2.1. Sampled Areas and Materials
For this study, 80 samples of clays outcropping in the vicinity of the selected villages were taken into account (
Table 1). All of them are geological Cenozoic formations, the exact extraction points of clay were determined through existing bibliography [
21,
22] and oral sources. When original extraction points were no longer available, sampling was performed on nearby equivalent geological outcrops (
Figure 2). The sampled materials for every village were:
Esparreguera: red clays (six samples) from decimetric layers inserted in proximal alluvial fan deposits belonging to the northern margin of the Vallès-Penedès basin (Miocene epoch, Vallesian age (11.2–8.9 Ma)). Additionally, four samples of the fault flour outcropping at the edge of the basin margin, in the main normal Vallès-Penedès fault, were also sampled as this material was traditionally added to the red clays [
1].
La Bisbal: ochre and red clays deposited in an alluvial plain environment (also Miocene epoch, Vallesian age) connected to the Gavarres massif. (17 samples)
Quart: red clay levels within arkosic sandstones (possibly Pliocene) that belong to a system of alluvial fans linked to the Gavarres massif. (11 samples)
Breda: red, black and white clays from relatively thin levels within sandstones (early Pliocene, ~5 Ma) deposited in an alluvial fan environment with predominance of igneous and metamorphic clasts from Variscan granitoids and the uplifted palaeozoic basement. (11 samples).
Verdú: grey and red clayey and calcareous marls from an environment of distal alluvial fans and lacustrine limestones (Oligocene epoch, Chattian/Rupelian age (~28 Ma)) (23 samples).
Sant Julià: red clays from relatively thin levels within sandstones and conglomerates (Eocene epoch, possibly Lutetian, ~45 Ma) deposited in an alluvial fan proximal environment. Initially 18 samples were obtained but 10 resulted to bear a high CaCO3 content (>25 wt.%) inconsistent with the Ca content of the corresponding ceramics and therefore they were discarded. These 10 samples possibly belong to a nearby formation of calcareous red marls. Therefore, eight samples were retained from Sant Julià.
Sampling of clays was performed by removing organic and soils layers and focusing on clays thin layers (avoiding coarser sized layers). However, most clay samples contain actually silt and very fine sand fractions. Nevertheless, the clay samples were neither sieved nor levigated because silt and sand fractions were also present on many pottery samples.
Besides the clay samples from the six selected areas, 101 samples of pottery likely produced by firing clays from the sampled formations were taken into account (
Table 1). The pottery shards were obtained through local museums, active pottery workshops, local historians and retired potters. The selection criterion was the high probability that the pottery was really produced using local clays. For the Breda pottery samples, the presence of ceramic stamps even allowed the identification of the local potter and the production period (19–20th century) [
23]. Pottery samples from Sant Julià are dated in the 17th century, and those from Esparreguera, Quart, and Bisbal are also from the 19–20th century like Breda. Finally, 27 extra newly produced pottery samples were added to samples from each locality (3–6 per studied site). These were prepared in form of small ceramic briquettes from local clays, firing them in a gasoil kiln during 10 h (including the heating ramp) reaching a maximum temperature of ~1000 °C for 2 h.
2.3. EDXRF Analysis
Besides basic mineralogical and petrographic characterization, the main analytical tool used has been Energy Dispersive X-ray fluorescence to obtain the required elemental data. That is the data that has been used to apply different statistical methods to identify a distinct geochemical fingerprint for each studied rural town (including their clays and pottery). Common sample preparation for geological materials and earthen objects has been undertaken consisting in the conversion of solid powdered samples into flat surface pellet specimens. Clays were first oven dried at 60 °C until constant weight. Glaze from glazed pottery shards was completely removed by scraping it using a drill. The shards were also oven dried as the clays and afterwards they were ground using a laboratory mill (Pulverissette™, Fritsch GmbH, Idar-Oberstein, Germany) to pass a 125 µm mesh.
