1. Introduction
Machine Learning plays a crucial role in extracting useful information in different research domains, for instance, medical data analysis [
1,
2,
3,
4], computer vision [
5], road accident analysis [
6], educational data mining [
7], sentiment analysis [
8] and many more. Instance reduction is one of the prime pre-processing tasks in machine learning applications. Before employing instance-based learning methods, alleviating the noisy, erroneous, and redundant data are highly desirable. Instance reduction mitigates sensitivity to noise and high storage requirements. Eventually, the complication of calculation to understand a superior classification technique decline. There should not be a noteworthy change in between-class distribution after and before data decline. A flawed data reduction technique may eradicate additional instances of one class, resulting in unfair datasets.
Instance reduction can be applied for both balanced and imbalanced data to improve classification performance. Researchers studied the instance decline from class-balanced data. However, there are not many studies on class-imbalanced data. Researchers attract to this issue in recent times because of practical applications in this domain [
9]. The imbalanced dataset poses difficulties in learning tasks. Traditional methods are exploited to learn from imbalanced data. Satisfactory outcomes are not yielded as these traditional methods execute excellent coverage for the mainstream class while marginal classes are disregarded. In some cases, high accuracies are demonstrated, but the outcome is not as trustworthy as the cardinality of the majority class is high contrasted to the minority class. For instance, the reduction to keep intact between-class distribution is vital. In imbalanced datasets, the minority class instances are also essential. Such instances may be treated as noise or outliers. However, these minority class instances must not be lessened while applying an instance reduction method. Hence, to take care of that, special techniques are needed.
Among different instance reduction methods for imbalanced data, data-level methods are of utmost importance. These data-level techniques can be classified into two types: oversampling, the size of the marginal class is enhanced and under-sampling, the size of the mainstream class is lessened, ensemble-based methods, and cost-sensitive methods. Various research papers suggested that evolutionary-based techniques performed better than the non-evolutionary ones in imbalanced dataset analysis and instance reduction.
Researchers have gained interest over the years to locate optimal values of the solution variables to meet definite conditions in case of global optimization concerns. Gigantic computational efforts are required for classical optimization methods that are inclined to be unsuccessful as the problem search space escalates. Meta-heuristic algorithms have come into the picture that exhibits better computational efficacy in evading local minima [
10]. These meta-heuristic algorithms showcased their superiority for tackling complex issues in different domains for the subsequent causes. (i) They can circumvent local minima; (ii) the gradient of the objective function is not needed; (iii) they are easy to implement and simple; (iv) different problems of various fields can be solved by utilizing it. The increasing processing power of computers has a positive impact on the development of such algorithms.
