

Join Operation for Semantic Data Enrichment of Asynchronous Time Series Data




Abstract
:1. Introduction
Motivation and Context: Barcelona Smart City Research Project
- The first contribution is the enhancement of data quality for asynchronous time series data, which is crucial for ensuring that accurate and reliable insights can be drawn from the information.
- Secondly, the article showcases the ability to integrate and unify data that originates from various, heterogeneous sources, thus facilitating a more comprehensive understanding of the smart city ecosystem.
- Another key aspect of this work is the increased availability of data, which can be used to support a wide range of smart city applications and initiatives aimed at improving urban living conditions. By making data more accessible, the article contributes to the advancement of smart city technologies and the development of innovative solutions to address the challenges faced by urban communities.
- Lastly, the article generates a methodology for handling all sorts of smart city data, making it possible for different actors and stakeholders involved in smart city applications to effectively utilize and benefit from the insights provided. This methodology ensures that the semantic data model can be applied to a broad range of scenarios and contexts, thereby increasing its overall value and impact.
2. Related Work
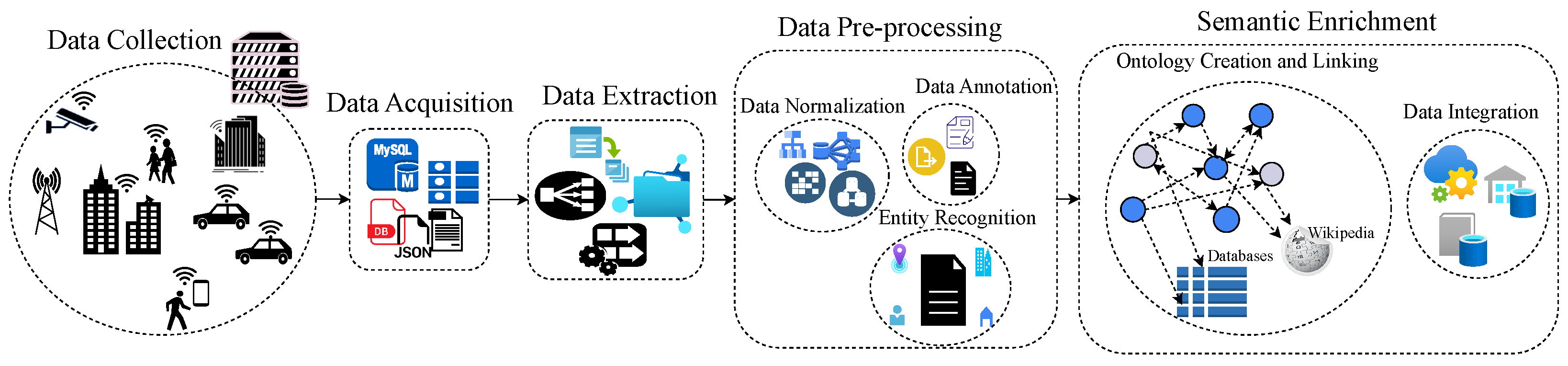
3. Data Semantic Enrichment Model and Implementation
3.1. Model
3.1.1. Input
3.1.2. Output
3.1.3. Semantic Data Model
- STEP 1.
- Compute the geographic distances between each location associated with and each location in :where is the geographical distance between s and .
- STEP 2.
- Find the measurement that minimizes the sum of the geographic distance and the absolute time difference with :In other words, we find the measurement m in that has the minimum sum of geographic distance with and the absolute time difference with the closest measurement in to t. The closest measurement in to t is obtained by computing the minimum time difference between all pairs of measurements in .
- STEP 3.
- If additional data is available for , associate it with the corresponding initial set value in :
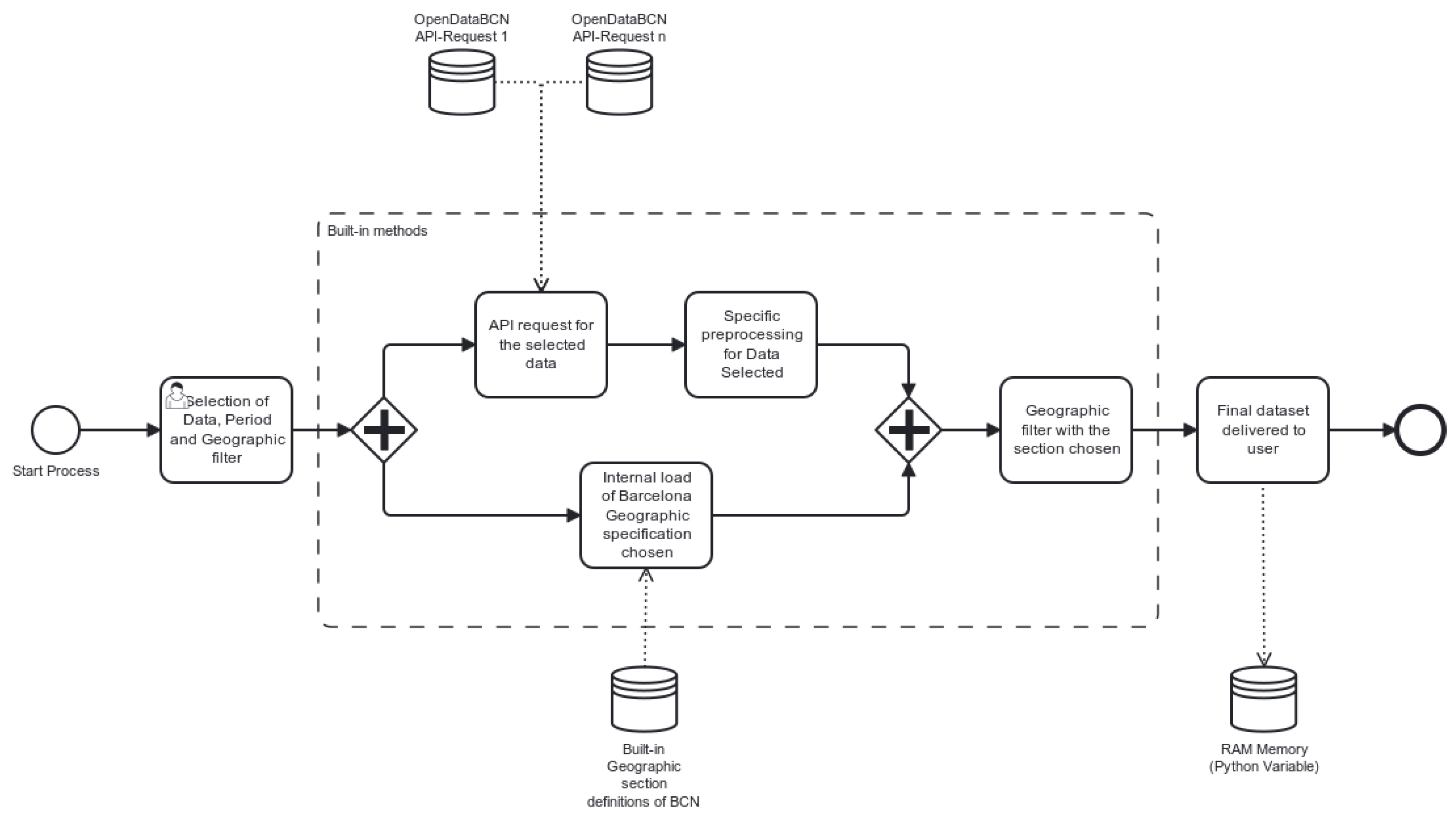
3.2. Implementation
| Algorithm 1: The methodology for associating initial geographical values in time with asynchronous measurements and additional data |
 |
- Initializing geographical coordinates for each initial section has a computational cost of .
- The computation of the distance between each location associated with and each location in , following the definition of the step where we have two sets of locations, requires iterating over them. This step has a time complexity of .
- Finding the measurement that minimizes the sum of geographic distances and absolute time differences involves finding minimum values across data points. This step in the worst-case complexity is .
- If additional data is available for a measurement, we need to associate it with its corresponding initial dataset value. This step incurs an extra cost if there exist additional data; otherwise, it adds no extra computational expense. The association process requires constant time which can be achieved using hash tables or similar structures.
