

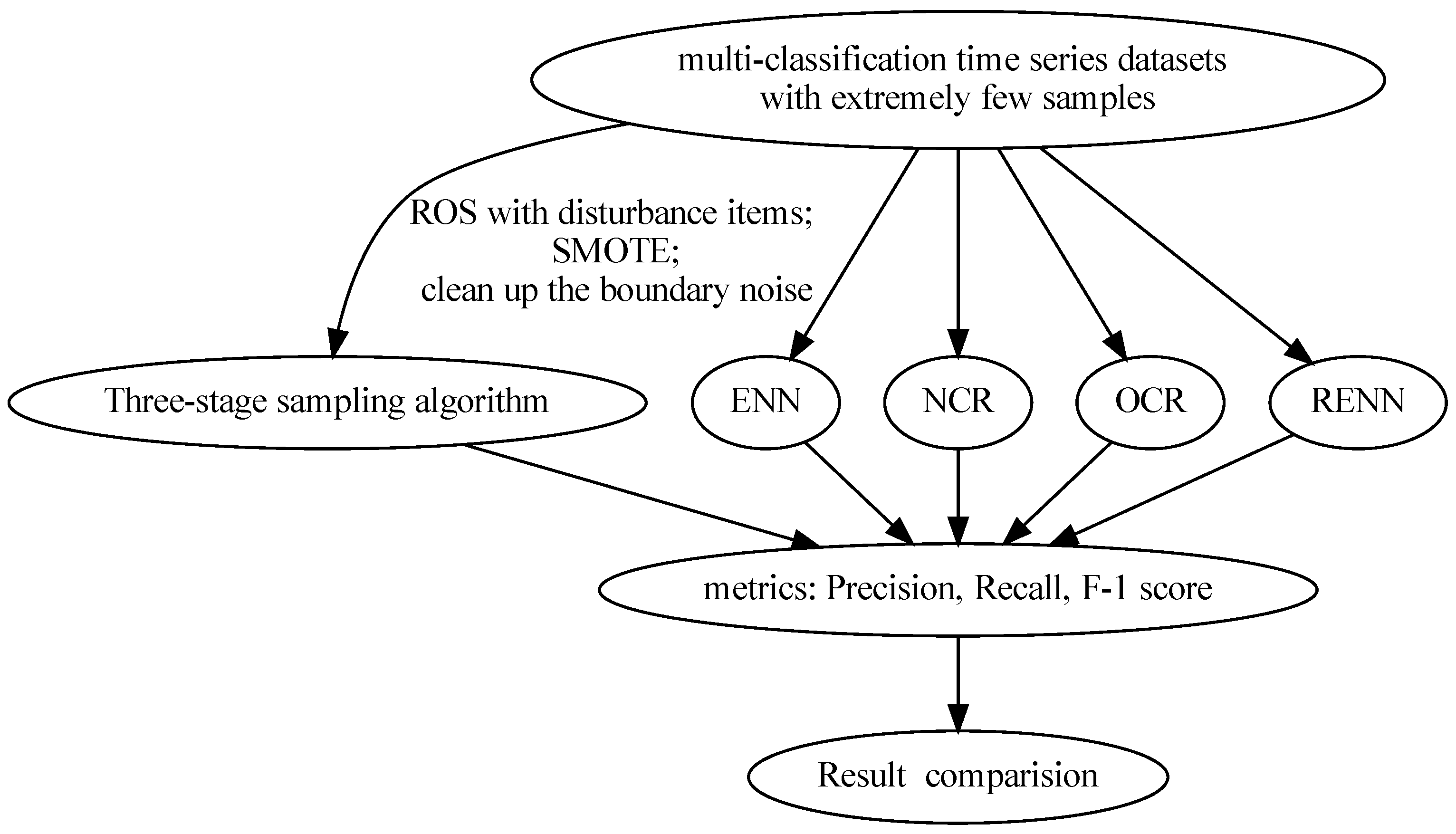
Three-Stage Sampling Algorithm for Highly Imbalanced Multi-Classification Time Series Datasets


Abstract
:1. Introduction
2. Application
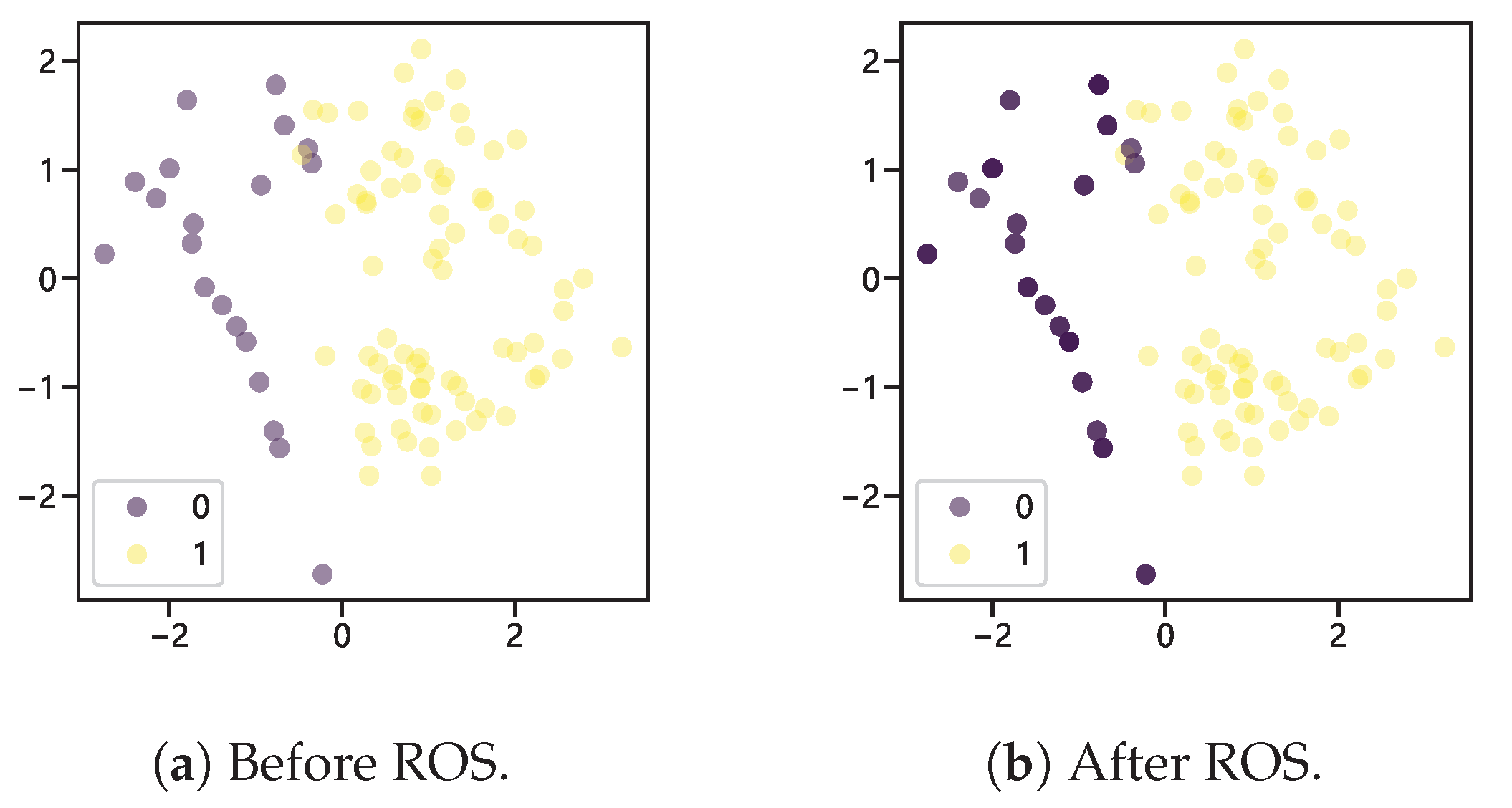
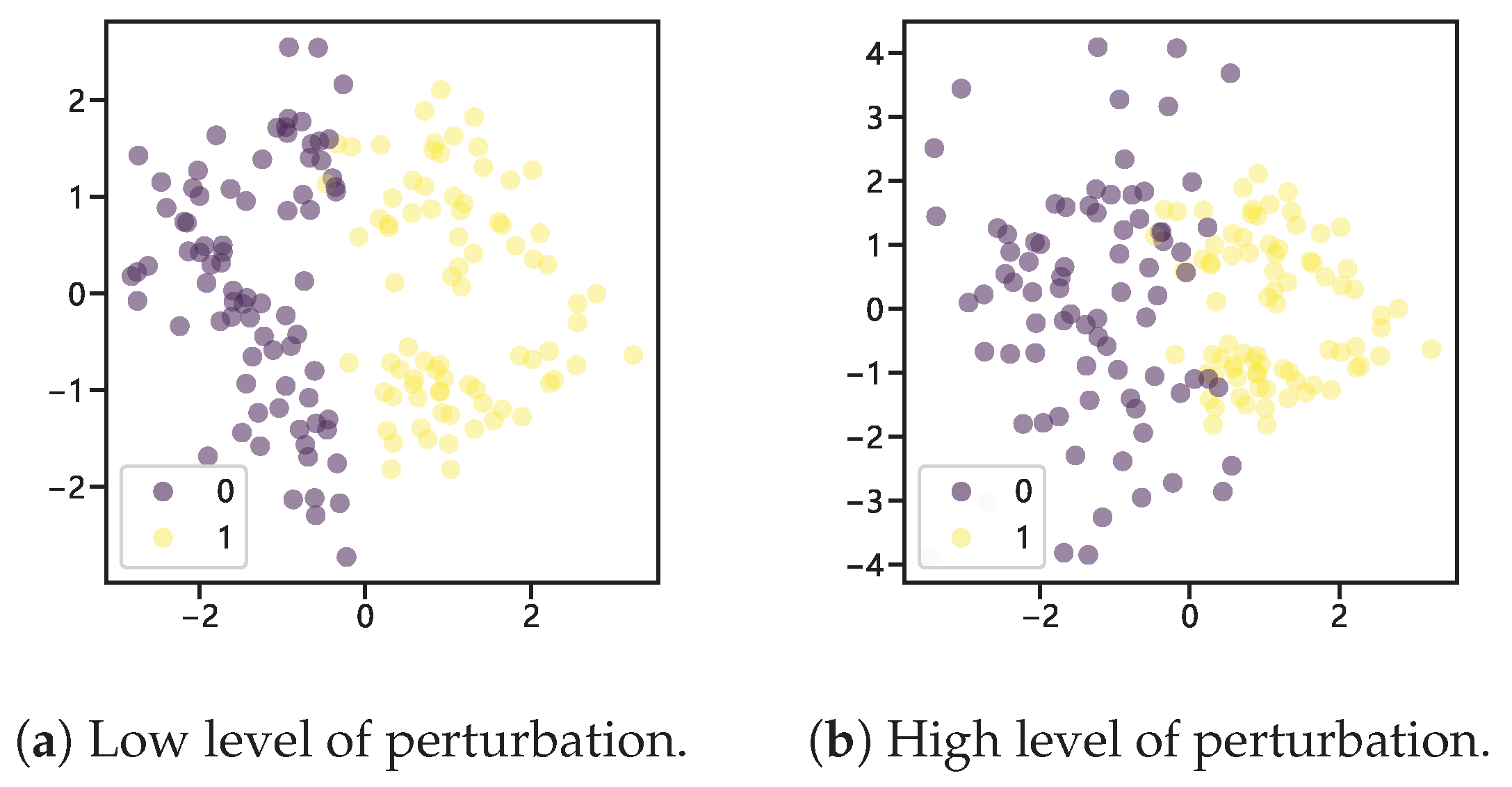
2.1. Step One: Increase the Number of Minority Class Sample Points
