
Cognitively Economical Heuristic for Multiple Sequence Alignment under Uncertainties

 , ,
, ,  , , and
, , and 
Abstract
:1. Introduction
- m is a nonnegative integer (),
- sequence represents recognized objects, i.e.,and the order of elements in is determined by the spatial order of recognized objects in the image reference system,
- sequence contains the corresponding real-valued recognition confidences for objects in .
2. Background and Related Work
- is the cost of deletion of symbol ,
- is the cost of insertion of symbol ,
- is the cost of replacement of symbol by symbol .
- (i)
- The number of clusters is determined prior to the pairwise sequence alignment. Each distinct maximum-length sequence in a set of recognition hypotheses is declared as a cluster representative. All other non-maximum-length sequences were then assigned to the closest cluster representative, where the distance between two sequences was calculated by means of the adapted edit distance algorithm.
- (ii)
- The proposed adaptation of the edit distance approach is inspired by human working memory limitations (cf. [26]). To reduce the “cognitive load” of our approach, we consider only “economical” sequence alignments that are optimal in terms of the standard minimum edit distance approach and in which no space is inserted into longer sequence. These two requirements for cognitive economy allow for the substantial reduction of the number of sequences derived in the alignment process by means of padding (as detailed in Section 3).
3. Heuristic for Multiple Sequence Alignment
- The gap-minimum alignment algorithm, introduced and illustrated in Section 3.1, is intended for alignment of two recognition hypotheses.
- The cluster-based voting algorithm, introduced and illustrated in Section 3.2, builds upon the first algorithm and is intended for multiple recognition hypothesis alignment, based on which a single recognition result is derived.
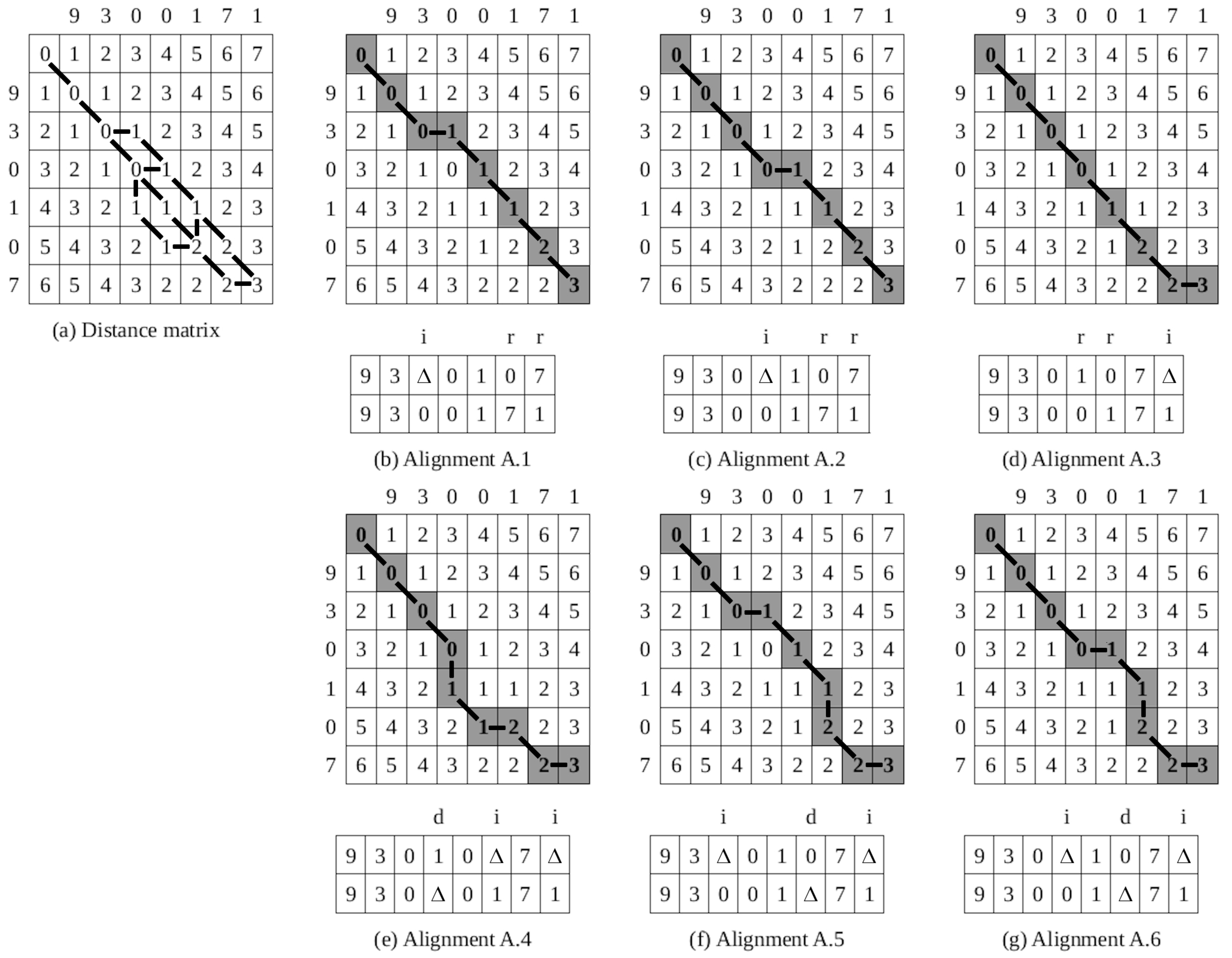
3.1. Gap-Minimum Two Sequence Alignment
