
Application of Assistive Computer Vision Methods to Oyama Karate Techniques Recognition




Abstract
:1. Introduction
1.1. Approaches to Actions Recognition
1.2. Recognition of Actions in Continuous Streams
1.3. Application of Deep Learning in Action Recognition
1.4. Application of Depth Sensors in Actions Recognition
1.5. Recognition and Quality Evaluation of Karate Techniques
1.6. The Motivation for This Paper
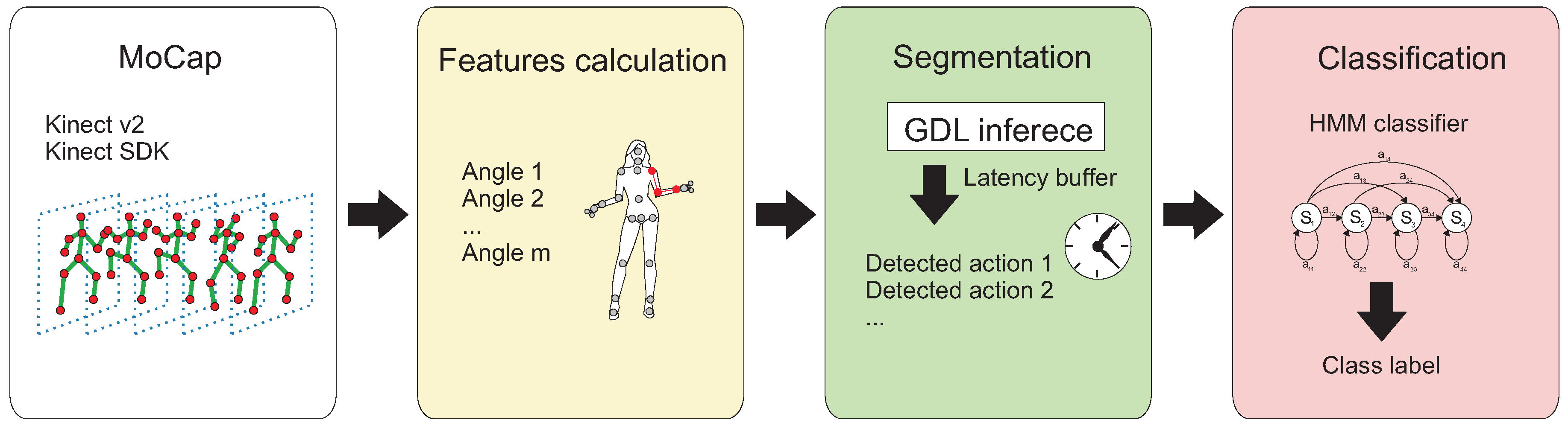
2. Materials and Methods
2.1. Pose Representation


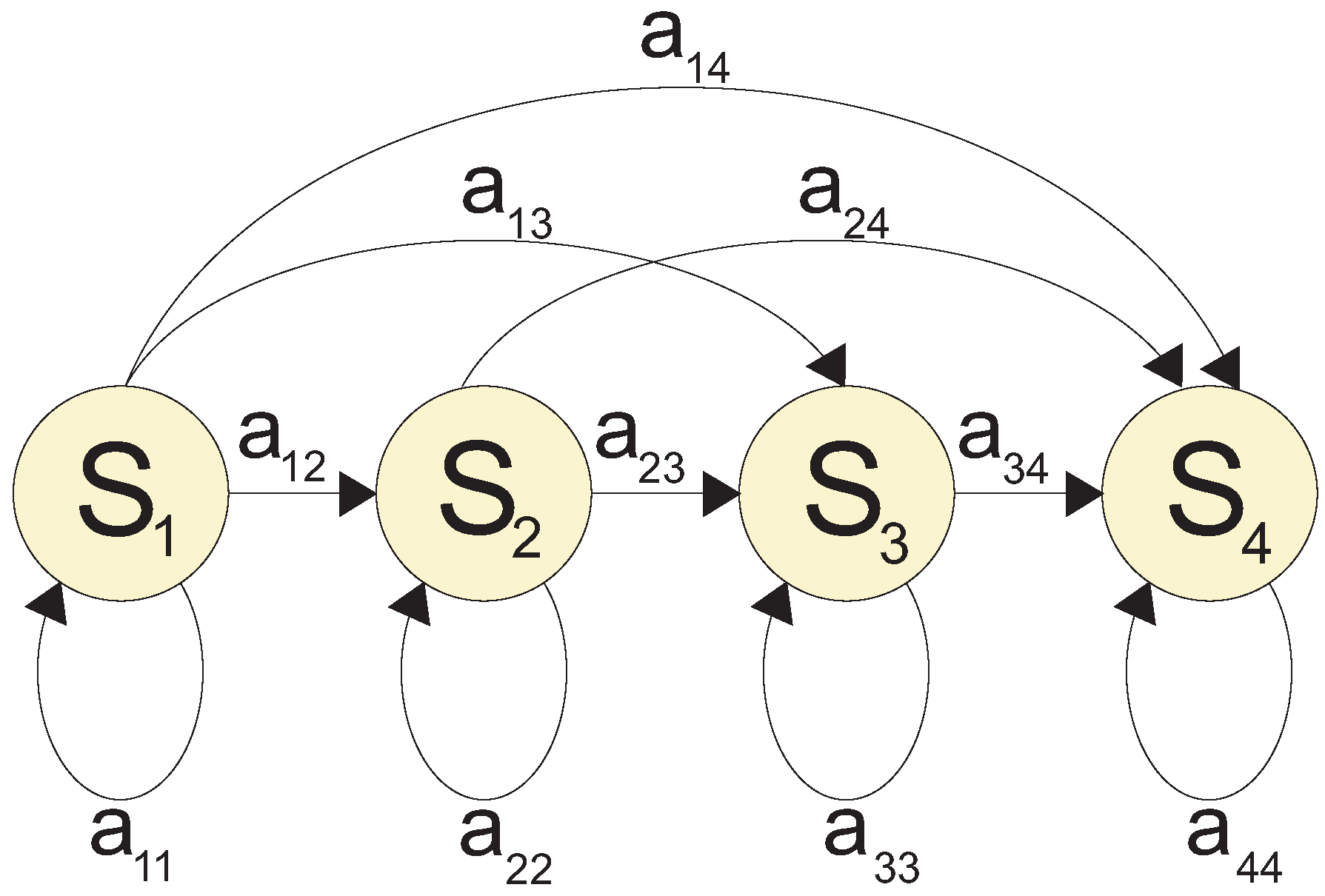
2.2. Continuous-Density Hidden Markov Models Classifier

- -
- Calculating the forward probability and the backward probability for each HMM state;
- -
- On the basis of this, determining the frequency of the transition-emission pair values and dividing it by the probability of the entire string.
