1. Introduction
There are numerous statistical models in the literature, but it is always possible to construct more flexible models that are better suited to actual real data in various fields such as engineering, environmental science, biomedical science, economics, reliability, biology, energy, and physics. Statisticians have previously proposed a variety of methods for dealing with these problems. When the processes acquire values in the range (0, 1), a main statistical analysis using the usual beta (B) and Kumaraswamy (Ku) models may be used. Before proceeding, a review of these models is required. To begin, they are generated from the B and Ku models. The B model is a continuous model, and it has the range (0, 1) and two positive shape parameters,
and
. The cumulative distribution function (cdf) of the B model is provided via:
where
.
The appropriate probability density function (pdf) of the B model may take the form of a U, a monotonic (decreasing or increasing) curve. Conversely, the equivalent hazard rate function (hrf) might increase with convex or U-shaped forms [
1,
2]. The Ku model was created in [
3] to supplement the B distribution. The Ku model theoretically depends on uniform-order statistics, and its functions are exceedingly basic, requiring no special functions. The cdf and pdf of the Ku model are provided via
and
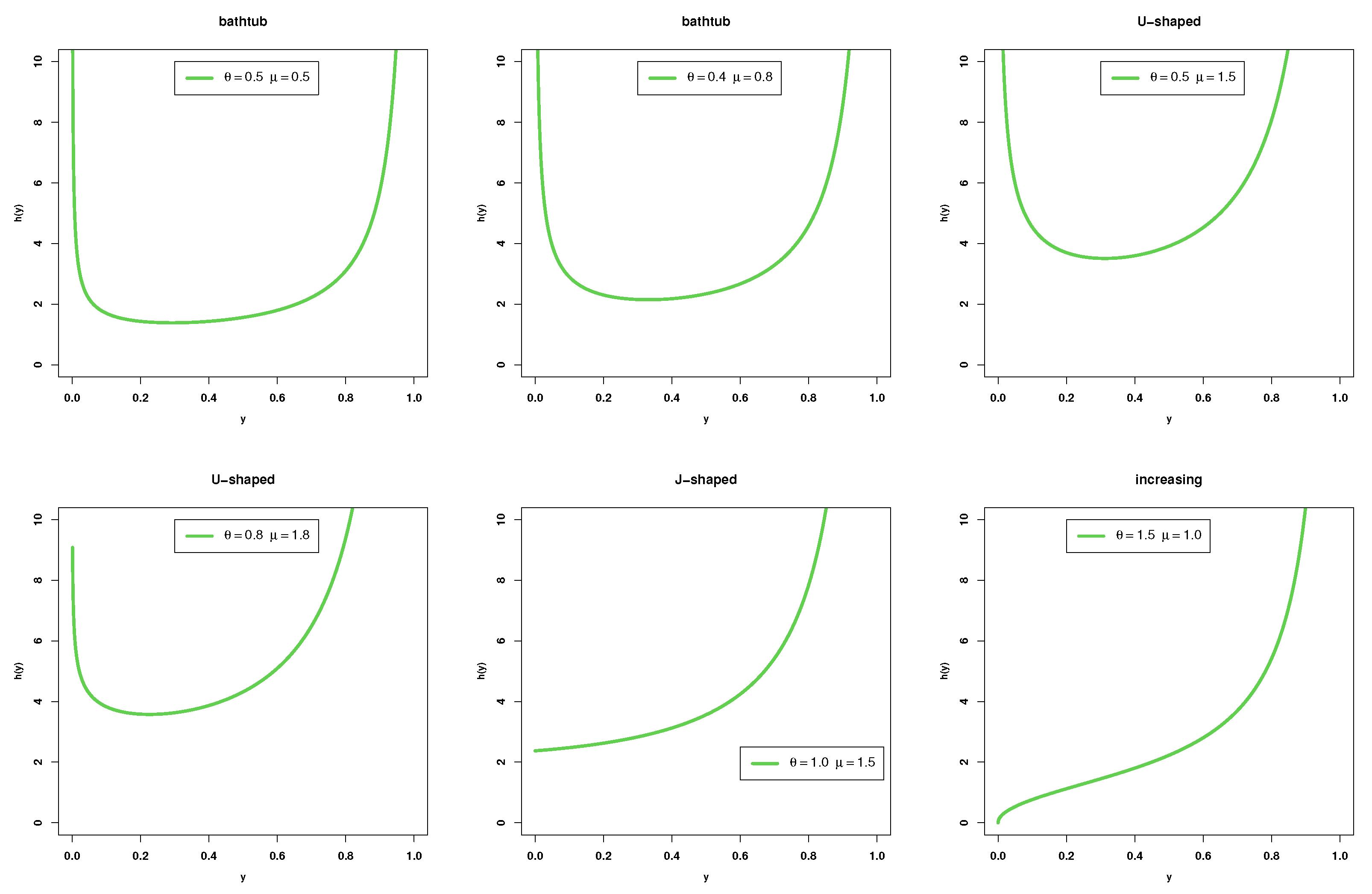
According to the values of the parameter, the pdf of the Ku model is asymmetric, and it has one of these forms: (i) bathtub when , , (ii) decreasing when , , (iii) increasing when , , (iv) unimodal when , (v) steady when .
