1. Introduction
The increase in user-made content on the web in the form of reviews, blogs, social networks, and tweets has resulted in circumstances in which everyone can publicly express their opinions about events, products, or people. This user-made text information can be critical to establishments and companies and provides valuable insights into consumer behavior, reputation management, and identification of new opportunities. Moreover, sentiment analysis has emerged as a powerful trading tool in the financial industry, in which markets are heavily influenced by human sentiments. In the financial sector, sentiment analysis provides valuable signals for stock trading strategies because market movements are often driven by sentiments.
Sentiment analysis, also known as opinion mining, involves computer studies of sentiments, emotions, and attitudes expressed in textual data regarding real entities or topics. It covers a wide range of areas and serves a wide range of purposes, such as assessing public sentiment regarding political movements, understanding market dynamics, measuring customer satisfaction, forecasting oil prices, and predicting stock prices. For example, Nguyen et al. [
1] was the first to demonstrate the effectiveness of incorporating sentiment analysis by investigating large-scale test data to predict stock price movements. In addition, Li et al. [
2] used Henry’s finance-specific dictionary to filter positive and negative words, and then calculated sentiment scores to enhance the accuracy of forecasting oil prices.
As previously mentioned, financial markets, particularly stock markets, were affected by sentiments; therefore, the sentiments can provide useful signals for trading. Accordingly, this study aimed to predict stock prices by extracting sentiments from news data. In particular, we perform a sentiment analysis using summarized text data to reduce the news body to a few sentences. That is, sentiment analysis will be performed with relatively little data in the body of the article. We estimate the sentiment of the summarized text data using FinBERT (Financial Bidirectional Encoder Representations from Transformers), a model specialized in finance. The FinBERT, a specialized language model built upon BERT, is tailored for financial language processing. Trained on financial texts such as news, earnings reports, regulations, and analyst summaries, FinBERT has gained prominence for its efficacy in predicting stock prices in various studies (Sidogi et al. [
3], Fazlija and Harder [
4], Jiang and Zeng [
5]). In addition, we conducted a sentiment analysis on the data summarized in FinBERT and investigated whether these results affect stock price forecasts. A detailed introduction to FinBERT will be provided in
Section 4.3.
Based on the sentiment analysis by using the FinBERT, we predict the S&P 500 index price. Our analysis focuses on concise news summaries sourced from The New York Times website, encompassing headlines, summaries, and bodies. These summaries, offering a brief article overview, are subjected to sentiment analysis. Using the summary data, we are able to use a relatively small amount of data over the same period compared to using the full texts. The text data used are from 1 January 2018 to 31 December 2022, a total of 1826 days. Correspondingly, S&P 500 index predictions are made for the same time period. The S&P 500 index data are extracted from Yahoo Finance.
Methodologically, we performed sentiment analysis on summarized text data from
The New York Times using FinBERT. This yielded a new variable termed ‘Sentiment Score’. Following Batra and Daudpota [
6], S&P 500 price prediction employed a variable set (‘Open’, ‘High’, ‘Low’, ‘Close’, ‘Adj Close’, and ‘Volume’) commonly used for such forecasts. Another prediction employed a set containing the sentiment score from prior analysis (‘Open’, ‘High’, ‘Low’, ‘Close’, ‘Adj Close’, ‘Volume’, and ‘Sentiment Score’). Both processes employed the same LSTM model optimized through random search (Bergstra and Bengio [
7]). To evaluate the sentiment score’s impact on stock price prediction, we compared the performance of the group without a sentiment score and the one with it.
Our study contributes to the existing body of literature in three ways. First, it investigated the relationship between the sentiment of news articles and stock price predictions. The empirical findings provide evidence supporting the notion that sentiments expressed in news articles can be used to predict stock prices.
Second, FinBERT, a highly effective technique, was employed to enhance the sentiment analysis of news article summaries from The New York Times. Previous research has demonstrated that FinBERT outperforms other techniques such as ELMo (Embeddings from Language Model) and ULMFit (Universal Language Model Fine-Tuning) in sentiment analysis. This study contributes to the existing literature by utilizing FinBERT, which has been found to exhibit superior performance in sentiment analysis.
Third, this study used summary news data for sentiment analysis. In other words, the researchers leveraged the advantages of summary data in terms of data volume and processing. Despite employing relatively condensed content instead of full-text articles, the research outcomes were comparable to those of previous studies on stock price prediction. Notably, previous studies employed
New York Times article data for sentiment analysis and established a connection between sentiment and stock prices (Wang et al. [
8], Costola et al. [
9]). However, this study achieved similar results solely through the use of summary data with relatively concise content.
Lastly, our research makes significant contributions to the field of mathematics-based sentiment analysis and asset prediction research. The advent of NLP and deep learning methodologies, such as BERT, has revolutionized the analysis of unstructured data through mathematical techniques, with sentiment analysis gathering substantial attention. This useful sentiment analysis technique finds applications in diverse domains, including marketing (Kauffmann et al. [
10]), social science (Hu et al. [
11]), and mathematical modeling (Sysoev et al. [
12], Srinivasarao and Sharaff [
13]). Our research design, built upon the foundation of FinBERT, further enriches and enhances these existing sentiment analysis studies. Furthermore, the prediction of financial assets remains a critical topic within financial mathematics. Recent studies have demonstrated the remarkable performance of Artificial Neural Network (ANN)-based machine learning methodologies in predicting future data (Casado-Vara et al. [
14], Chae and Choi [
15], Lin et al. [
16]). Our study takes an effective approach by utilizing the LSTM methodology to forecast the price of the S&P 500, contributing substantially to the growing body of knowledge in this area.
The remainder of this paper is organized as follows. Related studies are reviewed in the following section.
Section 3 describes the summary news data and S&P 500 index. In
Section 4, a comprehensive overview of the news sentiment analysis process is provided, along with a brief exploration of both the LSTM model and the finBERT model. The empirical findings pertaining to the prediction of the S&P 500 through the utilization of sentiment analysis are presented in
Section 5. We further provide a series of comprehensive discussions in
Section 6. Finally,
Section 7 presents the summary and concluding remarks.
