1. Introduction
Utilizing differential equations, Burr [
1] introduced twelve distributions. In the literature, Burr type XII distributions and single-parameter Burr type X, have drawn much interest. Surles and Padgett [
2] have proposed the two-parameter Burr X distribution (BXD), often known as the generalized Rayleigh distribution. For data modelling, the BXD can be used as an alternative to the Weibull and Rayleigh distributions. However, the model has a considerable impact on the prediction of failure rates and has generated a lot of interest in modelling across a wide range of disciplines, including hydrology, medicine and reliability analysis. The cumulative distribution function (CDF) of the BXD is given by:
where,
b > 0, and
a > 0 are the shape and scale parameters, respectively. The probability density function (PDF) associated with (1) is given by:
According to Raqab and Kundu [
3], the shape parameter (
b) determines whether the hazard rate function (HF) of the BXD is a bathtub or an increasing function. The HF is bathtub for
and is an increasing function for
In the literature, numerous studies have been undertaken in recent years to create modified or generalized forms of the BXD in order to increase the viability of BXDs, see, for example, [
4,
5,
6,
7,
8,
9]. Our focus is on the recently established power BXD (PBXD) by Usman and Ilyas [
10], with an additional shape parameter that depends on the transformation
The CDF and PDF of the PBXD are, respectively, given by:
For
the CDF (3) reduces to BXD. Usman and Ilyas [
10] mentioned that, subject to certain restrictions, their model can handle both symmetrical and heavy-tailed skewed data sets.
A significant challenge in data modelling is the selection of an adequate lifetime probability. However, over time, a variety of probability models have been widely proposed for the analysis of data sets in a variety of fields, including the medical sciences, actuarial sciences, engineering, finance and insurance, demography, biological sciences, and economics. In many practical scenarios, we are required to deal with the uncertainty of bounded situations. We commonly encounter variables that fall within the range of (0, 1), such as the percentage of a particular trademark, the results of some capacity tests, different lists, and rates. In order to model these variables effectively, continuous unit distributions, or probability distributions with support for (0, 1), are crucial. Due to this, some authors have recently concentrated on the creation of distributions that are specified on the bounded interval using any one of the parent distribution modification strategies. Among distributions that are specified in the (0, 1) interval, the beta distribution is obviously the most well-known. The beta distribution is helpful for simulating data on the unit interval, but different distributions have also been proposed and researched over time. The Topp–Leone distribution (see [
11]) and the Kumaraswamy distribution (see [
12]) can all be used as examples by the reader. The idea of offering distributions defined by the unit interval corresponding to any continuous distribution, however, has recently attracted the interest of statisticians. The following are a few of the most practical unit–interval distributions: the log–Lindley (Gómez-Déniz et al. [
13]), unit–Birnbaum–Saunders (Mazucheli et al. [
14]), unit–inverse Gaussian (Ghitany et al. [
15]), unit–Lindley (Mazucheli et al. [
16]), unit–BurrIII (Modi and Gill [
17]), unit–Weibull (Mazucheli et al. [
18]), unit–Burr XII (Korkmaz and Chesneau [
19]), unit–odd Fréchet power function (Haq et al. [
20]), unit–Teissier (Krishna et al. [
21]), unit–exponentiated exponential (Jha et al. [
22]) and unit–exponentiated half-logistic (Hassan et al. [
23]) among others.
In this study, we propose a new unit probability distribution, based on the PBXD, that has three parameters. A new unit-PBXD (UPBXD) is provided based on the transformation where Y represents the PBXD. The UPBXD has the following desirable characteristics:
- ▪
The UPBXD is a flexible model and can be used to describe a variety of datasets with a range between zero and one.
- ▪
The new density function of the UBBXD takes several shapes, including unimodal, reversed J-shaped, U-shaped, left-skewed, and symmetric (see
Section 2).
- ▪
The HF shapes of the UPBXD can be increasing, J-shaped, or bathtub (U-HF) (see
Section 2).
- ▪
We derive some of the most important statistical characteristics of the UPBXD, such as the analytical expression for moments, the quantile function, incomplete moments, stochastic ordering, some uncertainty measures, and stress–strength reliability.
- ▪
The parameter estimators of the UPBXD are explored using a Bayesian technique. The Bayesian credible intervals are also created.
- ▪
To examine the effectiveness of estimators based on accuracy criteria, an exclusive simulation study was conducted.
- ▪
Application to COVID-19 datasets from Saudi Arabia and the United Kingdom are used to show the superiority of the proposed model over other well-known models.
An outline of the paper’s structure is provided.
Section 2 provides a definition of the suggested distribution. The distributional characteristics of the UPBXD are covered in
Section 3. The maximum likelihood (ML) and Bayesian estimators utilizing various loss functions are covered in
Section 4. The effectiveness of the suggested point and interval estimators is assessed using a Monte Carlo simulation in
Section 5.
Section 6 shows that the UPBXD outperforms the other unit distributions when employed with COVID-19 data. The paper conclusion is completed in
Section 7.
2. Unit Power Burr X Distribution
In this section, we present the UPBXD, which results from the transformation of the type
where
Y is the PBXD and is a new bounded distribution with support on (0, 1). Thus, the following is how the CDF of the PBXD can be obtained:
which gives
Based on (5), we have
for
w ≤ 0, and
for
w ≤ 1. The PDF of the UPBXD related to (5) can be acquired as follows:
A random variable with PDF (6) is represented by UPBXD
For
b = 1, the PDF (6) gives UBXD as a new sub-model. The following is the HF of the UPBXD:
The related plots for various selections of the parameters
and
are shown in
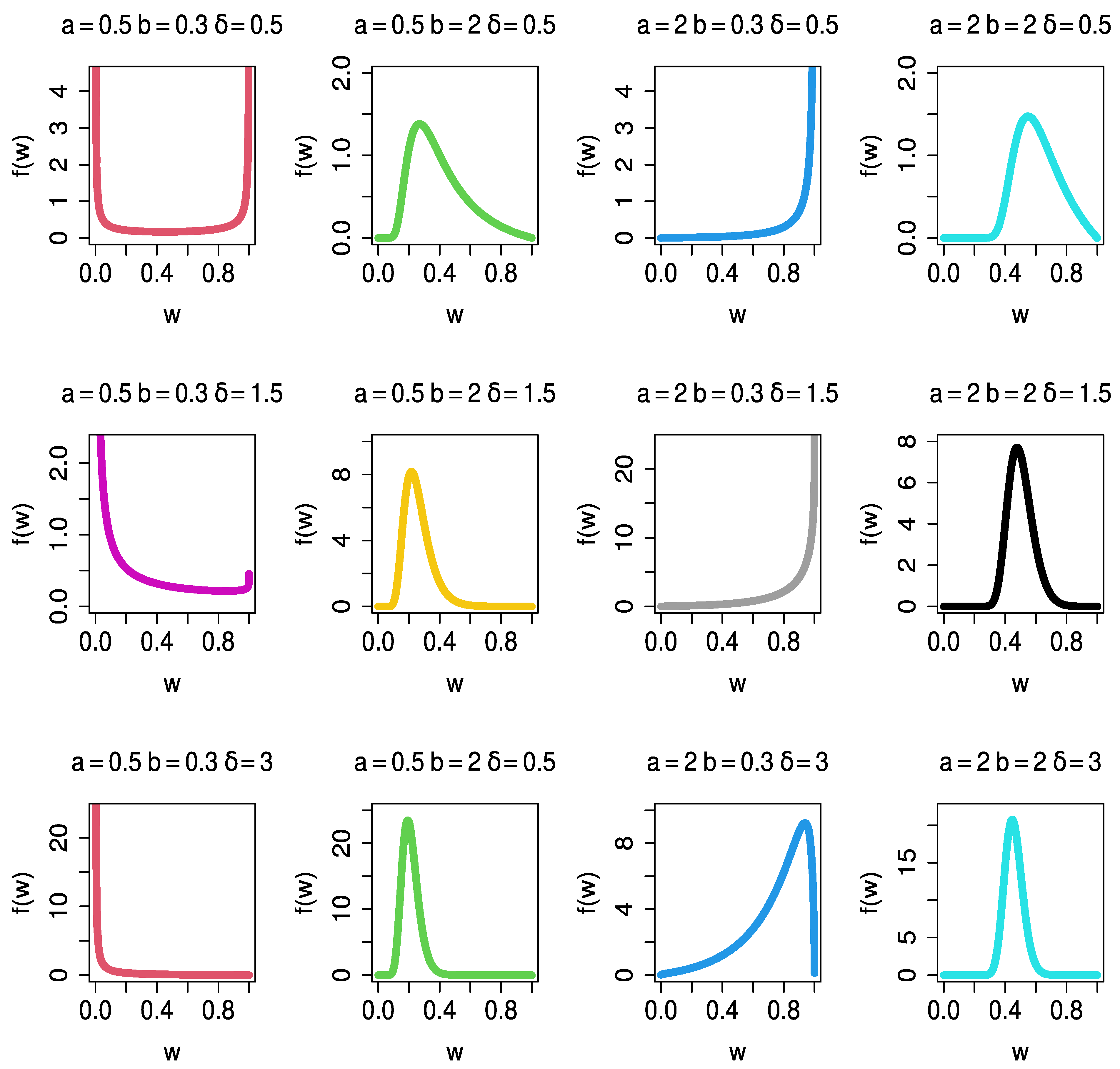
Figure 1 and
Figure 2 to provide a general overview of the shapes of the PDF (2) and HF (7).