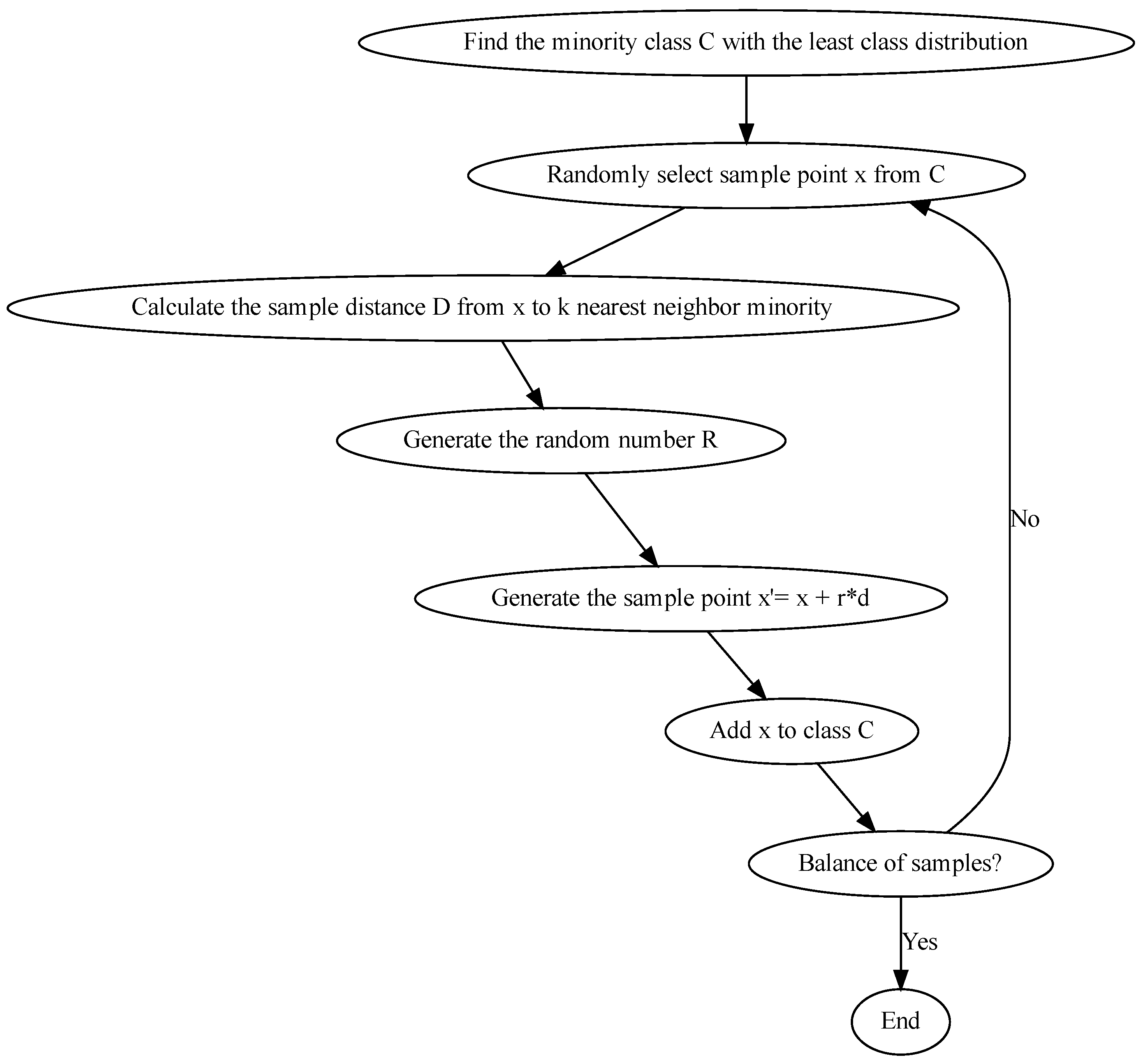
2.2. Step Two: Balanced Data Subset
- 1
- Find the minority class C with the lowest class distribution in the datasets.
- 2
- Randomly select a data point x from , which is .
- 3
- Calculate the distance d from point to its K-nearest neighbors that belong to the minority class.
- 4
- Randomly generate a number (rand) between [0, 1] and multiply it by distance d to generate a new sample point centered at . This process is performed based on the above formula.
- 5
- Add to class C.
- 6
- Repeat steps 2–5 until the number of samples in each class is balanced.
