1. Introduction
The notion of a fuzzy transform (F-transform) as a tool for modeling with fuzzy rules as specific transformation and for general approximation of functions has been introduced by Perfilieva in [
1] (see also [
2]) and is now recognized as a powerful technique with important properties and potentials for various applications, as developed in several papers and special issues (see, e.g, [
3,
4,
5] and the references therein).
In the present paper, we will focus on the use of quantile and expectile F-transform (and, more generally, on
-norm-based fuzzy-valued F-transforms) in modeling time series. In particular, we will show the application of direct and inverse
-norm F-transform to analyze the connection between Bitcoin returns and the level of interest in the world wide web. The Bitcoin observed time series is modeled through fuzzy-valued functions, whose level-cuts can be interpreted in the setting of expectile and quantile fuzzy regressions; these last are introduced in [
6,
7] as non-parametric smoothing methodologies and are constructed by defining fuzzy-valued
-norm extensions of the F-transforms (in particular, expectile or
-norm and quantile or
-norm).
Quantile regression is also applied in [
8] to show that Bitcoin reacts positively to uncertainty at both higher quantiles and shorter frequency movements of Bitcoin returns.
Following recent research on financial time series, where the properties of quantile and expectile modeling are discussed with respect to coherent and elicitable risk measures (see [
9,
10]), expectile methods seem to compete favourably with quantiles; furthermore, some recent papers (e.g., [
11]) suggest to adopt
-norm-based procedures with
p between 1 and 2 (e.g.,
), in order to consider (probabilistic) tail behaviour according, e.g., to robust Extreme Value Theory.
Literature about Bitcoin has hugely grown in recent years and some papers deserve a citation. An exhaustive analysis of Bitcoin and its statistical properties are explored in [
12] by a comparison with standard currencies dynamics. Yermack in [
13] shows that Bitcoin does not satisfy the three main properties called medium of exchange, unit of account and store of value, concluding that it is not a currency but rather a speculative asset. However, a debate is still open about the nature of Bitcoin and many hints can be found in [
14,
15,
16]. A shared property by financial instruments is the day-of-the-week effect and in [
17] the same effect is proved for Bitcoin returns and volatility through OLS and GARCH model. The possibility of global economic policy uncertainty to produce valid information to improve the prediction of returns and volatility in the Bitcoin market is detailed in [
18].
Research on possible forecasting models to be used as decision support tools in investment strategies is more recent; in [
19], monthly data are considered and it is shown that the predictive ability of the internet-based economic uncertainty related queries index is statistically stronger than the measure of uncertainty derived from newspapers in predicting Bitcoin returns.
The nexus between Bitcoin prices and market sentiment is further studied in many papers: in [
20] sentiment is shown to explain about 2.5% to 5% of the unusual level of price clustering in Bitcoin. In [
21] the cross-correlations between Google Trends and Bitcoin market is analyzed through the Multifractal Detrended Cross-correlation Analysis (MF-DCCA) method and in [
22], within the more general context of Dow Jones Industrial Average, it is shown that Google searches are power-law correlated with Hurst exponents between 0.8 and 1.1; the authors conclude that globally on time domain, there is no relationship between the on-line search queries and some financial measures. In [
23] investor sentiment regarding Bitcoin is introduced because of its significant information for explaining changes in Bitcoin volatility for future periods; on this basis Bitcoin is proved to be an investment asset with high volatility and dependence on investor sentiment rather than a monetary asset.
In a more general framework, in [
24], interactions between (mass) media reporting and financial market movements are measured with particular focus on the property of sentiment as a predictors of securities prices.
The existing high correlation between Bitcoin prices and Google Trend scores is discovered and documented since the origins of digital currencies (see, e.g., [
25]) and several pieces of research have discussed about its characteristics (see [
26]) and about predicting prices using sentiment analysis (see references numbered from 23 to 27 in [
26]). On the other hand, there is evidence that a bi-directional causal relationship exists between Bitcoin web-attention and Bitcoin returns, in particular for data in the left tail (poor performance) and the right tail (superior performance) of the observed statistical distribution (see [
27]).
A non-parametric forecasting model based on technical analysis is presented in [
28], focusing on the presence of predictive local non-linear trends that reflect the speculative nature of cryptocurrency trading. In [
29] a computational intelligence technique that uses a hybrid Neuro-Fuzzy controller is introduced to forecast the direction in the change of the daily price of Bitcoin and its performance is shown to be good when compared with two other computational intelligence models based on a simpler neuro-fuzzy model and an artificial neural network.
Forecasting of Bitcoin risk measures is developed in [
30] by comparing predictability of the one-step-ahead volatility with Value-at-Risk using several volatility models.
Many other authors approach general cryptocurrency properties. For example, in [
31] there is evidence that Bitcoin is the most influential among digital coins both as a transmitter toward digital currencies and as a receiver of spillovers from virtual and traditional instruments. An extended analysis is also presented in [
32] where the four cryptocurrencies Bitcoin, Ethereum, Ripple and Litecoin are predicted through a combination of eight models revealing that a combination of stochastic volatility and a student-t distribution gives the best results. The same topic of Bitcoin-realized volatility forecasting is studied in [
33] where conventional regression models are substituted by least-squares model-averaging methods and no investor sentiment is modeled.
In [
34,
35] a continuous time model for Bitcoin price dynamics is studied to detect bubbles; regarding the existence of a bubble, in [
36] it is proved it holds from early 2013 to mid-2014, but, not in late 2017 as supposed. Evidence of bubbly Bitcoin behaviour, mainly in the 2017–2018 period, is shown in [
37], where it is also proved that economic policy uncertainty and stock market volatility play the most important role in Bitcoin values.
The evidence for the Bitcoin bubble is confirmed in [
38] through the empirical validation of three properties: volume of trading is mainly explained in terms of price dynamics, trading is based exclusively on past prices and the price of Bitcoin is an explosive process.
In [
39] a thorough analysis is conducted: several alternative univariate and multivariate models for point and density forecasting of crypto-series are compared, finding statistically significant improvements in point forecasting when using combinations of univariate models, and in density forecasting when relying on the selection of multivariate models.
Various deep learning-based Bitcoin price prediction models are studied in [
40] using Bitcoin block-chain information; regression and classification problems are addressed in the sense that the first predicts the future Bitcoin price and the second one predicts whether the future price will go up or down.
In the case of Bitcoin prices using high frequency data, in [
41] it is shown that it exists a large degree of multi-fractality in all examined time intervals which can be attributed to the high kurtosis and the fat distributional tails of the series returns; in [
42] there is evidence about the leverage effect as the most powerful effect in volatility forecasting; volatility is also analyzed in [
43] in terms of the property of the long memory parameter to be significant and quite stable for both unconditional and conditional volatilities at different time scales. Extending the study to several high frequency cryptocurrencies data, in [
44] the investigation on stylized facts is developed in terms of the Hurst exponent of dependence between four different cryptocurrencies.
Also in [
45] multi-fractality of Bitcoin time series is investigated, confirming that both temporal correlation and the fat-tailed distribution are the main sources, in addition in [
46] a possible use of multi-fractal parameters in Technical Analysis is suggested.
The paper is organized into six sections. Preliminary facts on our methodology concerning F-transform are presented in section two. Our empirical experiments and analyses concerning Bitcoin prices and Google Trend scores are detailed in sections three and four: in section three, we apply the expectile and quantile (inverse) F-transforms to both time series and we examine their relationship on pre-clustered subsets of observations, subdivided in terms of three different clustering criteria; in section four we identify stylized facts for Bitcoin prices, based on local (low-order polynomial) trends obtained by direct F-transform, we study their clustering to obtain (centroid) typical forms and we use them to reconstruct the time series and to analyze their time evolution in terms of a transition matrix. Possible short-term forecasting models of Bitcoin prices using Google Trends are shown in section five and the Diebold–Mariano (DM) test statistics is applied for their significance. Section six closes with some comments and hints for future research paths.
2. Fuzzy-Transform Smoothing
We introduced in [
47] and then we enhance in [
6] two non-parametric smoothing methodologies called expectile and quantile fuzzy-transform; the first one is based on the classical direct F-transform and it is obtained by minimizing a least-squares (L
2-norm) operator while the second one is based on the L
1-type direct F-transform and it is obtained by minimizing an L
1-norm operator.
Some preliminary notions compose the research framework: a fuzzy set is a mapping and a fuzzy interval is a fuzzy set on with the properties that the mapping u is (i) normal ( with ), (ii) upper semi-continuous, (iii) fuzzy convex ( for all ), (iv) is a compact interval. A consequence of (ii) and (iii) is that the α-cuts are compact intervals for all . The 1-cut is the core of u; the interval is the 0-cut of u. A fuzzy interval is a fuzzy number if its core is a singleton with .
The space of real fuzzy intervals is denoted
and the mapping
satisfies what follows:
For a given real compact interval
, a generalized
r-partition is defined by a triplet
where
is integer,
,
, is a uniform decomposition of
; for simplicity of notation, if
we extend
by adding
points
on the left of
a and
points
on the right of
b. The second term of the triplet is a family
of
continuous fuzzy sets on
, called
basic functions, that satisfy the following condition for all
and are such that
, for
,
for all
.
If , the partition will be simply denoted by .
Families of basic functions can be obtained in terms of increasing shape functions such as rational splines of the form
with real parameters
,
; the Hermite-type conditions
,
,
,
are satisfied and
for all
. By any pair of non-negative values
,
, a large number of shape functions can be generated; for example, if
(with
,
) we have a quadratic function
, e.g.,
,
and
is linear.
Each basic function , , increasing on and decreasing on , is obtained by translating and from onto and , respectively (each is finally extended to by setting on the left of and on the right of ).
2.1. L2-Norm F-Transform in Expectile Smoothing
We just recall the discrete version of the direct F-transform.
Definition 1. (from [1]) Given a set of m values of a function and a fuzzy partition of such that each subinterval contains at least one point in its interior (so that for all k), then the discrete direct -type F-transform of with respect to is the n-tuple of real numbers where each component minimizes the function , . The associated inverse F-transform function (iF-transform for short) is defined by for all . More generally, we consider a
r-partition
and substitute the direct F-transform components
, with an
-tuple of polynomials of order
, say
with
,
. The
coefficients
are obtained, for fixed
k, by minimizing the function
with respect to the parameters
, under the assumption that for each
k, the data points
with
in the interval
produce a unique optimal solution. The details are shown in [
6].
The corresponding (inverse) iF-transform function is given by
Consider for simplicity the F-transform of order zero ().
The iF-transform function becomes
with the
-tuple of the direct F-transform
.
We recall from [
6] that the
expectile direct F-transform components are defined to be the minimizers of the strictly convex functions, for
and
,
where
The value
(depending on ω) is the expectile for the asymmetry parameter
and if
we obtain the direct F-transform component
in Equation (
5).
Proposition 1. ([6]) Given the set of minimizers of , consider ; then the compact intervalsdefine the α-cuts of a fuzzy numberwith membership function Definition 2. Given a set of m points , and a fuzzy r-partition of , the ()-vector of fuzzy numberswhere each fuzzy interval has α-cuts given by (8) in Proposition 1, is called the discrete direct expectile fuzzy-valued F-transform of f with respect to , based on the dataset Y. The corresponding inverse expectile fuzzy-valued iF-transform is the fuzzy-valued function defined by The fuzzy-valued function
is well defined as indeed each basic function
has non-negative values for each
. The
-cuts
of
will be denoted by
and the
-cuts of the fuzzy-valued function
,
, will be given by
When we obtain the standard direct transform and the standard transform function, corresponding to the core of the fuzzy-valued iF-transform.
2.2. L1-Norm F-Transform in Quantile Smoothing
The L1-norm direct and inverse F-transform are defined as follows.
Definition 3. Given a set of m values of a function and a fuzzy partition of such that each subinterval contains at least one point in its interior, then the discrete direct -type F-transform of with respect to is the n-tuple of real numbers where each component minimizes the function , . The associated inverse F-transform function (iF-transform for short) is defined by for all .
Also in this case, we consider a generalized
r-partition
and substitute the direct F-transform components
with an
-tuple of polynomials of order
, say
with
,
. The
coefficients
are obtained, for fixed
k, by minimizing the function
with respect to the parameters
(see details in [
6]).
The corresponding
-type inverse F-transform function is given by
The iF-transform function of order zero (
) becomes
with the
-tuple of the
-type direct F-transform
.
We recall from [
6] that the
quantile direct F-transform is defined in terms of the minimizers of the convex functions, for
and
,
where
As detailed in [
6], the minimization of
produces the family of compact intervals, for
and
,
and we obtain the
-cuts of a fuzzy number
with membership function
Definition 4. Given a set of m points , and a fuzzy r-partition of , the ()-vector of fuzzy numberswhere each fuzzy interval has α-cuts , is called the discrete direct quantile fuzzy transform of Y with respect to . The corresponding (inverse)
quantile iF-transform of
f is the fuzzy-valued function defined by
Denoting the
-cuts
of
by
then, the
-cuts of the corresponding fuzzy-valued function
,
, will be given by
2.3. General Lp-Norm-Based Discrete F-Transform
The general
-norm-based F-transform has been analyzed in detail in [
48] for the continuous case. Its interest in time series applications is motivated by recent literature on tail behaviour of economic and financial time series (see, e.g., [
11]) and in modeling risk measures ([
9,
10]):
-norm estimation with
has been suggested to balance robustness and fitting properties.