In
Figure 1, the PDF graphs for various parameter combinations display a variety of shapes, such as (
a = 2,
b = 2) symmetric normal, (
a = 0.5,
b = 0.3) U-shaped, (
a = 0.5,
b = 2) right-skewed, (
a = 2,
b = 0.3) J-shaped, and (
a = 2,
b = 2) normal tapered. In
Figure 2, the UPBXD’s HF shapes in (
a = 0.5,
b = 2), (
a = 2,
b = 0.3), and (
a = 2,
b = 2) have increasing and J shapes, while (
a = 0.5,
b = 0.3) has a bathtub shape.
The parameter is responsible for the bathtub shapes given that the other two parameters (a and b) are less than one. The parameter is responsible for the J shapes where a > 1 and b < 1.
By inverting (5), we can get the quantile function (QF) of the UPBXD, which looks like this:
where
q is the uniform random variables. The first, median, and third quantiles are produced by setting
q = 0.25, 0.5, and 0.75 in (8). It is simple to simulate the random variable of the UPBXD from (8).
3. The UPBXD’s Properties
In this section, we examine aspects of the UPBXD’s structural characteristics, such as some moment’s measures, information measures, stochastic ordering (SO), and stress–strength (SS) reliability.
3.1. Some Moments Measures
The
mth moment for
W~UPBXD
is determined as follows:
Using the binomial expansion in (9) provides
Let
then the
mth moment of
W, is given by
Use the exponential expansion then
, obtains the following form:
where,
is a gamma function. Furthermore, the
mth central moment of
W, is defined by
Some moments measures including, first four moments, variance (
), coefficient of skewness (
) and coefficient of kurtosis (
) for the UPBXD are calculated for specific parameter values.
Table 1 provides these measures considering parameter values as: (i)
(ii)
(iii)
(iv)
(v)
(vi)
and (vii)
Table 1 displays that the UPBXD is right- and left- skewed in accordance with the values of
Additionally, the distribution is leptokurtic and platykurtic according to the values of
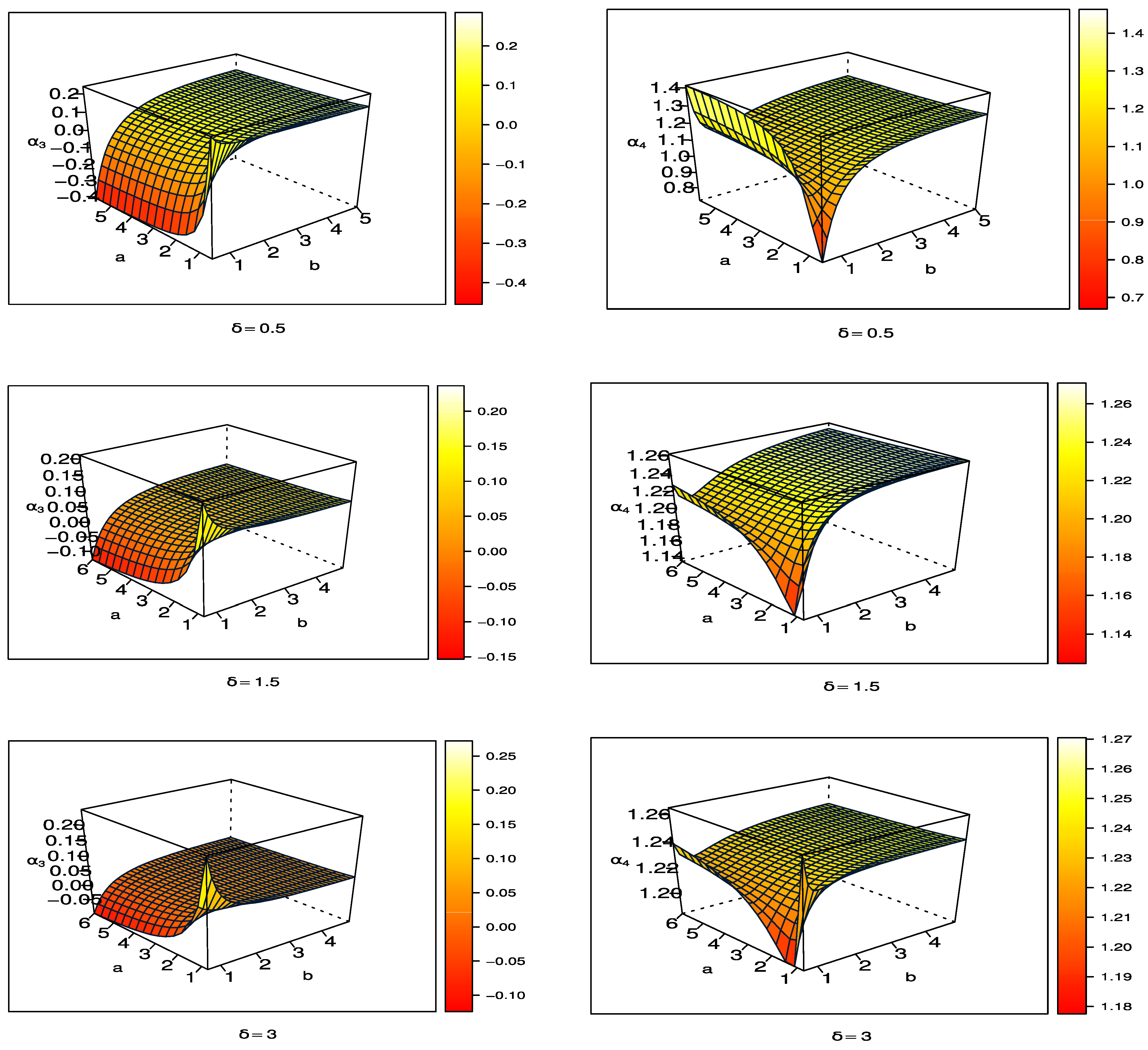
Figure 3 shows the 3-dimensional plots for coefficient of skewness and kurtosis for UPBXD with different values of parameters. Looking at
Figure 3, we can see that the coefficient of skewness and kurtosis increases when
b and
increases, while
a increases then the coefficient of skewness decreases and coefficient of kurtosis increases.
Furthermore, the
mth lower incomplete moment, say
of the UPBXD is given by:
Let
and using the binomial expansion, then the
mth incomplete moment of
W is
Using exponential expansion and after simplification, the
mth moment is as below:
where
is an upper incomplete gamma function. The Lorenz and Bonferroni curves are well-known applications of the first incomplete moment. In the fields of economics, demographics, insurance, engineering, and medicine, these curves are especially helpful.
3.2. Information Measures
In this sub-section, we examine the entropies of Rényi, Havrda and Charvat, as well as
d-generalized entropy as information metrics. These measures collectively provide information about the system’s overall amounts of data. The Rényi entropy presented by Rényi [
24], is conceptually the quantity of information contained in a random process, it is defined by:
Inserting (6) in (10), and using binomial expansion, then
is as follows:
Let
and using exponential expansion in (11), we obtain
where
Reference [
25] proposed another uncertainty measure, the Havrda and Charvat. Here we assume
and this is represented mathematically by:
Using the same procedure above, we obtain
as follows:
In reference [
26], a further generalized Shannon entropy form known as
d-generalized entropy was developed. It is represented mathematically as below:
Using a similar way as above, we obtain the
d-generalized entropy as follows,
where
We use the following sets of parameters to provide entropy numerical values for the measurements under consideration: (i)
(ii)
(iii)
(iv)
(v)
(vi)
and (vii)
Table 2 provides some numerical values for the provided three entropy measures.
3.3. Stochastic Ordering
The statistical literature places a great emphasis on the ordering of distributions, especially among lifetime distributions. A significant part of the ranking of various lifetime distributions is found in Johnson et al. [
27]. Here, we take into account four distinct SO for two independent UPBX random variables with a restricted parameter space: the usual, the hazard rate, the mean residual life, and the likelihood ratio order. Recall that a family has the monotone likelihood ratio property if it has a likelihood ratio ordering. This suggests that, when the other parameters are known, there exists a test that is consistently the strongest for any one-sided hypothesis. According to Shaked and Shanthikumar [
28], when two independent random variables, W
1 and W
2, have CDFs that are
and
, respectively, W
1 is said to be smaller than W
2 in the
- ▪
Stochastic order (W1 ≤st (W2)) if ≥ ∀w
- ▪
Hazard rate order (W1 ≤hr (W2)) if ≥ ∀w
- ▪
Mean residual life order (W1 ≤mrl (W2)) if ≥ ∀w
- ▪
Likelihood ratio order (W1 ≤lr (W2)) if decreases in w.