3.2. Cluster-Based Multiple Sequence Alignment
4. Evaluation and Discussion
4.1. Extrinsic Evaluation
- Hardware and software: the subjects used Android-based mobile phones of the same type and with the same software settings.
- Subjects: the subjects were of the same gender (male), and comparable in height and expertise in recording electric meters with an Android-based mobile phone. They did not have any insight into the post-processing results.
- Electricity meters: both subjects recorded the same set of 100 electricity meters, including 5 m with one rate, and 95 m with two rates.
- Ambient: to achieve the same ambient conditions, each electricity meter was recorded first by one subject and then immediately after by another.
- Recording span: when reading an electricity meter, the digit recognition system was set to record until ten image frames were recorded or the recording time reached three seconds.
- A total of 86 of 384 recognition hypothesis sets do not contain correct recognition hypotheses (39 sets in Corpus 1 and 47 sets in Corpus 2). However, the hypotheses from seven of these sets were correctly aligned; i.e., the correct recognition results were derived (in 1 of 39 sets in Corpus 1 and 6 of 47 sets in Corpus 2). One of these sets and the derivation of the recognition result are presented above in Example 3.
- A total of 114 of 384 sets contain at least one correct recognition hypothesis, but the number of correct hypotheses in each of these sets is less than or equal to the half of the number of hypotheses in a given set (59 sets in Corpus 1 and 55 sets in Corpus 2). The correct recognition results were derived for 72 of these sets (40 of 59 sets in Corpus 1 and 32 of 55 sets in Corpus 2).
- A total 184 of 384 sets contain correct recognition hypotheses, and the number of correct hypotheses in each of these sets is greater than the half of the number of hypotheses in a given set (96 sets in Corpus 1 and 88 sets in Corpus 2). The correct recognition results were derived for all these sets except one (from Corpus 2).

