1. Introduction
Together with the reform and opening up policies in China, “the third profit source” in enterprise logistics has become increasingly important for economic activity. As an important part of logistics activity, distribution directly affects how consumers evaluate logistics enterprises. Delayed delivery is a common problem in vehicle logistics, which leads to a decline in customer satisfaction and affects secondary consumption, and at the same time makes the relationship between customers and logistics enterprises tense, which is not conducive to the long-term development of logistics enterprises. For this reason, optimization of distribution is necessary. Because all uncertain information processing policies are different, the resulting solutions are often different.
Vehicle load distribution is an important component of logistics optimization. At the core of vehicle load distribution is how to reasonably arrange the goods to minimize the number of vehicles and ensure the vehicle loading rate without exceeding the load capacity of vehicles. Michael et al. [
1] analyzed the vehicle logistics with precise methods and optimized the vehicle logistics. Gizem et al. [
2] introduced and considered a dynamic variant of the vehicle routing problem with roaming delivery locations and developed an iterative re-optimization framework to solve it and focus on using branch-and-price in a dynamic decision-making environment to investigate its potential as a solution methodology for operational problems. Liu et al. [
3] presented a combinatorial optimization model for the courier delivery network design problem, and optimization aims to determine the transportation organization mode for each courier flow considering the frequency delay of accumulation in the sorting process. Wang et al. [
4] proposed the cooperation strategy for the green pickup and delivery problem (GPDP). Some researchers pay more attention to logistics and transportation optimization problems [
5,
6,
7,
8,
9,
10]. The above literature concerns reasonable optimization of distribution.
Many random factors in distribution can be represented using stochastic programming, and stochastic programming has been well studied. Al-Khamis et al. [
11] proposed a two-stage stochastic programming model for the parallel machine scheduling problem in which the objective was to determine the machine capacities that maximized the expected net profit of on-time jobs with uncertain due dates. Noyan et al. [
12] considered a risk-averse two-stage stochastic programming model with conditional value-at-risk (CVaR) as the risk measure. This approach constructed two decomposition algorithms based on the generic Benders-decomposition approach to solving such problems. Abdelaziz et al. [
13] surveyed various solution approaches for multi-objective stochastic problems in which random variables can exist in both the objectives and the constraint parameters. Abdelaziz et al. [
14] established stochastic programming models from different perspectives and proposed their own approaches and methods to solve stochastic problems. Wang et al. [
15] focused on finding a priori evacuation plans by considering side constraints, scenario-based stochastic link travel times, and capacities and proposed a stochastic programming framework for the reorganization of traffic routing for disaster response. Zahiri et al. [
16] proposed a novel multi-stage probabilistic stochastic programming approach and created a real post-disaster relief distribution planning case study. Goberna et al. [
17] dealt with uncertain multi-objective convex programming problems and presented sufficient conditions for the existence of highly robust weakly efficient solutions, that was, robust feasible solutions which were weakly efficient for any possible instance of the objective function within a specified uncertainty set. Ogbe et al. [
18] proposed a new cross-decomposition method combining two classical decomposition methods. The method outperformed Benders’ decomposition when the number of scenarios was large. Hasany et al. [
19] developed a two-stage stochastic program for the railroad blocking problem that considers the uncertainty inherent in demand and supply resource indicators and developed two exact algorithms based on the L-shaped method. Niu et al. [
20] presented a
d-minimal cut-based algorithm to evaluate the performance index
Rd+1 of a distribution network, defined as the probability that a specified demand
d + 1 can be successfully distributed through stochastic arc capacities from the source to the destination. Zheng et al. [
21] developed a multimodal macroscopic fundamental diagram (MFD) to represent the traffic dynamics in a multimodal transport system. Optimization was performed to minimize the total passenger hours traveled (PHT) to serve total demand by redistributing the road space among modes. Yu et al. [
22] addressed a new variant of the vehicle routing problem, called the two-echelon vehicle routing problem with time windows, covering options, and occasional drivers. Mancini et al. [
23] proposed a mixed delivery approach, which combines attended home delivery and f shared delivery location usage innovatively. Customers can either be served at home during their preferred time window, or they can be asked to pick up their parcel at one of the f shared delivery locations. Wang et al. [
24] proposed the two-stage delay distribution method based on a compensation mechanism under a random environment. Zhou et al. [
25] proposed the compensation mechanism of delayed distribution based on interest balance. Some researchers pay more attention to the logistics distribution problem [
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37].