Assume that Wi, i = 1, 2 have the UPBXD with parameters Further, assume that and indicate, respectively, Wi’s CDF and PDF.
If is a decreasing function ∀ w, then, in terms of likelihood ratio order; W1 is said to be stochastically less than W2 (W1 ≤ lrW2)
Let W
1~UPBXD
and W
2~UPBXD
then the likelihood ratio ordering is as follows:
For we get for all hence is decreasing in w and hence W1 ≤lr W2. Moreover, W1 is said to be smaller than W2 in other orderings such as SO (W1 ≤ stW2), HF(W1 ≤ hrW2), and mean residual order (W1 ≤ mrlW2).
3.4. Stress–Stress Reliability
In statistical literature, the term “SS reliability” is used to characterize the reliability of a system subjected to random stress
W2 and having random strength
W1, with the system failing if
W2 is greater than
W1, that is;
R =
P(
W2 <
W1). Let us assume that
W1∼UPBXD
and
W2∼UPBXD
are two independent random variables. The SS reliability of the UPBXD is then calculated as follows:
Using the binomial expansions in (13), we get
As seen in (14) the SS reliability dependent on the parameters and
4. Parameter Estimation
The estimation methodologies for the parameters of the UPBXD are obtained in this part using Bayesian and non-Bayesian estimation approaches. We provide classical method for the UPBXD as ML and Bayesian estimation utilizing various loss functions, including the squared error loss function (SELF), the linear exponential (LINEX) loss function and entropy loss function (ELF).
4.1. Maximum Likelihood Method
Consider a population that has a UPBXD described by PDF (6) with an unknown parameter vector
and that a random sample of size
n is taken from that population. Following that, the likelihood of UPBXD for
say
will be
The log likelihood function for
say
will be
The nonlinear equations created by differentiating (16) with respect to
and
are solved to obtain the ML estimator for the unknown parameters. The score vector components, say
are given by
The ML estimator of , say , is achieved by solving the nonlinear system (17)–(19). These equations cannot be resolved analytically, but they can be resolved numerically by iterative statistical software techniques. We can use iterative methods, such as a Newton–Raphson algorithm, to obtain these estimates.
4.2. Bayesian Estimation
In this section, the Bayesian estimators based on different loss functions and associated highest posterior density (HPD) intervals of the UPBXD parameters are developed. The posterior distribution of
is described in the following if we assume that the prior PDF of
is unknown.
The posterior density of is defined in Equation (20) as , where on the right hand side is the likelihood function of UPBXD and is the prior density of
4.2.1. Prior Information
For the purpose of discussing Bayesian estimate, we assume that the parameters
and
are independently distributed using the gamma distribution. Let
and
where
j =1, 2, 3, be the scale and shape parameters for the gamma priors of
and
The following is a proportionate representation of the joint density of
and
The hyper-parameters will be elicited using the informative priors. When
j = 1, …,
L and
k are the number of samples available from the UPBXD simulation, the mean and variance obtained using the ML estimates of the UPBXD
and
will be equal to the mean and variance of the considered priors (Gamma priors)
and
By equating
and
with the mean and variance of gamma priors, we may determine their respective means and variances. Thus, we obtain
In regard to be solving the above two equations, the estimated hyper-parameters can be written as described in the following subsections.
4.2.2. Posterior Distribution
Here, the symmetric loss function (SELF), and asymmetric loss function (LINEX and ELF) are used to develop the Bayesian estimators for the same unknown parameters by utilizing independent gamma priors.
The likelihood function (15) and the joint prior function (21) are combined to form the joint posterior distribution. Hence, the joint posterior density function is
The SELF, is defined as follows:
The Bayesian estimator of
under SELF is as follows:
The LINEX, as asymmetric loss function, which is denoted by
, is the derived as follows:
The Bayesian estimator of
under LINEX loss function is as follows:
The ELF was first suggested by James and Stein [
29] to estimate the Variance–Covariance (i.e., dispersion) matrix of the multivariate normal distribution. According to Calabria and Pulcini [
30], the ELF is an excellent asymmetric loss function. The form’s ELF is thought of as
The Bayesian estimator of
under ELF is as follows:
The Bayes estimator of and via different loss functions cannot be expressed in an explicit statement, as is evident from Equations (23)–(25). To do this, we suggest generating samples from conditional posterior distribution using Bayes Monte Carlo Markov chain (MCMC) techniques in order to compute the acquired Bayes estimates and create associated HPD intervals.
4.2.3. Markov Chain Monte Carlo
Since it is challenging to solve these integrals analytically, the MCMC method will be used. The most important sub-classes of MCMC algorithms are Gibbs sampling and the Metropolis–Hastings (MH) samplers. To do this, it regards a candidate value produced from a proposal distribution as normal for each iteration of the process, the MH method is comparable to acceptance–rejection sampling. From Equation (22), the full conditional density of
and
are provided, respectively, to execute the MCMC sampler as follows:
and
It is thought that the MH algorithm can resolve this issue (for detail, see Alrumayh et al. [
31] and Almetwally et al. [
32]). The MH algorithm’s sampling procedure is carried out as follows:
Step 1: Set the initial values and Step 2: Set I = 1.
Step 3: Generate and from and respectively.
Step 4: Obtain
Step 5: Generate samples Uj j =1,2,3 from the uniform U(0, 1) distribution.
Step 6: If and then set ; otherwise and
Step 7: Set I = I+ 1.
Step 8: Repeat steps 3–7 B times and obtain and for I = 1, 2,..., B.
4.2.4. Highest Posterior Density Interval
Using the technique suggested by Chen and Shao [
33],
HPD interval estimates of
and
are created. The MCMC samples of
for
j = 1, …, B are first ordered. Therefore, the two-sided
HPD interval of
is given by
where
and
5. Simulation
A Monte Carlo simulation was run to evaluate the performance of the proposed point and interval estimators that were introduced in the previous sections. Based on various selections for sample size n as 40, 80, and 160, UPBXD was used to create a total of 5000 samples. To compare the results of Bayesian estimate based on various loss functions, the bias and mean squared errors (MSE) were calculated. The UPBXD was used to generate the data for the lifetime of various parameters and as follows.
In
Table 3:
and
and 3. In
Table 4:
and
and 3. In
Table 5:
and
and 3. In
Table 6:
and
and 3.
The hybrid MCMC algorithm described in
Section 4.2.3 was adopted to generate 12,000 MCMC samples, and we discarded the first 2000 values as ‘burn-in’. Accordingly, the 10,000 MCMC samples were used to produce the average Bayes MCMC estimates and 95% two-sided Bayesian credible intervals.
Algorithm for simulation: By establishing all simulation controls, we can build our model. The following actions must be finished in this stage in the correct order:
Assume different values for the UPBXD parameter vector and sample size.
Make the sample random values for the UPBXD using uniform and the QF in Equation (7).
We calculated the accuracy measures for each Bayes estimates of the UPBXD parameters using MH algorithm.
This experiment should be run (L-1) times.
5.1. Simulation Results
Table 3,
Table 4,
Table 5 and
Table 6 show the results of the suggested techniques for calculating the point and interval parameter estimates. They offer the findings as well as some intriguing data. The following observations are permissible:
The estimates are asymptotically unbiased since they are more accurate as the sample size increases.
The parameter estimates come from the best unbiased estimator when the MSE value is near zero.
As the sample size grows, the MSE declines for each estimate, demonstrating consistency between the various estimates.
When the true value of increases, the bias, MSE, and length of the credible confidence interval (LCCI) of all estimates decrease.
The MSE and LCCI for the Bayesian estimates with positive weight for the asymmetric loss function are smaller than the Bayesian estimates with negative weight for asymmetric loss function.
The LCCI for estimates obtains its largest value, based on the suggested method, as the true values of the parameters increase.
An entropy loss function with positive weight is better than the other loss functions.