- n: represents the input size.
- : denotes number of sections in city C.
- : denotes number of locations within timestamp set.
- : denotes evaluation of all possible pairs from measurements at given timestamps t.

- Efficient data manipulation: Pandas provides efficient data structures like DataFrame and Series, making it easy to manipulate large datasets.
- Time-series support: Pandas offers built-in functionality for handling time-series data, which is useful for analyzing temporal patterns in data.
- Data cleaning and exploration: Pandas provides tools for handling missing data, filtering, and transforming data, which are essential for preparing datasets for analysis.
- Visualization: Pandas integrates with popular visualization libraries, allowing for easy creation of plots and charts to explore data patterns.
- Geospatial data handling: Geopandas extends pandas by adding support for geospatial data types, which is crucial when working with spatial information like coordinates and geometries.
- Spatial analysis: Geopandas offers spatial operations and functions that enable the analysis of spatial relationships, distances, and intersections between geospatial objects.
- Geospatial visualization: Geopandas integrates with visualization libraries to create maps and other spatial visualizations, which help in understanding spatial patterns and distributions.
3.2.1. Inputs
- initial_dataset: A pandas DataFrame containing the initial dataset to join. It should be structured accordingly with the following description of parameters:
- –
- Column Coordinates: Column with GeoPandas geometry objects.
- –
- Column Timestamp: Column with datetime objects representing timestamps.
- extra_dataset: A GeoDataFrame containing the extra dataset to join. It should be structured accordingly with the following description of parameters:
- –
- Column Coordinates: Column with GeoPandas geometry objects representing spaces with real coordinates
- –
- Column Timestamp: Column with datetime objects representing timestamps.
- –
- Columns for measurements: One or more columns with structured values that are associated with the two previous columns.
- measure: A string representing the measure to extract from the GeoDataFrameextra_dataset. It should match the name of the column being extracted.
- extra_values: A Boolean, indicating whether to extract additional measures from the GeoDataFrame extra_dataset.
- names_extra_measures: A list of strings representing the additional measures to extract from the GeoDataFrame extra_dataset. They have to match the name of the columns being extracted.
3.2.2. Outputs
- Column original_index: indices from the original dataset are stored here to make it easier to perform joins with other data.
- Column section: Column with GeoPandas geometry objects.
- Column timestamp: Column with datetime objects representing timestamps.
- Column geography: Column with GeoPandas geometry objects representing spaces with real coordinates.
