1. Introduction
Facial expression recognition (FER) has a vital role in emotional communication. As technology advances, facial expression recognition has been widely merged into our lives [
1,
2,
3,
4]. Human–computer symmetrical interaction and e-learning, etc., have become the current research hotspots for machine learning and artificial intelligence [
5,
6,
7,
8]. Traditional expression recognition consists mainly of three branches: image preprocessing, feature extraction, and classification. The most important branch in the whole process is feature extraction. This process is related to the correct recognition rate of facial expressions. In feature extraction, there are mainly active appearance models (AAM), which are based on the localization of facial feature points, and local feature extraction/algorithms, such as Gabor wavelets, local binary patterns (LBP) [
9], and multi-feature fusion [
10,
11], etc. Traditional feature extraction approaches in facial expression recognition applications can also be detected in [
12,
13]. Nevertheless, these feature extractions require sufficient artificial experience to design and they have limitations, such as a weak robustness to image sizes, illumination effects, and image angles.
Compared to traditional feature extraction methods, deep learning can autonomously learn the features in facial expression images and obtain a better recognition rate. Santosh et al. [
14] proposed an effective facial expression recognition method for identifying six basic facial expression images. Wang et al. [
15] proposed a multi-task depth framework that used key features to recognize facial expressions. Ruan et al. [
16] proposed a novel deep disturbance-disentangled learning (DDL) method for FER. To improve the recognition rate of these facial expressions, CNN models continuously add depth and breadth to the network [
17,
18,
19,
20,
21,
22]. However, with an increase in the depth and width of the network, the number of parameters will also increase rapidly. In this case, if we continue to use the small dataset, the over-fitting problem occurs. With an increase in the parameters, over-fitting is more likely to happen. However, it is impossible to offer extensive samples in some training phases. Some facial expression datasets have small sample sizes and unbalanced sample distributions. The numbers of happy and disgusted images in the CK+ dataset are 69 and 59, respectively, while the numbers of fear and contempt images are 25 and 18, respectively. As discussed above, this makes it hard for deeper CNN models to get good outcomes. Therefore, solving the issues of insufficient sample sizes and unbalanced sample distributions has become the key problem.
Data enhancement is one of the effective approaches to solving insufficient data and unbalanced sample distributions. Traditional image enhancement methods are generally geometric transformations. Zhou et al. [
23] constructed a new face sample by passing the symmetry of an image through a classifier that combined conventional cooperative expression with inverse linear regression. Li et al. [
24] used a horizontal mirror transformation for their data enhancement. Tripathi et al. [
25] proposed an adaptive geometric filter approach for gray and color image enhancement. Different from simple geometric transformations or increased illumination for data enhancement, generative adversarial networks (GAN) [
26] can effectively solve the high similarity of generated images. GANs can generate the same facial expressions, and different models need to be retrained when getting different facial expressions. Thus, this has caused training to be redundant. Choi et al. [
27] proposed StarGAN V2, which generates images of diverse styles over multiple domains. Therefore, various facial expression images can be generated in a model, reducing the redundant models. As shown in
Figure 1, the generator is inputted by different features to generate the target images. Important features will have a huge effect on the generated images. To generate more vivid images, we introduce an SENet [
28] to select the important features. Hinge loss [
29] is used to find the maximum margin between the real and fake images to enhance the realism of the created images.
To solve the problems of insufficient sample sizes and unbalanced sample distributions in these facial expression images, we introduced StarGAN V2 to enhance the facial expression datasets. To further improve the vividness of the created images and reduce the redundant features, an SENet was added to the generator in StarGAN V2. The SENet mainly extracted the vital facial expression features. Our network introduced the idea of relative discrimination [
30]. We replaced the standard discriminator with a relative discriminator. Additionally, we increased the ratio of the fake samples in the initial training to achieve a better training state. Our network introduced hinge loss to improve the authenticity of the created images.
The main contributions of this work are as follows:
- (1)
To solve the problems of insufficient data and unbalanced sample distributions in facial expression datasets, we used an improved StarGAN V2 model to generate facial images with different emotions. StarGAN V2 is an efficient method for enhancing facial expression images. StarGAN V2 generates different expression images in a model.