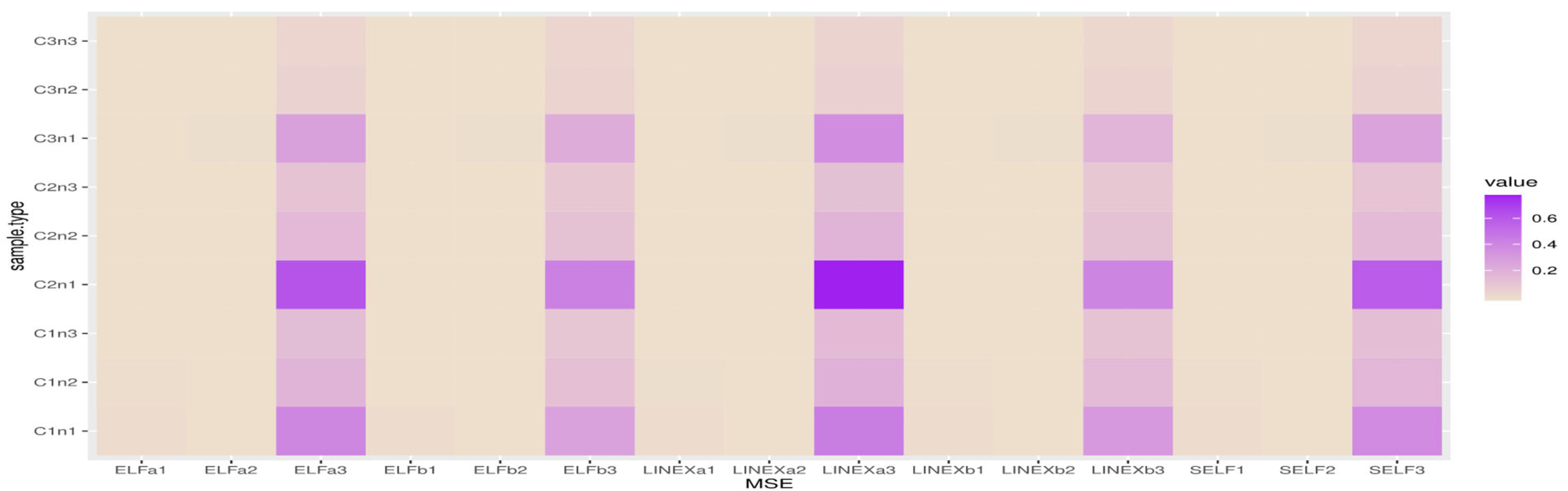
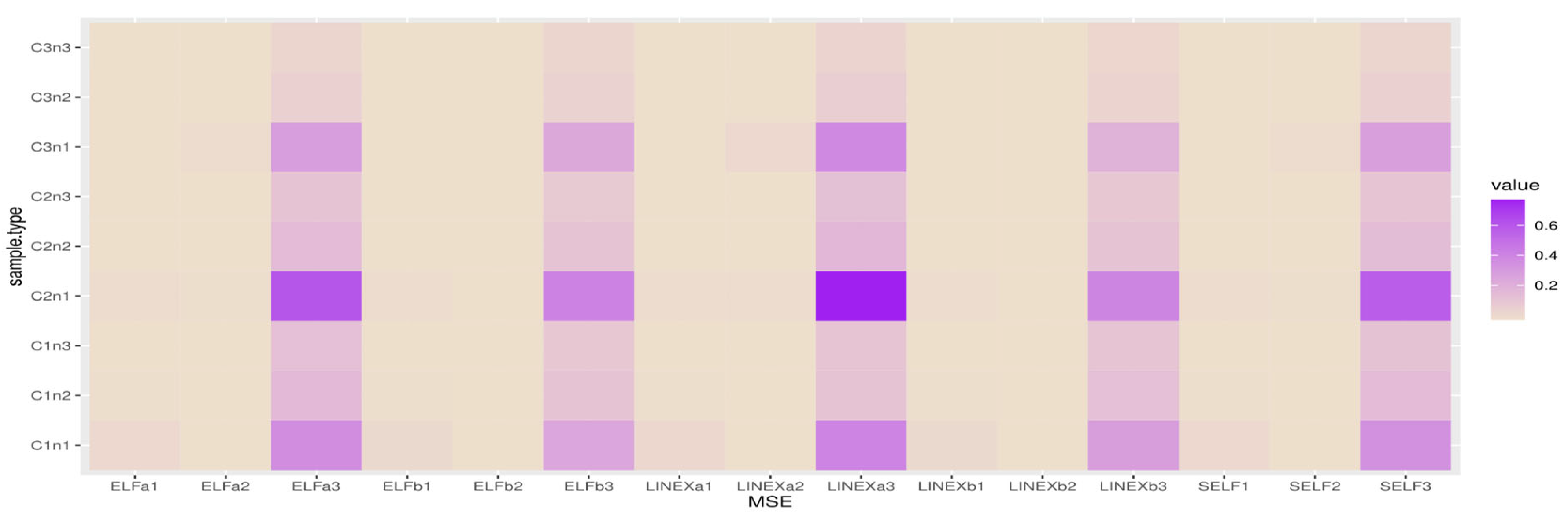
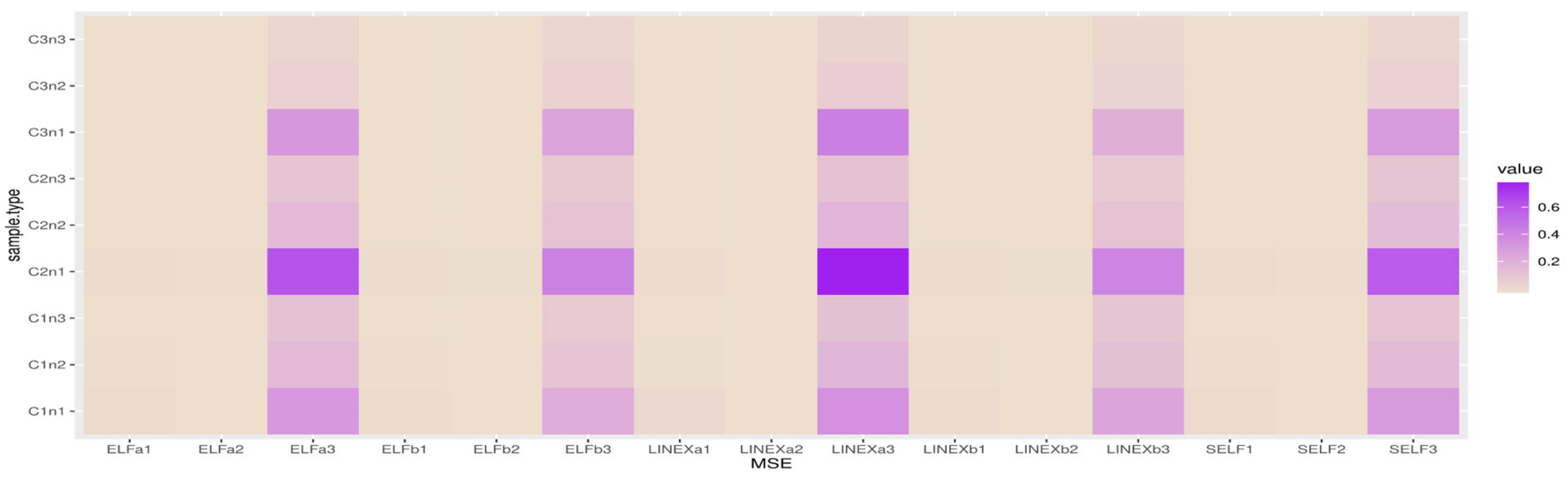
5.2. Represention Results
Figure 4,
Figure 5,
Figure 6 and
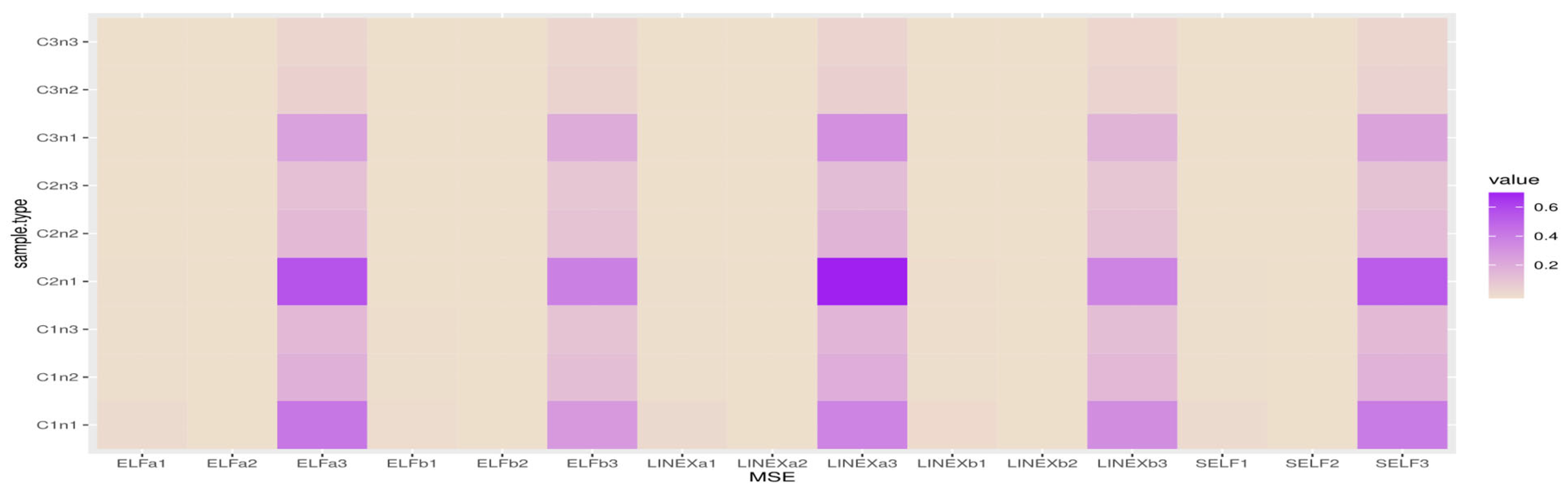
Figure 7 show heatmap descriptions for the MSE results, where the bold color represents the highest values of MSE and the white color represents the lowest values of MSE.