3.3. Computational Complexity and Performance
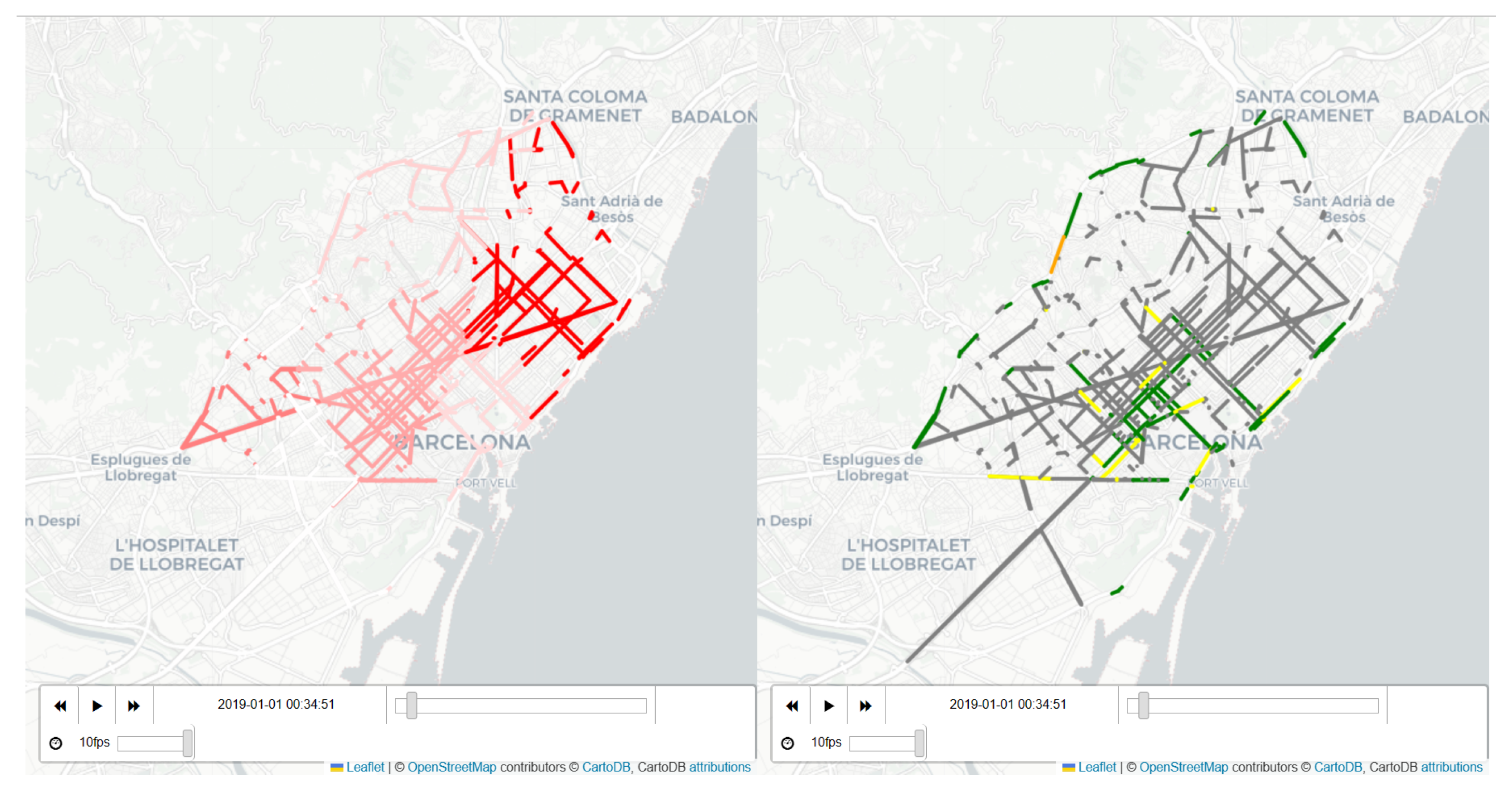
4. Case Study: From Time Series Data to Semantically Enriched Data
4.1. Challenges of the Real Life Problem of Car Traffic in the City
4.2. Definition of Requirements and State of the Original Data
4.3. Preprocessing, Feature Engineering and Standardization
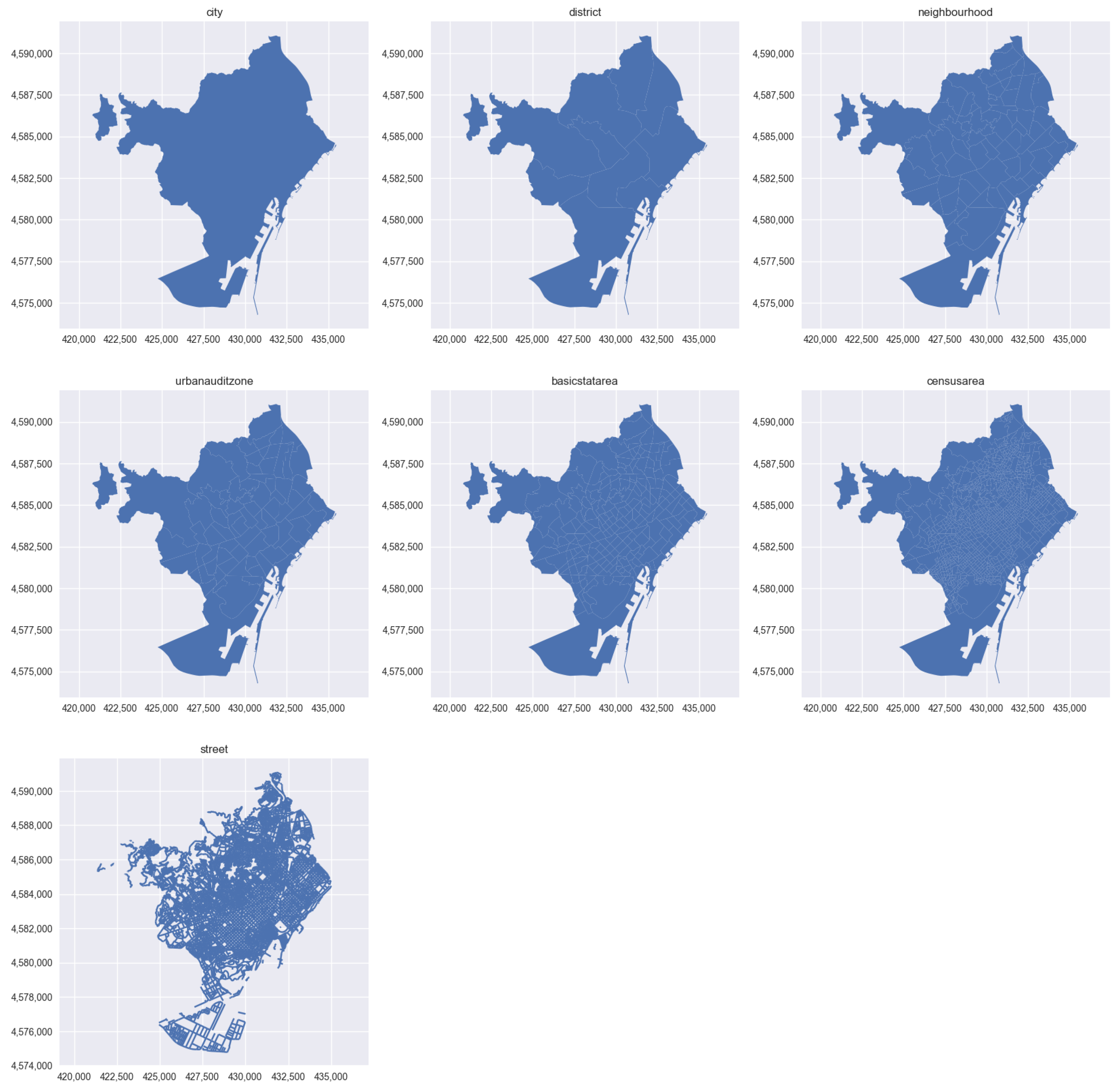
4.4. Open Data Barcelona Data Selection and Geographic Sections Definition
- city: This filter includes the entire city of Barcelona. This is the largest geographic area and encompasses all of the neighborhoods and districts within the city.
- district: Barcelona city is divided into 10 administrative districts, for which some data is only available on this division.
- neighbourhood: Each district in Barcelona city is further subdivided into neighborhoods.
- urbanauditzone: The Urban Audit project is a European-wide initiative that aims to provide comparative urban statistics. This filter allows focus to be directed on data from specific zones defined by the Urban Audit project.