Clay and pottery powders for analysis were prepared as pressed powder pellets following the methodology reported in [
24] and using a methyl-methacrylate resin as a binding agent. 5 g of sample were mixed and homogenized with 0.8 g of binder (Elvacite™ commercial resin). The resulting powder was poured into a pressing die (40 mm in diameter) and pressed at a pressure of 20 T. The resulting pellet of tablet was then ready for analysis.
A commercially available benchtop EDXRF spectrometer (S2 Ranger, Bruker/AXS, GmbH, Karlsruhe, Germany) was used in the present study. This instrument is equipped with a Pd target X-ray tube (50 W power max.) and a XFLASH™ LE Silicon Drift Detector (SDD), ultra-thin beryllium window (0.3 μm thickness) with a resolution lower than 129 eV at Mn-Kα line for a count rate of 100,000 counts-per-second (cps). In this LE configuration of SDD detectors, the intensities for Na K-alpha and Mg K-alpha are, respectively, close to around four times higher than the intensity recorded by conventional SDD detectors. The instrument is also equipped with nine primary filters that can be used in front of the tube before X-ray beam reaches the sample surface in order to improve measuring conditions for the elements of interest and it can operate under vacuum conditions.
The software used to control the equipment, to build calibrations, and to perform spectral data treatment was SPECTRA.EDX package (Bruker AXS, GmbH, Karlsruhe, Germany). This software can perform the full line profile fitting, deconvolutions when lines overlap, intensity corrections for inter-elemental effects and qualitative, semiquantitative or full-quantitative routines.
All the samples were analyzed to obtain a spectrum for the identification of all the elements present in samples. Quantification was made by the assisted fundamental parameters approach included in the above-mentioned software using certified BAS BCS-315 and ECRM 776-1 firebricks as reference materials. Analysis was made in a vacuum atmosphere allowing better detection of low Z elements and using different conditions of voltage to properly excite low, medium and high atomic number elements existing at the samples. Current was automatically adjusted to obtain a fixed counting rate of 100,000 cps. Total measuring time was set at 400 s as a trade-off between an acceptable repeatability of measurements and total analysis time.
The net intensity of each analytical line was calculated by subtracting the theoretical background adjusted by a polynomial function to the obtained experimental spectra.
2.4. Data Processing
Data processing was performed using available scripts from RStudio (the integrated development environment for R software). In rough outlines, all the samples (both clays and baked clays) display similar assemblies of elements. From the obtained data, only those elements present (above their detection limit) have been taken into account. Besides that, Ca, S and Pb values have been disregarded, the first (Ca) because it shows a very strong inverse correlation with Si values, S because it shows a very high dispersion with many samples exhibiting values below the corresponding detection limit and Pb due to evidence of contamination from glazes in glazed pottery, even after glaze removal. The list of elements that have been taken into account to test several statistical machine learning approaches to classify geochemically the samples from each village have been: Al, Si, Fe, Na, Mg, Cl, K, Ti, Cr, Mn, Ni, Cu, Zn, Rb, Sr, Y, Zr, and Nb. Both unsupervised and supervised modeling of data has been applied to the datasets containing values for this list of elements.