The X-label belongs to SELFj, (j = 1, 2, 3) which are the MSE of Bayes estimates based on SELF with different parameters;
LINEXaj, (j =1, 2, 3) are the MSE of Bayes estimates based on LINEX with different parameters;
LINEXbj, (j =1, 2, 3) are the MSE of Bayes estimates based on LINEX with different parameters;
ELFaj, (j =1, 2, 3) are the MSE of Bayes estimates based on ELF with different parameters;
ELFbj, (j =1, 2, 3) are the MSE of Bayes estimates based on ELF with different parameters.
The Y-label belongs to cases and sample sizes, where C1n1 for and n = 40; C1n2 for and n = 80; C1n3 for and n = 80.
6. Application of Real Data
This section analyses two real-world datasets to show the adaptability and practical application of the UPBXD. The UPBXD is compared with the following models: unit-exponentiated half-logistic (UEHL) [
23], Type II power Topp–Leone exponential (TIIPTLE) [
34], Topp–Leone generalized exponential (TLGE) [
35], Kumaraswamy (K), Beta, unit Weibull (UW), and Marshall–Olkin–Kumaraswamy (MOK). Two actual COVID-19 mortality rate datasets from Saudi Arabia and the United Kingdom are provided in this section to evaluate the UPBXD goodness of fit. The two real datasets were utilized to estimate the unknown parameters of the specified models using the maximum likelihood and Bayesian approaches. Kolmogorov–Smirnov statistics (KSS) with
p-value, Cramer–von Mises statistics (WS), and Anderson–Darling statistics (AS) were used to compare all of the models.
6.1. Analysis for First Data
Data set I: The first set of data shows Saudi Arabia’s COVID-19 mortality rates over a 36-day period (22 July 2021 to 26 August 2021). The information is as follows: 0.1310, 0.1319, 0.1497, 0.1504, 0.1686, 0.1689, 0.1706, 0.1716, 0.1879, 0.1890, 0.1924, 0.1951, 0.2063, 0.2077, 0.2091, 0.2113, 0.2126, 0.2140, 0.2167, 0.2249, 0.2259, 0.2271, 0.2278, 0.2314, 0.2329, 0.2347, 0.2353, 0.2375, 0.2452, 0.2487, 0.2666, 0.2674, 0.2683, 0.2711, 0.2752, 0.2962.
Table 7 shows the ML estimate of parameters with their standard errors (SEs) for each distribution and obtained the goodness of fit measures as KSS, WS, and AD. By the results shown in
Table 7, we are able to see that the UPBXD is better than the other distributions, such as TLPTLE, TLGE, K, Beta, UW, UEHL, and MOK, for COVID-19 mortality rates in the Saudi Arabia data set.
As can be seen, the TLPTLE, TLGE, K, Beta, UW, UEHL, and MOK distributions work well for modelling the COVID-19 mortality rates indicated in the Saudi Arabia data set, but that the UPBXD is the best. This is based on a significance level of 0.05.
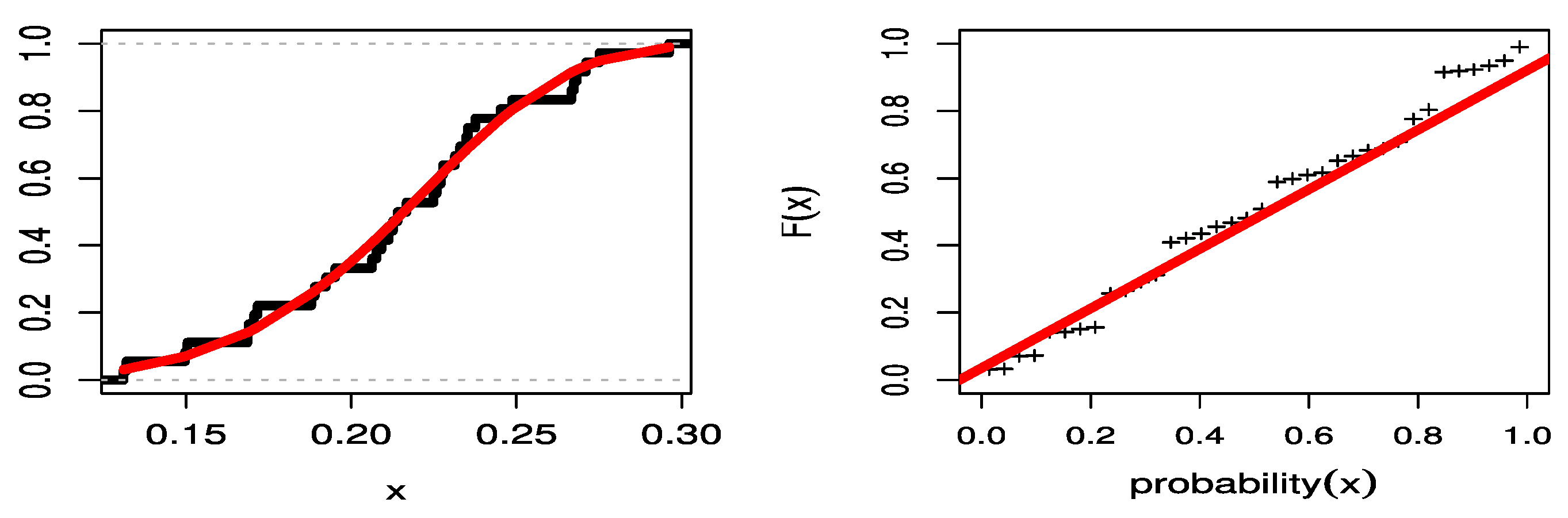
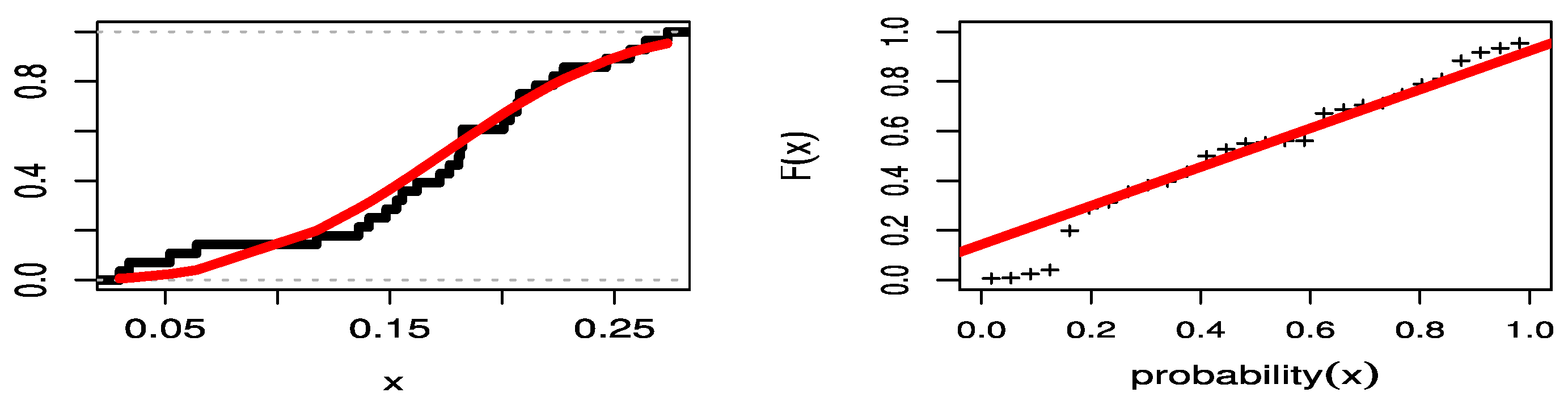
Figure 8 illustrates the estimated CDF in the red line with empirical CDF in the black line. It also shows the probability–probability (PP) plots of the UPBXD in the red line, also known as “parametric plots”, for the COVID-19 mortality rates of the Saudi Arabia data set, which demonstrate the empirical findings, reported in
Table 7 and the empirical CDF line the (black) with the estimated CDF line (red).