- basicstatarea: These areas are used by the Barcelona City Council for statistical purposes only, and there are 233 different areas. This filter allows focus to be directed on data from a specific area that is relevant to the statistical analysis being performed.
- censusarea: These areas are defined by the Spanish National Institute of Statistics (INE) for census purposes. This filter allows focus to be directed on data from a specific area that is relevant to the census analysis being performed.
- street: This filter allows focus to be directed on data from specific street segments within the Barcelona city. This can be useful for analyzing data that is related to traffic patterns, foot traffic, and other street-level activities.
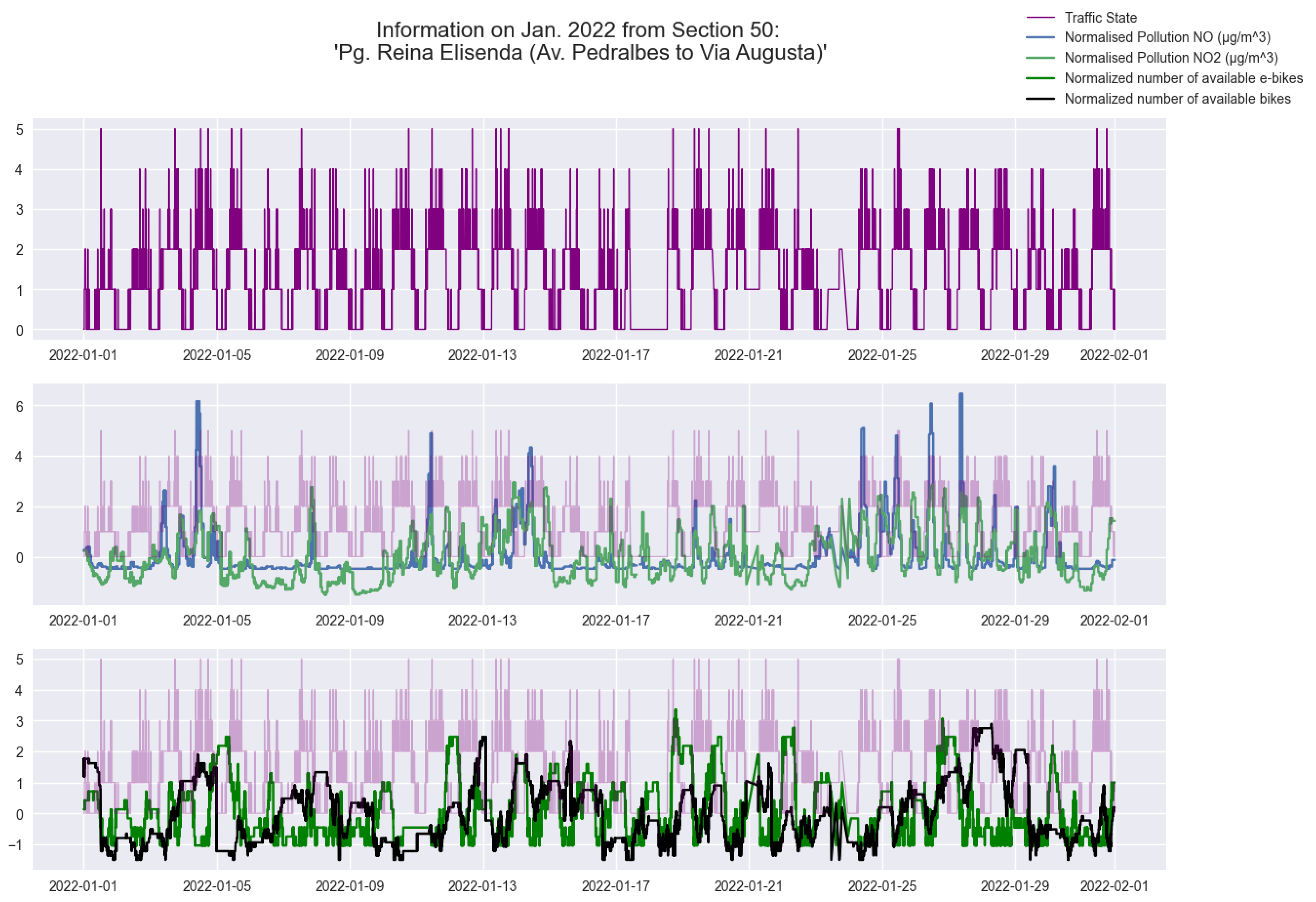
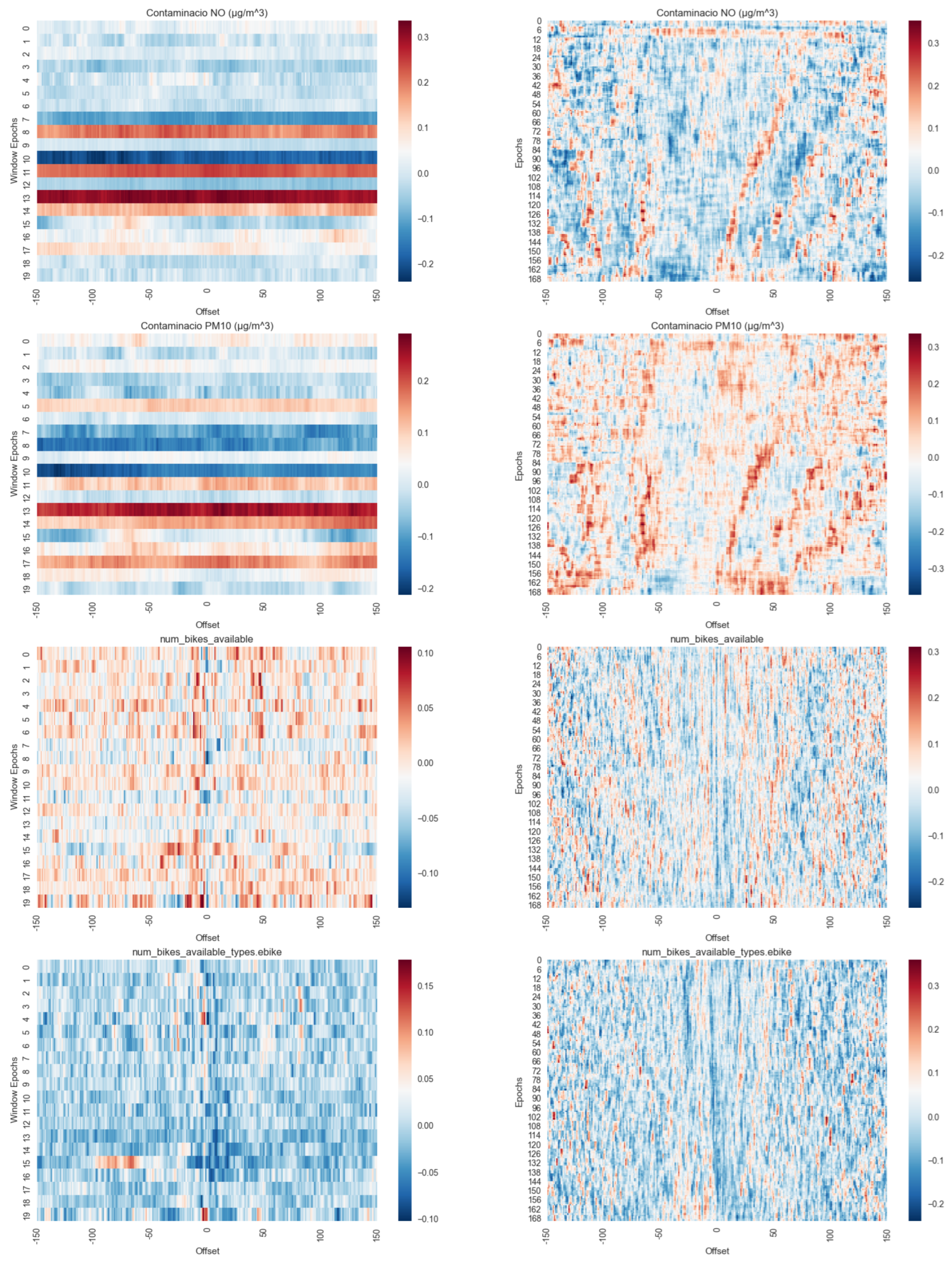
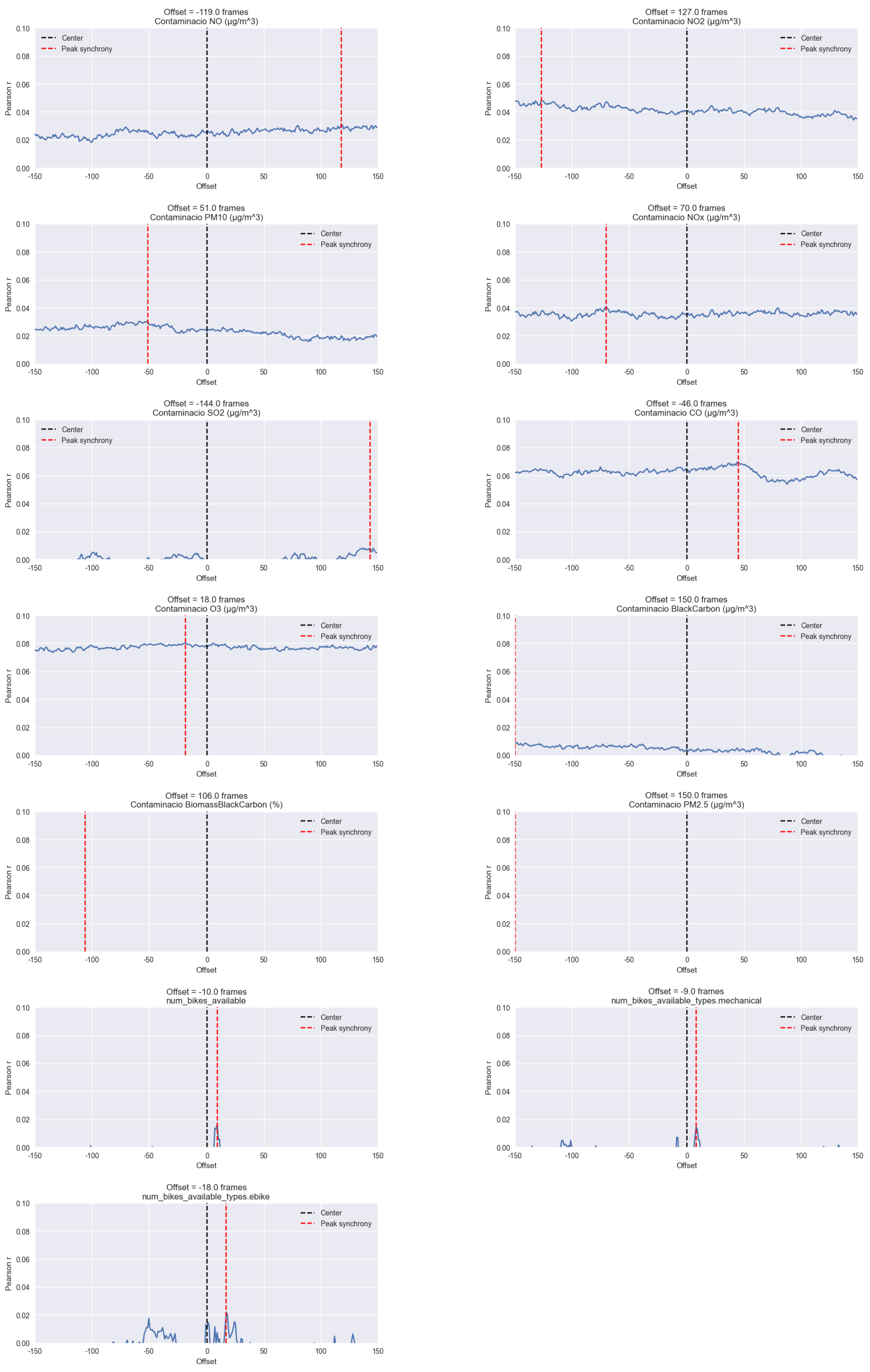
4.5. Computational Results
5. Summative Evaluation
