
Machine Learning Algorithms for Semi-Autogenous Grinding Mill Operational Regions’ Identification




Abstract
:1. Introduction
Contributions
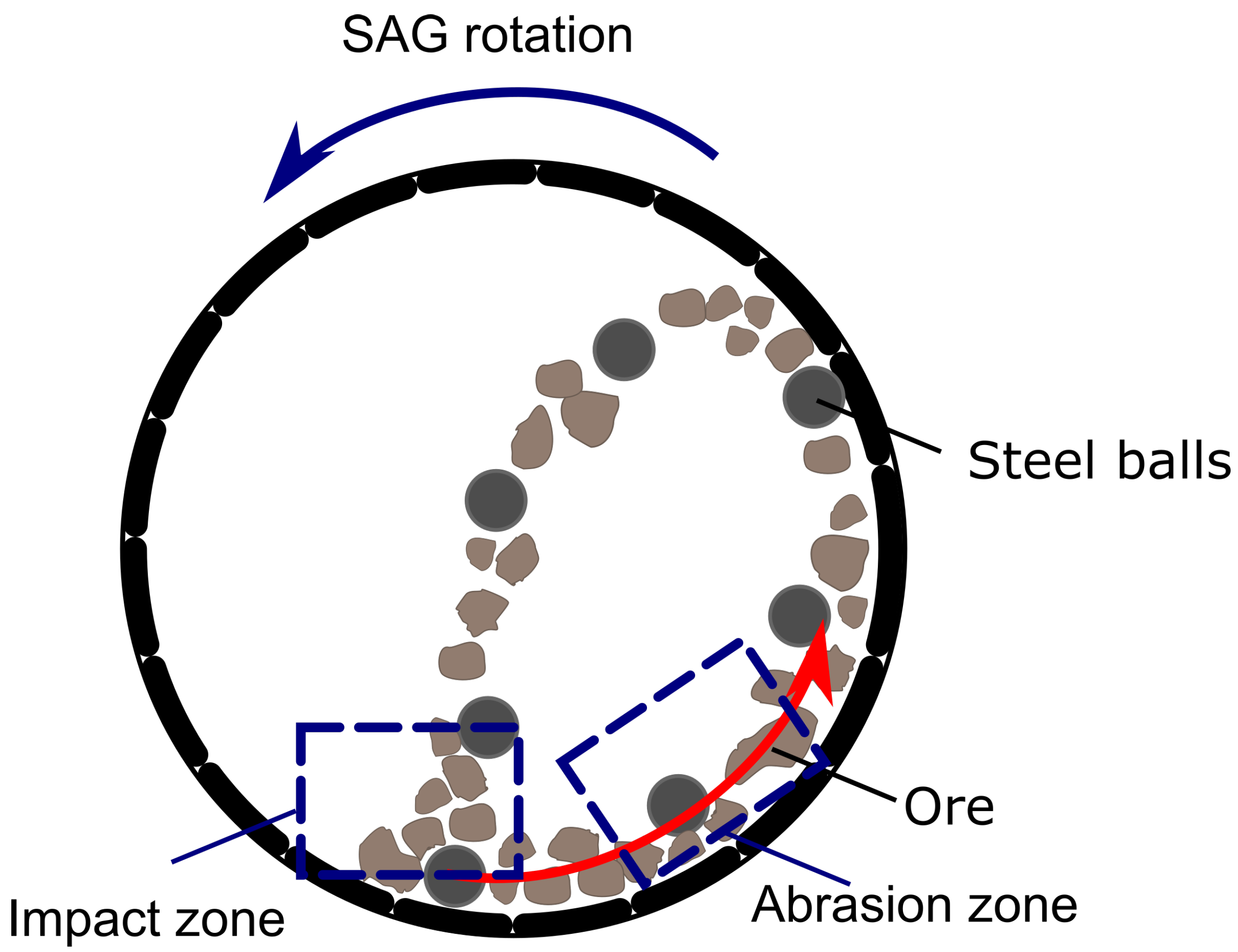
2. Background
- Size reduction: it seeks to increase the liberation of valuable minerals from gangue minerals through the reduction in particle size. Part of this process is carried out in mills, in which water is added to the ore prior to its operation. This is where the operation of SAG mills is considered, as these devices play a crucial role in the reduction in ore size and the preparation of the material for the subsequent stages of the process.
