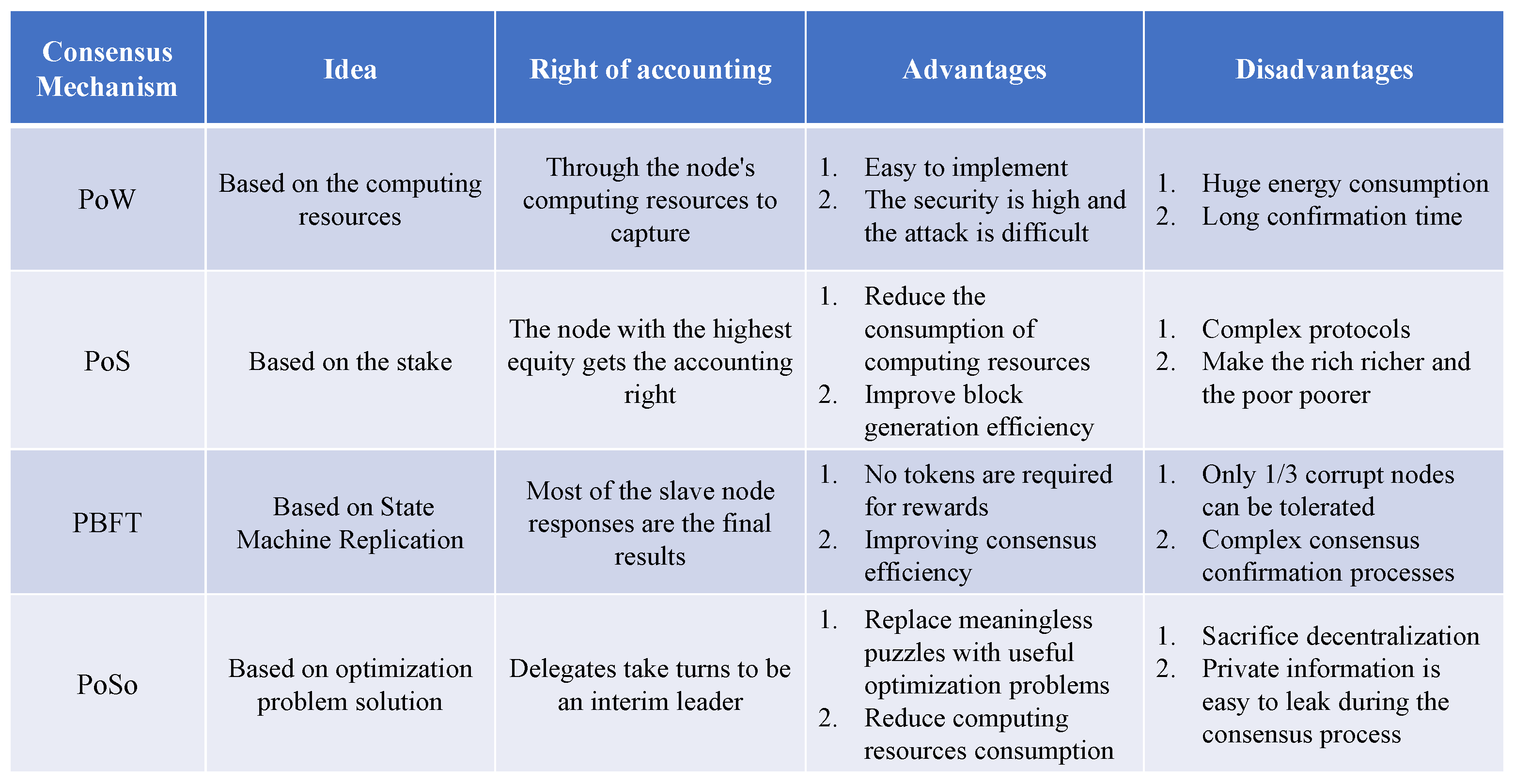
4.1. PoSo-Based Consensus Mechanism
In last section, we propose a negotiation mechanism for P2P energy trading, which is based on the marginal price. However, under the LMP mechanism, the agents who dominate the prices can earn more profit by taking some dishonest strategies. To solve this problem, in this section, a new consensus mechanism is proposed for P2P energy trading based on PoSo, which is an effective way to prevent agents from dishonest behavior.