There are shortcomings in the above-mentioned literature: Firstly, some researchers proposed the compensation mechanism for the delay distribution, but the research is too scant to improve the development of the delay distribution method. Secondly, there is no delay distribution involving n stages which only research stages 2–3. Furthermore, it is difficult to calculate the algorithm. Only the expectation or probability distribution is considered for the treatment of random variables without considering the variance, while the model error is large. Therefore the n-stage delay distribution method based on a compensation mechanism will be established to solve the above problems.
The remainder of this paper is organized as follows.
Section 2 contains the separate section notations.
Section 3 reviews the literature. In
Section 4, a delay distribution method based on penalty and the choice mechanism is analyzed. The solution procedure is proposed in
Section 5. A numerical example is given in
Section 6 to illustrate the effectiveness of the proposed model. The demarcation point of the delayed and non-delayed distribution is obtained, and the optimal solution is identified. A conclusion and recommended future research directions are given in the final section.
For narrative convenience, this paper uses the following definitions and assumptions: (1) is the integer part of , (e.g., int(1.1) = 1); and (2) is the remainder function of d about b (here, d and b are natural numbers, and ).
3. Delay Distribution Characteristic Analysis in a Random Environment
According to vehicle distribution characteristics, customer demand is a random variable. Therefore, the distribution model is a stochastic programming problem. In the distribution process, each nodal transportation task can be divided into non-fully loaded and fully loaded transport. Fully loaded transport can fully use the loading carrier capacity. Non-fully loaded transport is the total transportation task minus the remaining goods of the load transportation task. When the goods reach the conditions for full-load transportation, they need to be delivered on time on the delivery date. If they do not meet the conditions for full-load transportation, an additional cost is required for on-time delivery, which produces a certain penalty for delayed delivery. In this case, an important problem is determining the transportation plan that can minimize the cost. Based on the above situation, building an appropriate random distribution model and selecting the appropriate distribution threshold are highly important tasks for managers to make the correct decisions.
Delay distribution is an added limit, and additional uncertainty coexists in the complex decision problem, which has attracted widespread attention in academic applications. This section considers the full-load distribution problem in a random environment and discusses the method for determining the distribution mechanism.
To improve the service quality and management system, a car manufacturer transfers the car distribution to a third-party logistics company. The relevant regulations are as follows: (1) Set up n delivery days in each order cycle, that is, n time nodes; (2) All orders must be delivered within the order period; (3) If the number of orders on the current delivery day does not meet the conditions of full-load transportation, you can choose to postpone the delivery to the next delivery day, but delayed delivery requires a certain delivery penalty. In real life, based on the customer demand, the manufacturer supplies compensation to the customer, which can be viewed as a manufacturer’s penalty. We consider the delay choice in the process of the logistics distribution system.
Because delayed delivery is or is not closely related to the order number for the next time period, and because the next period of orders is a variable that depends on many factors, it needs to be treated as a random variable in data processing, the selection of delay delivery is a decision-making problem in a random environment. In this paper, we consider using the n = 2, n = 3, n = 4 and n = 10 delay distribution selection mechanisms to describe and verify. We make the following assumptions: If the order quantity does not meet the condition of full-load distribution, the distribution can be delayed; otherwise, the distribution cannot be delayed.
3.1. Choice Mechanism of 2-Stage Delay Distribution
For the first stage in which we cannot load distribution orders
k, and if, for the second stage, the order quantity is
with distribution
,
.
Z1(
k,
ξ2) is the cost function of choosing delayed delivery in the first stage,
Z2(
k,
ξ2) is the cost function of choosing delivery in the first stage. In the first stage,
k cars are delayed for delivery. Respectively, and these values are random variables; the distributions are as follows:
where
.