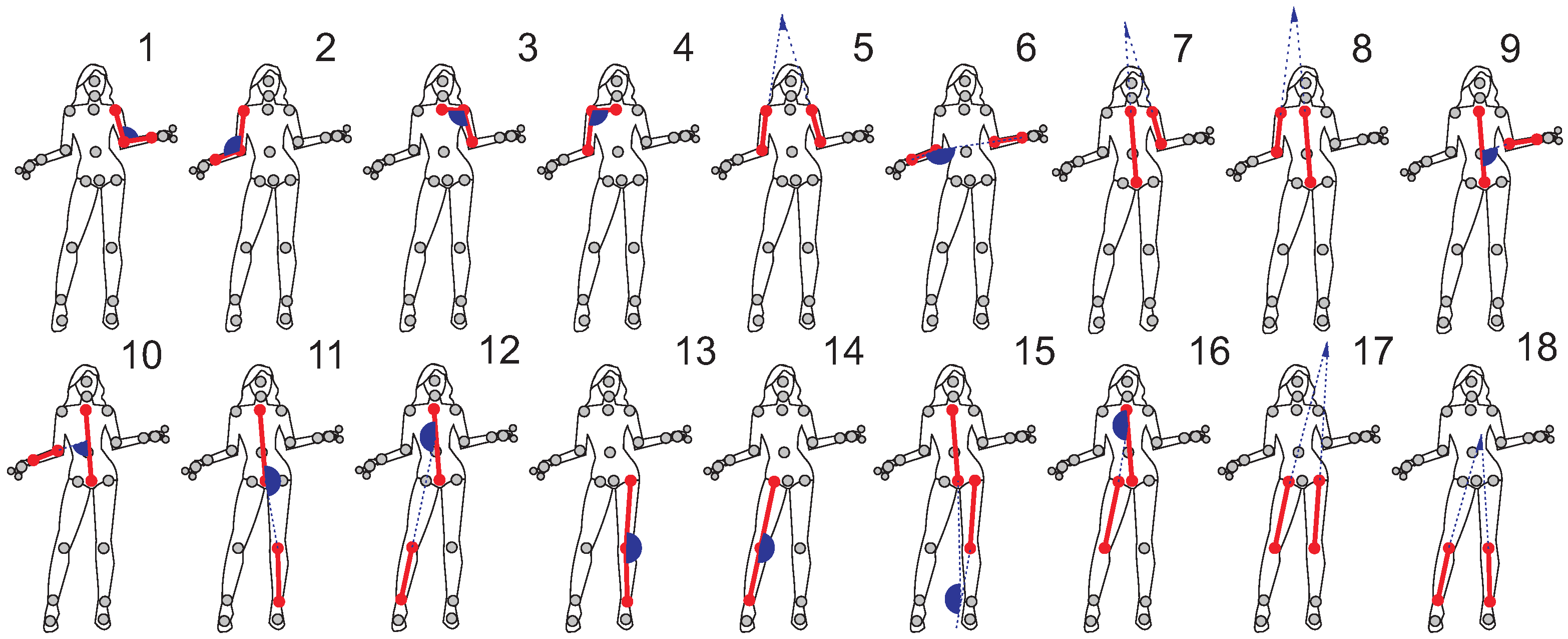
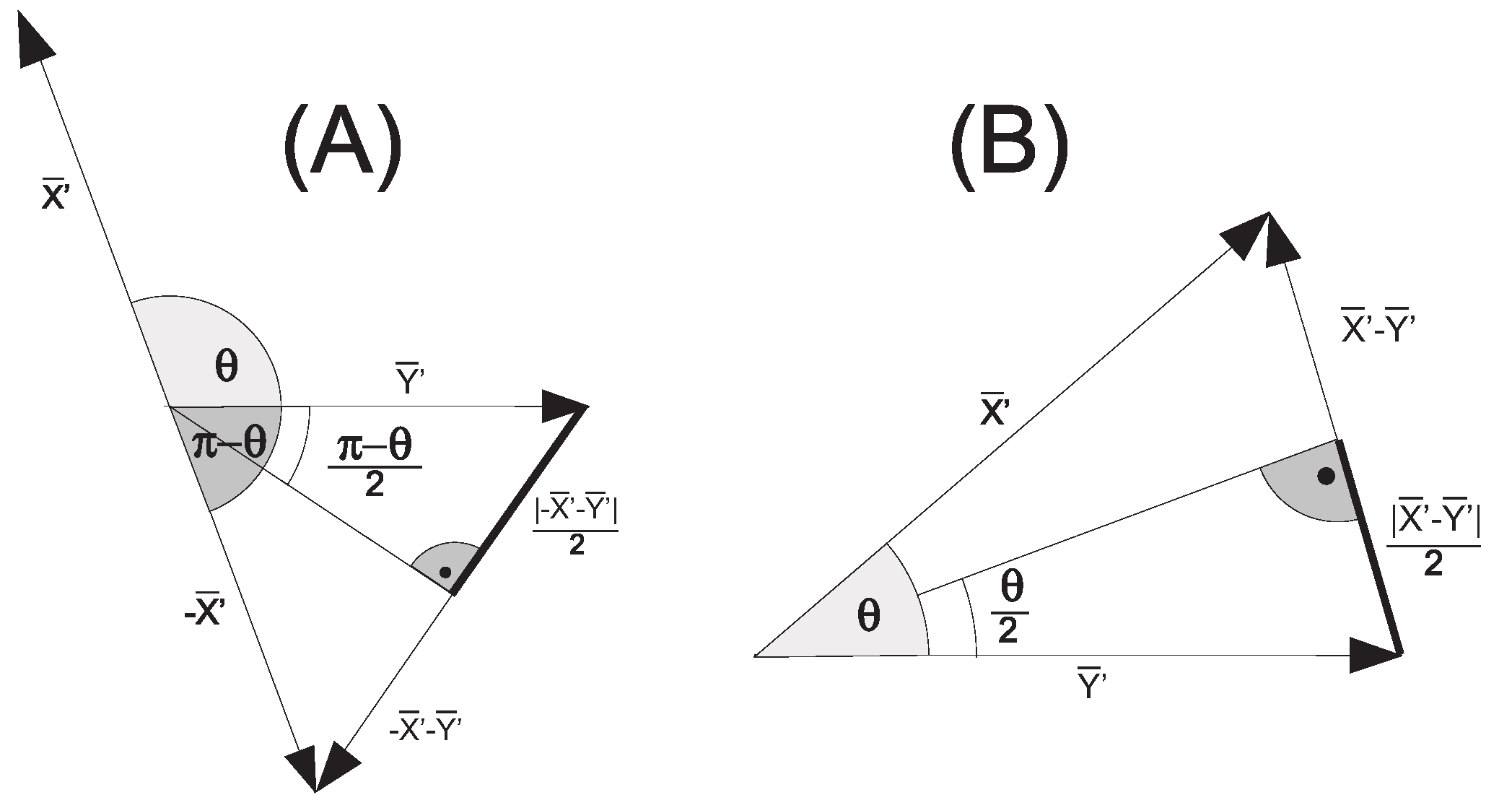
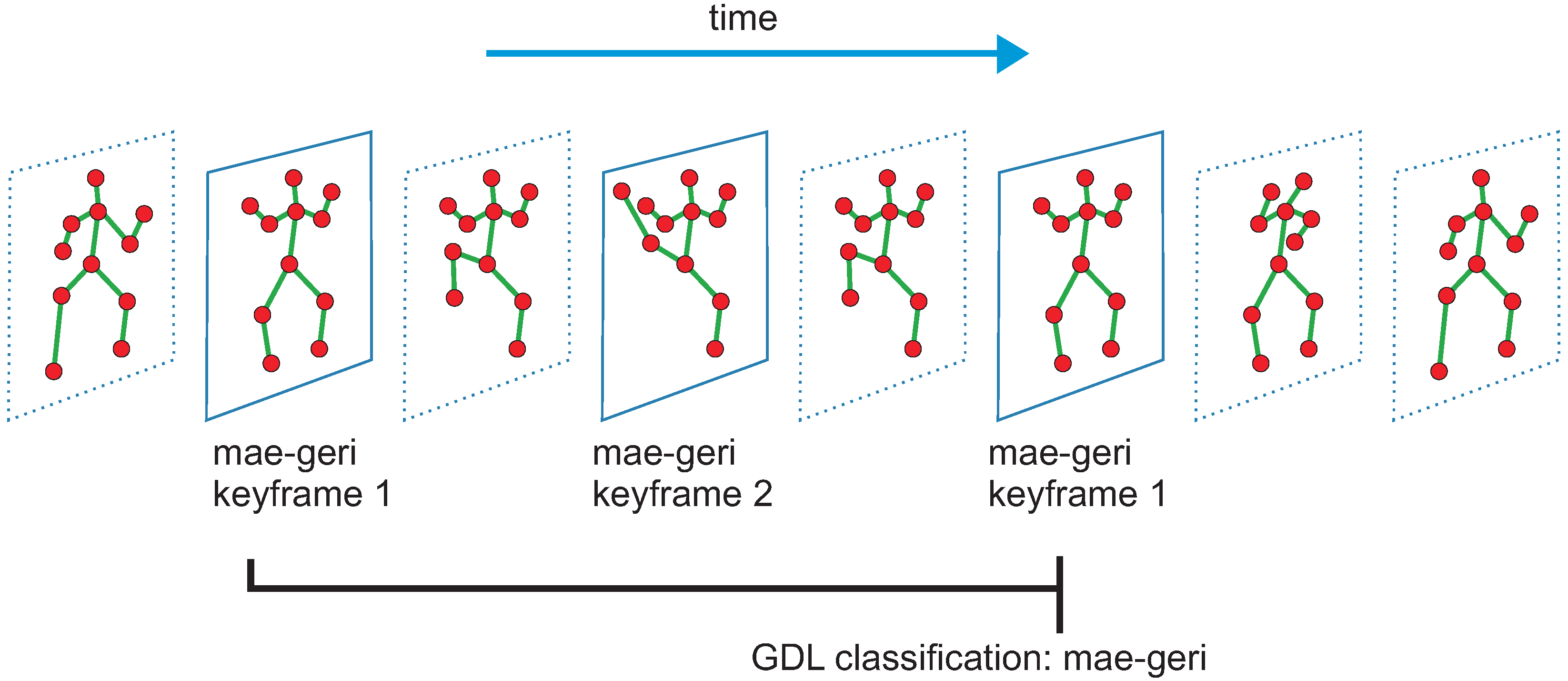
2.3. Unsupervised—Learned Actions Segmentation and Classification with Gestures Description Language

| Algorithm 1—Retrieving from GDL Memory Stack the Signal that was Classified to Class |
|---|
| //An ordered set that will contains the signal |
| F: = Empty |
| //Index of cluster—see Equation (7) |
| Cluster_Index: = N |
| //Indicates how deep in GDL memory stack lies the beginning of sequence |
| //(zero is a top of a stack) |
| Stack_Index: = 0 |
| //While we found all clusters (keyframes) |
| While (Cluster_Index > 0) |
| Begin |
| //Get all conclusions that are in memory stack in depth indicated |
| //by Stack_Index |
| All_Conclusions_Array: = Conclusions(Stack_Index) |
| //Get features that are in memory stack in depth indicated |
| //by Stack_Index |
| Features_Array: = Features(Stack_Index) |
| //Append features at the begining of ordered set F |
| //We must remembered that signal resides on stack in reversed order |
| Append Features_Array At Beginning Of F |
| //If conclusions array satisfied on this level of stack contains |
| //keyframe with index Cluster_index |
| If (All_Conclusions_Array Contains ) |
| Begin |
| //Select next cluster index |
| Cluster_Index: = Cluster_Index − 1 |
| END |
| //Go deeper into the stack |
| Stack_Index: = Stack_Index + 1 |
| END |
| //Set Stack_Index on level where last conclusion was found |
| Stack_Index: = Stack_Index − 1 |
2.4. Online Actions Segmentation and Classification—The Proposed Approach

| Algorithm 2. An Online Recordings Segmentation |
|---|
| //A set of all GDL conclusions |
| Conclusions: = Empty |
| //Indicates how deep in GDL memory stack lies the beginning of sequence |
| Stack_Index: = −1 |
| //How much time passed since last segmentation |
| Elapsed_Time: = 0 |
| //A minimal time latency since last segmentation—“latency buffer” |
| Latency: = 0.5 sec |
| //Initialize the GDL inference engine and stack |
| GDL_Interpreter: = Initialize_GDL_Interpreter |
| Stack: = Empty |
| //A class label of sequence that was recognized in this |
| //loop of application |
| Class_Label = “Not_Yet_Detected” |
| //While MoCap device is running |
| While MoCap_Is_Running |
| Begin |
| //Generate features array from captured MoCap skeleton |
| Features_Array: = GenerateFeatures(MoCap_Data) |
| //Add new features array to memory stack of GDL |
| Stack = Stack + Features_Array |
| //Return all conclusions that can be inferred from memory stack |
| New_Conclusions: = GDL_Interpreter(Features_Array) |
| Class_Label = “Not_Yet_Detected” |
| //If memory stack depth variable has been initialized in previous iterations |
| //increase its depth by 1 |
| If (Stack_Index ≥ 0) |
| Begin |
| Stack_Index: = Stack_Index + 1 |
| End |
| //For each conclusion inferred by GDL |
| Foreach conculsion In New_Conclusions |
| Begin |