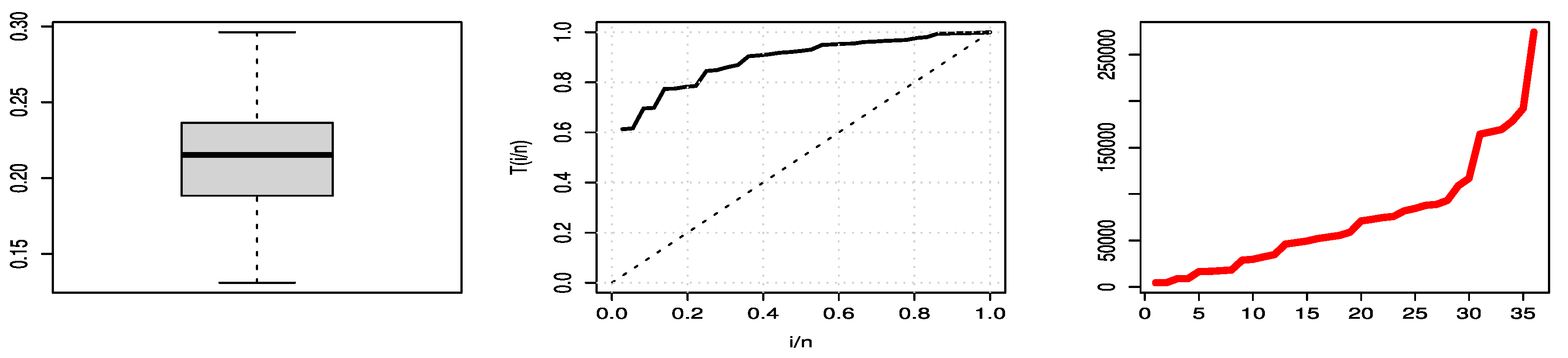
Figure 9 shows three plots of COVID-19 mortality rates for the Saudi Arabia data set, where the left is a boxplot of data that explains that the data have no outlier values, the center is a TTT plot of data that explains this data set is increasing, and the right is a hazard estimated plot line that indicates the HF is increasing.
6.2. Analysis for Second Data
Data set II: The second set of data shows the United Kingdom COVID-19 mortality rates over a 28-day period (1 January 2022 to 28 January 2022). The information is as follows: 0.1484, 0.1174, 0.0522, 0.0296, 0.0339, 0.2274, 0.1555, 0.1530, 0.2079, 0.0640, 0.1407, 0.2463, 0.2569, 0.2150, 0.1723, 0.1823, 0.1807, 0.1823, 0.2736, 0.2228, 0.2036, 0.1767, 0.1814, 0.1361, 0.1620, 0.2639, 0.2067, 0.2008.
Table 8 shows the ML estimate of parameters for each distribution and obtained the goodness of fit measures as KSS, WS, and AD. By the results of
Table 8, we can see that the UPBXD is better than the other distributions, such as TLPTLE, TLGE, K, Beta, UW, UEHL, and MOK, for COVID-19 mortality rates in the United Kingdom data set. Additionally, we can see that the TLPTLE, TLGE, K, Beta, UW, UEHL, and MOK distributions work well for modelling the COVID-19 mortality rates of the United Kingdom data set, though the UPBXD is the best. This is based on a significance level of 0.05.
Figure 10 illustrates the PP plots for the COVID-19 mortality rates of the United Kingdom data set, which demonstrate the empirical findings reported in
Table 8 and the empirical CDF line (black) with the estimated CDF line (red).
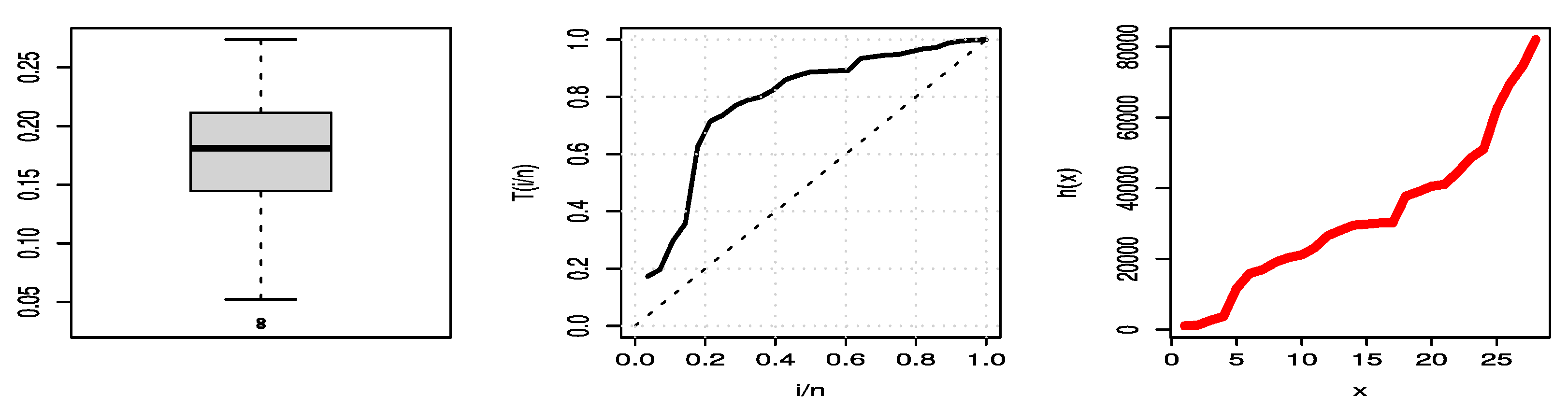
Figure 11 shows three plots of COVID-19 mortality rates for the United Kingdom data set, where the left is a boxplot of data that explains that these data have no outlier values, the center is a TTT plot of data that explains that these data are increasing, and the right is a hazard estimated plot line that indicates the hazard is increasing.
6.3. Data Analysis via Bayesian Method
Here, we analyze data sets presented in previous sub-sections using the proposed Bayesian estimation method.
The Bayesian estimation parameters of UPBXD for each of the data sets, respectively are given in
Table 9. The Bayesian estimates of UPBXD parameters under SELF and the corresponding SEs are calculated. The lower and upper HPD intervals are also calculated.
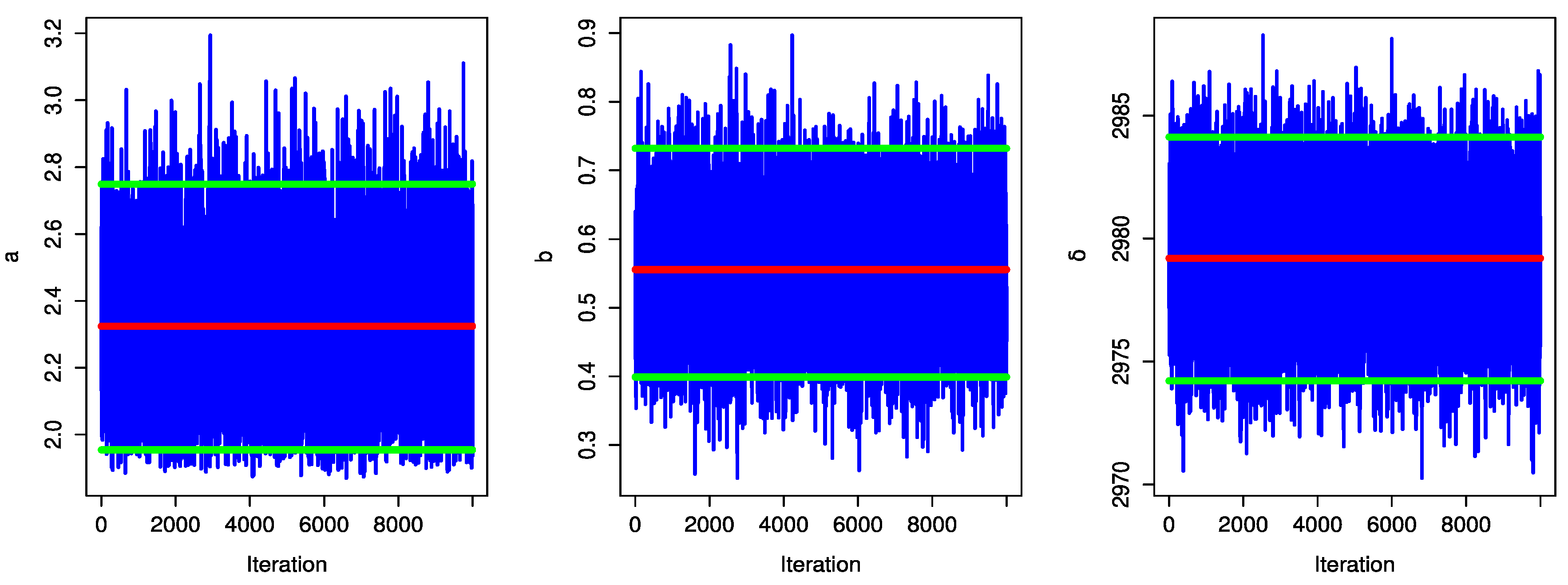
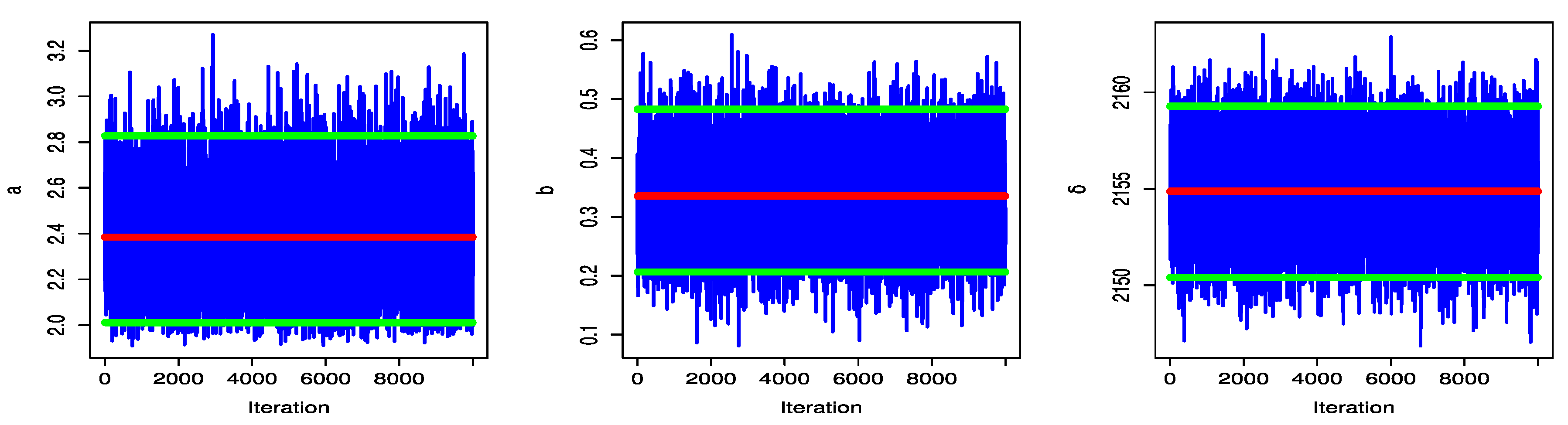
Figure 12 and
Figure 13 display the trace plot of the UPBXD’s parameter values for the MCMC finding.