For example, when
, we consider the delay decision method. Using probability theory, we obtain the distribution of
Z1(4,
ξ2) and
Z2(4,
ξ2) as shown in
Table 4 and
Table 5, respectively.
Because
Z1(
k,
ξ2) and
Z2(
k,
ξ2) are random variables, and no simple order relation exists between random variables, we cannot solve the problem directly. Therefore, this problem is solved by describing the value of random variables through mathematical expectation. According to
Table 2, we transform
E(Z
1(4,
ξ2)) and
E(Z
2(4,
ξ2)) into the form of a function
As in the above analysis, we let ; then, we obtain . Therefore, if , the distribution will occur in the first period; otherwise, the distribution will not occur in the first period. We can see that θ and c have a positive linear proportional relationship. When θ is large, c is also large.
In the above analysis, when , we obtain the values of E(Z1(4, ξ2)) and E(Z2(4, ξ2)), which are convenient for managers in making the correct decisions in the first stage.
Through the above analysis, we can get obtain the 2-stage delay distribution mod-el (model (1)) as follows (
):
In model (1), Q is the maximum loading capacity of each transport vehicle, and c is the single departure cost of each transport vehicle. θ is the compensation for the delivery delay in the first stage. If we choose delayed delivery on the first delivery day, , the amount of delayed delivery is k (), and each delayed delivery of goods needs a penalty of , otherwise . During the order cycle, all orders must be completed delivered.
3.2. 3-Stage Choice Mechanism of Delay Distribution
For the stage that cannot load distribution orders
k, we assume that the distributions of stages 2 and 3 orders
and
are
and
, where
is the distribution cost when we use the delayed distribution in stages 1 and 2;
is the distribution cost when we use the distribution strategy in which delivery is delayed in stage 1, and no distribution delay occurs in stage 2;
is the distribution cost when we use the distribution strategy in which delivery is delayed in stage 2, and no delay of distribution occurs in stage 1, and
is the distribution costs when we do not use the delay distribution in stages 1 and 2. In this work,
are random variables, and the specific form is shown below:
where
.
From the above analysis, when only the expected cost is considered, we obtain the following (here,
are constants,
):
and when
(that is, the distribution strategy of delaying distribution in stages 1 and 2 is the best one), the following linear inequalities hold:
that is,
In real life, ; therefore, we can see that the region constituted by the above three linear inequalities is convex. The other distribution strategies also result in the above conclusion. Therefore, we obtain the following theorem.
Theorem 1. In the 3-stage delay distribution model, taking the expectation value as the evaluation standard, the dependency region of the single transport cost of each transport vehicle c and the penalty for each car delay in a period-of-time distribution θ is a convex region.
Remark 1. In a 2-stage delay distribution model, there is a linear relationship between c and θ, which is analyzed in Section 3.1. When we consider the n-stage delay distribution model (), Theorem 2.1 still holds because there is a linear relationship between c and θ. Thus, Theorem 3.1 holds for the n-stage delay distribution model (). As in the above analysis, we see that no matter if the distribution occurs in each stage, the above conclusion is established. Using the above analysis, we obtain the 3-stage delay distribution model (model (2)) as follows:
where
Q is the loading capacity of each distribution vehicle. The single transport cost for transporting vehicles is
c. In each month, if the distribution occurs in the first period,
x1 = 1; otherwise,
x1 = 0. If the distribution occurs in the second period,
x2 = 1; otherwise,
x2 = 0. Additionally,
k is the part of the first-period demand that cannot be load distribution;
ξ2 and
ξ3 are the demand of the second and third stages, respectively;
m is the total number of distribution vehicles; and
θ is the compensation for distribution delays for a period (ten days). In each month (three periods), the order must be met.