The behavior of the Ku model is similar to that of the B model, but it is simpler since both its pdf and cdf are closed-form. Both the B and Ku models have the same boundary behavior and significant special models. This distribution might be a viable alternative in instances when the limits are, in fact, finite, i.e., (0, 1).
The Ku was primarily designed as a lifetime model. Several researchers explored and created generalizations of the Ku model, such as an exponentiated Ku model proposed in [
4], the Ku Ku model studied in [
5], transmuted Ku model discussed in [
6], the size-biased Ku model proposed in [
7], the Marshall–Olkin Ku model introduced in [
8], the exponentiated generalized Ku model suggested in [
9], the modified Ku model discussed in [
10], the type II half logistic Ku model proposed in [
11], the alpha power Ku model discussed in [
12], and the bivariate and multivariate weighted Ku models proposed in [
13]. All of the previous models are a generalization of the Ku model and have the range (0,1).
Additional parameters provide extra flexibility; however, they may increase the estimation’s complexity. Many authors used the approach of adding parameters, such as type II half-logistic odd Fréchet class of distributions by [
14], odd Perks class of distributions by [
15], type II power Topp-Leone class of distributions by [
16], generalized power Akshaya distribution by [
17], sec class of distributions by [
18]. Recently, the authors of [
19] have developed a novel transformation, known as the KM transformation family of distributions, to obtain new parsimonious families of distributions. The cdf and pdf of the KM transformation family of distributions are provided via
and
where
and
are the cdf and pdf of the parent distribution. The benefit of employing this transformation is that the produced distribution is parameter-parsimonious since no additional parameters are introduced.
The major goal of this article is to provide a novel extension of the Ku model named the KMKu model, which has two shape parameters and . The below considerations provide sufficient motivation and reason to investigate the KMKu model. We describe them as described below:
The new KMKu is more flexible than the Ku model, and they have the same number of parameters.
The curves of the pdf for the KMKu model are similar to the Ku model, and it can be asymmetric, such as (i) bathtub when , , (ii) decreasing when , , (iii) increasing when , , (iv) unimodal when .
The KMKu model has a closed form for the quantile function, making it simple to generate random numbers from the KMKu proposed model.
Several general statistical features of the KMku model were investigated.
The maximum likelihood estimation technique was employed to calculate the parameters of the KMKu model, employing simple and ranked set sampling.
The KMKu model gives more fit than the Ku model and numerous other well-known models for modeling real-world data sets in different fields, and we recommended that in the application section.
This paper is organized as follows. In
Section 2, the construction of the KMKu model is provided by combining the Ku model and the KM transformation. In
Section 3, we derive and investigate some important expansions, which we use to calculate the statistical properties of the KMKu model. In
Section 4, some general statistical features of the KMKu model are derived. In
Section 5, some different measures of entropy are computed. In
Section 6, ranked set sampling is discussed. In
Section 7, estimations of the unknown parameters using the maximum likelihood methodology under simple and ranked set sampling are studied. In
Section 8, simulation outcomes are discussed. In
Section 9, the importance and flexibility of the KMKu model are proved by employing three real data sets. Finally, the paper ended with concluding remarks.
