
FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning


Abstract
:1. Introduction
- We integrated existing well-known datasets and added additional problems beyond those in the field, constructing a larger dataset for geometric problem solving. This dataset comprises a total of 6981 manually annotated and solved geometric problems.
- We established a geometric formal language system (FormalGeo) that guides the transformation of natural language into formal language. Concurrently, we built a geometric problem solver (FGPS) to validate annotated theorem sequences. By annotating the original image and text information of problems into a form understandable by the geometric formal language system, we can input the theorem sequences for validation. This not only ensures the correctness of proofs but also achieves interpretable step-by-step deduction.
- We introduced reinforcement learning, specifically employing a Monte Carlo Tree Search, into geometric automated reasoning. This is executed by conducting heuristic searches in a geometric reasoning environment built upon the FormalGeo system to address the limited annotated data issue.
2. Related Work
2.1. Datasets for Geometry Problems Solving
2.2. Reinforcement Learning for Geometry Problems Solving
3. Geometry Formal System
3.1. Geometry Formal Language
3.2. FormalGeo7k Dataset
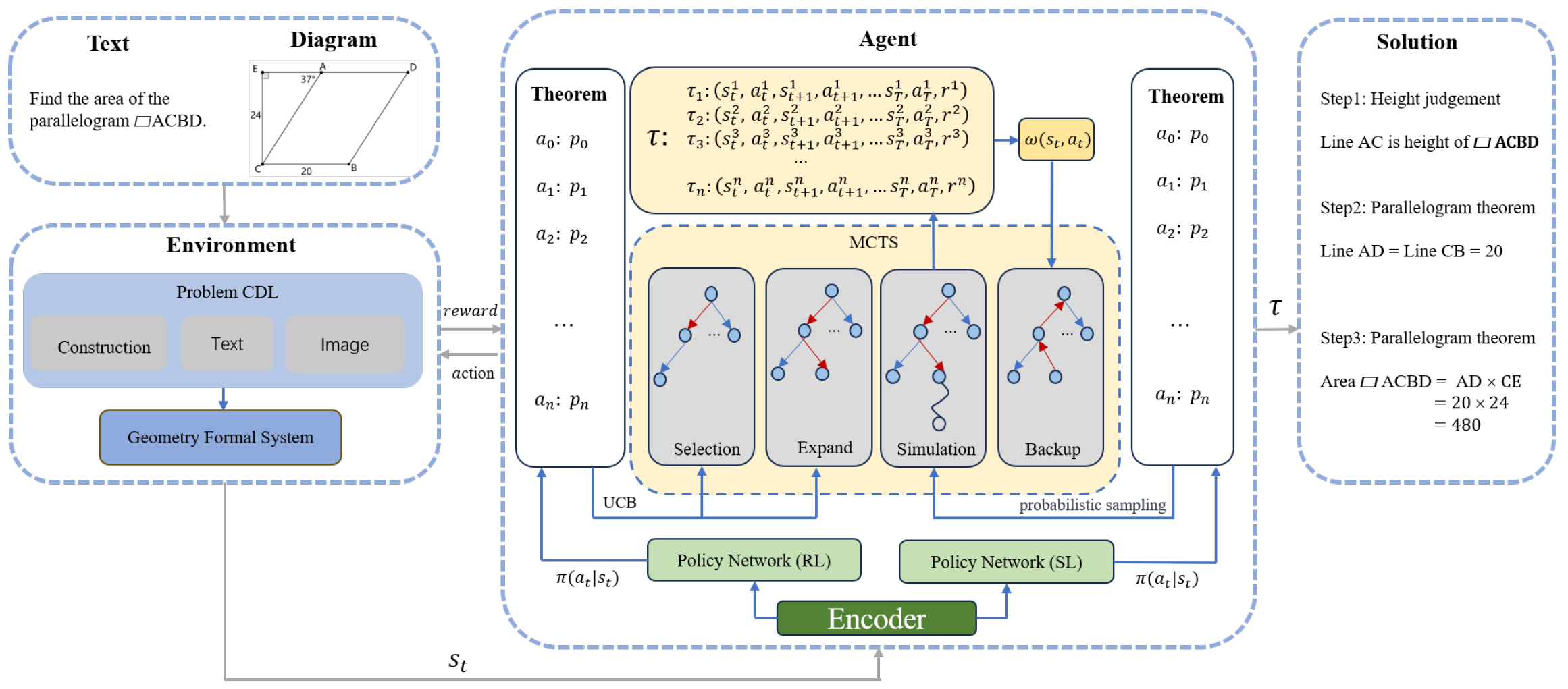
4. Reasoner
4.1. Environment
4.2. Guidance
4.3. Monte Carlo Tree Search
| Algorithm 1 Agent Trajectory Prediction |
|
5. Experiments
5.1. Training Method
5.1.1. Policy Network Datasets
5.1.2. Baseline
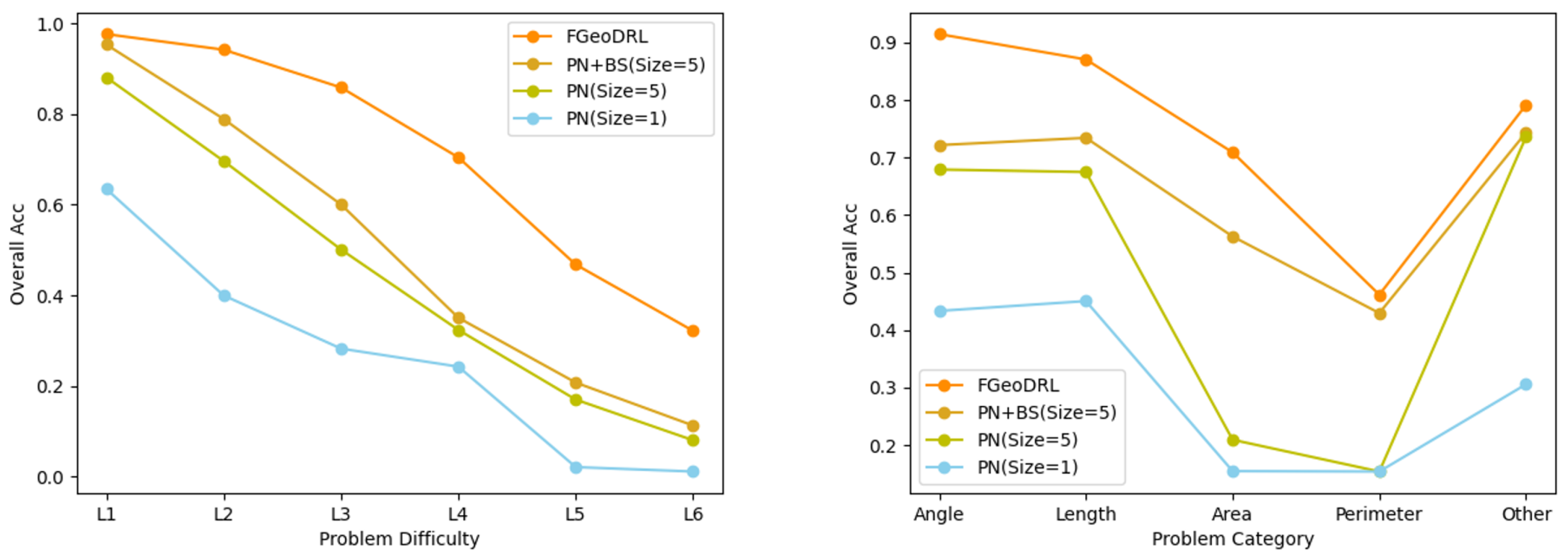
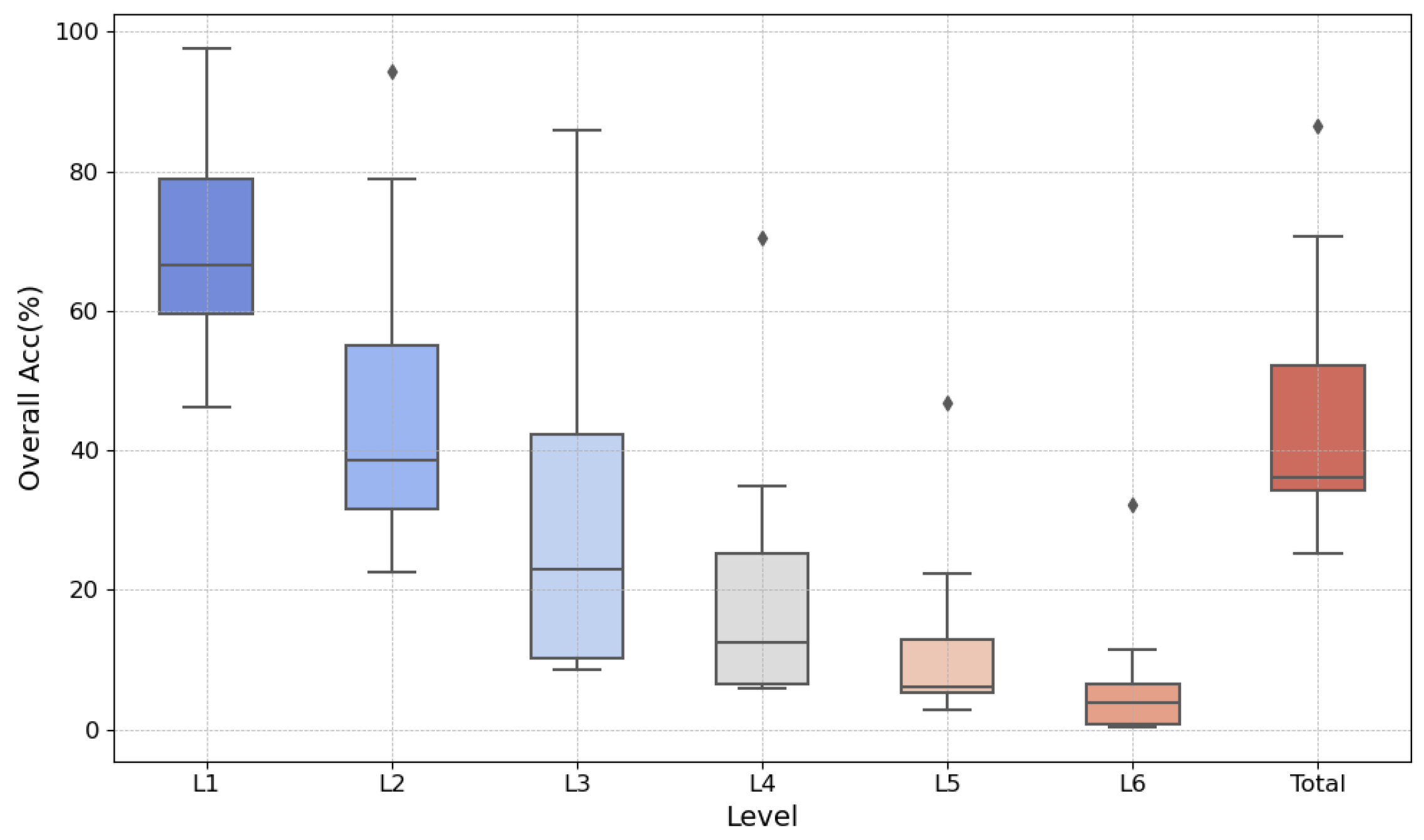