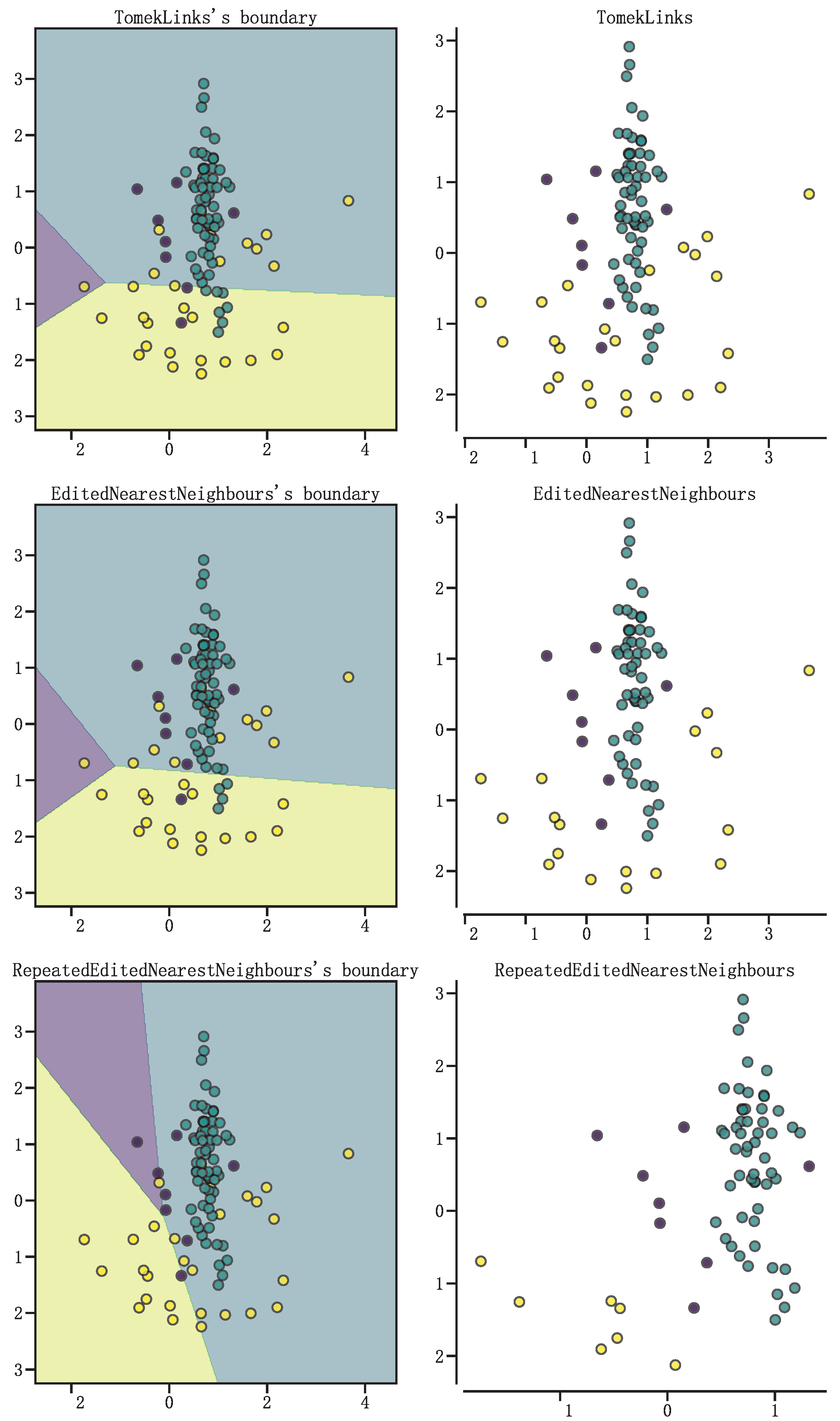
2.3. Step Three: Clear Boundary Noise
- 1
- Construct a matrix in which each element represents the distance between two time series at the corresponding position.
- 2
- Start at the top left corner of the matrix and traverse the matrix along the diagonal to the bottom right corner.
- 3
- At each position, select the distance at which d is minimized.
- 4
- Repeat steps 2–3 until you reach the lower right corner of the matrix.
- 5
- The element in the lower right corner of the matrix is the DTW distance between the two time series.
| Algorithm 1 Undersampling after SMOTE algorithm |
|
3. Experiments
3.1. Data Description
3.2. Metrics
3.3. Other Undersampling Algorithms, Classifiers, and Parameters
4. Results and Discussion
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nespoli, A.; Niccolai, A.; Ogliari, E.; Perego, G.; Collino, E.; Ronzio, D. Machine Learning Techniques for Solar Irradiation Nowcasting: Cloud Type Classification Forecast through Satellite Data and Imagery. Appl. Energy 2022, 305, 117834. [Google Scholar] [CrossRef]
- Stefenon, S.F.; Singh, G.; Yow, K.C.; Cimatti, A. Semi-ProtoPNet Deep Neural Network for the Classification of Defective Power Grid Distribution Structures. Sensors 2022, 22, 4859. [Google Scholar] [CrossRef] [PubMed]
- He, H.; Ma, Y. (Eds.) Imbalanced Learning: Foundations, Algorithms, and Applications; John Wiley & Sons, Inc: Hoboken, NJ, USA, 2013. [Google Scholar]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data Imbalance in Classification: Experimental Evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]