| //If a given conclusion indicates that an action has been detected |
| If (conclusion Is Action_Conclusion) |
| Begin |
| //Add conclusion to set of conclusions |
| Conclusions = Conclusions + conclusion |
| //Find depth of the stack where is a first keyframe |
| //that supports this conclusion—this value is hold |
| //in Algorithm 1 in variable Stack_Index |
| Index = GDL_Interpreter(conclusion) |
| //Use largest value of already found stack depths |
| If (Index > Stack_Index) |
| Begin |
| Stack_Index = Index |
| End |
| //Zero the time that elapsed since last action detected |
| Elapsed_Time: = 0; |
| End |
| End |
| //Increase elapsed time by time that passed since last iteration |
| //of main loop |
| Elapsed_Time = Elapsed_Time + Time_Since_Last_Iteration |
| //If set of conclusions is empty reset the elapsed time |
| If (Conclusions Is Empty) |
| Begin |
| Elapsed_Time = 0; |
| End |
| //If time since last detected action is greater than latency |
| //and Stack Index variable has been initialized |
| If (Elapsed_Time > Latency And Stack_Index ≥ 0) |
| Begin |
| //Get the sequence from memory stack starting from Stack_Index |
| //to its top |
| Sequence: = GDL_Interpreter(Stack_Index, 0) |
| //Classify the sequence with HMM classifier |
| Class_Label: = HMM(Sequence) |
| //Reset memory stack of GDL |
| GDL_Interpreter.Stack = Empty |
| //Reset conclusions set |
| Conclusions = Empty |
| Stack_Index = −1 |
| Elapsed_Time = 0 |
| End |
| End |
2.5. Z-Score Calculation
3. Experiment and Results
3.1. The Dataset

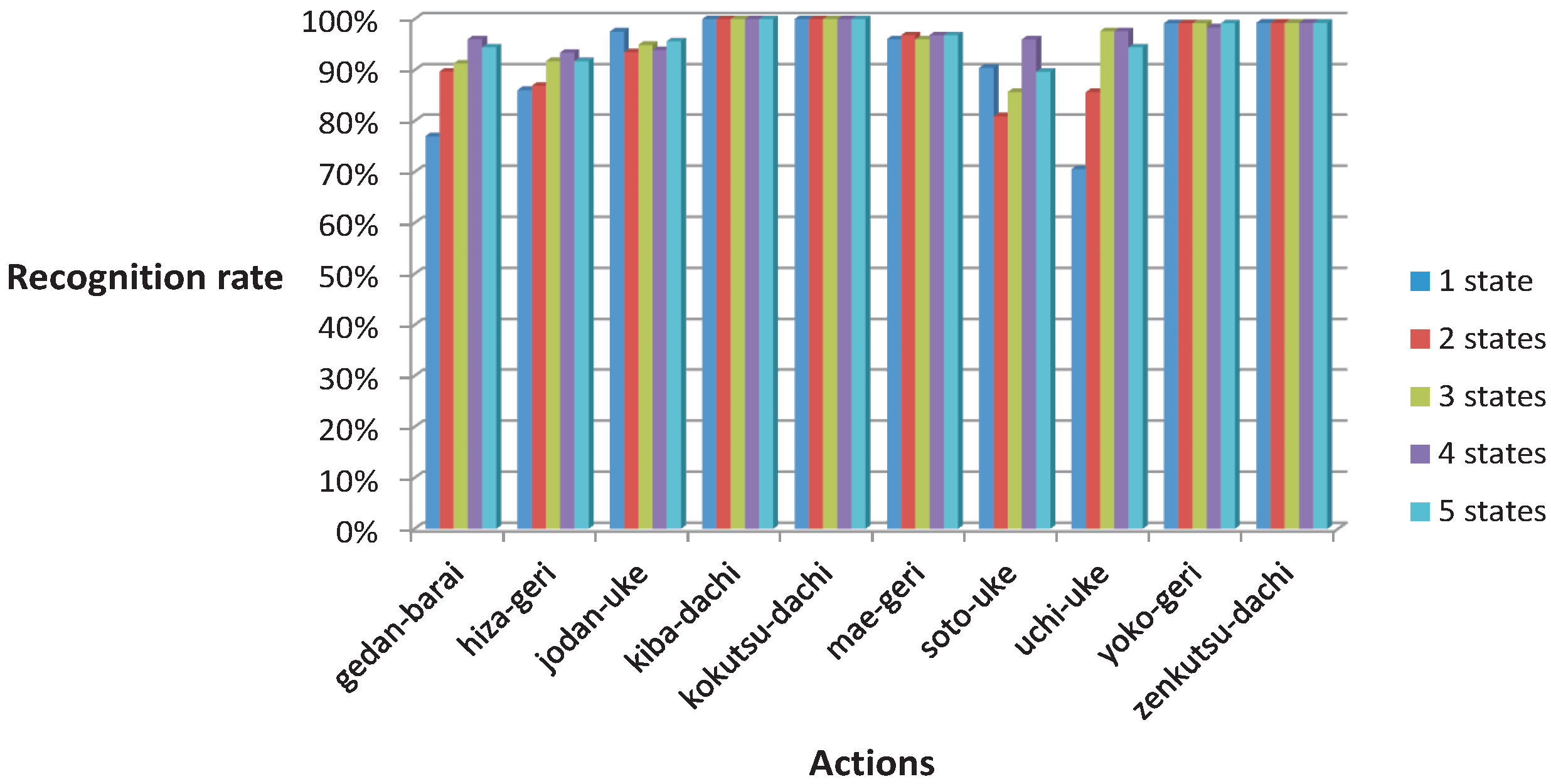
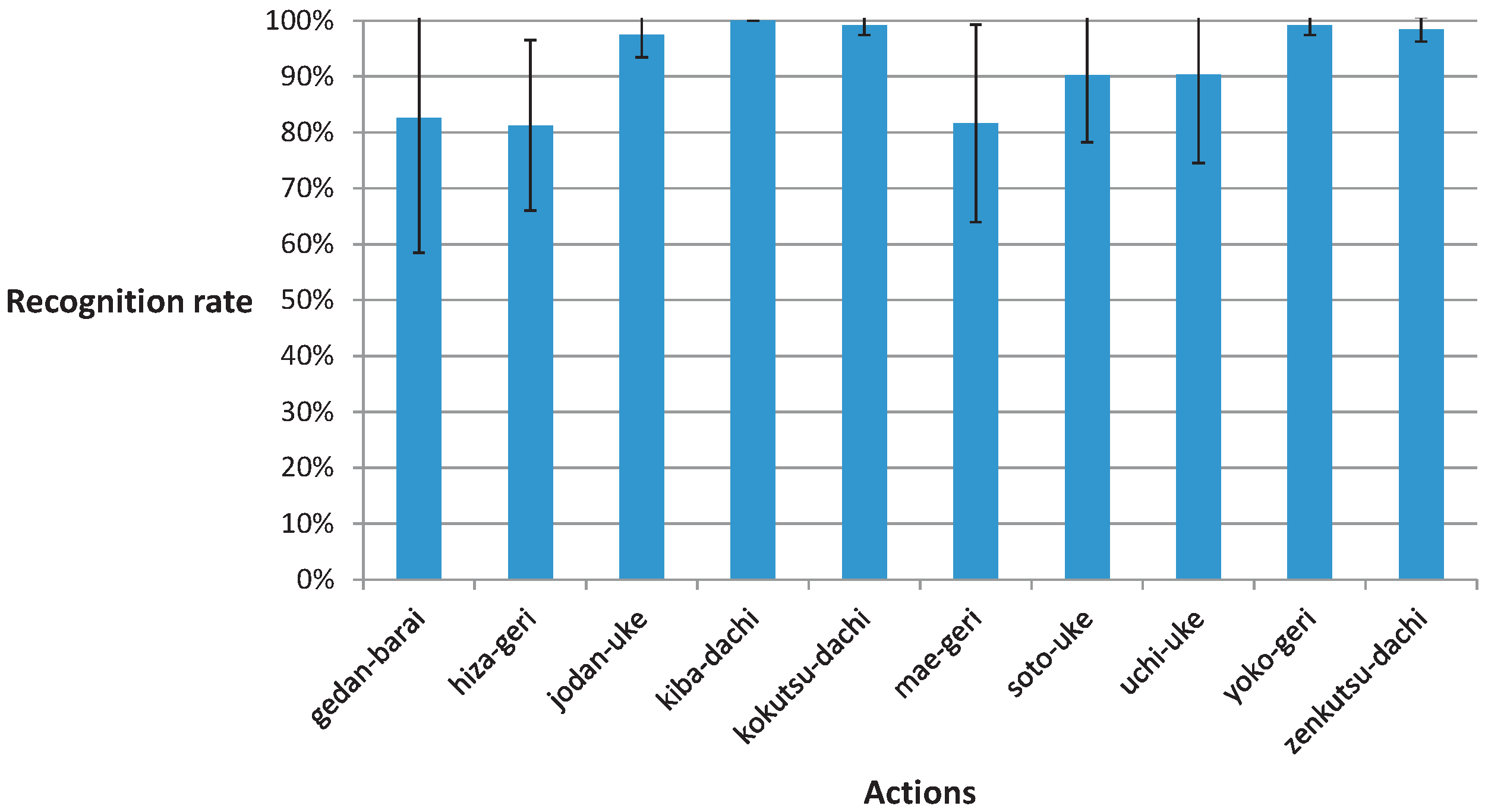
3.2. Classification of Segmented Recordings with Hidden Markov Model Classifier
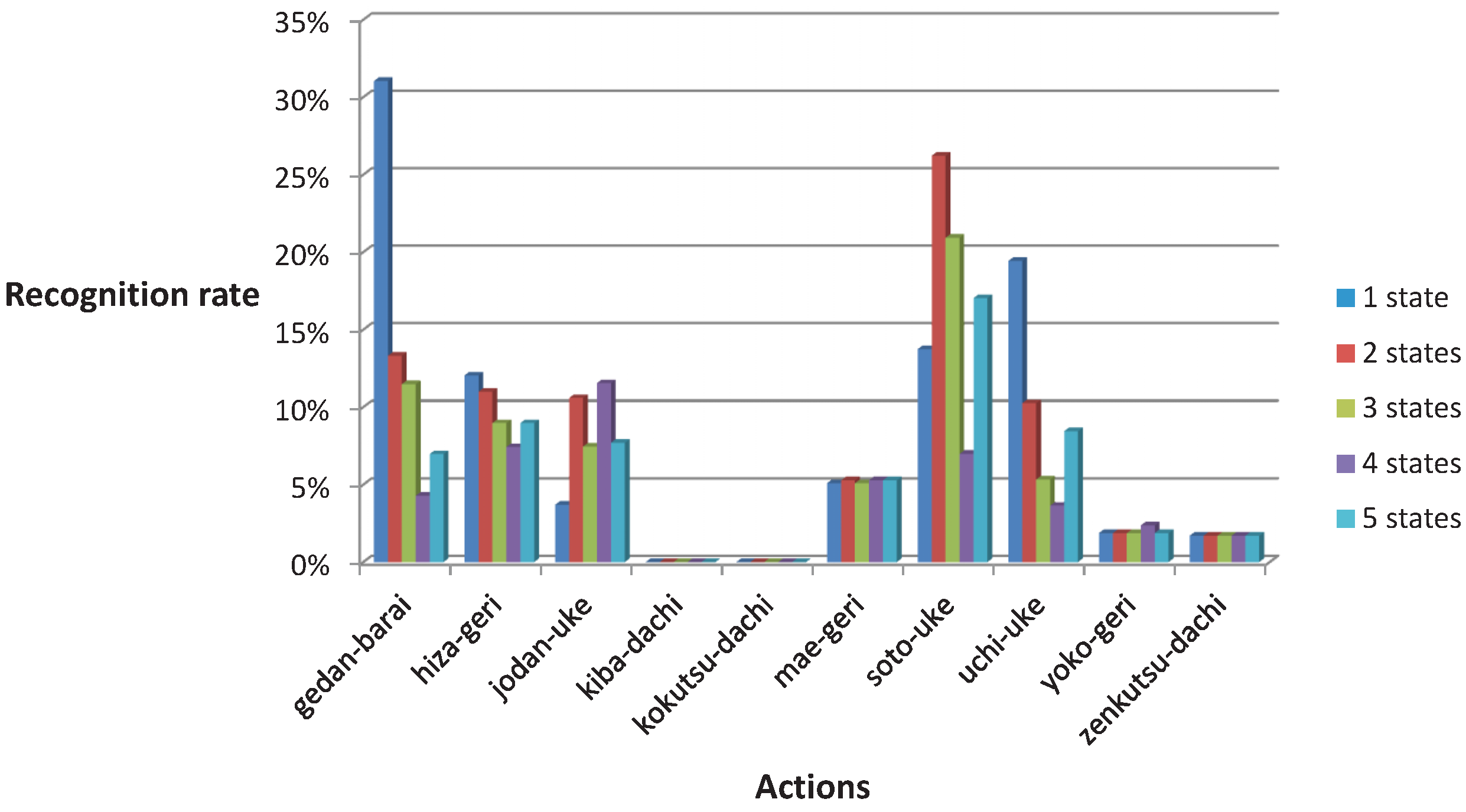
3.3. Classification of Unsegmented Recordings with Gestures Description Language and Hidden Markov Model Classifier

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Volunteer ID | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 2 | 20 | 19 | 19 | 20 | 20 | 20 | 20 | 20 | 20 | 20 |
| 3 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 20 |
| 4 | 21 | 20 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 22 |
| 5 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| 6 | 21 | 20 | 21 | 21 | 21 | 21 | 21 | 21 | 21 | 21 |
| Hidden states | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 state (GMM) | 77% ± 31% | 86% ± 12% | 98% ± 4% | 100% ± 0% | 100% ± 0% | 96% ± 5% | 90% ± 14% | 71% ± 19% | 99% ± 2% | 99% ± 2% |
| 2 states | 90% ± 13% | 87% ± 11% | 93% ± 11% | 100% ± 0% | 100% ± 0% | 97% ± 5% | 81% ± 26% | 86% ± 10% | 99% ± 2% | 99% ± 2% |
| 3 states | 91% ± 11% | 92% ± 9% | 95% ± 7% | 100% ± 0% | 100% ± 0% | 96% ± 5% | 86% ± 21% | 98% ± 5% | 99% ± 2% | 99% ± 2% |
| 4 states | 96% ± 4% | 93% ± 7% | 94% ± 12% | 100% ± 0% | 100% ± 0% | 97% ± 5% | 96% ± 7% | 98% ± 4% | 98% ± 2% | 99% ± 2% |
| 5 states | 94% ± 7% | 92% ± 9% | 96% ± 8% | 100% ± 0% | 100% ± 0% | 97% ± 5% | 90% ± 17% | 94% ± 8% | 99% ± 2% | 99% ± 2% |