- Classification: consists of separating the grinding product according to its size. Fine particles that meet the required size criteria are directed towards flotation, whereas larger coarse particles that exceed the specified size are sent back for regrinding.
- Concentration: achieved through processes such as flotation, involves enriching the ore by removing non-valuable components, generating a valuable ore concentrate.
3. Methodology
3.1. Dataset
3.2. Machine Learning Models
3.2.1. K-Means
- d: total distance between data points;
- K: number of clustering centers;
- N: total number of data points in the dataset;
- : k-th center;
- : i-th point in dataset.
3.2.2. SOM
3.2.3. Performance Metrics
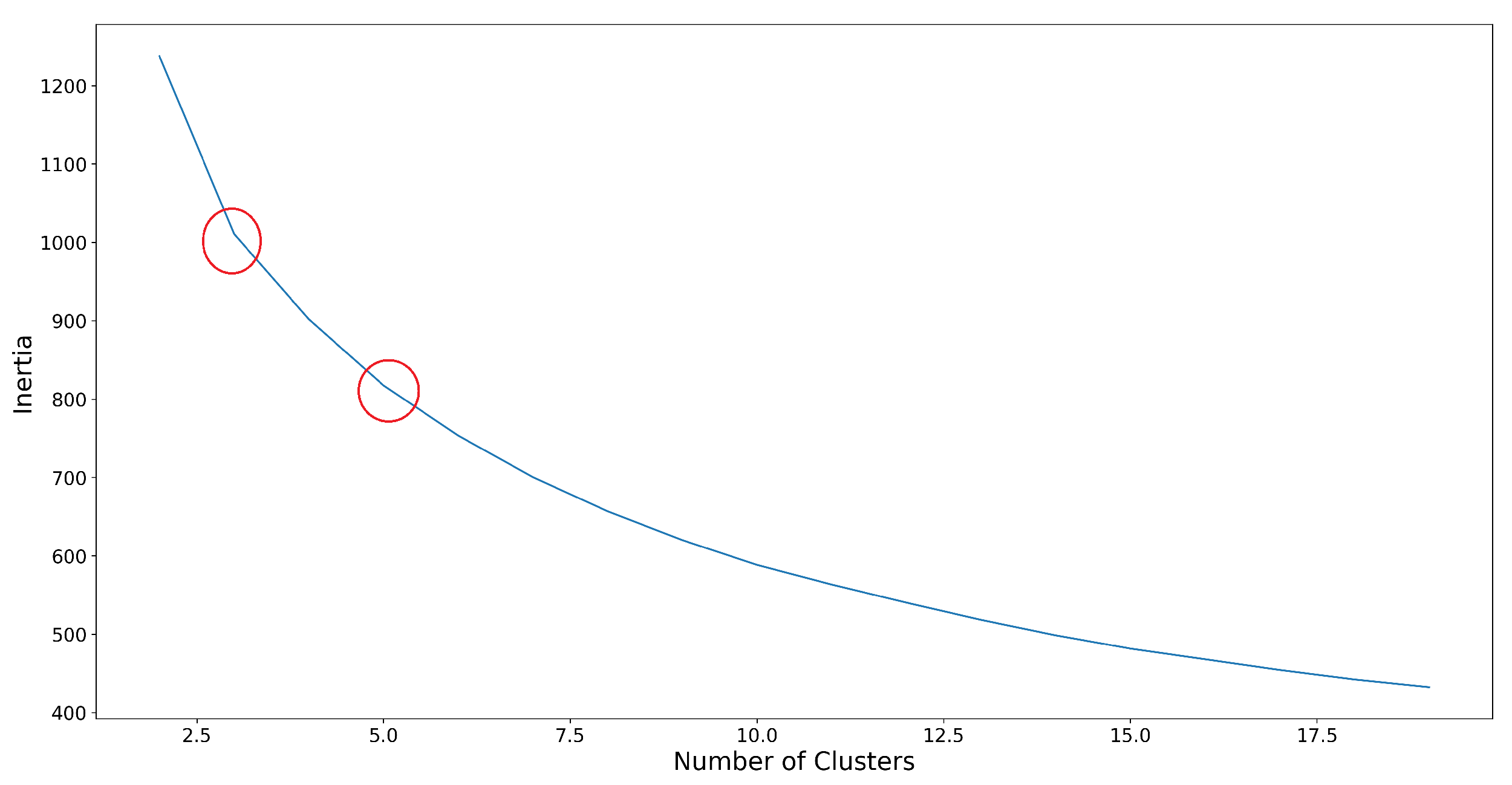
- Inertia: Is the square of the average distance between each instance (vector) and its nearest centroid. The smaller the inertia, the denser the cluster. However, it is also not advisable to consider the smallest inertia, as this would result in a poor model. That said, a middle point is considered, which is referred to as the ’elbow.’ The point where an elbow is observed indicates a good number of clusters for the dataset. As can be seen in Figure 2, two elbows are enclosed within a red circle, where you can observe how the curve changes its direction. This occurs with K equal to 3 and equal to 5, indicating that these would be good values for the number of clusters in our data.Figure 2. Inertia metric. Elbows are enclosed in red.
![Minerals 13 01360 g002]()