6. Sampling Techniques
The most popular sampling methods are simple random sampling (SRS) and ranked set sampling (RSS). SRS is the most common method of data collection. In many applications (such as fisheries and medical research), where actual measurement of the variable of interest would be either time-consuming or expensive, ranking a number of sampling units without actually measuring them can be performed reasonably simply and affordably. To obtain more representative samples from the underlying population and boost the effectiveness of the statistical inference under these circumstances, rank-based sampling strategies may be used. McIntyre’s initial suggestion of RSS is cited in references [
26,
27]. Numerous studies have shown that RSS-based statistical procedures are superior to their SRS scheme analogs, either numerically or theoretically. The initial ranking of
n samples of size
n for the one-cycle RSS looks like this:
where
s cycles to produce a sample of size
, and
denotes the
ith order statistic from the
jth SRS of size
N. The resulting sample is called a one-cycle RSS and has the size
. It is represented by the symbol
.
. Under the premise of perfect judgement ranking,
has the same distribution as
, the
ith order statistic in a set of size
n generated from the
ith sample with pdf, see [
28].
The cycle can be repeated s times until units are quantified.
Following that, several extensions to the original RSS were proposed. Assessing the performance of some ranked set of sampling designs using a hybrid approach has been discussed by [
29]; RSS with the application of modified Kies exponential distribution has been obtained by [
30]; some properties and estimations under RSS of the generalized Bilal distribution has been introduced by [
31]; an estimation of the exponential parameters of the Pareto distribution under ranked- and double-RSS designs has been obtained [
32]; and Bayesian estimation using an MCMC method of system reliability for inverted Topp–Leone distribution based on RSS has been introduced by [
33]. Contrarily, median RSS and MRSS [
34] only consider the units that rank as the median for each set. While paired RSS [
35] is a less expensive alternative that ranks fewer units, double RSS [
36] is a more effective but also more expensive version of RSS that rates a higher number of sets in two ordering stages. For other probability distributions, see the recently proposed sampling technique in [
37,
38,
39,
40,
41,
42,
43,
44].
8. Simulation
Some calculations are made in accordance with Monte Carlo simulation experiments using R packages with various combinations of sample sizes
n and cycle size
s as part of our rigorous effort to assess the effectiveness of the inference methods suggested in this paper. We generate a KMKu sample with the parameters (
): (0.2, 0.75), (0.2, 1.5), (0.2, 3), (0.5, 0.75), (0.5, 1.5), and (0.5, 3). It has been determined how well the resulting
, and
estimators perform in terms of their bias, corresponding mean squared error (MSE), relative efficiencies (REs) and coverage probability (CP) as follows:
and
Using a Monte Carlo simulation in R software (we used function “optim” in R-package “stats”) with 10,000 repeats for various set sizes, the number of cycles, and chosen parameter values, the performance of the estimations is compared. To generate a sample of RSS, we used function “rss” in R-package “RSSampling”, which the “rss” function samples from a target population by using a ranked set sampling method.
Table 3 and
Table 4 present the results of the simulation investigation. As sample size increases, bias and MSE decrease. We see that bias and MSE values based on RSS are always less than those based on SRS. Additionally, as sample sizes are increased for all parameters, the MSE values based on the SRS and RSS techniques become lower.