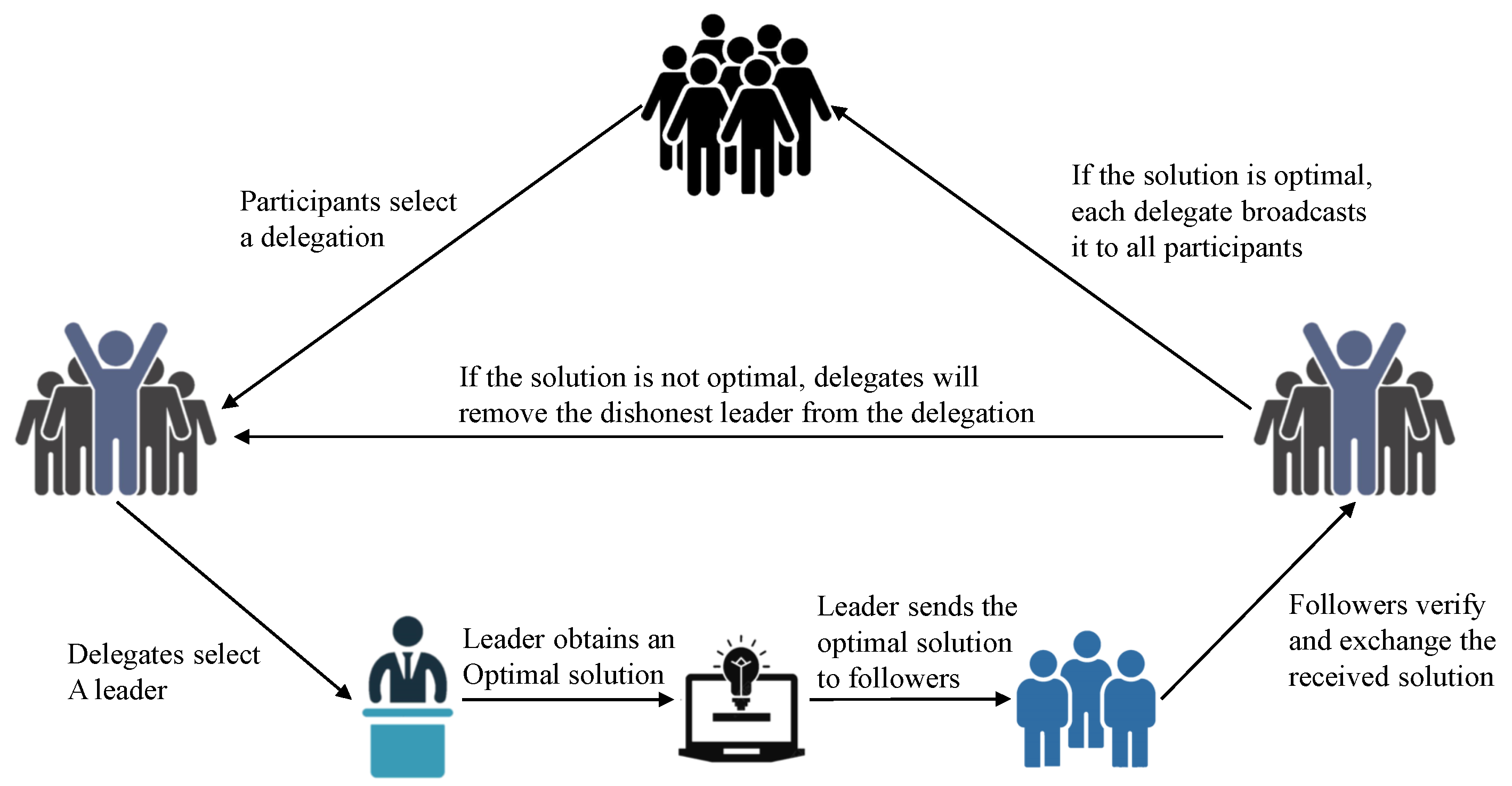
Reviewing the PoSo flow chart again, a delegate is first selected from participants, and a temporary leader is further elected from the delegate. The leader will solve the social welfare maximization problem to propose an optimal solution, while the followers in the delegate verify the optimality to decide whether to accept it or not. Although this mechanism has good computational efficiency, it is not suitable for P2P energy trading due to the unwillingness of prosumers to share private information with the central leader.
