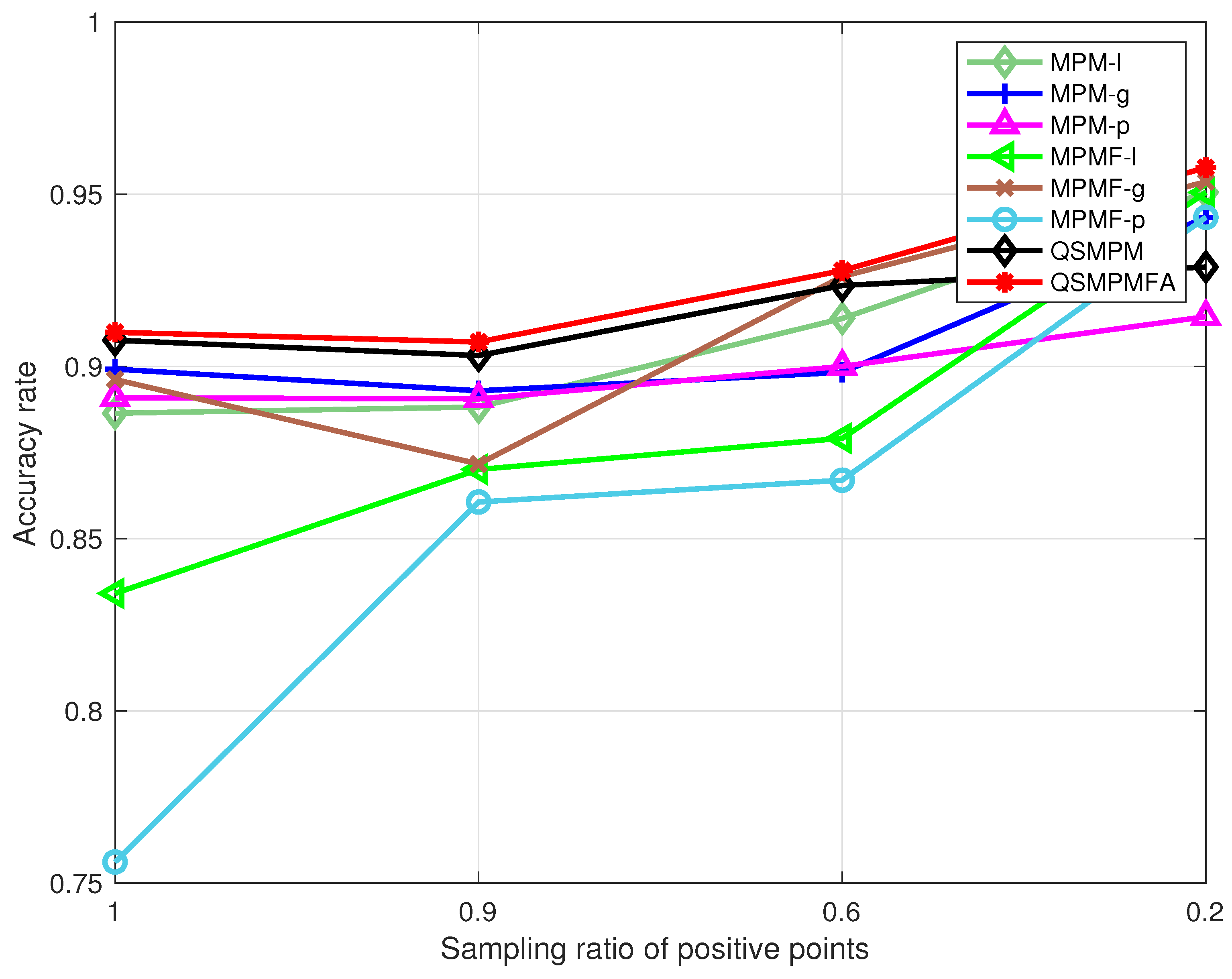
4. Numerical Tests
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lanckriet, G.R.G.; El Ghaoui, L.; Bhattacharyya, C.; Jordan, M.I. Minimax probability machine. In Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic; MIT Press: Cambridge, MA, USA, 2001; pp. 801–807. [Google Scholar]
- Huang, K.; Yang, H.; King, I.; Lyu, M.R.; Chan, L. Biased minimax probability machine for medical diagnosis. In Proceedings of the 8th International Symposium on Artificial Intelligence & Mathematics, Fort Lauderdale, FL, USA, 4–6 January 2004. [Google Scholar]
- Jiang, B.; Guo, Z.; Zhu, Q.; Huang, G. Dynamic minimax probability machine-based approach for fault diagnosis using pairwise discriminate analysis. IEEE Trans. Control. Syst. Technol. 2017, 27, 806–813. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Vairetti, C. Profit-based churn prediction based on minimax probability machines. Eur. J. Oper. Res. 2020, 284, 273–284. [Google Scholar] [CrossRef]
- Huang, K.; Yang, H.; King, I.; Lyu, M.R.; Chan, L. The minimum error minimax probability machine. J. Mach. Learn. Res. 2004, 5, 1253–1286. [Google Scholar]
- Huang, K.; Yang, H.; King, I.; Lyu, M.R. Imbalanced learning with a biased minimax probability machine. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2006, 36, 913–923. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.; Qiao, H.; Zhang, B. A minimax probability machine for nondecomposable performance measures. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Nath, J.S.; Bhattacharyya, C. Maximum margin classifiers with specified false positive and false negative error rates. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 35–46. [Google Scholar]
- Maldonado, S.; Carrasco, M.; López, J. Regularized minimax probability machine. Knowl.-Based Syst. 2019, 177, 127–135. [Google Scholar] [CrossRef]
- Jayadeva; Khemchandani, R.; Chandra, S. Twin support vector machines for pattern classification. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 905–910. [Google Scholar]