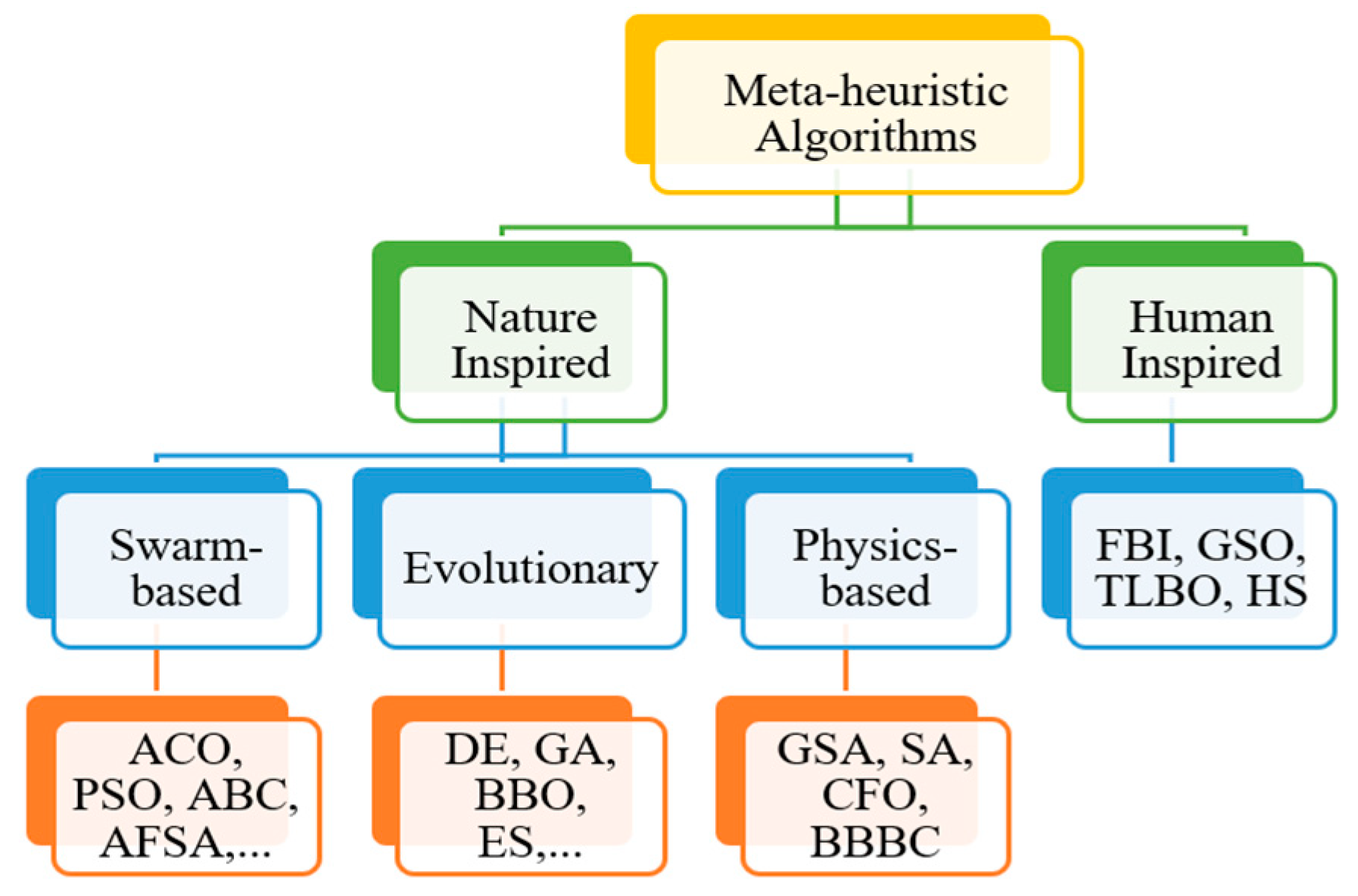
The metaphors applied in metaheuristic techniques are plants, humans, birds, the ecosystem, water, gravitational forces, and electromagnetic forces. As described in
Figure 1, it can be divided into two categories. The first category mimics physical or biological phenomena and three sub-categories come into existence from it. They are swarm-based, physics-based, and evolution-based techniques. Human phenomena are the main inspiration behind the second category.
Abbreviations: ACO: Ant Colony Optimization, PSO: Particle Swarm Optimization, ABC: Artificial Bee Colony, AFSA: Artificial Fish Swarm Algorithm, DE: Differential Evolution, GA: Genetic Algorithm, BBO: Biogeography-Based Optimizer, ES: Evolution Strategy, GSA: Gravitational Search Algorithm, SA: Simulated Annealing, CFO: Central Force Optimization, BBBC: Big-Bang Big-Crunch, FBI: Forensic-Based Investigation, GSO: Group Search Optimizer, TLBO: Teaching-Learning-Based Optimization, HS: Harmony Search.
Metaheuristic techniques were utilized for different real-world applications, Negi et al. [
11] proposed a hybrid approach with PSO and GWO methods and dubbed it HPSOGWO to tackle optimization problems and reliability allocation of life support systems and Complex bridge systems. In [
12], the authors devised a modified genetic algorithm (MGA) with a novel selection method, namely a generation-dependent mutation and an in-vitro-fertilization-based crossover. They applied their technique in commercial ship scheduling and routing with dynamic demand and supply environments. Their model could lessen risks and abate port time with a static load factor. Ganguly in [
13] proposed a framework for simultaneous optimization of Distributed Generation (DG) network performance index and penetration level to acquire the optimal sizes, numbers, and sites of DG units. He formulated two objective functions. Network performance index and DG penetration level were the two. Multi-objective particle swarm optimization was utilized by his solution framework and was validated on a distribution system comprising 38 nodes.
In [
14], the authors implemented a general type-2 fuzzy classification method for the medical assistance and the optimization of the general type-2 membership functions parameters using ALO for comparison these two type classifiers with the Framingham dataset. A general type-2 fuzzy classifier had been applied on the Jetson Nano hardware Development Board and execution time of the type-1 and type-2 fuzzy classification techniques were compared. A novel metaheuristic method called the Slime Mold Algorithm (SMA) was proposed in [
15]. A fuzzy controller tuning technique is also offered and the concept of enhancing the performance of metaheuristics with information feedback approaches has been applied. The fuzzy controllers and their tuning methods were validated in real-time with angular position control of the laboratory servo framework. In [
16], a survey was presented on scientific literature works that dealt with Type-2 fuzzy logic controllers devised utilizing nature-inspired optimization techniques. Their review exploited the most widespread optimizers to attain the key parameters on Type-2 and Type-1 fuzzy controllers to enhance the gained outcome. The PSO method was integrated in [
17], with the Multi-Verse Optimizer (MVO) to classify endometrial carcinoma with gene expression by optimizing the parameters of the Elman neural network.
