

A Review of Statistical-Based Fault Detection and Diagnosis with Probabilistic Models


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
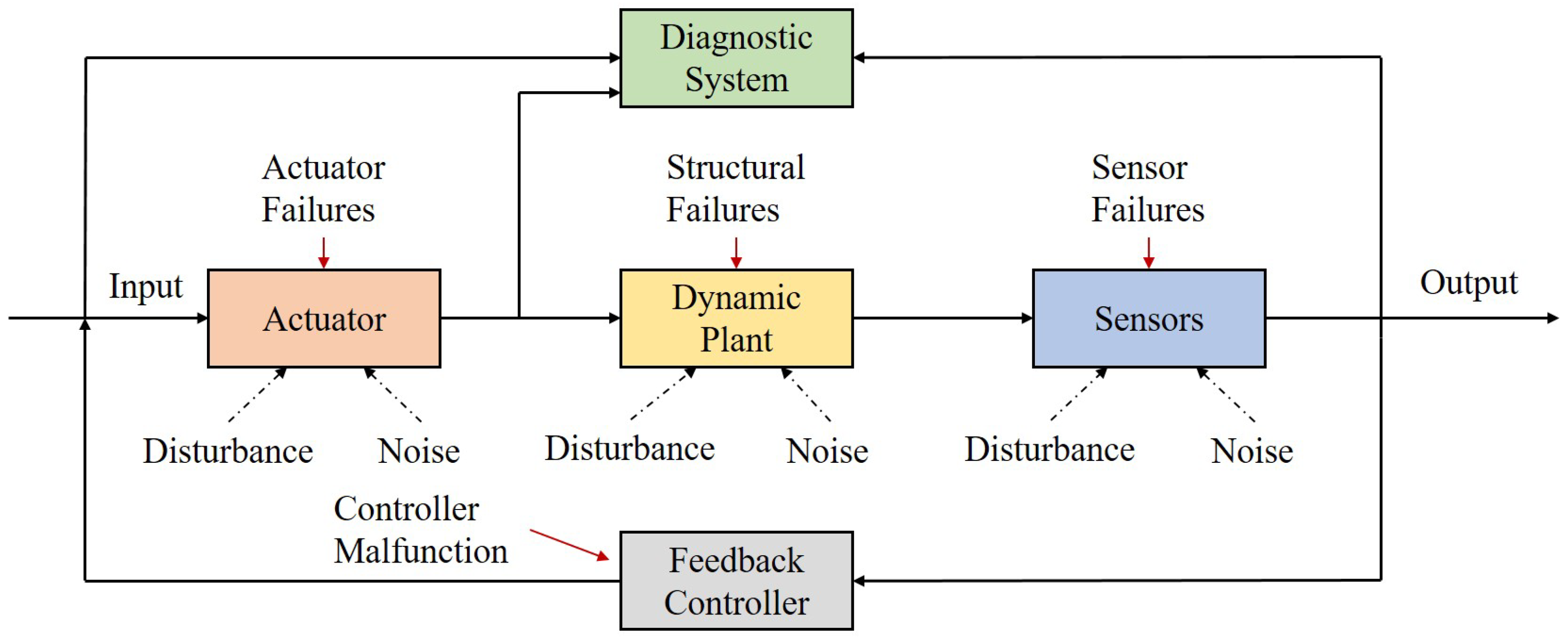
1.1. Background
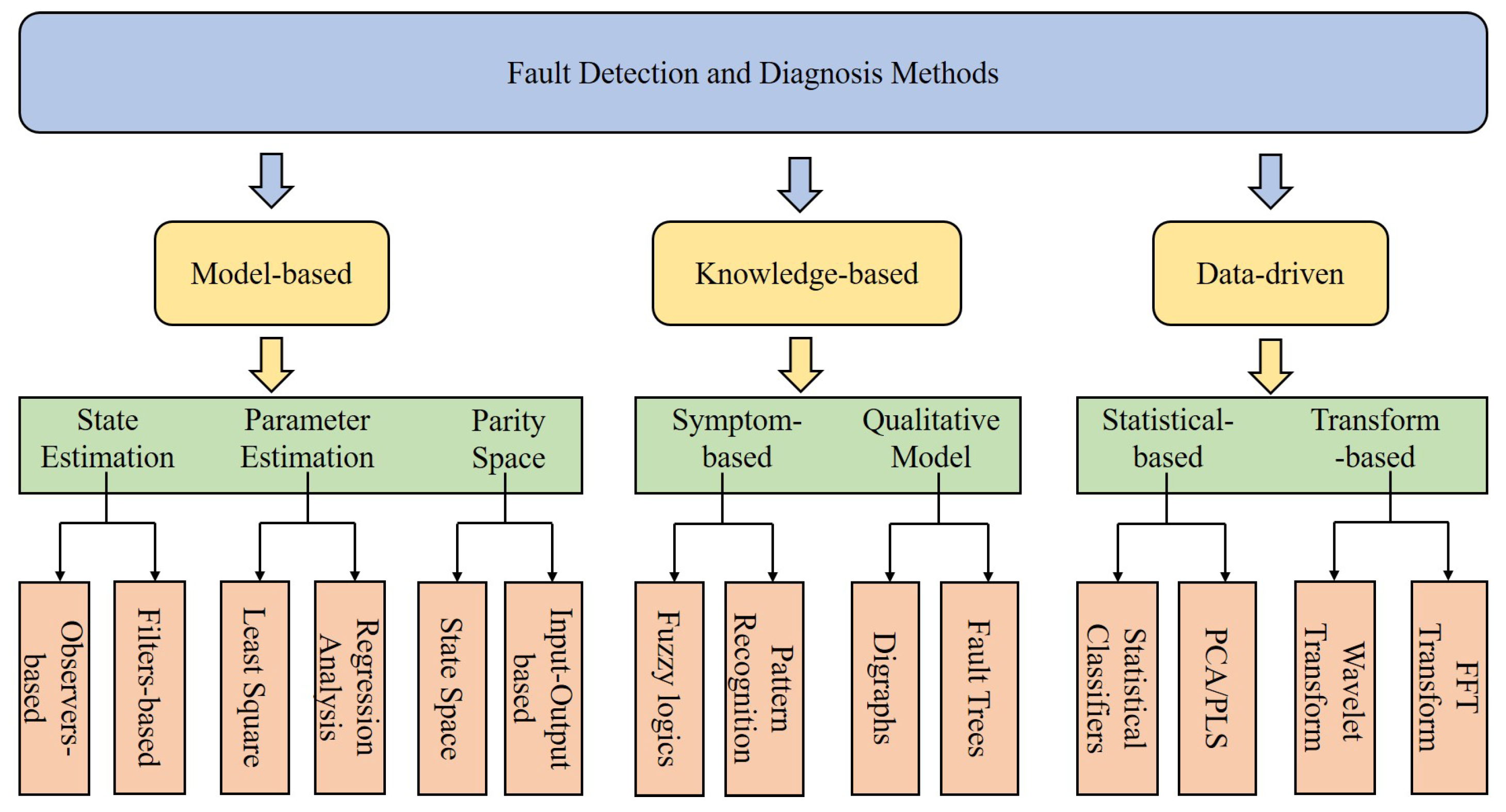
1.2. Evolution of Fault Detection and Diagnosis
1.2.1. Model-Based Methods
1.2.2. Knowledge-Based Methods
1.2.3. Data-Driven Methods
- (1)
- Without a complex model construction, a statistical-based FDD design can extract the information and make decisions directly on the sampling data.
