
An Improved Tikhonov-Regularized Variable Projection Algorithm for Separable Nonlinear Least Squares


Abstract
:1. Introduction
2. Parameter Estimation Method
2.1. Regularization Algorithm for Linear Parameter Estimation
2.1.1. TSVD Method
2.1.2. TR Method
2.1.3. Improved TR Method
2.2. LM Algorithm for Nonlinear Parameter Estimation
2.3. Algorithm Solution Determination
- Step 1:
- Take the initial value of the nonlinear parameter , the maximum number of iteration steps and set .
- Step 2:
- The initial nonlinear parameter value is used to calculate the initial values of the linear parameters via the TR, TSVD or improved TR method. Then the residual function and approximate Jacobian matrix are obtained.
- Step 3:
- The iterative step length and search direction are determined by solving Equations (19) and (20), respectively; thereafter, the nonlinear parameters are updated according to Equation (18).
- Step 4:
- The linear and nonlinear parameters are cross-updated until ; then, the calculation is terminated.
3. Numerical Simulation
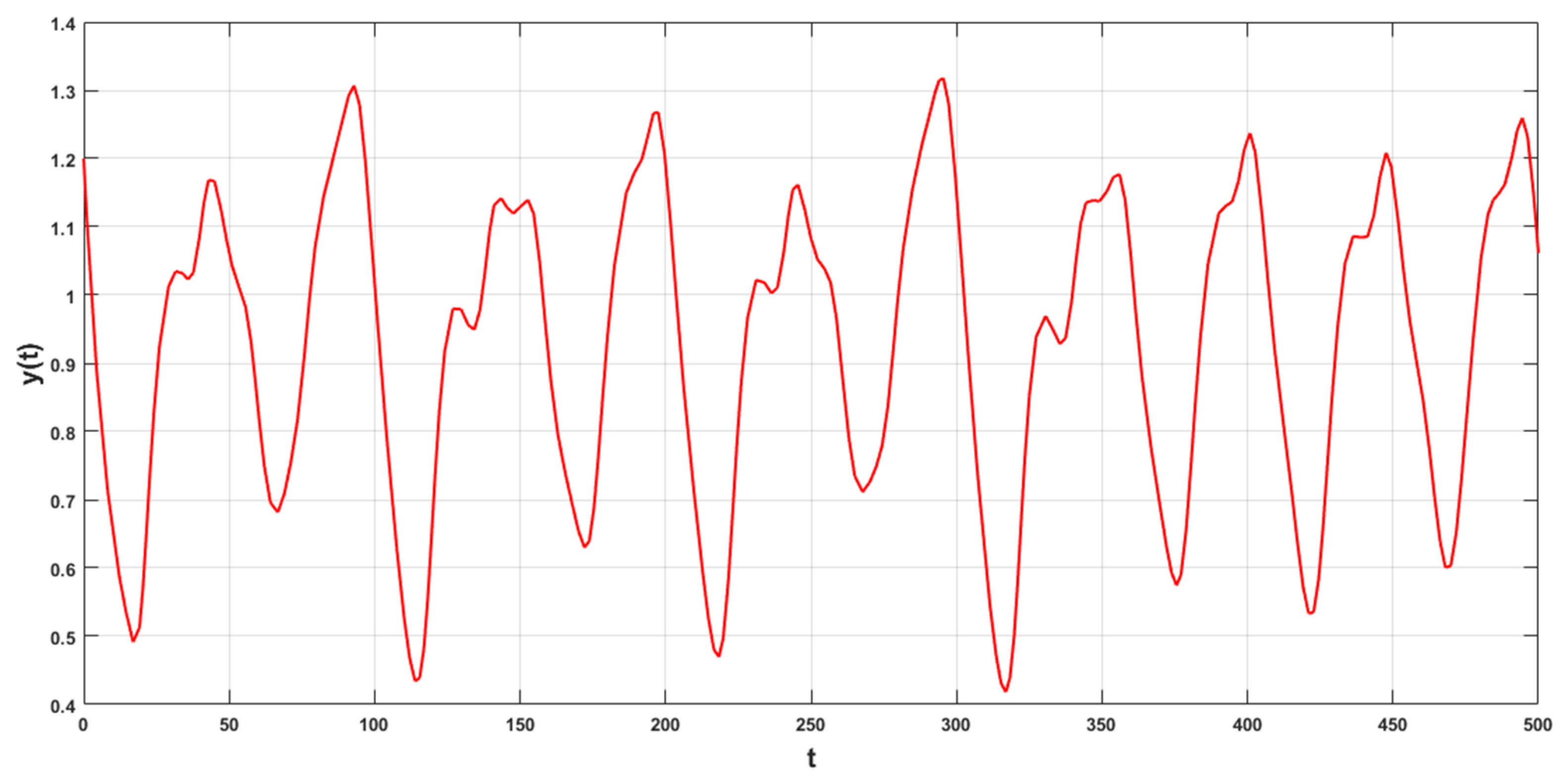
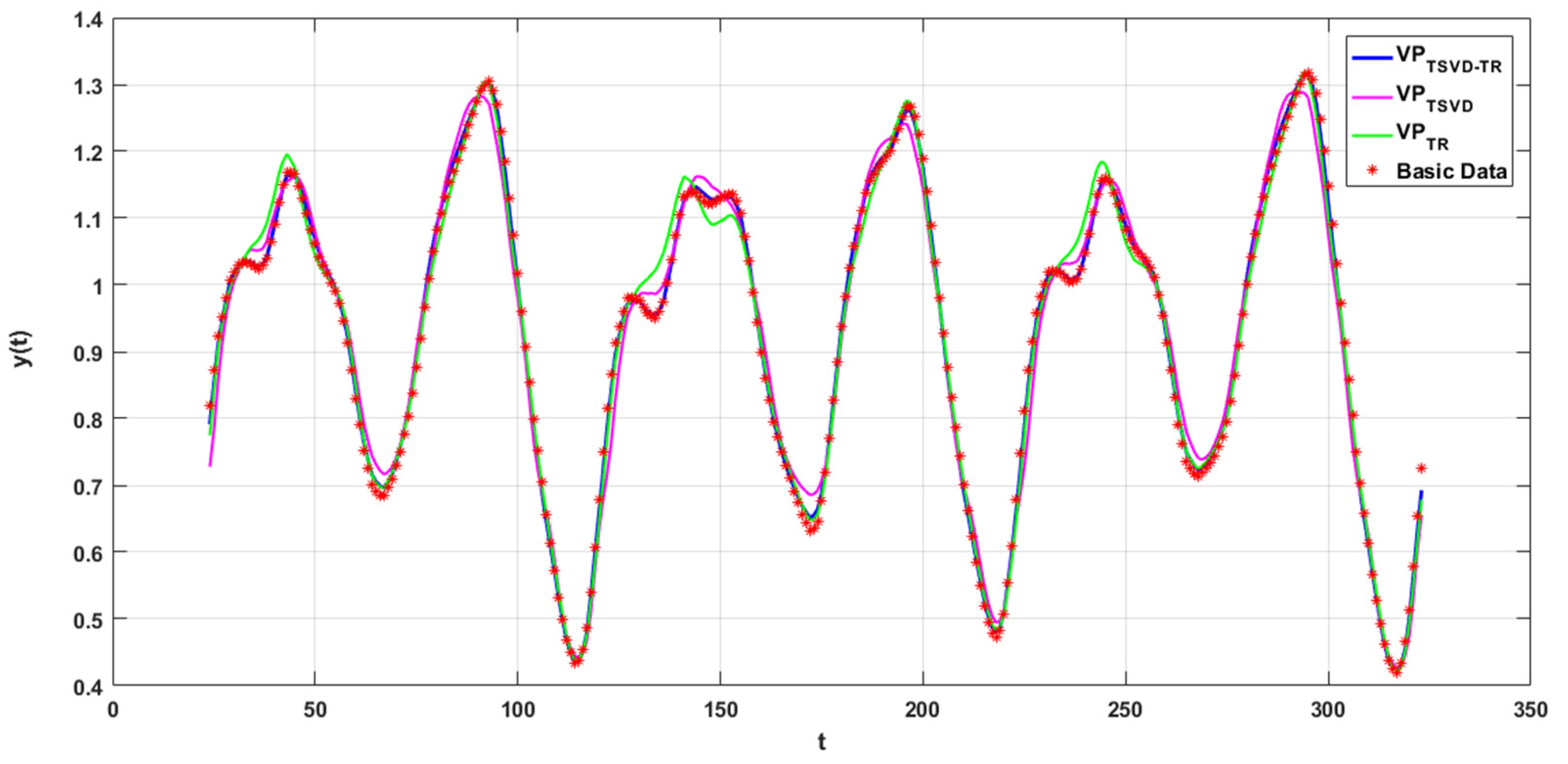
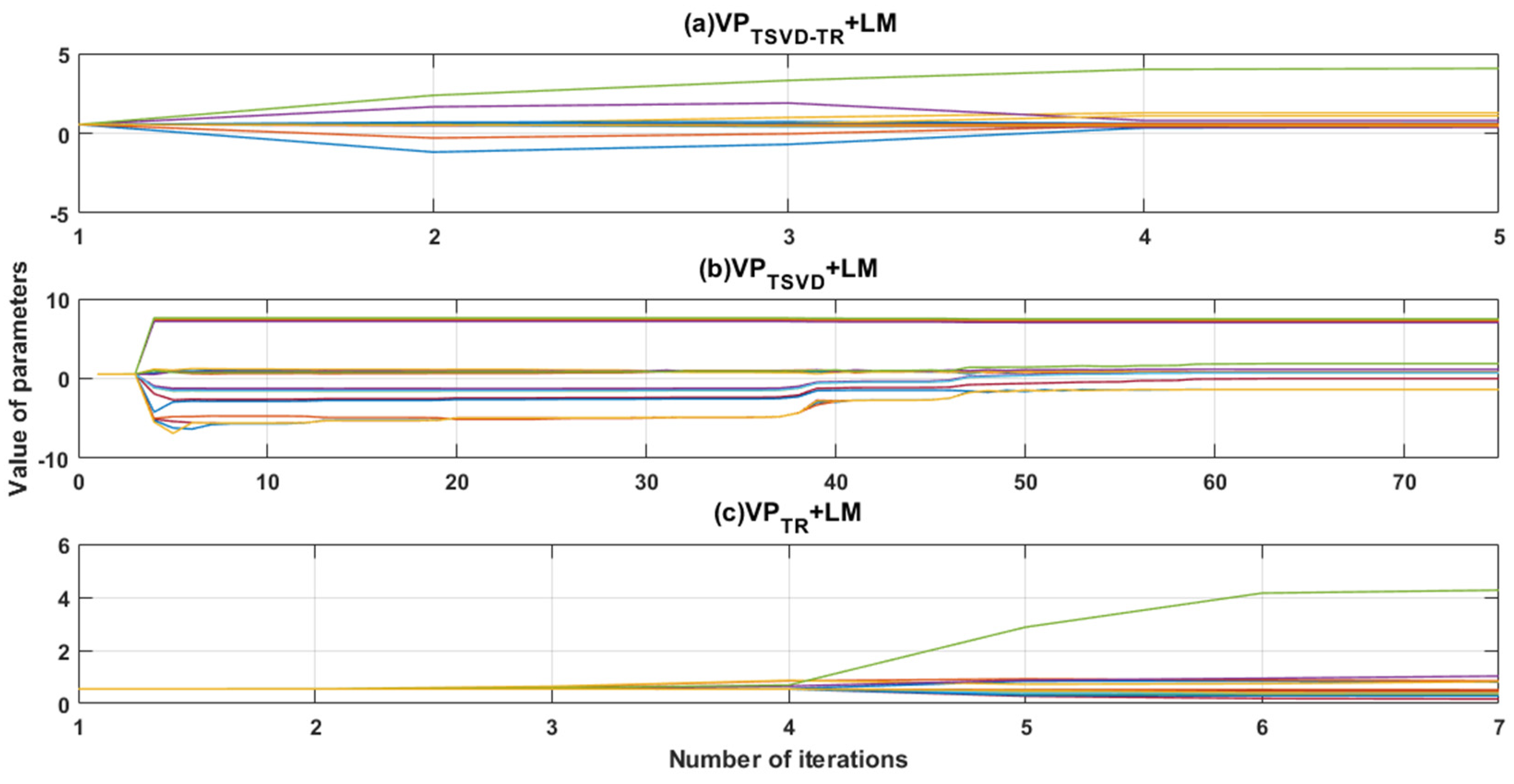
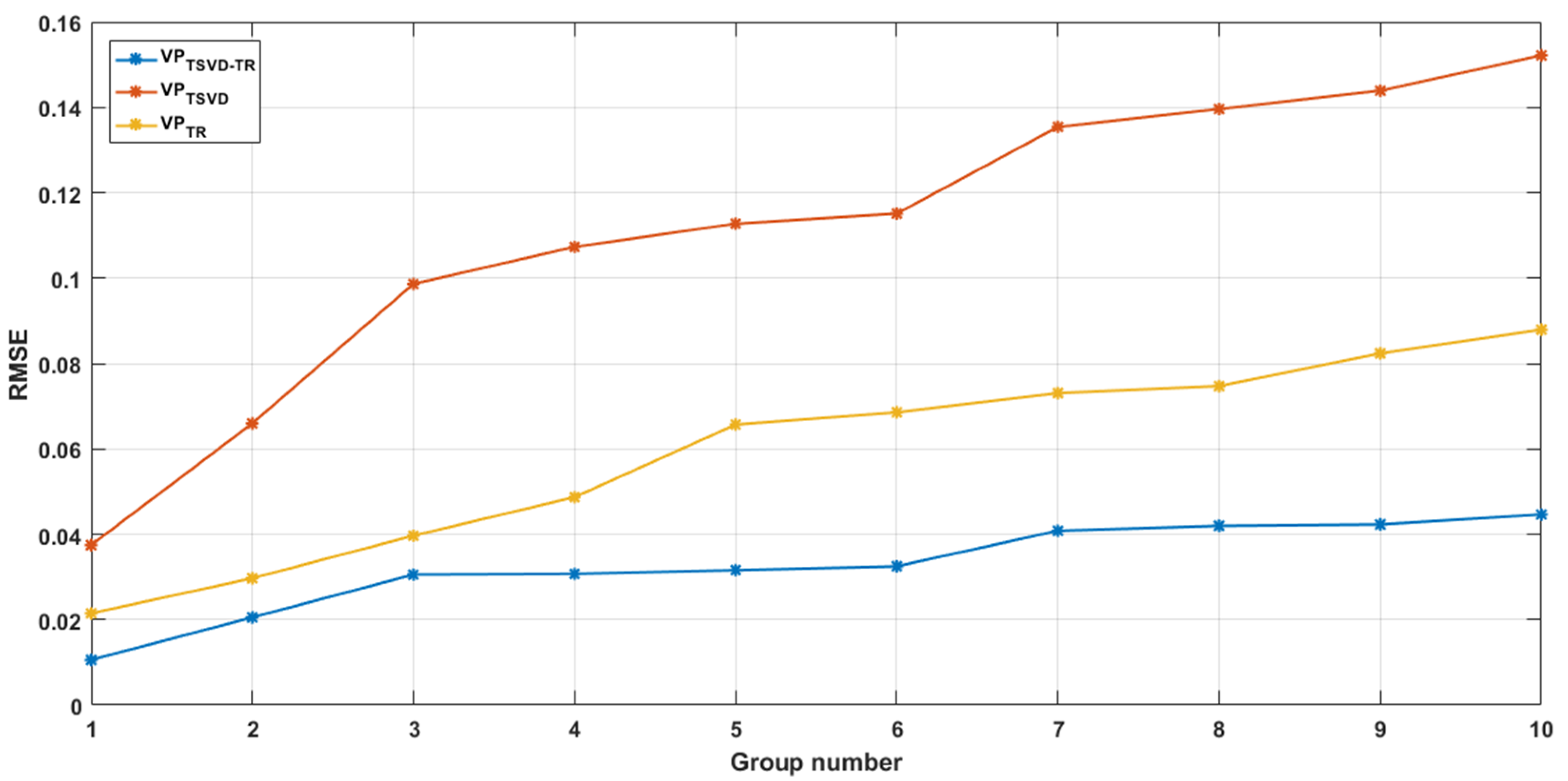
3.1. Predicting the Mackey-Class Time Series Using an RBF Neural Network
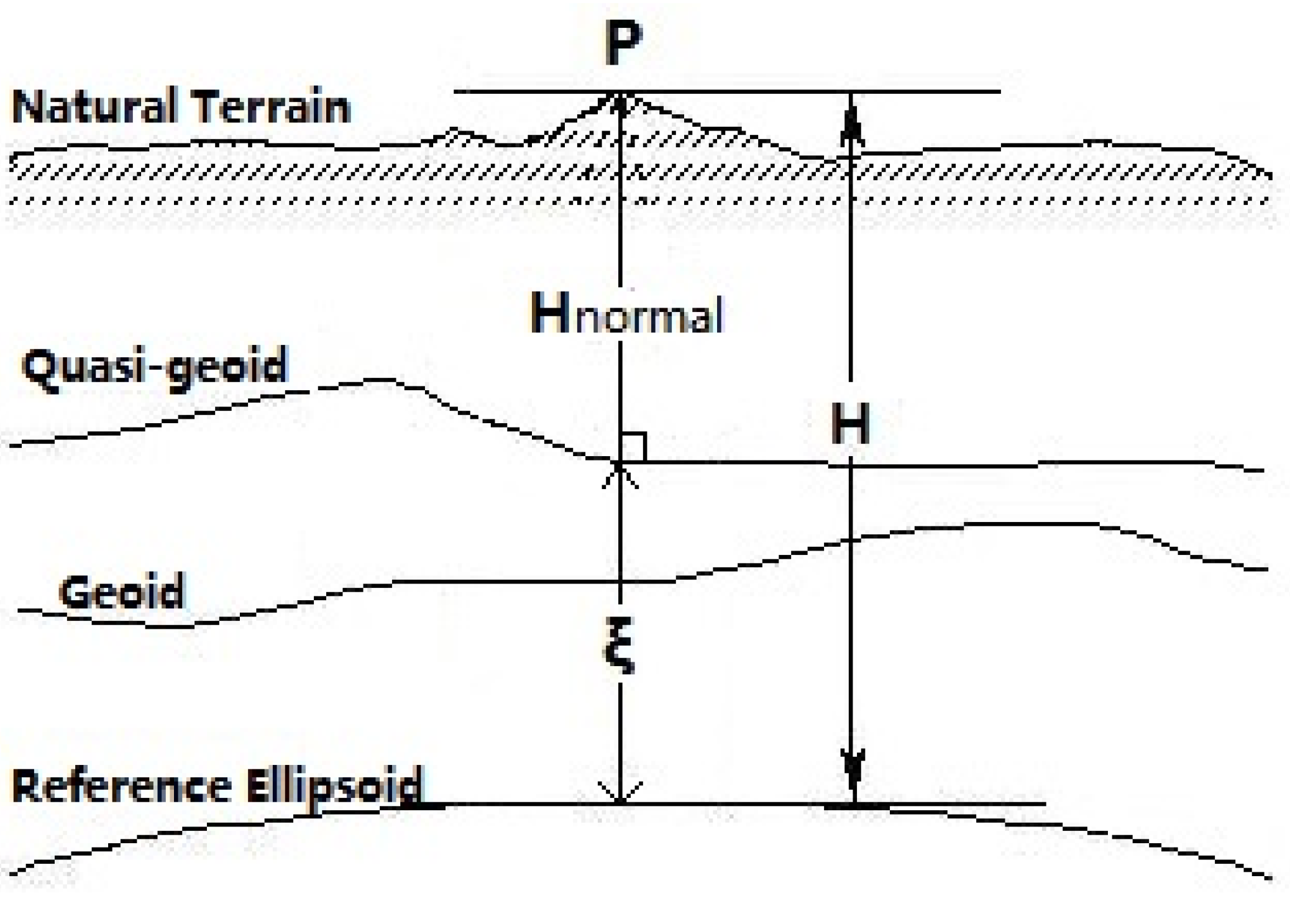
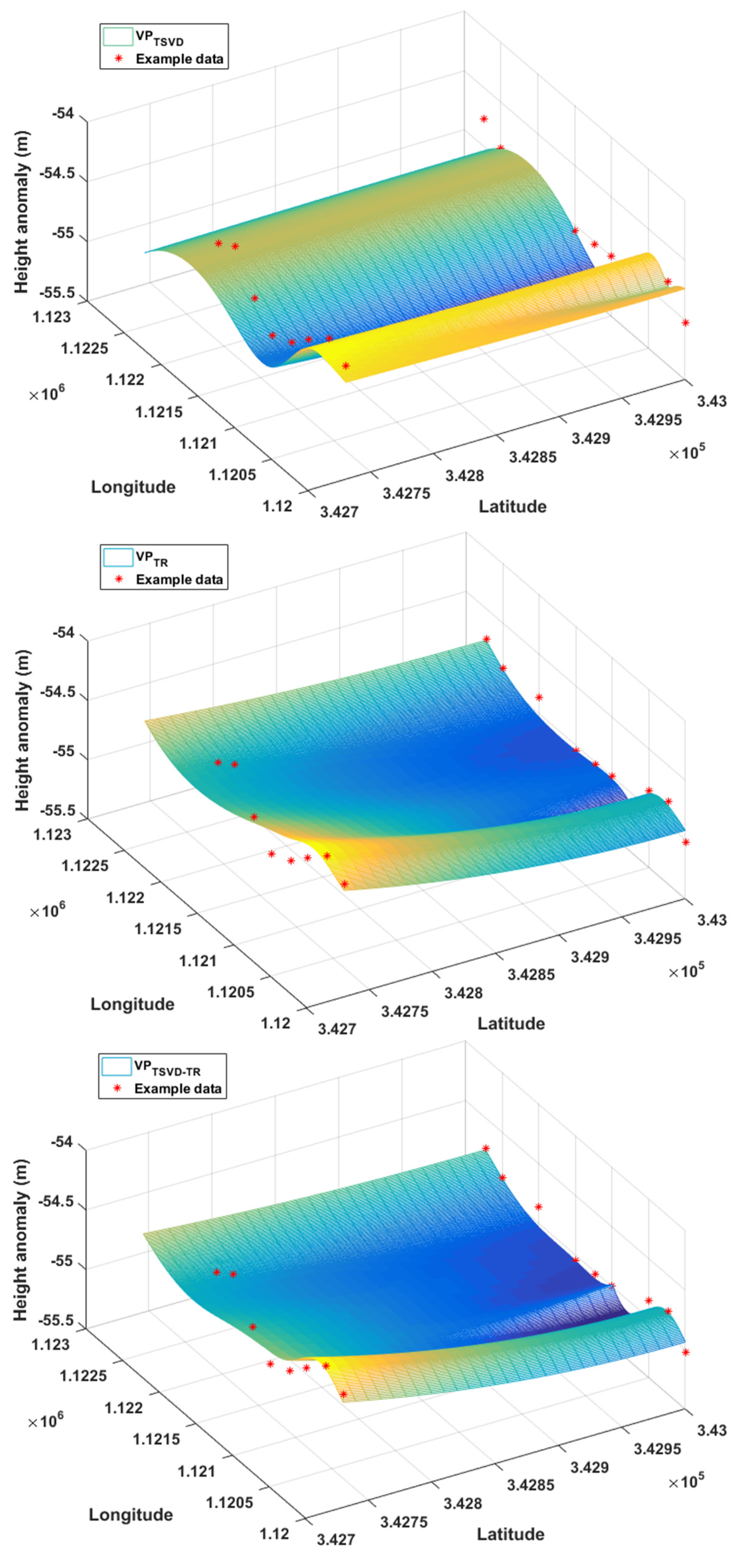
