1. Introduction
Air pollution prediction is an important topic that is often discussed lately because it is closely related to human health. It has been observed that this pollution usually reduces air quality in an area, and some of its causes include industrial activities, transportation, forest burning, new land clearing, and cigarette smoke [
1]. This decrease in quality is caused by the release of harmful substances or gases into the air or the earth’s atmosphere, such as carbon dioxide (CO
2), carbon monoxide (CO), nitrogen dioxide (NO
2), and sulfur dioxide (SO
2). These substances tend to be very dangerous when air pollutant-producing activities continue to increase, and there is no special treatment for the disposal of hazardous residues in the open air. For example, the dangerous effects of air pollution on human health include shortness of breath, lung cancer, heart disease, respiratory tract infections, and even death [
1].
Studies showed that air quality data are in time-series as they are collected based on periods. Several time-series prediction methods for air quality measurements have been performed, including autoregressive integrated moving average (ARIMA) [
2], support vector machine (SVM) [
3], and fuzzy time series (FTS) [
4]. The concept of FTS was introduced by Song and Chissom [
5] through applying the principles of fuzzy logic in predicting a problem in which the actual data is converted into the form of linguistic values known as fuzzy sets [
6,
7]. The advantage of FTS is that it is able to predict linguistic data where it is impossible to calculate using ordinary time series methods. Furthermore, the use of FTS produces better prediction accuracy than other methods [
8], and it is widely used in financial forecasting [
9], tourism [
10], agriculture [
11], and air pollution [
12]. However, it still has several obstacles, such as determining the interval length of the universe of discourse, which has no special rules, using repeated fuzzy relationships, and considering the weight of fuzzy logical relationships (FLR).
Alyousifi et al. [
13] studied Markov weighted fuzzy time series (MWFTS) to overcome its weakness, such as using repetitive fuzzy and weighting considerations on FLR with the basic idea of applying the method and specifying weights within the framework of the FLR loop through the Markov chain. This process aims to obtain the greatest probability value using a transition probability matrix in determining the FLR weights between observations of stochastic time series patterns. The MWFTS method applied to air quality data in Klang, Malaysia produced good predictive results but also has problems in determining the interval length of the universe of discourse, thereby producing different accuracy values. This is the reason Alyousifi et al. [
13] proposed the use of a partition clustering method to overcome the MWFTS problem when determining the interval length. Research related to the Markov weighted fuzzy time series was also developed by Satria and Sugiyarto [
14], where the MWFTS method with the fuzzy k-medoids partition method, which was optimized using the particle swarm optimizer (PSO), was able to overcome the problem of determining the length of the U talk universe interval and improve accuracy.
This current study employed the MWFTS previously studied by Alyousifi et al. [
13] as the main method for predicting and overcoming the constraint when determining the interval length using the fuzzy k-medoids clustering (FKM) partition method. Dincer and Akkus [
15] also conducted a study to obtain the interval length of the fuzzy time series (FTS) using the FKM partition method. It was observed that the FKM produced optimal intervals compared to the fuzzy c-means (FCM) and Gustafson–Kessel (GK) methods, indicating that it is able to provide better predictive results. A further development was performed by optimizing the FKM partition method using the cat and mouse-based optimizer (CMBO), developed by Dehghani et al. [
16]. The performance of this new optimization method is much more competitive compared to the other nine algorithms because it provides a quasi-optimal solution that is more suitable and close to the global optimal solution. The CMBO method was chosen as an optimizer for FKM to see how far CMBO’s performance can improve the quality of FKM grouping.
In addition, the CMBO optimization in the FKM method is performed by optimizing the FKM cluster center in order to obtain an optimal medoid value; hence, it is able to improve the quality of grouping and MWFTS prediction results. The CMBO process in the FKM occurs iteratively until it reaches the stopping criterion, called the maximum iteration. In this study, the MWFTS method based on the CMBOFKM partition method is tested using air quality data.