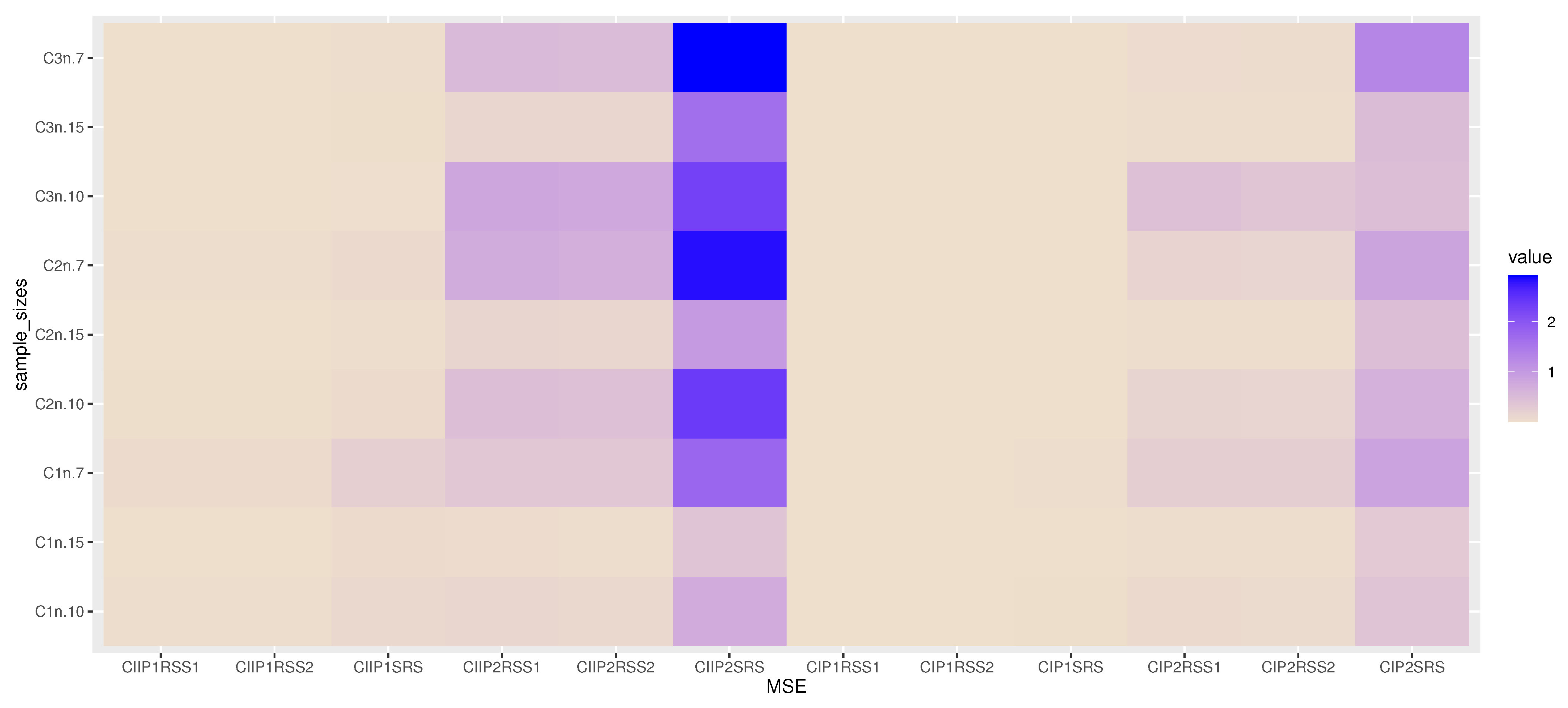
Figure 3 shows the MSE values of parameters based on SRS with different sample sizes and different parameter values, and this indicates that the MSE decreases when sample size increases.
Figure 4 shows the heat map for MSE values of parameters based on RSS with different fixed values of sample sizes and parameters, and
increases, the MSE for
decreases, while the MSE for
increases. In
Figure 4, the X label is MSE for different methods of each parameter: CIP1SRS is MSE of SRS for
when
, CIP2SRS is MSE of SRS for
when
, etc., while the Y label is MSE with different sample sizes, where C1n7 is MSE when
and n = 7, C2n7 is MSE when
and n = 7, etc. The results of the simulation show that the RSS scheme performs better than the SRS method. We can also infer that the RSS technique is more effective than the SRS scheme for estimating the unknown parameters of the KMKu distribution. The results of RSS in simulation tables show that the RSS with a greater cycle, s = 3, is superior to the RSS with a single cycle.
9. Application
This section compares the KMKu distribution with well-known unit distributions in the literature by analyzing three data sets, one of which is connected to coronavirus data and the others to burr measurements on iron sheets. These models for comparison are (together with their pdfs for
): unit Weibull (UW), which was discussed by [
45], Ku, B; Marshall–Olkin Ku (MOKu), which introduced by [
8]; unit-Gompertz (UG), which was obtained by [
46]; Marshall–Olkin-extended Topp–Leone (MOTL), which was discussed by [
47]; and unit-exponentiated half logistic (UEHL), which was introduced by [
48].