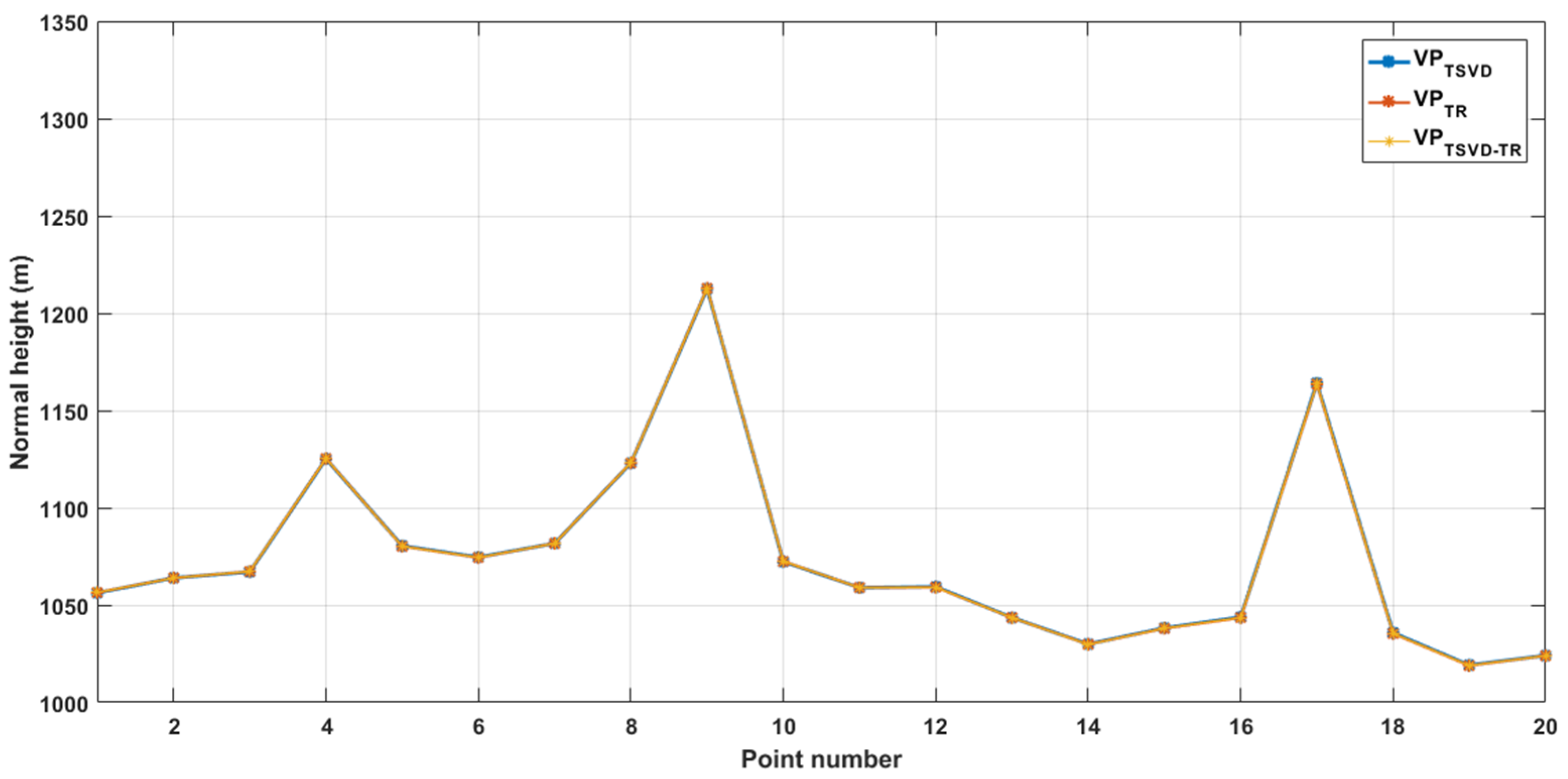
3.2. Height Anomaly Fitting
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Okatani, T.; Deguchi, K. On the Wiberg algorithm for matrix factorization in the presence of missing components. Int. J. Comput. Vis. 2007, 72, 329–337. [Google Scholar] [CrossRef]
- Levenberg, K. A method for the solution of certain non-linear problems in least squares. Q. Appl. Math. 1944, 2, 164–168. [Google Scholar] [CrossRef] [Green Version]
- Marquardt, D.W. An Algorithm for Least-Squares Estimation of Nonlinear Parameters. SIAM J. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Hong, J.H.; Zach, C.; Fitzgibbon, A. Revisiting the variable projection method for separable nonlinear least squares problems. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5939–5947. [Google Scholar]
- Golub, G.H.; Pereyra, V. The Differentiation of Pseudo-Inverses and Nonlinear Least Squares Problems Whose Variables Separate. SIAM J. Numer. Anal. 1973, 10, 413–432. [Google Scholar] [CrossRef]
- Golub, G.H.; Pereyra, V. Separable nonlinear least squares: The variable projection method and its applications. Speech Commun. 2003, 45, 63–87. [Google Scholar] [CrossRef]
- Kaufman, L. A variable projection method for solving separable nonlinear least squares problems. BIT Numer. Math. 1975, 15, 49–57. [Google Scholar] [CrossRef]