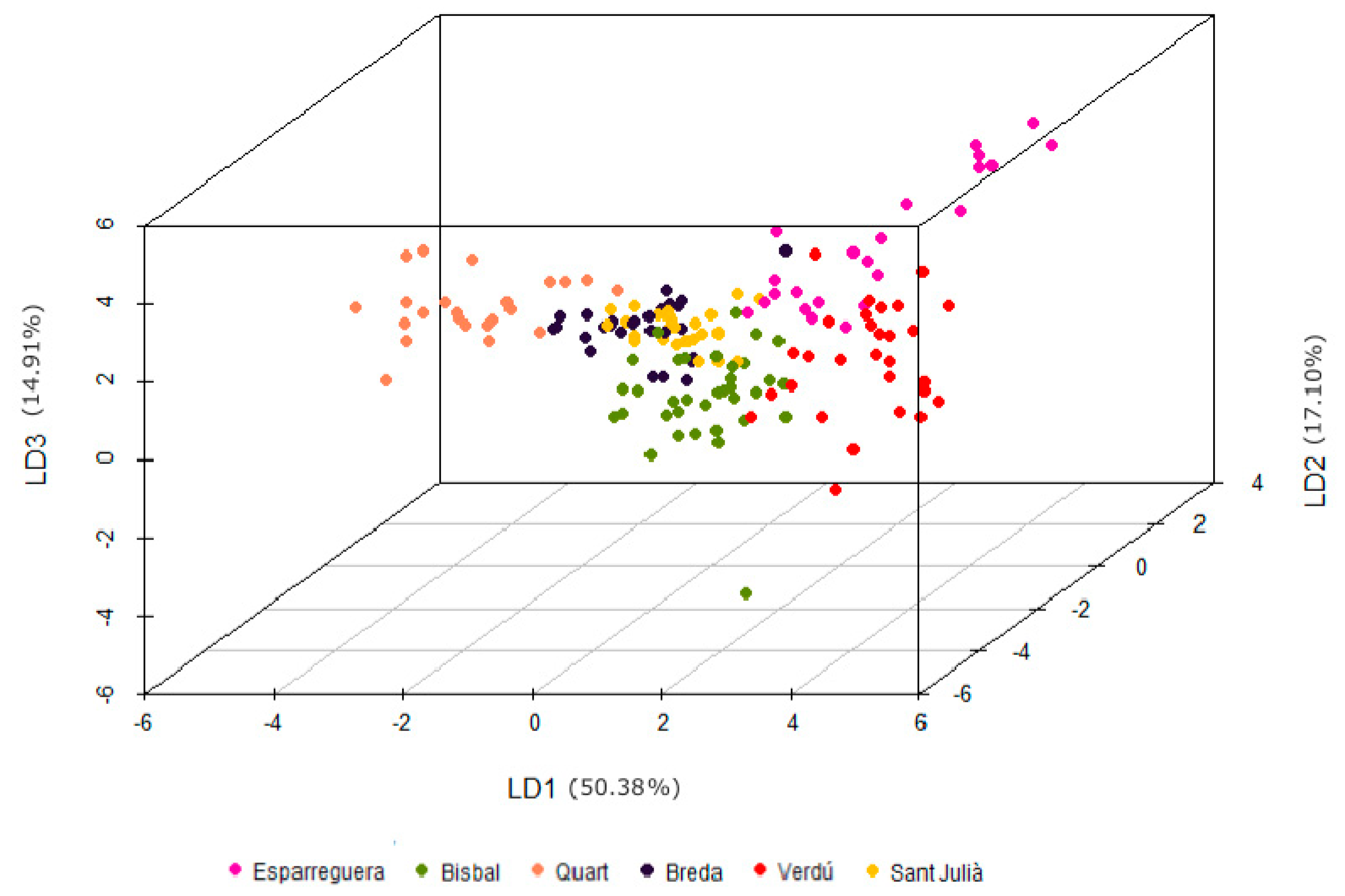
Unsupervised learning is a way of organizing data that helps to find previously unknown patterns in datasets without pre-existing class labels. In contrast, supervised machine-learning relies on prior knowledge of the class labels. Some unsupervised methods, and particularly principal component analysis (PCA), are widely used in archaeometry to facilitate the identification of compositional groups and determining the chemical basis of group separation and extensive literature can be found on the subject. In contrast the use of supervised methods is quite scarce. However, some incursions within the supervised methods domain had also been done previously, from the pioneering works of [
17,
25] to much more recent papers [
26,
27,
28] that focus particularly on the artificial neural network (ANN) approach.