For a dataset of m values and a generalized r-partition , the -norm direct F-transform is an -tuple of polynomials of order with , , where this time, the coefficients , are obtained by minimizing the functions with respect to the parameters .
If
, the direct fuzzy-valued F-transform components, for a fixed
, are obtained by minimizing the strictly convex functions, for
and
,
where
The minimizers
(depending on
) define the
-norm direct F-transform components for the asymmetry parameter
. We have (the proof is similar to the case
in [
6])
Proposition 2. Given the set of minimizers of , consider ; then, the compact intervalsdefine the α-cuts of a fuzzy number with membership function Definition 5. Given a set of m points , and a fuzzy r-partition of , the ()-vector of fuzzy numberswhere each fuzzy interval has α-cuts given by (26) in Proposition 2, is called the discrete direct -norm fuzzy-valued F-transform with respect to , based on the dataset Y. The corresponding inverse -norm fuzzy-valued iF-transform is the fuzzy-valued function defined by The
-cuts
of
will be denoted by
and the
-cuts of the fuzzy-valued function
,
, are
When we obtain the -norm direct F-transform and (inverse) iF-transform function, corresponding to the core of the fuzzy-valued -norm iF-transform.
3. Analysis of Bitcoin Prices and Google Trends by F-Transform
To focus on the strength of fuzzy-valued -norm F-transform smoothing, we will apply the proposed models to the time series of Bitcoin prices, which has received much attention by regulators and investors in the last decade.
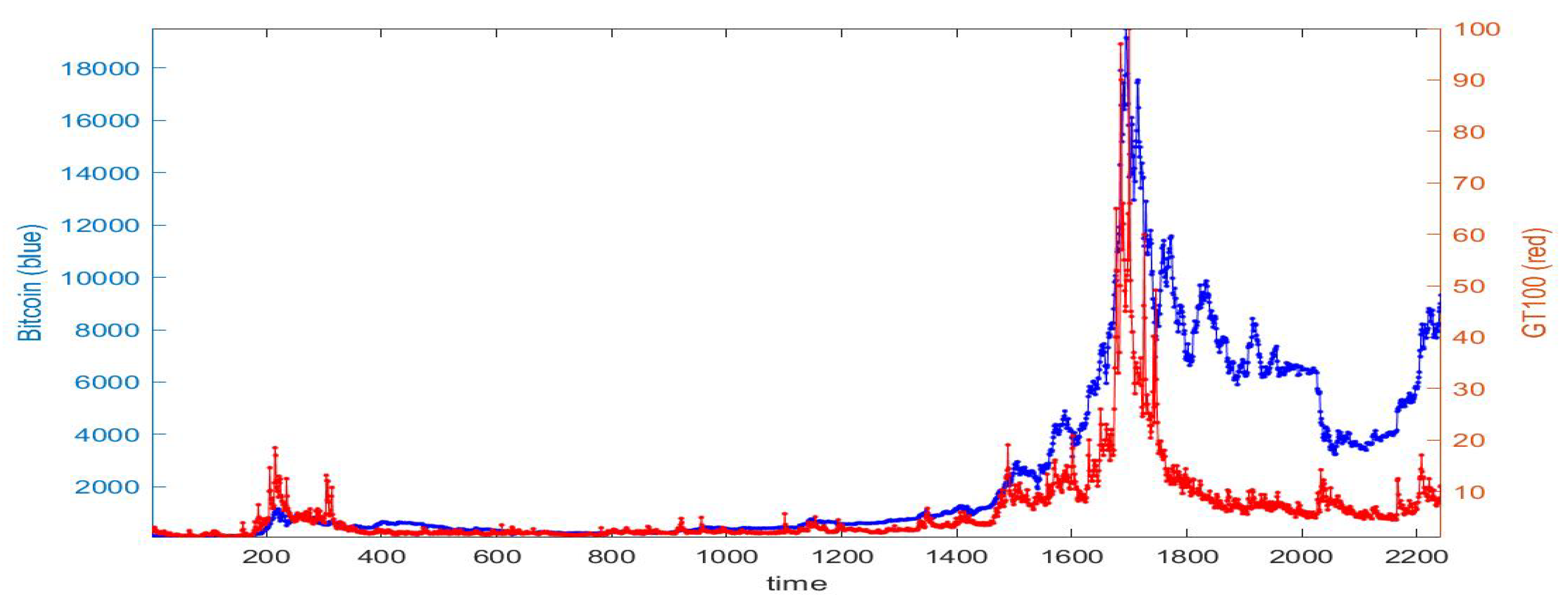
Bitcoin was released at the beginning of 2009 as a digital currency in the market; it remained under $0.20 for three years and it began to increase during the first quarter of 2013. By the end of 2017, Bitcoin was valued at nearly $18,000 per “coin”. In 2018, the price plummeted $4000 and it grew again in 2019.
The second dataset we consider is Google Trends, the search index that measures what people are currently interested in and curious about. In particular, we consider Google Trends with value 100 out of 100 meaning that trend (word Bitcoin) is on its peak in the considered time period.
Here, we work on two daily time series, as in
Figure 1, from April 2013 to June 2019: Bitcoin prices (from www.blockchain.info) and Google Trends (from
https://trends.google.com). The label
time in the figures refers to daily observation number (t = 1 corresponds to the first observation considered); the labels Bitcoin and
GT100 denote the arrays with the data.
Remark that the F-transform (direct and inverse) is linear with respect to the data-set, in particular it is homogeneous and scale invariant: we can normalize the two time series and the direct F-transform components (or the iF-transform function) are multiplied by the same factor. In this way, we can compare the F-transform results for the two series in terms of the obtained smoothing effect and by visualizing the scatter-plots of the of each series and the obtained iF-transform reconstructions.
The
degree of smoothness of a given time series
,
is measured in terms of its (average) absolute variation, given by
on the other hand, it is well known that the inverse
-norm F-transform function, for a fixed
r-partition
, allows the computation of the smoothing values
corresponding to the estimated (local) polynomials of order
q,
,
. The corresponding absolute variation, given by
is in general smaller than
; the ratio
represents the proportion of absolute variation which remains in the smoothed time series
with respect to the original data
f, while
is the amount of removed variation.
We have computed the
-norm F-transforms for different values of
and orders
. The excellent performance of the smoothing based on F-transform are strongly confirmed for these two special time series, as summarized in
Table 1 and
Table 2.
All computations are performed with a 1-partition (), a decomposition of into equispaced nodes and basic functions obtained from , . For both series, covering the same time period, we have so that each subinterval , of has exactly 8 observations (13 observations internal to intervals , on which basic function is non-zero); remark that the two series are observed all days of the week, including holidays, so that all internal nodes of correspond to the same day in the week.
For the results of
Table 1, the observed values are normalized in the range
; on this common range, the computed absolute variations are
and
and Bitcoin is
less
fluctuating (on average) than GT100. For all values of
p, the reduction in total variation expressed by the ratios
, for both series, is more depending on the order
q than on the used norm
; this is not surprising, because increasing the degree of local polynomials will reduce the average fitting errors but increase their variation.
In
Table 2 the smoothing and fitting of the time series by
-norm F-transforms are compared in terms of three well-known indices: the mean square error MSE, the mean absolute percentage error
and the Kendall
rank correlation.
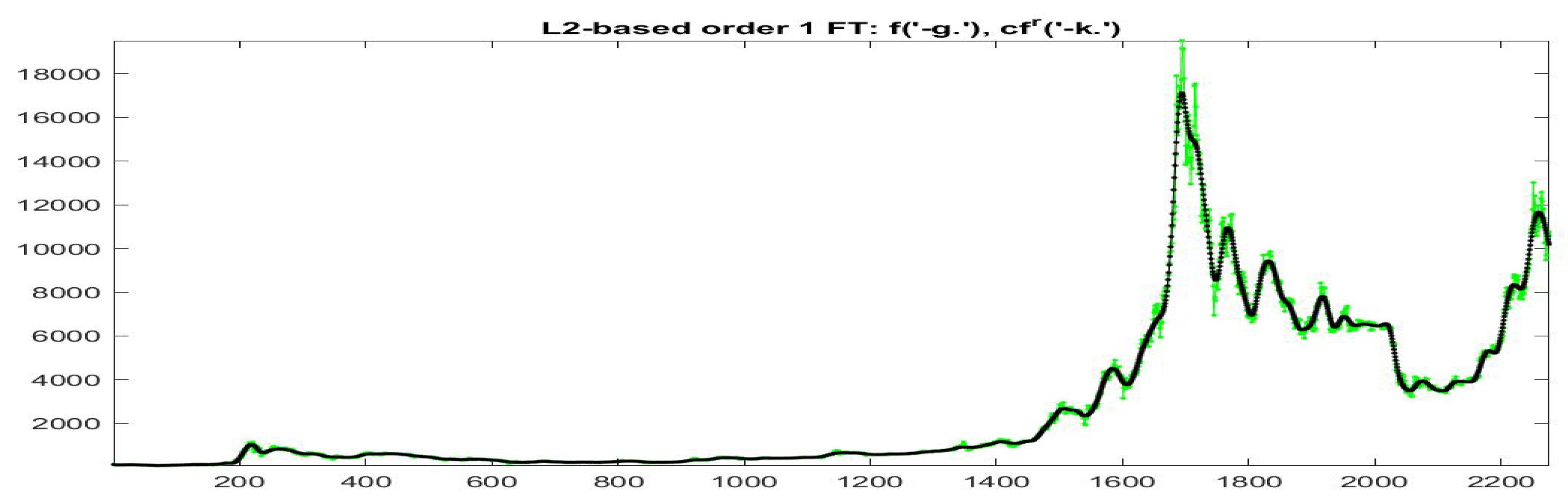
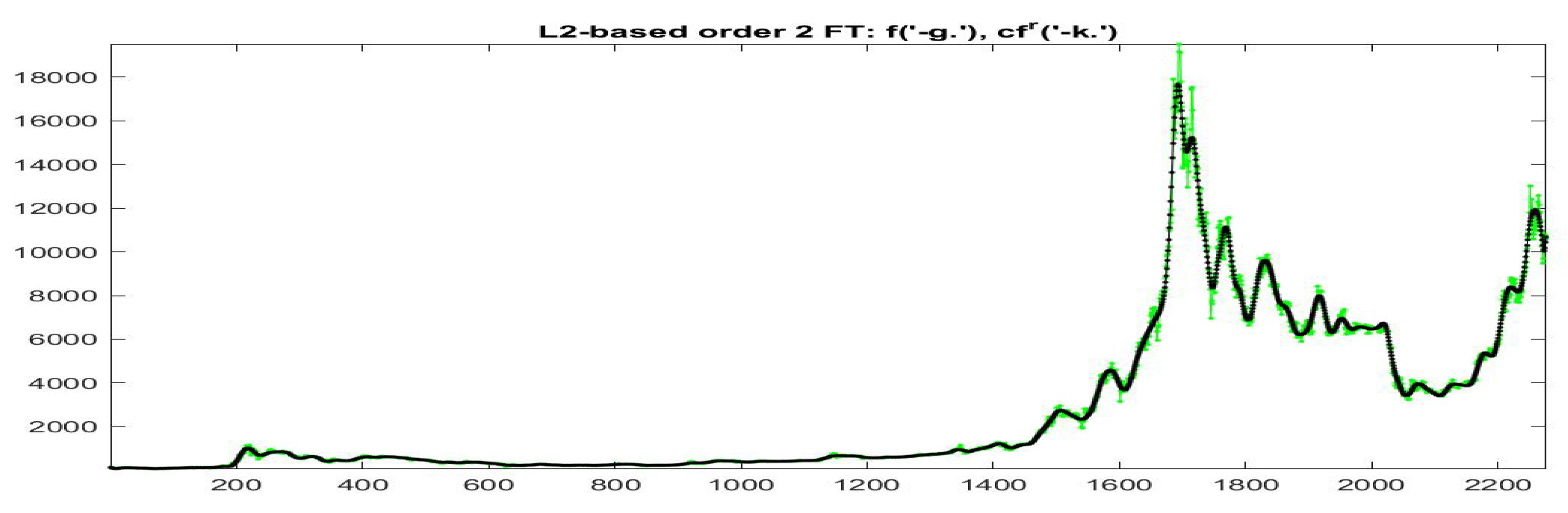
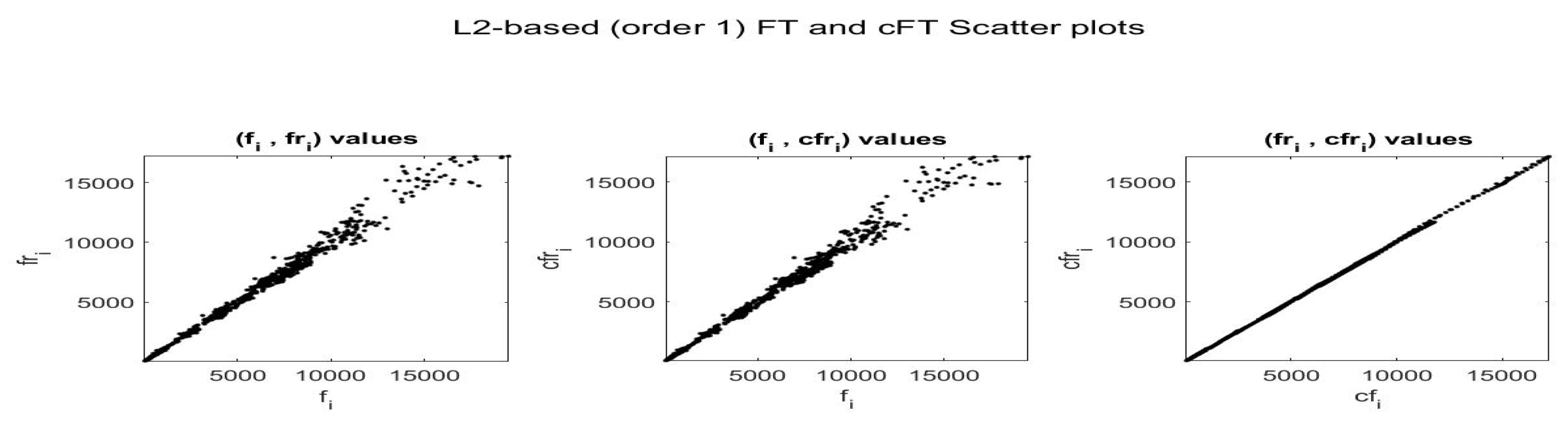
Here the series are not normalized (in particular, the value of index depends on the scale of the series). In all cases, the F-transform fitting for Bitcoin series has significantly smaller errors than for GT100, as demonstrated by indices and (the Kendall is always significantly positive with p-value less than ).
