
Extended Deep-Learning Network for Histopathological Image-Based Multiclass Breast Cancer Classification Using Residual Features


Abstract
:1. Introduction
- Mammography: Mammography is an X-ray imaging technique used to examine breast tissue.
- Ultrasound: Ultrasound imaging uses high-frequency sound waves to produce images of the breast tissue.
- Magnetic resonance imaging (MRI): MRI is a noninvasive imaging technique that uses powerful magnetic fields and radio waves to produce detailed images of breast tissue.
- Histopathological images: Histopathological images involve examining tissue samples from a patient’s breast to identify the presence of cancerous cells.
- A residual feature that represents spatial features from the present layers is integrated with the spatial features of previous layers. The retention of residual features before integrating them with the features of previous layers helps us better learn texture classification [5].
- A complete framework integrating learnable residual features with a pretrained DenseNet161 network is presented for histopathological image classification. An experimental evaluation using binary classification and multiclass classification is presented.
- A state-of-the-art comparison with other residual and CNN networks classifying benign and malignant images and malignant image subclass categorization for the benchmark dataset used is presented.
2. Related Work
3. Proposed Method
3.1. Residual Feature Extraction
3.2. Concatenation of Global Spatial Features and Residual Features
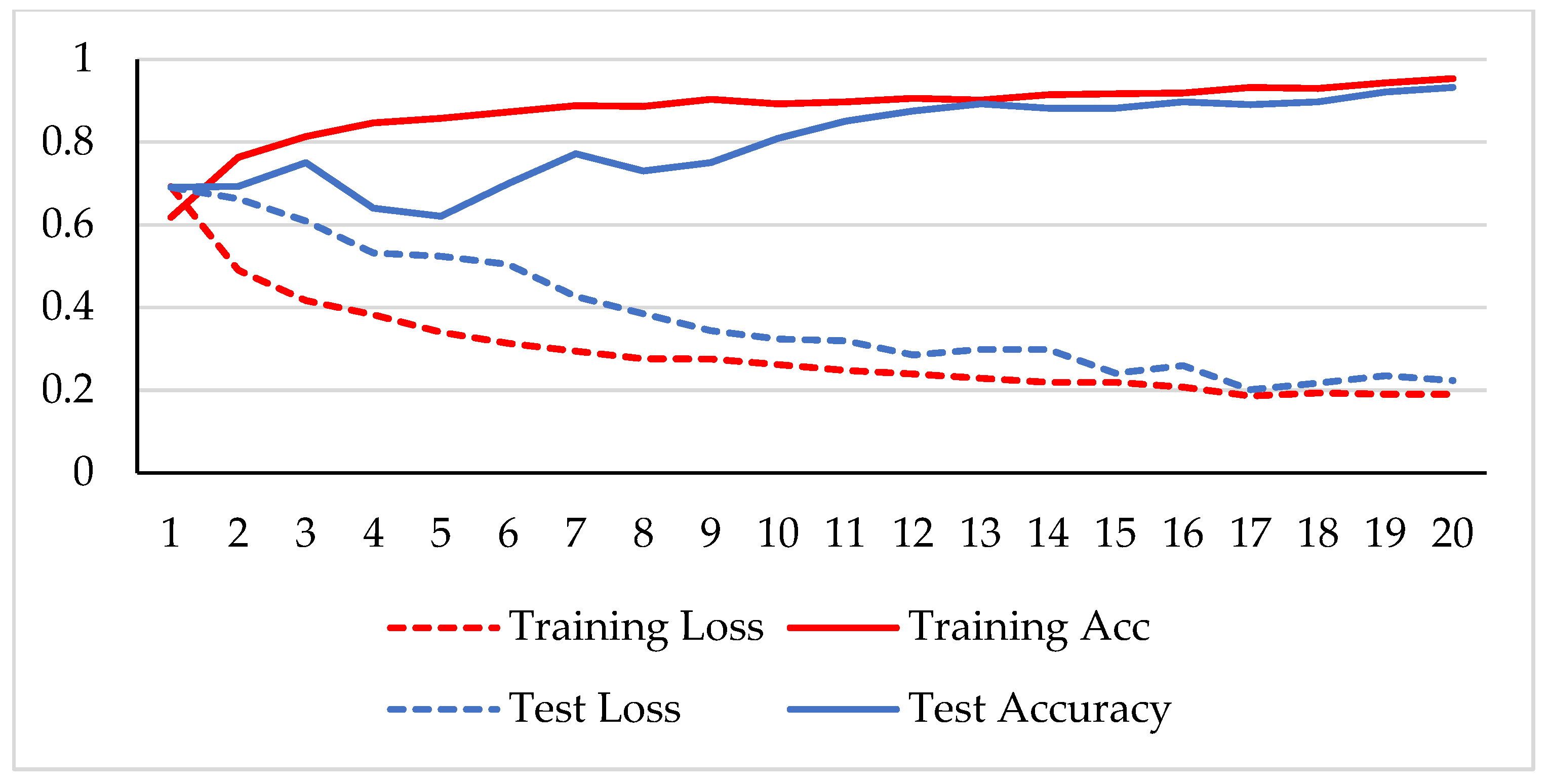
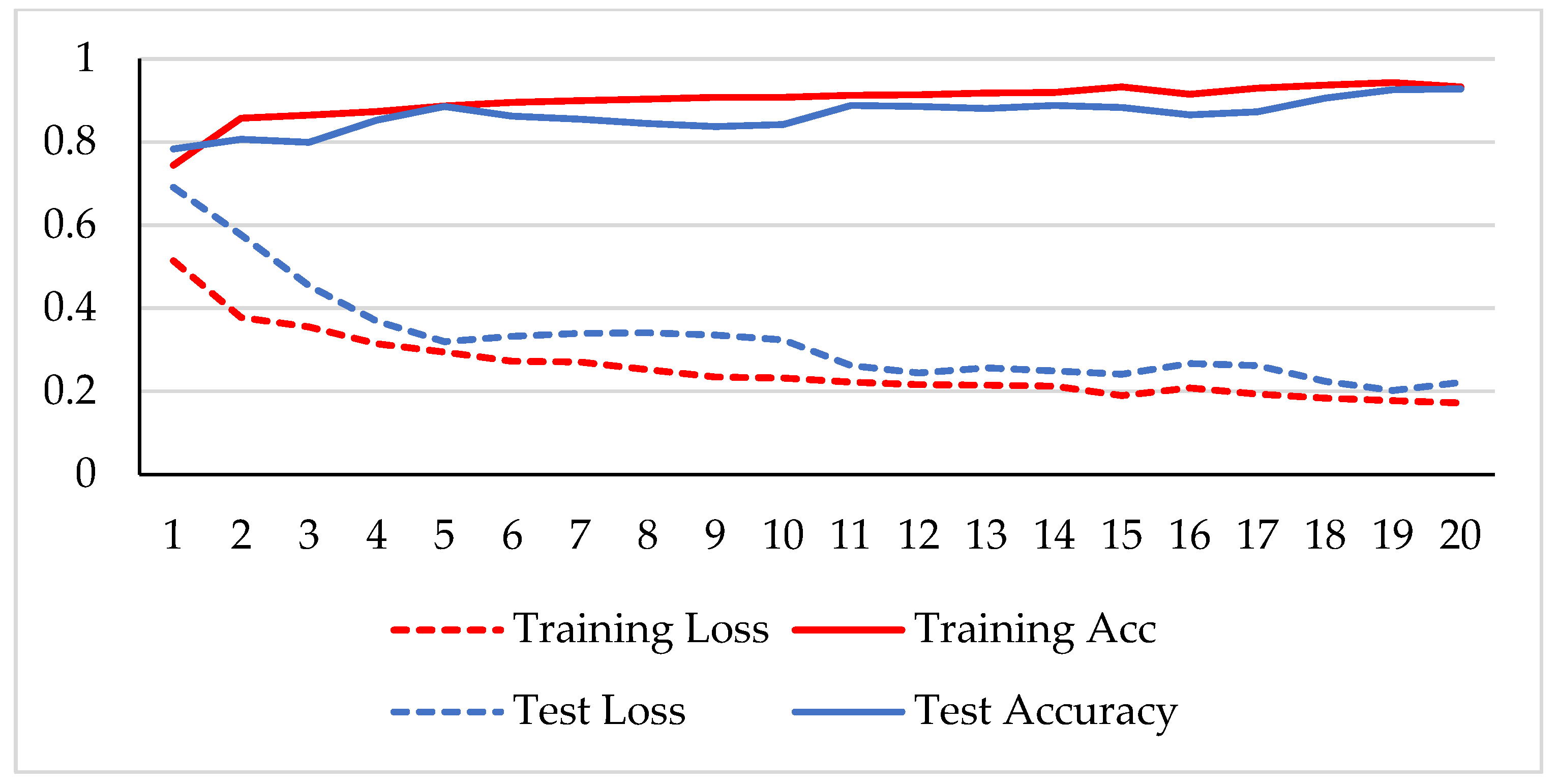
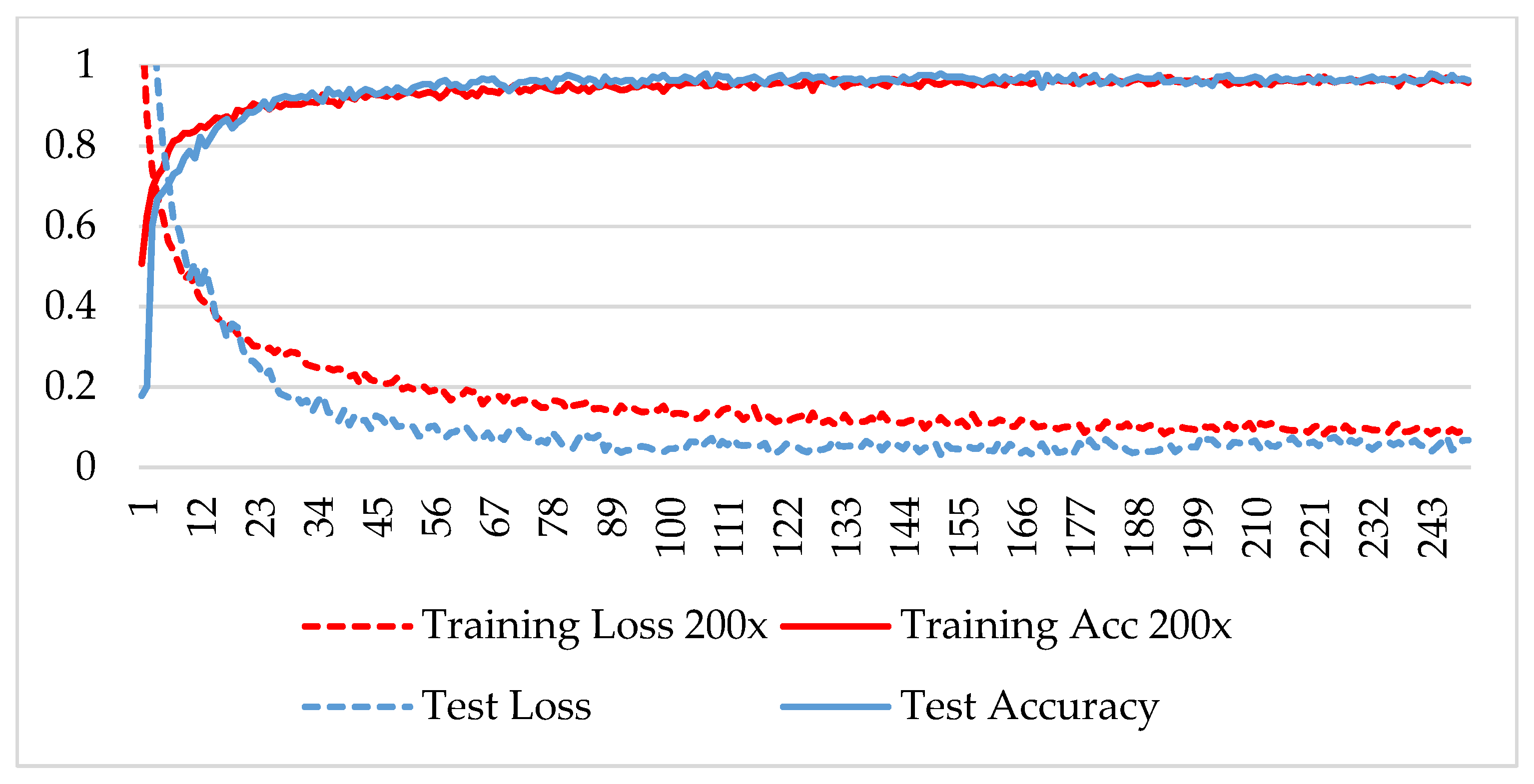
4. Results and Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 40X | 100X | 200X | 400X |
|---|---|---|---|---|
| ResHist Model [27] | 86.38 | 87.28 | 91.35 | 86.29 |
| DenseNet CNN [28] | 93.64 | 97.42 | 95.87 | 94.67 |
| MuDeRN (Residual Network) [29] | 95.60 | 94.89 | 95.69 | 94.63 |
| Interleaved DenseNet121 [30] | 81.8 | 79.3 | 81.4 | 83.2 |
| ResNet [31] | 96.3 | 95 | 95 | 95.4 |
| Fisher vector + CNN [32] | 90.2 | 91.2 | 87.8 | 87.4 |
| VGGNet [26] | 92.22 | 93.40 | 95.23 | 92.80 |