5.2. Ablation Study
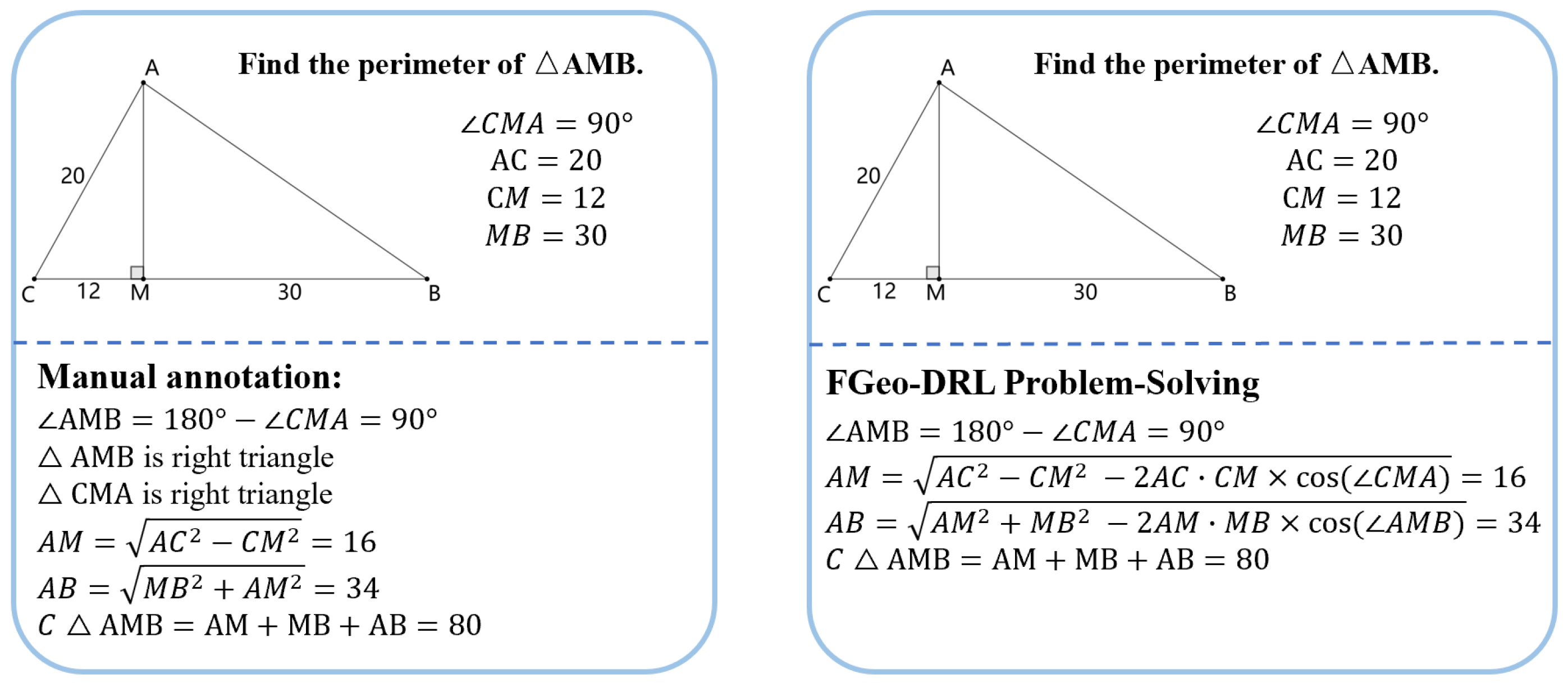
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Orrù, G.; Piarulli, A.; Conversano, C.; Gemignani, A. Human-like problem-solving abilities in large language models using ChatGPT. Front. Artif. Intell. 2023, 6, 1199350. [Google Scholar] [CrossRef]
- Lu, P.; Gong, R.; Jiang, S.; Qiu, L.; Huang, S.; Liang, X.; Zhu, S.C. Inter-GPS: Interpretable geometry problem solving with formal language and symbolic reasoning. arXiv 2021, arXiv:2105.04165. [Google Scholar]
- Gao, J.; Pi, R.; Zhang, J.; Ye, J.; Zhong, W.; Wang, Y.; Hong, L.; Han, J.; Xu, H.; Li, Z.; et al. G-llava: Solving geometric problem with multi-modal large language model. arXiv 2023, arXiv:2312.11370. [Google Scholar]
- Webb, T.; Holyoak, K.J.; Lu, H. Emergent analogical reasoning in large language models. Nat. Hum. Behav. 2023, 7, 1526–1541. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Nam, H.; Kim, S.; Jung, K. Number sequence prediction problems for evaluating computational powers of neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4626–4633. [Google Scholar]
- Chen, J.; Tang, J.; Qin, J.; Liang, X.; Liu, L.; Xing, E.P.; Lin, L. GeoQA: A geometric question answering benchmark towards multimodal numerical reasoning. arXiv 2021, arXiv:2105.14517. [Google Scholar]
- Cao, J.; Xiao, J. An augmented benchmark dataset for geometric question answering through dual parallel text encoding. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 1511–1520. [Google Scholar]
- Zhang, X.; Zhu, N.; He, Y.; Zou, J.; Huang, Q.; Jin, X.; Guo, Y.; Mao, C.; Zhu, Z.; Yue, D.; et al. FormalGeo: The First Step Toward Human-like IMO-level Geometric Automated Reasoning. arXiv 2023, arXiv:2310.18021. [Google Scholar]
