Process Variable Importance Analysis by Use of Random Forests in a Shapley Regression Framework


Abstract
:1. Introduction
2. Shapley Regression
2.1. Methodology
2.2. Axiomatic Properties of Shapley Values
3. Random Forests
3.1. Decision Trees
3.2. Ensembles of Decision Trees
- From the data, draw bootstrap samples.
- Grow a tree for each of the sets of bootstrap samples. For each tree (, randomly select variables for splitting at each node of the tree. Each terminal node in this tree should have no fewer than cases.
- Aggregate information from the trees for new data prediction, according to Equations (3) and (4).
- Compute an out-of-bag (OOB) error rate based on the data not in the bootstrap sample.
3.3. Splitting Criteria
4. Variable Importance Measures
4.1. Shapley Variable Importance with Random Forests and Linear Regression Models
4.2. Permutation Variable Importance
4.3. Gini Variable Importance
5. Case Studies
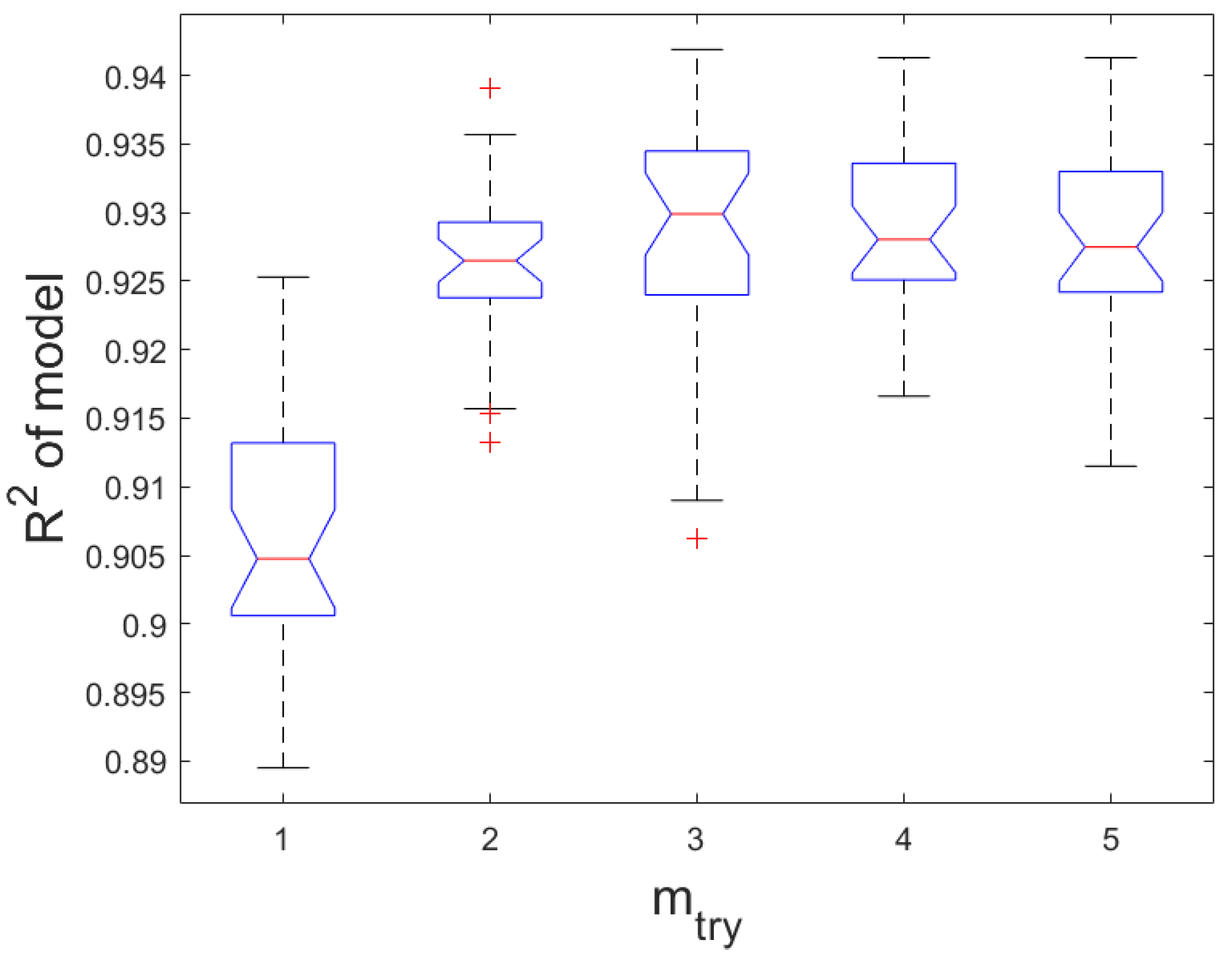
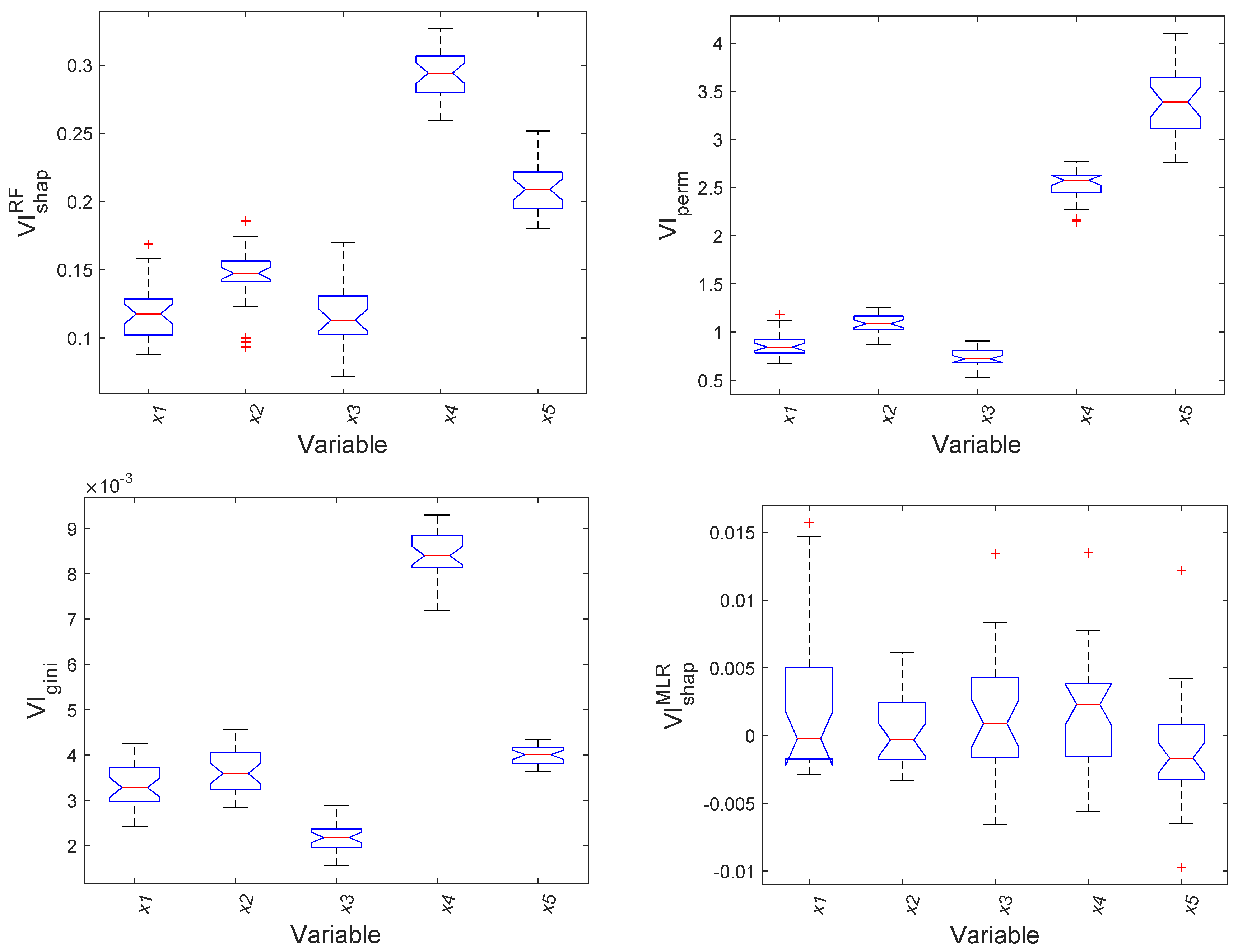
5.1. Linear System with Weakly Correlated Predictors
5.2. Nonlinear System with Strongly Correlated Predictors
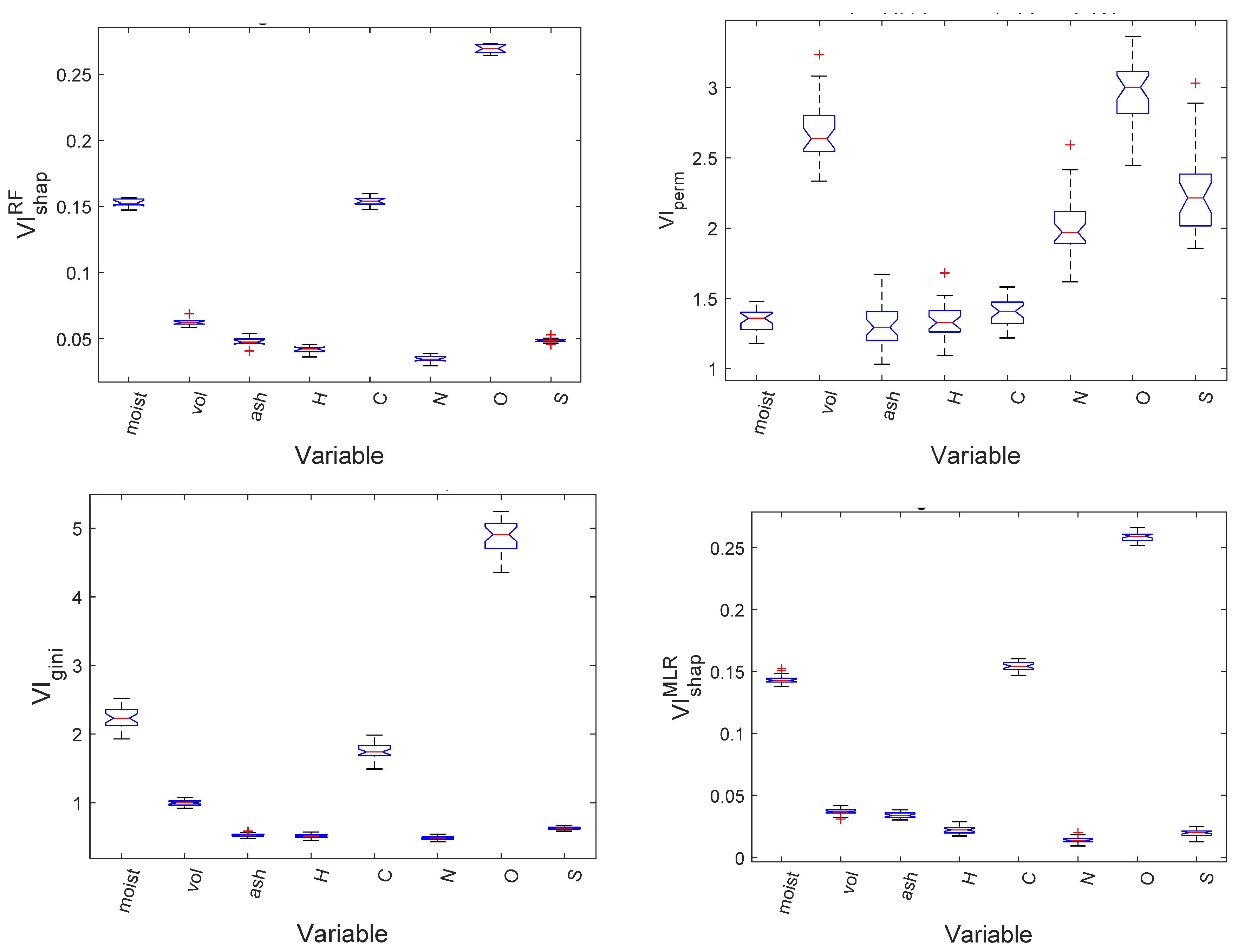
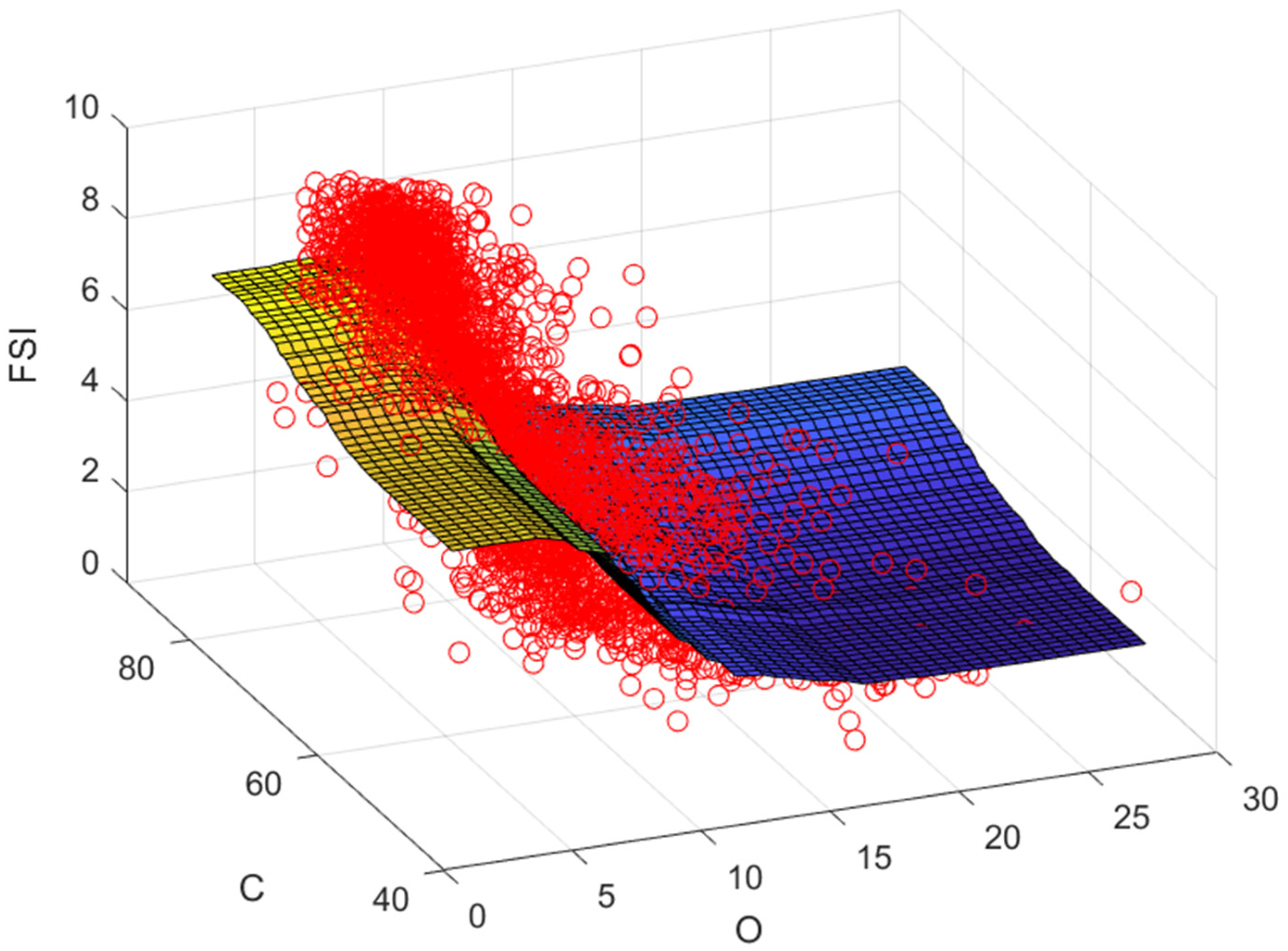