- (2)
- These strategies are designed to address FDD in static or dynamic systems in a stable state with the flexible application of statistical tests and their mixed indices.
1.3. Motivation and Contribution
1.4. Organization of This Paper
2. Theoretic Background
2.1. Maximum Likelihood Estimation
2.2. Bayesian Learning
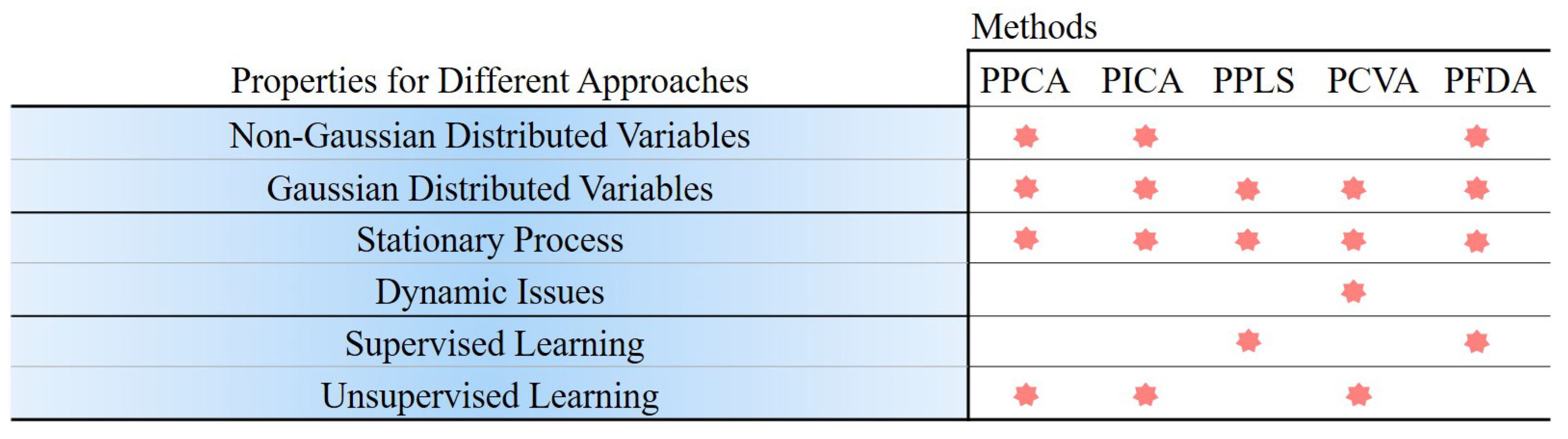
3. Probabilistic Statistical-Based Approaches
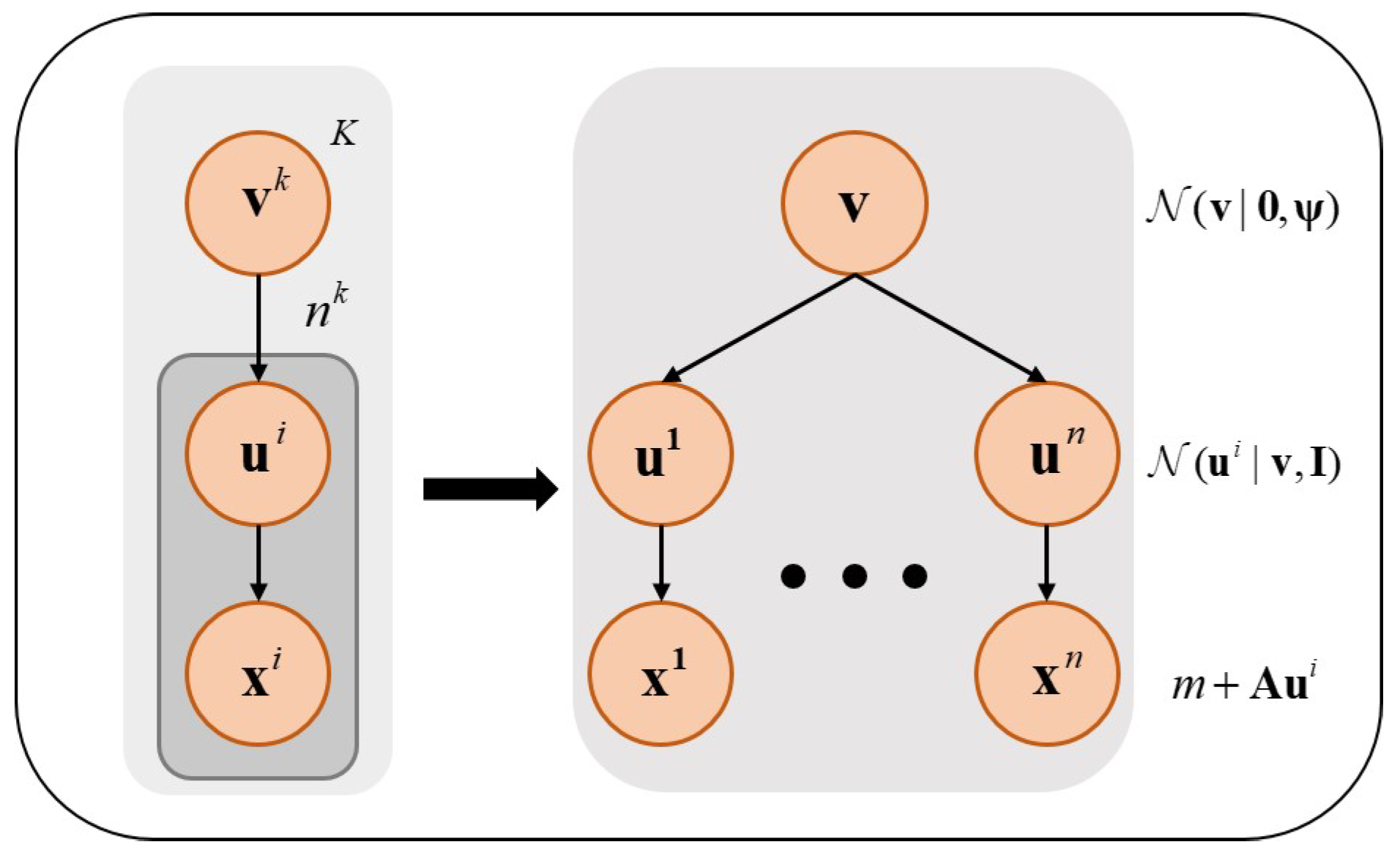
3.1. Probabilistic Principal Component Analysis
- (1)
- Enhanced Robustness: In practical applications, disturbances are unavoidable in a complex working environment. Probabilistic PCA disposes of the problem that sampling data are mixed with outliers and missing values by using distribution modeling of these data and enhancing robustness.