| BiCNN [33] | 97.89 | 93.62 | 94.54 | 94.42 |
| CNN [24] | 94.65 | 94.07 | 94.54 | 93.77 |
| DenseNet 201 [15] | 92.61 | 92 | 93.93 | 91.73 |
| Proposed method | 100 | 95.39 | 95.68 | 94.65 |
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hermansyah, D.; Firsty, N.N. The Role of Breast Imaging in Pre- and Post-Definitive Treatment of Breast Cancer. In Breast Cancer; Patel, K.C., Mayrovitz, H.N., Eds.; Exon Publications: Brisbane, Australia, 2022; pp. 83–99. [Google Scholar] [CrossRef]
- Gamble, P.; Jaroensri, R.; Wang, H.; Tan, F.; Moran, M.; Brown, T.; Flament-Auvigne, I.; Rakha, E.A.; Toss, M.; Dabbs, D.J.; et al. Determining breast cancer biomarker status and associated morphological features using deep learning. Commun. Med. 2021, 1, 14. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Chen, J.; Fieguth, P.; Zhao, G.; Chellappa, R.; Pietikäinen, M. From BoW to CNN: Two Decades of Texture Representation for Texture Classification. Int. J. Comput. Vis. 2019, 127, 74–109. [Google Scholar] [CrossRef]
- Zhang, H.; Xue, J.; Dana, K. Deep TEN: Texture Encoding Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2896–2905. [Google Scholar] [CrossRef]
- Mao, S.; Rajan, D.; Chia, L.T. Deep residual pooling network for texture recognition. Pattern Recognit. 2021, 112, 107817. [Google Scholar] [CrossRef]
- Prusty, S.; Patnaik, S.; Dash, S.K. SKCV: Stratified K-fold cross-validation on ML classifiers for predicting cervical cancer. Front. Nanotechnol. 2022, 4, 972421. [Google Scholar] [CrossRef]
- Stegmuller, T.; Bozorgtabar, B.; Spahr, A.; Thiran, J.-P. ScoreNet: Learning Non-Uniform Attention and Augmentation for Transformer-Based Histopathological Image Classifica-tion. arXiv 2022, arXiv:2202.07570. [Google Scholar] [CrossRef]
- Gandomkar, Z.; Brennan, P.C.; Mello-Thoms, C. A framework for distinguishing benign from malignant breast histopathological images using deep residual networks. In Proceedings of the 14th International Workshop on Breast Imaging (IWBI 2018), Atlanta, GA, USA, 8–11 July 2018; Krupinski, E.A., Ed.; SPIE: Atlanta, GA, USA, 2018; p. 54. [Google Scholar] [CrossRef]