- Ruhe, A. Algorithms for separable nonlinear least squares problems. SIAM Rev. 1980, 22, 318–337. [Google Scholar] [CrossRef]
- O’Leary, D.P.; Rust, B.W. Variable projection for nonlinear least squares problems. Comput. Optim. Appl. 2013, 54, 579–593. [Google Scholar] [CrossRef]
- Ruano, A.E.B.; Jones, D.I.; Fleming, P.J. A new formulation of the learning problem of a neural network controller. In Proceedings of the 30th IEEE Conference on Decision and Control, Brighton, UK, 11–13 December 1991; pp. 865–866. [Google Scholar]
- Gan, M.; Chen, C.L.P.; Chen, G.; Chen, L. On some separated algorithms for separable nonlinear least squares problems. IEEE Trans. Cybern. 2018, 48, 2866–2874. [Google Scholar] [CrossRef]
- Gan, M.; Li, H. An Efficient Variable Projection Formulation for Separable Nonlinear Least Squares Problems. IEEE Trans. Cybern. 2014, 44, 707–711. [Google Scholar] [CrossRef]
- Chen, G.Y.; Gan, M.; Ding, F. Modified Gram-Schmidt Method Based Variable Projection Algorithm for Separable Nonlinear models. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2410–2418. [Google Scholar] [CrossRef]
- Böckmann, C. A modification of the trust-region Gauss-Newton method to solve separable nonlinear least squares problems. J. Math. Syst. Estim. Control 1995, 5, 1–16. [Google Scholar]