| Technique | No Decision | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 17% ± 13% | 71% ± 23% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 3% ± 5% | 9% ± 16% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 27% ± 10% | 0% ± 0% | 69% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 4% ± 6% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 14% ± 9% | 0% ± 0% | 0% ± 0% | 84% ± 10% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 5% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 95% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 16% ± 13% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 77% ± 14% | 0% ± 0% | 0% ± 0% | 7% ± 15% | 0% ± 0% | 0% ± 0% |
| mae-geri | 27% ± 14% | 0% ± 0% | 7% ± 8% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 55% ± 17% | 1% ± 2% | 11% ± 24% | 0% ± 0% | 0% ± 0% |
| soto-uke | 14% ± 12% | 1% ± 2% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 68% ± 19% | 16% ± 17% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 12% ± 15% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 86% ± 16% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 19% ± 14% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 1% ± 2% | 79% ± 12% | 0% ± 0% |
| zenkutsu-dachi | 5% ± 10% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 95% ± 10% |
| Technique | No Decision | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | MAE-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 11% ± 14% | 83% ± 24% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 9% ± 20% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 20% ± 18% | 0% ± 0% | 81% ± 15% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 5% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 1% ± 2% | 0% ± 0% | 0% ± 0% | 97% ± 4% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 0% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 99% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| mae-geri | 22% ± 15% | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 82% ± 18% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| soto-uke | 6% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 90% ± 12% | 6% ± 6% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 1% ± 14% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 90% ± 16% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 1% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 99% ± 2% | 0% ± 0% |
| zenkutsu-dachi | 1% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 98% ± 2% |


4. Discussion
5. Conclusions
Conflicts of Interest
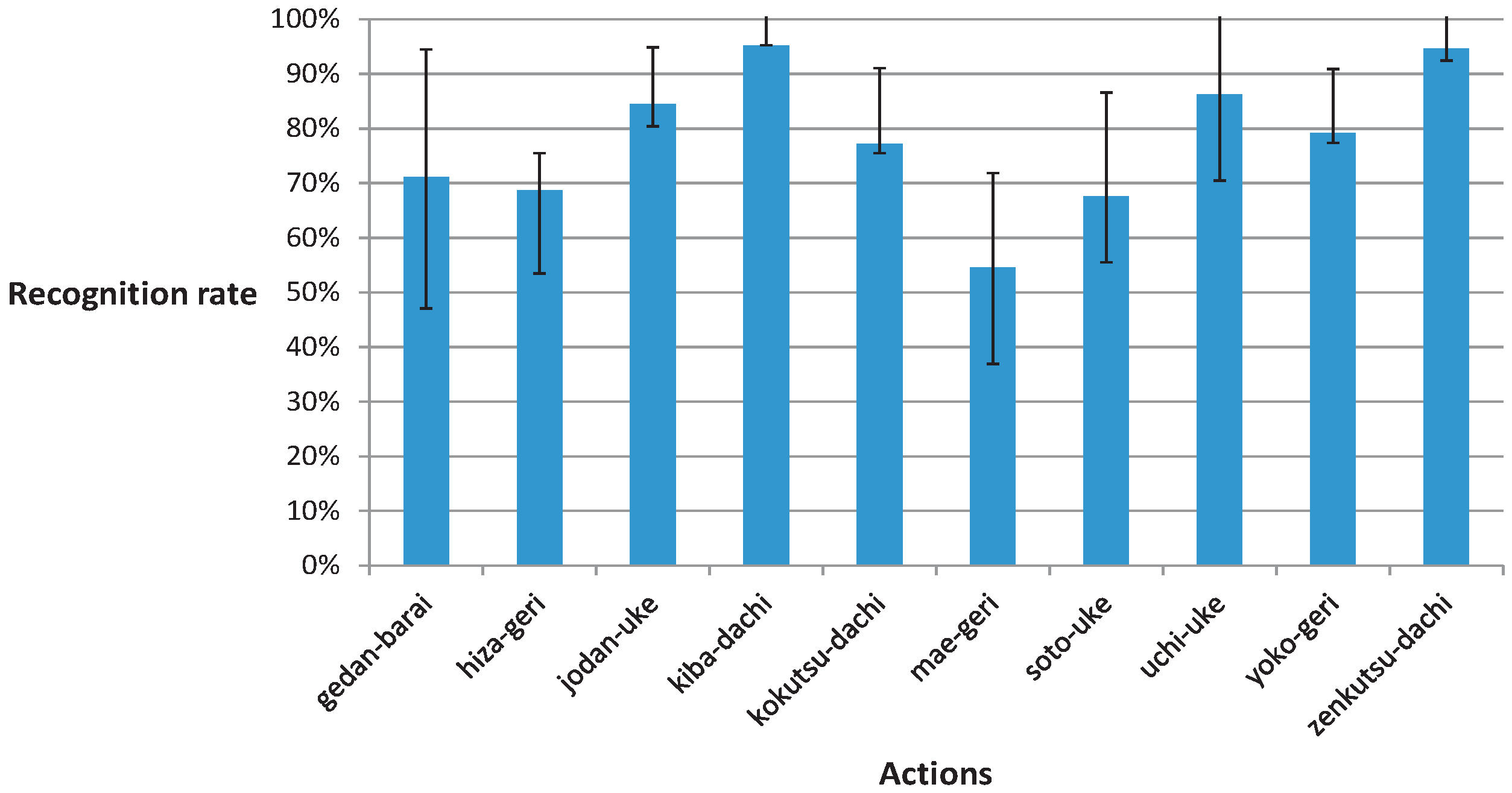
Appendix