- Li, K.; Gupta, A.; Reddy, A.; Pong, V.H.; Zhou, A.; Yu, J.; Levine, S. Mural: Meta-learning uncertainty-aware rewards for outcome-driven reinforcement learning. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 6346–6356. [Google Scholar]
- Arjona-Medina, J.A.; Gillhofer, M.; Widrich, M.; Unterthiner, T.; Brandstetter, J.; Hochreiter, S. Rudder: Return decomposition for delayed rewards. Adv. Neural Inf. Process. Syst. 2019, 32, 13566–13577. [Google Scholar]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Zou, J.; Zhang, X.; He, Y.; Zhu, N.; Leng, T. FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning. arXiv 2024, arXiv:2402.09051. [Google Scholar] [CrossRef]
- Gelernter, H.; Hansen, J.R.; Loveland, D.W. Empirical explorations of the geometry theorem machine. In Proceedings of the Western Joint IRE-AIEE-ACM Computer Conference, San Francisco, CA, USA, 3–5 May 1960; pp. 143–149. [Google Scholar]
- Wen-Tsun, W. Basic principles of mechanical theorem proving in elementary geometries. J. Autom. Reason. 1986, 2, 221–252. [Google Scholar] [CrossRef]
- Chou, S.C.; Gao, X.S.; Zhang, J.Z. Automated generation of readable proofs with geometric invariants: I. Multiple and shortest proof generation. J. Autom. Reason. 1996, 17, 325–347. [Google Scholar] [CrossRef]
- Seo, M.; Hajishirzi, H.; Farhadi, A.; Etzioni, O.; Malcolm, C. Solving geometry problems: Combining text and diagram interpretation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1466–1476. [Google Scholar]
- Kaliszyk, C.; Urban, J.; Michalewski, H.; Olšák, M. Reinforcement learning of theorem proving. Adv. Neural Inf. Process. Syst. 2018, 31, 8822–8833. [Google Scholar]