For example, when , we consider the delay decision method with 3 stages. At the end of the first stage, the part of the first-stage demand that cannot be a load distribution is 3. The part of the second-stage demand that cannot be a load distribution has 13 possibilities, which are . In each case, we decide between no delivery and delivery of 3 cars in the first stage. In the second stage, in some cases (for example, the part of the second-stage demand that cannot be load distribution is 5), if the 3 cars are not delivered in the first stage, we decide between no delivery and delivery of 8 (3 + 5) cars in the second stage; otherwise, we decide between no delivery and delivery of 5 cars in the second stage. There are 26 possibilities for no delivery or delivery of 3 cars in the first stage. With each possibility, the part of the third-stage demand that cannot be a load distribution also has 13 possibilities, which are . There are 676 (26 × 13 × 2 = 262) possibilities for no delivery or partial delivery of cars in the second stage, and so on. If we consider the n-stage delay distribution model, there are 26n possibilities for no delivery or partial delivery of cars in the second stage. From this analysis, we can see that the computational complexity is too high to solve using analytical methods. Next, we consider the demand as a random variable, with the corresponding expectation and variance.
4. The Generalized Expectation Value Model of Delay Distribution in a Random Environment
The goal is to build a model for each time period (including
n cycles) that minimizes the overall distribution cost. In this paper, we consider only the two most important costs, namely, the vehicle transportation cost and the delay penalty fee. Using the above analysis, we obtain the
n-stage delay distribution model (model (3)) as follows:
where
Q is the loading capacity of each distribution vehicle, and a single transport cost for transporting vehicles is
c. In each time period, if the distribution occurs in the
i-th period,
xi = 1; otherwise
xi = 0.
θ is the compensation for distribution delays for a period. In each month, the order must be met.
k is the part of the first-period demand that cannot be a load distribution,
is the cost of the
i-stage delay distribution, and
ξi is the demand of the
i-th stage.
Model (3) is a formal description model of the
n-stage problem. Using model (3), we can utilize the recursive solution method in
Section 4, which can be used in the following models (4) and (5).
Random information cannot be compared in the same manner as real numbers. Thus, model (3) is a formal description. The key to solving model (3) is to select a method to compare random information. Generally, we convert stochastic programming into crisp programming. If we consider the random variable expectation to describe the variables, the expectation value model can be expressed as model (4).
The model is recursive and crisp programming. If we want to obtain the solution of a 3-stage delay distribution model, we first find the solution of a 2-stage delay distribution model. If we want to obtain the solution of a 4-stage delay distribution model, we first find the solution of a 3-stage delay distribution model, and so on. Therefore, if we want to obtain the solution of model (4) (the expectation value model), we first solve the model with n-1 stages. The solution complexity of model (4) is far lower than that of model (3), which has 26n possible solutions.
The expected value is beneficial but merely one characteristic of a random variable. There is an essential difference between a random variable and its expected value. There are many inconsistencies between the expected value model and a random decision in the structure. The core inconsistency is that the decision reliability of the model cannot be reflected. In the statistical sense, min
ξ meets the reliability
β, min
a meets
, and
Here, Zβ is the β-quantile of (that is, ). Thus, if we regard Zβ as a constant C, can be converted into .
The following can be easily seen. (1) In (*), β should be a larger value (for example, ), and when β is large, Zβ is a non-negative value (for example, when ξ obeys the normal distribution, Z0.75 = 0.68, Z0.90 = 1.29, and Z0.95 = 1.65; when ξ obeys the exponential distribution, Z0.75 = 0.39, Z0.90 = 1.30, and Z0.95 = 1.99; and when ξ obeys the uniform distribution, Z0.75 = 0.87, Z0.90 = 1.39, and Z0.95 = 1.56). This fact indicates that C in should be non-negative (generally, ). (2) If we regard the variance as the credibility measure index of “using the expected value to collect the value of the random variable,” C can be interpreted as a penalty coefficient (the effect weakened by uncertainty). (3) When , is the mathematical expectation , which implies that can be regarded as the generalized expectation of ξ.
According to this analysis, it is a compound quantization model with both the size characteristics and the uncertainty of the value. The measurement model based on model (3) can be generalized into the following model (5) (called the
generalized expectation value model, abbreviated as GEM):
Using the above discussion, we can see that (1) when C = 0, model (5) is model (4), and the computational complexities of model (5) and model (4) are the same; (2) model (5) has good structural characteristics and can be explained by the different values, which reflect the degree of randomness in the decision-making process; and (3) model (5) defines the statistical significance (i.e., the reliability quantile of ). In the actual problem, we can choose the specific value of C via the distribution characteristics of .