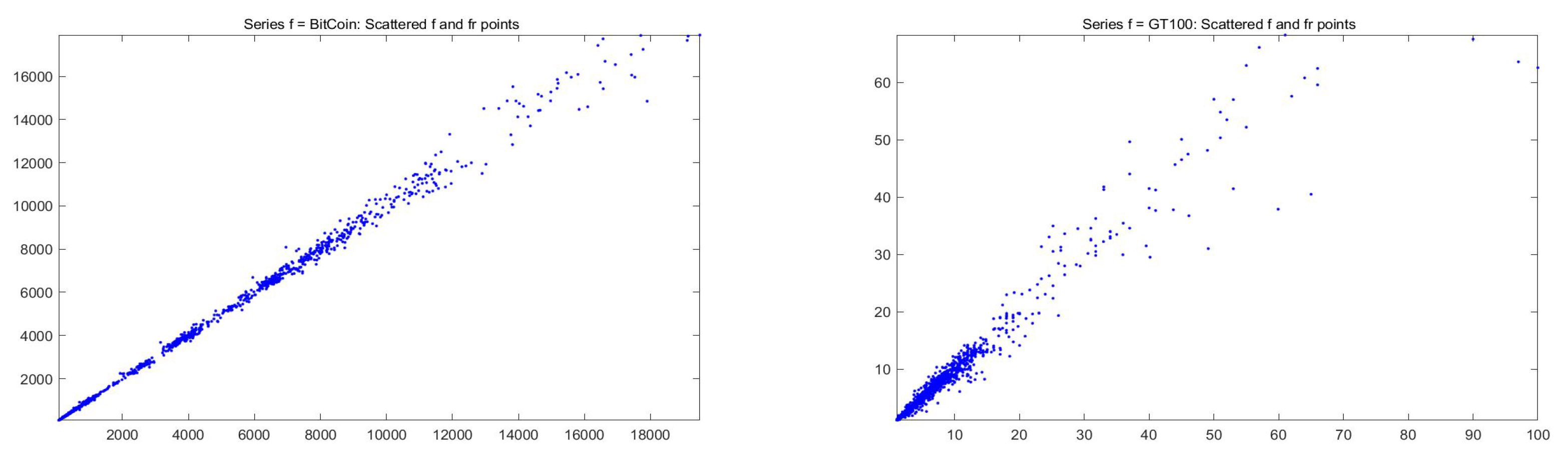
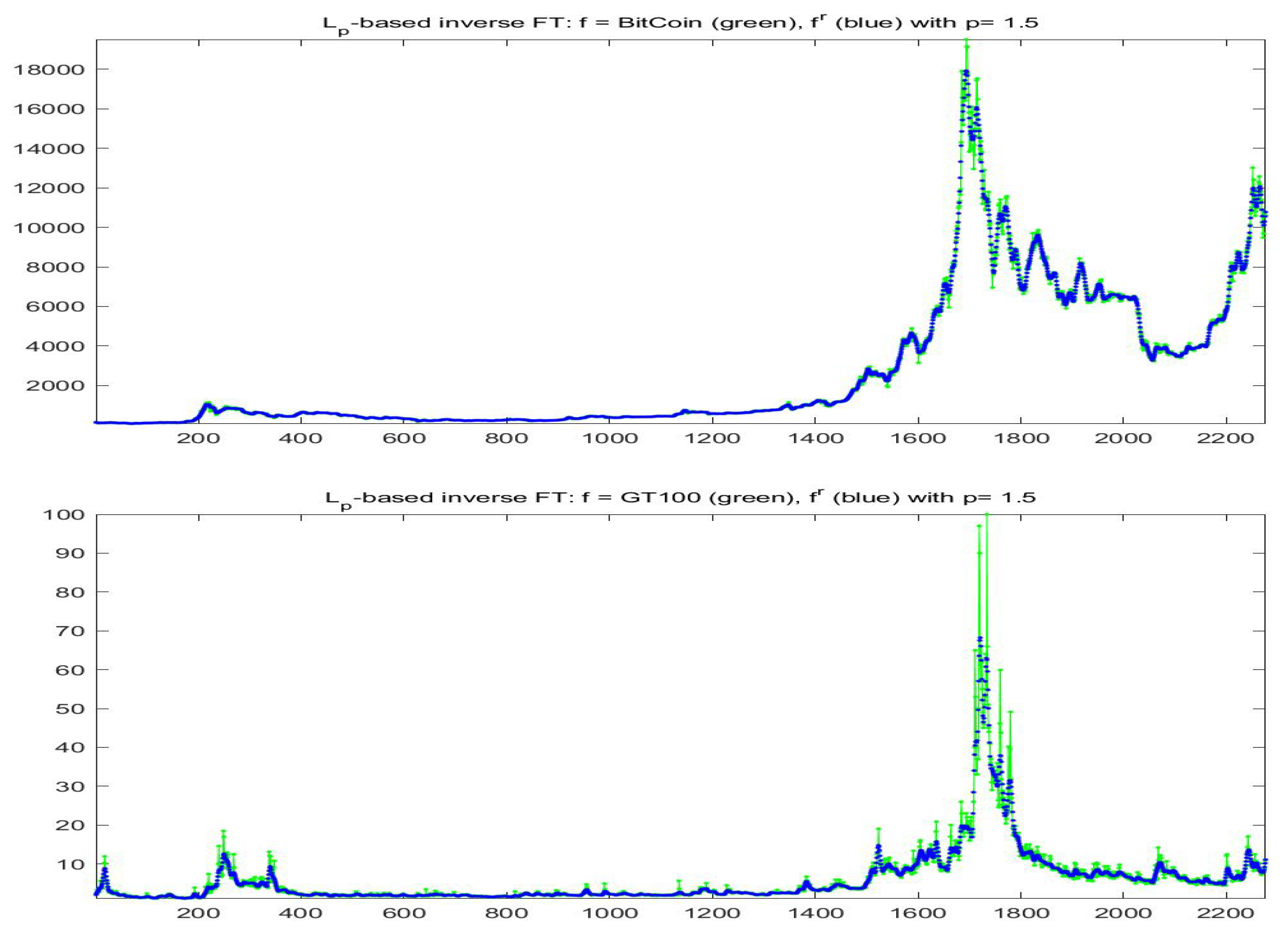
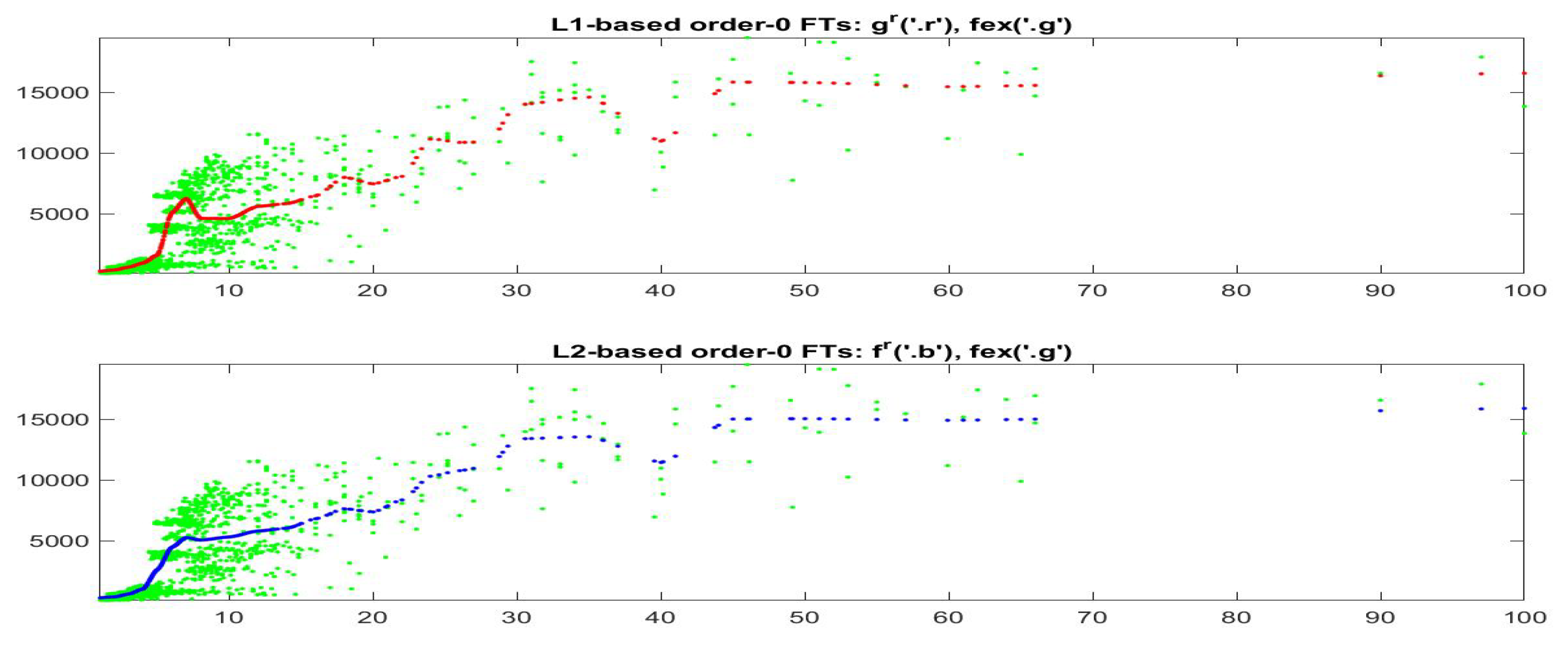
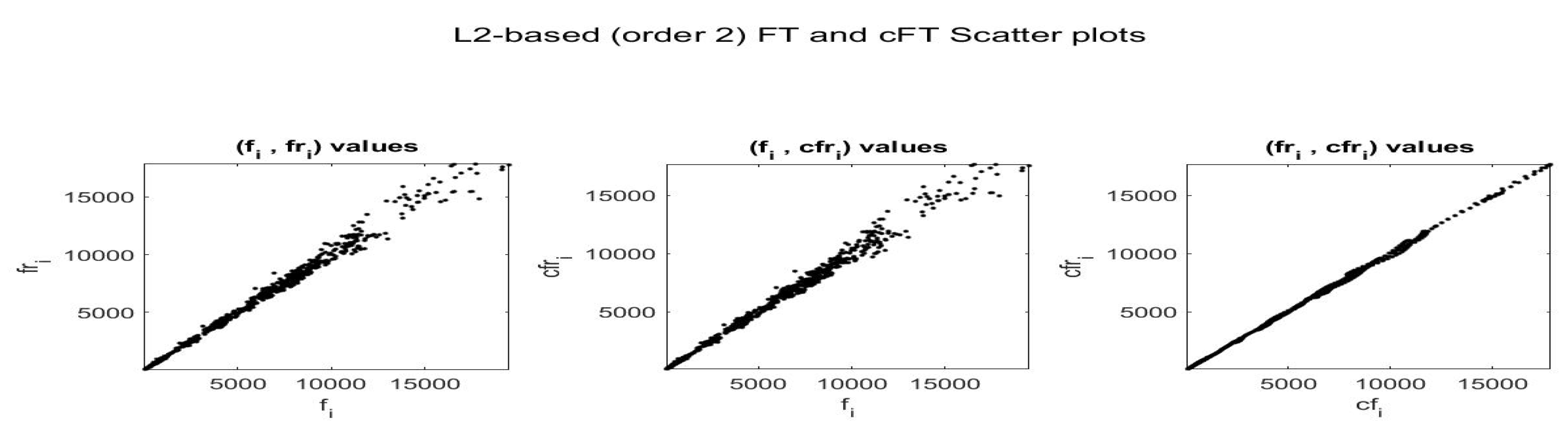
For the fitting F-transform functions obtained by
-norm with
and
, the scatter-plots of time series
are pictured in
Figure 2;
Figure 3 plots
and
with respect to time. Remark that peaks in the series tend always to be smoothed, as a characteristics of the smoothing effect produced by F-transform.
Assuming a bi-directional dependence between
and
time series, empirically demonstrated, e.g., in [
27], and focusing on the impact of
on
, we want now to investigate the form of dependence by use of expectile (fuzzy-valued) F-transform; in particular, we see that while the fitting of iF-transform obtained on the totality of observed values
presents a high dispersion, a very big improvement in the fitting quality is obtained if F-transform is applied to clustered subsets of observed data. A relatively small number of clusters (from 20 to 24) in sufficient to obtain a fitting with correlation coefficient greater than
.