- Wakili, M.A.; Shehu, H.A.; Sharif, H.; Sharif, H.U.; Umar, A.; Kusetogullari, H.; Ince, I.F.; Uyaver, S. Classification of Breast Cancer Histopathological Images Using DenseNet and Transfer Learning. Comput. Intell. Neurosci. 2022, 2022, 8904768. [Google Scholar] [CrossRef] [PubMed]
- Vulli, A.; Srinivasu, P.N.; Sashank, M.S.K.; Shafi, J.; Choi, J.; Ijaz, M.F. Fine-Tuned DenseNet-169 for Breast Cancer Metastasis Prediction Using FastAI and 1-Cycle Policy. Sensors 2022, 22, 2988. [Google Scholar] [CrossRef] [PubMed]
- Mewada, H.K.; Patel, A.V.; Hassaballah, M.; Alkinani, M.H.; Mahant, K. Spectral–Spatial Features Integrated Convolution Neural Network for Breast Cancer Classification. Sensors 2020, 20, 4747. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Liu, X.; Qi, Y. Adaptive Threshold Learning in Frequency Domain for Classification of Breast Cancer Histopathological Images. Int. J. Intell. Syst. 2024, 2024, 9199410. [Google Scholar] [CrossRef]
- Salunkhe, P.B.; Patil, P.S. Rapid tri-net: Breast cancer classification from histology images using rapid tri-attention network. Multimedia Tools Appl. 2024, 83, 1–31. [Google Scholar] [CrossRef]
- Patel, H.; Mewada, H. Dictionary Properties for Sparse Representation: Implementation and Analysis. J. Artif. Intell. 2017, 11, 1–8. [Google Scholar] [CrossRef]
- Zerouaoui, H.; Idri, A. Deep hybrid architectures for binary classification of medical breast cancer images. Biomed. Signal Process. Control 2021, 71, 103226. [Google Scholar] [CrossRef]
- Wang, P.; Wang, J.; Li, Y.; Li, P.; Li, L.; Jiang, M. Automatic classification of breast cancer histopathological images based on deep feature fusion and enhanced routing. Biomed. Signal Process. Control 2020, 65, 102341. [Google Scholar] [CrossRef]
- Pandey, A.; Kumar, A. An integrated approach for breast cancer classification. Multimed. Tools Appl. 2023, 82, 33357–33377. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Naderan, M.; Zaychenko, Y. Convolutional Autoencoder Application for Breast Cancer Classification. In Proceedings of the 2020 IEEE 2nd International Conference on System Analysis & Intelligent Computing (SAIC), Kyiv, Ukraine, 5–9 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Jiang, Y.; Chen, L.; Zhang, H.; Xiao, X. Breast cancer histopathological image classification using convolutional neural networks with small SE-ResNet module. PLoS ONE 2019, 14, e0214587. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Liu, Z.; Liu, S. Semi-supervised breast histopathological image classification with self-training based on non-linear distance metric. IET Image Process. 2022, 16, 3164–3176. [Google Scholar] [CrossRef]
- Kolla, B.; P, V. An integrated approach for magnification independent breast cancer classification. Biomed. Signal Process. Control 2024, 88, 105594. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, C.; Gao, S. Breast Cancer Classification from Histopathological Images Using Resolution Adaptive Network. IEEE Access 2022, 10, 35977–35991. [Google Scholar] [CrossRef]
- Xu, Y.; Li, F.; Chen, Z.; Liang, J.; Quan, Y. Encoding spatial distribution of convolutional features for texture representation. Adv. Neural Inf. Process. Syst. 2021, 34, 22732–22744. [Google Scholar]
- Spanhol, F.A.; Oliveira, L.S.; Petitjean, C.; Heutte, L. A Dataset for Breast Cancer Histopathological Image Classification. IEEE Trans. Biomed. Eng. 2015, 63, 1455–1462. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Singh, S.K.; Saxena, S.; Lakshmanan, K.; Sangaiah, A.K.; Chauhan, H.; Shrivastava, S.; Singh, R.K. Deep feature learning for histopathological image classification of canine mammary tumors and human breast cancer. Inf. Sci. 2019, 508, 405–421. [Google Scholar] [CrossRef]
- Gour, M.; Jain, S.; Kumar, T.S. Residual learning based CNN for breast cancer histopathological image classification. Int. J. Imaging Syst. Technol. 2020, 30, 621–635. [Google Scholar] [CrossRef]
- Nguyen, P.T.; Nguyen, T.T.; Nguyen, N.C.; Le, T.T. Multiclass Breast Cancer Classification Using Convolutional Neural Network. In Proceedings of the 2019 International Symposium on Electrical and Electronics Engineering (ISEE), Ho Chi Minh, Vietnam, 10–12 October 2019; pp. 130–134. [Google Scholar] [CrossRef]