| Technique | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 77% ± 31% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 11% ± 14% | 7% ± 11% | 4% ± 6% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 0% ± 0% | 86% ± 12% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 7% ± 8% | 0% ± 0% | 7% ± 11% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 0% ± 0% | 0% ± 0% | 98% ± 4% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 2% ± 2% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| mae-geri | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 96% ± 5% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% |
| soto-uke | 0% ± 0% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 90% ± 14% | 7% ± 10% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 0% ± 0% | 1% ± 2% | 3% ± 4% | 0% ± 0% | 0% ± 0% | 25% ± 20% | 1% ± 2% | 71% ± 19% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 99% ± 2% | 0% ± 0% |
| zenkutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 99% ± 2% |
| Technique | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 90% ± 13% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 6% ± 10% | 3% ± 5% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 0% ± 0% | 87% ± 11% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 6% ± 7% | 0% ± 0% | 7% ± 9% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 0% ± 0% | 0% ± 0% | 93% ± 11% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 7% ± 11% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| mae-geri | 0% ± 0% | 1% ± 2% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 97% ± 5% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% |
| soto-uke | 0% ± 0% | 0% ± 0% | 2% ± 5% | 0% ± 0% | 0% ± 0% | 2% ± 5% | 81% ± 26% | 14% ± 19% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 0% ± 0% | 1% ± 2% | 5% ± 7% | 0% ± 0% | 0% ± 0% | 8% ± 11% | 1% ± 2% | 86% ± 10% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 99% ± 2% | 0% ± 0% |
| zenkutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 99% ± 2% |
| Technique | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 91% ± 11% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 2% ± 2% | 3% ± 5% | 4% ± 7% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 0% ± 0% | 92% ± 9% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 6% ± 7% | 0% ± 0% | 3% ± 6% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 0% ± 0% | 0% ± 0% | 95% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 5% ± 7% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| mae-geri | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 96% ± 5% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% |
| soto-uke | 0% ± 0% | 0% ± 0% | 5% ± 11% | 0% ± 0% | 0% ± 0% | 2% ± 4% | 86% ± 21% | 8% ± 11% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 2% ± 5% | 0% ± 0% | 98% ± 5% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 99% ± 2% | 0% ± 0% |
| zenkutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 99% ± 2% |