In the processing of the obtained data some unsupervised models have been tested and, as it will be shown, all of them fail to produce data groups with good correlation with the real classes. The widely used hierarchical cluster analysis (HCA), k-means and PCA will be used to illustrate the low performance of such models. The HCA algorithm produces a tree diagram (dendrogram) according to a given metric and linkage criterion (e.g., [
29,
30]), the k-means algorithm identifies k clusters from a given dataset, every cluster is identified with a centroid and the corresponding data, the algorithm basically tries to keep inter-cluster data as similar as possible, while the centroids are as different as possible [
31]. PCA logic is based on the concepts of linear correlation and variance. PCA is a dimensionality reduction technique, starting with the features (i.e., the chemical values) describing a set of objects (i.e., our samples), the target defines other variables that are linearly uncorrelated with each other. The output is a new set of variables defined as linear combinations of the initial features. The new variables are ranked on the basis of their relevance. The number of the new variables is less than or equal to the initial number of features and it is possible to select the most relevant features. Then, it is possible to define a smaller set of features, reducing the problem dimension, see page 169 in [
32].
Taking into account that the provenance of the analyzed samples is known (i.e., the class labels are known for each object) supervised models can also be used to process the data. Starting from the whole experimental dataset, it is possible to constitute a training dataset [
26]. The labelled geochemical data is then used to build models that proxy for class characteristics. After optimization of the model parameters, the model is finally tested with new objects. The best performing predictive model can be selected looking at their ability to predict class memberships for these new objects. In this study, an 80% portion of the total dataset was used to train the models and the remaining data was used for model testing. The dataset was divided randomly using a specific seed in such a way that all the models tested in this study use the same train and test sets. The performance of the different tested models was evaluated using the widely employed confusion or error matrix [
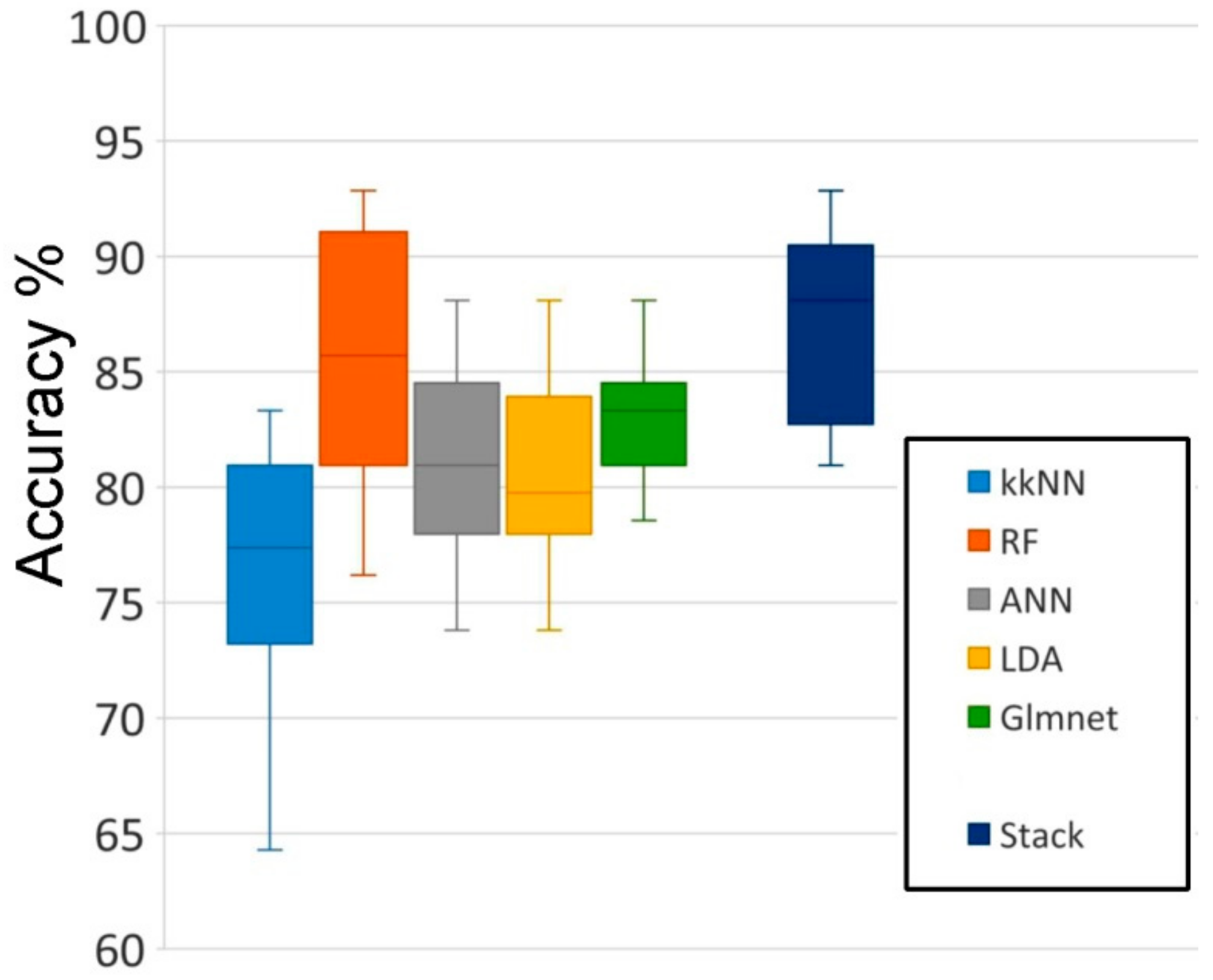
33], where each row represents the distribution of samples from an actual class among the predicted classes organized in columns (or vice versa). As the predicted and actual classes are presented in the same order, the successful predictions (usually called hits or true positives) concentrate along the main diagonal of the matrix, whilst unsuccessful predictions lie outside the diagonal. Additionally, an overall value of accuracy was computed as the ratio between hits and the total number of objects (i.e., samples). An overall accuracy value of 1 would indicate 100% of success and therefore no errors.