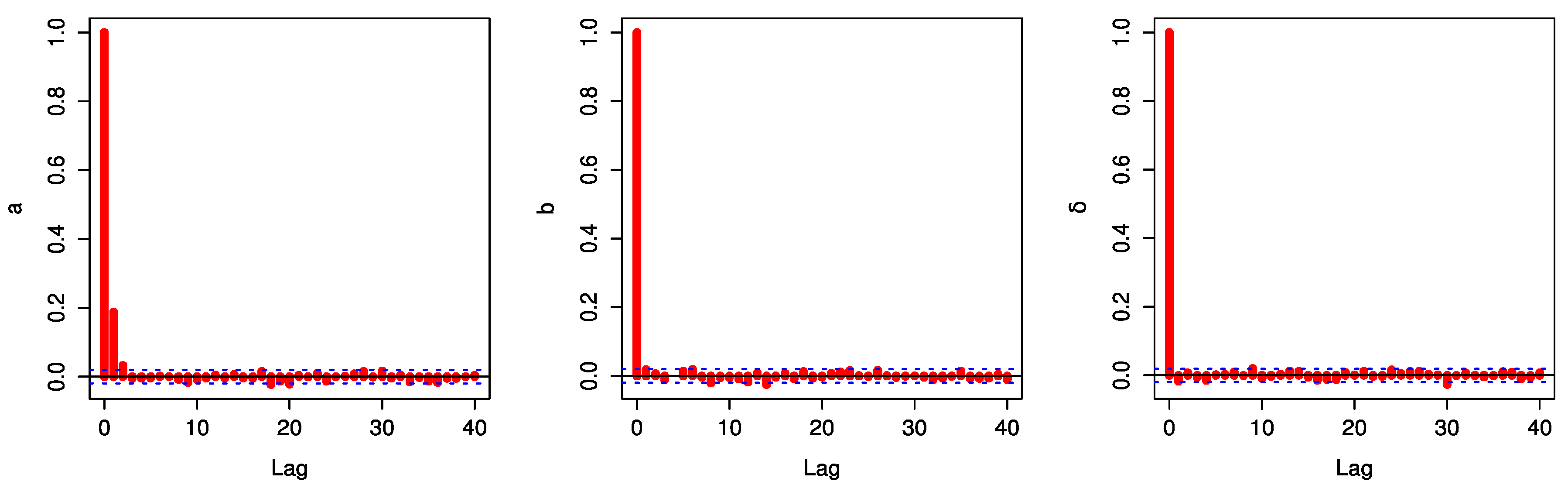
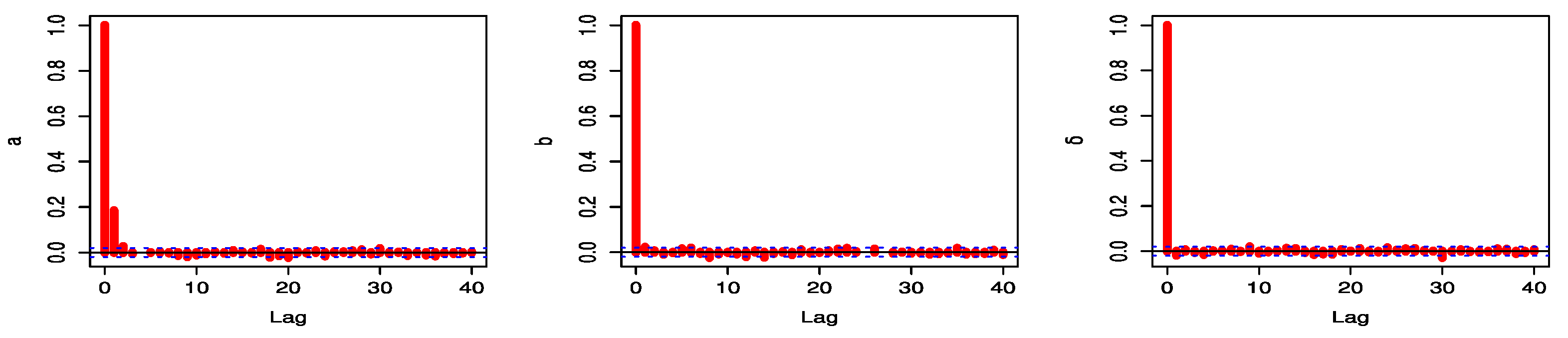
The autocorrelation function (ACF) is generated as shown in
Figure 14 and
Figure 15.
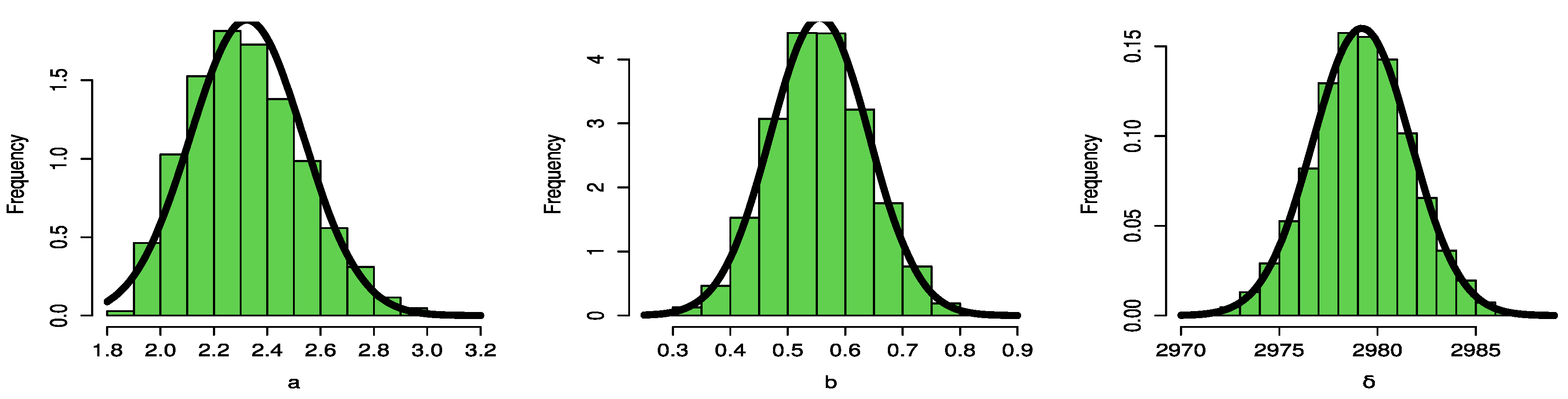
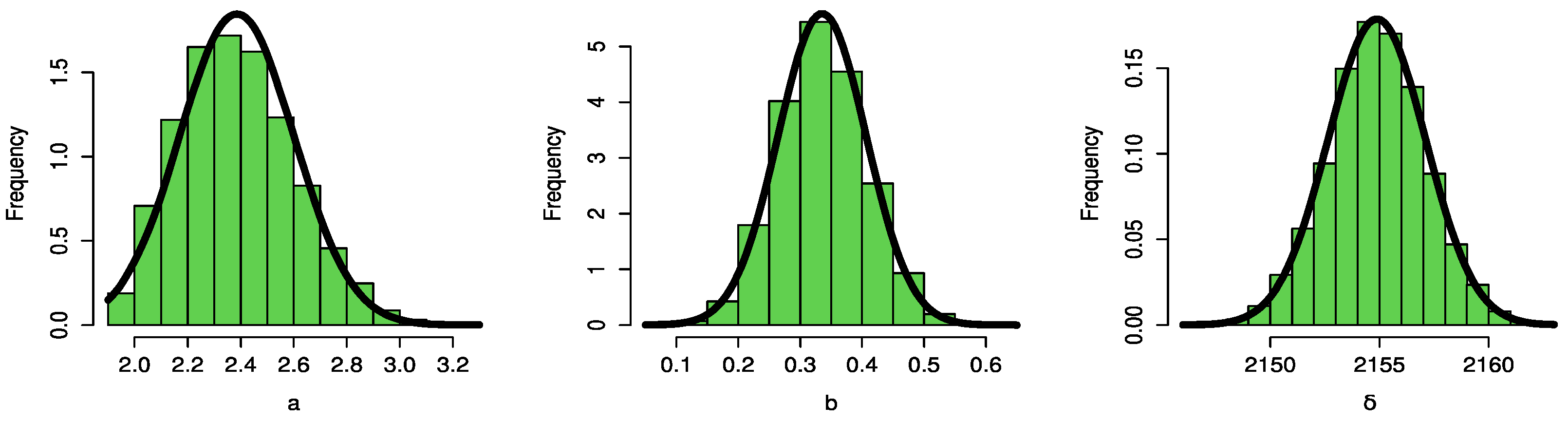
Figure 16 and
Figure 17 demonstrate the symmetric normal distribution of the posterior density for the parameters of the UPBXD.