- Chung, J.J.; Nagy, G. An efficient iterative approach for large-scale separable nonlinear inverse problems. SIAM J. Sci. Comput. 2010, 31, 4654–4674. [Google Scholar] [CrossRef]
- Li, X.L.; Liu, K.; Dong, Y.S.; Tao, D.C. Patch alignment manifold matting. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 3214–3226. [Google Scholar] [CrossRef] [Green Version]
- Tikhonov, A.N.; Arsenin, V.Y. Solutions of ill-posed problems. SIAM Rev. 1979, 21, 266–267. [Google Scholar]
- Park, Y.; Reichel, L.; Rodriguez, G. Parameter determination for Tikhonov regularization problems in general form. J. Comput. Appl. Math. 2018, 343, 12–25. [Google Scholar] [CrossRef]
- Hansen, P.C. The Truncated SVD as A Method for Regularization. BIT Numer. Math. 1987, 27, 534–553. [Google Scholar] [CrossRef]
- Xu, P.L. Truncated SVD methods for Discrete Linear Ill-posed Problems. Geophys. J. Int. 1998, 1335, 505–514. [Google Scholar] [CrossRef]
- Aravkin, A.Y.; Drusvyatskiy, D.; van Leeuwen, T. Efficient quadratic penalization through the partial minimization technique. IEEE Trans. Autom. Control 2018, 63, 2131–2138. [Google Scholar] [CrossRef] [Green Version]
- Pang, S.C.; Li, T.; Dai, F.; Yu, M. Particle Swarm Optimization Algorithm for Multi-Salesman Problem with Time and Capacity Constraints. Appl. Math. Inf. Sci. 2013, 7, 2439–2444. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.Z.; Liu, D.Y.; Zhang, Q.Y.; Huang, H.L. The iteration by correcting characteristic value and its application in surveying data processing. J. Heilongjiang Inst. Technol. 2001, 15, 3–6. [Google Scholar]