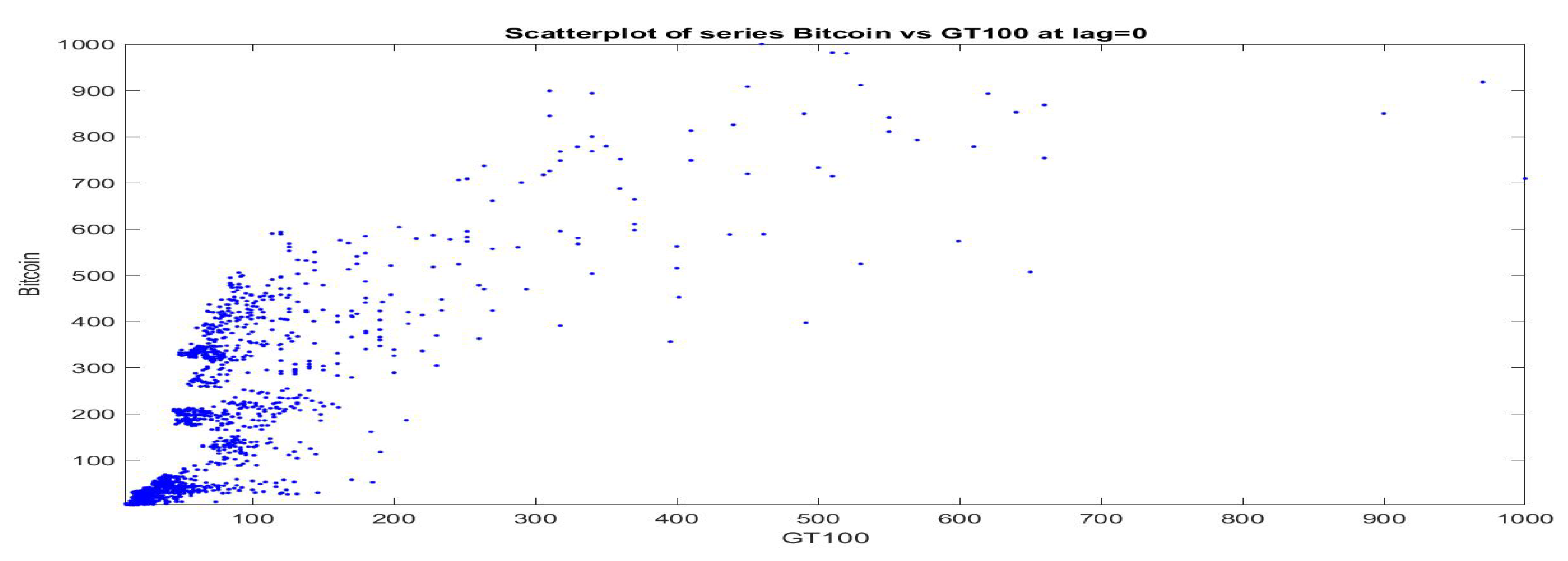
First of all, a scatter plot of the pairs is pictured in
Figure 4 (the two time series are normalized in the range
and GT100 appears in horizontal axis); observations in our data-set cover the cited time period 2013–2019, are concentrated on the bottom-left part of the positive quadrant and have rare points with big values in both series. At a first look, no evident functional relationships emerge from the data; they simply show a tendency to be co-monotonic, but the points are very sparse.
For a deeper analysis, we propose a model based on F-transform, relating the pairs of data
. F-transform is thus used to model BitCoin as a function of GT100. The
-norm and
-norm-based inverse iF-transforms of the data-set
are computed; taking into account the sparsity of the values
(in particular above the threshold 40), we use a non-uniform 1-partition
of the range
of the observed
, namely the set of 25 nodes
, as pictured in
Figure 5. The two curves give the predominant relationship between
and
. It is evident that both iF-transforms of
are not increasing on the whole range of
(in particular, they decrease when GT100 is around 7–8, around 20 and 40). On the other hand, observing the dispersion of points in
Figure 4, both iF-transforms are not good fitting of the complete data-set and it appears that the points can be “clustered”, e.g., for different levels of Bitcoin prices, and better sub-fittings can be attempted.
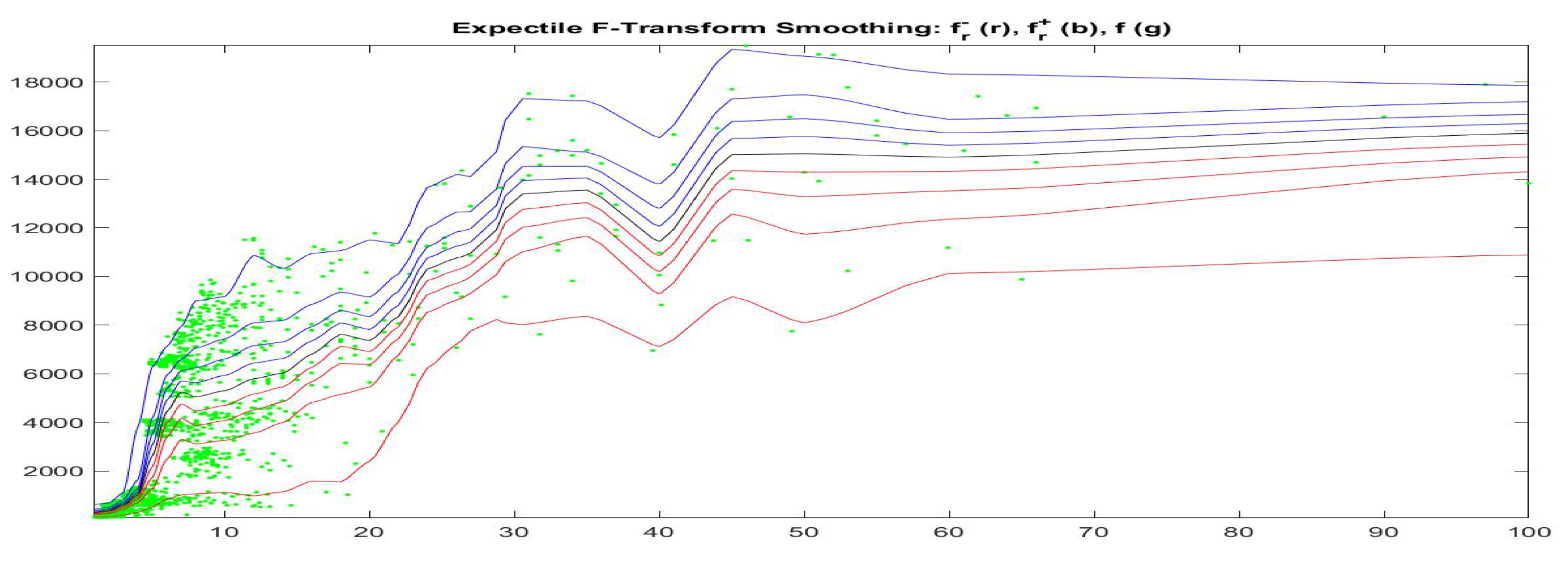
This can be better analyzed by applying the quantile and the expectile F-transforms to our data-set
, pictured in
Figure 6, which shows the fuzzy-valued expectile F-transform of Bitcoin as a function of GT100 for five different
-cuts corresponding to
(i.e., ten values
for the asymmetry expectile parameter
).
We see that corresponding to different values of , i.e., corresponding to subintervals in the range of Bitcoin prices, the relationship between our time series changes significantly.
This suggests that possibly, the clustering of the data into subsets may significantly improve the quality of fitting.