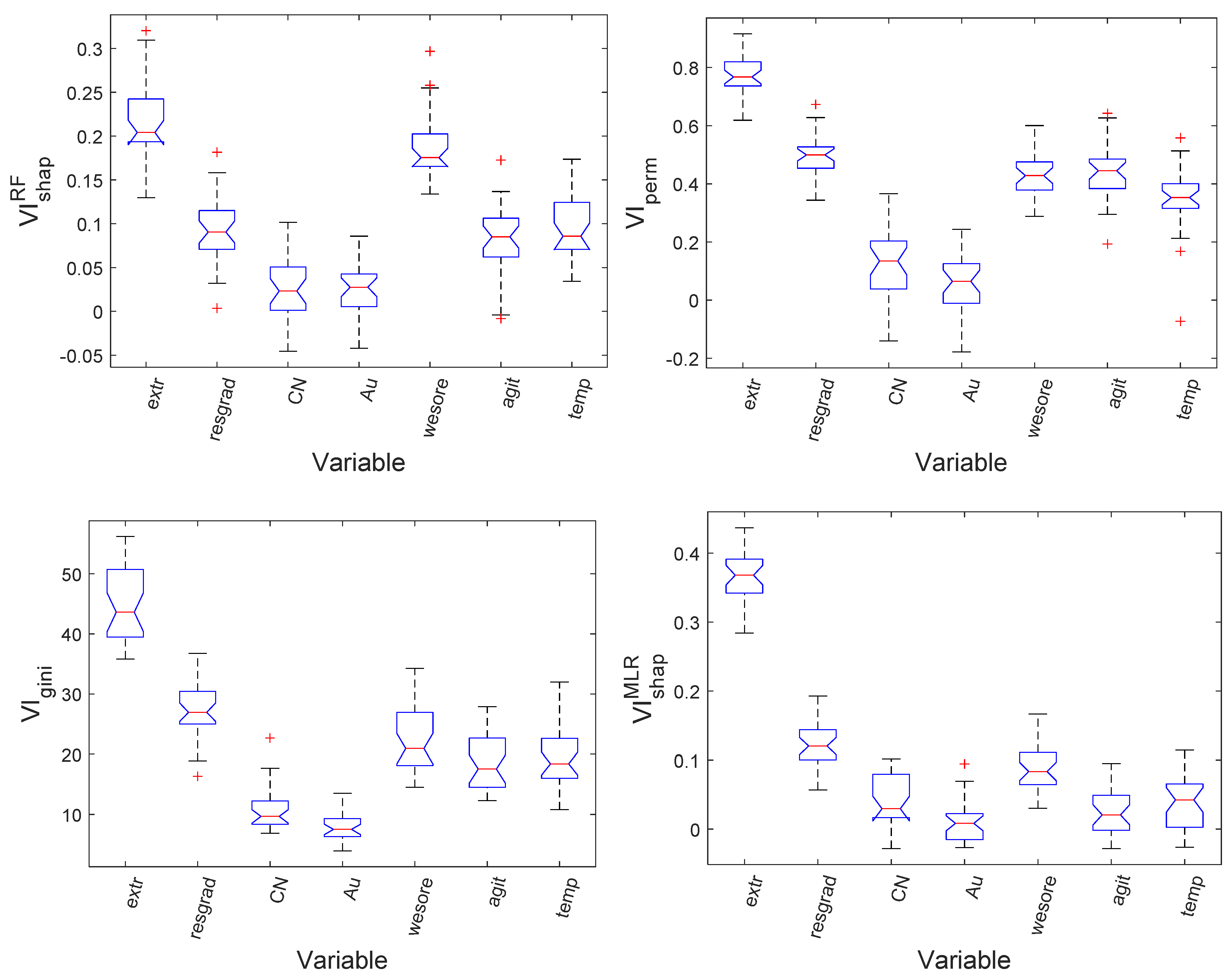
5.3. Free Swelling Index of Coal
5.4. Consumption of Leaching Reagent in a Gold Circuit
6. Discussion and Conclusions
Funding
Conflicts of Interest
References
- Suriadi, S.; Leemans, S.J.J.; Carrasco, C.; Keeney, L.; Walters, P.; Burrage, K.; ter Hofstede, A.H.M.; Wynn, M.T. Isolating the impact of rock properties and operational settings on minerals processing performance: A data-driven approach. Miner. Eng. 2018, 122, 53–66. [Google Scholar] [CrossRef] [Green Version]
- Lipovetsky, S.; Conklin, M. Analysis of regression in game theory approach. Appl. Stoch. Models Bus. Ind. 2001, 17, 319–330. [Google Scholar] [CrossRef]
- Israeli, O. A Shapley-based decomposition of the R-Square of a linear regression. J. Econ. Inequal. 2007, 5, 199–212. [Google Scholar] [CrossRef]
- Grömping, U. Variable importance in regression models. Comput. Stat. 2015, 7, 137–152. [Google Scholar] [CrossRef]
- Budescu, D.V. Dominance analysis: A new approach to the problem of relative importance of predictors in multiple regression. Psychol. Bull. 1993, 114, 542–551. [Google Scholar] [CrossRef]
- Kruskal, W. Relative importance by analyzing over orderings. Am. Stat. 1987, 41, 6–10. [Google Scholar]