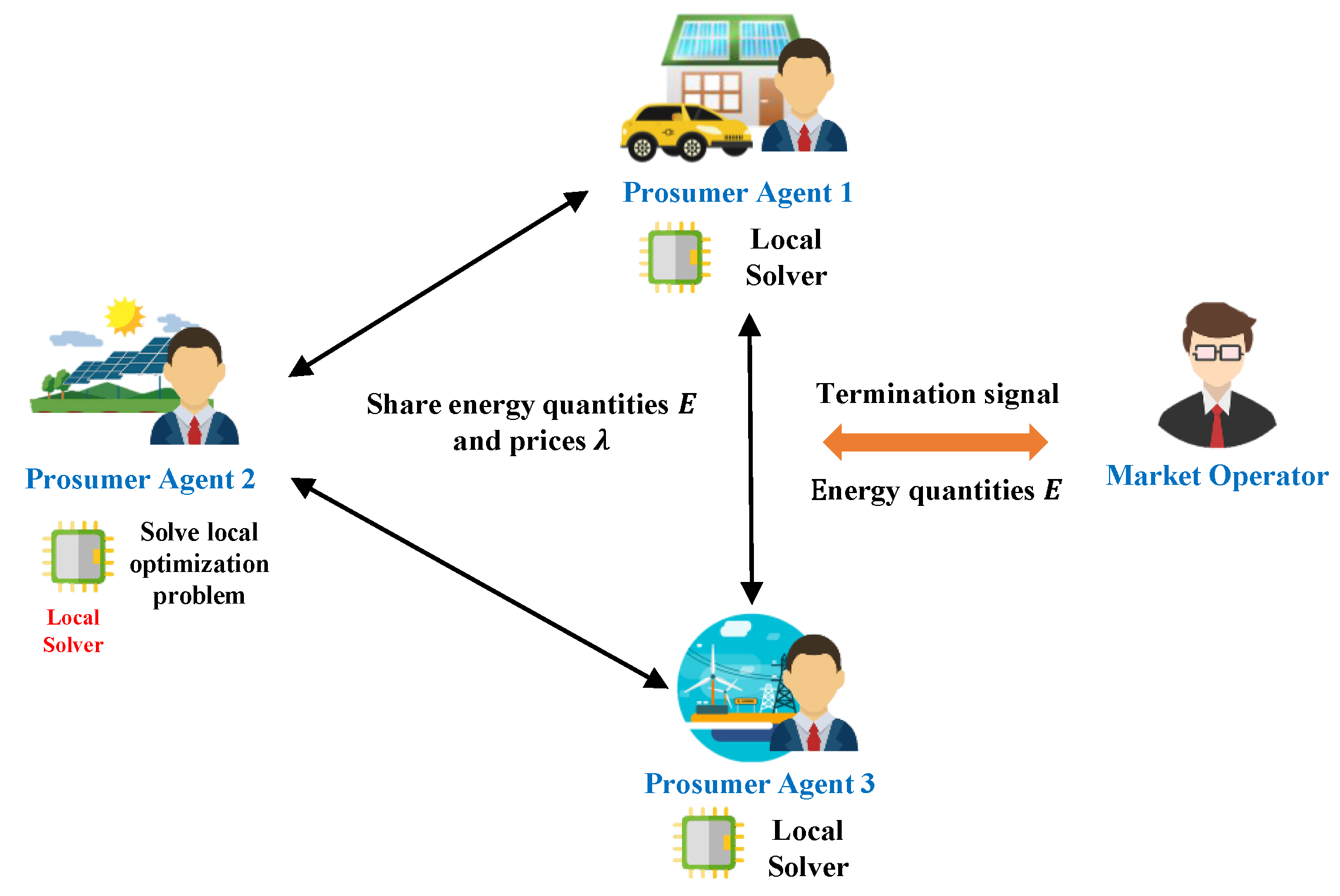
Therefore, to solve this problem, an improved and revised version of the PoSo mechanism is designed to fit our proposed CADMM-based P2P energy trading negotiation mechanism [
38], which can well protect the private information. Each agent solves individual optimization problems (
15) to obtain an optimal solution, and neighbor agents verify the equivalent KKT conditions to prove its optimality. Then, in turn, the agent will also check the solution of neighbor agent. Thus, the consensus mechanism is running in a symmetric manner.