| Technique | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 96% ± 4% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 1% ± 2% | 2% ± 4% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 0% ± 0% | 93% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 7% ± 7% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 0% ± 0% | 0% ± 0% | 94% ± 12% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 6% ± 12% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| mae-geri | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 97% ± 5% | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% |
| soto-uke | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 96% ± 7% | 4% ± 7% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 2% ± 4% | 0% ± 0% | 98% ± 4% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% | 98% ± 2% | 0% ± 0% |
| zenkutsu-dachi | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 99% ± 2% |
| Technique | Gedan-Barai | Hiza-Geri | Jodan-Uke | Kiba-Dachi | Kokutsu-Dachi | Mae-Geri | Soto-Uke | Uchi-Uke | Yoko-Geri | Zenkutsu-Dachi |
|---|---|---|---|---|---|---|---|---|---|---|
| gedan-barai | 94% ± 7% | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 1% ± 2% | 2% ± 5% | 0% ± 0% | 0% ± 0% |
| hiza-geri | 0% ± 0% | 92% ± 9% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 6% ± 7% | 0% ± 0% | 3% ± 6% | 0% ± 0% | 0% ± 0% |
| jodan-uke | 0% ± 0% | 0% ± 0% | 96% ± 8% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 4% ± 8% | 0% ± 0% | 0% ± 0% |
| kiba-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| kokutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 100% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% |
| mae-geri | 0% ± 0% | 2% ± 4% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 97% ± 5% | 0% ± 0% | 2% ± 2% | 0% ± 0% | 0% ± 0% |
| soto-uke | 0% ± 0% | 0% ± 0% | 3% ± 5% | 0% ± 0% | 0% ± 0% | 2% ± 5% | 90% ± 17% | 5% ± 7% | 0% ± 0% | 0% ± 0% |
| uchi-uke | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 5% ± 9% | 0% ± 0% | 94% ± 8% | 0% ± 0% | 0% ± 0% |
| yoko-geri | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 0% ± 0% | 99% ± 2% | 0% ± 0% |
| zenkutsu-dachi | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 0% ± 0% | 1% ± 2% | 0% ± 0% | 99% ± 2% |
References
- Chatzis, S.P.; Kosmopoulos, D.I.; Doliotis, P. A conditional random field-based model for joint sequence segmentation and classification. Pattern Recognit. 2013, 46, 1569–1578. [Google Scholar]
- Yang, X.; Tian, Y. Effective 3D action recognition using EigenJoints. J. Visual Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Boubou, S.; Suzuki, E. Classifying actions based on histogram of oriented velocity vectors. J. Intell. Inf. Syst. 2015, 44, 49–65. [Google Scholar] [CrossRef]
- Celiktutan, O.; Akgul, C.B.; Wolf, C.; Sankur, B. Graph-based analysis of physical exercise actions. In Proceedings of the 1st ACM international workshop on Multimedia indexing and information retrieval for healthcare (MIIRH ′13), Barcelona, Catalunya, Spain, 21–25 October 2013; pp. 23–32.
- Miranda, L.; Vieira, T.; Martínez, D.; Lewiner, T.; Vieira, A.W.; Campos, M.F.M. Online gesture recognition from pose kernel learning and decision forests. Pattern Recognit. Lett. 2014, 39, 65–73. [Google Scholar] [CrossRef]
