
Analysis of the Term Structure of Major Currencies Using Principal Component Analysis and Autoencoders



Abstract
:1. Introduction
2. Literature Review
3. Data Description and Methods
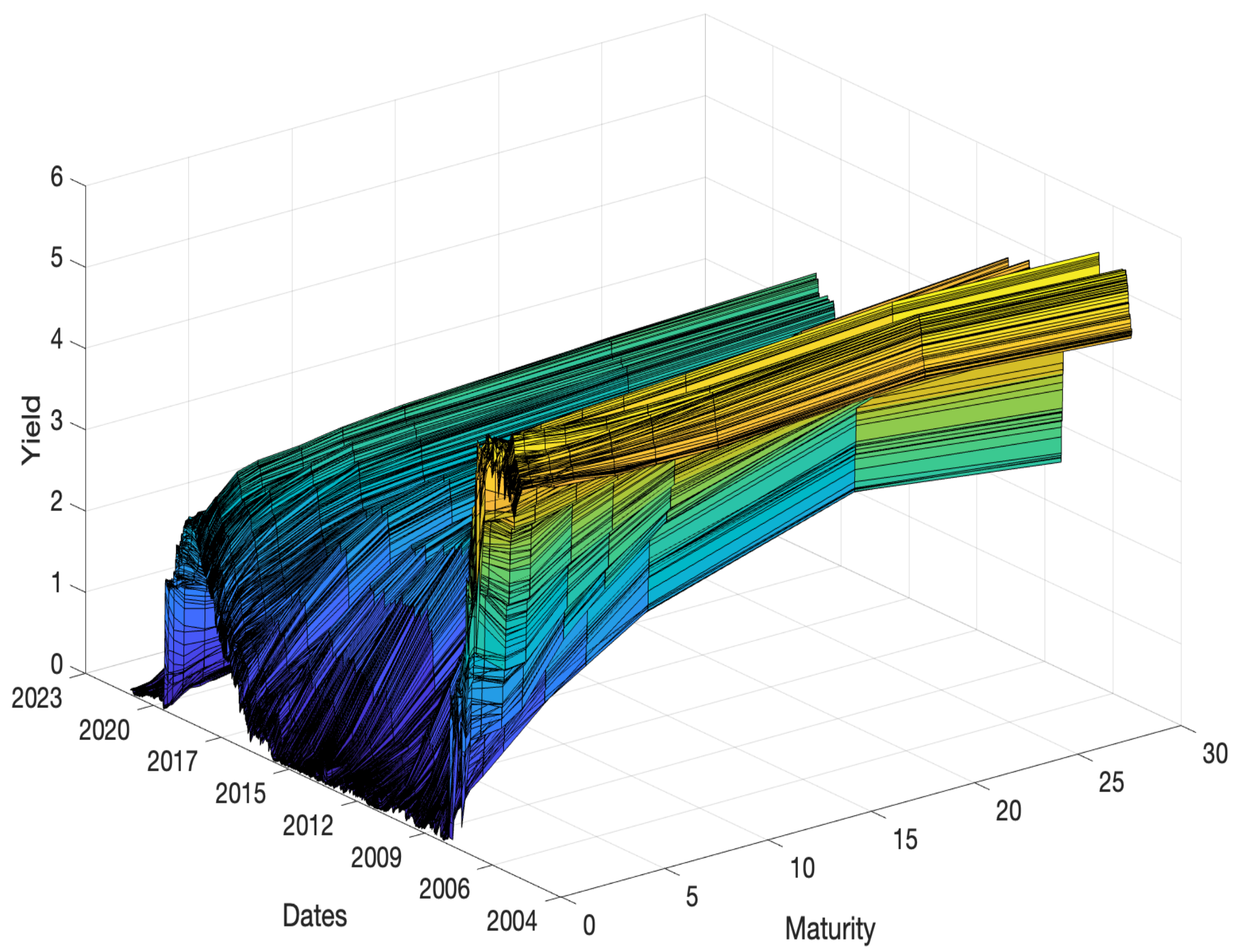
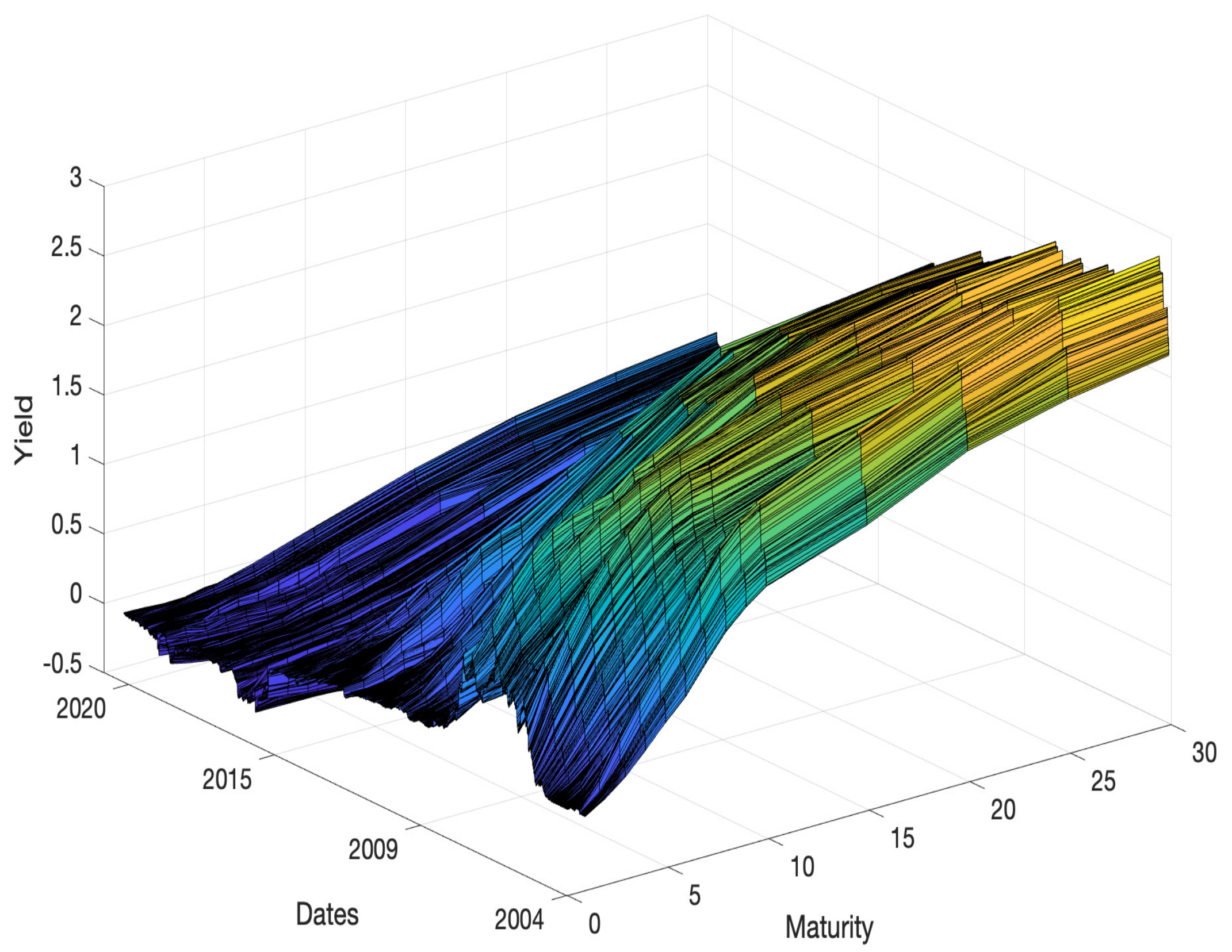
3.1. Data Description
3.2. PCA
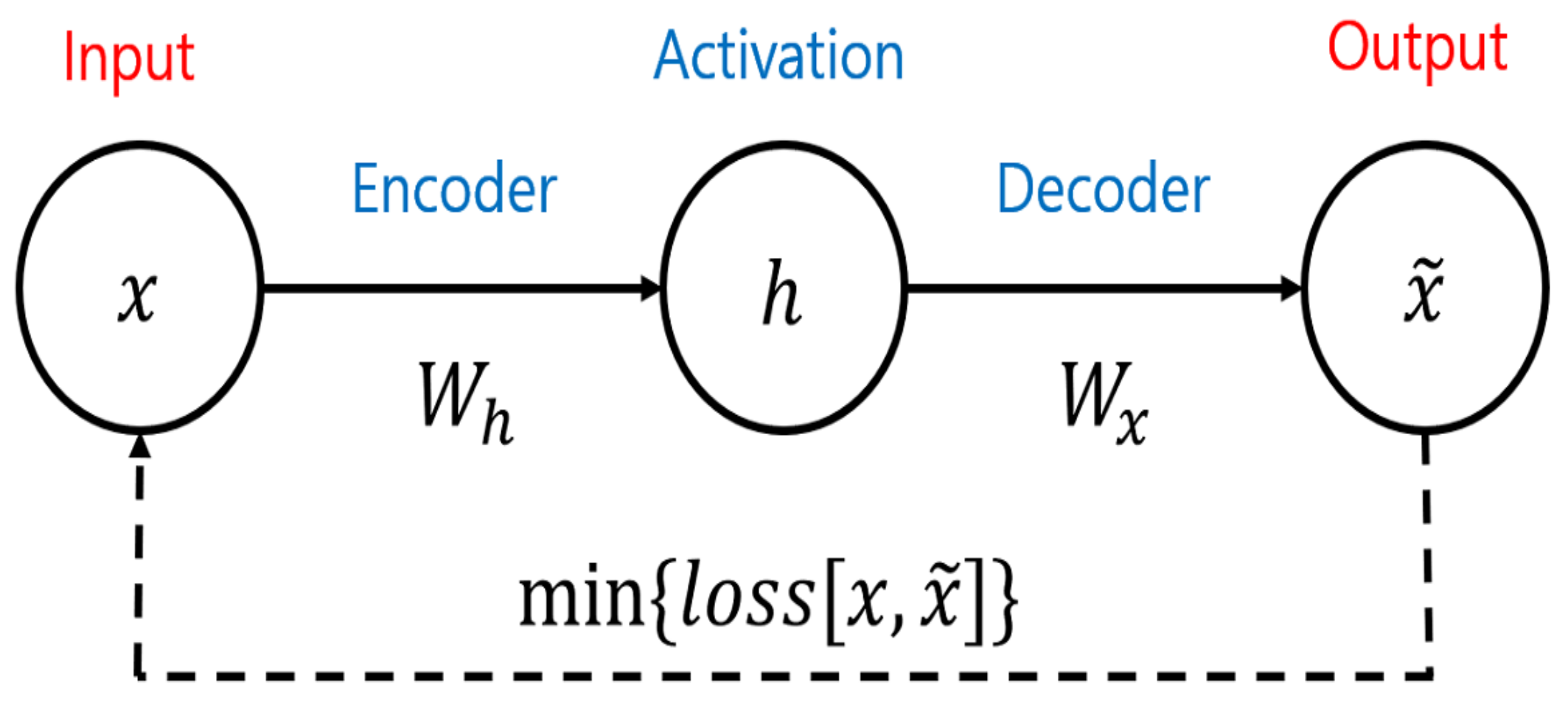
3.3. AE
4. Results
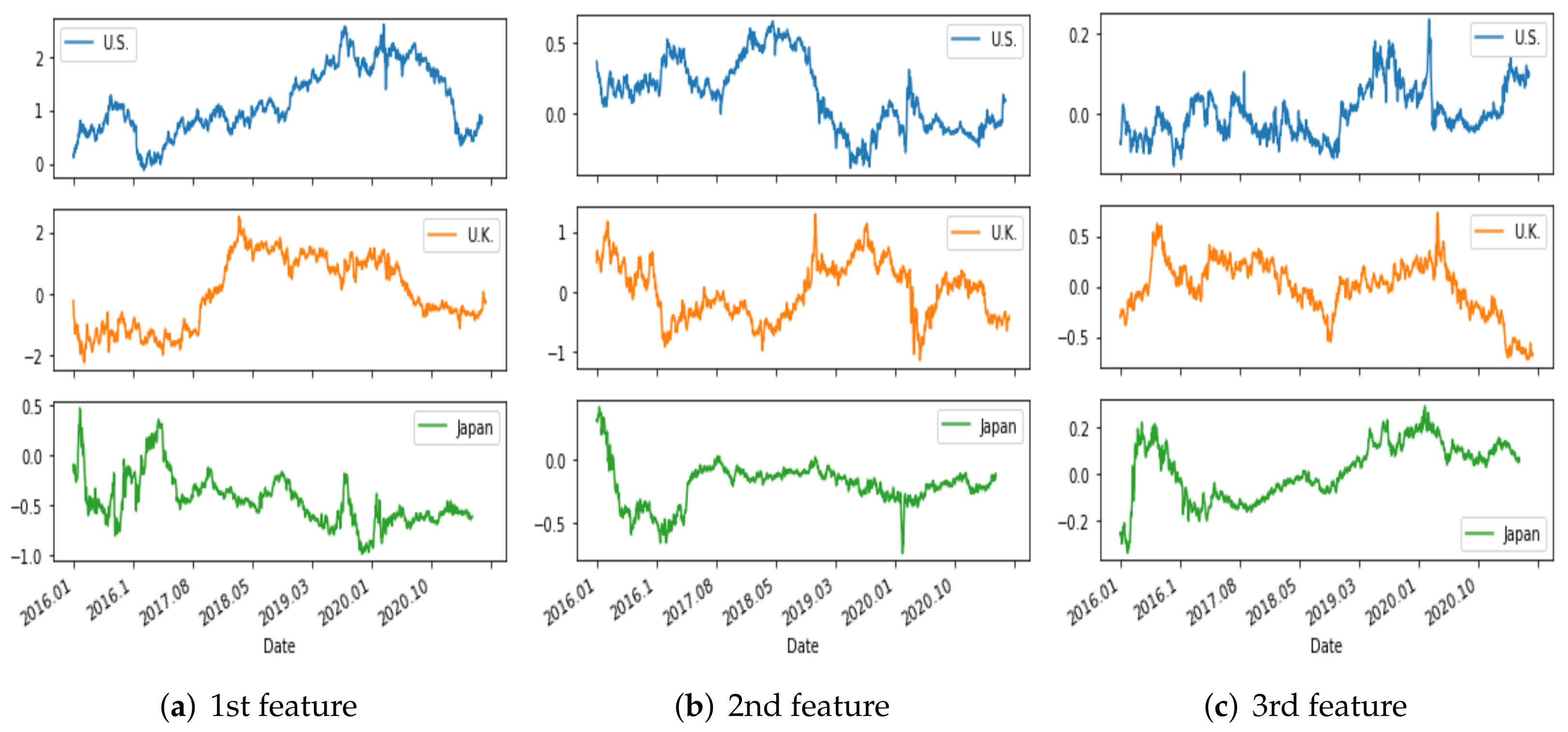
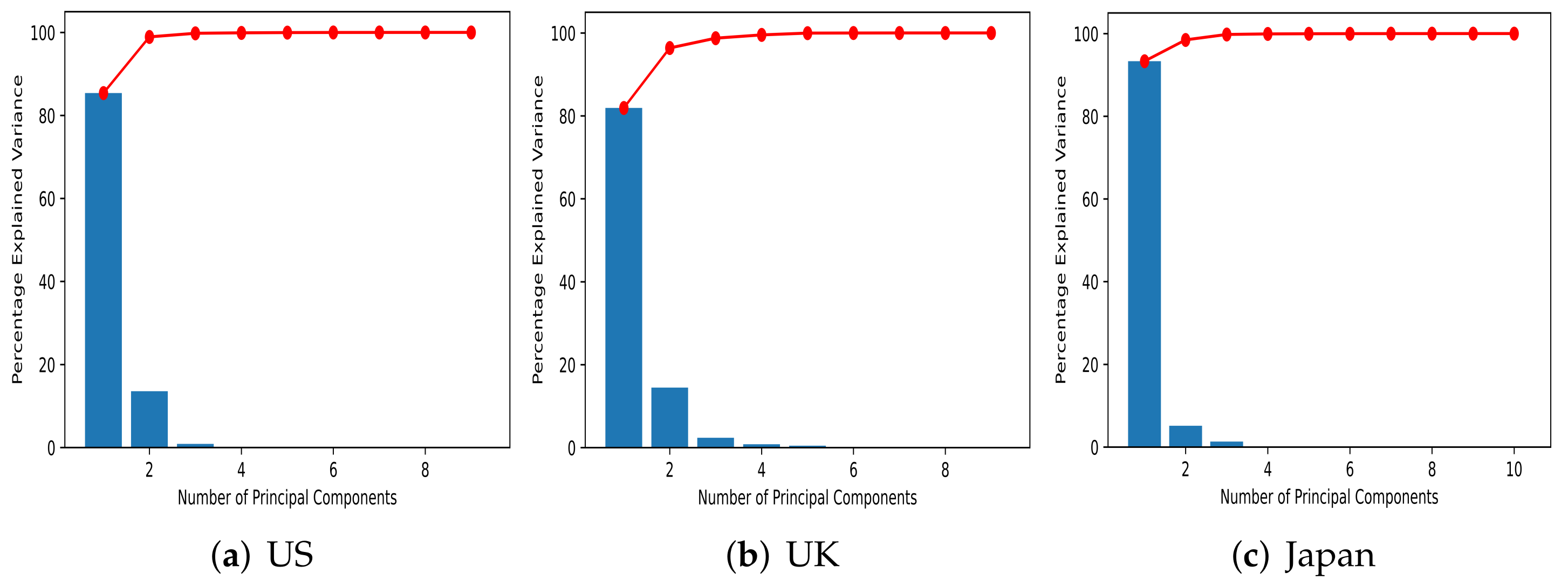
4.1. PCA
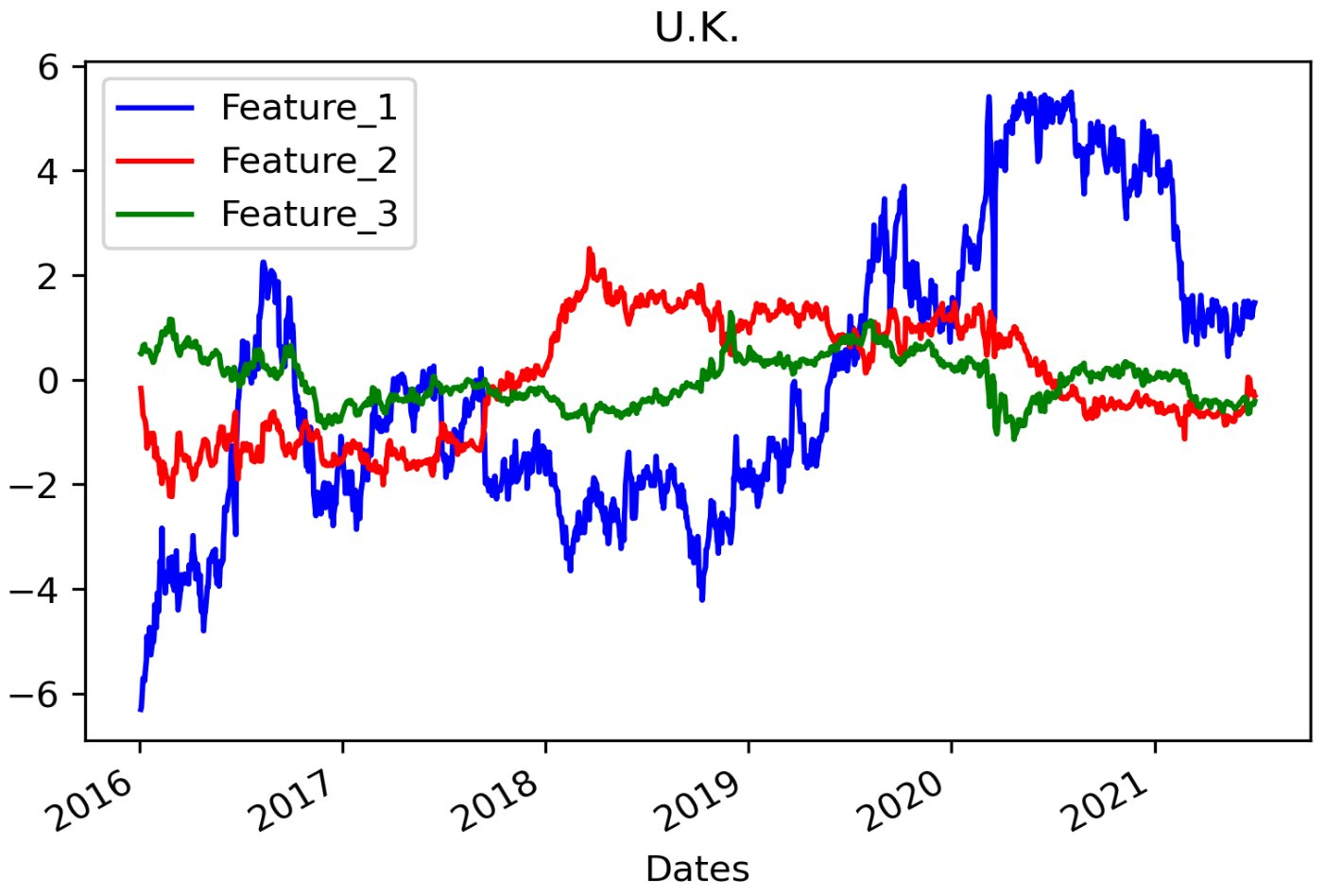
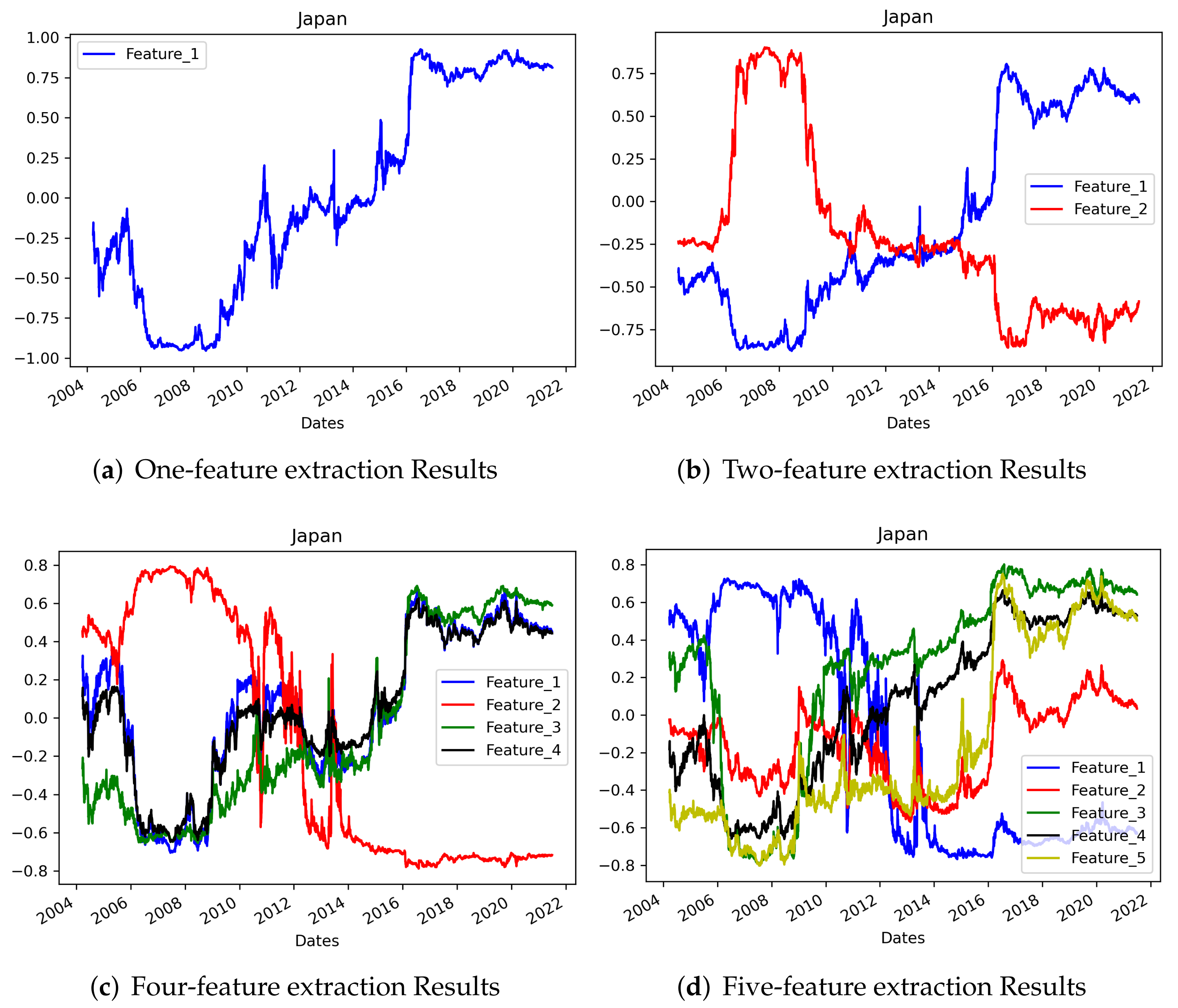
4.2. AE
4.3. Comparisons
4.3.1. Comparison of the PCA and AE Results
4.3.2. Comparison of the AE Results Obtained with Different Numbers of Layers
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chacko, G.; Das, S. Pricing interest rate derivatives: A general approach. Rev. Financ. Stud. 2002, 15, 195–241. [Google Scholar] [CrossRef]
- Rudebusch, G.D.; Wu, T. A macro-finance model of the term structure, monetary policy and the economy. Econ. J. 2008, 118, 906–926. [Google Scholar] [CrossRef] [Green Version]