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Python Code
Appendix B. Computational Results


References
- Azad, S.A.; Wasimi, S.; Ali, A.S. Business data enrichment: Issues and challenges. In Proceedings of the 2018 5th Asia-Pacific World Congress on Computer Science and Engineering (APWC on CSE), Nadi, Fiji, 10–12 December 2018; pp. 98–102. [Google Scholar]
- Clarke, M.; Harley, P. How smart is your content? Using semantic enrichment to improve your user experience and your bottom line. Science 2014, 37, 41. [Google Scholar]
- Belsky, M.; Sacks, R.; Brilakis, I. Semantic enrichment for building information modeling. Comput. Aided Civ. Infrastruct. Eng. 2016, 31, 261–274. [Google Scholar] [CrossRef]
- Bouaicha, S.; Ghemmaz, W. A Semantic Interoperability Approach for Heterogeneous Meteorology Big IoT Data. In Proceedings of the 12th International Conference on Information Systems and Advanced Technologies “ICISAT 2022” Intelligent Information, Data Science and Decision Support System; Springer: Berlin/Heidelberg, Germany, 2023; pp. 214–225. [Google Scholar]
- Bassier, M.; Bonduel, M.; Derdaele, J.; Vergauwen, M. Processing existing building geometry for reuse as Linked Data. Autom. Constr. 2020, 115, 103180. [Google Scholar] [CrossRef]
- Palavalli, A.; Karri, D.; Pasupuleti, S. Semantic internet of things. In Proceedings of the 2016 IEEE Tenth International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 4–6 February 2016; pp. 91–95. [Google Scholar]
- Zhang, L.; Liu, K. Semantic Modeling for Supporting Planning Decision Making toward Smart Cities. In Proceedings of the Construction Research Congress 2022, Arlington, VA, USA, 9–12 March 2022; pp. 272–280. [Google Scholar]
- Božić, B.; Winiwarter, W. A showcase of semantic time series processing. Int. J. Web Inf. Syst. 2013, 9, 117–141. [Google Scholar] [CrossRef]
- Ajuntament de Barcelona. Open Data BCN. Available online: https://opendata-ajuntament.barcelona.cat/en/open-data-bcn (accessed on 13 February 2023).