The main advantage is that no authorization is required and the agent does not need to convey private information to the central leader. All agents can solve the local optimization problem in parallel and broadcast the results to neighboring agents for optimality verification.
In more detail, the KKT conditions for local updates (
15) are listed as in (
18).
The above equations construct a nonlinear problem with primal variables and dual variables . are for constraints , and is for ().
However, if we choose to check all of these equations, it will cause a very large computational and communication burden. Alternatively, we choose to verify the cumulative KKT condition as below:
After each update, agent
n will send a information set
to neighboring agents for verification. The set contains information as below:
If the cumulative KKT conditions (
19) are met, the optimality of the solution is also successfully verified, and results are exchanged among other neighbor agents until the majority of them are approved. An incentive and punishment mechanism is also designed. In detail, if the verification fails, the dishonest agent
n will be subject to a heavy fine, which is expressed as adding a penalty indicator function
in the objective function. If the result is optimal,
; on the contrary,
. Here,
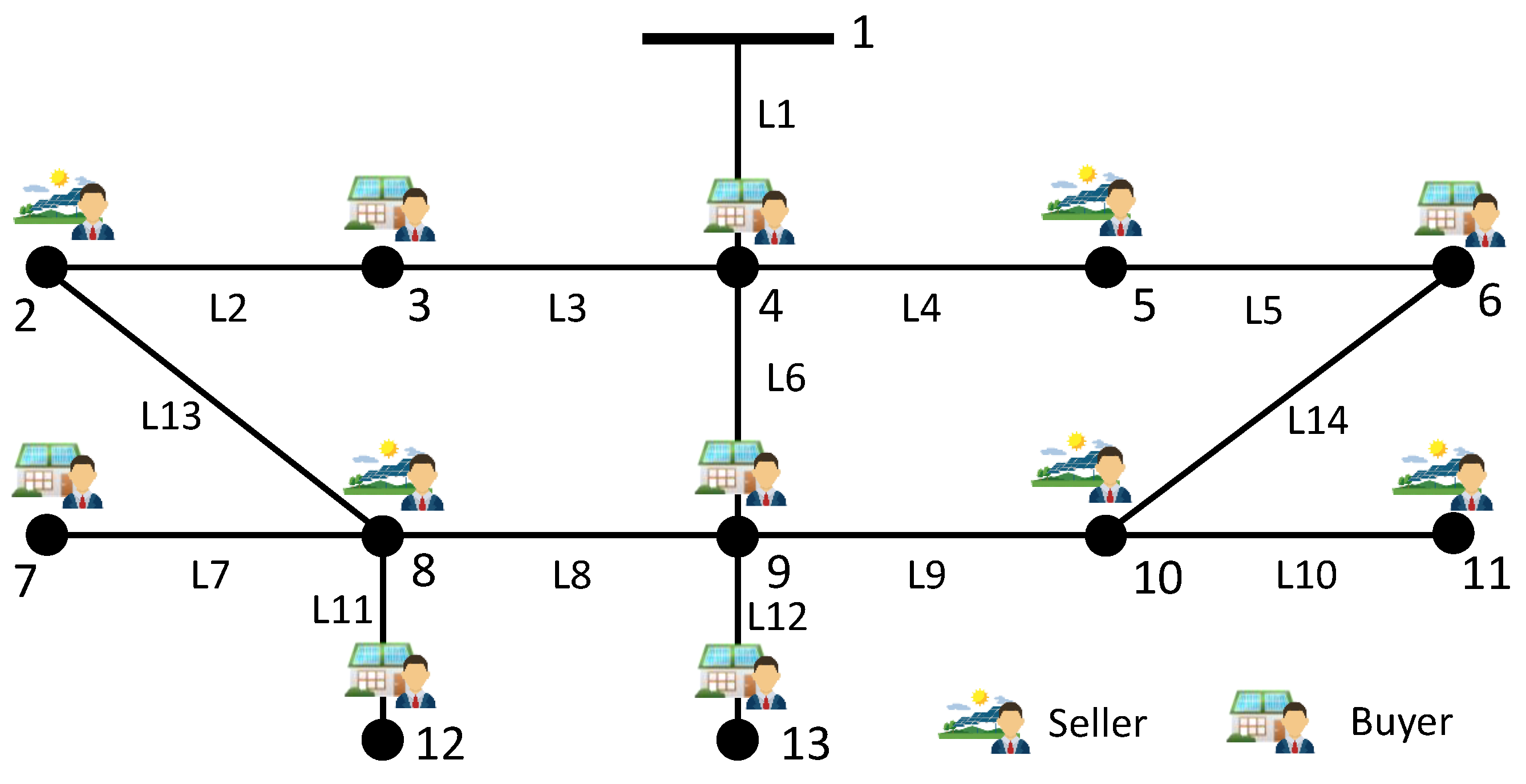
P is a predefined penalty that will be distributed equally among all verifiers who participate in the consensus process. This new consensus mechanism can motivate agents to participate honestly in the energy market and achieve an incentive compatible market. An illustrative example is shown in the
Figure 5, and the consensus mechanism is summarized in Algorithm 1.
| Algorithm 1: The improved PoSo-based consensus mechanism for P2P energy trading. |