- Duffee, G.R. The relation between treasury yields and corporate bond yield spreads. J. Financ. 1998, 53, 2225–2241. [Google Scholar] [CrossRef]
- Nelson, C.R.; Siegel, A.F. Parsimonious modeling of yield curves. J. Bus. 1987, 60, 473–489. [Google Scholar] [CrossRef]
- Pooter, M.D. Examining the Nelson-Siegel Class of Term Structure Models; Technical Report, Tinbergen Institute Discussion Paper; SSRN: Rochester, NY, USA, 2007. [Google Scholar]
- Koopman, S.J.; Mallee, M.I.; Van der Wel, M. Analyzing the term structure of interest rates using the dynamic Nelson–Siegel model with time-varying parameters. J. Bus. Econ. Stat. 2010, 28, 329–343. [Google Scholar] [CrossRef] [Green Version]
- Luo, X.; Han, H.; Zhang, J.E. Forecasting the term structure of Chinese Treasury yields. Pac.-Basin Financ. J. 2012, 20, 639–659. [Google Scholar] [CrossRef]
- Subramanian, K. Term structure estimation in illiquid markets. J. Fixed Income 2001, 11, 77–86. [Google Scholar] [CrossRef]
- Svensson, L.E. Estimating and Interpreting Forward Interest Rates: Sweden 1992–1994; National Bureau of Economic Research: Cambridge, MA, USA, 1994. [Google Scholar]