- López-Méndez, A.; Casas, J.R. Model-based recognition of human actions by trajectory matching in phase spaces. Image Vis. Comput. 2012, 30, 808–816. [Google Scholar] [CrossRef]
- Jiang, X.; Zhong, F.; Peng, Q.; Qin, X. Online robust action recognition based on a hierarchical model. Visual Comput. 2014, 30, 1021–1033. [Google Scholar] [CrossRef]
- Kviatkovsky, I.; Rivlin, E.; Shimshoni, I. Online action recognition using covariance of shape and motion. Comput. Vis. Image Underst. 2014, 129, 15–26. [Google Scholar] [CrossRef]
- Theodorakopoulos, I.; Kastaniotis, D.; Economou, G.; Fotopoulos, S. Pose-based human action recognition via sparse representation in dissimilarity space. J. Visual Commun. Image Represent. 2014, 25, 12–23. [Google Scholar] [CrossRef]
- Nyirarugira, C.; Kim, T.Y. Stratified gesture recognition using the normalized longest common subsequence with rough sets. Signal Process. Image Commun. 2015, 30, 178–189. [Google Scholar] [CrossRef]
- Hachaj, T.; Ogiela, M.R. Rule-based approach to recognizing human body poses and gestures in real time. Multimed. Syst. 2014, 20, 81–99. [Google Scholar] [CrossRef]
- Meinard, M. Information Retrieval for Music and Motion; Springer: Heidelberg, Germany, 2007. [Google Scholar]
- Arici, T.; Celebi, S.; Aydin, A.S.; Temiz, T.T. Robust gesture recognition using feature pre-processing and weighted dynamic time warping. Multimed. Tools Appl. 2014, 72, 3045–3062. [Google Scholar] [CrossRef]
- Barnachon, M.; Bouakaz, S.; Boufama, B.; Guillou, E. Ongoing human action recognition with motion capture. Pattern Recognit. 2014, 47, 238–247. [Google Scholar] [CrossRef]
- Su, C.-J.; Chiang, C.-Y.; Huang, J.-Y. Kinect-enabled home-based rehabilitation system using Dynamic Time Warping and fuzzy logic. Appl. Soft Comput. 2014, 22, 652–666. [Google Scholar] [CrossRef]
- Pham, H.-T.; Kim, J.-J.; Nguyen, T.L.; Won, Y. 3D motion matching algorithm using signature feature descriptor. Multimed. Tools Appl. 2015, 74, 1125–1136. [Google Scholar] [CrossRef]
- Głowacz, A.; Głowacz, W. DC machine diagnostics based on sound recognition with application of LPC and Fuzzy Logic. Prz. Elektrotech. Electr. Rev. 2009, 85, 112–115. [Google Scholar]
- Głowacz, A.; Głowacz, W. Diagnostics of Direct Current motor with application of acoustic signals, reflection coefficients and K-Nearest Neighbor classifier. Prz. Elektrotech. Electr. Rev. 2012, 88, 231–233. [Google Scholar]
- Mead, R.; Atrash, A.; Matarić, M.J. Automated Proxemic Feature Extraction and Behavior Recognition: Applications in Human-Robot Interaction. Int. J. Soc. Robot. 2013, 5, 367–378. [Google Scholar] [CrossRef]
- Kosmopoulos, D.; Papoutsakis, K.; Argyros, A. Online segmentation and classication of modeled actions performed in the context of unmodeled ones. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014.