- Auret, L.; Aldrich, C. Interpretation of nonlinear relationships between process variables by use of random forests. Miner. Eng. 2012, 35, 27–42. [Google Scholar] [CrossRef]
- Aldrich, C. Consumption of steel grinding media in mills—A review. Miner. Eng. 2013, 49, 77–91. [Google Scholar] [CrossRef]
- Tohry, A.; Chelgani, S.C.; Matin, S.S.; Noorhammadi, M. Power-draw prediction by random forest based on operating parameters for an industrial ball mill. Adv. Powder Technol. 2019, 31, 967–972. [Google Scholar] [CrossRef]
- Bardinas, J.P.; Aldrich, C.; Napier, L.F.A. Predicting the operational states of grinding circuits by use of recurrence texture analysis of time series data. Processes 2018, 6, 17. [Google Scholar] [CrossRef] [Green Version]
- Shahbazi, B.; Chelgani, S.C.; Matin, S. Prediction of froth flotation responses based on various conditioning parameters by random forest method. Colloids Surf. A Physicochem. Eng. Asp. 2017, 529, 936–941. [Google Scholar] [CrossRef]
- Pu, Y.; Szmigiel, A.; Apel, D.B. Purities prediction in a manufacturing froth flotation plant: The deep learning techniques. Neural Comput. Appl. 2020, 2020, 1–11. [Google Scholar] [CrossRef]