- Christensen, J.H.; Diebold, F.X.; Rudebusch, G.D. An Arbitrage-Free Generalized Nelson–Siegel Term Structure Model; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Novosyolov, A.; Satchkov, D. Global term structure modelling using principal component analysis. J. Asset Manag. 2008, 9, 49–60. [Google Scholar] [CrossRef]
- Chantziara, T.; Skiadopoulos, G. Can the dynamics of the term structure of petroleum futures be forecasted? Evidence from major markets. Energy Econ. 2008, 30, 962–985. [Google Scholar] [CrossRef]
- Juneja, J. Common factors, principal components analysis, and the term structure of interest rates. Int. Rev. Financ. Anal. 2012, 24, 48–56. [Google Scholar] [CrossRef]
- Sowmya, S.; Prasanna, K.; Bhaduri, S. Linkages in the term structure of interest rates across sovereign bond markets. Emerg. Mark. Rev. 2016, 27, 118–139. [Google Scholar] [CrossRef]
- Wellmann, D.; Trück, S. Factors of the term structure of sovereign yield spreads. J. Int. Money Financ. 2018, 81, 56–75. [Google Scholar] [CrossRef]
- Choi, S.Y. The influence of shock signals on the change in volatility term structure. Econ. Lett. 2019, 183, 108593. [Google Scholar] [CrossRef]
- Barber, J.R. Empirical analysis of term structure shifts. J. Econ. Financ. 2021, 45, 360–371. [Google Scholar] [CrossRef]
- Kanevski, M.; Maignan, M.; Pozdnoukhov, A.; Timonin, V. Interest rates mapping. Phys. A Stat. Mech. Its Appl. 2008, 387, 3897–3903. [Google Scholar] [CrossRef] [Green Version]
- Gogas, P.; Papadimitriou, T.; Matthaiou, M.; Chrysanthidou, E. Yield curve and recession forecasting in a machine learning framework. Comput. Econ. 2015, 45, 635–645. [Google Scholar] [CrossRef] [Green Version]
- Plakandaras, V.; Gogas, P.; Papadimitriou, T.; Gupta, R. The informational content of the term spread in forecasting the US inflation rate: A nonlinear approach. J. Forecast. 2017, 36, 109–121. [Google Scholar] [CrossRef] [Green Version]