- Cao, L.; Zhai, Y. Imbalanced Data Classification Based on a Hybrid Resampling SVM Method. In Proceedings of the 2015 IEEE 12th Intl Conf on Ubiquitous Intelligence and Computing and 2015 IEEE 12th Intl Conf on Autonomic and Trusted Computing and 2015 IEEE 15th Intl Conf on Scalable Computing and Communications and Its Associated Workshops (UIC-ATC-ScalCom), Beijing, China, 10–14 August 2015; pp. 1533–1536. [Google Scholar] [CrossRef]
- Ganganwar, V. An Overview of Classification Algorithms for Imbalanced Datasets. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 42–47. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Advances in Intelligent Computing, Proceedings of the International Conference on Intelligent Computing, ICIC 2005, Hefei, China, 23–26 August 2005; Lecture Notes in Computer Science; Huang, D.S., Zhang, X.P., Huang, G.B., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar] [CrossRef]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. DBSMOTE: Density-Based Synthetic Minority Over-sampling TEchnique. Appl. Intell. 2012, 36, 664–684. [Google Scholar] [CrossRef]
- Devi, D.; Biswas, S.K.; Purkayastha, B. A Review on Solution to Class Imbalance Problem: Undersampling Approaches. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 626–631. [Google Scholar] [CrossRef]
- Wang, H.; Liu, X. Undersampling Bankruptcy Prediction: Taiwan Bankruptcy Data. PLoS ONE 2021, 16, e0254030. [Google Scholar] [CrossRef] [PubMed]