2. Materials and Methods
The MWFTS and FKM clustering partition method optimized with the Cat and mouse-based optimizer was utilized. The stages in building the MWFTS–CMBOFKM predictive model are as follows:
2.1. Euclidean Distance
Euclidean distance is a calculation method used for measuring the distance between two points in Euclidean space. Its value was obtained with the following formula [
17]:
where,
: Euclidean distance between and ;
: -th cluster center value;
: -th actual data value;
: number of actual data;
: cluster number.
2.2. Fuzzy Time Series
The FTS is a prediction technique that uses fuzzy logic principles and is generally used for historical data in the form of linguistic data. The stages in the FTS model include defining the universe of discourse , partitioning into several intervals, fuzzification, forming fuzzy relationships, defuzzification, and determining predictive values.
Definition 1 [
5,
12,
13].
Suppose is the universe of discourse, then is a possible linguistic value in the . Furthermore, the fuzzy set of linguistic variables from is defined as follows:
where is a membership function of the fuzzy set then , and Definition 2 [
5,
13,
18]
. Suppose is a subset of real numbers defined by the fuzzy set . When is a set of , then is known as a fuzzy time series defined at .
Definition 3 [
5,
19]
. The relationship between and is expressed as . Suppose and , then the relationship between and is represented by FLR, where a and b refer to the left and right sides of the FTS.
Fuzzification is one of the stages in the FTS in which data are converted into linguistic values to form FLR. This formation requires upper and lower limit values obtained from the following equation [
19,
20]:
where
.
is the upper bound of the
-th interval, and
is the lower bound of the
-th interval. Since there is no cluster center before the first and after the last cluster center, the values of the lower limit on
and the upper limit on
were obtained using the following rules [
19]:
2.3. Fuzzy K-Medoids Clustering (FKM)
FKM is one of the clustering methods used to classify data into clusters by using the distance criterion as its determination, which is calculated based on the cluster center of the data values. The fundamental difference between the FKM method and the FCM method is the determination of the cluster center. For example, in the FCM method, the cluster center sometimes lies in any value in the universe of discourse, denoted as U, while, in the FKM, it is in the data value known as medoid [
21]. Medoid is an object or value located in a cluster data [
22]
It is important to note that the utilized calculation of FKM has the same concept as the FCM method, while the difference only lies in the final step of determining the cluster center. The medoid value is obtained in the FKM by first performing the FCM calculation process to determine an updated membership matrix
, then the index data with the largest membership value from each cluster are used to select the medoid. Meanwhile, the FKM method minimizes the objective function value to obtain good clustering results. The equation for the FKM objective function is as follows [
20]:
where,
: objective function in -th iteration;
: distance of the -th cluster center to the -th data value;
: membership degree in the membership matrix;
: fuzzy rank .
The FKM method also uses membership degrees for cluster center calculations, in which the initial membership degree value (
) is formed in the
membership matrix based on the following equation [
19]:
The membership matrix denoted as
was updated in each iteration, and is computed using the following equation [
21]:
After obtaining the
membership matrix, the cluster center is calculated with the following equation [
23]:
2.4. Markov Weighted Rule
The Markov weighted matrix was first introduced by Alyousifi et al. [
13]. based on the development of studies by Tsaur [
24] and Effendi et al. [
25]. It is a matrix that contains weighted elements of FLR through transition numbers. Its elements are determined as the ratio of the repetition numbers of a particular FLR to the total number of FLR. Furthermore, the Markov weighted matrix is defined as
, and its elements are calculated with the equation below [
12]:
where
is the transition probability value in
and
,
is the transition number in
and
, while
represents the number of transitions in
. Therefore, the transition probability matrix is written as follows [
13]:
and
.
According to Alyousifi et al. [
13], the two stages for calculating the defuzzification of predictive values using the Markov weighted rule in the MWFTS method include initial prediction and prediction adjustment. The first is generated by multiplying the Markov (
) weight matrix with the middle-value matrix (
). Meanwhile, the initial predictive value is calculated according to the following rules [
12,
13]:
Case 1: When the FLRG of
is a one-to-one relation (
with
and
, then the initial predicted value of
is the middle value of
with the equation denoted as
.