- (2)
- Increased Complex Data: The introduced latent variables enable probabilistic PCA to process non-linear data, improving the performance of dimensional reduction.
- (3)
- Probability Inference: Probabilistic PCA is a dimensionality reduction method based on probability models. It provides quantitative information on uncertainty and probabilistic inferences to obtain more accuracy and effectiveness. Ultimately, the ability to interpret data is substantially intensified.
3.2. Probabilistic Partial Least Squares
3.3. Probabilistic Independent Component Analysis
3.4. Probabilistic Canonical Correlation Analysis
3.5. Probabilistic Fisher Discriminant Analysis
4. Test Statistics
4.1. Test Statistic
4.2. SPE or Q Statistic
4.3. KL Divergence
4.4. Hellinger Distance
5. Recent Applications on Statistical Fault Diagnosis
5.1. Approaches Targeted for Data with Outliers and Missing Values
5.2. Modifications Designed for Non-Gaussian and Nonlinear Processes
5.3. Approaches for Non-Stationary Processes
5.4. Work on Robustness
5.5. Artificial Intelligence Approaches
6. Challenges and Open Problems
6.1. Preprocessing High-Dimensionality Data
6.2. Statistical FD Schemes Developed without Real-Time Ability
6.3. Enhancement on Existing Methods
6.4. Development on Fault Diagnosis
6.5. Processes with Multichannel Data from Multiple Sensors
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ma, C.Y.; Li, Y.B.; Wang, X.Z.; Cai, Z.Q. Early fault diagnosis of rotating machinery based on composite zoom permutation entropy. Reliab. Eng. Syst. Saf. 2023, 230, 108967. [Google Scholar] [CrossRef]
- Tan, H.C.; Xie, S.C.; Ma, W.; Yang, C.X.; Zheng, S.W. Correlation feature distribution matching for fault diagnosis of machines. Reliab. Eng. Syst. Saf. 2023, 231, 108981. [Google Scholar] [CrossRef]
- Xia, P.C.; Huang, Y.X.; Tao, Z.Y.; Liu, C.L.; Liu, J. A digital twin-enhanced semi-supervised framework for motor fault diagnosis based on phase-contrastive current dot pattern. Reliab. Eng. Syst. Saf. 2023, 235, 109256. [Google Scholar] [CrossRef]
- Liu, Z.H.; Chen, L.; Wei, H.L.; Wu, F.M.; Chen, L.; Chen, Y.N. A Tensor-based domain alignment method for intelligent fault diagnosis of rolling bearing in rotating machinery. Reliab. Eng. Syst. Saf. 2023, 230, 108968. [Google Scholar] [CrossRef]
- Lu, L.; Han, X.; Li, J.; Hua, J.; Ouyang, M. A review on the key issues for lithium-ion battery management in electric vehicles. J. Power Sources 2013, 226, 272–288. [Google Scholar] [CrossRef]
- Dong, Y.T.; Jiang, H.K.; Wu, Z.H.; Yang, Q.; Liu, Y.P. Digital twin-assisted multiscale residual-self-attention feature fusion network for hypersonic flight vehicle fault diagnosis. Reliab. Eng. Syst. Saf. 2023, 235, 109253. [Google Scholar] [CrossRef]
- Yuan, Z.X.; Xiong, G.J.; Fu, X.F.; Mohamed, A.W. Improving fault tolerance in diagnosing power system failures with optimal hierarchical extreme learning machine. Reliab. Eng. Syst. Saf. 2023, 236, 109300. [Google Scholar] [CrossRef]
- Choi, U.M.; Blaabjerg, F.; Lee, K.B. Study and handling methods of power IGBT module failures in power electronic converter systems. IEEE Trans. Power Electron. 2014, 30, 2517–2533. [Google Scholar] [CrossRef]
- Song, Y.T.; Wang, B.S. Survey on reliability of power electronic systems. IEEE Trans. Power Electron. 2012, 28, 591–604. [Google Scholar] [CrossRef]
- Riera Guasp, M.; Antonino Daviu, J.A.; Capolino, G.A. Advances in electrical machine, power electronic, and drive condition monitoring and fault detection: State of the art. IEEE Trans. Ind. Electron. 2014, 62, 1746–1759. [Google Scholar] [CrossRef]
- Han, T.; Li, Y.F. Out-of-distribution detection-assisted trustworthy machinery fault diagnosis approach with uncertainty-aware deep ensembles. Reliab. Eng. Syst. Saf. 2022, 226, 108648. [Google Scholar] [CrossRef]
- Zhang, P.J.; Du, Y.; Habetler, T.G.; Lu, B. A survey of condition monitoring and protection methods for medium-voltage induction motors. IEEE Trans. Ind. Appl. 2010, 47, 34–46. [Google Scholar] [CrossRef]
- Jung, J.H.; Lee, J.J.; Kwon, B.H. Online diagnosis of induction motors using MCSA. IEEE Trans. Ind. Electron. 2006, 53, 1842–1852. [Google Scholar] [CrossRef]
- CusidÓCusido, J.; Romeral, L.; Ortega, J.A.; Rosero, J.A.; Espinosa, A.G. Fault detection in induction machines using power spectral density in wavelet decomposition. IEEE Trans. Ind. Electron. 2008, 55, 633–643. [Google Scholar] [CrossRef]
- Hameed, Z.; Hong, Y.S.; Cho, Y.M.; Ahn, S.H.; Song, C.K. Condition monitoring and fault detection of wind turbines and related algorithms: A review. Renew. Sustain. Energy Rev. 2009, 13, 1–39. [Google Scholar] [CrossRef]
- Garcia Marquez, F.P.; Mark Tobias, A.; Pinar Perez, J.M.; Papaelias, M. Condition monitoring of wind turbines: Techniques and methods. Renew. Energy 2012, 46, 169–178. [Google Scholar] [CrossRef]
- Jiang, G.Q.; He, H.B.; Yan, J.; Xie, P. Multiscale convolutional neural networks for fault diagnosis of wind turbine gearbox. IEEE Trans. Ind. Electron. 2018, 66, 3196–3207. [Google Scholar] [CrossRef]