- Yang, L.; Wen, Y.; Zhang, M.; Wang, X. Twin minimax probability machine for pattern classification. Neural Netw. 2020, 131, 201–214. [Google Scholar] [CrossRef] [PubMed]
- Dagher, I. Quadratic kernel-free non-linear support vector machine. J. Glob. Optim. 2008, 4, 15–30. [Google Scholar] [CrossRef]
- Luo, J.; Fang, S.C.; Deng, Z.; Guo, X. Soft quadratic surface support vector machine for binary classification. Asia-Pac. J. Oper. Res. 2016, 33, 1650046. [Google Scholar] [CrossRef]
- Bai, Y.; Han, X.; Chen, T.; Yu, H. Quadratic kernel-free least squares support vector machine for target diseases classification. J. Comb. Optim. 2015, 30, 850–870. [Google Scholar] [CrossRef]
- Yan, X.; Bai, Y.; Fang, S.C.; Luo, J. A kernel-free quadratic surface support vector machine for semi-supervised learning. J. Oper. Res. Soc. 2016, 67, 1001–1011. [Google Scholar] [CrossRef]
- Tian, Y.; Sun, M.; Deng, Z.; Luo, J.; Li, Y. A new fuzzy set and nonkernel SVM approach for mislabeled binary classification with applications. IEEE Trans. Fuzzy Syst. 2017, 25, 1536–1545. [Google Scholar] [CrossRef]
- Luo, J.; Yan, X.; Tian, Y. Unsupervised quadratic surface support vector machine with application to credit risk assessment. Eur. J. Oper. Res. 2020, 280, 1008–1017. [Google Scholar] [CrossRef]
- Gao, Z.; Fang, S.C.; Luo, J.; Medhin, N. A kernel-free double well potential support vector machine with applications. Eur. J. Oper. Res. 2021, 290, 248–262. [Google Scholar] [CrossRef]
- Yan, X.; Zhu, H. A novel robust support vector machine classifier with feature mapping. Knowl.-Based Syst. 2022, 257, 109928. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, Z.; Yang, X. Kernel-free quadratic surface minimax probability machine for a binary classification problem. Symmetry 2021, 13, 1378. [Google Scholar] [CrossRef]
- Lanckriet, G.R.; Ghaoui, L.E.; Bhattacharyya, C.; Jordan, M.I. A robust minimax approach to classification. J. Mach. Learn. Res. 2002, 3, 555–582. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Zhou, Z. Machine Learning; Tsinghua University Press: Beijing, China, 2016. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 1 January 2022).