- Zeng, X.Y.; Peng, H.; Zhou, F.; Xi, Y.H. Implementation of regularization for separable nonlinear least squares problems. Appl. Soft Comput. 2017, 60, 397–406. [Google Scholar] [CrossRef]
- Chen, G.Y.; Gan, M.; Chen CL, P.; Li, H.X. A Regularized Variable Projection Algorithm for Separable Nonlinear Least–Squares Problems. IEEE Trans. Autom. Control 2019, 64, 526–537. [Google Scholar] [CrossRef]
- Wang, K.; Liu, G.L.; Tao, Q.X.; Zhai, M. Efficient Parameters Estimation Method for the Separable Nonlinear Least Squares Problem. Complexity 2020, 2020, 9619427. [Google Scholar] [CrossRef] [Green Version]
- Fuhry, M.; Reichel, L. A new Tikhonov regularization method. Number Algorithms 2012, 59, 433–445. [Google Scholar] [CrossRef]
- Lin, D.f.; Zhu, J.j.; Song, Y.C. Regularized singular value decomposition parameter construction method. J. Surv. Mapp. 2016, 45, 883–889. [Google Scholar]
- Byrd, R.H.; Schnabel, R.B.; Shultz, G.A. A Trust Region Algorithm for Nonlinearly Constrained Optimization. SIAM J. Numer. Anal. 1987, 24, 1152–1170. [Google Scholar] [CrossRef] [Green Version]