- (2)
To improve the vividness of the created images, an SENet was added to the generator in StarGAN V2 to extract the important facial expression features.
- (3)
We introduced hinge loss and relative discrimination. Hinge loss was used to find the maximum margins among the different sample distributions and improve the authenticity of the generated images. Relative discrimination made our network achieve a better training state.
The remainder of the paper is organized as follows. In
Section 2, we review some related work, including StarGAN V2 and the SENet. Our proposed network is described in detail in
Section 3. In
Section 4, we introduce some public databases and ablation experiments and display our experimental results, while the conclusion is placed in
Section 5.
3. Proposed Method
With a continuously increasing network structure, the demand magnitude of the required training data increases. However, many existing facial expression datasets affect the performance of deep neural networks. Those datasets contain insufficient sample sizes and unbalanced sample distributions. Increasing these sample sizes and balancing the sample distributions become necessary. Therefore, data enhancement tasks apply GANs, but this method needs to train different models repeatedly, which takes up a lot of resources and a long training time. In the meantime, StarGAN V2 provides a better result for the above problems. StarGAN V2 generates different expressions in facial images when inputting one facial image and retains the identity information of the input images. Its generator can achieve various styles when learning the different original images. Nevertheless, the importance of each feature is different, which produces different effects on the image generation. Concerning the generation of more vivid images, our model adopted an SENet to pick up the important features, while ignoring the redundant ones. Our generator is the attention mechanism + generator (
) in
Figure 3. To improve the quality of the image generation, we improved the reconstruction loss by introducing the hinge loss. Our network structure is shown in
Figure 4.
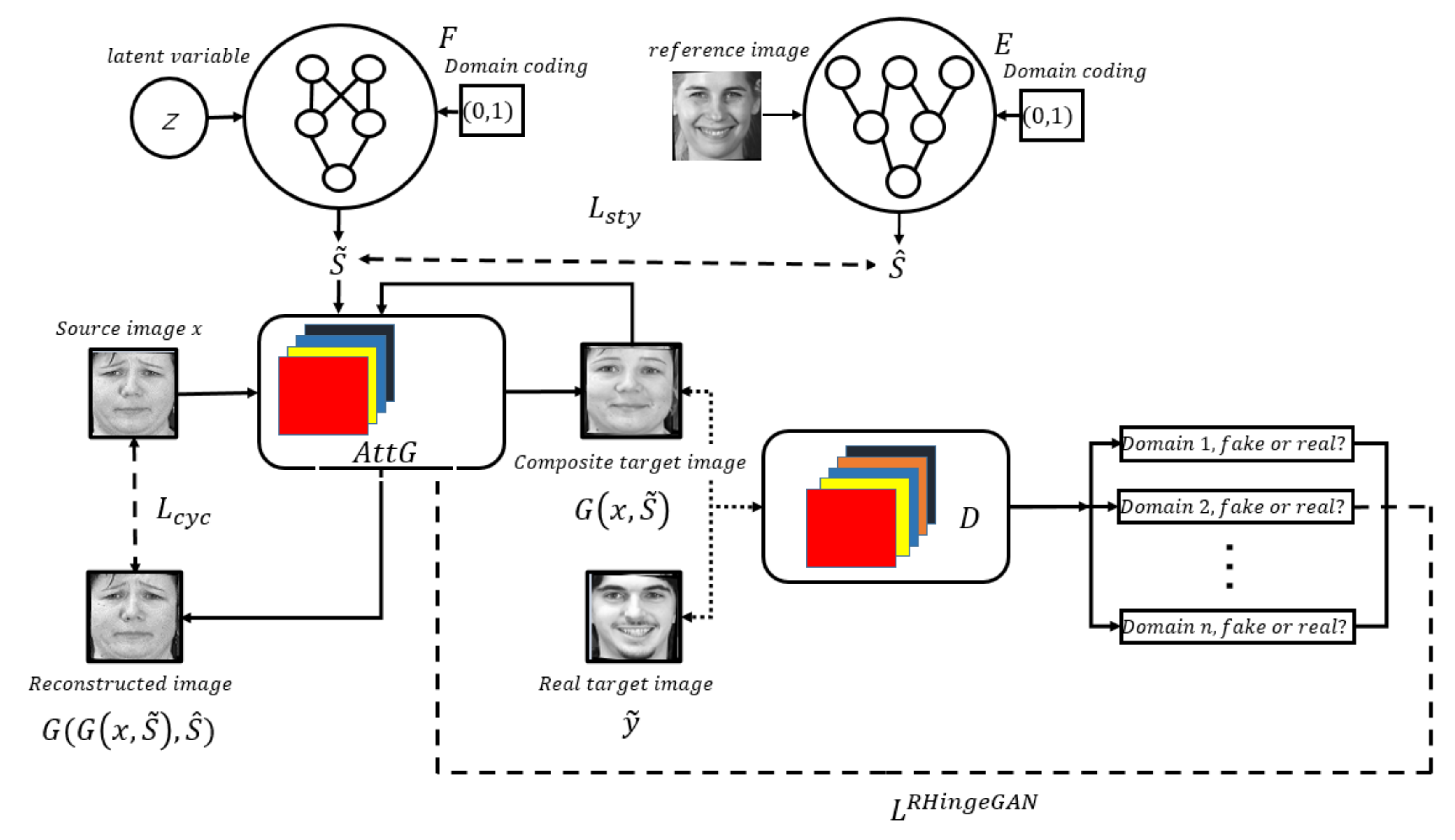
3.1. The Proposed Network
As shown in
Figure 4, our network structure is composed of
, a discriminator
, a mapping network
(mapping network
forms the style code
), and a style encoder
(style encoder
produces the style code
).
learns the style coding of the target domain
.
learns the style coding of the source domain
, while the discriminator D distinguishes between the real and fake images. The network is optimized by an adversarial loss
.
The generator can produce different styles of emoticon images. The discriminator is a multi-task discriminator that is composed of multiple output branches. Each branch is a binary classification that is used to determine whether an image is real or fake. The mapping network is composed of an MLP with multiple output branches to provide style codes for all the available domains. Additionally, the mapping network contains two inputs: one is a potential encoding converted into a multiple domain style encoding, and the other is generated by random noise. The style encoder can produce diverse style codes from the various reference emoticon images.