- Nunes, M.; Gerding, E.; McGroarty, F.; Niranjan, M. A comparison of multitask and single task learning with artificial neural networks for yield curve forecasting. Expert Syst. Appl. 2019, 119, 362–375. [Google Scholar] [CrossRef] [Green Version]
- Suimon, Y.; Sakaji, H.; Izumi, K.; Matsushima, H. Autoencoder-based three-factor model for the yield curve of Japanese government bonds and a trading strategy. J. Risk Financ. Manag. 2020, 13, 82. [Google Scholar] [CrossRef]
- Kim, W.J.; Jung, G.; Choi, S.Y. Forecasting Cds term structure based on nelson–siegel model and machine learning. Complexity 2020, 2020, 2518283. [Google Scholar] [CrossRef]
- Bianchi, D.; Büchner, M.; Tamoni, A. Bond risk premiums with machine learning. Rev. Financ. Stud. 2021, 34, 1046–1089. [Google Scholar] [CrossRef]
- Jung, G.; Choi, S.Y. Forecasting Foreign Exchange Volatility Using Deep Learning Autoencoder-LSTM Techniques. Complexity 2021, 2021, 6647534. [Google Scholar] [CrossRef]
- Kumar, R. Towards a Deeper Understanding of Yield Curve Movements. Available at SSRN 3657341. 2020. Available online: https://ssrn.com/abstract=3657341 (accessed on 4 January 2022).