- He, Z.; Tang, Z.; Yan, Z.; Liu, J. DTCWT-based zinc fast roughing working condition identification. Chin. J. Chem. Eng. 2018, 26, 1721–1726. [Google Scholar] [CrossRef]
- Nazari, S.; Chehreh Chelgani, S.Z.; Shafaei, B.; Shahbazi, S.S.; Matin, M. Gharabaghi, Flotation of coarse particles by hydrodynamic cavitation generated in the presence of conventional reagents. Sep. Purif. Technol. 2019, 220, 61–68. [Google Scholar] [CrossRef]
- Fu, Y.; Aldrich, C. Flotation froth image analysis by use of a dynamic feature extraction algorithm. IFAC-PapersOnLine 2016, 49, 84–89. [Google Scholar] [CrossRef]
- Aldrich, C.; Smith, L.K.; Verrelli, D.I.; Bruckard, W.J.; Kistner, M. Multivariate image analysis of a realgar-orpiment froth flotation system. Miner. Process. Extr. Metall. Trans. C. 2018, 127, 146–156. [Google Scholar]
- Tuşa, L.; Kern, M.; Khodadadzadeh, R.; Blannin, R.; Gloaguen, R.; Gutzmer, J. Evaluating the performance of hyperspectral short-wave infrared sensors for the pre-sorting of complex ores using machine learning methods. Miner. Eng. 2020, 146, 106150. [Google Scholar]
- Ohadi, B.; Sun, X.; Esmaieli, K.; Consens, S.P. Predicting blast-induced outcomes using random forest models of multi-year blasting data from an open pit mine. Bull. Eng. Geol. Environ. 2020, 79, 329–343. [Google Scholar] [CrossRef]