- Gandomkar, Z.; Brennan, P.C.; Mello-Thoms, C. MuDeRN: Multi-category classification of breast histopathological image using deep residual networks. Artif. Intell. Med. 2018, 88, 14–24. [Google Scholar] [CrossRef]
- Li, X.; Shen, X.; Zhou, Y.; Wang, X.; Li, T.-Q. Classification of breast cancer histopathological images using interleaved DenseNet with SENet (IDSNet). PLoS ONE 2020, 15, e0232127. [Google Scholar] [CrossRef] [PubMed]
- Eltoukhy, M.M.; Hosny, K.M.; Kassem, M.A. Classification of Multiclass Histopathological Breast Images Using Residual Deep Learning. Comput. Intell. Neurosci. 2022, 2022, 9086060. [Google Scholar] [CrossRef]
- Song, Y.; Chang, H.; Huang, H.; Cai, W. Supervised Intra-embedding of Fisher Vectors for Histopathology Image Classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 11–13 September 2017; Descoteaux, M., Maier-Hein, L., Franz, A., Jannin, P., Collins, D.L., Duchesne, S., Eds.; Lecture Notes in Computer Science, Volume 10435. Springer International Publishing: Cham, Switzerland, 2017; pp. 99–106. [Google Scholar] [CrossRef]
- Wei, B.; Han, Z.; He, X.; Yin, Y. Deep learning model based breast cancer histopathological image classificationin. In Proceedings of the 2017 IEEE 2nd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 28–30 April 2017; pp. 348–353. [Google Scholar]
- Nawaz, M.; Sewissy, A.A.; Hassan, T. Multi-Class Breast Cancer Classification using Deep Learning Convolutional Neural Network. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 316–322. [Google Scholar] [CrossRef]
- Bardou, D.; Zhang, K.; Ahmad, S.M. Classification of Breast Cancer Based on Histology Images Using Convolutional Neural Networks. IEEE Access 2018, 6, 24680–24693. [Google Scholar] [CrossRef]
- Asare, S.K.; You, F.; Nartey, O.T. A Semisupervised Learning Scheme with Self-Paced Learning for Classifying Breast Cancer Histopathological Images. Comput. Intell. Neurosci. 2020, 2020, 8826568. [Google Scholar] [CrossRef] [PubMed]
- Joseph, A.A.; Abdullahi, M.; Junaidu, S.B.; Ibrahim, H.H.; Chiroma, H. Improved multi-classification of breast cancer histopathological images using handcrafted features and deep neural network (dense layer). Intell. Syst. Appl. 2022, 14, 200066. [Google Scholar] [CrossRef]