When training , an original picture and target domain style code are imported into . outputs the synthesized target image . The synthesized target image and the source image style code are inputted into again. Finally, outputs a reconstructed image . Preserving the similarity between and is maintained through the cyclic consistency loss . Through continuous adversarial training, generates realistic pictures that can be classified as the target domains.
3.1.1. Attention Generator
The original generator
structure of StarGAN V2 is shown in
Table 1. The generator
finds the sample distribution law and generates facial expression images with similar distribution laws. When a source image
is inputted, a corresponding composite image is generated. The content information provided by the original picture
and the style code provided by the target domain picture
are inputted into the generator
The generator
generates the image
.
is injected into
using adaptive instance normalization (
AdaIN). We observe that
is designed to represent the style of a particular domain of the source image
. This eliminates the need to supply a source image to
and allows
to synthesize an image of the target domain. The generator converts the input image into an output image that reflects the style code that is specific to the domain. To better extract the important features, an SENet is added to
. The specific structure is shown in
Table 2. This makes the generated image more vivid.
In the generator, Instance Normalization (
IN) normalizes the feature statistics of a single sample to keep the contents of the images. Thus, the content of the images before and after translation is kept unchanged, while the style of the images is changed. The AdaIN layer aligns the mean and variance of the content features with those of the style features and realizes the style transfer. Hence, we use the SENet to enhance some detailed features to make the generated images more vivid. We place the SENet in the middle layer (the middle layer is shown in
Figure 3).
3.1.2. Multi-Task Discriminator
The discriminator
tries to distinguish between the fake and real pictures. The discriminator in our network is a multi-task discriminator, which contains multiple linear output branches. Each branch employs a binary classification to determine the real domain
of an image y or the synthesized target image
generated by
. Multiple classifiers are avoided by making general judgments about whether the resulting image is authentic or not. This is because we want the generated images to be true in a particular domain, rather than the entire image to be real. The generated images make the optimization more specific. The specific structure of the multi-task discriminator
is shown in
Table 3.