For all statistical models, we also calculate the goodness-of-fit statistics for the estimated different measures such as “Akaike Information Criteria (AIC), corrected AIC (CAIC), Bayesian information criterion (BIC), Hannan–Quinn information criterion (HQIC), Kolmogorov–Smirnov distance (KSS), p-value (PVKS), Cramer-von-Mises (WS), and Anderson–Darling (AS)”. The model with the smaller AIC, CAIC, BIC, HQIC, KSS, WS, and AS statistics and the higher PVKS of the goodness-of-fit statistics is typically considered to be the best one. It should be noted that the MLE approach was used to achieve all results.
We used SRS and RSS techniques with various set sizes and cycle counts to observe random samples of various sizes for analysis. We then computed MLEs of the parameters for the observed SRS and RSS with various cycle counts, and we compared the performance of the estimates.
Firstly: The COVID-19 data in question are mortality rates from the United Kingdom and span 82 days, from May 1 to July 16, 2021, as follows: 0.0023, 0.0023, 0.0023, 0.0046, 0.0065, 0.0067, 0.0069, 0.0069, 0.0091, 0.0093, 0.0093, 0.0093, 0.0111, 0.0115, 0.0116, 0.0116, 0.0119, 0.0133, 0.0136, 0.0138, 0.0138, 0.0159, 0.0161, 0.0162, 0.0162, 0.0162, 0.0163, 0.0180, 0.0187, 0.0202, 0.0207, 0.0208, 0.0225, 0.0230, 0.0230, 0.0239, 0.0245, 0.0251, 0.0255, 0.0255, 0.0271, 0.0275, 0.0295, 0.0297, 0.0300, 0.0302, 0.0312, 0.0314, 0.0326, 0.0346, 0.0349, 0.0350, 0.0355, 0.0379, 0.0384, 0.0394, 0.0394, 0.0412, 0.0419, 0.0425, 0.0461, 0.0464, 0.0468, 0.0471, 0.0495, 0.0501, 0.0521, 0.0571, 0.0588, 0.0597, 0.0628, 0.0679, 0.0685, 0.0715, 0.0766, 0.0780, 0.0942, 0.0960, 0.0988, 0.1223, 0.1343, 0.1781. This data have been cited in
https://covid19.who.int/ (accessed on 1 February 2023).
Table 5 discusses the MLE for different models with different measures of goodness-of-fit for COVID-19 data of the United Kingdom.
Figure 5 shows estimated cdf with empirical cdf, estimated pdf with histogram probability of COVID-19 data of the United Kingdom and a P-P plot for KMKu.