- Kubat, M.; Matwin, S. Addressing the Curse of Imbalanced Training Sets: One-Sided Selection. In Proceedings of the Fourteenth International Conference on Machine Learning, Nashville, TN, USA, 8–12 July 1997; Morgan Kaufmann: Burlington, MA, USA, 1997; pp. 179–186. [Google Scholar]
- Koziarski, M.; Woźniak, M.; Krawczyk, B. Combined Cleaning and Resampling Algorithm for Multi-Class Imbalanced Data with Label Noise. Knowl.-Based Syst. 2020, 204, 106223. [Google Scholar] [CrossRef]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning: Applications and Solutions. ACM Comput. Surv. 2019, 52, 79:1–79:36. [Google Scholar] [CrossRef]
- Aguiar, G.; Krawczyk, B.; Cano, A. A Survey on Learning from Imbalanced Data Streams: Taxonomy, Challenges, Empirical Study, and Reproducible Experimental Framework. Mach. Learn. 2023. [CrossRef]
- Zeng, M.; Zou, B.; Wei, F.; Liu, X.; Wang, L. Effective Prediction of Three Common Diseases by Combining SMOTE with Tomek Links Technique for Imbalanced Medical Data. In Proceedings of the 2016 IEEE International Conference of Online Analysis and Computing Science (ICOACS), Chongqing, China, 28–29 May 2016; pp. 225–228. [Google Scholar] [CrossRef]
- Wang, S. Optimizing the Smoothed Bootstrap. Ann. Inst. Stat. Math. 1995, 47, 65–80. [Google Scholar] [CrossRef]
- Fernandez, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-Year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Keogh, E.; Ratanamahatana, C.A. Exact Indexing of Dynamic Time Warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Knerr, S.; Personnaz, L.; Dreyfus, G. Single-Layer