5. Empirical Results
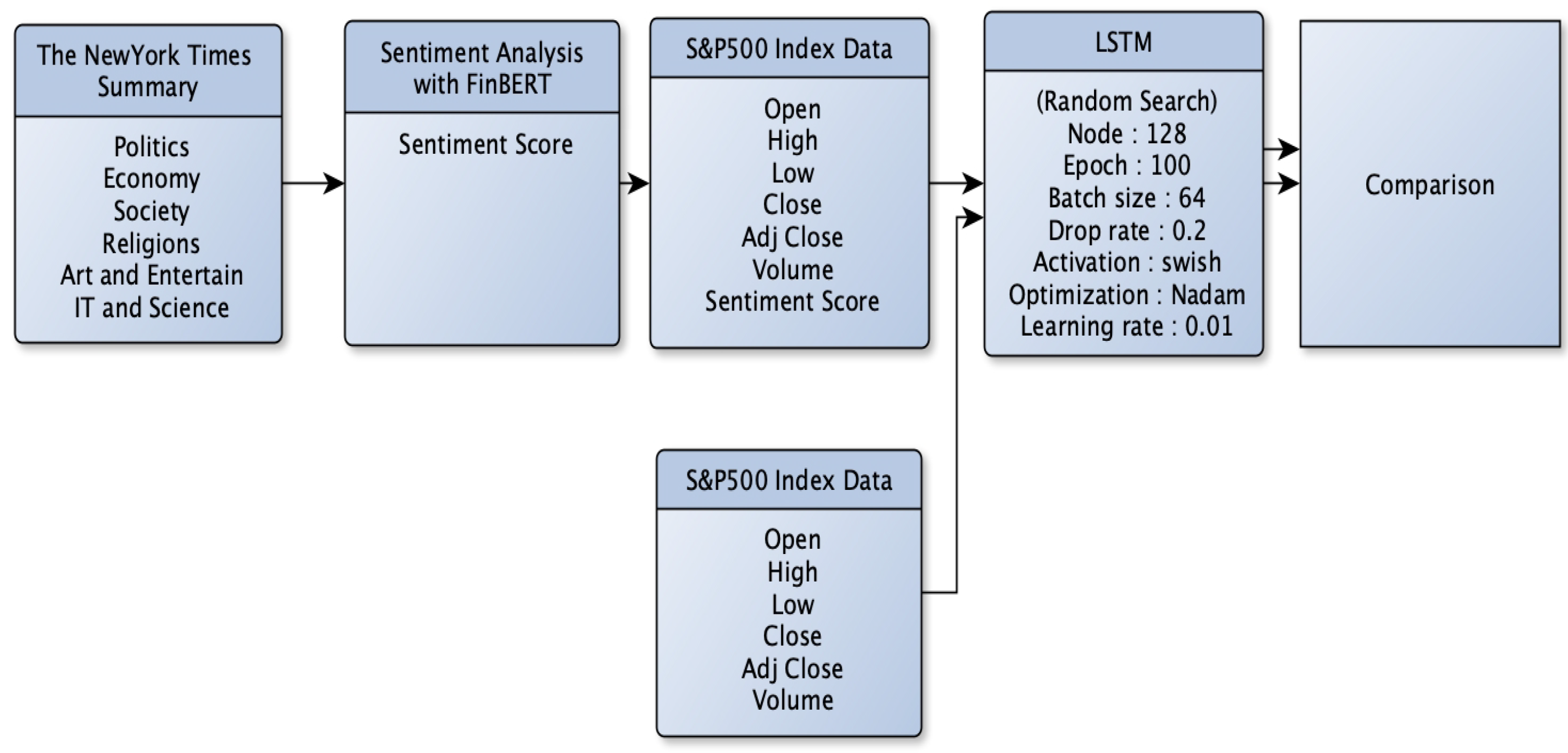
This study follows the process shown in
Figure 6 and uses two datasets of size 1240 to predict the S&P 500 index using LSTM. The first dataset used (‘Open’, ‘High’, ‘Low’, ‘Close’, ‘Adj Close’, and ‘Volume’) of the S&P 500 index. The second dataset used (‘Open’, ‘High’, ‘Low’, ‘Close’, ‘Adj Close’, ‘Volume’, and ‘Sentiment score’).
To calculate the sentiment score, we used news summaries from 2018 to 2022 provided by The New York Times. The news summaries also included weekends. However, the S&P 500 index excluded holidays. Therefore, we fitted the sentiment scores to the S&P 500 business-day data.
The features of the S&P 500 index had different scales. For example, ‘Open’, ‘High’, and ‘Low’ had similar sizes, but were different in absolute size in terms of ‘Volume’, which was the same as the ‘sentiment score’. Therefore, the weights could have excessively large values. Normalization using Sklearn’s MinMaxScaler was applied to reduce the complexity of the model and avoid overfitting.
We handled the data from 30 January 2018, to 30 December 2022. The data contained only business days, and we split the entire dataset into 70% training set and 30% test set without shuffling sequentially. Next, we removed the date feature and set ‘Close’ as the label. We used (‘Open’, ‘High’, ‘Low’, ‘Close’, ‘Adjusted Close’, ‘Volume’) and (‘Open’, ‘High’, ‘Low’, ‘Close’, ‘Adjusted Close’, ‘Volume’, ‘Sentiment Score’) as features. We then prepared the training and test sets to fit the input form of the LSTM model for short-term forecasting and converted them to (# of samples, 1, # of features). Then, we trained the LSTM layer model with hyperparameter tuning on the prepared train data. We used a random search method to determine the optimal hyperparameters.
Finally, the two feature sets were input into the LSTM model with the hyperparameter tuned to predict the S&P 500 index. We checked the goodness-of-fit of the model by comparing the error measures of the predicted results.