Case 2: When the FLRG of
is a one-to-many relation (
, and the data set
at time
is in state
, then the prediction results are as follows:
where
is the middle value of
, and
is replaced with
in
state to obtain a better accuracy value.
It is important to note that prediction adjustment is conducted after obtaining the initial prediction value, which is then adjusted by adding or subtracting the absolute value of the difference between the midpoint
and the actual value of
at the same interval when the data occurred in state
before moving forward to the state
or back to state
. When there are no moves, the prediction value remains; otherwise, it is calculated as follows [
12,
13]:
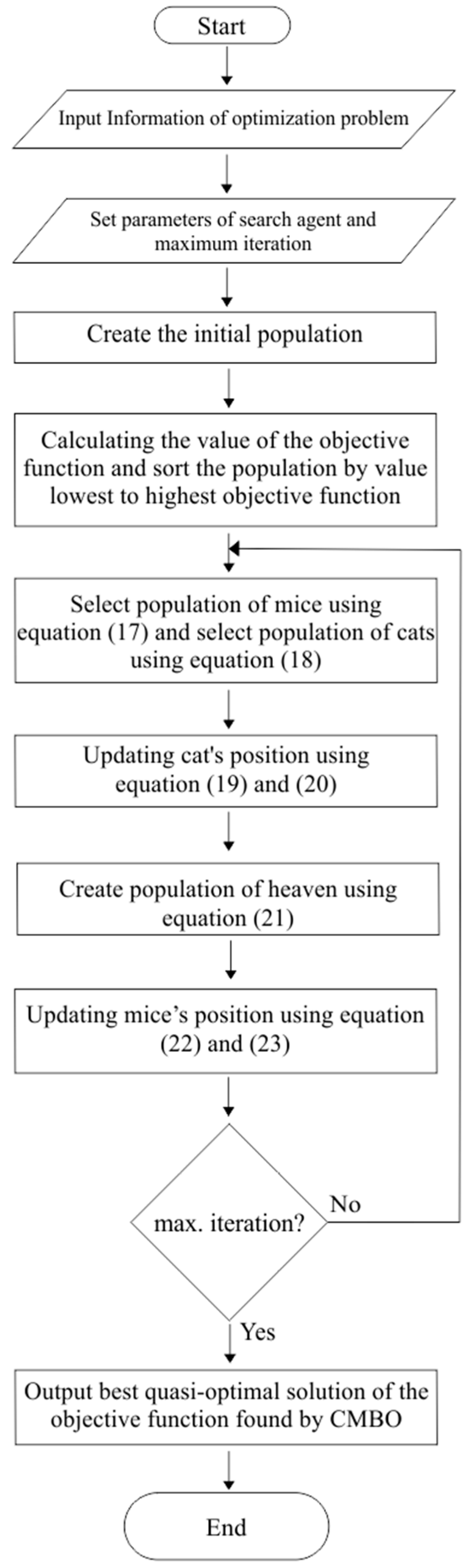
2.5. Cat and Mouse-Based Optimizer (CMBO)
CMBO is a new population-based optimization method that adopts cats’ behavior of chasing mice and mice looking for nests to find shelter. In the CMBO optimization process, the population is divided into cats and mice; afterwards, the population members are updated in two phases, namely calculating the movement of cats toward mice and the movement of mice looking for nests to find shelter. This method generates a population matrix in which each member is a solution to the problem variable.
The initial stage of CMBO optimization is to generate a population matrix containing solutions to the problem variables. This generated population matrix is generally written as follows [
16]:
where
is a population matrix containing solutions to the problem variable and
is the population matrix element, denoted as Z.
The second stage is where the objective function is calculated for each member of the population and sorted from the smallest value to the largest objective function. Specifically, the population members are addressed based on the objective function that has been sorted.