From this analysis, we observe that model (5) contains the traditional random processing method. With the different types of synthesis effect functions, the model shows different decision-making approaches, increasing computational complexity.
6. Numerical Examples
In this section, selected examples are presented to demonstrate the effectiveness of the proposed model.
Case 1 (2-stage delay distribution problem). The automobile manufacturer cooperates with the third-party logistics company, and the third-party logistics company is responsible for transporting the produced automobiles to the automobile dealers. There are two delivery dates in a delivery cycle, that is, two time nodes. If the goods are not delivered in time on the first delivery day, the third-party logistics company needs to compensate the car dealers, and the compensation for each commercial car is θ. All orders need to be completed before the second delivery date.
The third-party logistics company’s distribution vehicle load capacity is 12 (Q = 12), and the vehicle type is the same, the unit transportation cost of each distribution vehicle is C. The demand on each delivery day is a random variable. If the delivery is timely, the transportation cost is Z1(k, ξ2); Otherwise, the transportation cost is Z2(k, ξ2).
After the distribution of the commercial vehicles before the first delivery date is arranged according to the load of the distribution vehicles, the remaining 9 vehicles do not meet the full load distribution standard. In order to reduce the cost of the third party logistics enterprises, we arrange according to the distribution demand of the next delivery day. The distribution demand of the next delivery day is predicted by the historical data, as shown in
Table 6. (These data are obtained from actual research and statistics and have a certain degree of credibility.)
The demand in stage 2 is
. With
Table 3, we obtain
. According to the demand distribution, we obtain the cost when the demand for vehicles is 8 in this period.
We obtain
E(z
1) = 1.95
c + 9
θ and
E(z
2) = 2.08
c. Using the above analysis, we obtain
Table 8 and
Table 9 in
Table 7.
With the expectation value model, we only consider the expectation of
Z1(
k,
ξ2) and
Z2(
k,
ξ2). From
Table 6, we can see that, for a given
c and
θ,
E(
Z1(
k,
ξ2)) is monotonous and increasing about
k. Using this analysis method, the solution of model (4) (the expectation value model) is
x1 = 1, the optimal global solution. The other cases of average cost are addressed with different
c and
θ values. Using the proposed algorithm with Matlab 7.0, we obtain the GEM solutions, as shown in
Table 10. We obtain the expected cost
E(
Z2(
k,
ξ2)) and the generalized expectation cost
.
When
C = 0, the GEM degenerates into an expectation value model. From
Table 10, we note that the proposed method’s solutions contain the solutions
x1 = 1 and
x1 = 0, which are the solutions of the expectation value model. Thus, the solution is more reliable. All results were obtained using a single core of a 24-core AMD EPYC 7451 CPU running at a base clock frequency of 3.1 GHz. The computation time is 0.0421 s.
Model (5) represents different decision preferences. In the generalized expected value model, when C is small, the third-party logistics company mainly focuses on the expected value of transportation cost. When C is large, the third-party logistics company mainly focuses on the variance of the second stage demand.
Case 2 (3-stage delay distribution problem). This case is similar to Case 1, except that each month contains three transportation time points, i.e., the 10th, 20th, and 30th.