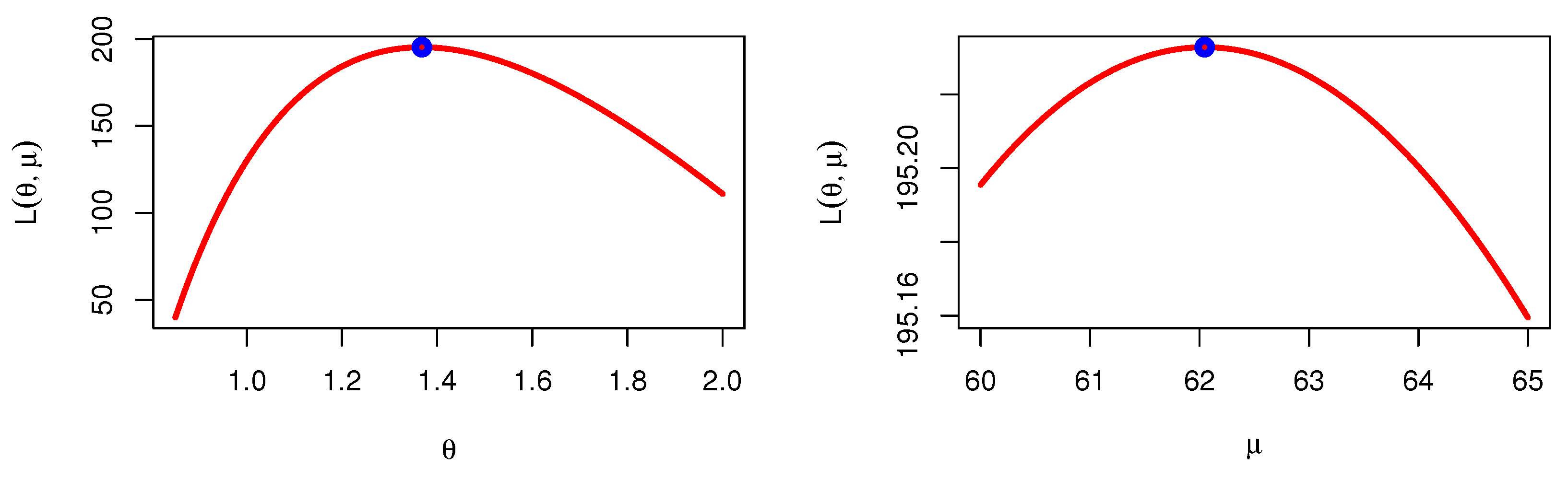
Figure 6 was obtained to check whether the estimators are maximum or not for parameters of the KMKu distribution based on COVID-19 data of the United Kingdom.
In the first set of data, we obtained the RSS data for when N = 50 with one cycle, as shown in
Table 6, and we obtained the RSS data for when the size was n = 5, and the cycle was
, as shown in
Table 7. According to these data, the MLE based on SRS and RSS with the different cycles for COVID-19 data of the United Kingdom when n = 50 is shown in
Table 8.
The second data set relates to the newly discovered coronavirus epidemic in Turkey. This dataset has been cited in
https://covid19.who.int/ (accessed on 1 February 2023). A total of 25 observations make up this data set, which covers the period from 27 March to 20 April and was calculated as the daily ratio of recoveries to confirm cases in Turkey. This indicates the daily proportion of people making a full recovery in all circumstances. The information was provided in data set II as follows: 0.0074 0.0095 0.0113 0.0150 0.0180 0.0212 0.0229 0.0231 0.0328 0.0385 0.0439 0.0464 0.0483 0.0507 0.0515 0.0568 0.0605 0.0648 0.0737 0.0818 0.0955 0.1099 0.1270 0.1388 0.1476.
Table 9 presents the MLE for different models with different measures of goodness-of-fit for the COVID-19 data of Turkey.
Figure 7 shows the estimated cdf with empirical cdf, the estimated pdf with histogram probability of COVID-19 data of Turkey, and the P–P plot for KMKu.
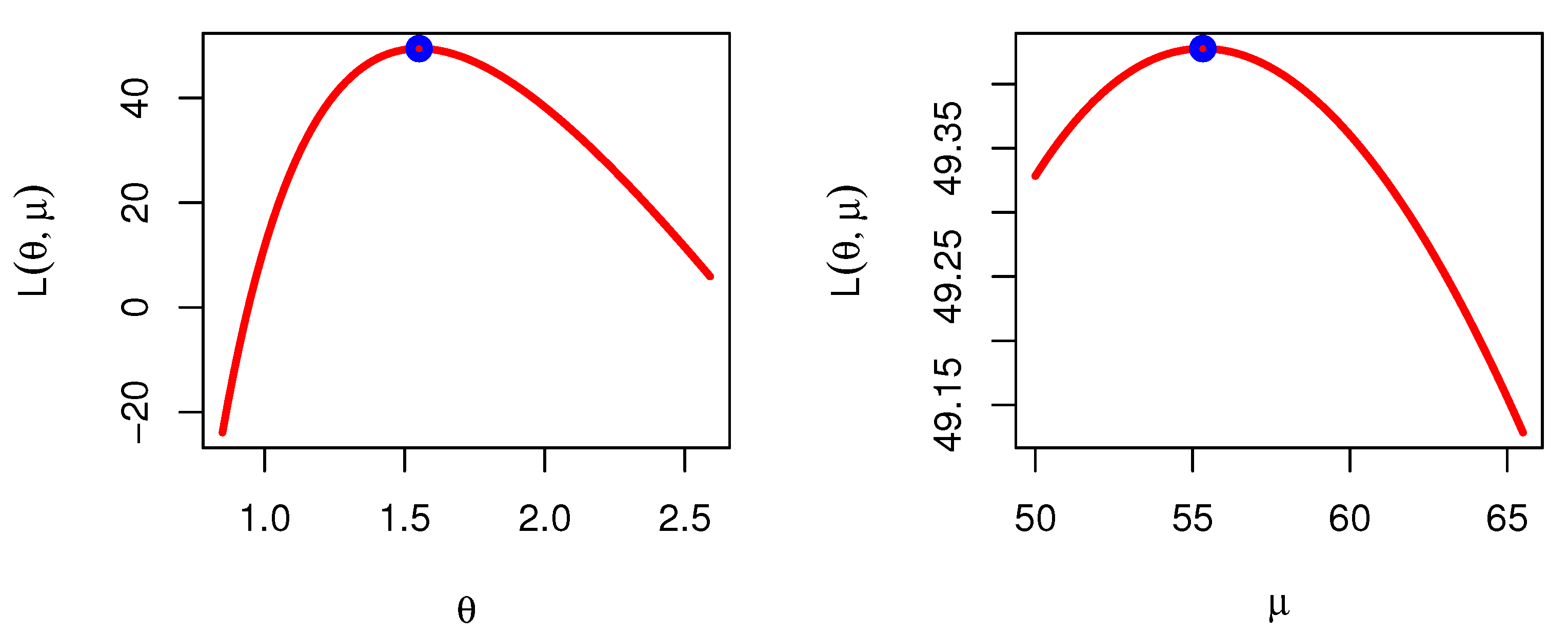
Figure 8 was produced to check whether the estimators are maximums or not for the parameters of KMKu distribution based on COVID-19 data of Turkey.
In the second data set, we obtained the RSS data for when N = 15 with one cycle, as shown in
Table 6, and we obtained the RSS data for when the size is n = 5 and the cycle is
, as shown in
Table 7. According to these data, the MLE based on SRS and RSS with the different cycles for COVID-19 data of Turkey when n = 15 is shown in