- Alkassar, S.; Jebur, B.A.; Abdullah, M.A.M.; Al-Khalidy, J.H.; Chambers, J.A. Going deeper: Magnification-invariant approach for breast cancer classification using histopathological images. IET Comput. Vis. 2021, 15, 151–164. [Google Scholar] [CrossRef]
- Boumaraf, S.; Liu, X.; Zheng, Z.; Ma, X.; Ferkous, C. A new transfer learning based approach to magnification dependent and independent classification of breast cancer in histopathological images. Biomed. Signal Process. Control 2020, 63, 102192. [Google Scholar] [CrossRef]














| Classes | Subclasses | No. of Patients | Magnification Factor | Total | |||
|---|---|---|---|---|---|---|---|
| 40X | 100X | 200X | 400X | ||||
| Benign (B) | Adenosis (A) | 4 | 114 | 113 | 111 | 106 | 444 |
| Fibroadenoma (F) | 10 | 253 | 260 | 264 | 237 | 1014 | |
| Phyllodes Tumor (PT) | 7 | 149 | 150 | 140 | 130 | 569 | |
| Tubular Adenoma (TA) | 3 | 109 | 121 | 108 | 115 | 453 | |
| Total | 24 | 625 | 644 | 623 | 588 | 2480 | |
| Malignant (M) | Ductal Carcinoma (DC) | 38 | 864 | 903 | 896 | 788 | 3451 |
| Lobular Carcinoma (LC) | 5 | 156 | 170 | 163 | 137 | 626 | |
| Mucinous Carcinoma (MC) | 9 | 205 | 222 | 196 | 169 | 792 | |
| Papillary Carcinoma (PC) | 6 | 145 | 142 | 135 | 138 | 560 | |
| Total | 58 | 1370 | 1437 | 1390 | 1232 | 5429 | |
| Magnification Factor | TP | FP | FN | TN | Precision | Recall | Accuracy | F1 Score |
|---|---|---|---|---|---|---|---|---|
| 40X | 42 | 0 | 0 | 52 | 100 | 100 | 100 | 100 |
| 100X | 163 | 19 | 2 | 272 | 89.56 | 98.78 | 95.39 | 93.94 |
| 200X | 147 | 18 | 1 | 274 | 89.09 | 99.32 | 95.68 | 93.92 |
| 400X | 142 | 14 | 7 | 230 | 91.02 | 95.30 | 94.65 | 93.11 |
| Magnification Factor | 40X | 100X | 200X | 400X |
|---|---|---|---|---|
| Training dataset | 1073 | 1148 | 893 | 912 |
| Test dataset | 270 | 269 | 227 | 241 |
| Magnification Factor | TP | FP | FN | TN | Precision | Recall | Accuracy | F1 Score |
|---|---|---|---|---|---|---|---|---|
| DC 40X | 154 | 3 | 8 | 105 | 98.09 | 95.06 | 95.93 | 96.55 |
| DC 100X | 168 | 6 | 7 | 111 | 96.55 | 96.00 | 95.55 | 96.28 |