5.1. Hyperparameter Tuning
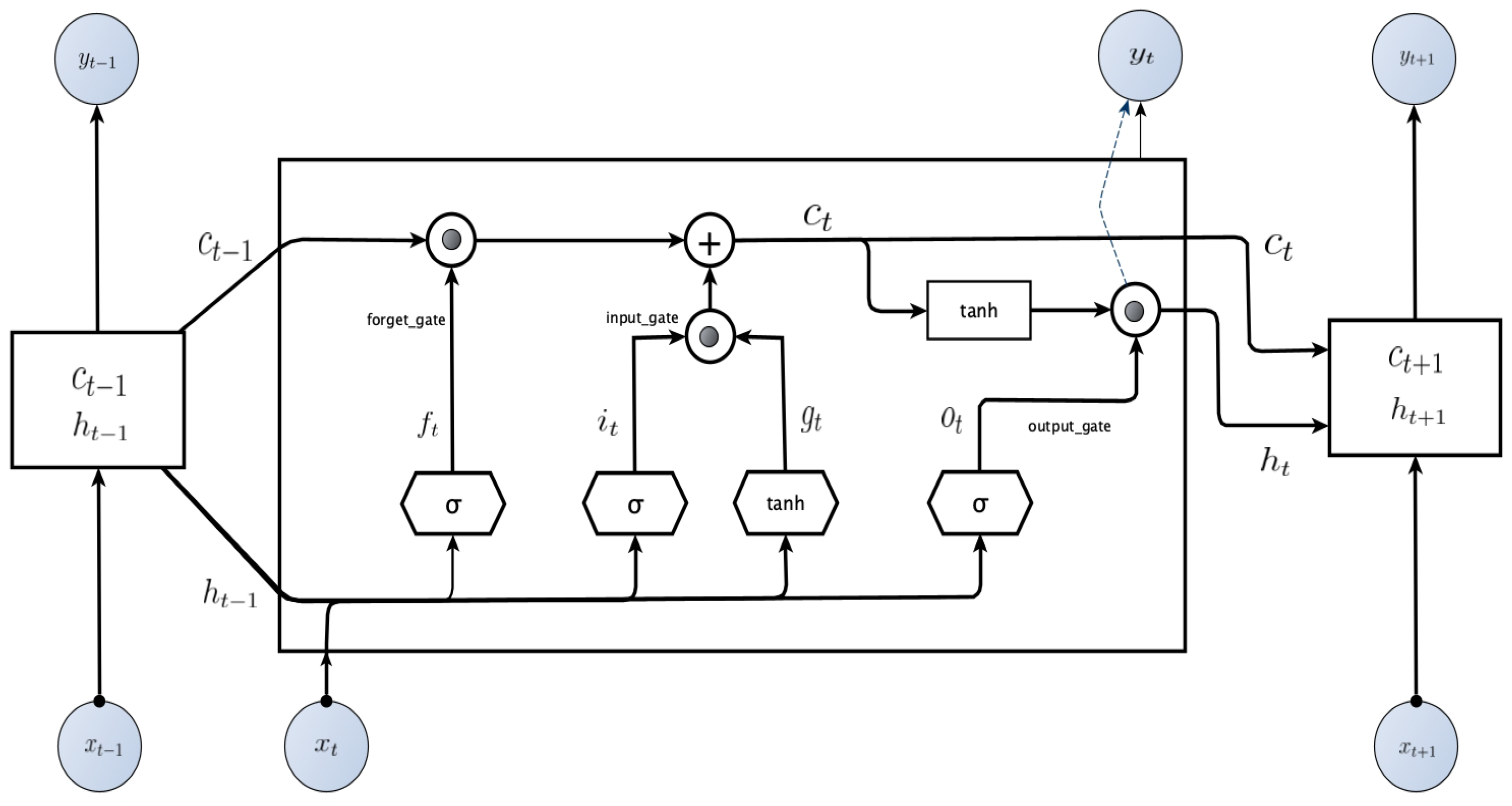
When modeling an LSTM, the choice of hyperparameters is important. The LSTM used the following hyperparameters: ‘unit’, ‘dropout rate’, ‘optimizer’, ‘activation function’, ‘learning rate’, ‘epochs’, and ‘batch size’. ‘unit’ determines the number of units in the layer; more units makes the model more complex and slower to learn. ‘dropout’ removes random neurons, preventing the model from overfitting. ‘optimizer’ selects the optimization algorithm, such as Adam, SGD, and Nadam. ‘activation function’ selects the activation function used by the layer; sigmoid and tanh are commonly used, and recently ReLU, ELU, and Swish are also used as they perform better. ‘learning rate’ determines the rate at which the model learns, with high learning rates enabling faster learning, but at the cost of performance. ‘epochs’ determines the number of times the model learns the dataset. ‘batch size’ determines the number of small batches of data used to train the model. Larger batches result in faster training, but may cause memory issues.
Random Search is one of the hyperparameter optimization methods. Tuning hyperparameters is the process of finding hyperparameters that minimize the error measure (e.g., MSE, MAE). Hyperparameters influence the performance of the model during training. Therefore, finding the optimal values for hyperparameters is crucial. Grid Search, another hyperparameter optimization method, tries all possible combinations of the hyperparameters grid to find the optimal values, which often requires a significant amount of resources. On the other hand, Random Search randomly selects hyperparameter grid points for tuning.
According to Bergstra and Bengio [
7], Random Search outperformed Grid Search in most cases and required less computation time. Therfore, in this study, we used a Random Search algorithm, and the parameter grid used for the Random Search is presented in
Table 4.
We also created a dataset from the data collected from 29 January 2018 to 30 December 2022, to check for lags of 1, 5, and 10. The results showed a significant and distinct change in the metrics when the lag was set to 1. The choice of lag 1 was driven by the fact that it exhibited higher explanatory power compared to lags 5 and 10 (See
Table A1). Additionally, the difference in results between models with sentiment scores and those without became more pronounced when using lag 1. Moreover, among the models incorporating sentiment scores, the one utilizing lag 1 demonstrated the best performance, with the highest
value. We also saw performance improvements across other error metrics.