- Chan-Hon-Tong, A.; Achard, C.; Lucat, L. Simultaneous segmentation and classification of human actions in video streams using deeply optimized Hough transform. Pattern Recognit. 2014, 47, 3807–3818. [Google Scholar] [CrossRef]
- Hoai, M.; Lan, Z.; de la Torre, F. Joint segmentation and classication of human actions in video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 20–25 June 2011; pp. 3265–3272.
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3d convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Le, Q.; Ngiam, J.; Chen, Z.; Chia, D.; Koh, P.; Ng, A. Tiled convolutional neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 6–11 December 2010; pp. 1279–1287.
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Wei, H.; Ferryman, J. A survey of human motion analysis using depth imagery. Pattern Recognit. Lett. 2013, 34, 1995–2006. [Google Scholar] [CrossRef]
- Wang, B.; Li, Z.; Ye, W.; Xie, Q. Development of human-machine interface for teleoperation of a mobile manipulator. Int. J. Control Autom. Syst. 2012, 10, 1225–1231. [Google Scholar] [CrossRef]
- Jagodziński, P.; Wolski, R. Assessment of Application Technology of Natural User Interfaces in the Creation of a Virtual Chemical Laboratory. J. Sci. Educ. Technol. 2015, 24, 16–28. [Google Scholar] [CrossRef]
- Galna, B.; Barry, G.; Jackson, D.; Mhiripiri, D.; Olivier, P.; Rochester, L. Accuracy of the Microsoft Kinect sensor for measuring movement in people with Parkinson’s disease. Gait Posture 2014, 39, 1062–1068. [Google Scholar] [CrossRef] [PubMed]
- Kongsro, J. Estimation of pig weight using a Microsoft Kinect prototype imaging system. Comput. Electron. Agric. 2014, 109, 32–35. [Google Scholar] [CrossRef]
- Mastorakis, G.; Makris, D. Fall detection system using Kinect’s infrared sensor. J. Real Time Image Process. 2014, 9, 635–646. [Google Scholar] [CrossRef]
- Planinc, R.; Kampel, M. Introducing the use of depth data for fall detection. Pers. Ubiquitous Comput. 2013, 17, 1063–1072. [Google Scholar] [CrossRef]
- Won, A.S.; Bailenson, J.N.; Stathatos, S.C.; Dai, W. Automatically Detected Nonverbal Behavior Predicts Creativity in Collaborating Dyads. J. Nonverbal Behav. 2014, 38, 389–408. [Google Scholar] [CrossRef]
- Xu, X.; Ke, F. From psychomotor to “motorpsycho”: Learning through gestures with body sensory technologies. Educ. Technol. Res. Dev. 2014, 62, 711–741. [Google Scholar] [CrossRef]
- Hachaj, T.; Baraniewicz, D. Knowledge Bricks—Educational immersive reality environment. Int. J. Inf. Manag. 2015. [Google Scholar] [CrossRef]
- Clark, R.A.; Pua, Y.H.; Fortin, K.; Ritchie, C.; Webster, K.E.; Denehy, L.; Bryant, A.L. Validity of the Microsoft Kinect for assessment of postural control. Gait Posture 2012, 36, 372–377. [Google Scholar] [CrossRef] [PubMed]
- Song, X.; Zhong, F.; Wang, Y.; Qin, X. Estimation of Kinect depth confidence through self-training. Visual Comput. 2014, 30, 855–865. [Google Scholar] [CrossRef]
- Kolahi, A.; Hoviattalab, M.; Rezaeian, T.; Alizadeh, M.; Bostan, M.; Mokhtarzadeh, H. Design of a marker-based human motion tracking system. Biomed. Signal Process. Control 2007, 2, 59–67. [Google Scholar] [CrossRef]
- Ilg, W.; Mezger, J.; Giese, M. Estimation of Skill Levels in Sports Based on Hierarchical Spatio-Temporal Correspondences. Pattern Recognit. 2003, 2781, 523–531. [Google Scholar]
- Stasinopoulos, S.; Maragos, P. Human action recognition using Histographic methods and hidden Markov models for visual martial arts applications. In Proceedings of the 2012 19th IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012.
- Bianco, S.; Tisato, F. Karate moves recognition from skeletal motion. In Proceedings of the SPIE 8650, Three-Dimensional Image Processing (3DIP) and Applications 2013, Burlingame, CA, USA, 12 March 2013.
- Hachaj, T.; Ogiela, M.R.; Piekarczyk, M. Dependence of Kinect sensors number and position on gestures recognition with Gesture Description Language semantic classifier. In Proceedings of the 2013 Federated Conference on Computer Science and Information Systems, Krakow, Poland, 8–11 September 2013; pp. 571–575.
- Hachaj, T.; Ogiela, M.R. Full-body gestures and movements recognition: User descriptive and unsupervised learning approaches in GDL classifier. In Proceedings of the SPIE 9217, Applications of Digital Image Processing XXXVII, San Diego, CA, USA, 23 September 2014.
- Ogiela, M.R.; Hachaj, T. Natural User Interfaces in Medical Image Analysis: Advances in Computer Vision and Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Accord.NET Framework. Available online: http://accord-framework.net/ (accessed on 1 September 2015).
- GDL Technology. Available online: http://cci.up.krakow.pl/gdl/ (accessed on 1 September 2015).
- Obdržálek, Š.; Kurillo, G.; Ofli, F.; Bajcsy, R.; Seto, E.; Jimison, H.; Pavel, M. Accuracy and Robustness of Kinect Pose Estimation in the Context of Coaching of Elderly Population. In Proceedings of the 34th International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), San Diego, CA, USA, 28 August–1 September 2012.
- Vignais, N.; Kulpa, R.; Brault, S.; Presse, D.; Bideau, B. Which technology to investigate visual perception in sport: Video vs. virtual reality. Human Mov. Sci. 2015, 39, 12–26. [Google Scholar] [CrossRef] [PubMed]
- Piorkowski, A.; Jajesnica, L.; Szostek, K. Computer Networks. Commun. Comput. Inf. Sci. 2009, 39, 218–224. [Google Scholar]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hachaj, T.; Ogiela, M.R.; Koptyra, K. Application of Assistive Computer Vision Methods to Oyama Karate Techniques Recognition. Symmetry 2015, 7, 1670-1698. https://doi.org/10.3390/sym7041670
Hachaj T, Ogiela MR, Koptyra K. Application of Assistive Computer Vision Methods to Oyama Karate Techniques Recognition. Symmetry. 2015; 7(4):1670-1698. https://doi.org/10.3390/sym7041670
Chicago/Turabian StyleHachaj, Tomasz, Marek R. Ogiela, and Katarzyna Koptyra. 2015. "Application of Assistive Computer Vision Methods to Oyama Karate Techniques Recognition" Symmetry 7, no. 4: 1670-1698. https://doi.org/10.3390/sym7041670
APA StyleHachaj, T., Ogiela, M. R., & Koptyra, K. (2015). Application of Assistive Computer Vision Methods to Oyama Karate Techniques Recognition. Symmetry, 7(4), 1670-1698. https://doi.org/10.3390/sym7041670