- Zhou, K.L.; Fu, C.; Yang, S.L. Big data driven smart energy management: From big data to big insights. Renew. Sustain. Energy Rev. 2016, 56, 215–225. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.M.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Oppenheimer, C.H.; Loparo, K.A. Physically based diagnosis and prognosis of cracked rotor shafts. In Proceedings of the Component and Systems Diagnostics, Prognostics, and Health Management II, Orlando, FL, USA, 1–5 April 2002; Volume 4733, pp. 122–132. [Google Scholar]
- Zhu, Y.T.; Zhao, S.Y.; Zhang, C.X.; Liu, F. Tuning-free filtering for stochastic systems with unmodeled measurement dynamics. J. Frankl. Inst. 2023, 361, 933–943. [Google Scholar] [CrossRef]
- Asadi, D. Actuator Fault detection, identification, and control of a multirotor air vehicle using residual generation and parameter estimation approaches. Int. J. Aeronaut. Space Sci. 2023, 25, 176–189. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Li, Y.Y.; Zhang, C.X.; Luan, X.L.; Liu, F.; Tan, R.M. Robustification of Finite Impulse Response Filter for Nonlinear Systems With Model Uncertainties. IEEE Trans. Instrum. Meas. 2023, 72, 6506109. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Zhou, Z.; Zhang, C.X.; Wu, J.; Liu, F.; Shi, G.Y. Localization of underground pipe jacking machinery: A reliable, real-time and robust INS/OD solution. Control Eng. Pract. 2023, 141, 105711. [Google Scholar] [CrossRef]
- Gao, Z.W.; Cecati, C.; Ding, S.X. A Survey of Fault Diagnosis and Fault-Tolerant Techniques-Part II: Fault Diagnosis with Knowledge-Based and Hybrid/Active Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Ding, S.X. Data-driven design of monitoring and diagnosis systems for dynamic processes: A review of subspace technique based schemes and some recent results. J. Process Control 2014, 24, 431–449. [Google Scholar] [CrossRef]
- Yu, X.L.; Zhao, Z.B.; Zhang, X.W.; Chen, X.F.; Cai, J.B. Statistical identification guided open-set domain adaptation in fault diagnosis. Reliab. Eng. Syst. Saf. 2023, 232, 109047. [Google Scholar] [CrossRef]
- Joe Qin, S. Statistical process monitoring: Basics and beyond. J. Chemom. J. Chemom. Soc. 2003, 17, 480–502. [Google Scholar] [CrossRef]
- Malhi, A.; Gao, R.X. PCA-based feature selection scheme for machine defect classification. IEEE Trans. Instrum. Meas. 2004, 53, 1517–1525. [Google Scholar] [CrossRef]
- Choqueuse, V.; Benbouzid, M.E.H.; Amirat, Y.; Turri, S. Diagnosis of three-phase electrical machines using multidimensional demodulation techniques. IEEE Trans. Ind. Electron. 2011, 59, 2014–2023. [Google Scholar] [CrossRef]
- Misra, M.; Yue, H.H.; Qin, S.J.; Ling, C. Multivariate process monitoring and fault diagnosis by multi-scale PCA. Comput. Chem. Eng. 2002, 26, 1281–1293. [Google Scholar] [CrossRef]
- Vong, C.M.; Wong, P.K.; Ip, W.F. A new framework of simultaneous-fault diagnosis using pairwise probabilistic multi-label classification for time-dependent patterns. IEEE Trans. Ind. Electron. 2012, 60, 3372–3385. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Zhou, D.H. Geometric properties of partial least squares for process monitoring. Automatica 2010, 46, 204–210. [Google Scholar] [CrossRef]
- Zhang, Y.W.; Zhou, H.; Qin, S.J.; Chai, T.Y. Decentralized fault diagnosis of large-scale processes using multiblock kernel partial least squares. IEEE Trans. Ind. Inf. 2009, 6, 3–10. [Google Scholar] [CrossRef]
- Muradore, R.; Fiorini, P. A PLS-based statistical approach for fault detection and isolation of robotic manipulators. IEEE Trans. Ind. Electron. 2011, 59, 3167–3175. [Google Scholar] [CrossRef]
- He, X.; Wang, Z.D.; Liu, Y.; Zhou, D.H. Least-squares fault detection and diagnosis for networked sensing systems using a direct state estimation approach. IEEE Trans. Ind. Inf. 2013, 9, 1670–1679. [Google Scholar] [CrossRef]
- Kim, D.S.; Lee, I.B. Process monitoring based on probabilistic PCA. Chemom. Intell. Lab. Syst. 2003, 67, 109–123. [Google Scholar] [CrossRef]
- Kim, D.S.; Yoo, C.K.; Kim, Y.I.; Jung, J.H.; Lee, I.B. Calibration, prediction and process monitoring model based on factor analysis for incomplete process data. J. Chem. Eng. Jpn. 2005, 38, 1025–1034. [Google Scholar] [CrossRef]
- Choi, S.W.; Martin, E.B.; Morris, A.J.; Lee, I.B. Fault detection based on a maximum-likelihood principal component analysis (PCA) mixture. Ind. Eng. Chem. Res. 2005, 44, 2316–2327. [Google Scholar] [CrossRef]
- Abid, A.; Khan, M.T.; Iqbal, J. A review on fault detection and diagnosis techniques: Basics and beyond. Artif. Intell. Rev. 2021, 54, 3639–3664. [Google Scholar] [CrossRef]
- Chen, J.L.; Zhang, L.; Li, Y.F.; Shi, Y.F.; Gao, X.H.; Hu, Y.Q. A review of computing-based automated fault detection and diagnosis of heating, ventilation and air conditioning systems. Renew. Sustain. Energy Rev. 2022, 161, 112395. [Google Scholar] [CrossRef]
- Yu, J.B.; Zhang, Y. Challenges and opportunities of deep learning-based process fault detection and diagnosis: A review. Neural Comput. Appl. 2023, 35, 211–252. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Si, X.S.; Wang, W.B.; Hu, C.H.; Zhou, D.H.; Pecht, M.G. Remaining useful life estimation based on a nonlinear diffusion degradation process. IEEE Trans. Reliab. 2012, 61, 50–67. [Google Scholar] [CrossRef]