3.1.3. Style Coder
The style encoder
generates different style codes using various reference pictures. An input picture is symbolized as
and its corresponding target domain is marked as
.
can extract the stylistic encoding
from the source image
. The style encoder is the same as the multi-branch discriminator structure setting. The style encoder
can generate diversified style codes using different reference pictures. It allows the generator
to synthesize an output image that reflects the style
of the reference images. The style encoder
is used to extract the different image style features from the different reference images. Therefore, the network can provide a variety of style features with the use of different reference images for training. The specific structure of the style encoder
is shown in
Table 3.
3.1.4. Mapping Network
The mapping network
accepts the latent code from the standard Gaussian distribution, and subsequently, the generator can get rid of the label constraint to generate the target images. Given a domain
, with a latent encoding
as its input, a network encoding
is generated by the mapping network
.
is composed of an MLP with multiple output branches to offer style codes for all the available domains. The specific structure of the mapping network
is displayed in
Table 4.
3.2. Improved Reconstruction Loss Function
The choice of a loss function is a significant factor affecting the network’s performance. The essence of a GAN’s adversarial loss is to find the Nash equilibrium solution in the zero-sum game. During the image’s translation, the generator will generate samples that appear to match the distribution of the source dataset.
represents the sample distribution of the image’s domain
,
represents the sample distribution of the image’s domain z, and the loss function is defined in the original GAN as follows:
In Formula (4) and Formula (5), the discriminator
measures the optimization of
under the optimal
as equal to the optimization of the
divergence (Jensen–Shannon divergence) [
26] between
and
. There is a minimum value for the
divergence, but the discriminator does not know the a priori knowledge that half of the input data is true and half is fake. There may be an actual situation in that all the inputs of
have
. This makes it difficult for the discriminator to rely on both the real and created data. Eventually, the probability of the real data and created data finds it difficult to reach 0.5 in its ideal state, and it is hard to find the real Nash equilibrium settlement.
Considering the problem that standard GAN adversarial loss fails to make complete use of the prior knowledge of the input data being half real and half fake, our network introduces the idea of relative discrimination. This means replacing the standard discriminator with a relative discriminator to increase the ratio of the fake samples in the initial training, in order to achieve a better training state. In facial expression generation, increasing the spacing boundary between true and false images can improve the authenticity of the created pictures. Therefore, using a combination of relative discrimination and hinge loss, the loss functions of the discriminator and generator are shown in Formula (6) and Formula (7), respectively:
In Formulas (6) and (7), represents the real data distribution. represents the real and fake discriminative structure in the discriminator . represents the target label.
The style reconstruction loss forces
to use the style encoding
when generating the image
(
,
). This is shown in the following Formula (8):
To further make
produce different images, the diversity sensitivity loss is used to regularize
as in Formula (9),
The target style codes
and
are generated by the mapping style
according to the two random latent codes
and
, namely
for
. Maximizing the regular term can force
to explore the picture space and find meaningful style features to create various pictures. However, it is not guaranteed that the created picture will only change the content related to the input picture domain and retain the other contents of the input picture. Therefore, the cyclic consistency loss is used in the generator, as in Formula (10)
where
is the style code of the input picture
.
is the target domain of
. The synthesized image
and
are input into
, in an attempt to reconstruct the source picture
. Additionally, the reconstructed image
and
calculate the difference of the
norm.
learns to change its style while retaining the original characteristics of
. Finally, the complete objective function of optimizing
and
is as in Formula (11)
where
,
, and
denote the style reconstruction loss hyperparameters, diversity sensitive loss hyperparameters, and cycle consistency loss hyperparameters, and the correlation coefficients are set as 1, 2, 1.
represents the adversarial loss between the generator and discriminator.
3.3. The Algorithm in the Paper
The generator and multi-task discriminator conduct adversarial training in alternating ways. First, we fix to train D, followed by fixing D to train , and then continue with the cyclic training. The abilities of and are enhanced. Eventually, the images generated by can be seen as real. For example, in facial expression generation, when one facial expression image generates different facial expression images, the specific training process is as follows:
- (1)
is fixed, training with and training n epochs (once for each sample in the training sample set).