- Ajuntament de Barcelona. Barcelona Science Plan 2020–2023. Available online: https://www.barcelona.cat/barcelonaciencia/en/who-we-are/city-science-and-knowledge/barcelona-science-plan-2020-2023 (accessed on 13 February 2023).
- Honti, G.M.; Abonyi, J. A review of semantic sensor technologies in internet of things architectures. Complexity 2019, 2019, 6473160. [Google Scholar] [CrossRef] [Green Version]
- Xhafa, F.; Kilic, B.; Krause, P. Evaluation of IoT stream processing at edge computing layer for semantic data enrichment. Future Gener. Comput. Syst. 2020, 105, 730–736. [Google Scholar] [CrossRef]
- Chen, Y.; Sabri, S.; Rajabifard, A.; Agunbiade, M.E.; Kalantari, M.; Amirebrahimi, S. The design and practice of a semantic-enabled urban analytics data infrastructure. Comput. Environ. Urban Syst. 2020, 81, 101484. [Google Scholar] [CrossRef]
- Zappatore, M.; Longo, A.; Martella, A.; Di Martino, B.; Esposito, A.; Gracco, S.A. Semantic models for IoT sensing to infer environment–wellness relationships. Future Gener. Comput. Syst. 2023, 140, 1–17. [Google Scholar] [CrossRef]
- Buchmann, R.A.; Karagiannis, D. Pattern-based transformation of diagrammatic conceptual models for semantic enrichment in the Web of Data. Procedia Comput. Sci. 2015, 60, 150–159. [Google Scholar] [CrossRef] [Green Version]
- Djenouri, Y.; Belhadi, H.; Akli-Astouati, K.; Cano, A.; Lin, J.C.W. An ontology matching approach for semantic modeling: A case study in smart cities. Comput. Intell. 2022, 38, 876–902. [Google Scholar] [CrossRef]
- Xu, Y.; Xiao, W.; Yang, X.; Li, R.; Yin, Y.; Jiang, Z. Towards effective semantic annotation for mobile and edge services for Internet-of-Things ecosystems. Future Gener. Comput. Syst. 2023, 139, 64–73. [Google Scholar] [CrossRef]
- Xue, F.; Wu, L.; Lu, W. Semantic enrichment of building and city information models: A ten-year review. Adv. Eng. Inform. 2021, 47, 101245. [Google Scholar] [CrossRef]
- Amato, F.; Casola, V.; Gaglione, A.; Mazzeo, A. A semantic enriched data model for sensor network interoperability. Simul. Model. Pract. Theory 2011, 19, 1745–1757. [Google Scholar] [CrossRef]
- Jiang, Y.; Su, X.; Treude, C.; Wang, T. Hierarchical semantic-aware neural code representation. J. Syst. Softw. 2022, 191, 111355. [Google Scholar] [CrossRef]
- Ataei Nezhad, M.; Barati, H.; Barati, A. An Authentication-Based Secure Data Aggregation Method in Internet of Things. J. Grid Comput. 2022, 20, 29. [Google Scholar] [CrossRef] [PubMed]
- Iatrellis, O.; Panagiotakopoulos, T.; Gerogiannis, V.C.; Fitsilis, P.; Kameas, A. Cloud computing and semantic web technologies for ubiquitous management of smart cities-related competences. Educ. Inf. Technol. 2021, 26, 2143–2164. [Google Scholar] [CrossRef]
- Ribeiro, M.B.; Braghetto, K.R. A Scalable Data Integration Architecture for Smart Cities: Implementation and Evaluation. J. Inf. Data Manag. 2022, 13. [Google Scholar] [CrossRef]
- Tao, M. Semantic ontology enabled modeling, retrieval and inference for incomplete mobile trajectory data. Future Gener. Comput. Syst. 2023, 145, 1–11. [Google Scholar] [CrossRef]
- Psyllidis, A.; Bozzon, A.; Bocconi, S.; Titos Bolivar, C. A platform for urban analytics and semantic data integration in city planning. In Proceedings of the Computer-Aided Architectural Design Futures. The Next City-New Technologies and the Future of the Built Environment: 16th International Conference, CAAD Futures 2015, São Paulo, Brazil, 8–10 July 2015; Selected Papers 16. Springer: Berlin/Heidelberg, Germany, 2015; pp. 21–36. [Google Scholar]
- Costa, C.; Santos, M.Y. The SusCity big data warehousing approach for smart cities. In Proceedings of the 21st International Database Engineering & Applications Symposium, Bristol, UK, 12–14 July 2017; pp. 264–273. [Google Scholar]
- Boker, S.; Xu, M.; Rotondo, J.; King, K. Windowed cross-correlation and peak picking for the analysis of variability in the association between behavioral time series. Psychol. Methods 2002, 7, 338–355. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Year | Area of Study | Methods | Contributions |
|---|---|---|---|---|
| [11] | 2019 | IoT, & Semantic sensor technologies | Literature review | Semantic sensor technologies improve interoperability and data quality in IoT systems. |
| [12] | 2020 | IoT, & Edge computing | Experimental study | Edge computing is a promising solution for improving the efficiency and effectiveness of semantic data enrichment. |
| [13] | 2020 | Urban Analytics & Semantic-enabled infrastructure | Case study | Semantic-enabled infrastructure can effectively integrate and analyze data from multiple sources, providing valuable insights for urban decision-making. |