- Sambasivan, R.; Das, S. A statistical machine learning approach to yield curve forecasting. In Proceedings of the 2017 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 2–3 June 2017; pp. 1–6. [Google Scholar]
- Diebold, F.X.; Li, C. Forecasting the term structure of government bond yields. J. Econom. 2006, 130, 337–364. [Google Scholar] [CrossRef] [Green Version]
- De Pooter, M. Examining the Nelson-Siegel Class of Term Structure Models: In-sample Fit Versus Out-of-Sample Forecasting Performance. Available at SSRN 992748. 2007. Available online: https://ssrn.com/abstract=992748 (accessed on 4 January 2022).
- Diebold, F.X.; Li, C.; Yue, V.Z. Global yield curve dynamics and interactions: A dynamic Nelson–Siegel approach. J. Econom. 2008, 146, 351–363. [Google Scholar] [CrossRef] [Green Version]
- Goukasian, L.; Cialenco, I. The reaction of term structure of interest rates to monetary policy actions. J. Fixed Income 2006, 16, 76–91. [Google Scholar] [CrossRef]
- Baruník, J.; Malinska, B. Forecasting the term structure of crude oil futures prices with neural networks. Appl. Energy 2016, 164, 366–379. [Google Scholar] [CrossRef] [Green Version]
- Kirczenow, G.; Hashemi, M.; Fathi, A.; Davison, M. Machine Learning for Yield Curve Feature Extraction: Application to Illiquid Corporate Bonds. arXiv 2018, arXiv:1812.01102. [Google Scholar]
- Cao, L.; Chua, K.S.; Chong, W.; Lee, H.; Gu, Q. A comparison of PCA, KPCA and ICA for dimensionality reduction in support vector machine. Neurocomputing 2003, 55, 321–336. [Google Scholar] [CrossRef]
- Ma, J.; Yuan, Y. Dimension reduction of image deep feature using PCA. J. Vis. Commun. Image Represent. 2019, 63, 102578. [Google Scholar] [CrossRef]
- Litterman, R.; Scheinkman, J. Common factors affecting bond returns. J. Fixed Income 1991, 1, 54–61. [Google Scholar] [CrossRef]
- Dai, Q.; Singleton, K.J. Specification analysis of affine term structure models. J. Financ. 2000, 55, 1943–1978. [Google Scholar] [CrossRef]
- Heidari, M.; Wu, L. Are interest rate derivatives spanned by the term structure of interest rates? J. Fixed Income 2003, 13, 75–86. [Google Scholar] [CrossRef]
- Blaskowitz, O.; Herwartz, H. Adaptive forecasting of the EURIBOR swap term structure. J. Forecast. 2009, 28, 575–594. [Google Scholar] [CrossRef] [Green Version]
- Fengler, M.; Härdle, W.; Schmidt, P. Common factors governing VDAX movements and the maximum loss. Financ. Mark. Portf. Manag. 2002, 16, 16. [Google Scholar] [CrossRef] [Green Version]
- Barber, J.R.; Copper, M.L. Principal component analysis of yield curve movements. J. Econ. Financ. 2012, 36, 750–765. [Google Scholar] [CrossRef]
- Le Cun, Y.; Fogelman-Soulié, F. Modèles connexionnistes de l’apprentissage. Intellectica 1987, 2, 114–143. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. Adv. Neural Inf. Process. Syst. 2007, 19, 153–160. [Google Scholar]
- Lord, R.; Pelsser, A. Level–Slope–Curvature–Fact or Artefact? Appl. Math. Financ. 2007, 14, 105–130. [Google Scholar] [CrossRef] [Green Version]
- Fabozzi, F.J.; Martellini, L.; Priaulet, P. Predictability in the shape of the term structure of interest rates. J. Fixed Income 2005, 15, 40–53. [Google Scholar] [CrossRef]
- Tabak, B.M. A note on the effects of monetary policy surprises on the Brazilian term structure of interest rates. J. Policy Model. 2004, 26, 283–287. [Google Scholar] [CrossRef]
- Kaminska, I.; Meldrum, A.; Smith, J. A Global Model Of International Yield Curves: No-Arbitrage Term Structure Approach. Int. J. Financ. Econ. 2013, 18, 352–374. [Google Scholar] [CrossRef]
- Jorion, P.; Mishkin, F. A multicountry comparison of term-structure forecasts at long horizons. J. Financ. Econ. 1991, 29, 59–80. [Google Scholar] [CrossRef] [Green Version]
- Sørensen, C.K.; Werner, T. Bank Interest Rate Pass-through in the Euro Area: A cross Country Comparison; Technical Report, ECB Working Paper; European Central Bank: Frankfurt, Germany, 2006. [Google Scholar]
- Hardouvelis, G.A. The term structure spread and future changes in long and short rates in the G7 countries: Is there a puzzle? J. Monet. Econ. 1994, 33, 255–283. [Google Scholar] [CrossRef]
- Clarida, R.H.; Sarno, L.; Taylor, M.P.; Valente, G. The out-of-sample success of term structure models as exchange rate predictors: A step beyond. J. Int. Econ. 2003, 60, 61–83. [Google Scholar] [CrossRef] [Green Version]
- Inci, A.C.; Lu, B. Exchange rates and interest rates: Can term structure models explain currency movements? J. Econ. Dyn. Control 2004, 28, 1595–1624. [Google Scholar] [CrossRef]
- De Los Rios, A.D. Can affine term structure models help us predict exchange rates? J. Ournal Money Credit. Bank. 2009, 41, 755–766. [Google Scholar] [CrossRef]
- Bui, A.T.; Fisher, L.A. The relative term structure and the Australian-US exchange rate. Stud. Econ. Financ. 2016, 33, 417–436. [Google Scholar] [CrossRef]
- Kaya, H. Forecasting the yield curve and the role of macroeconomic information in Turkey. Econ. Model. 2013, 33, 1–7. [Google Scholar] [CrossRef]
- Hong, Z.; Niu, L.; Zeng, G. US and Chinese yield curve responses to RMB exchange rate policy shocks: An analysis with the arbitrage-free Nelson-Siegel term structure model. China Financ. Rev. Int. 2019, 9, 360–385. [Google Scholar] [CrossRef]
- Nunes, M.; Gerding, E.; McGroarty, F.; Niranjan, M. The memory advantage of long short-term memory networks for bond yield forecasting.Available at SSRN 3415219. 2019. Available online: https://ssrn.com/abstract=3415219 (accessed on 4 January 2022).