- Excoffier, L.; Slatkin, M. Maximum-likelihood estimation of molecular haplotype frequencies in a diploid population. Mol. Biol. Evol. 1995, 12, 921–927. [Google Scholar] [PubMed]
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Li, K.; Ahn, C.K.; Huang, B.; Liu, F. Tuning-Free Bayesian Estimation Algorithms for Faulty Sensor Signals in State-Space. IEEE Trans. Ind. Electron. 2022, 70, 921–929. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Huang, B.; Zhao, C.H. Online probabilistic estimation of sensor faulty signal in industrial processes and its applications. IEEE Trans. Ind. Electron. 2020, 68, 8853–8862. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Shmaliy, Y.S.; Ahn, C.K.; Zhao, C.H. Probabilistic monitoring of correlated sensors for nonlinear processes in state space. IEEE Trans. Ind. Electron. 2019, 67, 2294–2303. [Google Scholar] [CrossRef]
- Lo, C.H.; Wong, Y.K.; Rad, A.B. Bond graph based Bayesian network for fault diagnosis. Appl. Soft Comput. 2011, 11, 1208–1212. [Google Scholar] [CrossRef]
- Boudali, H.; Dugan, J.B. A discrete-time Bayesian network reliability modeling and analysis framework. Reliab. Eng. Syst. Saf. 2005, 87, 337–349. [Google Scholar] [CrossRef]
- Cai, B.P.; Huang, L.; Xie, M. Bayesian networks in fault diagnosis. IEEE Trans. Ind. Inf. 2017, 13, 2227–2240. [Google Scholar] [CrossRef]
- Cai, B.P.; Liu, H.L.; Xie, M. A real-time fault diagnosis methodology of complex systems using object-oriented Bayesian networks. Mech. Syst. Signal Process. 2016, 80, 31–44. [Google Scholar] [CrossRef]
- Cai, B.P.; Liu, Y.; Xie, M. A dynamic-Bayesian-network-based fault diagnosis methodology considering transient and intermittent faults. IEEE Trans. Autom. Sci. Eng. 2016, 14, 276–285. [Google Scholar] [CrossRef]
- Trucco, P.; Cagno, E.; Ruggeri, F.; Grande, O. A Bayesian Belief Network modelling of organisational factors in risk analysis: A case study in maritime transportation. Reliab. Eng. Syst. Saf. 2008, 93, 845–856. [Google Scholar] [CrossRef]
- Langseth, H.; Portinale, L. Bayesian networks in reliability. Reliab. Eng. Syst. Saf. 2007, 92, 92–108. [Google Scholar] [CrossRef]
- Khakzad, N.; Khan, F.; Amyotte, P. Safety analysis in process facilities: Comparison of fault tree and Bayesian network approaches. Reliab. Eng. Syst. Saf. 2011, 96, 925–932. [Google Scholar] [CrossRef]
- O’Hagan, A. Bayesian analysis of computer code outputs: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 1290–1300. [Google Scholar] [CrossRef]
- Bobbio, A.; Portinale, L.; Minichino, M.; Ciancamerla, E. Improving the analysis of dependable systems by mapping fault trees into Bayesian networks. Reliab. Eng. Syst. Saf. 2001, 71, 249–260. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Yan, X.F.; Huang, B. Performance-driven distributed PCA process monitoring based on fault-relevant variable selection and Bayesian inference. IEEE Trans. Ind. Electron. 2015, 63, 377–386. [Google Scholar] [CrossRef]
- Da Silva, A.M.; Povinelli, R.J.; Demerdash, N.A. Induction machine broken bar and stator short-circuit fault diagnostics based on three-phase stator current envelopes. IEEE Trans. Ind. Electron. 2008, 55, 1310–1318. [Google Scholar] [CrossRef]
- Zhou, T.T.; Zhang, L.B.; Han, T.; Droguett, E.L.; Mosleh, A.; Chan, F.T. An uncertainty-informed framework for trustworthy fault diagnosis in safety-critical applications. Reliab. Eng. Syst. Saf. 2023, 229, 108865. [Google Scholar] [CrossRef]
- Zhou, T.T.; Han, T.; Droguett, E.L. Towards trustworthy machine fault diagnosis: A probabilistic Bayesian deep learning framework. Reliab. Eng. Syst. Saf. 2022, 224, 108525. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Silva, V.D.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Zhang, D.; Frangi, A.F.; Yang, J.Y. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. B Stat. Methodol. 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Kariwala, V.; Odiowei, P.E.; Cao, Y.; Chen, T. A branch and bound method for isolation of faulty variables through missing variable analysis. J. Process Control 2010, 20, 1198–1206. [Google Scholar] [CrossRef]
- Yang, Y.W.; Ma, Y.X.; Song, B.; Shi, H.B. An aligned mixture probabilistic principal component analysis for fault detection of multimode chemical processes. Chin. J. Chem. Eng. 2015, 23, 1357–1363. [Google Scholar] [CrossRef]
- He, B.; Yang, X.H.; Chen, T.; Zhang, J. Reconstruction-based multivariate contribution analysis for fault isolation: A branch and bound approach. J. Process Control 2012, 22, 1228–1236. [Google Scholar] [CrossRef]
- Zhu, J.L.; Ge, Z.Q.; Song, Z.H. Robust modeling of mixture probabilistic principal component analysis and process monitoring application. AlChE J. 2014, 60, 2143–2157. [Google Scholar] [CrossRef]
- Ge, Z.Q.; Song, Z.H. Robust monitoring and fault reconstruction based on variational inference component analysis. J. Process Control 2011, 21, 462–474. [Google Scholar] [CrossRef]