Learning Revisited: A Stepwise Procedure for Building and Training a Neural Network. In Neurocomputing; Soulié, F.F., Hérault, J., Eds.; Springer: Berlin/Heidelberg, Germany, 1990; pp. 41–50. [Google Scholar] [CrossRef]
- Clark, P.; Boswell, R. Rule Induction with CN2: Some Recent Improvements. In Machine Learning—EWSL-91, Proceedings of the European Working Session on Learning, Porto, Portugal, 6–8 March 1991; Lecture Notes in Computer Science; Kodratoff, Y., Ed.; Springer: Berlin/Heidelberg, Germany, 1991; pp. 151–163. [Google Scholar] [CrossRef]
- Anand, R.; Mehrotra, K.; Mohan, C.; Ranka, S. Efficient Classification for Multiclass Problems Using Modular Neural Networks. IEEE Trans. Neural Netw. 1995, 6, 117–124. [Google Scholar] [CrossRef] [PubMed]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR Time Series Archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Gowda, T.; You, W.; Lignos, C.; May, J. Macro-Average: Rare Types Are Important Too. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 1138–1157. [Google Scholar] [CrossRef]
- Dempster, A.; Petitjean, F.; Webb, G.I. ROCKET: Exceptionally Fast and Accurate Time Series Classification Using Random Convolutional Kernels. Data Min. Knowl. Discov. 2020, 34, 1454–1495. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
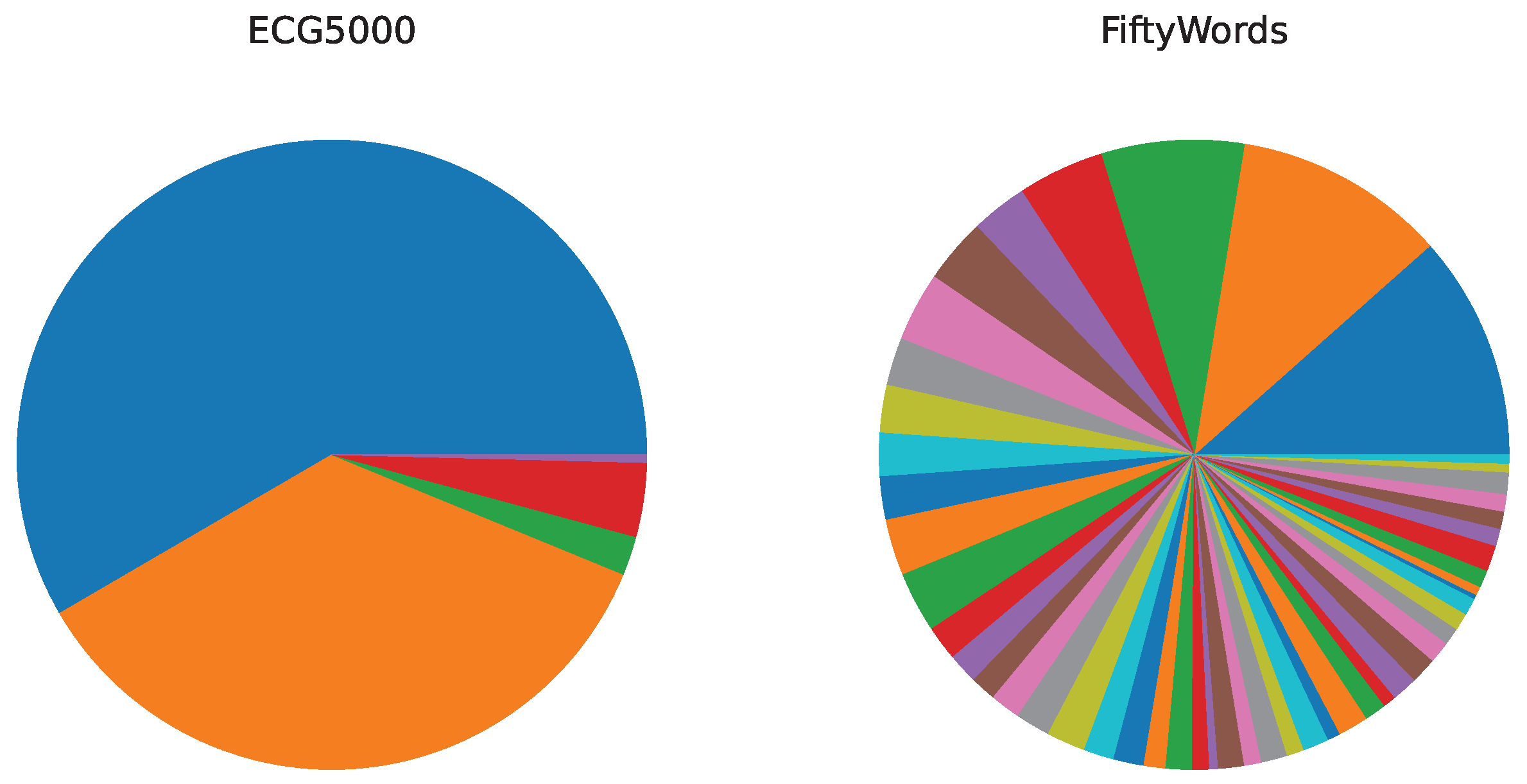
| Datasets | Imbalance Rate |
|---|---|
| ChlorineConcentration | 2.88 |
| DistalPhalanxOutlineAgeGroup | 8.57 |
| DistalPhalanxTW | 11.83 |
| ECG5000 | 146.00 |
| FiftyWords | 52.00 |