Moreover, we focused on short-term forecasting, not long-term forecasting in this study. The reason for this is as follows. According to Kumar and Ningombam [
49], fundamental analysis and technical analysis are two popular strategies for predicting stock prices. Fundamental analysis is based on the overall conditions of the economy and industry. Technical analysis is an analytical strategy that predicts the direction of a stock price and is preferred because it can predict short-term returns and actually helps traders make informed decisions before committing to trading. Therefore, our study focused on short-term forecasts and the news summary data we used is also short-term forecast because the frequency is daily. In addition, according to Jiang and Zeng [
5], it is difficult to predict long-term behavior in the financial market because there are too many factors and these factors affect the financial market. In addition, there are many studies on daily stock price forecasting (Khare et al. [
50], Weng et al. [
51]). Due to the volatility of the market, the rate of change in prices is usually larger in long-term forecasts than short-term, so short-term price forecasts can be more effective than long-term forecasts. For these reasons, we focused on short-term forecasting rather than long-term forecasting. Fundamental investing also requires a long-term strategy, as it takes a long time to invest. Due to these characteristics, we also need a long-term strategy. So, we will be working on a long-term forecast in the future.
5.2. Error Measure
We used various measures in evaluating the forecasts using LSTM. The mean squared error (MSE) is a forecasting error that measures the difference between the predicted and actual values by squaring and taking the average of the two values. Therefore, the MSE varies sensitively depending on the size of the prediction error. The root mean squared error (RMSE) is the square root of the MSE. Therefore, it is less sensitive to error size because it takes the square root of the MSE. Thus, the error size can be interpreted more intuitively. The mean absolute error (MAE) is an average of absolute errors. It reacts less sensitively to prediction error size and receives less influence from outliers compared to MSE. Accordingly, lower MSE, RMSE, and MAE suggest better performance, reflecting closer average predictions to real values. On the other hand,
is a statistical measure indicating how much of the variance in the dependent variable can be explained by the independent features of a model. It ranges from 0 to 1, where 0 indicates that the model does not explain any variance and 1 indicates a perfect fit. The