In the third stage, the initial population matrix that has been sorted was divided into two equal parts in which the two matrices are regarded as the mouse and the cat, respectively. The division of these two populations was determined by standard rules, in which the first 50% of the rat population was obtained from the initial population of the lowest objective function, while the other 50% is the cat population taken from the highest objective function value. Furthermore, this rule of dividing the population into two equal parts aims to have each cat target exactly one mouse in the direction of lowest objective function value. This means that when mice and cats are updated, a new balanced population emerges. The mice and cat population matrix is written as follows:
where
is the mouse population matrix,
represents the number of rows of the mouse population,
denotes the cat population matrix,
is the number of rows of the cat population,
is the
-th mouse agent, and
represents the
-th cat agent.
In the fourth stage, the cat and mouse populations were updated through two phases, which include changing the position of the cat that was chasing the mouse and that of mouse running towards the nest to hide.
Phase 1: The change in the position of the cat chasing the mouse is formulated below:
With
where
is the new position of the
-th at agent,
represents the element of the new cat agent’s position in the
matrix,
denotes a random number at interval
, and
is the objective function value of the
-th position of the new cat agent.
Phase 2: The change in mice position when moving towards the nest is formulated below:
where
denotes the -th mouse nest, represents the objective function value of the -th mouse nest, is the new position of the i-th rat agent, is the element of the new mouse agent position in matrix , and indicates the objective function value of the new mouse agent position to -th.
The last stage involves the repetition of the second stage to the fourth stage until the criteria for stopping the CMBO method is met. Conceptually, the stopping criterion in the CMBO method is the maximum iteration obtained, while the optimal CMBO solution is determined based on the population member with the lowest objective value. The CMBO flowchart can be seen in