- Zhu, J.L.; Ge, Z.Q.; Song, Z.H. Dynamic mixture probabilistic PCA classifier modeling and application for fault classification. J. Chemom. 2015, 29, 361–370. [Google Scholar] [CrossRef]
- Zhu, J.L.; Ge, Z.Q.; Song, Z.H. HMM-driven robust probabilistic principal component analyzer for dynamic process fault classification. IEEE Trans. Ind. Electron. 2015, 62, 3814–3821. [Google Scholar] [CrossRef]
- de Andrade Melani, A.H.; de Carvalho Michalski, M.A.; da Silva, R.F.; de Souza, G.F.M. A framework to automate fault detection and diagnosis based on moving window principal component analysis and Bayesian network. Reliab. Eng. Syst. Saf. 2021, 215, 107837. [Google Scholar] [CrossRef]
- Zheng, J.H.; Song, Z.H.; Ge, Z.Q. Probabilistic learning of partial least squares regression model: Theory and industrial applications. Chemom. Intell. Lab. Syst. 2016, 158, 80–90. [Google Scholar] [CrossRef]
- Pérez, N.F.; Ferré, J.; Boqué, R. Calculation of the reliability of classification in discriminant partial least-squares binary classification. Chemom. Intell. Lab. Syst. 2009, 95, 122–128. [Google Scholar] [CrossRef]
- Zheng, J.H.; Song, Z.H. Semisupervised learning for probabilistic partial least squares regression model and soft sensor application. J. Process Control 2018, 64, 123–131. [Google Scholar] [CrossRef]
- Xie, Y. Fault monitoring based on locally weighted probabilistic kernel partial least square for nonlinear time-varying processes. J. Chemom. 2019, 33, e3196. [Google Scholar] [CrossRef]
- Botella, C.; Ferré, J.; Boqué, R. Classification from microarray data using probabilistic discriminant partial least squares with reject option. Talanta 2009, 80, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.H.; Pan, F.; Zhao, Z.G. Concurrent probabilistic PLS regression model and its applications in process monitoring. Chemom. Intell. Lab. Syst. 2017, 171, 40–54. [Google Scholar] [CrossRef]
- Beckmann, C.F.; Smith, S.M. Probabilistic independent component analysis for functional magnetic resonance imaging. IEEE Trans. Med. Imaging 2004, 23, 137–152. [Google Scholar] [CrossRef] [PubMed]
- Bach, F.R.; Jordan, M.I. A Probabilistic Interpretation of Canonical Correlation Analysis; Technical Report; University of California Berkeley: Berkeley, CA, USA, 2005. [Google Scholar]
- He, X.F.; Yan, S.C.; Hu, Y.X.; Niyogi, P.; Zhang, H.J. Face recognition using laplacianfaces. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 328–340. [Google Scholar]
- Yu, H.; Yang, J. A direct LDA algorithm for high-dimensional data—With application to face recognition. Pattern Recognit. 2001, 34, 2067–2070. [Google Scholar] [CrossRef]
- Chen, L.F.; Liao, H.Y.M.; Ko, M.T.; Lin, J.C.; Yu, G.J. A new LDA-based face recognition system which can solve the small sample size problem. Pattern Recognit. 2000, 33, 1713–1726. [Google Scholar] [CrossRef]
- Sugiyama, M. Dimensionality reduction of multimodal labeled data by local Fisher discriminant analysis. J. Mach. Learn. Res. 2007, 8, 1027–1061. [Google Scholar]
- Liu, J.; Xu, H.T.; Peng, X.Y.; Wang, J.L.; He, C.M. Reliable composite fault diagnosis of hydraulic systems based on linear discriminant analysis and multi-output hybrid kernel extreme learning machine. Reliab. Eng. Syst. Saf. 2023, 234, 109178. [Google Scholar] [CrossRef]
- Bouveyron, C.; Brunet, C. Probabilistic Fisher discriminant analysis: A robust and flexible alternative to Fisher discriminant analysis. Neurocomputing 2012, 90, 12–22. [Google Scholar] [CrossRef]
- Xie, L.; Zeng, J.S.; Kruger, U.; Wang, X.; Geluk, J. Fault detection in dynamic systems using the Kullback–Leibler divergence. Control Eng. Pract. 2015, 43, 39–48. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Lu, N.Y. An improved incipient fault detection method based on Kullback-Leibler divergence. ISA Trans. 2018, 79, 127–136. [Google Scholar] [CrossRef] [PubMed]
- Beran, R. Minimum Hellinger distance estimates for parametric models. Ann. Stat. 1977, 445–463. [Google Scholar] [CrossRef]
- Jiang, Q.C.; Wang, B.; Yan, X.F. Multiblock independent component analysis integrated with Hellinger distance and Bayesian inference for non-Gaussian plant-wide process monitoring. Ind. Eng. Chem. Res. 2015, 54, 2497–2508. [Google Scholar] [CrossRef]
- Palmer, K.A.; Bollas, G.M. Sensor selection embedded in active fault diagnosis algorithms. IEEE Trans. Control Syst. Technol. 2019, 29, 593–606. [Google Scholar] [CrossRef]
- Chen, H.T.; Jiang, B.; Lu, N.Y. A newly robust fault detection and diagnosis method for high-speed trains. IEEE Trans. Intell. Transp. Syst. 2018, 20, 2198–2208. [Google Scholar] [CrossRef]
- Barnett, V.; Lewis, T. Outliers in Statistical Data; Wiley: New York, NY, USA, 1994; Volume 3. [Google Scholar]
- Zhu, J.L.; Ge, Z.Q.; Song, Z.H.; Gao, F.F. Review and big data perspectives on robust data mining approaches for industrial process modeling with outliers and missing data. Annu. Rev. Control 2018, 46, 107–133. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.X.; Xie, X.C.; Luo, H. A review on basic data-driven approaches for industrial process monitoring. IEEE Trans. Ind. Electron. 2014, 61, 6418–6428. [Google Scholar] [CrossRef]