Swarm intelligence methods were also utilized for feature reduction. Gupta et al. [
18] presented a revised antlion optimization procedure to better identify thyroid infection. To mitigate the computational time and enhance the classification accuracy, the proposed method was exploited as a feature reduction technique to detect the vital attributes from a large set of attributes. Their method had successfully eradicated 71.5% of irrelevant features. Based on Stochastic Fractal Search (SFS), El-Kenawy et al. [
19] introduced a Modified Binary GWO (MbGWO) to determine key characteristics by attaining the exploitation and exploration balance. They tested their MbGWO-SFS method with 19 machine learning datasets from the University of California, Irvine (UCI). Comparison with the state-of-the-art optimization methods demonstrated the superiority of the method. Lin et al. [
20] applied modified cat swarm optimization (CSO) that outperformed PSO. The limitation of CSO is that its computation time is long. Hence, their modified version was called ICSO. Their method selected features in big data-related text classification. To propose a feature selection method, Wan et al. [
21] utilized a customized binary-coded ant colony optimization (MBACO) method in combination together with a genetic algorithm. Their technique comprised of two models, the pheromone density model (PMBACO) and the visibility density model (VMBACO). The results acquired by GA were applied as early pheromone evidence in the PMBACO model, whereas the solution attained by GA was employed as visibility information in the VMBACO model. Based on the modified grasshopper optimization method, Zakeri et al. [
22] devised a new feature selection technique. The novel method dubbed Grasshopper Optimization Algorithm for Feature Selection (GOFS) replicated the duplicate features with promising features by applying statistical techniques while performing iterations.
Instance reduction is a pre-processing task devised to improve learning jobs. Nanni et al. [
23] developed an effective technique based on particle swarm optimization for prototype reduction. Their technique minimized the error rate on the training set. Zhai et al. [
24] introduced a novel immune binary particle swarm optimization technique for time series classification, which searched for the smallest instance combination with the highest classification accuracy. Hamidzadeh et al. [
25] presented a Large Margin Instance Reduction Algorithm (LMIRA) that kept border instances and removed the non-border ones. The algorithm considered the instance reduction issue as a constrained binary optimization problem, and a filled function algorithm was exploited to tackle the issue. The reduction process’s basic was relied on the hyperplane that separated the two-class data and demonstrated large margin separation. Saidi et al. [
26] proposed a novel instance selection method dubbed Ensemble Margin Instance Selection (EMIS). The ensemble margin was employed in their method. They applied their method for automatic recognition and selection of white blood cells WBC in cytological images.
Carbonera and Abel [
27] devised an effective and simple density-based framework for instance collection termed local density-based instance selection (LDIS). Their technique kept the densest instances in an arbitrary neighborhood by examining the instances of each class. For evaluating the accuracy, they applied the K-Nearest Neighbor (KNN) algorithm. de Haro-García et al. [
28] utilized boosting method to obtain reduced instances to achieve better accuracy. The stepwise addition of instances was performed by applying the weighting of instances from the building of ensembles of classifiers.
Numerous modified versions of Antlion optimizers have been proposed for solving different research problems. In [
29], Wang et al. proposed an enhanced alternate method for Antlion Optimizer (ALO), incorporating opposition-based training with two functional operators centered on differential evolution, named MALO, which is suggested to deal with the implicit vulnerabilities of conventional ALO. Pierezan et al. [
30] suggested four multi-objective ALO (MOALO) methods utilizing swarming distance, supremacy idea for choosing the elite, and tournament collection techniques with various programs to pick the chief. Assiri et al. [
31] showed the benefits and different categories like Modified, Hybrid, and Multi-Objective of ALO algorithms after giving a detailed introduction of this procedure. This paper also discussed the applications and foundations of this method and finished with some suggestions and possible directions in the future.