Figure 1.
2.6. Prediction Evaluation
Prediction evaluation was employed to determine the quality of the model developed. In this present study, the evaluation methods utilized include root mean square error (RMSE) and mean absolute percentage error (MAPE). The RMSE was used to evaluate the prediction model by squaring the difference between the actual data and the previous prediction results, divided by the amount of data. The prediction result is considered more accurate when the RMSE value is close to zero [
26]:
where
is the actual value of the data at time
-th,
represents the predicted value at time -
, and
denotes the data number.
MAPE is a prediction model evaluation method that presents the prediction model error accuracy value in the form of a percentage [
6]:
where
is the number of data,
is the actual data at time
t-th, and
represents the predicted value at time
-th.
Table 1 shows the standard value prediction criteria for MAPE [
27].
2.7. Flowchart MWFTS-CMBOFKM
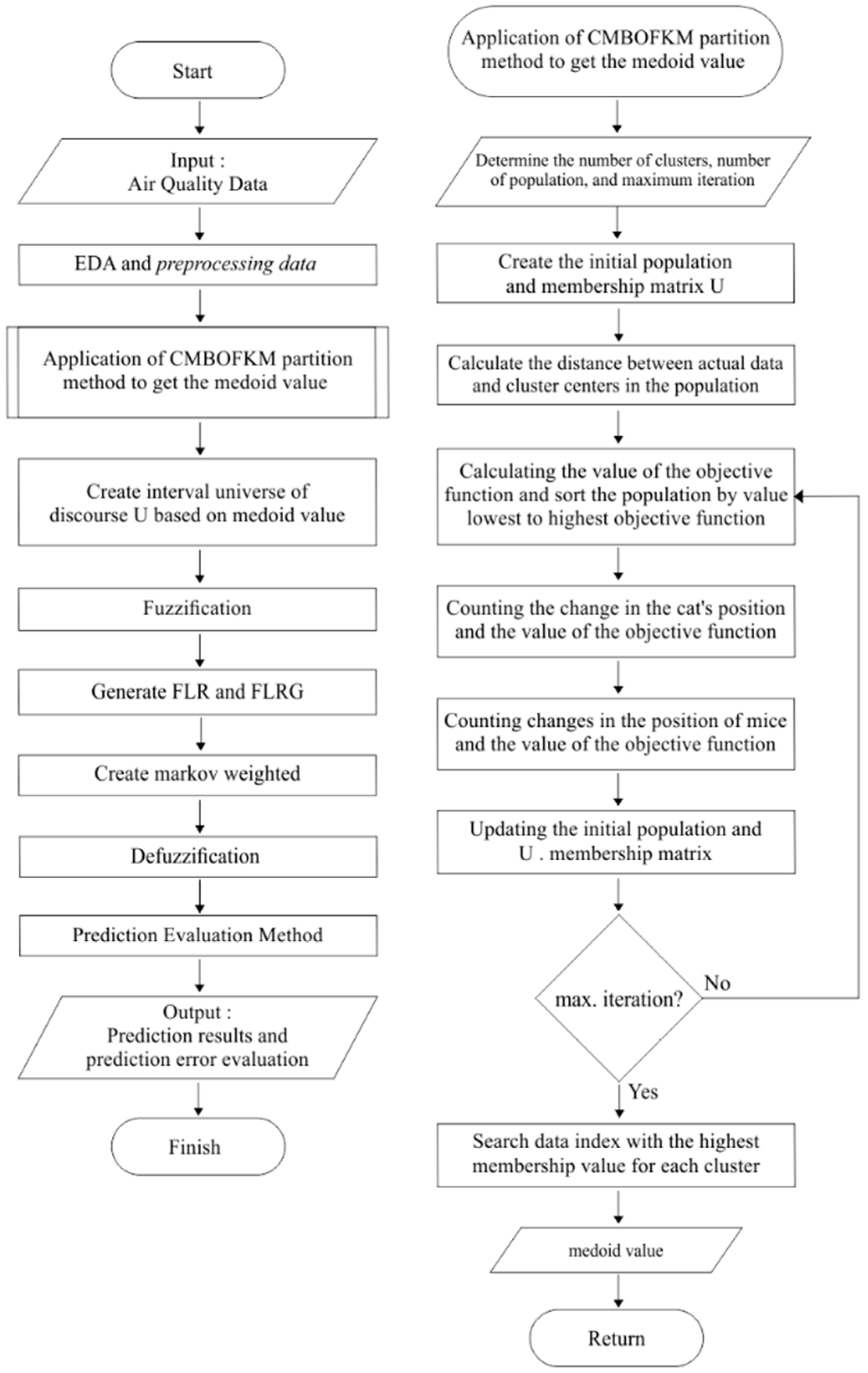
The flowchart of the Markov Wighted Fuzzy Time Series model hybridized with CMBOFKM can be seen in
Figure 2. First, we enter air quality data and then check the attribute data through EDA and data pre-processing. Data that has gone through EDA and data preprocessing will enter the MWFTS-CMBOFKM model process. In the MWFTS-CMBOFKM Model Algorithm it is divided into 2 important processes, the first is to find the medoid value of the data through the CMBOFKM method, then process the medoid value into U-speech universe intervals to form FLR and FLRG to obtain the predicted value and the results of the prediction model accuracy.
3. Results and Discussion
This study employed the air quality datasets in Klang, Malaysia recorded from 1 January 2020 to 1 May 2022, and the data platform accessed on 9 November 2021 was sourced from the Air Quality Historical Data Platform website on the
https://aqicn.org/data-platform/register/. The first dataset used is shown in
Table 2.
AQI is used to assess air pollution in Malaysia, which was regarded as a simple measure of air quality status. The total number of datasets considered was 852.