- Silhouette score: this metric varies in the range of [−1, 1]. A score of 1 indicates that the instance is well within its own cluster and far from others; a value close to 0 suggests that the instance is near the perimeter of another cluster; and a value close to −1 means that the instance could have been assigned to the wrong cluster. In Figure 3, one can see how the values range between 0.35 and 0.1. From Figure 3, it can be observed that, with 2 or 5 clusters, the results show a variation of 0.15 in the Silhouette score.Figure 3. Silhouette score metric. Critical K values are enclosed in red.
![Minerals 13 01360 g003]()


4. Results
4.1. K-Means
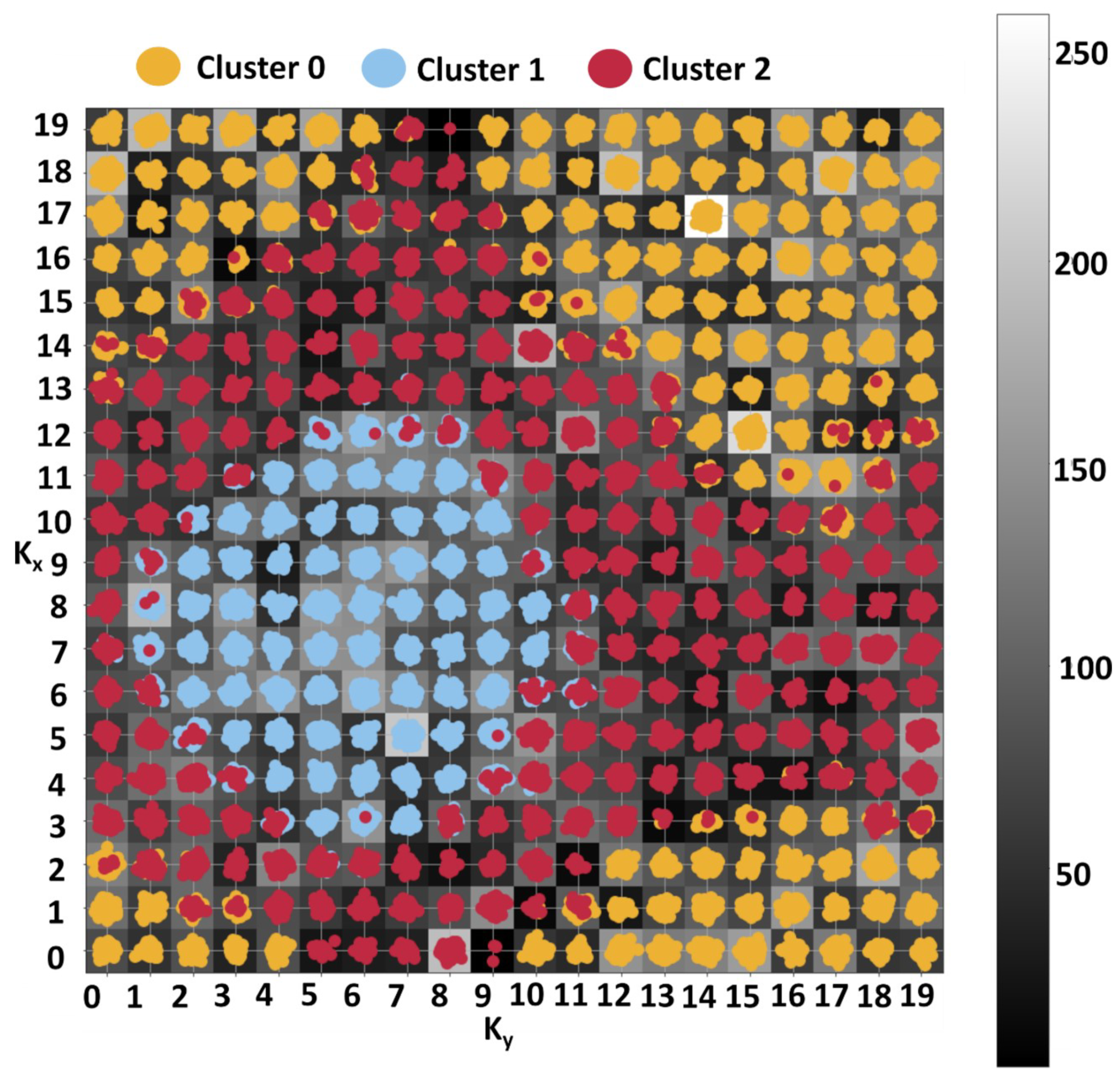
4.2. SOM
4.3. Sensitivity Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Comision Chilena del Cobre. Proyección del Consumo de Energía Eléctrica en la Minería del Cobre 2019–2030; Technical Report; COCHILCO: Santiago, Chile, 2019.
- Kawatra, S.K.; Young, C. SME Mineral Processing & Extractive Metallurgy Handbook; Society for Mining Metallurgy & Exploration (SME): Denver, CO, USA, 2019; p. 279. [Google Scholar]
- Salazar, J.L.; Valdés-González, H.; Vyhmesiter, E.; Cubillos, F. Model predictive control of semiautogenous mills (sag). Miner. Eng. 2014, 64, 92–96. [Google Scholar] [CrossRef]
- Sbárbaro, D.; del Villar, R. Advanced Control and Supervision of Mineral Processing Plants; Springer: London, UK, 2010. [Google Scholar] [CrossRef]
- Owusu, K.B.; Skinner, W.; Asamoah, R. Feed hardness and acoustic emissions of autogenous/semi-autogenous (AG/SAG) mills. Miner. Eng. 2022, 187, 107781. [Google Scholar] [CrossRef]
- Owusu, K.B.; Skinner, W.; Asamoah, R.K. Acoustic Sensing and Supervised Machine Learning for In Situ Classification of Semi-Autogenous (SAG) Mill Feed Size Fractions Using Different Feature Extraction Techniques. Powders 2023, 2, 299–322. [Google Scholar] [CrossRef]