was used to evaluate how well the model fitted the data and how much variation in stock prices could be attributed to the predictor variables. However, a high value of
does not guarantee that the model is accurate. The formulas are as follows:
where
n is the number of data,
is the realized value of the S&P 500 index and
is the prediction value using the LSTM model.
5.3. Summary Results
We determined whether the results of the sentiment analysis of news data trained using the S&P 500 data from 2018 to 2022 could be used to forecast stock prices. According to Engelberg and Parsons [
52], news about financial events affects stock prices. In this study, we determined whether a more accurate stock price prediction model could be created using sentiment scores of the summary text in The Front Page section of
The New York Times and financial event news.
Table 5 demonstrates the model’s ability to predict the S&P 500 index by utilizing both S&P 500 data and
The New York Times sentiment analysis. Specifically, the table presents the best-performing results among values obtained from 10 iterations of random search hyperparameter tuning. As depicted in the table, models that incorporate sentiment scores exhibit a noticeable enhancement in error measures. This improvement is reflected in an elevated
value, signifying increased consistency and heightened predictive stability. Furthermore,
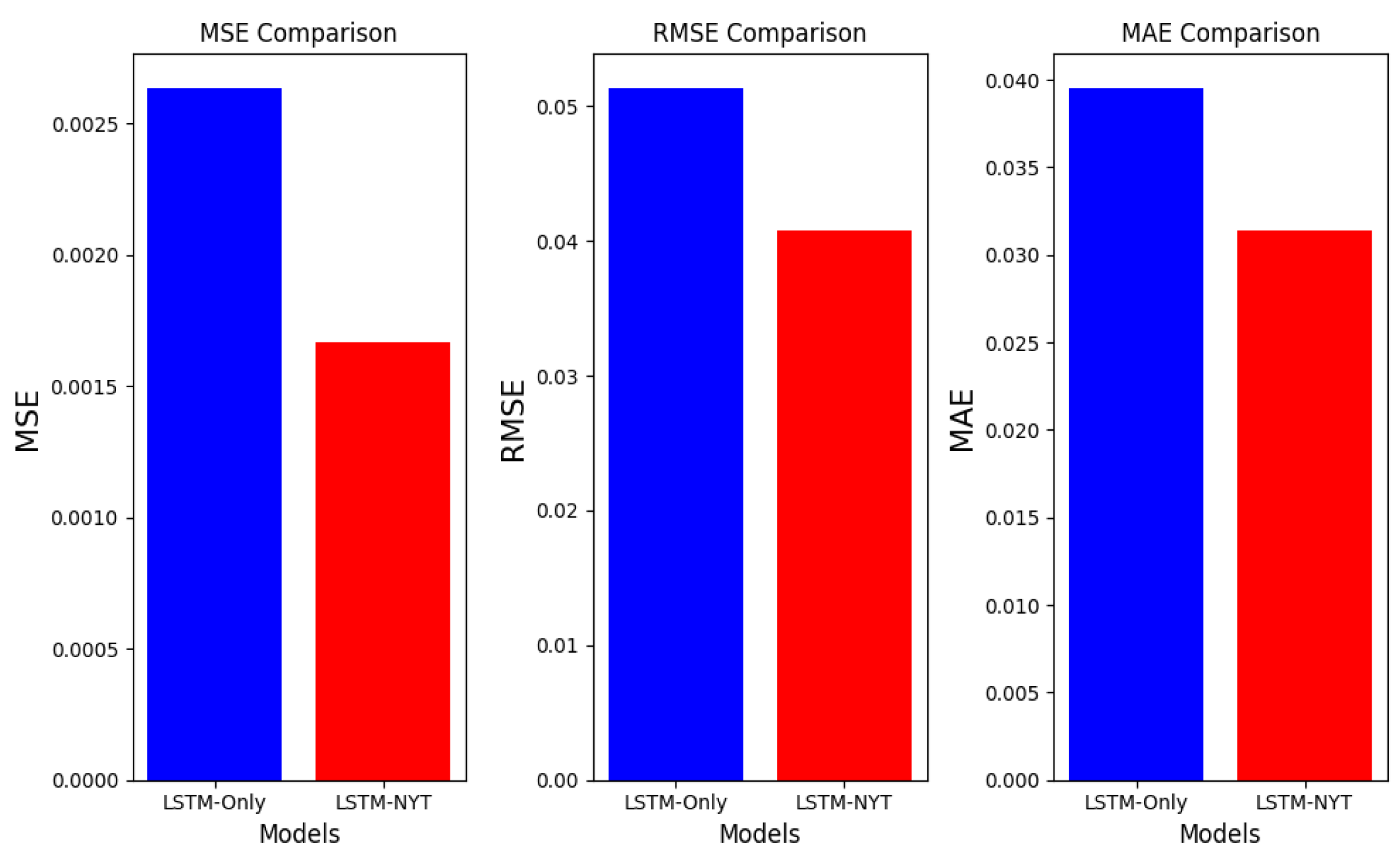
Figure 7 provides a comparative view, highlighting the distinct error measures of the two models. This differentiation further indicates the pronounced advantages of integrating sentiment scores. Moreover,
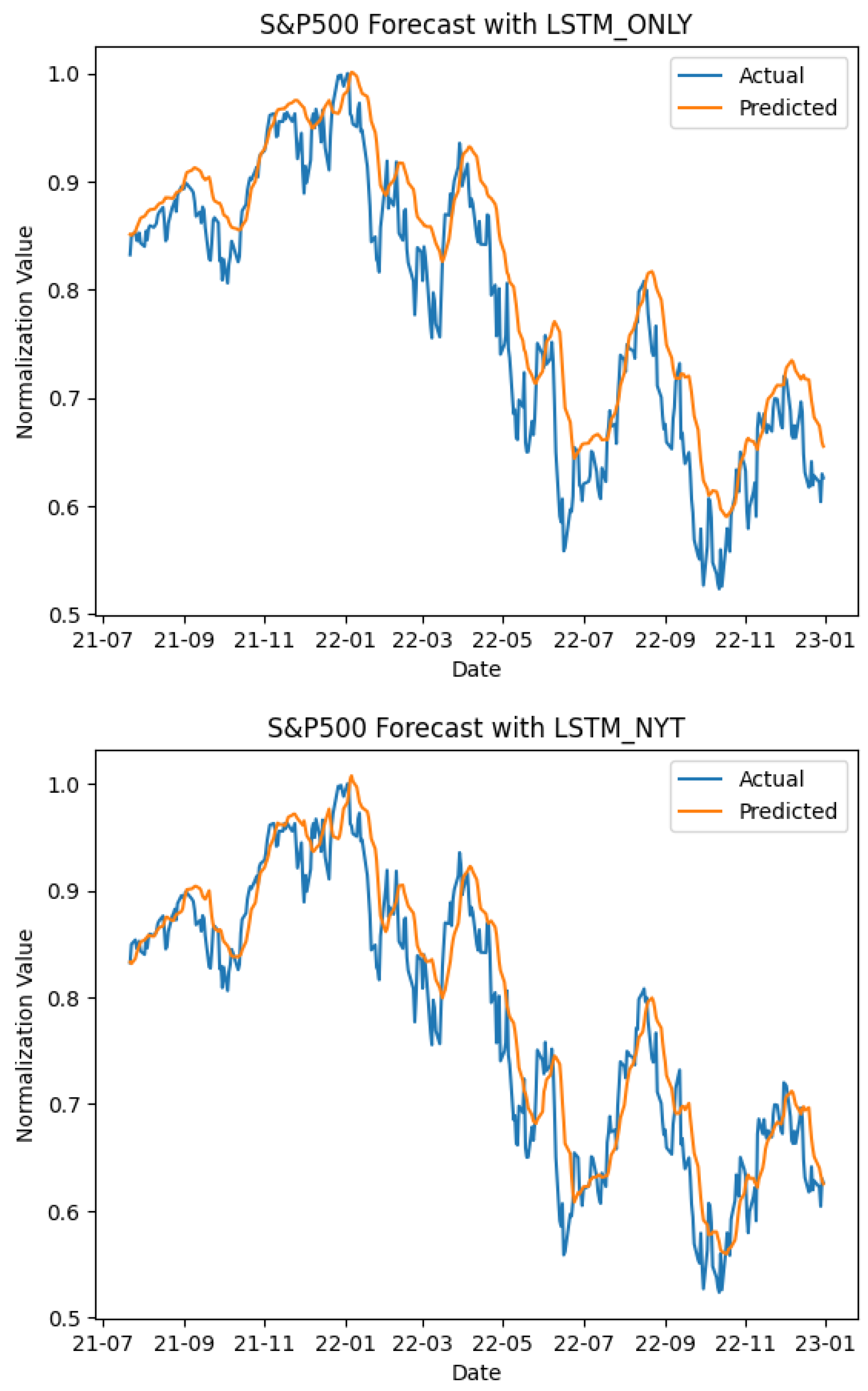
Figure 8 visually emphasizes the predictive capacity of the sentiment score integrated model by demonstrating the predicted normalized S&P 500 index. Remarkably, the predictive trends described in the figure substantiate the model’s superior proficiency in forecasting the actual normalized S&P 500 index.
In conclusion, the model that used the daily summary explained the S&P 500 index better than the LSTM model with the basic features of the S&P 500 index. Specifically, whereas previous studies used results of sentiment analyses of news related to companies to predict stock prices, this study used sentiment analysis of news summaries from various fields other than the corporate and financial sectors. Additionally, predicting S&P 500 index using a feature set containing sentiment scores resulted in smaller errors. This finding confirms that news sentiments on various topics affect stock prices.