The demand in stages 2 and 3 is
and
, and the distributions are Pr(
ξ2 =
l2) and Pr(
ξ3 =
l3), respectively, whcih are shown in
Table 11. From
Table 7, we find that
and
. As in the analysis in
Section 3.2 and Theorem 3.1, the relation of
c and
θ is as shown in
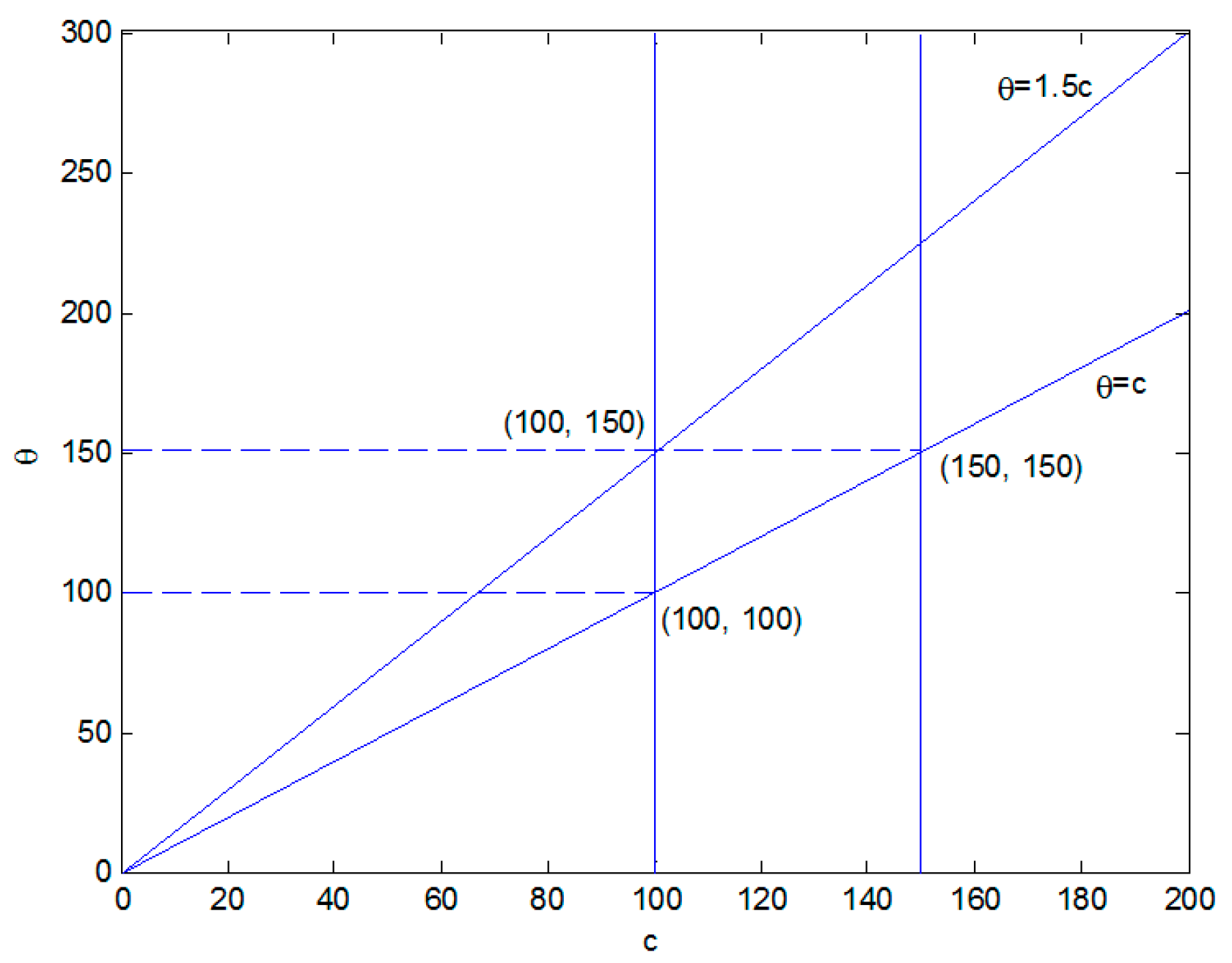
Figure 1.
If we only consider the expectation value, we can observe that, for c = 100, when , we use the delay distribution in stages 1 and 2. When , we use the distribution strategy to delay delivery in stage 1, with no delay in stage 2. When , we use the distribution strategy in which delivery is delayed in stage 2, and no distribution delay occurs in stage 1. When , we do not use the delay distribution in stages 1 and 2. We can also determine that, for θ = 1000, when , we do not use the delay distribution in stages 1 and 2. When , we use the distribution strategy in which delivery is delayed in stage 2 with no distribution delay in stage 1. When , we use the distribution strategy in which delivery is delayed in stage 1, and there is no distribution delay in stage 2. When , we use the distribution delay in stages 1 and 2.