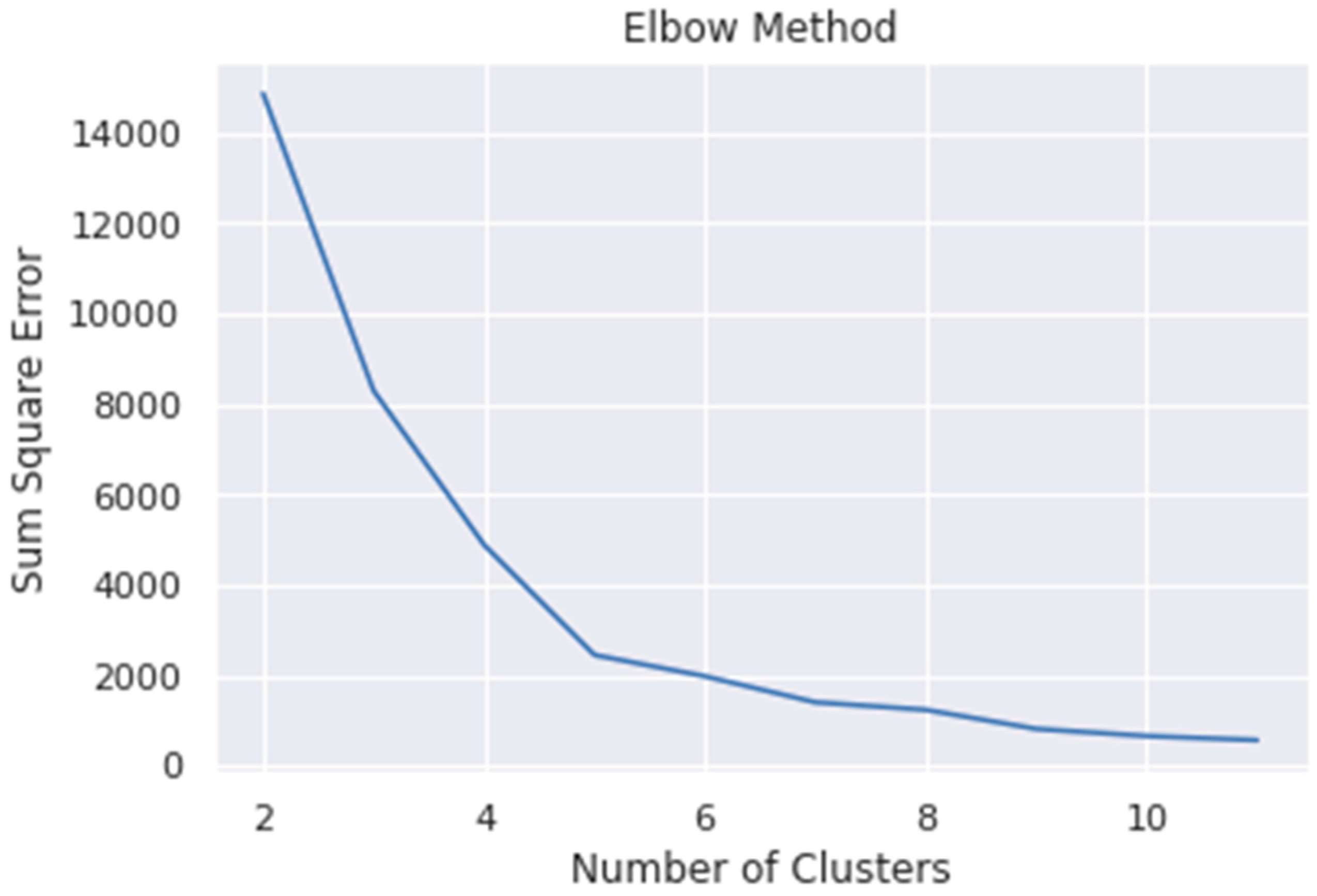
The first step was applying the FKM method with CMBO in order to obtain the medoid value used to form the universe of discourse interval
. The selection of parameter values used in this research method has previously been simulated by determining the number of clusters using the elbow method, the number of agents is evaluated based on the lowest MAPE percentage value. The simulation results of the number of clusters used can be seen in
Figure 3 while the results of the evaluation of the number of agents based on 100 iterations can be seen in
Table 3.
Figure 3 shows that the angled curve is formed when the number of clusters is at five, while
Table 3 shows that the smallest MAPE percentage is at 20 search agents, so that the number of clusters used in this study is five, and the number of search agents is 20.