- Azen, R.; Budescu, D.V. The dominance analysis approach for comparing predictors in multiple regression. Psychol. Methods 2003, 8, 129–148. [Google Scholar] [CrossRef]
- Huettner, F.; Sunder, M. Axiomatic arguments for decomposing goodness of fit according to Shapley and Owen values. Electron. J. Stat. 2012, 6, 1239–1250. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Strobl, C.; Malley, J.; Tutz, G. An introduction to recursive partitioning: Rationale, application, and characteristics of classification and regression trees, bagging, and random forests. Psychol. Methods 2009, 14, 323–348. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carranza, E.J.M.; Laborte, A.G. Random forest predictive modelling of mineral prospectivity with small number of prospects and data with missing values in Abra (Philippines). Comput. Geosci. 2015, 74, 60–70. [Google Scholar] [CrossRef]
- Aldrich, C.; Auret, L. Fault detection and diagnosis with random forest feature extraction and variable importance methods. IFAC Proc. Vol. 2010, 43, 79–86. [Google Scholar] [CrossRef]
- Auret, L.; Aldrich, C. Unsupervised process fault diagnosis with random forests. Ind. Eng. Chem. Res. 2010, 49, 9184–9194. [Google Scholar] [CrossRef]
- Auret, L.; Aldrich, C. Change point detection in time series data with random forests. Control Eng. Pract. 2010, 18, 990–1002. [Google Scholar] [CrossRef]
- Auret, L.; Aldrich, C. Empirical comparison of tree ensemble variance importance measures. Chemom. Intell. Lab. Syst. 2011, 105, 157–170. [Google Scholar] [CrossRef]
- Archer, K.J.; Kimes, R.V. Empirical characterization of random forest variable importance measures. Comput. Stat. Data Anal. 2008, 52, 2249–2260. [Google Scholar] [CrossRef]
- Olden, J.D.; Joy, M.K.; Death, R.G. An accurate comparison of methods for quantifying variable importance in artificial neural networks using simulated data. Ecol. Model. 2004, 178, 389–397. [Google Scholar] [CrossRef]
- Gregorutti, B.; Michel, B.; Saint-Pierre, P. Correlation and variable importance in random forests. Stat. Comput. 2017, 27, 659–678. [Google Scholar] [CrossRef] [Green Version]
- Chelgani, C.S.; Matin, S.S.; Makaremi, S. Modelling of free swelling index based on variable importance measurement of parent coal properties by random forest methods. Measurement 2016, 94, 416–422. [Google Scholar] [CrossRef]