Using the proposed algorithm with Matlab 7.0, we obtain the GEM solutions, as shown in
Table 12.
From
Table 12, we note that when
, the solution of the proposed method contains the solution
x1 = 1,
x2 = 0, which is the solution of the expectation value model. With different
C values, the solutions are different, which shows different decision-making preferences. When the
C value is small, the solution is the same as that of the expectation value model. When the
C value is large, the solution indicates that more attention should be paid to the variance in the random variable. Thus, the solution is more reliable. All results were obtained using a single core of a 24-core AMD EPYC 7451 CPU running at a base clock frequency of 3.1 GHz. The computation time is 0.1266 s.
Case 3 (
4-stage delay distribution problem). This case is similar to
Case 1, except that each month contains four transportation time points, i.e., the 7th, 14th, 21st, and 30
th, as shown in
Table 13.
The demand in stages 2, 3 and 4 is
,
,
, and the distributions are Pr(
ξ2 =
l2), Pr(
ξ3 =
l3), Pr(
ξ4 =
l4), respectively. From
Table 11, we obtain
, and
. As in the analysis in
Section 3.2, we can determine the relation of
c and
θ, as shown in
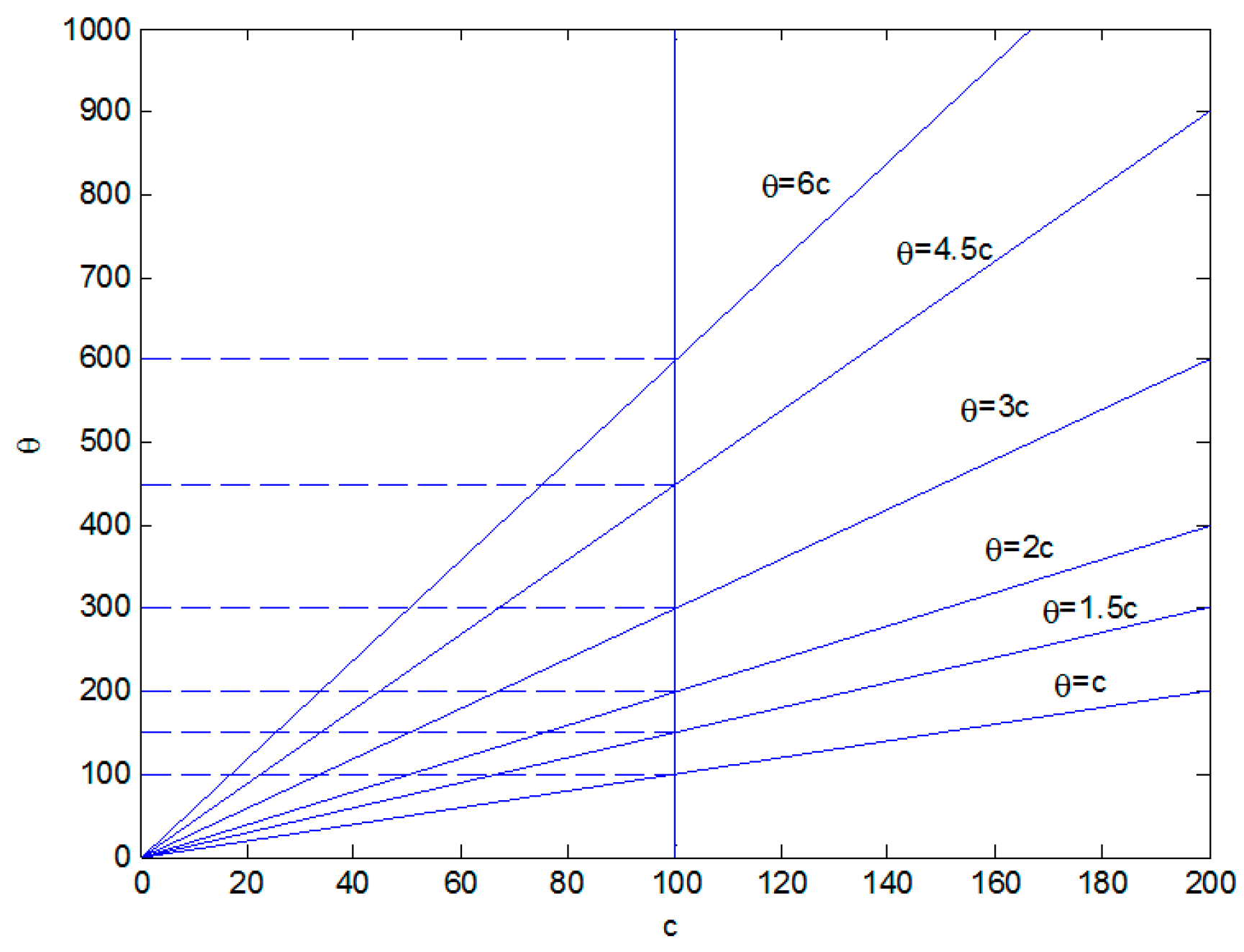
Figure 2.