| [14] | 2023 | IoT & Semantic models for data analysis | System proposal | Semantic models can lead to a more accurate and efficient analysis of IoT sensor data and valuable insights into how environmental factors impact human well-being. |
| [15] | 2015 | Web of Data & Diagrammatic conceptual models | Pattern-based approach | Pattern-based approach improves web data interoperability. |
| [16] | 2020 | Smart cities & Ontology matching | Case study | Proposed method effectively matches ontologies and resolves semantic mismatches between them. |
| [17] | 2023 | IoT & Semantic annotation | System proposal | Semantic annotations can improve the efficiency and accuracy of data processing in IoT ecosystems and the interoperability of different IoT devices. |
| [18] | 2021 | Building and city information modeling & Semantic enrichment | Literature review | Semantic enrichment improves data interoperability, data quality, and data usability. |
| [19] | 2021 | Semantic sensor technologies & Semantically enriched data model | Experimental study | Semantically enriched data model effectively improves sensor network interoperability. |
| [20] | 2022 | Hierarchical & semantically-aware code representation | System proposal | Incorporating semantic information into code representation improves comprehension of code structure. |
| [21] | 2022 | IoT | Authentication-based secure data aggregation | Proposed a two-tier architecture for secure data aggregation in IoT using symmetric key encryption. |
| [22] | 2021 | Smart Cities | Cloud-based platform, Semantic web technologies, Competency management, Learning management, Assessment tools | Proposed system is flexible, adaptable, and scalable, and has the potential to revolutionize the way we manage competencies in smart city contexts. |
| [23] | 2022 | Smart Cities | Scalable data integration architecture, Three-layer architecture for data collection, processing, and analysis, Case study using real-world data | Proposed architecture is effective and scalable for integrating and analyzing data from multiple sources. |
| [24] | 2023 | Mobile Trajectory Data | Semantic ontology, Probabilistic model for handling missing data, Graph-based retrieval method | Proposed framework is effective and efficient in dealing with incomplete trajectory data and improving trajectory retrieval accuracy. |
| [25] | 2015 | Urban Analytics | Platform for urban analytics and integration of semantic data in city planning | Platform facilitates collaboration among various stakeholders involved in urban planning by providing tools for collecting, analyzing, and visualizing data. |
| [26] | 2017 | Smart Cities | Big data warehousing approach, Three-layer architecture for data ingestion, warehousing, and analytics, Machine learning algorithms for predictive analytics | Approach addresses the challenges of managing and analyzing the large and diverse data generated by smart city systems. |
| Dataset | Geographical Locations | Information | Periodicity |
|---|---|---|---|
| Traffic Density (Geographic definition: Lines) | 534 sections of streets defined in the city map of Barcelona | Traffic Density values and Initial Locations in a categorical internal system (from no traffic to jam). | Every 15 min (when there is data available) |
| Pollutants (Geographic definition: Points) | Eight pollution sensors coordinates (points) spread out on Barcelona city | Pollutant Values:
| Every hour (when there is data available) |
| Public Bike Availability (Geographic definition: Points) | 519 public bike system stations | Bike availability number by type:
| Every 20 to 40 s (when there is data available) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Garcia, E.; Peyman, M.; Serrat, C.; Xhafa, F. Join Operation for Semantic Data Enrichment of Asynchronous Time Series Data. Axioms 2023, 12, 349. https://doi.org/10.3390/axioms12040349
Garcia E, Peyman M, Serrat C, Xhafa F. Join Operation for Semantic Data Enrichment of Asynchronous Time Series Data. Axioms. 2023; 12(4):349. https://doi.org/10.3390/axioms12040349
Chicago/Turabian StyleGarcia, Eloi, Mohammad Peyman, Carles Serrat, and Fatos Xhafa. 2023. "Join Operation for Semantic Data Enrichment of Asynchronous Time Series Data" Axioms 12, no. 4: 349. https://doi.org/10.3390/axioms12040349
APA StyleGarcia, E., Peyman, M., Serrat, C., & Xhafa, F. (2023). Join Operation for Semantic Data Enrichment of Asynchronous Time Series Data. Axioms, 12(4), 349. https://doi.org/10.3390/axioms12040349