{kind=link}
{kind=link}
{kind=link}
| # Correct Recognition | Corpus 1 | Corpus 2 | Total | |||
|---|---|---|---|---|---|---|
| Hypotheses in a Set | # Sets | # Correctly Aligned | # Sets | # Correctly Aligned | # Sets | # Correctly Aligned |
| 0 | 39 | 1 | 47 | 6 | 86 | 7 |
| ≤half of the set, ≠0 | 59 | 40 | 55 | 32 | 114 | 72 |
| >half of the set | 96 | 96 | 88 | 87 | 184 | 183 |
| Total | 194 | 137 | 190 | 125 | 384 | 262 |
4.2. Comparison to Human Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gnjatović, M.; Maček, N.; Adamović, S. Putting Humans Back in the Loop: A Study in Human-Machine Cooperative Learning. Acta Polytech. Hung. 2020, 17, 191–210. [Google Scholar] [CrossRef]
- Singh, P.; Diwakar, M.; Gupta, R.; Kumar, S.; Chakraborty, A.; Bajal, E.; Jindal, M.; Shetty, D.K.; Sharma, J.; Dayal, H.; et al. A Method Noise-Based Convolutional Neural Network Technique for CT Image Denoising. Electronics 2022, 11, 3535. [Google Scholar] [CrossRef]
- Momeny, M.; Latif, A.M.; Agha Sarram, M.; Sheikhpour, R.; Zhang, Y.D. A noise robust convolutional neural network for image classification. Results Eng. 2021, 10, 100225. [Google Scholar] [CrossRef]
- De Man, R.; Gang, G.J.; Li, X.; Wang, G. Comparison of deep learning and human observer performance for detection and characterization of simulated lesions. J. Med. Imaging 2019, 6, 025503. [Google Scholar] [CrossRef] [PubMed]
- Montalt-Tordera, J.; Muthurangu, V.; Hauptmann, A.; Steeden, J.A. Machine learning in Magnetic Resonance Imaging: Image reconstruction. Phys. Med. Eur. J. Med. Phys. 2021, 83, 79–87. [Google Scholar] [CrossRef] [PubMed]
- Gnjatović, M.; Maček, N.; Adamović, S. A Non-Connectionist Two-Stage Approach to Digit Recognition in the Presence of Noise. In Proceedings of the 10th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Naples, Italy, 23–25 October 2019; pp. 15–20. [Google Scholar] [CrossRef]
- Finton, D.J. Cognitive-Economy Assumptions for Learning. In Encyclopedia of the Sciences of Learning; Seel, N., Ed.; Springer: Boston, MA, USA, 2012; pp. 626–628. [Google Scholar] [CrossRef]
- Hui, W.; Yu, L. The uncertainty and explainability in object recognition. J. Exp. Theor. Artif. Intell. 2021, 33, 807–826. [Google Scholar] [CrossRef]
- Heydari, M.; Mylonas, A.; Tafreshi, V.H.F.; Benkhelifa, E.; Singh, S. Known unknowns: Indeterminacy in authentication in IoT. Future Gener. Comput. Syst. 2020, 111, 278–287. [Google Scholar] [CrossRef]
- Wang, L.; Jiang, T. On the complexity of multiple sequence alignment. J. Comput. Biol. 1944, 1, 337–348. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Speech Recognition, and Computational Linguistics, 2nd ed.; Prentice-Hall: Hoboken, NJ, USA, 2009. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals, Cybernetics and Control Theory. Cybern. Control. Theory 1966, 10, 707–710. [Google Scholar]
- Wagner, R.A.; Fischer, M.J. The String-to-String Correction Problem. J. Assoc. Comput. Mach. 1974, 21, 168–173. [Google Scholar] [CrossRef]
- Chao, J.; Tang, F.; Xu, L. Developments in Algorithms for Sequence Alignment: A Review. Biomolecules 2022, 12, 546. [Google Scholar] [CrossRef]