Predictive modeling of the training set was conducted using five machine learning algorithms and finally a combination of all them. These algorithms were called from packages within the freely available Caret R library:
Weighted k-nearest neighbors (kkNN) [
34], its basic idea is that a new object will be classified according to the class that have their k-nearest neighbors. The R package used was class.
Random forest (RF) [
35,
36], this algorithm is based on the concept of decision tree (a series of yes/no questions asked to the data that in the end lead to a predicted class). The RF model deals with many decision trees (i.e., a forest) using random sampling to build the trees and random subsets of features when splitting nodes of the trees. The R package used was randomForest.
Artificial neural network (ANN) [
37], a mathematical mimic of human learning where individual processing elements are organized in layers. The input layer receives the weighted values of the features of an object to produce new values through so called activation functions; these values will be also weighted and transferred to new layers until reaching the output which is made of as many elements as classes. The obtained values are used to assign a class to the object. The R package used was nnet.
Linear discriminant analysis (LDA) [
38,
39], similarly to the PCA logic, delineates a new set of variables defined as linear combinations of the initial features reducing the dimensionality of the problem, but instead of looking for the maximum variance, LDA maximizes the separability among classes (the distance between their means) and simultaneously minimizes the internal scatter within each class. The R package used was lda.
Generalized linear models (Glmnet) [
40,
41]. These are generalization models of a linear relationship between the output variable (class) and a set of input variables (features) where the distribution of the output variable can be non-normal and non-continuous and the function linking input and output variables can be more complex than a simple identity function. Specifically, the Glmnet algorithm incorporates regularization (i.e., reduction of variance) by the lasso and elastic-net methods to avoid overfitting (i.e., noise fitting). The R package used was Glmnet.
Stack of models. With the aim of improving the accuracy of the predictions, information from multiple models (i.e., a stack of models, see [
42]) was used to generate a new model using a random forest approach to the predictions from different models. The R package used was randomForest.
All these models, including the stack of models, were optimized during the training step. This was done following a homogeneous approach for all the models and included a first phase of traincontrol using the repeatedcv method:
fit_control<-trainControl(method="repeatedcv",number=10,repeats=2,savePredictions="final",classProbs=TRUE)
preproc=c("center","scale")
Then, in a second phase, the best optimizable parameters to improve the attained accuracy were automatically spotted with code lines as in the following example:
BASE.lrm<-train(target~.,Dataset[train,],method="glmnet",metric="Accuracy",preProc=preproc,trControl=fit_control)












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}