- (2)
is generated from , training with and training n epochs.
- (3)
is fixed, using the output of as the image’s label, calculating the loss function, and continuing with training and the epochs.
- (4)
Steps (1)–(3) are repeated until the images generated by can be seen as real.
- (5)
The test image set is selected to assess the performance of the final network and the quality of the generated image.
4. Experimental Results and Analysis
The experiments were implemented on Pytorch 1.6.0, Python 3.6.10, Tensorflow 1.14.0, and 18.04.1-Ubuntu operating systems. The improved StarGAN V2 in the experiment ran on the Intel(R)Xeon(R)CPU
[email protected] GHz in the CPU and NVIDIA GEFORCE GTX TITAN X graphics card in the GPU. In the experiment, the GPU was used to speed up the model’s computation and decrease the training time.
All the models in our network were trained using the Adam optimization algorithm, the initial learning rate of the network was set to 1 × 10−4, the batch size was 128, and each network was trained for 100 iterations.
4.1. Experimental Dataset
To evaluate our network, this section will cover the experiments conducted on two public facial expression datasets, which were the extended Cohn-Kanade library (CK+) [
52] dataset and the MMI dataset [
53]. CK+ and MMI were captured in controlled lab environments. Since the experiment in our network was for static images, the three peaks of the expression changes in the video sequence ((CK+) expression library and MMI expression library) were taken as image samples, and all the images were scaled to 512 × 512. Among them, the entire number of CK+ images was 981, and the entire number of MMI pictures was 609.
Table 5 and
Table 6 display the number of various emotion pictures in the CK+ and MMI datasets.
4.2. Using Different GANs to Generate Different Samples on the CK+ Dataset
Figure 5 shows the original image (an angry expression in the CK+ data).
Figure 6 shows the different facial expression images generated from the angry expressions in the CK+ data in each of the different networks. The first column (a) represents the sample generated by our network. The second column (b) represents the samples generated by
Att-StarGAN V2. The third column (c) represents the samples created by
Hinge-StarGAN V2 and (d) represents the samples created by StarGAN V2. The
ATT-StarGAN V2 represents a combination of StarGAN V2 and SENet. The
Hinge-StarGAN V2 denotes a combination of StarGAN V2 and the hinge loss.
As shown in
Figure 6, the images generated by our network still had some advantages over the images generated by the other three networks. The details of the expressions produced by our network were better performed. For example, when the facial expression was in the fear state, the images generated by our network were more realistic and vivid, and the expression details were processed appropriately. The images generated by our network appeared to be more vivid than the images generated by
ATT-StarGAN V2.
The facial expression image details generated by ATT-StarGAN V2 were suited. It can be seen that the detail characteristics of the generated images in column (b) are more perfect compared to column (d). The expression details of the images generated by ATT-StarGAN V2 were better than the expression details of the images generated by Hinge-StarGAN V2. The images generated by our network had advantages in their realism and expression details over the images generated by StarGAN V2.
The facial expression images generated by Hinge-StarGAN V2 were more realistic. The created pictures in column (c) are more realistic than those in column (d). Another example is that when the facial expression was surprised, it could better reflect the advantages of our network.