- Chang, J.; He, L.; Chen, L.; Shen, Z.; Chuah, L.F.; Bokhari, A.; Klemeš, J.J.; Han, N. Numerical simulation of liquid jet atomization in subsonic crossflow. Energy 2022, 257, 124676. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Positive # | Negative # | Total # | Feature # | Imbalanced Ratio |
|---|---|---|---|---|---|
| Iris | 50 | 50 | 100 | 4 | 1 |
| Seeds | 70 | 70 | 140 | 7 | 1 |
| Glass | 51 | 163 | 214 | 9 | 3.20 |
| Wholesale customers | 142 | 298 | 440 | 7 | 2.10 |
| WDBC | 212 | 357 | 569 | 30 | 1.68 |
| Balance | 288 | 288 | 576 | 4 | 1 |
| Breast cancer | 241 | 458 | 699 | 9 | 1.90 |
| Banknote | 610 | 762 | 1372 | 4 | 1.25 |
| Segment | 330 | 1980 | 2310 | 19 | 6 |
| Rice | 1630 | 2180 | 3810 | 7 | 1.34 |
| Dry Bean | 1322 | 12289 | 13,611 | 16 | 9.30 |
| Skin | 50,859 | 194,198 | 245,057 | 3 | 3.82 |
| Data Set | MPM-l | MPM-g | MPM-p | MPMF-l | MPMF-g | PMPF-p | QSMPM | QSMPMFA |
|---|---|---|---|---|---|---|---|---|
| Iris | 1.0000± 0.0000 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 0.9968 ± 0.0102 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 |
| Seeds | 0.9530 ± 0.0309 | 0.9907 ± 0.0120 | 0.9887 ± 0.0130 | 0.9839 ± 0.0188 | 0.9643 ± 0.0454 | 0.9497 ± 0.0291 | 0.9699 ± 0.295 | 0.9862 ± 0.0160 |
| Glass | 0.7728 ± 0.0702 | 0.8456 ± 0.0472 | 0.8722 ± 0.0558 | 0.8158 ± 0.0452 | 0.8795 ± 0.0478 | 0.8604 ± 0.0504 | 0.8259 ± 0.0463 | 0.8534 ± 0.0564 |
| Wholesale customers | 0.8158 ± 0.0413 | 0.8452 ± 0.0421 | 0.8425 ± 0.0164 | 0.8017 ± 0.1277 | 0.8451 ± 0.0430 | 0.7256 ± 0.1361 | 0.8608 ± 0.0327 | 0.8660 ± 0.0379 |
| WDBC | 0.9357 ± 0.0172 | 0.9495 ± 0.0192 | 0.9524 ± 0.0171 | 0.9495 ± 0.0195 | 0.9548 ± 0.0194 | 0.9519 ± 0.0108 | 0.9598 ± 0.0162 | 0.9603 ± 0.0116 |
| Balance | 0.9448 ± 0.0147 | 0.9901 ± 0.0087 | 0.9849 ± 0.0126 | 0.9605 ± 0.0105 | 0.9885 ± 0.0066 | 0.9596 ± 0.0099 | 0.9878 ± 0.0080 | 0.9818 ± 0.0105 |
| Breast cancer | 0.9427 ± 0.0158 | 0.9558 ± 0.0156 | 0.9503 ± 0.0210 | 0.9500 ± 0.0200 | 0.9556 ± 0.0142 | 0.9471 ± 0.0294 | 0.9527 ± 0.0158 | 0.9567 ± 0.0117 |
| Banknote | 0.8619 ± 0.0253 | 0.9895 ± 0.0042 | 0.9820 ± 0.0050 | 0.9850 ± 0.0060 | 0.9908 ± 0.0071 | 0.9823 ± 0.0069 | 0.9773 ± 0.0070 | 0.9957 ± 0.0057 |
| Segment | 0.5791 ± 0.0164 | 0.6265 ± 0.0714 | 0.7106 ± 0.0521 | 0.9660 ± 0.0120 | 0.9771 ± 0.0312 | 0.9110 ± 0.0359 | 0.9302 ± 0.0209 | 0.9814 ± 0.0153 |
| Rice | 0.9047 ± 0.0094 | 0.9142 ± 0.0237 | 0.9073 ± 0.0313 | 0.9098 ± 0.0074 | 0.9063 ± 0.0117 | 0.9131 ± 0.0078 | 0.9135 ± 0.0074 | 0.9142 ± 0.0080 |
| Dry Bean | 0.5263 ± 0.0121 | 0.8361 ± 0.0436 | 0.8117 ± 0.0393 | 0.8790 ± 0.0109 | 0.8639 ± 0.0078 | 0.8617 ± 0.0082 | 0.8353 ± 0.0135 | 0.8867 ± 0.0097 |
| Skin | 0.8098 ± 0.0017 | - | - | 0.8793 ± 0.0013 | - | - | 0.8562 ± 0.0012 | 0.8824 ± 0.0178 |
| Average rank | 7.08 | 3.83 | 4.79 | 4.79 | 3.96 | 5.46 | 4.08 | 2.00 |