- Golub, G.H.; Styan, G.P.H. Numerical computations for univariate linear models. J. Stat. Comput. Simul. 1973, 2, 253–274. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Iterations | Function Evaluation Number | Second Norm of Residual Vector | RMSE-t | |
|---|---|---|---|---|
| VPTSVD | 75 | 1953 | 0.34373 | 0.27918 |
| VPTR | 5 | 135 | 0.36427 | 0.19919 |
| VPTSVD-TR | 7 | 185 | 0.05818 | 0.09653 |
| No. | Latitude | Longitude | |||
|---|---|---|---|---|---|
| D01 | 343000.0000 | 1120000.0000 | 1001.5220 | 1056.5490 | −55.0270 |
| D02 | 343000.0000 | 1120230.0000 | 1009.1290 | 1063.9280 | −54.7990 |
| D03 | 343000.0000 | 1120500.0000 | 1012.3950 | 1067.2510 | −54.8560 |
| D04 | 343000.0000 | 1120730.0000 | 1070.1860 | 1125.3030 | −55.1170 |
| D05 | 343000.0000 | 1121000.0000 | 1025.2330 | 1080.2320 | −54.9990 |
| D06 | 343000.0000 | 1121230.0000 | 1019.4310 | 1074.4540 | −55.0230 |
| D07 | 343000.0000 | 1121500.0000 | 1026.7090 | 1081.7560 | −55.0470 |
| D08 | 343000.0000 | 1121730.0000 | 1067.9940 | 1123.1420 | −55.1480 |
| D09 | 343000.0000 | 1122000.0000 | 1157.7220 | 1212.5890 | −54.8670 |
| D10 | 343000.0000 | 1122230.0000 | 1017.5320 | 1072.6350 | −55.1030 |
| D11 | 343000.0000 | 1122500.0000 | 1004.0630 | 1058.9510 | −54.8880 |
| D12 | 343000.0000 | 1122730.0000 | 1004.3500 | 1059.1140 | −54.7640 |
| D13 | 342730.0000 | 1120000.0000 | 988.8130 | 1043.3570 | −54.5440 |