- Wu, M.; Norrish, M.; Walder, C.; Dezfouli, A. Tacticzero: Learning to prove theorems from scratch with deep reinforcement learning. Adv. Neural Inf. Process. Syst. 2021, 34, 9330–9342. [Google Scholar]
- Wu, Q.; Zhang, Q.; Huang, X. Automatic math word problem generation with topic-expression co-attention mechanism and reinforcement learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1061–1072. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, D.; Gao, L.; Song, J.; Guo, L.; Shen, H.T. Mathdqn: Solving arithmetic word problems via deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Peng, S.; Fu, D.; Liang, Y.; Gao, L.; Tang, Z. Geodrl: A self-learning framework for geometry problem solving using reinforcement learning in deductive reasoning. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 30 June 2023; pp. 13468–13480. [Google Scholar]
- Kocsis, L.; Szepesvári, C. Bandit based Monte-Carlo planning. In Proceedings of the European Conference on Machine Learning, Berlin, Germany, 18–22 September 2006; pp. 282–293. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 1994. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AR, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Auer, P.; Cesa-Bianchi, N.; Fischer, P. Finite-time analysis of the multiarmed bandit problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Nevins, A.J. Plane geometry theorem proving using forward chaining. Artif. Intell. 1975, 6, 1–23. [Google Scholar] [CrossRef]
- Gelernter, H. Realization of a geometry-theorem proving machine. In Computers & Thought; MIT Press: Cambridge, MA, USA, 1995; pp. 134–152. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson: London, UK, 2016. [Google Scholar]