Next, we only consider, for a given c, the changes that range near θ. For a given θ, the change analysis of c is similar. For a given c = 100, when , we use the delay distribution in stages 1, 2, and 3. When , we use the distribution strategy to delay delivery in stage 1, with no distribution delay in stages 2 and 3. When , we use the distribution strategy in which delivery is delayed in stage 2 with no distribution delay in stages 1 and 3. When , we use the distribution strategy in which delivery is delayed in stage 3, and no distribution delay occurs in stages 1 and 2. When , we use the distribution strategy in which delivery is delayed in stages 1 and 2, and no distribution delay occurs in stage 3. When , we use the distribution strategy in which delivery is delayed in stages 1 and 3, and no distribution delay occurs in stage 2. When , we use the distribution strategy in which delivery is delayed in stages 2 and 3, and no distribution delay occurs in stage 1. When , we use the distribution strategy in which delivery is delayed in stages 1, 2, and 3.
Using the proposed algorithm with Matlab 7.0, we obtain the GEM solutions, as shown in
Table 14.
From
Table 14, we note that when
, the solution of the proposed method contains the solution
x1 = 0,
x2 = 1,
x3 = 0, which is the solution of the expected value model. With different
C values, the solutions are different and show different decision-making preferences. When the
C value is small, the solution is the same as the expected value model. When the
C value is large, the solution pays more attention to the variance of the random variable. Thus, the solution is more reliable. All results were obtained using a single core of a 24-core AMD EPYC 7451 CPU running at a base clock frequency of 3.1 GHz. The computation time is 0.3214 s.
Case 4 (10-stage delay distribution problem). This case is similar to Case 1, except that each month contains ten transportation time points, i.e., the 3rd, 6th, 9th, 30th.
According to historical data, we forecast the next 9 stage node demand probability distributions as shown in
Table 15.
From
Table 15, we obtain
For
C = 0.1 and
c = 100, using the proposed algorithm with Matlab 7.0, we obtain the GEM solutions, as shown in
Table 16.
From
Table 16, we note that when
, the solutions of the proposed method contain the solution
x1 = 0,
x2 = 1,
x3 = 0,
x4 = 0,
x5 = 1,
x6 = 0,
x7 = 0,
x8 = 1,
x9 = 0, which is the solution of the expected value model. Thus, the solution is more reliable. All results were obtained using a single core of a 24-core AMD EPYC 7451 CPU running at a base clock frequency of 3.1 GHz.The computation time is 1.2279 s. From
Case 4, we can see that, if the stage 2 to stage-
n node demand probability distributions are given, the proposed method can be developed into an
n-stage case.
From the above analysis, we can see that the proposed model can solve the n-stage delayed distribution problem. It can be concluded whether the distribution should be delayed at each stage with different c and θ. This conclusion can well assist logistics enterprises to make the optimal decision, to reduce the total cost and improve the efficiency of logistics enterprises. In real life, the stage number is not large, so the proposed model has good system structure features and interpretability, and it can be used in a wide variety of applications.







{kind=link}
{kind=link}