Clearly, there are several procedures and criteria to cluster the observed data ; we use the well-known k-means method and the number of clusters is selected according to the silhouette measures available in MATLAB R2018b. We have performed three types of clusters, the first on the basis of variable , the second using the pair and the third using observations where is the first difference operator . The clustering measure is the standard Euclidean distance.
Let denote the number of clusters and let be the labels of cluster . Each observation is assigned to cluster , i.e., the observation t is assigned to cluster labelled .
For a given clustering, identified by clusters
, the
-norm-based F-transform is applied (independently) on each subset of data, for
,
Finally, for the observations of each cluster, the inverse iF-transform is computed and the fitted values, for each cluster, are obtained and recomposed to obtain the fitted values for the whole dataset.
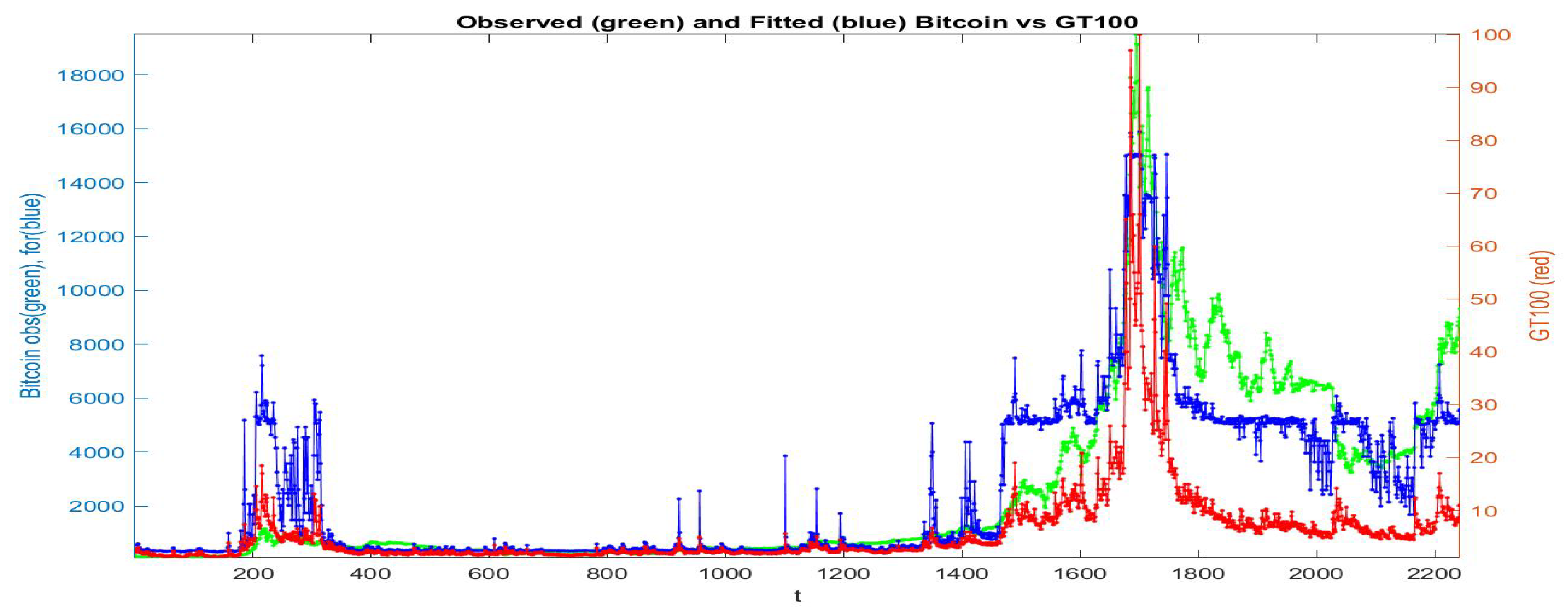
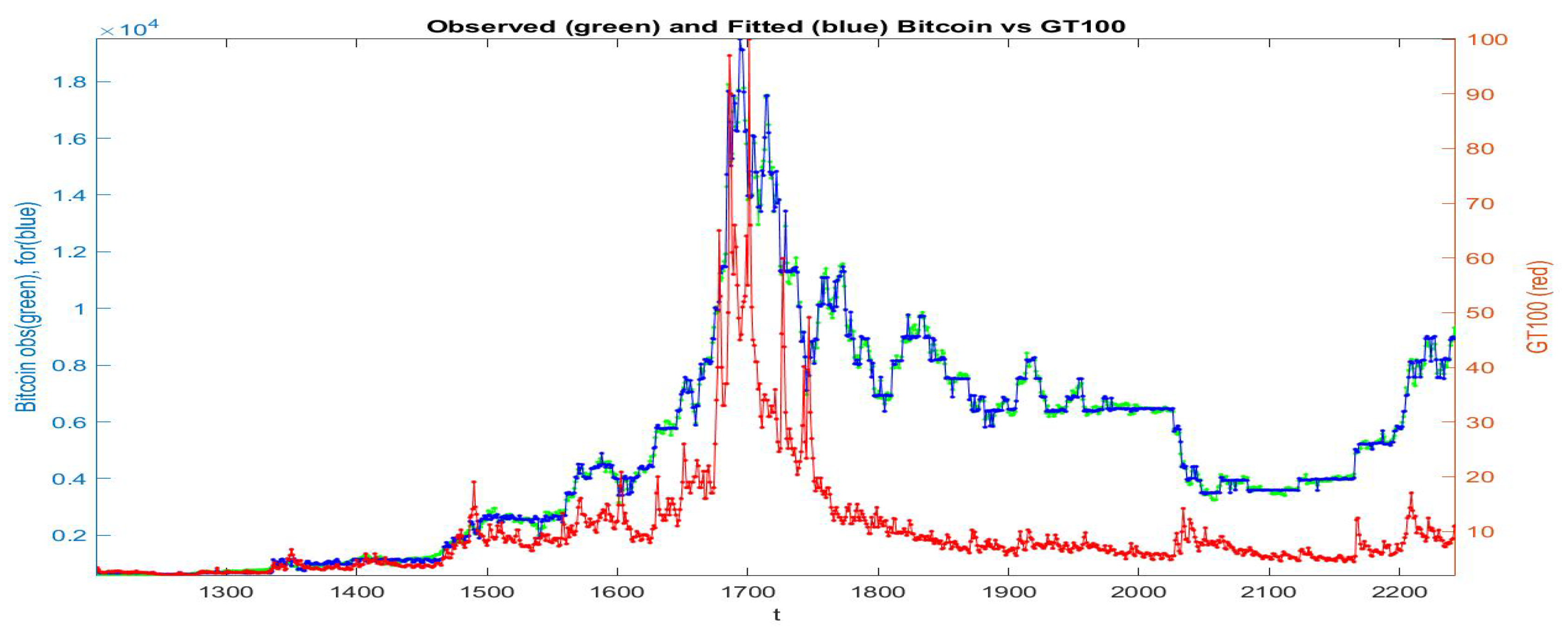
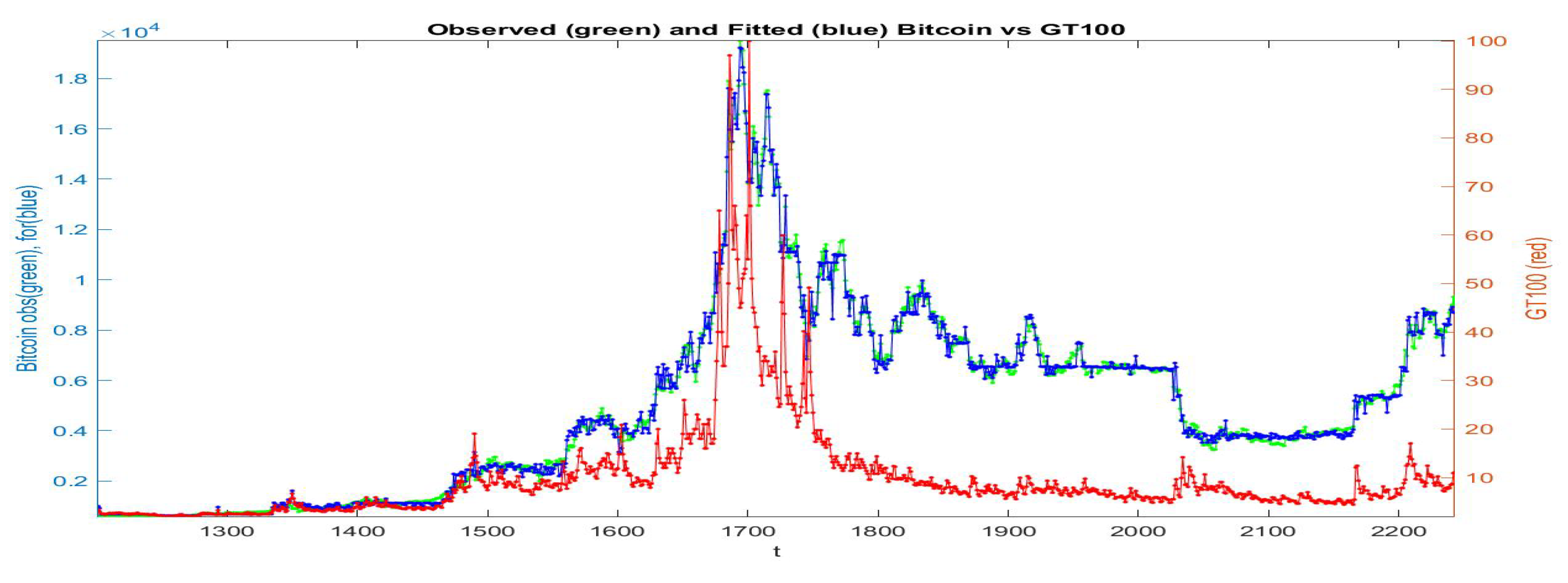
If all the data are collected in a unique cluster and the F-transform is applied to the whole data-set, we obtain the fitted
series pictured in
Figure 7: the green points give the observed
, the red points are the
series and in blue is the fitting of
. We see that the fitting preserves the qualitative (gross) form of the observed Bitcoin prices, but in several portions of time period the fitting is not good.
Significant improvements are obtained by adopting the three described pre-clustering, denoted respectively by labels A, B and C.
The computations are performed on the second half portion of the time period, starting with observation time ; the first part is less interesting because, from observation to both time series have small variations and relatively flat curves. Without performing pre-clustering, the -norm F-transform reconstruction (of order 1) of in terms of has Kendall rank correlation and Spearman correlation . We will compare and indices as preliminary evaluation of the effect of pre-clustering on the fitting quality.
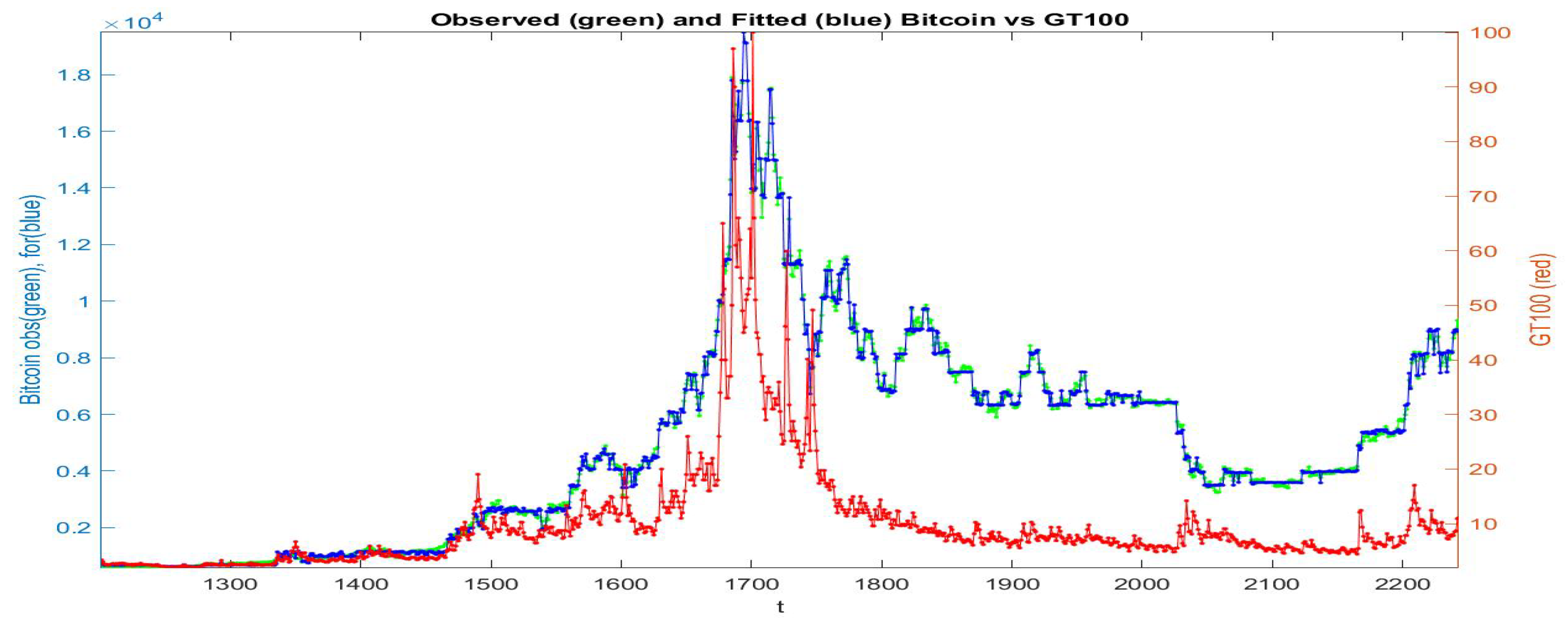
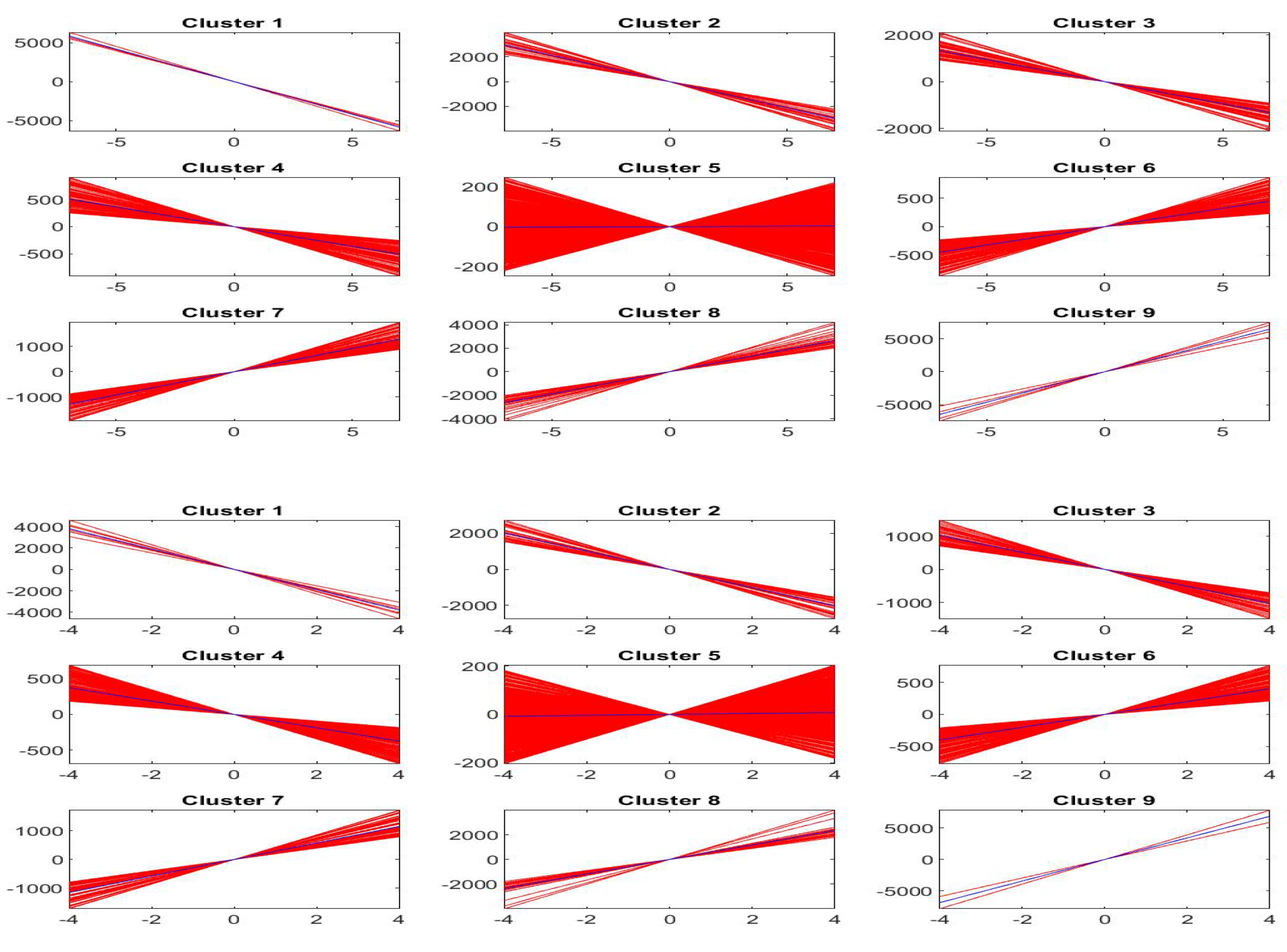
Clustering A. Clusters are based on variable : the number of clusters is . The -norm F-transform reconstruction (of order 1) of in terms of with pre-clustering A has much higher Kendall rank correlation and Spearman correlation .