Additionally, we categorized the predicted values of the LSTM Only model (LSTM_Only) and the LSTM model with sentiment scores (LSTM_NYT). Subsequently, an independent two-sample
t-test was performed to identify statistically significant distinctions between these two groups. According to the
t-test (
Table 6), there was a significant difference in the mean between the two predicted value groups.
5.4. Model Performance in Crisis Periods
In this subsection, we examine how sentiment scores impact S&P 500 index prediction during high-volatility periods. We focus on the COVID-19 and Russia–Ukraine (RU) War periods. The sudden COVID-19 pandemic severely affected financial markets, causing significant disruptions (Choi [
53], Szczygielski et al. [
54], Liu et al. [
55]). The RU War also led to increased market volatility, characterized by supply chain disruptions and energy concerns (Umar et al. [
56], Lo et al. [
57], Alam et al. [
58]). The COVID-19 disruption spanned from 1 March 2020 to 31 December 2020, while the RU War disruption occurred from 23 February 2022 to 31 December 2022.
We employ LSTM models to make predictions both with and without sentiment scores.
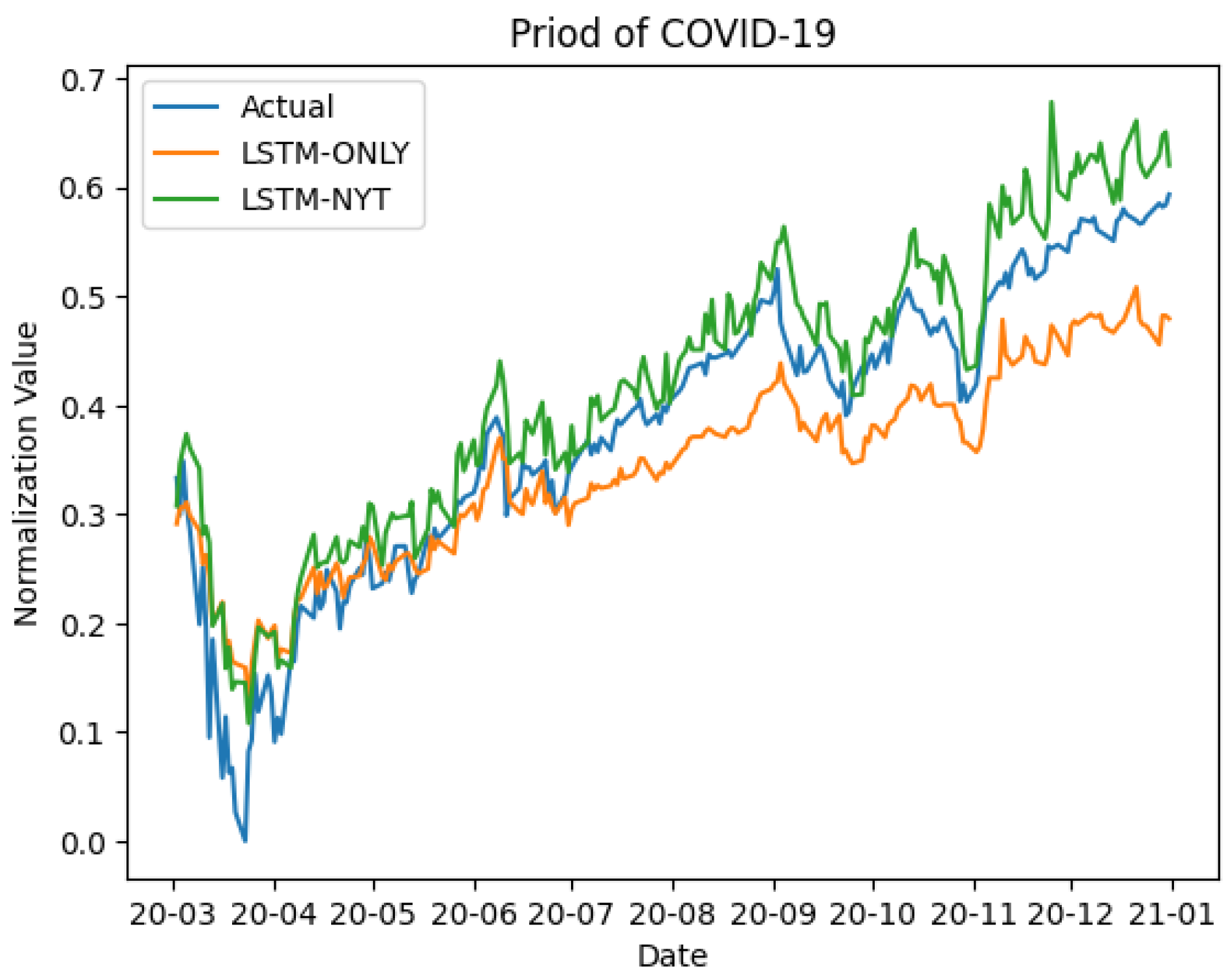
Table 7 shows that models with sentiment scores outperform models without sentiment scores in terms of measuring error, even during the COVID-19 period. Including sentiment scores also increased the
value, improving the explanatory power of the model. Similarly,
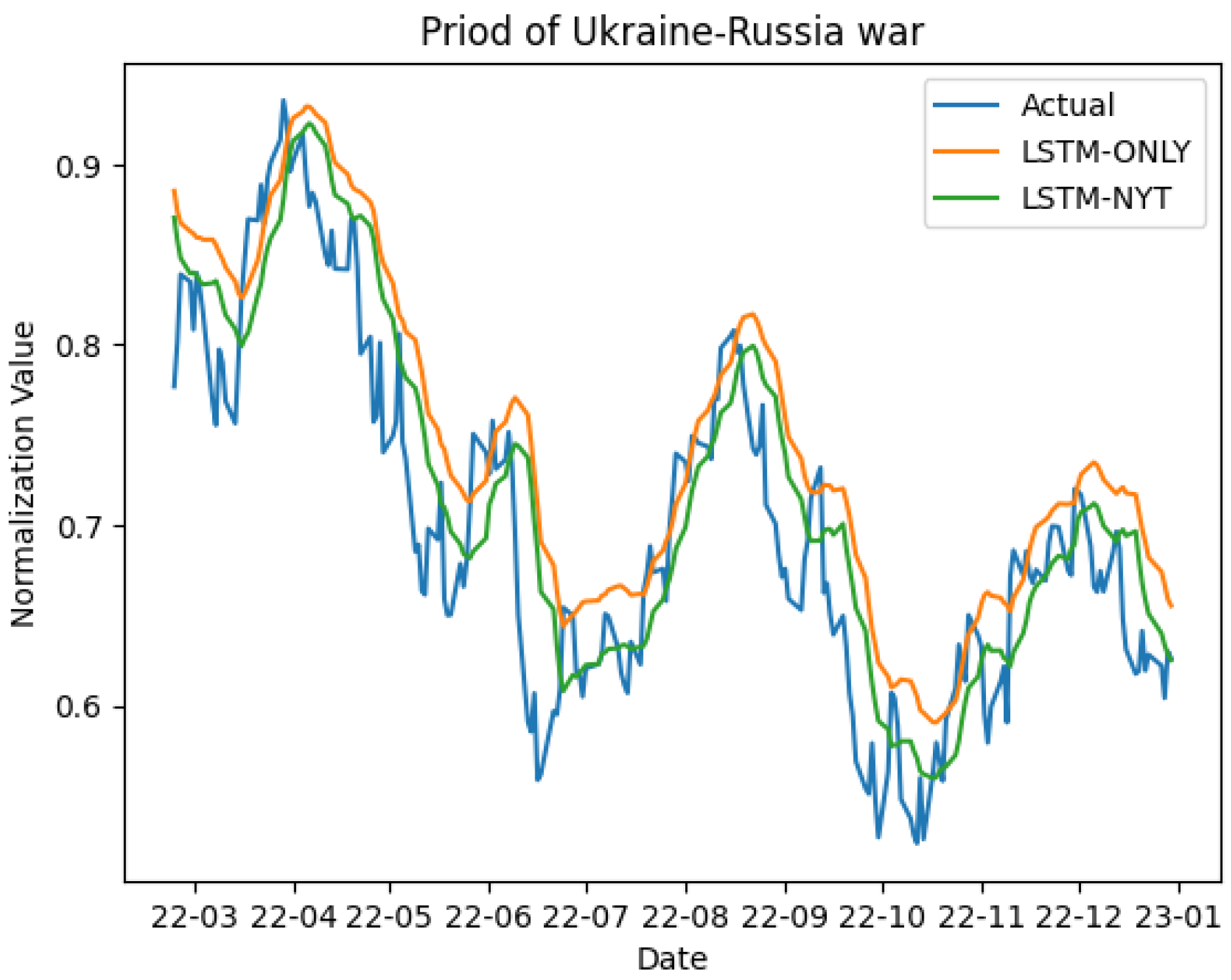
Table 8 also indicates that models incorporating sentiment scores performed better even during the RU War. Visual representations in
Figure 9 and
Figure 10 provide intuitive insights into predictive performance during the COVID-19 and RU War periods.
In conclusion, our analysis underscores the meaningful role of sentiment scores in predicting the S&P 500 index, particularly during phases of high volatility.
6. Discussion
In the finance domain, stock prices exhibit high volatility and complexity. Predicting stock prices has driven numerous research efforts. The broader social environment, especially sentiments in diverse media such as news or social networks, is recognized as a potential driver of stock prices. Significant news releases particularly affect stock movements. Several studies have explored sentiment analysis on media, especially news articles, to understand sentiments’ role in stock price prediction (Li et al. [
23], Nguyen et al. [
1], Kalyani et al. [
48], Mohan et al. [