- Avalos, S.; Kracht, W.; Ortiz, J.M. An LSTM Approach for SAG Mill Operational Relative-Hardness Prediction. Minerals 2020, 10, 734. [Google Scholar] [CrossRef]
- Acuña, G.; Curilem, M.; Cubillos, F. Development of a software sensor based on a narmax-support vector machine model for semiautogenous grinding. Rev. Iberoam. Automática Informática Ind. RIAI 2014, 11, 109–116. [Google Scholar] [CrossRef]
- Olivier, J.; Aldrich, C. Dynamic Monitoring of Grinding Circuits by Use of Global Recurrence Plots and Convolutional Neural Networks. Minerals 2020, 10, 958. [Google Scholar] [CrossRef]
- Liao, Z.; Xu, C.; Chen, W.; Chen, Q.; Wang, F.; She, J. Effective Throughput Optimization of SAG Milling Process Based on BPNN and Genetic Algorithm. In Proceedings of the 2023 IEEE 6th International Conference on Industrial Cyber-Physical Systems (ICPS), Wuhan, China, 8–11 May 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Hoseinian, F.S.; Aliakbar, A.; Bahram, R. Semi-autogenous mill power prediction by a hybrid neural genetic algorithm. J. Cent. South Univ. 2018, 25, 151–158. [Google Scholar] [CrossRef]
- Avalos, S.; Kracht, W.; Ortiz, J.M. Machine Learning and Deep Learning Methods in Mining Operations: A Data-Driven SAG Mill Energy Consumption Prediction Application. Mining Metall. Explor. 2020, 37, 1197–1212. [Google Scholar] [CrossRef]
- Hoseinian, F.S.; Faradonbeh, R.S.; Abdollahzadeh, A.; Rezai, B.; Soltani-Mohammadi, S. Semi-autogenous mill power model development using gene expression programming. Powder Technol. 2017, 308, 61–69. [Google Scholar] [CrossRef]
- Kahraman, A.; Kantardzic, M.; Kahraman, M.M.; Kotan, M. A Data-Driven Multi-Regime Approach for Predicting Energy Consumption. Energies 2021, 14, 6763. [Google Scholar] [CrossRef]