In the literature, different metaheuristic and optimization algorithms were proposed to enhance the performance of classification using the instance reduction issue. However, as far as the authors are aware, this is the first time ALO algorithm or a modified version of it is proposed to solve the instance reduction issue in balanced and imbalanced data. In this paper, MALO will be utilized to enhance the ALO’s ability to escape the local optima while providing a better convergence rate and enhancing the classification performance in real-world datasets by optimized instance reduction.
The main contributions of this work are summarized as follows:
(1) Since the ALO algorithm suffers from local optima stagnation and slow convergence speed for some optimization problems [
32], this study’s intention is to propose a new modified antlion optimization (MALO) algorithm to enhance the optimization efficiency and accuracy of ALO by adding a new parameter depends on the step length of each ant while updating the antlion position based on the parameter, upper and lower bounds of search space.
(2) The proposed MALO algorithm is tested on twenty-three benchmark functions at 500 iterations and thirteen benchmark functions at 1000 iterations. The results provide evidence that the suggested MALO escapes the local optima and provides a better convergence rate as compared to the basic ALO algorithm, some well-known and recent optimization algorithms.
(3) Furthermore, 15 balanced and imbalanced datasets were employed to test the performance of the proposed MALO algorithm on reducing instances of the training data and the results are compared with some well-known optimization algorithms.
(4) The Wilcoxon signed-rank test is also applied. The results showcase that the proposed instance reduction method statistically outperforms the MALO algorithm and other comparable optimization techniques based on the recorded Accuracy, BACC, G-Mean, and AUC metrics while keeping less computational time.
(5) Moreover, antlion optimization and MALO were used to perform training data reduction for 18 oversampled imbalanced datasets, and learning is performed using Support Vector Machines (SVM) classifier in all performed experiments. The results are compared with one novel resampling method and two recent algorithms.
4. Conclusions
An optimization-based method was proposed in this paper for the problem of instance reduction to obtain better results in terms of many metrics in both balanced and imbalanced data. A new modified antlion optimization (MALO) method was adapted for this task after validating its ability in terms of optimization compared to state-of-the-art optimizers using benchmark functions. The results obtained at 500 and 1000 iterations for twenty-three and thirteen benchmark functions, respectively, demonstrated that the proposed MALO algorithm could escape the local optima and provide a better convergence rate as compared to the basic ALO algorithm and state-of-the-art optimizers.
Additionally, instance reduction results from MALO were compared to basic antlion Optimization and some well-known optimization algorithms on 15 balanced and imbalanced datasets to test the performance on reducing instances of the training data. Furthermore, antlion optimization and MALO were used to perform training data reduction for 18 oversampled imbalanced datasets, and the reduced datasets were classified by SVM in all experiments. The results were also compared with one novel resampling method.
Obtained results demonstrated that the proposed MALO was superior in minimizing the number of training set instances, hence maximizing the classification performance while reducing the run time compared to state-of-the-art methods used to reduce the original balanced and imbalanced datasets without the need to perform oversampling pre-processing methods which consume computational time and memory space. MALO reduced the instances of oversampled imbalanced datasets with better performance compared to the full oversampled dataset and the recently proposed ACOR instance reduction method, ALO, GWO, and WOA.
The MALO algorithm results showed an increment in Accuracy, BACC, G-mean, and AUC rates up to 7%, 3%, 15%, and 9%, respectively, for some datasets over the basic ALO algorithm while keeping less computational time.
The need for determining the best values of the parameters of MALO can seem to be a limitation; however, the instance reduction problem in balanced and imbalanced data is a complex problem that can be encountered in many real-world applications and this limitation can be resolved by adjusting the parameters by adopting different statistical concepts.
Owing to the encouraging outcomes and high performance of MALO in the instance reduction challenge, numerous new evolutionary optimization algorithms can be adjusted for improved outcomes for this hot research area. Multi-objective or many-objective versions of the evolutionary optimization methods can also be adapted to obtain a wider range of non-dominating and alternative solutions that can promote more appropriate roles for this important task by instantaneously satisfying the different conflicting and contradictory objectives using only a single optimization routine.
Current or new evolutionary optimization and search methods can also be hybridized for performance increment by employing the two or more combined methods and eliminating the possible disadvantages of the methods. In this way, a good balance between exploration and exploitation can enhance the performance of the proposed MALO, for instance, the reduction problem in balanced and imbalanced data.
Different techniques for decreasing the computational cost can be embedded in the proposed MALO. Adaptive versions of the methods can also be proposed. Different initialization methods can be integrated into MALO in order to obtain better results for instance reduction problems and other complex real-world problems by obtaining a more uniform population. As another future direction of work, the proposed model can be adapted for real big data classification processes.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}