- Aldrich, C. Exploratory Analysis of Metallurgical Process Data with Neural Networks and Related Methods; Process Metallurgy Series 12; Elsevier Science B.V.: Amsterdam, The Netherlands, 2002; ISBN 0444503129. [Google Scholar]
- Strobl, C.; Boulesteix, A.-L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Moisture | Vol | Ash | H | C | N | O | S |
| 1.000 | 0.024 | −0.050 | 0.397 | −0.594 | −0.325 | 0.919 | 0.086 | −0.597 | |
| 0.024 | 1.000 | −0.241 | 0.482 | −0.058 | 0.068 | 0.166 | 0.343 | −0.258 | |
| −0.050 | −0.241 | 1.000 | −0.693 | −0.711 | −0.364 | −0.110 | 0.370 | −0.091 | |
| 0.397 | 0.482 | −0.693 | 1.000 | 0.220 | 0.184 | 0.425 | −0.176 | −0.185 | |
| −0.594 | −0.058 | −0.711 | 0.220 | 1.000 | 0.491 | −0.569 | −0.498 | 0.570 | |
| −0.325 | 0.068 | −0.364 | 0.184 | 0.491 | 1.000 | −0.281 | −0.336 | 0.160 | |
| 0.919 | 0.166 | −0.110 | 0.425 | −0.569 | −0.281 | 1.000 | −0.046 | −0.748 | |
| 0.086 | 0.343 | 0.370 | −0.176 | −0.498 | −0.336 | −0.046 | 1.000 | −0.042 | |
| −0.597 | −0.258 | −0.091 | −0.185 | 0.570 | 0.160 | −0.748 | −0.042 | 1.000 |
| Variables | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 0.644 | −0.396 | 0.173 | −0.280 | 0.00490 | 0.417 | 0.678 | |
| 0.644 | 1 | −0.305 | −0.113 | −0.269 | 0.0455 | 0.200 | 0.502 | |