| Data Set | MPM-l | MPM-g | MPM-p | MPMF-l | MPMF-g | PMPF-p | QSMPM | QSMPMFA |
|---|---|---|---|---|---|---|---|---|
| Iris | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 0.9967 ± 0.0105 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 | 1.0000 ± 0.0000 |
| Seeds | 0.9524 ± 0.0317 | 0.9905 ± 0.0123 | 0.9893 ± 0.0144 | 0.9833 ± 0.0196 | 0.9619 ± 0.0504 | 0.9476 ± 0.0310 | 0.9690 ± 0.0298 | 0.9857 ± 0.0166 |
| Glass | 0.8938 ± 0.0328 | 0.9281 ± 0.0223 | 0.9406 ± 0.0280 | 0.9125 ± 0.0235 | 0.9406 ± 0.0242 | 0.9375 ± 0.0156 | 0.9141 ± 0.0247 | 0.9328 ± 0.0256 |
| Wholesale customers | 0.8864 ± 0.0250 | 0.8992 ± 0.0305 | 0.8909 ± 0.0148 | 0.8341 ± 0.1572 | 0.8962 ± 0.0297 | 0.7561 ± 0.1686 | 0.9076 ± 0.0220 | 0.9099 ± 0.0221 |
| WDBC | 0.9520 ± 0.0132 | 0.9626 ± 0.0144 | 0.9709 ± 0.0137 | 0.9632 ± 0.0138 | 0.9661 ± 0.0148 | 0.9637 ± 0.0087 | 0.9696 ± 0.0126 | 0.9708 ± 0.0087 |
| Balance | 0.9453 ± 0.0143 | 0.9901 ± 0.0087 | 0.9849 ± 0.0127 | 0.9593 ± 0.0110 | 0.9884 ± 0.0067 | 0.9581 ± 0.0104 | 0.9878 ± 0.0080 | 0.9814 ± 0.0109 |
| Breast cancer | 0.9603 ± 0.0108 | 0.9689 ± 0.0111 | 0.9656 ± 0.0141 | 0.9646 ± 0.0138 | 0.9689 ± 0.0099 | 0.9636 ± 0.0199 | 0.9670 ± 0.0109 | 0.9694 ± 0.0082 |
| Banknote | 0.8789 ± 0.0214 | 0.9914 ± 0.0021 | 0.9872 ± 0.0042 | 0.9864 ± 0.0055 | 0.9917 ± 0.0064 | 0.9840 ± 0.0063 | 0.9794 ± 0.0065 | 0.9961 ± 0.0051 |
| Segment | 0.7924 ± 0.0144 | 0.8658 ± 0.0347 | 0.8831 ± 0.0305 | 0.9902 ± 0.0036 | 0.9953 ± 0.0095 | 0.9729 ± 0.0116 | 0.9788 ± 0.0066 | 0.9947 ± 0.0044 |
| Rice | 0.9182 ± 0.0082 | 0.9248 ± 0.0127 | 0.9094 ± 0.0216 | 0.9190 ± 0.0068 | 0.9158 ± 0.0113 | 0.9227 ± 0.0068 | 0.9241 ± 0.0067 | 0.9253 ± 0.0071 |
| Dry Bean | 0.8412 ± 0.0065 | 0.9490 ± 0.0208 | 0.9571 ± 0.0202 | 0.9761 ± 0.0022 | 0.9771 ± 0.0032 | 0.9705 ± 0.0047 | 0.9634 ± 0.0034 | 0.9775 ± 0.0022 |
| Skin | 0.9096 ± 0.0008 | - | - | 0.9430 ± 0.0007 | - | - | 0.9342 ± 0.0006 | 0.9448 ± 0.0089 |
| Average rank | 6.92 | 4.08 | 4.46 | 4.83 | 3.83 | 5.63 | 4.08 | 2.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, X.; Xiao, Z.; Ma, Z. A Quadratic Surface Minimax Probability Machine for Imbalanced Classification. Symmetry 2023, 15, 230. https://doi.org/10.3390/sym15010230
Yan X, Xiao Z, Ma Z. A Quadratic Surface Minimax Probability Machine for Imbalanced Classification. Symmetry. 2023; 15(1):230. https://doi.org/10.3390/sym15010230
Chicago/Turabian StyleYan, Xin, Zhouping Xiao, and Zheng Ma. 2023. "A Quadratic Surface Minimax Probability Machine for Imbalanced Classification" Symmetry 15, no. 1: 230. https://doi.org/10.3390/sym15010230
APA StyleYan, X., Xiao, Z., & Ma, Z. (2023). A Quadratic Surface Minimax Probability Machine for Imbalanced Classification. Symmetry, 15(1), 230. https://doi.org/10.3390/sym15010230