![Symmetry 15 01561 i001]() |
Similar to other blockchain consensus mechanisms, the proposed consensus mechanism is only effective if the number of honest neighbor agents exceeds the number of dishonest agents. An effective consensus mechanism indicates that all participants take actions based on the correct and identical optimal solution. As long as there are honest neighbor agents in the verifiers list, all honest agents will eventually see the optimal solution, so the consensus verification succeeds. In other words, as long as there are a majority of honest neighbor agents, the optimality of the received solution can be successfully verified. When more than 50% of the neighbor agents obtain the same verification result, anyone can trust the result because a non-optimal solution is impossible to be accepted by more than half of the neighbor agents. However, if dishonest agents dominate the verifiers set, they may also control the verification outcome.
4.2. Protect the Private Information and Resist Malicious Agents
In the consensus verification process, agents have to send private information to neighboring agents. However, there may be dishonest nodes who will collect individual privacy to take strategy and earn more profit. Additionally, they may not complete the verification work or deliberately disapprove the optimality of the received solutions. Thus, the proposed method should resist untrusted agents who have this misbehavior. In this section, we propose a privacy-preserving consensus mechanism that is resistance to untrusted agents, who may collect individual privacy or destroy the consensus verification process. Here, we assume that there are always no more than f of N agents are untrusted and malicious in the neighboring agents set.