- Nunes, M.; Gerding, E.; McGroarty, F.; Niranjan, M. Artificial Neural Networks in Fixed Income Markets for Yield Curve Forecasting. Available at SSRN 3144622. 2018. Available online: https://ssrn.com/abstract=3144622 (accessed on 4 January 2022).
- Ying, J.C.; Wang, Y.B.; Chang, C.K.; Chang, C.W.; Chen, Y.H.; Liou, Y.S. DeepBonds: A Deep Learning Approach to Predicting United States Treasury Yield. In Proceedings of the 2019 Twelfth International Conference on Ubi-Media Computing (Ubi-Media), Bali, Indonesia, 5–8 August 2019; pp. 245–250. [Google Scholar]
- Yu, W.; Kim, I.Y.; Mechefske, C. An improved similarity-based prognostic algorithm for RUL estimation using an RNN autoencoder scheme. Reliab. Eng. Syst. Saf. 2020, 199, 106926. [Google Scholar] [CrossRef]
- Yu, W.; Kim, I.Y.; Mechefske, C. Analysis of different RNN autoencoder variants for time series classification and machine prognostics. Mech. Syst. Signal Process. 2021, 149, 107322. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| US term structure | |||||||||
| Index | Mean | Std. Dev. | 1st pctl. | 10th pctl. | 25th pctl. | Median | 75th pctl. | 90th pctl. | 99th pctl. |
| 1Y | 1.187 | 0.879 | 0.05 | 0.1 | 0.43 | 1.12 | 1.96 | 2.468 | 2.7 |
| 2Y | 1.294 | 0.873 | 0.11 | 0.15 | 0.54 | 1.3 | 1.96 | 2.56 | 2.88 |
| 3Y | 1.390 | 0.856 | 0.15 | 0.21 | 0.61 | 1.47 | 2.05 | 2.64 | 2.952 |
| 5Y | 1.597 | 0.807 | 0.26 | 0.37 | 0.9 | 1.68 | 2.2 | 2.75 | 3.03 |
| 7Y | 1.805 | 0.756 | 0.44 | 0.582 | 1.31 | 1.84 | 2.35 | 2.828 | 3.111 |
| 10Y | 1.963 | 0.711 | 0.59 | 0.78 | 1.56 | 2 | 2.49 | 2.88 | 3.172 |
| 20Y | 2.297 | 0.596 | 1.01 | 1.302 | 1.92 | 2.33 | 2.78 | 3 | 3.29 |
| 30Y | 2.506 | 0.575 | 1.229 | 1.522 | 2.19 | 2.65 | 2.99 | 3.11 | 3.37 |
| UK term structure | |||||||||
| Index | Mean | Std. Dev. | 1st pctl. | 10th pctl. | 25th pctl. | Median | 75th pctl. | 90th pctl. | 99th pctl. |
| 1Y | 0.314 | 0.297 | −0.124 | −0.033 | 0.049 | 0.245 | 0.562 | 0.747 | 0.862 |
| 2Y | 0.415 | 0.343 | −0.198 | −0.063 | 0.164 | 0.384 | 0.708 | 0.906 | 1.061 |
| 3Y | 0.607 | 0.412 | −0.169 | −0.010 | 0.339 | 0.568 | 0.939 | 1.153 | 1.390 |
| 5Y | 1.018 | 0.536 | 0.052 | 0.195 | 0.539 | 1.135 | 1.466 | 1.644 | 1.983 |
| 7Y | 1.404 | 0.601 | 0.319 | 0.486 | 0.833 | 1.588 | 1.885 | 2.109 | 2.377 |
| 10Y | 1.881 | 0.594 | 0.762 | 0.975 | 1.380 | 2.056 | 2.336 | 2.601 | 2.847 |
| 20Y | 2.076 | 0.557 | 0.935 | 1.285 | 1.663 | 2.157 | 2.424 | 2.610 | 3.364 |
| 30Y | 1.081 | 0.394 | 0.094 | 0.554 | 0.844 | 1.134 | 1.295 | 1.557 | 1.920 |
| Index | Mean | Std. Dev. | 1st pctl. | 10th pctl. | 25th pctl. | Median | 75th pctl. | 90th pctl. | 99th pctl. |
| 1Y | −0.178 | 0.064 | −0.340 | −0.291 | −0.207 | −0.157 | −0.132 | −0.120 | −0.045 |
| 2Y | −0.171 | 0.057 | −0.335 | −0.258 | −0.202 | −0.153 | −0.131 | −0.117 | −0.029 |
| 3Y | −0.163 | 0.061 | −0.351 | −0.250 | −0.191 | −0.149 | −0.124 | −0.101 | −0.014 |
| 5Y | −0.140 | 0.072 | −0.364 | −0.240 | −0.171 | −0.115 | −0.096 | −0.076 | 0.012 |
| 7Y | −0.116 | 0.093 | −0.385 | −0.246 | −0.171 | −0.091 | −0.050 | −0.018 | 0.029 |
| 10Y | 0.007 | 0.093 | −0.273 | −0.127 | −0.043 | 0.031 | 0.063 | 0.099 | 0.220 |
| 20Y | 0.449 | 0.162 | 0.056 | 0.235 | 0.343 | 0.450 | 0.575 | 0.625 | 0.929 |
| 30Y | 0.631 | 0.211 | 0.125 | 0.353 | 0.459 | 0.651 | 0.808 | 0.856 | 1.208 |
| PC’s Explained Proportion | |||||||
|---|---|---|---|---|---|---|---|