- Jäntschi, L. Detecting extreme values with order statistics in samples from continuous distributions. Mathematics 2020, 8, 216. [Google Scholar] [CrossRef]
- Gan, W.; Yu, X.; Zhang, T.; Wang, M. Automatically proving plane geometry theorems stated by text and diagram. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1940003. [Google Scholar] [CrossRef]
- Sachan, M.; Dubey, K.; Xing, E. From textbooks to knowledge: A case study in harvesting axiomatic knowledge from textbooks to solve geometry problems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 773–784. [Google Scholar]
- Sachan, M.; Xing, E. Learning to solve geometry problems from natural language demonstrations in textbooks. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (* SEM 2017), Vancouver, Canada, 3–4 August 2017; pp. 251–261. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number | ||||||
|---|---|---|---|---|---|---|---|
| Total | |||||||
| Total | 6981 | 2407 | 1898 | 1247 | 824 | 313 | 292 |
| Angle | 3523 | 1246 | 1160 | 535 | 378 | 127 | 77 |
| Length | 2553 | 918 | 512 | 545 | 321 | 116 | 141 |
| Area | 366 | 106 | 96 | 67 | 44 | 17 | 36 |
| Perimeter | 305 | 22 | 81 | 74 | 56 | 41 | 31 |
| Other | 234 | 115 | 49 | 26 | 25 | 12 | 7 |
| Range | 1 | 3 | 5 | 10 | 15 | 20 | 25 |
|---|---|---|---|---|---|---|---|
| Hit Rate(%) | 49.35 | 72.89 | 81.74 | 89.67 | 93.21 | 94.76 | 95.91 |
| Method | Success Rates (%) | ||||||
|---|---|---|---|---|---|---|---|
| Total | |||||||
| FW-BFS | 38.86 | 59.95 | 38.62 | 28.55 | 17.35 | 8.63 | 3.77 |
| FW-DFS | 36.16 | 55.75 | 40.04 | 22.94 | 12.38 | 7.03 | 4.11 |