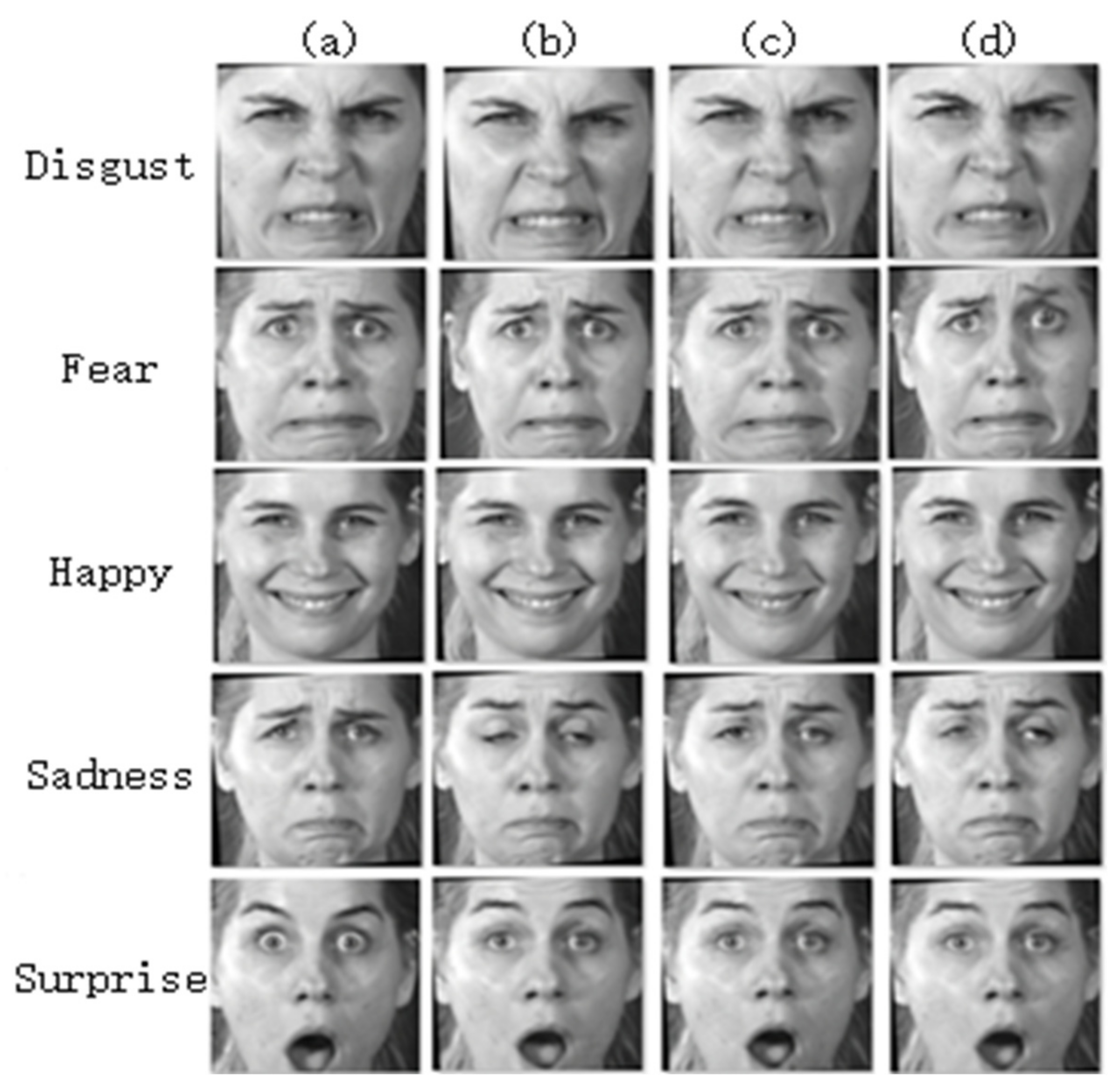
4.3. Using Different GANs to Generate Different Samples on the MMI Dataset
Figure 7 shows the original image (an angry expression in the MMI data).
Figure 8 shows the different types of expressions generated from the angry expressions in the MMI data in each of the different networks. The first column (a) represents the samples generated by our network, the second column (b) represents the samples generated by
ATT-StarGAN V2, column (c) represents the samples generated by
Hinge-StarGAN V2, and column (d) represents the samples generated by StarGAN V2. In the MMI dataset, the facial expression amplitude changed greatly, so it was also possible to generate a poor image quality, such as sad expressions, as seen in
Figure 8. Our network could generate better-quality facial expression images, but the facial expression images generated by the other three networks were deformed. In column (b) and column (d), the left eyes of the pictures in the sad row, created by
ATT-StarGAN V2 and StarGAN V2, respectively, are incomplete. The emotional details of the facial expression pictures were processed without processing the authenticity of the facial expression image, which proved that it was difficult to achieve the expected effect. Hinge loss could make the generated facial expression images more realistic. However, by adding the SENet, it was possible for the performance of the expression details in the generated facial expression images to be more complete and vivid. For example, in the fear row, which shows the facial expression images generated by StarGAN V2, the eyebrows are deformed, and the quality of the images from the other three networks displays some progress.