| −0.396 | −0.305 | 1 | −0.214 | 0.266 | 0.468 | 0.167 | −0.294 | |
| 0.173 | −0.113 | −0.214 | 1 | −0.0512 | −0.185 | 0.150 | 0.156 | |
| −0.280 | −0.269 | 0.266 | −0.0512 | 1 | −0.0247 | −0.443 | 0.169 | |
| 0.00490 | 0.0455 | 0.468 | −0.185 | −0.0247 | 1 | 0.392 | −0.229 | |
| 0.417 | 0.200 | 0.167 | 0.150 | −0.443 | 0.392 | 1 | −0.0212 | |
| 0.678 | 0.502 | −0.294 | 0.156 | 0.169 | −0.229 | −0.0212 | 1 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldrich, C. Process Variable Importance Analysis by Use of Random Forests in a Shapley Regression Framework. Minerals 2020, 10, 420. https://doi.org/10.3390/min10050420
Aldrich C. Process Variable Importance Analysis by Use of Random Forests in a Shapley Regression Framework. Minerals. 2020; 10(5):420. https://doi.org/10.3390/min10050420
Chicago/Turabian StyleAldrich, Chris. 2020. "Process Variable Importance Analysis by Use of Random Forests in a Shapley Regression Framework" Minerals 10, no. 5: 420. https://doi.org/10.3390/min10050420
APA StyleAldrich, C. (2020). Process Variable Importance Analysis by Use of Random Forests in a Shapley Regression Framework. Minerals, 10(5), 420. https://doi.org/10.3390/min10050420