- Ding, S.X. Data-Driven Design of Fault Diagnosis and Fault-Tolerant Control Systems; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Chen, H.T.; Jiang, B.; Ding, S.X.; Huang, B. Data-driven fault diagnosis for traction systems in high-speed trains: A survey, challenges, and perspectives. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1700–1716. [Google Scholar] [CrossRef]
- Wang, G.Z.; Liu, J.C.; Zhang, Y.W.; Li, Y. A novel multi-mode data processing method and its application in industrial process monitoring. J. Chemom. 2015, 29, 126–138. [Google Scholar] [CrossRef]
- Bakdi, A.; Kouadri, A.; Mekhilef, S. A data-driven algorithm for online detection of component and system faults in modern wind turbines at different operating zones. Renew. Sustain. Energy Rev. 2019, 103, 546–555. [Google Scholar] [CrossRef]
- Zhou, J.L.; Zhang, S.L.; Wang, J. A dual robustness projection to latent structure method and its application. IEEE Trans. Ind. Electron. 2020, 68, 1604–1614. [Google Scholar] [CrossRef]
- Ma, Z.; Luo, Y.Z.; Yun, C.B.; Wan, H.P.; Shen, Y.B. An MPPCA-based approach for anomaly detection of structures under multiple operational conditions and missing data. Struct. Health Monit. 2023, 22, 1069–1089. [Google Scholar] [CrossRef]
- Jin, X.H.; Zhao, M.B.; Chow, T.W.; Pecht, M. Motor bearing fault diagnosis using trace ratio linear discriminant analysis. IEEE Trans. Ind. Electron. 2013, 61, 2441–2451. [Google Scholar] [CrossRef]
- Chen, Z.W.; Ding, S.X.; Peng, T.; Yang, C.H.; Gui, W.H. Fault detection for non-Gaussian processes using generalized canonical correlation analysis and randomized algorithms. IEEE Trans. Ind. Electron. 2017, 65, 1559–1567. [Google Scholar] [CrossRef]
- Ge, Z.Q.; Song, Z.H.; Gao, F.R. Review of recent research on data-based process monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Li, R.F.; Wang, X.Z. Dimension reduction of process dynamic trends using independent component analysis. Comput. Chem. Eng. 2002, 26, 467–473. [Google Scholar] [CrossRef]
- Kano, M.; Tanaka, S.; Hasebe, S.; Hashimoto, I.; Ohno, H. Monitoring independent components for fault detection. AlChE J. 2003, 49, 969–976. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B. A review of fault detection and diagnosis for the traction system in high-speed trains. IEEE Trans. Intell. Transp. Syst. 2019, 21, 450–465. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Z.; Alippi, C.; Huang, B.; Liu, D. Explainable intelligent fault diagnosis for nonlinear dynamic systems: From unsupervised to supervised learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Chiang, L.H.; Russell, E.L.; Braatz, R.D. Fault Detection and Diagnosis in Industrial Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Bach, F. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Chiang, L.H.; Kotanchek, M.E.; Kordon, A.K. Fault diagnosis based on Fisher discriminant analysis and support vector machines. Comput. Chem. Eng. 2004, 28, 1389–1401. [Google Scholar] [CrossRef]
- Chan, K.; Lee, T.W.; Sejnowski, T.J. Variational Bayesian learning of ICA with missing data. Neural Comput. 2003, 15, 1991–2011. [Google Scholar] [CrossRef]
- Salazar, A.; Vergara, L.; Serrano, A.; Igual, J. A general procedure for learning mixtures of independent component analyzers. Pattern Recognit. 2010, 43, 69–85. [Google Scholar] [CrossRef]
- Lawrence, N.; Hyvärinen, A. Probabilistic non-linear principal component analysis with Gaussian process latent variable models. J. Mach. Learn. Res. 2005, 6, 1783–1816. [Google Scholar]
- Ge, Z.Q.; Song, Z.H. Nonlinear probabilistic monitoring based on the Gaussian process latent variable model. Ind. Eng. Chem. Res. 2010, 49, 4792–4799. [Google Scholar] [CrossRef]
- Li, X.; Li, Y.; Yan, K.; Shao, H.D.; Lin, J.J. Intelligent fault diagnosis of bevel gearboxes using semi-supervised probability support matrix machine and infrared imaging. Reliab. Eng. Syst. Saf. 2023, 230, 108921. [Google Scholar] [CrossRef]
- Guo, J.; Wang, X.; Li, Y.; Wang, G.Z. Fault detection based on weighted difference principal component analysis. J. Chemom. 2017, 31, e2926. [Google Scholar] [CrossRef]
- Pilario, K.E.S.; Cao, Y. Canonical variate dissimilarity analysis for process incipient fault detection. IEEE Trans. Ind. Inform. 2018, 14, 5308–5315. [Google Scholar] [CrossRef]
- Kulkarni, S.G.; Chaudhary, A.K.; Nandi, S.; Tambe, S.S.; Kulkarni, B.D. Modeling and monitoring of batch processes using principal component analysis (PCA) assisted generalized regression neural networks (GRNN). Biochem. Eng. J. 2004, 18, 193–210. [Google Scholar] [CrossRef]
- Roweis, S.; Ghahramani, Z. A unifying review of linear Gaussian models. Neural Comput. 1999, 11, 305–345. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Shmaliy, Y.S.; Liu, F. Batch Optimal FIR Smoothing: Increasing State Informativity in Nonwhite Measurement Noise Environments. IEEE Trans. Ind. Inf. 2022. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Wang, J.F.; Shmaliy, Y.S.; Liu, F. Discrete Time q-Lag Maximum Likelihood FIR Smoothing and Iterative Recursive Algorithm. IEEE Trans. Signal Process. 2021, 69, 6342–6354. [Google Scholar] [CrossRef]