- Alkuhlani, A.; Gad, W.; Roushdy, M.; Voskoglou, M.G.; Salem, A.b.M. PTG-PLM: Predicting Post-Translational Glycosylation and Glycation Sites Using Protein Language Models and Deep Learning. Axioms 2022, 11, 469. [Google Scholar] [CrossRef]
- Daugelaite, J.; O’ Driscoll, A.; Sleator, R.D. An Overview of Multiple Sequence Alignments and Cloud Computing in Bioinformatics. ISRN Biomath. 2013, 2013, 615630. [Google Scholar] [CrossRef] [Green Version]
- Kholidy, H.A. Detecting impersonation attacks in cloud computing environments using a centric user profiling approach. Future Gener. Comput. Syst. 2021, 117, 299–320. [Google Scholar] [CrossRef]
- Campbell, J.; Lewis, J.P.; Seol, Y. Sequence alignment with the Hilbert-Schmidt independence criterion. In Proceedings of the 15th ACM SIGGRAPH European Conference on Visual Media Production, London, UK, 13–14 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Chasanis, V.T.; Likas, A.C.; Galatsanos, N.P. Scene Detection in Videos Using Shot Clustering and Sequence Alignment. IEEE Trans. Multimed. 2009, 11, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Dogan, P.; Li, B.; Sigal, L.; Gross, M. A Neural Multi-Sequence Alignment TeCHnique (NeuMATCH). In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8749–8758. [Google Scholar] [CrossRef] [Green Version]
- Schimke, S.; Vielhauer, C.; Dittmann, J. Using adapted Levenshtein distance for on-line signature authentication. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004; Volume 2, pp. 931–934. [Google Scholar] [CrossRef] [Green Version]
- Just, W. Computational complexity of multiple sequence alignment with SP-score. J. Comput. Biol. 2001, 8, 615–623. [Google Scholar] [CrossRef]
- Herman, J.L.; Novák, A.; Lyngsø, R.; Szabó, A.; Miklós, I.; Hein, J. Efficient representation of uncertainty in multiple sequence alignments using directed acyclic graphs. BMC Bioinform. 2015, 16, 108. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Chamberlain, R.D.; Agrawal, K.; Tian, C.; Hu, Z. Analysis of classic algorithms on highly-threaded many-core architectures. Future Gener. Comput. Syst. 2018, 82, 528–543. [Google Scholar] [CrossRef]
- Feng, D.F.; Doolittle, R.F. Progressive sequence alignment as a prerequisite to correct phylogenetic trees. J. Mol. Evol. 1987, 25, 351–360. [Google Scholar] [CrossRef]
- Miller, G. The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information. Psychol. Rev. 1956, 63, 81–97. [Google Scholar] [CrossRef] [Green Version]
- Peli, E. Contrast in complex images. J. Opt. Soc. Am. A 1990, 7, 2032–2040. [Google Scholar] [CrossRef] [PubMed]



| Frame Recognition Hypotheses |
|---|
| Step 2.1 | Step 2.2 | Step 2.3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hypotheses | Cluster | Hypotheses | Cluster | Arraying | |||||||
| 477 | ? | 4 | △ | △ | 7 | △ | 7 | ||||
| 4677 | ? | 4 | 6 | 7 | 7 | △ | △ | ||||
| 4677 | ? | 4 | 6 | 7 | 7 | △ | △ | ||||
| 4677 | ? | 4 | 6 | 7 | 7 | △ | △ | ||||
| 467787 | 467787 | 4 | 6 | 7 | 7 | 8 | 7 | ||||
| 4677 | ? | 4 | 6 | 7 | 7 | △ | △ | ||||
| 4677 | ? | 4 | 6 | 7 | 7 | △ | △ | ||||
| 487787 | 487787 | 4 | 8 | 7 | 7 | 8 | 7 | ||||
| 477 | ? | 4 | △ | △ | 7 | △ | 7 | ||||
| ↓ | ↓ | ↓ | ↓ | ↓ | ↓ | ||||||
| Voting: | 4 | 6 | 7 | 7 | △ | 7 | |||||
| Final result: | 46777 | ||||||||||
| System | Image Frames | Corpus 1 | Corpus 2 | Total |
|---|---|---|---|---|