To verify the availability of our network, the generated image data and original data were trained and tested. The numbers of the various emotional pictures in the training set and test set are displayed in
Table 7 and
Table 8.
In the experiment, the images were rescaled to 48 × 48 in the training and testing phases. We employed VGG19 for the training and testing. The training and testing phases were repeated 60 times, and we selected the best recognition rate as the final result.
4.4. Ablation Experiment
The ablation experiment outcomes are displayed in
Table 9, and the recognition accuracy (%) is served as the performance evaluation.
As demonstrated in
Table 9, our network could improve the facial expression recognition rate. Our network had a certain improvement effect compared to the other six networks.
In the original CK+ and MMI datasets, the accuracy of VGG19 was 96.8085% and 74.576%, respectively. The accuracy of VGG19 + StarGAN V2 was 97.7845% and 93.0788%, respectively. Compared to the original CK+ and MMI datasets, the accurate rates of recognition showed increases of 0.976% and 18.5028%, respectively, by using StarGAN V2. After adding the hinge loss into StarGAN V2, the accurate rates of recognition were 98.6930% and 95.4687% for the CK+ and MMI datasets, respectively. Compared to the StarGAN V2-enhanced CK+ and MMI datasets, the accurate rates of recognition showed increases of 0.9085% and 2.3899%, respectively, by using the Hinge-StarGAN V2-enhanced CK+ and MMI datasets.
After adding the SENet to StarGAN V2, the accurate rates of recognition were 99.173% and 95.2514% for the CK+ and MMI datasets, respectively. Compared to the StarGAN V2-enhanced CK+ and MMI datasets, the accurate rates of recognition showed increases of 1.3885% and 2.1726% by using the ATT-StarGAN V2-enhanced CK+ and MMI datasets. For the CK+ and MMI datasets that were enhanced by our network, the accurate rates of recognition were 99.2031% and 98.1378%, respectively. Compared to the StarGAN V2 enhanced-CK+ and MMI datasets, the accuracy showed increases of 1.4186% and 5.059% by using our enhanced network. Compared to the CK+ and MMI datasets with no enhancement, the recognition rates of our network improved by 2.3946% and 23.5618%, respectively.
Table 9 shows that the dataset was enhanced and that the expression recognition rates of the CK+ and MMI datasets were improved. Compared to the quality of the images generated by StarGAN V2, our network’s generated image quality was also improved.
After the data enhancement, the recognition rate of the CK+ dataset was significantly improved. The main causes for this were that the images in the CK+ dataset consisted primarily of young men and women and that the characteristics were obvious. Therefore, compared to the original CK+ dataset, the recognition rate of the images generated by our network increased by 2.3946%. Compared to the original MMI dataset, the recognition rate of the images generated by our network increased by 23.5618%. The recognition rate of the MMI dataset was greatly improved by our enhanced network. There were two main reasons for this. On the one hand, it was due to the small number of samples in the original MMI dataset; on the other hand, it was due to age and facial occlusion. Thus, after the data enhancement, we solved the problems of insufficient data and unbalanced sample distributions, which was more conducive to network learning.
To further prove that the location of the SENet selection in the network was conducive to the quality of the network improvement, we placed the SENet at the front and back of the middle layer (the middle layer is shown in
Figure 3). The middle layer + SENet denotes that the middle layer was placed in front of the SENet. The SENet + middle layer denotes that the SENet was placed behind the middle layer.
Table 9 shows the gap among the accuracy rates. The improvement effect of the SENet + middle layer was better than that of the middle layer + SENet, as it had a certain effect on improving the accuracy rate. It could focus on the original person’s identity characteristics, so our network was based on the SENet + middle layer.
Our proposed model could effectively enhance facial expression images and generate different types of these facial expression images. The comparison results of the ablation experiment show that our proposed model could effectively improve the accuracy of facial expression recognition. Therefore, our proposed model could effectively enhance facial expression images, which is more conducive to improving the correct recognition rate for facial expression images.