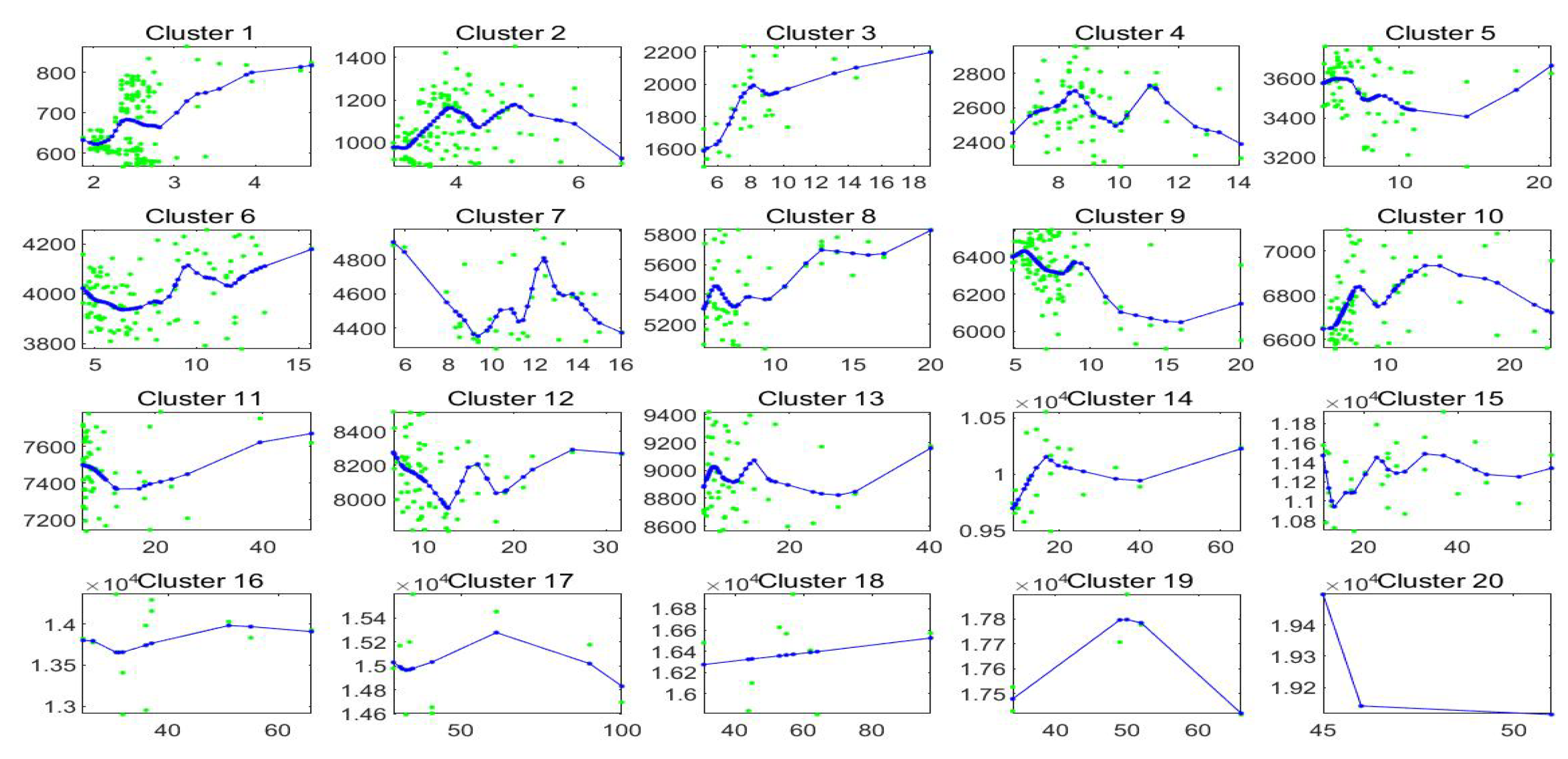
In
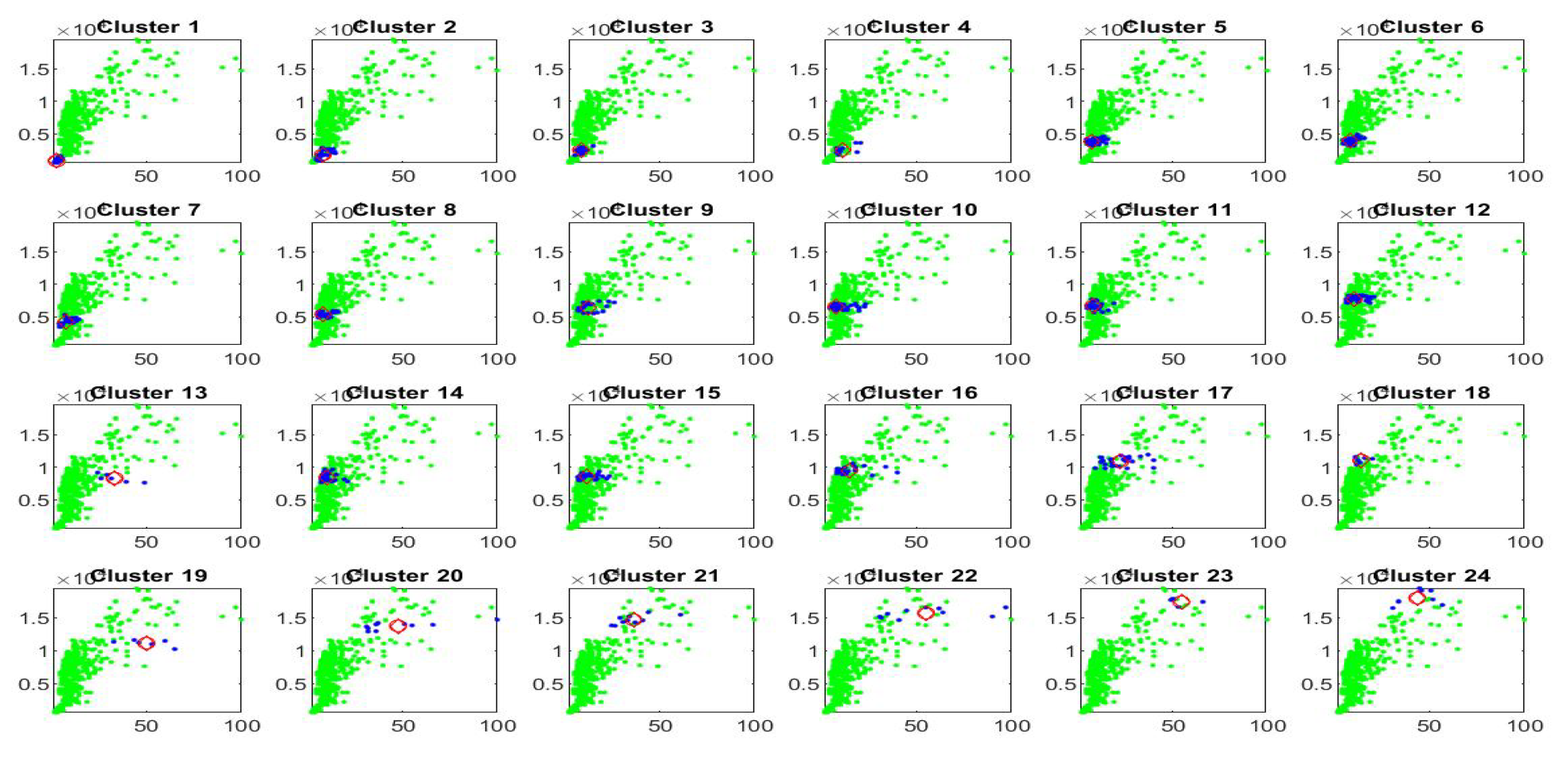
Figure 8 we plot the observed and fitted Bitcoin series for the second half of observations, with evidence that clustering A allows a much better fitting. The 20 clusters are pictured and expanded in
Figure 9 where also the sub-fittings are visible.
Clustering B. Clusters are based on both variables : the number of clusters is . The -norm F-transform reconstruction (of order 1) of in terms of with pre-clustering B has high Kendall correlation and Spearman correlation , similar to clustering A.
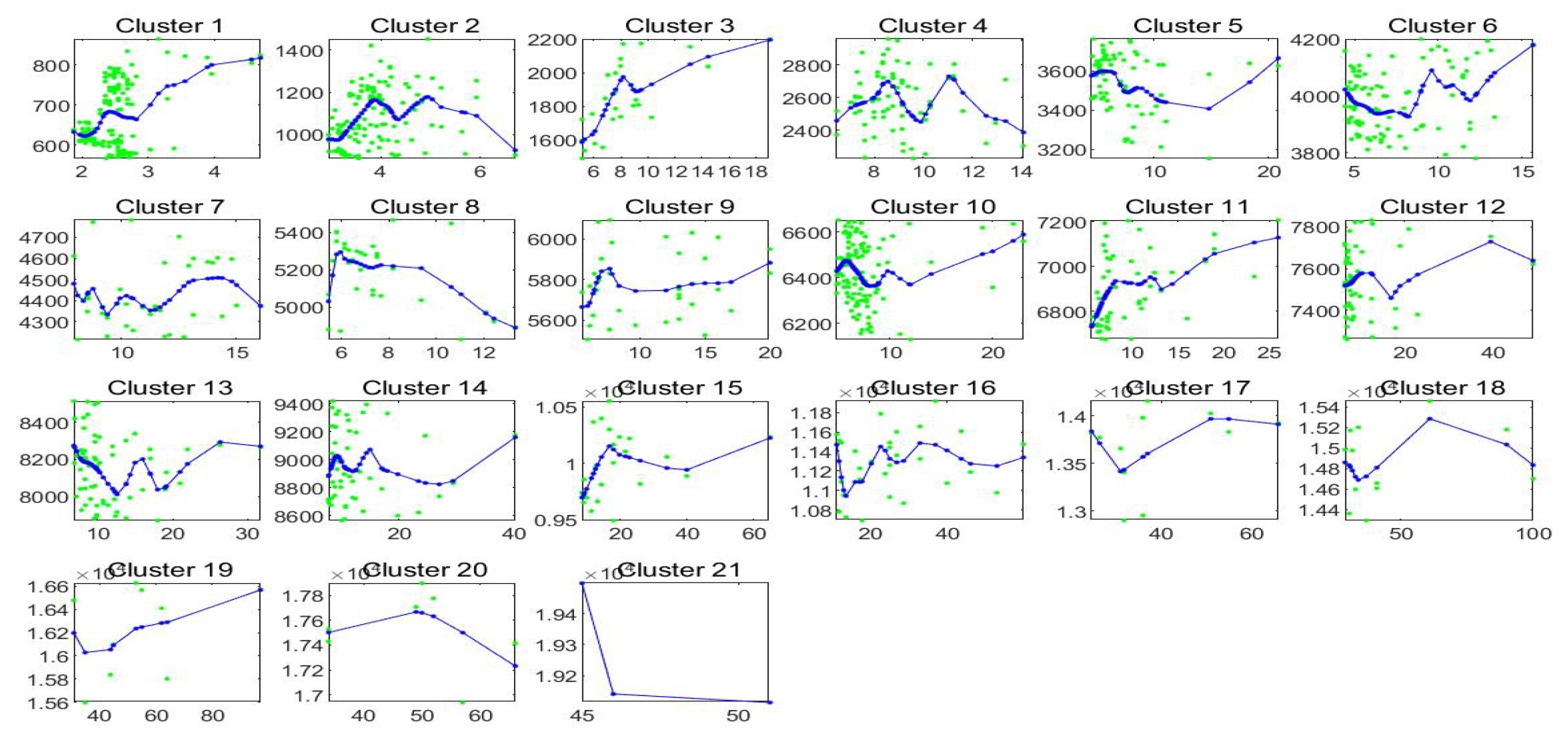
In
Figure 10 we plot the observed and fitted Bitcoin series for the second half of observations, with evidence that clustering B allows a good fitting. The 21 clusters are pictured and expanded in
Figure 11 where also the sub-fittings are visible.
Clustering C. Clusters are based on variables ; the number of clusters is . The -norm F-transform reconstruction (of order 1) of in terms of with this pre-clustering has high Kendall correlation and Spearman correlation , similar but not better than pre-clustering A and B.
In
Figure 12 we plot the observed and fitted Bitcoin series for the second half of observations, with evidence that also clustering C allows a good fitting. The 24 clusters are pictured (blue colours) in
Figure 13 and expanded in
Figure 14 where also the sub-fittings are pictured.
The overall result is that pre-clustering of the data, even based on very simple clustering strategies and a relatively small number of clusters (from 20 to 24) significantly improves the fitting ability of F-transform.
It is also interesting to see that the form of relationships between and is very different for each cluster; this has important consequences on the analysis and modeling of Bitcoin time series as, in particular, it follows different paths in various sub-periods of time and in cases of rare values of the data (e.g., big values and/or big absolute changes).
4. Stylized Facts of Bitcoin Prices Identified by F-Transform Components
The empirical identification of stylized facts, emerging from the analysis of financial time series, is a common tool in data-based approaches to time series modeling (see [
49]) and is consolidated by availability of large data-sets and by application of computer-intensive efficient methods for analyzing their properties. In this section, we will analyze the local F-transform components, in particular the form of polynomials
of
-norm F-transform, of orders
and
described in
Section 2.1, applied to the Bitcoin time series.
We have selected the number m of daily observations such that is a multiple of 7 ( and are observed all the days in the year): in this way, the available data are .
Consider an r-partition with nodes ; denoting the time points of observations simply by (or for ) we consider two uniform :
()—a dense partition with and (i.e., each observation is a node) and the bandwidth r is chosen such that each open interval contains (internally) a prescribed sufficient number of data. E.g., with each contains all data of the week centred at ; with , contains the two weeks ending and starting with .
()—a sparse partition with and (i.e., there is a node every 7 observations) and the bandwidth is chosen. The (direct) F-transform components will span 21 observed values on each side (left or right) of the nodes.