| MedicalImages | 33.83 |
| MiddlePhalanxOutlineAgeGroup | 4.31 |
| MiddlePhalanxTW | 6.40 |
| ProximalPhalanxTW | 11.25 |
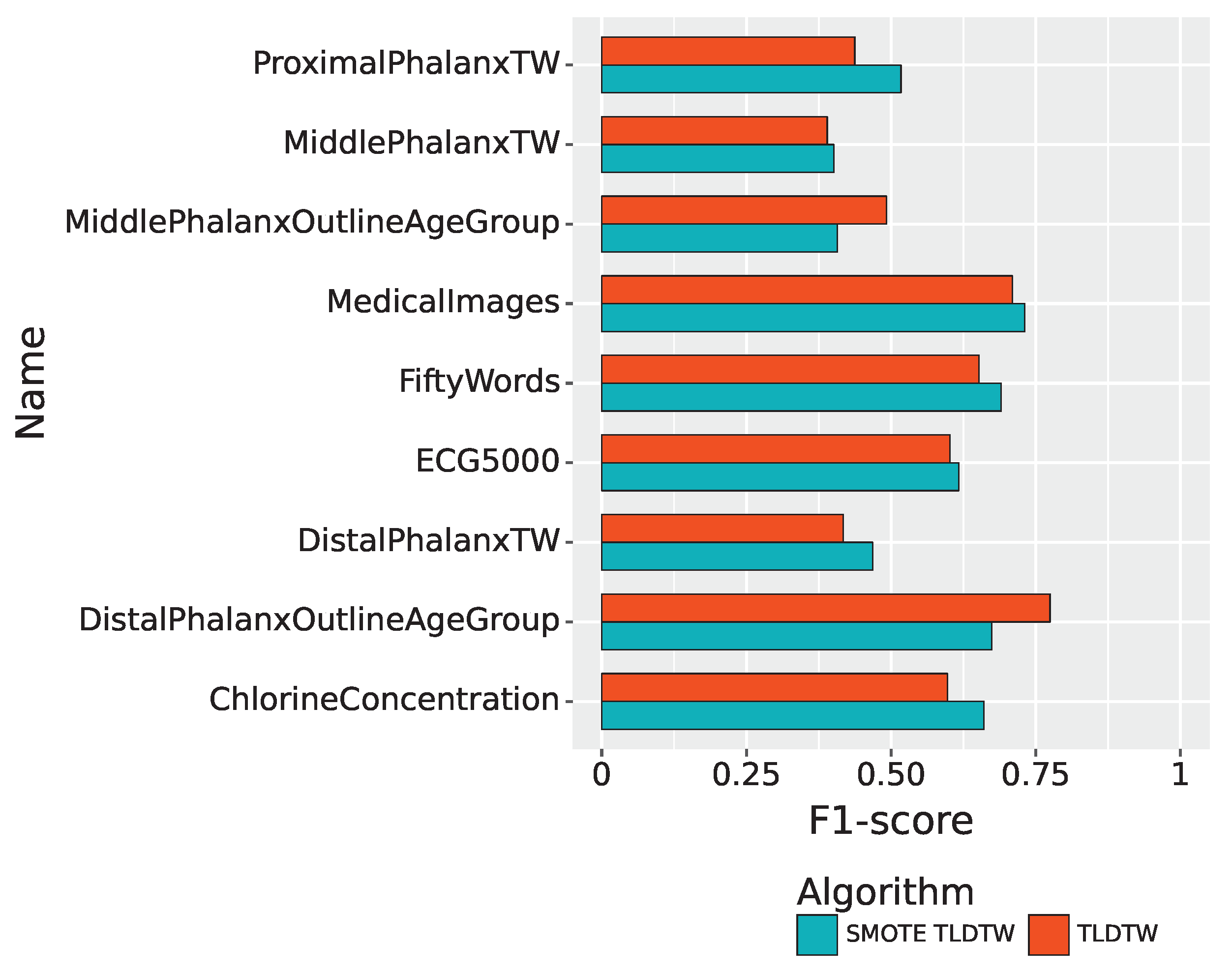
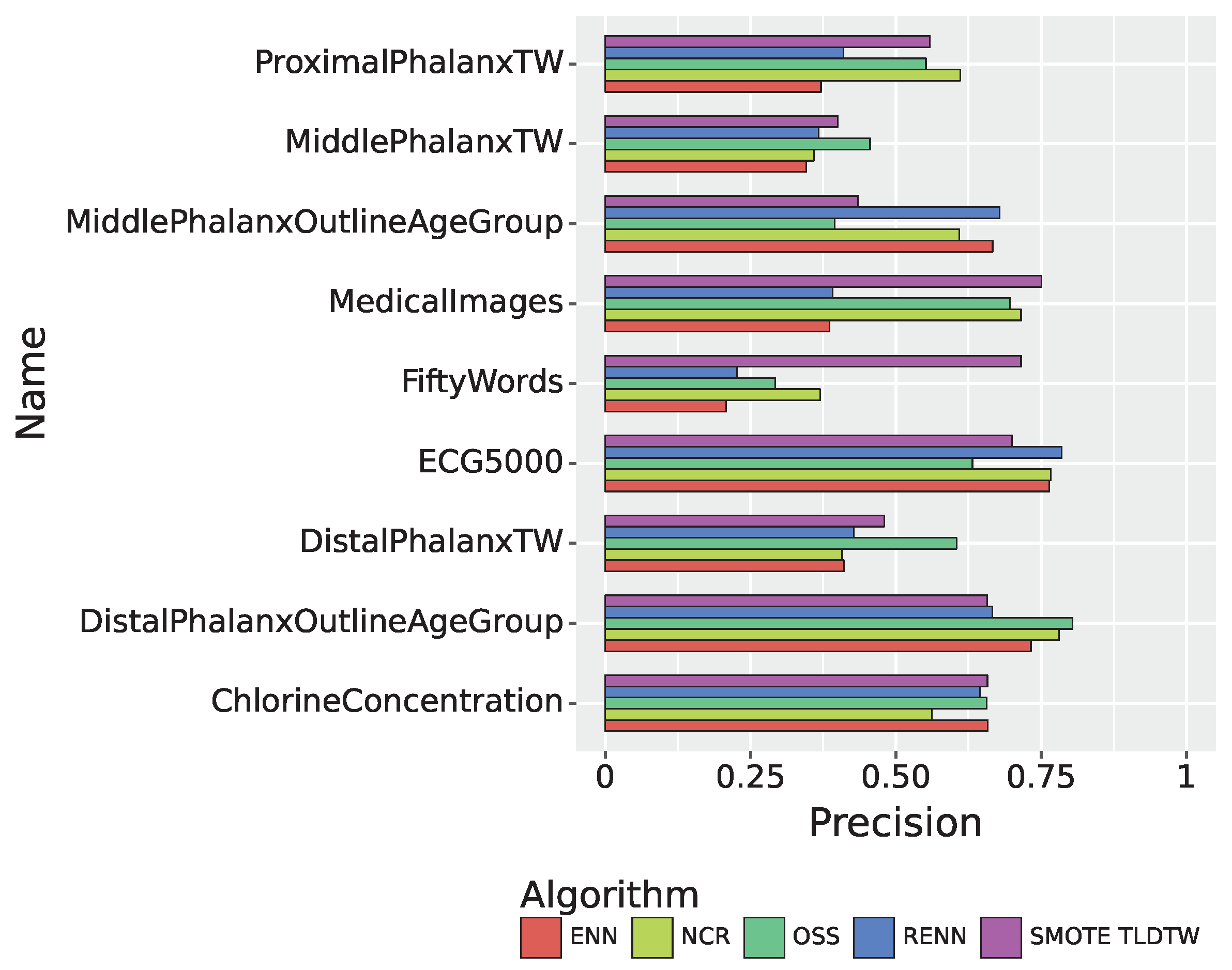
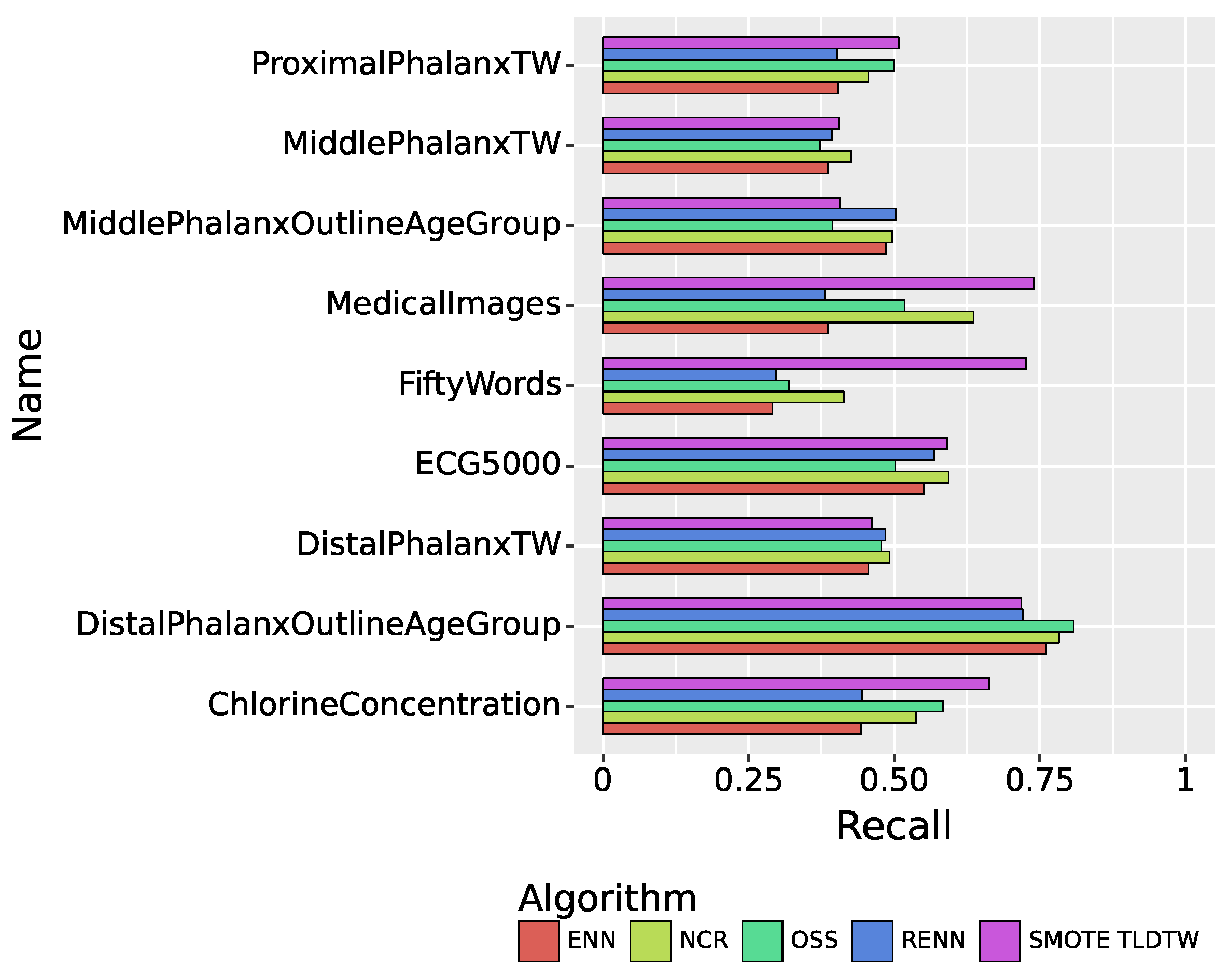
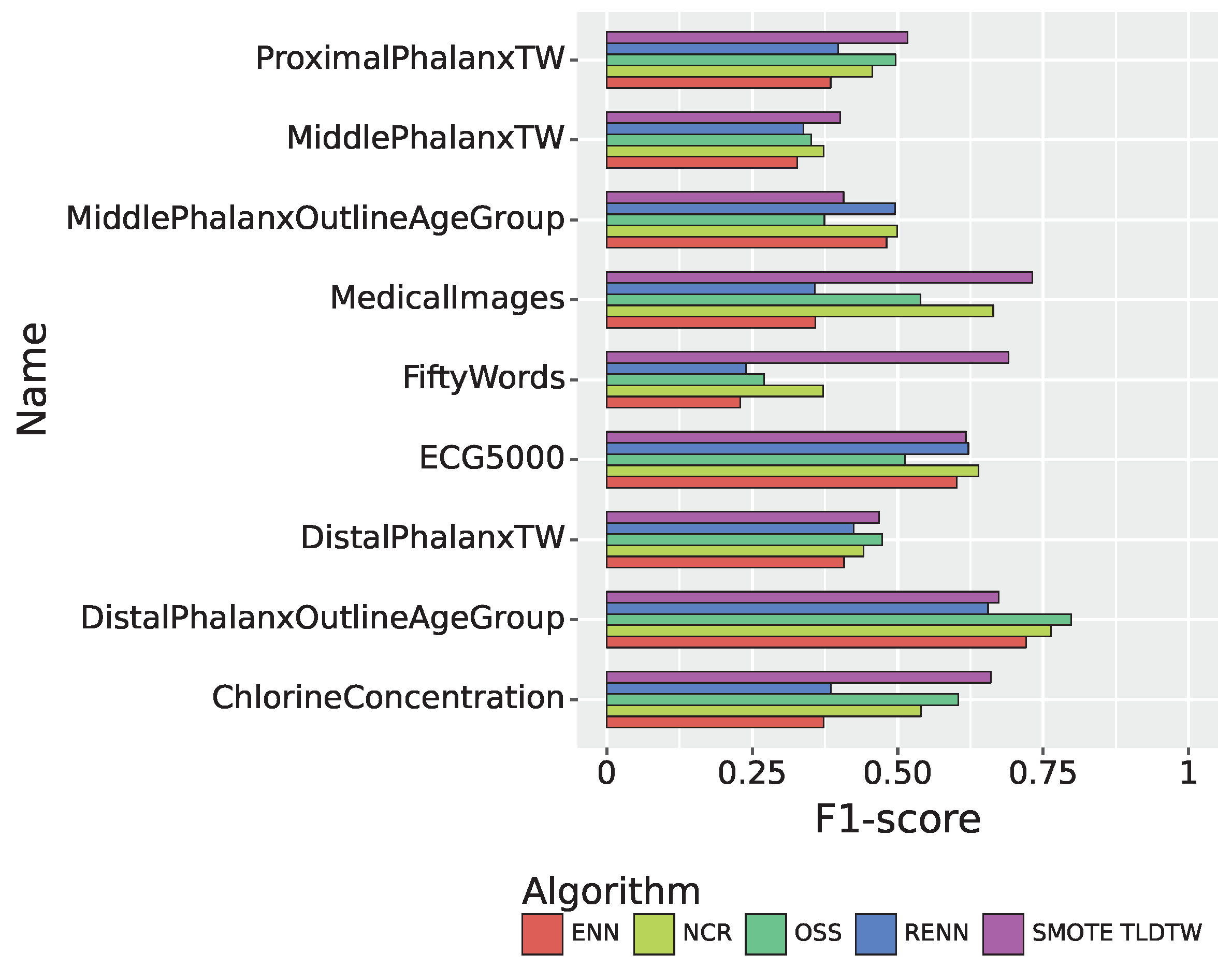
| Datasets | Precision | Recall | F1-Score |
|---|---|---|---|
| ChlorineConcentration | 0.6577 | 0.6633 | 0.6602 |
| DistalPhalanxOutlineAgeGroup | 0.6576 | 0.7178 | 0.6739 |
| DistalPhalanxTW | 0.4803 | 0.4622 | 0.4680 |
| MedicalImages | 0.7507 | 0.7397 | 0.7311 |
| MiddlePhalanxOutlineAgeGroup | 0.4351 | 0.4064 | 0.4070 |
| MiddlePhalanxTW | 0.4004 | 0.4052 | 0.4010 |
| ProximalPhalanxTW | 0.5583 | 0.5075 | 0.5170 |
| ECG5000 | 0.6998 | 0.5904 | 0.6171 |
| FiftyWords | 0.7156 | 0.7261 | 0.6901 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H. Three-Stage Sampling Algorithm for Highly Imbalanced Multi-Classification Time Series Datasets. Symmetry 2023, 15, 1849. https://doi.org/10.3390/sym15101849
Wang H. Three-Stage Sampling Algorithm for Highly Imbalanced Multi-Classification Time Series Datasets. Symmetry. 2023; 15(10):1849. https://doi.org/10.3390/sym15101849
Chicago/Turabian StyleWang, Haoming. 2023. "Three-Stage Sampling Algorithm for Highly Imbalanced Multi-Classification Time Series Datasets" Symmetry 15, no. 10: 1849. https://doi.org/10.3390/sym15101849
APA StyleWang, H. (2023). Three-Stage Sampling Algorithm for Highly Imbalanced Multi-Classification Time Series Datasets. Symmetry, 15(10), 1849. https://doi.org/10.3390/sym15101849