| External number | # image frames | 2011 | 1873 | 3884 |
| recognition system [1] | average root mean square contrast | |||
| # correctly recognized image frames | ||||
| Proposed post-processing | # hypothesis sets | 194 | 190 | 384 |
| subsystem | average # hypotheses per set | |||
| average# correct hypotheses per set | ||||
| # correctly aligned recognition result |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ND | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 92 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 3 | 99 |
| 1 | 0 | 90 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 93 |
| 2 | 0 | 0 | 94 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 6 | 101 |
| 3 | 0 | 2 | 0 | 115 | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 121 |
| 4 | 0 | 1 | 0 | 0 | 101 | 0 | 0 | 0 | 0 | 0 | 3 | 105 |
| 5 | 0 | 1 | 0 | 1 | 0 | 74 | 1 | 0 | 0 | 0 | 1 | 78 |
| 6 | 4 | 0 | 0 | 1 | 0 | 1 | 80 | 0 | 2 | 0 | 6 | 94 |
| 7 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 86 | 4 | 0 | 4 | 95 |
| 8 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 89 | 0 | 4 | 95 |
| 9 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 85 | 2 | 88 |
| INS | 0 | 5 | 0 | 1 | 1 | 0 | 1 | 1 | 5 | 0 | – | 14 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ND | Total | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 88 | 2 | 0 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 4 | 98 |
| 1 | 0 | 92 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 93 |
| 2 | 0 | 0 | 89 | 0 | 4 | 0 | 0 | 4 | 0 | 0 | 2 | 99 |
| 3 | 0 | 0 | 0 | 103 | 0 | 0 | 0 | 0 | 0 | 1 | 6 | 110 |
| 4 | 0 | 0 | 0 | 0 | 99 | 0 | 0 | 1 | 0 | 0 | 5 | 105 |
| 5 | 1 | 0 | 0 | 4 | 0 | 70 | 0 | 0 | 0 | 0 | 1 | 76 |
| 6 | 6 | 0 | 0 | 1 | 0 | 3 | 78 | 0 | 1 | 0 | 4 | 93 |
| 7 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 88 | 1 | 0 | 1 | 92 |
| 8 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 93 | 0 | 3 | 97 |
| 9 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 80 | 2 | 86 |
| INS | 0 | 12 | 1 | 5 | 1 | 0 | 2 | 2 | 10 | 9 | – | 42 |
| # Sets | # Correctly Derived Results | Total Overlap | |||
|---|---|---|---|---|---|
| Heuristic | Human | Overlap | |||
| C1 | |||||
| C2 | |||||
| Total | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gnjatović, M.; Maček, N.; Saračević, M.; Adamović, S.; Joksimović, D.; Karabašević, D. Cognitively Economical Heuristic for Multiple Sequence Alignment under Uncertainties. Axioms 2023, 12, 3. https://doi.org/10.3390/axioms12010003
Gnjatović M, Maček N, Saračević M, Adamović S, Joksimović D, Karabašević D. Cognitively Economical Heuristic for Multiple Sequence Alignment under Uncertainties. Axioms. 2023; 12(1):3. https://doi.org/10.3390/axioms12010003
Chicago/Turabian StyleGnjatović, Milan, Nemanja Maček, Muzafer Saračević, Saša Adamović, Dušan Joksimović, and Darjan Karabašević. 2023. "Cognitively Economical Heuristic for Multiple Sequence Alignment under Uncertainties" Axioms 12, no. 1: 3. https://doi.org/10.3390/axioms12010003
APA StyleGnjatović, M., Maček, N., Saračević, M., Adamović, S., Joksimović, D., & Karabašević, D. (2023). Cognitively Economical Heuristic for Multiple Sequence Alignment under Uncertainties. Axioms, 12(1), 3. https://doi.org/10.3390/axioms12010003