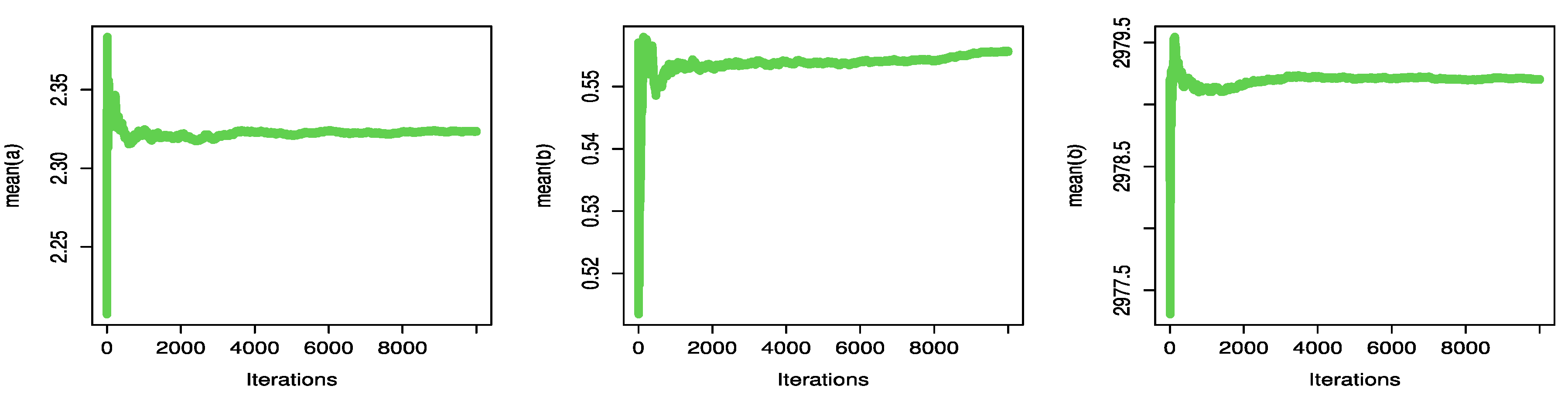
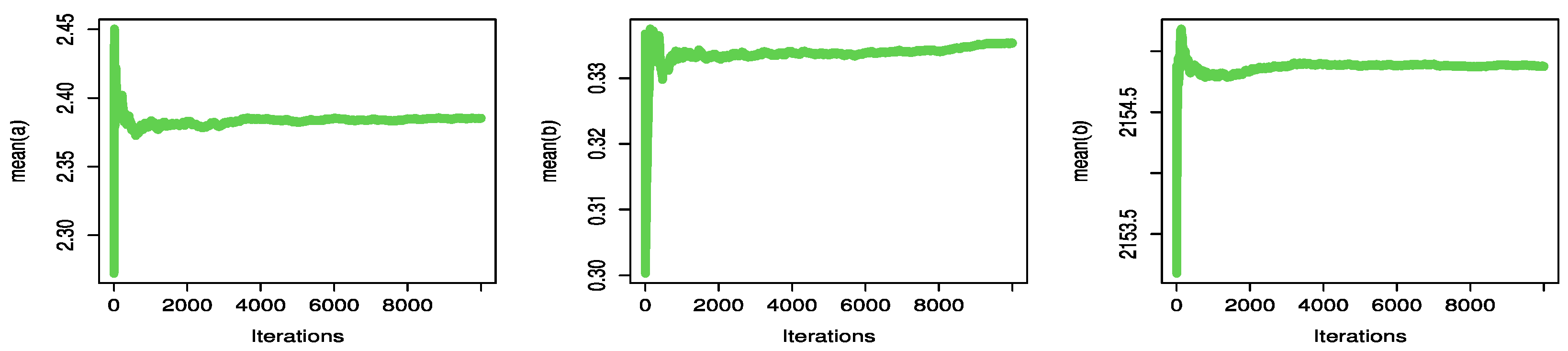
Figure 18 and
Figure 19 display the parameter convergence charts for UPBXD draws as well as the parameter random draw plot, respectively.
























{kind=link}
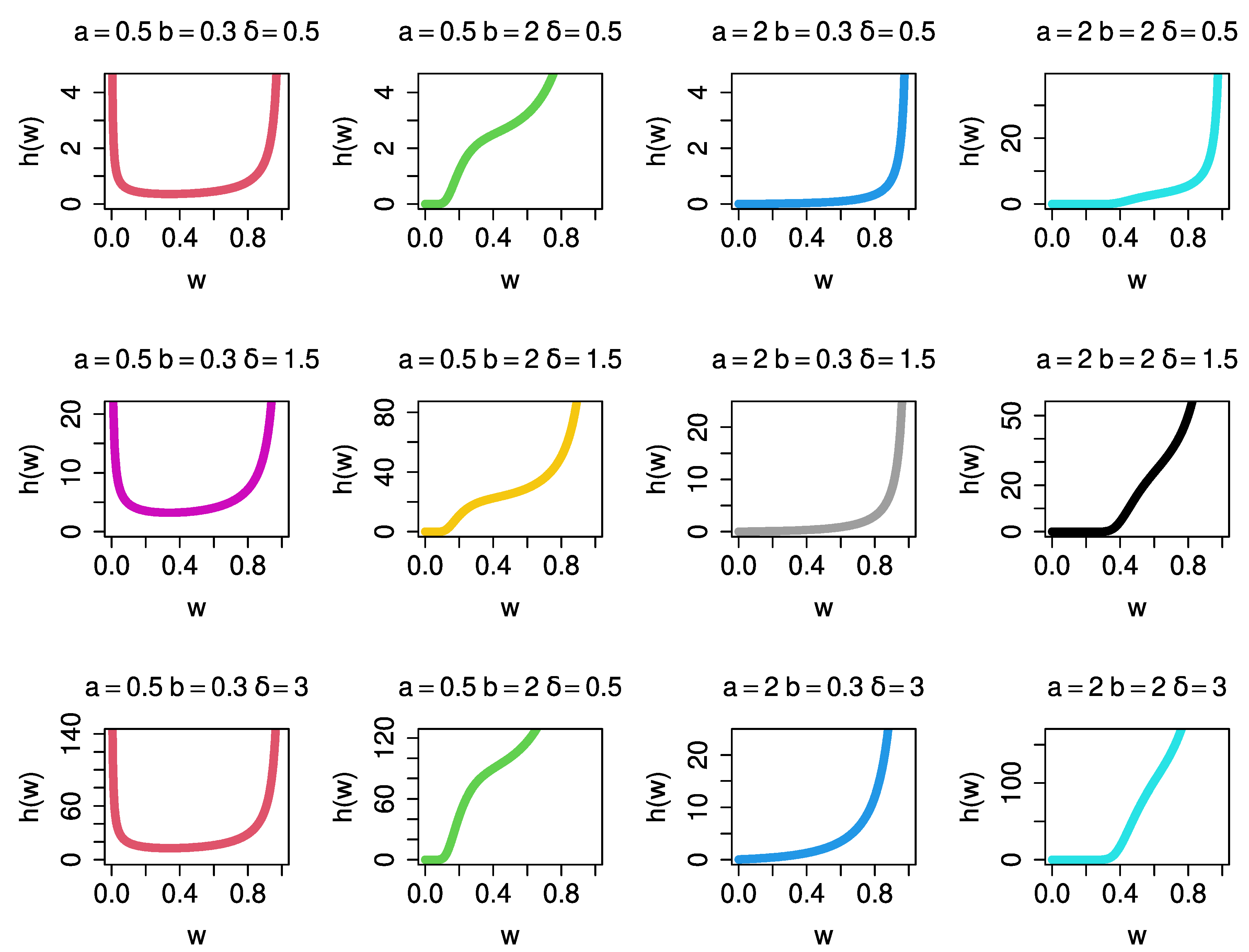{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}