| D14 | 342730.0000 | 1120230.0000 | 975.3010 | 1029.7370 | −54.4360 |
| D15 | 342730.0000 | 1120500.0000 | 983.5130 | 1038.1040 | −54.5910 |
| D16 | 342730.0000 | 1120730.0000 | 988.8550 | 1043.5930 | −54.7380 |
| D17 | 342730.0000 | 1121000.0000 | 1108.9430 | 1163.7680 | −54.8250 |
| D18 | 342730.0000 | 1121230.0000 | 980.5940 | 1035.2260 | −54.6320 |
| D19 | 342730.0000 | 1121500.0000 | 964.1870 | 1018.5260 | −54.3390 |
| D20 | 342730.0000 | 1120000.0000 | 1001.5220 | 1056.5490 | −55.0270 |
| Algorithms | SSR (m2) | SSRf (m2) | RMSE (m) | RMSEf (m) | |
|---|---|---|---|---|---|
| VPTSVD | 0.5004 | 0.9337 | 0.1826 | 0.4321 | 0.2599 |
| VPTR | 0.0850 | 0.3770 | 0.0753 | 0.2746 | 0.8744 |
| VPTSVD-TR | 0.0798 | 0.3545 | 0.0729 | 0.2663 | 0.8820 |
| No. | Hnormal (m) | rTSVD (m) | rTR (m) | rTSVD+TR (m) |
|---|---|---|---|---|
| D01 | 1056.5490 | 0.2871 | 0.1041 | 0.0902 |
| D02 | 1063.9280 | −0.0457 | −0.0457 | −0.0161 |
| D03 | 1067.2510 | 0.1498 | −0.0245 | −0.0742 |
| D04 | 1125.3030 | 0.1702 | 0.0015 | 0.0224 |
| D05 | 1080.2320 | −0.2271 | −0.0266 | 0.0108 |
| D06 | 1074.4540 | −0.1912 | −0.0084 | −0.0399 |
| D07 | 1081.7560 | −0.0025 | −0.0036 | −0.0052 |
| D08 | 1123.1420 | 0.2312 | 0.0942 | 0.1011 |
| D09 | 1212.5890 | 0.0406 | −0.1688 | −0.1694 |
| D10 | 1072.6350 | 0.2850 | 0.1092 | 0.1078 |
| D11 | 1058.9510 | −0.0049 | −0.0108 | −0.0069 |