59]). They have explored sentiments’ impact on stock price prediction, employing slightly different sentiment extraction methods. Nevertheless, their common findings underscore the notable influence of sentiments on stock price prediction.
Likewise, our study aimed to enhance stock price predictions by incorporating sentiment analysis outcomes into our predictive models. Specifically, we extracted sentiments from The New York Times article summaries, as a representation of various media sources. This investigation allowed us to establish that the sentiment extracted from the summary of an article played an important role in predicting stock prices. By integrating sentiment analysis into our models, we achieved more precise stock price predictions. Our study highlights the crucial role of sentiments in improving stock price prediction methods, affirming the importance of the social atmosphere.
To ensure the consistency of sentiment analysis, we intentionally focused on using only one source, The New York Times, for sentiment extraction in our study. However, we acknowledge that employing different financial news media or data sources may lead to variations in sentiment analysis due to differences in word selection and content. Relying on a single news source limits the generalizability of our findings to broader market scenarios.
In future research, we aim to address this limitation by expanding our analysis to include various media outlets such as
The New York Times, Reuters, Yahoo Finance, and the Wall Street Journal (Chowdhury et al. [
60], Kalyani et al. [
48], Souma et al. [
61]). By incorporating data from diverse sources, we aim to explore the consistency and robustness of sentiment analysis across different platforms. This comparative analysis will provide valuable insights into the variations and potential biases that may arise from employing multiple news sources. Moreover, we intend to investigate the applicability of sentiment analysis beyond traditional news articles. For instance, we will explore the feasibility of extracting sentiments from individually authored content on platforms such as Twitter. According to Souza et al. [
62], exploring this approach could provide a distinct viewpoint on sentiments from the public or market participants, potentially enhancing our stock price prediction models with real-time sentiment data from social media. By expanding our scope to encompass multiple media sources and exploring unconventional data outlets, we aim to enhance the reliability and applicability of sentiment analysis in the context of stock price prediction, ultimately contributing to a more comprehensive understanding of sentiment-driven market dynamics.