| FW-RS | 39.71 | 59.24 | 40.04 | 33.68 | 16.38 | 5.43 | 4.79 |
| FW-BS | 25.28 | 46.12 | 22.60 | 13.47 | 5.83 | 2.88 | 0.34 |
| BW-BFS | 35.44 | 67.22 | 33.72 | 11.15 | 6.67 | 6.07 | 1.03 |
| BW-DFS | 33.73 | 65.93 | 30.82 | 8.90 | 6.55 | 5.11 | 0.68 |
| BW-RS | 34.05 | 66.64 | 31.66 | 8.66 | 5.83 | 4.47 | 0.68 |
| BW-BS | 34.39 | 67.10 | 31.35 | 9.46 | 6.31 | 5.75 | 1.03 |
| PN | 64.40 | 90.46 | 70.18 | 50.93 | 33.20 | 17.02 | 8.05 |
| PN+BS | 70.61 | 95.02 | 78.95 | 60.27 | 34.82 | 22.34 | 11.49 |
| FGeo-DRL | 86.40 | 97.65 | 94.21 | 85.87 | 70.45 | 46.81 | 32.18 |
| Method | Size | Success Rates (%) | ||
|---|---|---|---|---|
| Overall Acc (%) | Avg Time(s) | Avg Steps | ||
| PN | 1 | 40.84 | 0.67 | 2.35 |
| PN | 3 | 55.15 | 3.05 | 3.57 |
| PN | 5 | 63.22 | 3.59 | 3.75 |
| PN + BS | 3 | 61.79 | 3.41 | 3.26 |
| PN + BS | 5 | 70.61 | 3.57 | 3.43 |
| FGeo-DRL | / | 86.40 | / | 3.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, J.; Zhang, X.; He, Y.; Zhu, N.; Leng, T. FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning. Symmetry 2024, 16, 437. https://doi.org/10.3390/sym16040437
Zou J, Zhang X, He Y, Zhu N, Leng T. FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning. Symmetry. 2024; 16(4):437. https://doi.org/10.3390/sym16040437
Chicago/Turabian StyleZou, Jia, Xiaokai Zhang, Yiming He, Na Zhu, and Tuo Leng. 2024. "FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning" Symmetry 16, no. 4: 437. https://doi.org/10.3390/sym16040437
APA StyleZou, J., Zhang, X., He, Y., Zhu, N., & Leng, T. (2024). FGeo-DRL: Deductive Reasoning for Geometric Problems through Deep Reinforcement Learning. Symmetry, 16(4), 437. https://doi.org/10.3390/sym16040437