| D12 | 1059.1140 | −0.2656 | −0.0069 | −0.0091 |
| D13 | 1043.3570 | −0.1411 | −0.0576 | −0.0701 |
| D14 | 1029.7370 | −0.2104 | −0.0699 | −0.0269 |
| D15 | 1038.1040 | −0.0726 | 0.1139 | 0.0854 |
| D16 | 1043.5930 | −0.1204 | 0.1882 | 0.0878 |
| D17 | 1163.7680 | −0.2611 | 0.2026 | 0.1069 |
| D18 | 1035.2260 | −0.4721 | −0.0523 | −0.1058 |
| D19 | 1018.5260 | −0.6528 | −0.4140 | −0.4319 |
| D20 | 1056.5490 | −0.4494 | −0.3555 | −0.3710 |
| RMSE | 0 | 0.2678 | 0.1520 | 0.1474 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Liu, G.; Wang, L. An Improved Tikhonov-Regularized Variable Projection Algorithm for Separable Nonlinear Least Squares. Axioms 2021, 10, 196. https://doi.org/10.3390/axioms10030196
Guo H, Liu G, Wang L. An Improved Tikhonov-Regularized Variable Projection Algorithm for Separable Nonlinear Least Squares. Axioms. 2021; 10(3):196. https://doi.org/10.3390/axioms10030196
Chicago/Turabian StyleGuo, Hua, Guolin Liu, and Luyao Wang. 2021. "An Improved Tikhonov-Regularized Variable Projection Algorithm for Separable Nonlinear Least Squares" Axioms 10, no. 3: 196. https://doi.org/10.3390/axioms10030196
APA StyleGuo, H., Liu, G., & Wang, L. (2021). An Improved Tikhonov-Regularized Variable Projection Algorithm for Separable Nonlinear Least Squares. Axioms, 10(3), 196. https://doi.org/10.3390/axioms10030196