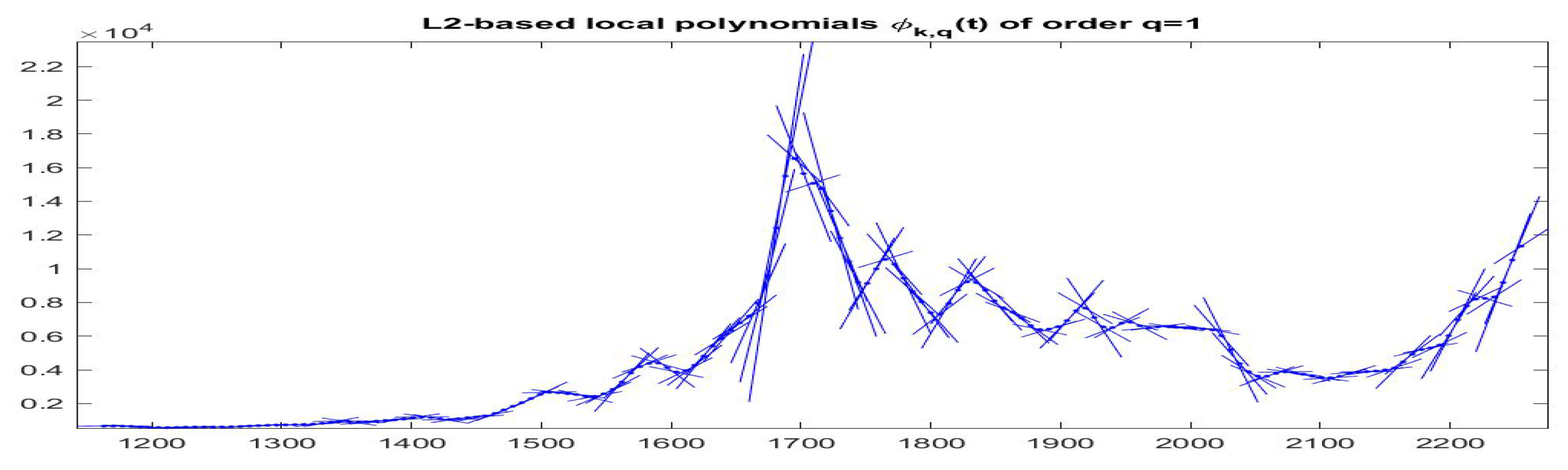
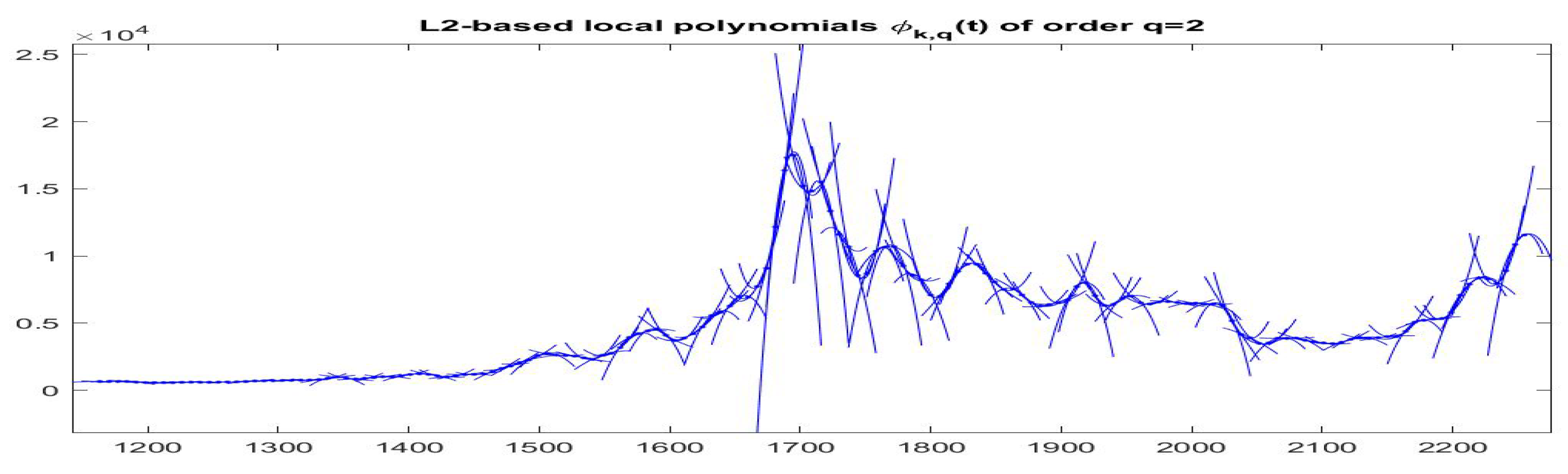
4.1. F-Transform Fitting with Dense r-Partition
In the dense partition case, we obtain the best
-norm F-transform components
associated with all observations (indeed,
corresponds to all observed times
); in this way, we are able to estimate the local trend around every observation and se can follow the time evolution of trends by plotting
around
on subintervals
(see
Figure 15 and
Figure 16).
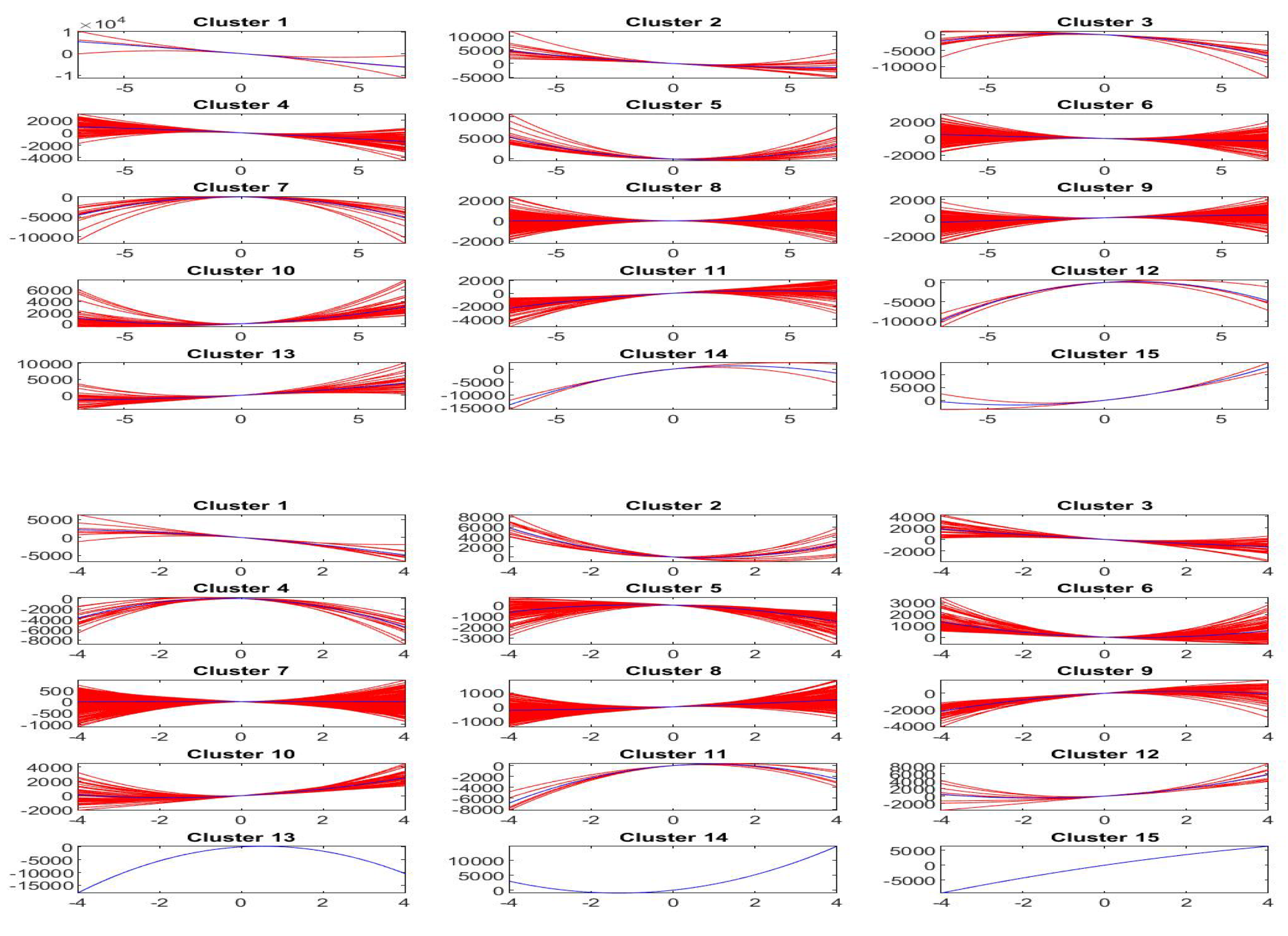
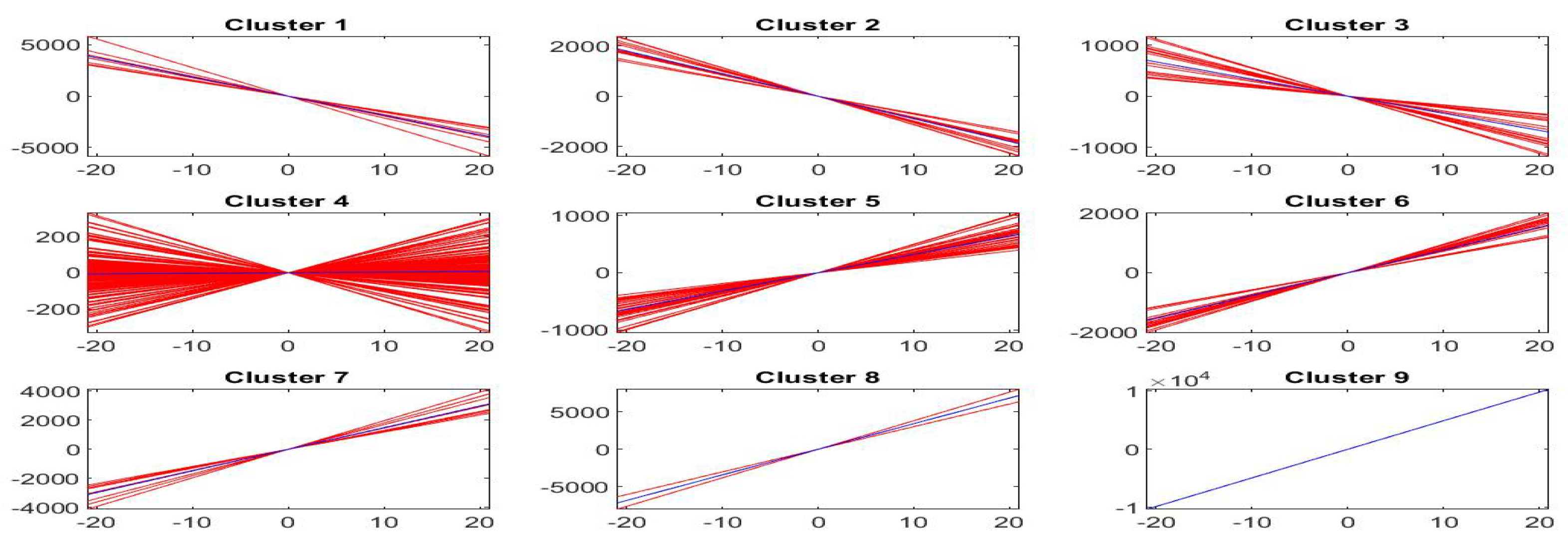
On the other hand, if we translate vertically the polynomials , the polynomials are such that for all k and, if , we can cluster the by clustering the set of vectors of the estimated coefficients. If we obtain a set of lines through the origin with different slopes (in terms of a single variable ); if we obtain a set of parabolic functions through the origin, in terms of two variables and .
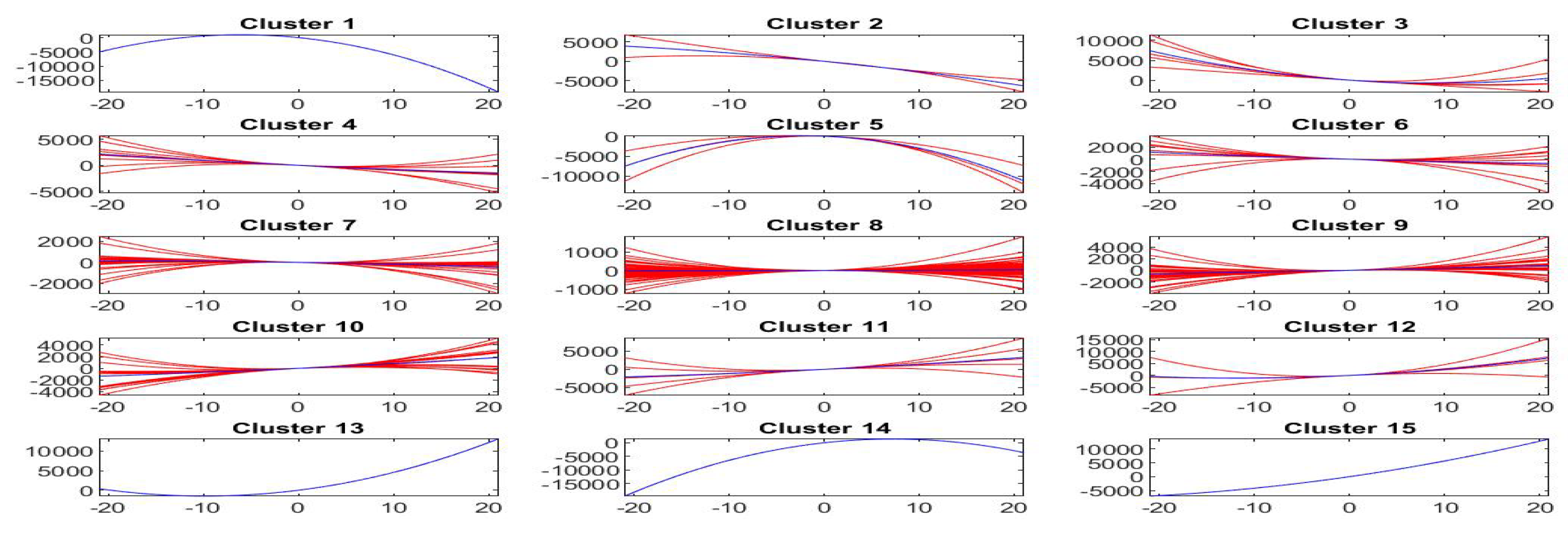
Using the k-means clustering method with the Euclidean distance and testing the number of clusters using the silhouette values, we have that the best number of clusters is when and when .