- Zhang, T.Y.; Zhao, S.Y.; Luan, X.L.; Liu, F. Bayesian Inference for State-Space Models with Student-t Mixture Distributions. IEEE Trans. Cybern. 2022, 4435–4445. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.Y.; Huang, B. Trial-and-error or avoiding a guess? Initialization of the Kalman filter. Automatica 2020, 121, 109184. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Shmaliy, Y.S.; Andrade-Lucio, J.A.; Liu, F. Multipass optimal FIR filtering for processes with unknown initial states and temporary mismatches. IEEE Trans. Ind. Inf. 2020, 17, 5360–5368. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Shmaliy, Y.S.; Ahn, C.K.; Liu, F. Self-tuning unbiased finite impulse response filtering algorithm for processes with unknown measurement noise covariance. IEEE Trans. Control Syst. Technol. 2020, 29, 1372–1379. [Google Scholar] [CrossRef]
- Lee, J.M.; Yoo, C.K.; Lee, I.B. Statistical monitoring of dynamic processes based on dynamic independent component analysis. Chem. Eng. Sci. 2004, 59, 2995–3006. [Google Scholar] [CrossRef]
- Zhang, Y.W. Enhanced statistical analysis of nonlinear processes using KPCA, KICA and SVM. Chem. Eng. Sci. 2009, 64, 801–811. [Google Scholar] [CrossRef]
- Hubert, M.; Rousseeuw, P.J.; Vanden Branden, K. ROBPCA: A new approach to robust principal component analysis. Technometrics 2005, 47, 64–79. [Google Scholar] [CrossRef]
- Li, G.Y.; Chen, Z.L. Projection-pursuit approach to robust dispersion matrices and principal components: Primary theory and Monte Carlo. J. Am. Stat. Assoc. 1985, 80, 759–766. [Google Scholar] [CrossRef]
- Xie, Y.L.; Wang, J.H.; Liang, Y.Z.; Sun, L.X.; Song, X.H.; Yu, R.Q. Robust principal component analysis by projection pursuit. J. Chemom. 1993, 7, 527–541. [Google Scholar] [CrossRef]
- Hubert, M.; Rousseeuw, P.J.; Verboven, S. A fast method for robust principal components with applications to chemometrics. Chemom. Intell. Lab. Syst. 2002, 60, 101–111. [Google Scholar] [CrossRef]
- Croux, C.; Ruiz Gazen, A. High breakdown estimators for principal components: The projection-pursuit approach revisited. J. Multivar. Anal. 2005, 95, 206–226. [Google Scholar] [CrossRef]
- Ding, X.H.; He, L.H.; Carin, L. Bayesian robust principal component analysis. IEEE Trans. Image Process. 2011, 20, 3419–3430. [Google Scholar] [CrossRef] [PubMed]
- Luttinen, J.; Ilin, A.; Karhunen, J. Bayesian robust PCA of incomplete data. Neural Process. Lett. 2012, 36, 189–202. [Google Scholar] [CrossRef]
- Gao, J.B. Robust L1 principal component analysis and its Bayesian variational inference. Neural Comput. 2008, 20, 555–572. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Martin, E.; Montague, G. Robust probabilistic PCA with missing data and contribution analysis for outlier detection. Comput. Stat. Data Anal. 2009, 53, 3706–3716. [Google Scholar] [CrossRef]
- Chen, H.; Luo, H.; Huang, B.; Jiang, B.; Kaynak, O. Transfer Learning-motivated Intelligent Fault Diagnosis Designs: A Survey, Insights, and Perspectives. IEEE Trans. Neural Netw. Learn. Syst. 2022, 2969–2983. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Huang, B. Fault-tolerant soft sensors for dynamic systems. IEEE Trans. Control. Syst. Technol. 2022, 2805–2818. [Google Scholar] [CrossRef]
- Su, H.; Chong, K.T. Induction machine condition monitoring using neural network modeling. IEEE Trans. Ind. Electron. 2007, 54, 241–249. [Google Scholar] [CrossRef]
- Li, C.J.; Huang, T.Y. Automatic structure and parameter training methods for modeling of mechanical systems by recurrent neural networks. Appl. Math. Modell. 1999, 23, 933–944. [Google Scholar]
- Deuszkiewicz, P.; Radkowski, S. On-line condition monitoring of a power transmission unit of a rail vehicle. Mech. Syst. Signal Process. 2003, 17, 1321–1334. [Google Scholar] [CrossRef]
- Bai, R.X.; Meng, Z.; Xu, Q.S.; Fan, F.J. Fractional Fourier and time domain recurrence plot fusion combining convolutional neural network for bearing fault diagnosis under variable working conditions. Reliab. Eng. Syst. Saf. 2023, 232, 109076. [Google Scholar] [CrossRef]
- Wang, H.; Li, Y.F. Bioinspired membrane learnable spiking neural network for autonomous vehicle sensors fault diagnosis under open environments. Reliab. Eng. Syst. Saf. 2023, 233, 109102. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Zhao, S.; Zhang, Y.; Zhang, C.; Wu, J. A Review of Statistical-Based Fault Detection and Diagnosis with Probabilistic Models. Symmetry 2024, 16, 455. https://doi.org/10.3390/sym16040455
Zhu Y, Zhao S, Zhang Y, Zhang C, Wu J. A Review of Statistical-Based Fault Detection and Diagnosis with Probabilistic Models. Symmetry. 2024; 16(4):455. https://doi.org/10.3390/sym16040455
Chicago/Turabian StyleZhu, Yanting, Shunyi Zhao, Yuxuan Zhang, Chengxi Zhang, and Jin Wu. 2024. "A Review of Statistical-Based Fault Detection and Diagnosis with Probabilistic Models" Symmetry 16, no. 4: 455. https://doi.org/10.3390/sym16040455
APA StyleZhu, Y., Zhao, S., Zhang, Y., Zhang, C., & Wu, J. (2024). A Review of Statistical-Based Fault Detection and Diagnosis with Probabilistic Models. Symmetry, 16(4), 455. https://doi.org/10.3390/sym16040455