- López, P.; Reyes, I.; Risso, N.; Aguilera, C.; Campos, P.G.; Momayez, M.; Contreras, D. Assessing Machine Learning and Deep Learning-based approaches for SAG mill Energy consumption. In Proceedings of the 2021 IEEE CHILEAN Conference on Electrical, Electronics Engineering, Information and Communication Technologies (CHILECON), Valparaíso, Chile, 6–9 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Dorkhah, A.; Arab Solghar, A.; Rezaeizadeh, M. Experimental Analysis of Semi-autogenous Grinding Mill Characteristics under Different Working Conditions. Iran. J. Sci. Technol. Trans. Mech. Eng. 2020, 44, 1103–1114. [Google Scholar] [CrossRef]
- Olivier, J.; Aldrich, C. Use of Decision Trees for the Development of Decision Support Systems for the Control of Grinding Circuits. Minerals 2021, 11, 595. [Google Scholar] [CrossRef]
- Zhou, P.; Chai, T.; Sun, J. Intelligence-Based Supervisory Control for Optimal Operation of a DCS-Controlled Grinding System. IEEE Trans. Control. Syst. Technol. 2013, 21, 162–175. [Google Scholar] [CrossRef]
- Saldaña, M.; Gálvez, E.; Navarra, A.; Toro, N.; Cisternas, L.A. Optimization of the SAG Grinding Process Using Statistical Analysis and Machine Learning: A Case Study of the Chilean Copper Mining Industry. Materials 2023, 16, 3220. [Google Scholar] [CrossRef] [PubMed]
- Loudari, C.; Cherkaoui, M.; Bennani, R.; Harraki, I.E.; Younsi, Z.E.; Adnani, M.E.; Abdelwahed, E.H.; Benzakour, I.; Bourzeix, F.; Baina, K. Predicting energy consumption of grinding mills in mining industry: A review. AIP Conf. Proc. 2023, 2814, 040003. Available online: https://pubs.aip.org/aip/acp/article-pdf/doi/10.1063/5.0148768/18038672/040003_1_5.0148768.pdf (accessed on 10 August 2023).