4.2.1. Algorithm
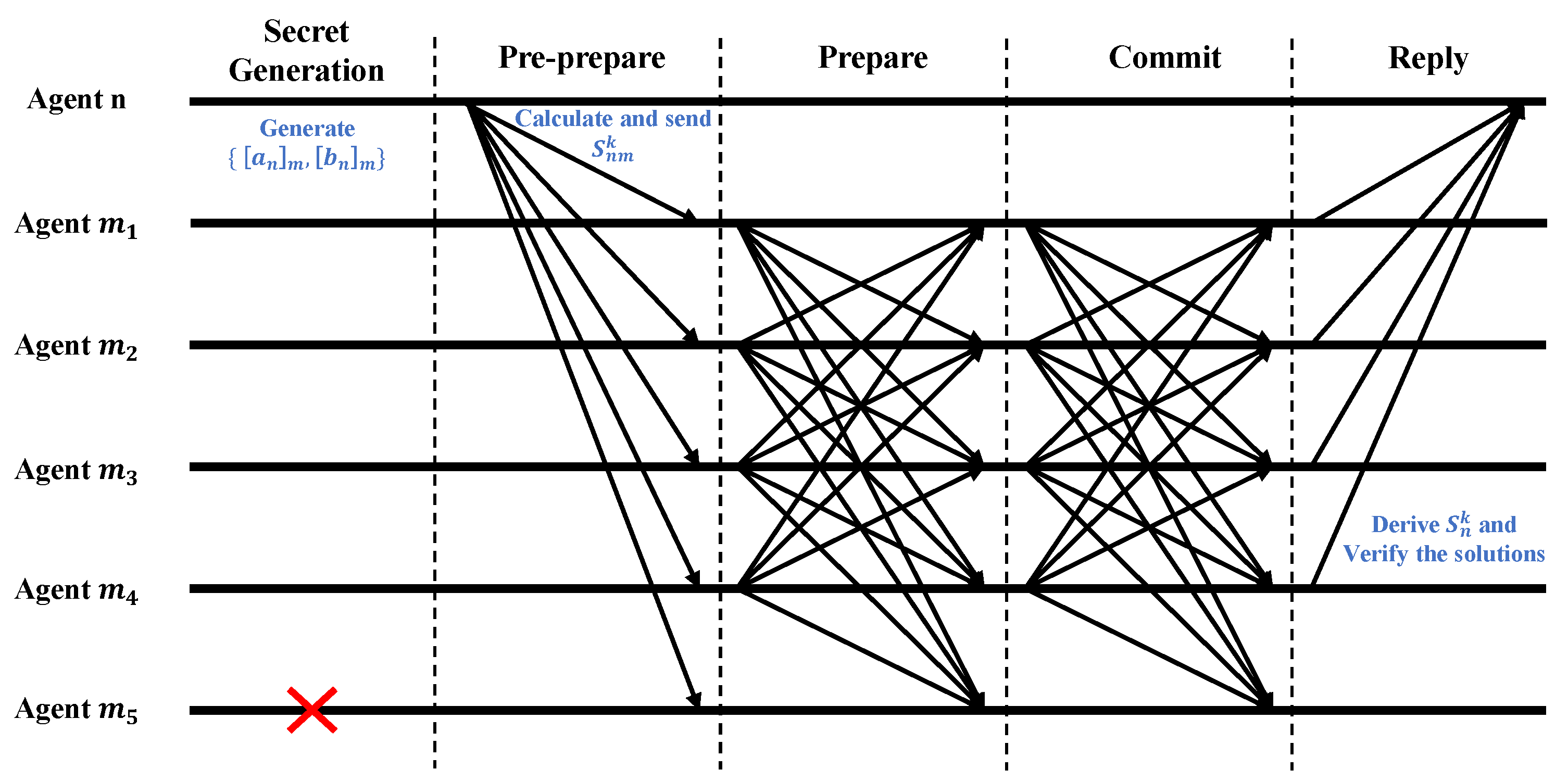
The proposed privacy-preserving consensus mechanism is illustrated in
Figure 6. The agent
is malicious, who will not forward any messages.
Briefly speaking, an agent generates
pieces of encrypted data and separately submits encrypted aggregated information to each corresponding neighboring agent. Then, we use a PBFT-based method [
39] to realize that the trusted agents can recover the right result even under the misbehavior of malicious agents.
In detail, first of all, in the secret generation phase, before the negotiations begin, agent
n would generate pieces of the encrypted
and
using Shamir’s Secret Sharing scheme [
40]. It constructs polynomials
where
are randomly generated. Then, for each neighboring agent
, agent
n generates encrypted information
. Here, we use
to denote
for simplicity.