The obtained number of clusters = 5, the initial search agents = 20, and the maximum iteration = 100. The CMBOFKM partition process first generates the membership matrix , while the initial population represents the cluster center.
The membership matrix
was generated based on Equation (8) with a size of
population. This means that each member of the population has their own membership value denoted as
. The objective function is also calculated using Equation (7) regarding the populations and the membership matrix
. Furthermore, the objective function
was sorted from the smallest to the largest values as well as the initial population members and the
membership matrix as shown in
Table 4.
The initial population that has been sorted is divided into two equal parts, which include mice and cats populations. Agents 1 to 10 are members of the mouse population, while that of 11 to 20 are the cats. Furthermore, the two populations are updated based on two phases, such as the cat chasing the mouse and the mouse hiding in the nest. The phase of the cat chasing the mouse was determined with Equation (19), while mouse hiding was obtained using Equations (21) and (22). The values of the new objective function in each new population were compared with the old objective function using Equations (20) and (23), and the updated mouse and cat populations are shown in
Table 5 and
Table 6.
The updated results of the rat and cat populations are combined into an entirely new population with the newest mouse and cat serving as new members, respectively. Furthermore, the membership matrix was calculated for each new population member based on Equation (9), and the iteration was performed by sorting the objective values in order to update the membership matrix and a new population regarding the specified maximum iterations.
It is important to note that the maximum iteration in this study was 100, and the membership matrix
was selected based on the search agent with the lowest objective function. Furthermore, the medoid was selected based on the highest membership value in each cluster and was adjusted by sorting the smallest to largest medoid values.
Table 7 shows the CMBOFKM’s results of the medoid values.
The results of the medoid in
Table 8 are used to form the universe of discourse interval
using Equations (3)–(6) before determining the middle value of each of them. The results of