| DC 200X | 38 | 1 | 2 | 186 | 97.44 | 95.00 | 98.68 | 96.20 |
| DC 400X | 35 | 3 | 3 | 200 | 92.11 | 92.11 | 97.51 | 92.11 |
| LC 40X | 35 | 2 | 3 | 230 | 94.59 | 92.11 | 98.15 | 93.33 |
| LC 100X | 34 | 2 | 3 | 253 | 94.44 | 91.89 | 98.29 | 93.15 |
| LC 200X | 116 | 3 | 7 | 101 | 97.48 | 94.31 | 95.59 | 95.87 |
| LC 400X | 134 | 5 | 8 | 94 | 96.40 | 94.37 | 94.61 | 95.37 |
| MC 40X | 40 | 4 | 1 | 225 | 90.91 | 97.56 | 98.15 | 94.12 |
| MC 100X | 42 | 5 | 5 | 240 | 89.36 | 89.36 | 96.58 | 89.36 |
| MC 200X | 31 | 4 | 3 | 189 | 88.57 | 91.18 | 96.92 | 89.86 |
| MC 400X | 31 | 2 | 3 | 205 | 93.94 | 91.18 | 97.93 | 92.54 |
| PC 40X | 28 | 4 | 1 | 237 | 87.50 | 96.55 | 98.15 | 91.80 |
| PC 100X | 29 | 6 | 3 | 231 | 82.86 | 90.63 | 96.65 | 86.57 |
| PC 200X | 30 | 4 | 0 | 193 | 88.24 | 100.00 | 98.24 | 93.75 |
| PC 400X | 30 | 1 | 2 | 208 | 96.77 | 93.75 | 98.76 | 95.24 |
| Method | Magnification | |||
|---|---|---|---|---|
| 40X | 100X | 200X | 400X | |
| CNN [33] | 78.30 | 80.68 | 72.13 | 74.79 |
| [36] | 92.87 | 90.41 | 92.19 | 91.40 |
| Handcrafted features + CNN [37] | 90.87 | 89.57 | 91.58 | 88.67 |
| Inception network + ECmax [38] | 92.2 | 88.2 | 89.4 | 88.5 |
| ResNet-18 [39] | 94.49 | 93.27 | 91.29 | 89.56 |
| Proposed method | 97.59 | 96.76 | 97.35 | 97.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mewada, H. Extended Deep-Learning Network for Histopathological Image-Based Multiclass Breast Cancer Classification Using Residual Features. Symmetry 2024, 16, 507. https://doi.org/10.3390/sym16050507
Mewada H. Extended Deep-Learning Network for Histopathological Image-Based Multiclass Breast Cancer Classification Using Residual Features. Symmetry. 2024; 16(5):507. https://doi.org/10.3390/sym16050507
Chicago/Turabian StyleMewada, Hiren. 2024. "Extended Deep-Learning Network for Histopathological Image-Based Multiclass Breast Cancer Classification Using Residual Features" Symmetry 16, no. 5: 507. https://doi.org/10.3390/sym16050507
APA StyleMewada, H. (2024). Extended Deep-Learning Network for Histopathological Image-Based Multiclass Breast Cancer Classification Using Residual Features. Symmetry, 16(5), 507. https://doi.org/10.3390/sym16050507