The encryption algorithm has two important properties as follows:
(i) The algorithm is a
threshold scheme. The actual information
of agent
n can be decrypted using (22) only if at least
encrypted messages are collected.
(ii) It is additively homomorphic. That is to say, only when the sum of at least
agent
n encrypted information is collected, can (
23) be used to decrypt the sum of agent
n information.
As far as we know, Shamir’s secret sharing is the simplest scheme that satisfy the above properties in the domain of real numbers. Our approach remains valid for other schemes with the same properties, such as the Brickell scheme [
41].
We then try to explore a way to realize that trusted agents can always recover correct information even under the misbehavior of malicious agents. This algorithm inherits the idea of PBFT. Specifically, in the Pre-prepare phase, agent
n obtains the updated solution
after iteration
k, agent
n calculates aggregated piece information
as follows:
and sends them to corresponding neighboring agents; then, in the Prepare phase, each agent
m will broadcast
to all agents in
; after that, in the Commit phase, when receiving
from no less than
agents, each agent send a Commit message to others; finally, in the Reply phase, when receiving Commit messages from no less than
agents (including itself), agent
m derives the correct aggregated result
by executing Algorithm 3. In short, the agent enumerates all possible decryption results, and most of these possible results are considered correct.
After the result reconstruction process, each neighboring agent validates the optimality of the received solutions
by (
19) according to the correct results. Algorithms 2 and 3 introduce the procedure of the privacy-preserving consensus mechanism for agent
n and correct result decryption method.
4.2.2. Security Analysis
Theorem 1: If the proportion of untrusting neighboring agents is less than 1/4, i.e., , the proposed method guarantees the correctness of the consensus verification result.
Proof 1: The Reply phase ensures the correctness of the aggregation result
. In detail, when an agent receives no less than
Commit messages, at least
Commit messages were sent by trusted agents. Therefore, a trusted agent can obtain at least
correct results in Algorithm 3. Untrusted agents may tamper with pieces of their encrypted messages to cause trusted agents to decrypt incorrect results. However, even if the untrusted agents send
f of
Commit messages, the trusted agent exports incorrectly aggregated data up to
times [
42]. Therefore, the trusted agent always outputs the correct result
in Algorithm 3.
| Algorithm 2: Privacy-preserving consensus mechanism for agent n. |
![Symmetry 15 01561 i002]() |
| Algorithm 3: Correct aggregated result decryption method. |
![Symmetry 15 01561 i003]() |
4.3. Improve the Efficiency of the Consensus Mechanism
In a distributed optimization method-based P2P energy trading mechanism, it usually takes many iterations to converge, which will cause a mass of communication time for the consensus mechanism. Additionally, since agents have to exchange information with each other to reach a consensus, the communication complexity is , where k is the iterations for convergence, and N is the numbers of agents in the market. It is undeniable that our algorithm is inefficient when dealing with a large number or prosumers, but there are two ways to improve efficiency.
First, it can be discovered that the verification equation contains the previous results . It means that if a dishonest agent constructs an incorrect solution at a certain iteration to pass the verification, it probably will not pass in the next iteration unless it proceeds to solve the local problems using the sub-optimal solutions, but it may result in economic loss. Therefore, the optimal solutions are linked to each other to form a “chain”, and it is sufficient to verify the optimality of only the first and last few iterations. To be specific, for each agent n, we only verify the solutions of the first three iterations and last few iterations according to the residuals (17). When the maximal value of and is less than , the consensus verification process is activated. The smaller means less consensus verification. The is chosen to be 10 in this work. By using this low-frequency consensus mechanism, the computational burden can be highly reduced.
Second, in the energy community, prosumers usually have frequent or fixed trading partners. Thus, it is better to divide the network into different shards according the transaction history, and prosumers only need to communicate with others in the same shard. In this way, the communication complexity can be highly reduced, and more shards, lower complexity. How to reasonably allocate prosumers to different shards is the focus of our future work.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}