4.5. The Score FID Different Models on CK+ and MMI Database
To further imply the quality of the generated pictures, we utilized Fréchet inception distance (FID) [
54] (lower is better) as the evaluation indicator to measure the visual quality. FID is a common metric for evaluating pictures created by GANs. It conveys the quality and diversity of the generated images by comparing the feature vectors among the different images. The results of the paper’s comparison are displayed in
Table 10. The
ATT-StarGAN V2 represents the combination of StarGAN V2 and the SENet. The
Hinge-StarGAN V2 denotes the combination of StarGAN V2 and the hinge loss. The results show that the SENet- and hinge-loss-improved StarGAN V2 achieved the best outcomes. Compared to StarGAN V2, our method effectively improved the quality of the created pictures.
4.6. Comparison with Other Works
The comparison results with other works are shown in
Table 11:
As shown in
Table 11, compared to other methods, our network had noticeable, obvious advantages with regard to the MMI dataset. Since there were many different characters in the MMI dataset and the expression amplitudes were quite different, it was difficult to accurately identify the facial expressions. Our network could generate more samples so that multiple sample expressions could be learned and the facial expression recognition rate could be better improved. After the data enhancement, the recognition rate of the MMI dataset was greatly promoted. Compared to the traditional feature extraction method, Refs. [
11,
12,
13,
14] used the hybrid feature extraction method, which significantly promoted the recognition accuracy. Due to the limitations of traditional methods, the extracted feature information was not comprehensive enough and it was necessary to add auxiliary measures to improve the recognition accuracy. In [
15,
36,
37,
38,
55,
58,
59,
60], deep learning methods were used to conduct global learning, local learning, or a combination of global and local learning. However, due to the small number of samples and the unbalanced sample distributions in the MMI and CK+ datasets, redundant learning and repetitive learning occurred from time to time. The accuracy of the recognition rate was not as accurate as that of our network. Our network could generate many samples, which effectively improved the recognition rate. In [
16,
56,
57], the problem of facial expression image recognition across datasets was solved, but due to the fusion of multiple datasets, the difficulty of the recognition increased.
5. Conclusions
Facial expression datasets often contain insufficient data and unbalanced sample distributions. This article constructed, implemented, and demonstrated an improved StarGAN V2 model for a facial expression data enhancement. Firstly, we used StarGAN V2 to generate different facial expression images and enrich the expression dataset. Secondly, the SENet paid more attention to the vital regions of the images and improved the vividness of the created pictures. The model was integrated into the generator in StarGAN V2 to improve the quality of the generated images. Lastly, we introduced the hinge loss to StarGAN V2 to distinguish between the real or fake samples and improve the authenticity of the generated images. The outcomes of the two public CK+ and MMI datasets showed the effectiveness of our method. The improved StarGAN V2 was conducive to improving the accuracy of the network recognition, which could retain the identity information and transform the different styles.
Our proposed network was compared to previous studies from the LR. Compared to [
61], our network was based on StarGAN V2. The network generated diverse images within a model and retained the original identity information. Compared to pix2pix [
62], our network did not require the training of image pairs. Our network products had more freedom in generating different image styles.
The advantages of our proposed model are as follows:
- (1)
We propose a new facial expression image generation model. The model can generate different facial expression images by applying a simple structure.
- (2)
Our network is an effective model, avoiding the training of redundant models and saving a lot of time and resources.
- (3)
The generated facial expression images maintain the identity information of the original input image. Additionally, our model improves the recognition rate of the facial expression images.
The weaknesses of our proposed model are shown below:
- (1)
There is a lot of text and speech information in the expression dataset. We only enhance the images.
- (2)
In addition to inputting the original image, the generator also inputs the corresponding stylistic features. The amount of input into the generator should be minimized while maintaining the quality of the generated image. This reduces the computational effort of the model.
- (3)
We only enhance the facial expression images, without corresponding transformations for hairstyles and clothing, etc.
With the emergence of multimedia technology, facial expression recognition is not only limited to images, but also involves many other aspects, such as sound and text. Methods of integrating expression recognition into multimedia technology, in order to make it more conducive to research on expression recognition, will be the focus of our future research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}