| Index | PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 |
| US | 85.36 | 13.55 | 0.87 | 0.11 | 0.06 | 0.03 | 0.01 |
| U.K. | 81.88 | 14.48 | 2.38 | 0.79 | 0.43 | 0.02 | 0.01 |
| Japan | 93.33 | 5.15 | 1.31 | 0.04 | 0.02 | 0.01 | 0.01 |
| Index | F.1 | F.2 | F.3 | F.4 | F.5 | |
| US | F.1 | 0.147 | −0.137 | −0.590 | −0.930 | 0.942 |
| UK | F.1 | 0.896 | −0.972 | 0.992 | −0.914 | 0.900 |
| Japan | F.1 | −0.861 | 0.528 | 0.911 | 0.987 | 0.946 |
| Index | F.1 | F.2 | F.3 | F.4 | F.5 | |
| US | F.1 | 0.967 | 0.853 | 0.328 | −0.095 | 0.368 |
| F.2 | 0.286 | 0.550 | 0.743 | 0.974 | −0.877 | |
| UK | F.1 | 0.829 | 0.934 | 0.987 | −0.935 | 0.901 |
| F.2 | −0.959 | 0.994 | −0.960 | 0.887 | −0.887 | |
| Japan | F.1 | −0.798 | 0.629 | 0.858 | 0.959 | 0.983 |
| F.2 | 0.785 | −0.489 | −0.990 | −0.920 | −0.804 | |
| Index | F.1 | F.2 | F.3 | F.4 | F.5 | |
| US | F.1 | 0.829 | 0.941 | 0.650 | 0.588 | −0.358 |
| F.2 | 0.106 | 0.339 | 0.578 | 0.801 | −0.811 | |
| F.3 | −0.576 | −0.329 | 0.299 | 0.686 | −0.862 | |
| UK | F.1 | 0.890 | −0.969 | 0.994 | −0.919 | 0.898 |
| F.2 | −0.917 | 0.965 | −0.961 | 0.862 | −0.844 | |
| F.3 | 0.657 | −0.815 | 0.896 | −0.977 | 0.979 | |
| Japan | F.1 | 0.617 | −0.760 | −0.698 | −0.834 | −0.979 |
| F.2 | 0.571 | −0.326 | −0.900 | −0.688 | −0.495 | |
| F.3 | −0.894 | 0.469 | 0.926 | 0.996 | 0.921 | |
| Index | F.1 | F.2 | F.3 | F.4 | F.5 | |
| US | F.1 | 0.972 | 0.961 | 0.472 | 0.230 | 0.090 |
| F.2 | 0.638 | 0.395 | −0.171 | −0.640 | 0.833 | |
| F.3 | 0.513 | 0.737 | 0.768 | 0.909 | −0.710 | |
| F.4 | 0.848 | 0.659 | 0.194 | −0.355 | 0.594 | |
| UK | F.1 | 0.902 | −0.981 | 0.996 | −0.940 | 0.925 |
| F.2 | −0.696 | 0.515 | −0.336 | 0.064 | −0.058 | |
| F.3 | 0.826 | −0.937 | 0.992 | −0.964 | 0.936 | |
| F.4 | −0.652 | 0.817 | −0.912 | 0.989 | −0.970 | |
| Japan | F.1 | −0.575 | 0.741 | 0.898 | 0.844 | 0.862 |
| F.2 | 0.991 | −0.175 | −0.859 | −0.954 | −0.781 | |
| F.3 | −0.781 | 0.635 | 0.828 | 0.947 | 0.987 | |
| F.4 | −0.704 | 0.684 | 0.931 | 0.924 | 0.920 | |
| Index | F.1 | F.2 | F.3 | F.4 | F.5 | |
| US | F.1 | 1 | 0.951 | 0.612 | 0.637 | −0.911 |
| F.2 | 1 | 0.507 | 0.423 | −0.570 | ||
| F.3 | 1 | −0.730 | −0.866 | |||
| F.4 | 1 | 0.153 | ||||
| F.5 | 1 | |||||
| UK | F.1 | 1 | −0.966 | −0.967 | −0.943 | −0.990 |
| F.2 | 1 | 0.876 | 0.873 | 0.923 | ||
| F.3 | 1 | −0.730 | −0.866 | |||
| F.4 | 1 | 0.726 | ||||
| F.5 | 1 | |||||
| Japan | F.1 | 1 | 0.043 | 0.356 | 0.926 | 0.890 |
| F.2 | 1 | −0.803 | 0.344 | 0.762 | ||
| F.3 | 1 | −0.914 | 0.677 | |||
| F.4 | 1 | −0.685 | ||||
| F.5 | 1 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chae, S.C.; Choi, S.-Y. Analysis of the Term Structure of Major Currencies Using Principal Component Analysis and Autoencoders. Axioms 2022, 11, 135. https://doi.org/10.3390/axioms11030135
Chae SC, Choi S-Y. Analysis of the Term Structure of Major Currencies Using Principal Component Analysis and Autoencoders. Axioms. 2022; 11(3):135. https://doi.org/10.3390/axioms11030135
Chicago/Turabian StyleChae, Soo Chang, and Sun-Yong Choi. 2022. "Analysis of the Term Structure of Major Currencies Using Principal Component Analysis and Autoencoders" Axioms 11, no. 3: 135. https://doi.org/10.3390/axioms11030135
APA StyleChae, S. C., & Choi, S. -Y. (2022). Analysis of the Term Structure of Major Currencies Using Principal Component Analysis and Autoencoders. Axioms, 11(3), 135. https://doi.org/10.3390/axioms11030135