Table 10.
The third data set included 30 measurements of polyester fibers’ tensile strength, which has been discussed by [
46]. The information is provided in data set III as follows: “0.023, 0.032, 0.054, 0.069, 0.081, 0.094, 0.105, 0.127, 0.148, 0.169, 0.188, 0.216, 0.255, 0.277, 0.311, 0.361, 0.376, 0.395, 0.432, 0.463, 0.481, 0.519, 0.529, 0.567, 0.642, 0.674, 0.752, 0.823, 0.887, 0.926”.
Table 11 discusses MLE for different models with different measures of goodness-of-fit for data on the strength of polyester fibers.
Figure 9 shows estimates cdf with empirical cdf, the pdf with histogram probability of data on the strength of polyester fibers, and the P–P plot for KMKu.
Figure 10 was produced to check whether the estimators are maximums or not for parameters of KMKu distribution based on data on the strength of polyester fibers.
In the third data set, we obtained the RSS data for when N = 15 with one cycle, as shown in
Table 6, and we obtained the RSS data for when the size is n = 5 and the cycle is
, as shown in
Table 7. By these data, the MLE based on SRS and RSS with the different cycles for data on the strength of polyester fibers when n = 15 is shown in
Table 12.
By delivering the lowest AIC, BIC, CAIC, HQIC WS, and AS values in
Table 5,
Table 9 and
Table 11, the model fitted to KMKu is clearly outperforming other competitive models, such as UW, UG, Ku, B, UEHL, MOETL, and MOKu. This indicates that KMKu-based models provide more accurate and fitting information about these three real data sets.
Figure 6,
Figure 8 and
Figure 10 show the parameters of the KMKu model have a maximum log-likelihood with the other parameters fixed.
Table 8,
Table 10 and
Table 12 make it evident that the model fitted using the RSS design is outperforming the other competing models by offering the lowest SE, indicating that RSS-based models are more accurate at representing the real model utilized in these numerical examples.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}