- Mayne, D.Q. Model predictive control: Recent developments and future promise. Automatica 2014, 50, 2967–2986. [Google Scholar] [CrossRef]
- Risso, N.; Altin, B.; Sanfelice, R.G.; Sprinkle, J. Set-Valued Model Predictive Control. In Proceedings of the 2021 60th IEEE Conference on Decision and Control (CDC), Austin, TX, USA, 14–17 December 2021; pp. 283–288. [Google Scholar]
- Raković, S.V.; Zhang, S.; Hao, Y.; Dai, L.; Xia, Y. Convex MPC for exclusion constraints. Automatica 2021, 127, 109502. [Google Scholar] [CrossRef]
- Dunn, P.K. Scientific Research and Methodology: An Introduction to Quantitative Research in Science and Health; RStudio, PBC: Boston, MA, USA, 2021. [Google Scholar]
- Wills, B.; Finch, J. Wills’ Mineral Processing Technology: An Introduction to the Practical Aspects of Ore Treatment and Mineral Recovery; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 563–564. [Google Scholar] [CrossRef]
- Kohonen, T. Self-Organizing Maps; Springer Series in Information Sciences; Springer: Berlin, Germany, 1995; Volume 30. [Google Scholar] [CrossRef]
- Melssen, W.; Wehrens, R.; Buydens, L. Supervised Kohonen networks for classification problems. Chemom. Intell. Lab. Syst. 2006, 83, 99–113. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Parameter | Unit |
|---|---|---|
| Timestamp | Sampling time | min |
| TPH total | Inbound material to the mill | TPH |
| SAG speed | Mill speed | RPM |
| Thick split | Coarse material percentage | TPH |
| Water | Inbound water to the mill | m/h |
| SAG weight | Total mill weight | ton |
| Power SAG | Power consumed | kW |
| Size | Percentage solids F80 | in |
| Rock hardness | Ore hardness | kWh/t |
| Pebbles | Recirculating pebbles | TPH |
| Variable | Mean Val Cluster 0 | Mean Val Cluster 1 |
|---|---|---|
| TPH (TPH) | 2588.2 | 2447.8 |
| SAG speed (RPM) | 9.16 | 9.51 |
| Water (m/h) | 899.5 | 895.4 |
| SAG weight (ton) | 3853.5 | 3885.8 |
| Power SAG (kW) | 12,717.4 | 13,291.8 |
| Size (in) | 3.15 | 3.74 |
| Rock hardness (kWh/t) | 16.74 | 45.56 |
| Variable | Mean Val Cluster 0 | Mean Val Cluster 1 | Mean Val Cluster 2 |
|---|---|---|---|
| TPH (TPH) | 2587.6 | 2395.3 | 2557.0 |
| SAG speed (RPM) | 9.11 | 9.53 | 9.37 |
| Water (m/h) | 891.5 | 901.9 | 902.7 |
| SAG weight (ton) | 3851.3 | 3894.6 | 3865.8 |
| Power SAG (kW) | 12,704.9 | 13,405.7 | 12,931.7 |
| Size (in) | 3.51 | 3.86 | 3.55 |
| Rock hardness (kWh/t) | 12.07 | 52.04 | 31.79 |
| Variable | Mean Val Cluster 0 | Mean Val Cluster 1 | Mean Val Cluster 2 |
|---|---|---|---|
| TPH (TPH) | 2400.6 | 2553.1 | 2581.9 |
| Water (m/h) | 899.6 | 900.6 | 888.3 |
| Power SAG (kW) | 13,365.9 | 12,919.0 | 12,679.4 |
| Size (in) | 3.85 | 3.54 | 3.5 |
| Rock hardness (kWh/t) | 51.8 | 31.49 | 12.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez, P.; Reyes, I.; Risso, N.; Momayez, M.; Zhang, J. Machine Learning Algorithms for Semi-Autogenous Grinding Mill Operational Regions’ Identification. Minerals 2023, 13, 1360. https://doi.org/10.3390/min13111360
Lopez P, Reyes I, Risso N, Momayez M, Zhang J. Machine Learning Algorithms for Semi-Autogenous Grinding Mill Operational Regions’ Identification. Minerals. 2023; 13(11):1360. https://doi.org/10.3390/min13111360
Chicago/Turabian StyleLopez, Pedro, Ignacio Reyes, Nathalie Risso, Moe Momayez, and Jinhong Zhang. 2023. "Machine Learning Algorithms for Semi-Autogenous Grinding Mill Operational Regions’ Identification" Minerals 13, no. 11: 1360. https://doi.org/10.3390/min13111360
APA StyleLopez, P., Reyes, I., Risso, N., Momayez, M., & Zhang, J. (2023). Machine Learning Algorithms for Semi-Autogenous Grinding Mill Operational Regions’ Identification. Minerals, 13(11), 1360. https://doi.org/10.3390/min13111360