In addition, our study’s main focus was evaluating how sentiments in articles influence stock price fluctuations. To achieve this, we concentrated solely on stock data and sentiment scores, omitting other potential impacting factors. The outcomes showed that article sentiment, particularly from the summary, notably influenced stock price prediction. Nevertheless, it is crucial to acknowledge that actual stock price movements can be driven by a multitude of factors, including macroeconomic indicators, company fundamentals, geopolitical events, and external shocks. Several studies have predicted stock prices by considering these indicators (Boyer and Filion [
63], Hussainey and Khanh Ngoc [
64], Al-Tamimi et al. [
65], Weng et al. [
66], Choi [
67], Umar et al. [
68]), and we plan to conduct a comprehensive analysis of their influence in our future research.
Furthermore, we chose the LSTM model for stock price prediction due to its suitability for sequential analysis. To validate this choice, we conducted a comparison experiment in
Appendix B using an alternative machine learning model for S&P 500 prediction. The results highlight the superior forecasting accuracy of the LSTM model. Similarly, Sethia and Raut [
69] found that LSTM outperformed GRU, ANN, and SVM models in stock price prediction. However, according to their findings, it is important to note that LSTM may have limitations in handling extreme price drops or rapid price spikes when used as a single model. To address this limitation, our future research will explore and compare the predictive capabilities of various machine learning models when incorporating sentiment scores into the prediction process. Furthermore, although we used FinBERT for the sentiment analysis process in this study, we propose as a future study to calculate the sentiment score of summary data using the lexicon-based approaches (SentiWordNet, a sentiment-dictionary, and VADER) methodology.
Finally, we conducted sentiment analysis using summary data from New York Times articles, a more efficient approach than analyzing the entire article body due to reduced data volume. Summaries capture essential content in a few sentences. While summary data saves space, it might not encompass all article details. Hence, comparing predictive performance between models analyzing full articles versus summaries is crucial. Furthermore, optimizing effective article summarization without losing sentiments is one of the future research topics.
7. Concluding Remarks
Stock price prediction is a field in which active research is continuously being conducted. This study investigated the impact of news sentiment on stock prices. We collected summary data from The New York Times website and compared the accuracy of stock price predictions with and without sentiment analysis results. Our target stock price index was the S&P 500, and we used five-year data (2018–2022). Our study differs from previous studies in two ways. First, we did not restrict ourselves to financial articles, but instead used data from articles on various fields that were available on the Front Page of The New York Times. The collected text data were subjected to sentiment analysis using the FinBERT model specifically designed for the financial domain. Second, we used article summaries on The New York Times rather than full article texts. For the prediction model, we employed an LSTM model optimized using a random search method.
The main contributions of this study are as follows: First, we conducted a sentiment analysis on the collected news data. Stock prices were predicted using two datasets that were distinguished by the presence or absence of sentiment analysis results. The stock price we predicted is S&P 500, and an LSTM model tuned using the Random Search method was used for the prediction. As a result, the MSE, RMSE, and MAE of the model that included the sentiment analysis result were significantly reduced compared to the model that did not. Through this, we were able to confirm that the sentiment of the news affects the prediction of the stock price. Similar results can be found in the existing literature on sentiment analysis and news on stock prices, such as Heston and Sinha [
70] and Wang et al. [
8]. Moreover, the model incorporating sentiment scores shows a higher
value, indicating a strong fit. This suggests that utilizing sentiment analysis enhances stock price prediction accuracy. These results emphasize sentiment’s significance in finance, providing insights for better risk management and informed investment strategies.
Second, we used FinBERT for the sentiment analysis of news. As previously explained, FinBERT is a BERT model trained based on finance-related news data and contains the characteristics of the finance domain. In Araci [
45], it was found that FinBERT outperformed other techniques such as ELMo and ULMFit even with only 500 training sets in the financial domain. They also found that it could solve the data shortage problem even with a small amount of data. Costola et al. [
9] also used FinBERT to analyze sentiments and found a significant relationship between stock return and sentiment. We also performed sentiment analysis on the summary data of
The New York Times using FinBERT and found a relationship between the result and the stock price.
Third, by performing sentiment analysis using summary data, the size of data was reduced compared to using full news. The study is meaningful because it produced results similar to those of other studies that used full articles. Although summarizing the articles reduced the amount of text data, the subjects and sentiments that the articles aimed to convey were not lost. In addition, among the words that appear in the text, it was determined that meaningless words or expressions that could interfere with sentiment analysis would have been removed. Therefore, the results show that we can predict stock prices using the sentiments extracted from summary data. Using summary data can significantly reduce the amount of data and analysis time, with results similar to those that use full texts of the articles. This is important, particularly for time-consuming sentiment analyses.
Our study revealed that incorporating sentiment analysis results from news data into a stock price prediction model improves prediction accuracy. This finding implies that stock market movements are related to sentiments. This allows investors to use sentiment analysis as a way to bring higher returns. Furthermore, this study provides further research possibilities for various sentiment analyses. Numerous studies have employed sentiment analysis across various domains. For example, Daniel et al. [
71] explored Twitter users’ sentiment in response to events by companies such as Apple, Microsoft, and Walmart. Hasselgren et al. [
72] proposed a method recommending stocks based on sentiment trends extracted from Twitter. Sun et al. [
73] analyzed sentiments on the Guba platform to anticipate bear markets. Wu et al. [
74] highlighted sentiment’s efficacy in predicting small-size company stock prices. In Wang et al. [
75], sentiment analysis predicted fundraising results from online comments. Kauffmann et al. [
76] improved product recommendations through Amazon reviews’ sentiment classification. In addition, our research allows companies to identify the relationship between sentiment and stock prices and manage their stock prices using sentiment analysis of news. As an example of corporate management, Suunto, a Finnish outdoor company, employed sentiment analysis to manage negative feedback during a product launch, preserving brand integrity (“10 Sentiment Analysis Examples That Will Help Improve Your Products”, 15 November 2018, Wonderflow,
https://www.wonderflow.ai/blog/sentiment-analysis-examples/#examples (accessed on 1 August 2023)).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