and middle value are shown in
Table 8.
Furthermore, the interval obtained was later entered into the data fuzzification process by changing its value into a fuzzy
. After fuzzification, the data were in the form of FLR and fuzzy logical relationships group (FLRG) based on Definition 3. The FLRG in the MWFTS method contains the number of transition events from
to
, while the data fuzzification as well as the formation of FLR and FLRG results are shown in
Table 9 and
Table 10.
Table 10 was used to form a Markov weighted matrix based on Equation (11). The result was expressed as follows:
The defuzzification of the predictor value was also calculated based on two stages, namely initial prediction and prediction adjustment. The defuzzification results of the predicted value of MWFTS–CMBOFKM are shown in
Table 11.
The MWFTS–CMBOFKM prediction results were evaluated based on MAPE and RMSE. It was observed that the method has a MAPE percentage of 6.85% with an RMSE score of 6071.
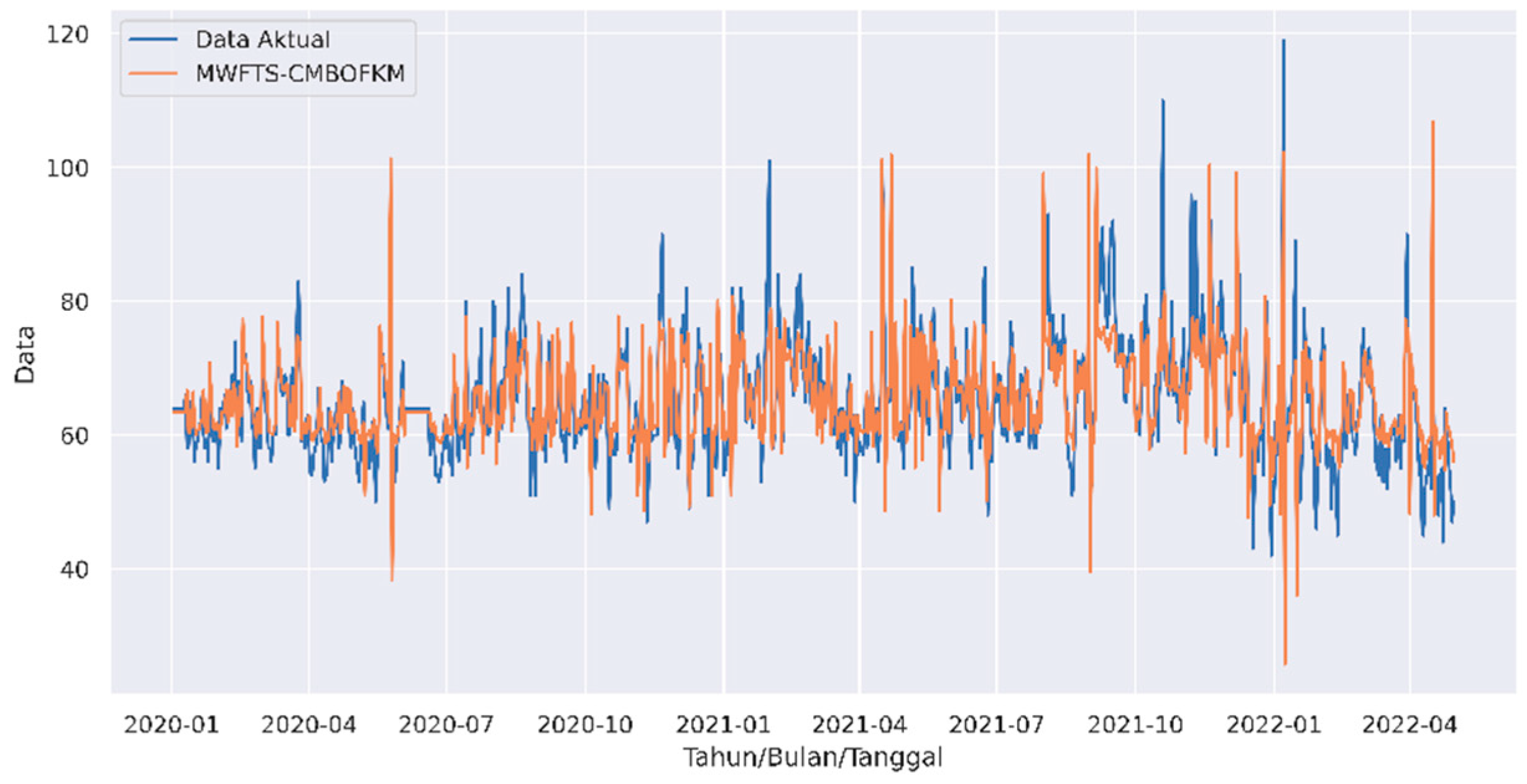
Figure 4 shows the graph comparing the actual data with the predicted results.
According to
Figure 4, the MWFTS–CMBOFKM prediction value approaches the actual data value. Meanwhile, the MAPE percentage regarding
Table 1 shows that the MWFTS–CMBOFKM prediction model is included in the very accurate prediction criteria.
4. Conclusions
The CMBO method optimizes the FKM cluster center to obtain the best membership matrix
as a producer of the optimal medoid value, which helps to increase the MWFTS predictive accuracy. The implementation of the MWFTS–CMBOFKM method on air quality data in Klang, Malaysia was evaluated using MAPE and RMSE. The results showed that MAPE had a percentage of 6.85%, indicating that the prediction accuracy of MWFTS–CMBOFKM was 93.15% with an RMSE score of 6071. Graphically, it was observed that the predicted value was close to the actual data. Based on
Table 1, the MWFTS–CMBOFKM prediction model was very accurate with a MAPE percentage < 10%.
Further studies need to investigate other partitioning methods useful for determining the universe of discourse interval . Furthermore, other population-based optimization methods such as ant colony optimization, bee colony optimization, and the latest population-based optimization methods have to be considered when comparing the resulting level of accuracy.









{kind=link}
{kind=link}
{kind=link}
{kind=link}