The interpretation of clusters (characterized by variable ) is interesting, because we have a central cluster of local trends with slope around 0 and other eight clusters characterized by slopes ranging from very negative values (cluster 1) to intermediate negative values (cluster 3) up to intermediate positive (cluster 7) to very positive slopes (cluster 9).
Analogous interpretation is applied to the case of clusters (and ), where again cluster 1 corresponds to the most negative slope, cluster 8 to almost zero slope and cluster 15 to the most positive slope; clearly, also the degrees of concavity and convexity (represented by the second variable ) are taken into account in this case.
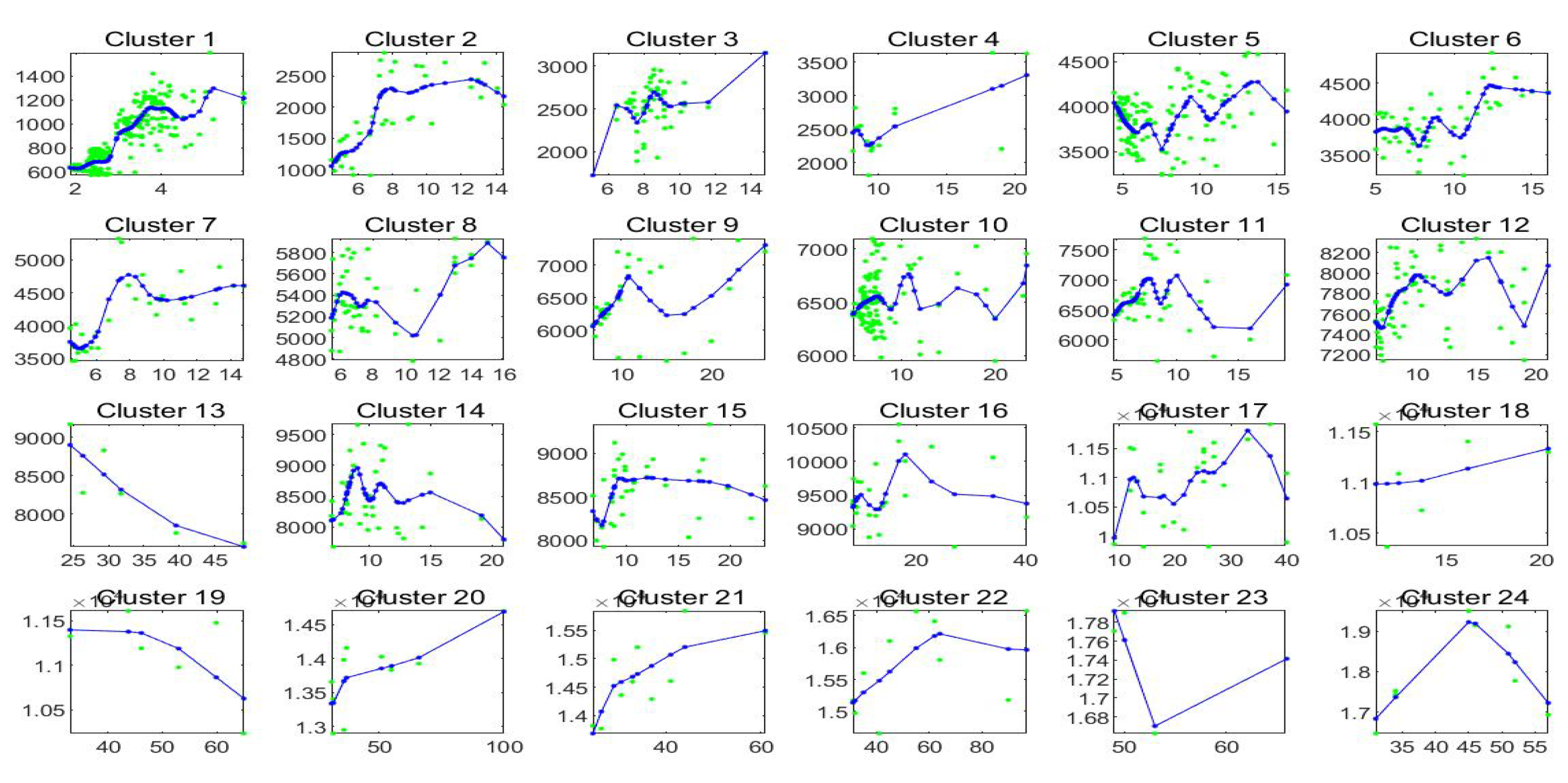
Figure 17 pictures, for each cluster
,
, the first order shifted polynomials
assigned to
(red colors) and the centroid polynomial (blue color) obtained by averaging the parameters
.
Similarly,
Figure 18 pictures, for each cluster
,
, the second order shifted polynomials
assigned to
(red colors) and the centroid polynomial (blue color) obtained by averaging the pairs of parameters
.
As we have said, the centroid polynomials, identified by averaging the parameters of all elements assigned to each cluster or , can be considered to be the stylized forms of the local trends. If we identify each estimated trend by the centroid of its cluster, we then have stylized forms, one for each cluster, that form the possible typical trends around the observed points of the time series.
As a last step, we can produce a simple analysis of how good the stylized trends represent the effective observations: let’s denote by
the standard inverse iF-transform values at times
obtained with estimated direct F-transform (polynomial) components
, i.e.,
denote by
the analogous expression obtained by substituting each local polynomial
by
(here
or
), where the parameters
or the pairs
are the ones that identify the centroid of cluster containing time
k, i.e., if an observation belongs to cluster
we substitute the computed local trend with the local trend of the corresponding centroid:
Essentially, we identify the elements of each cluster by its centroid and we estimate its goodness in terms of the vicinity between the modified version
at times
and the observed data
. In
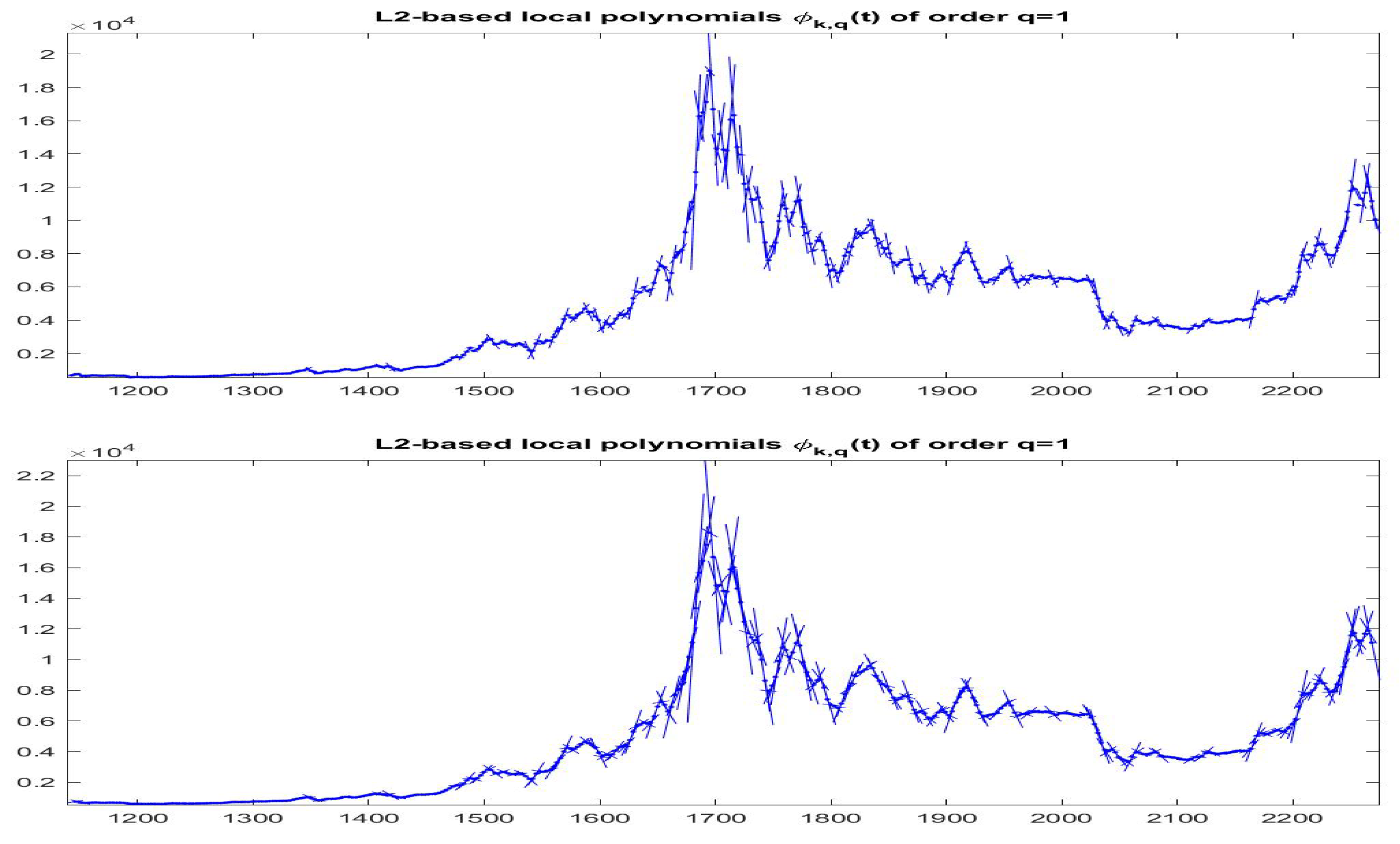
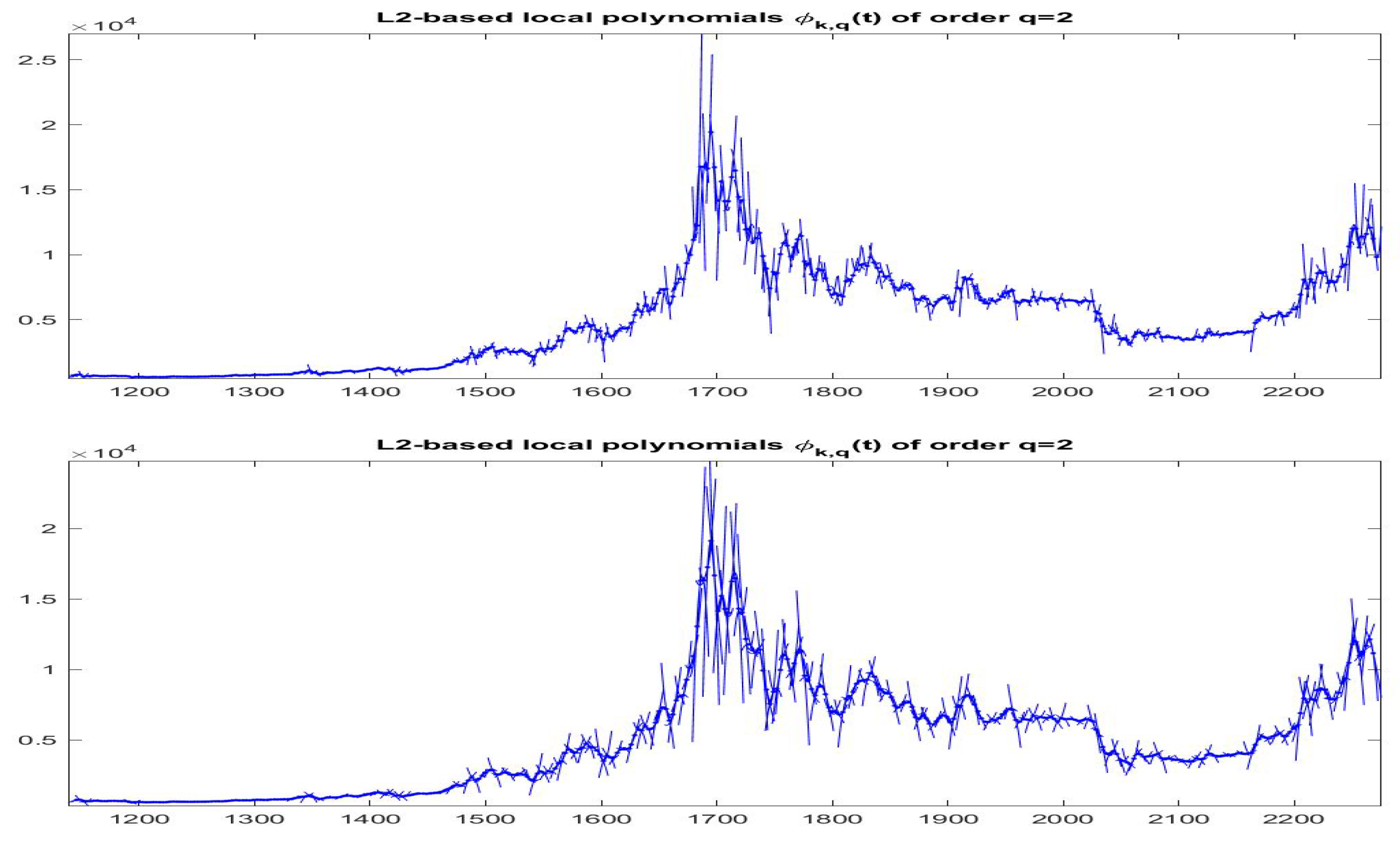
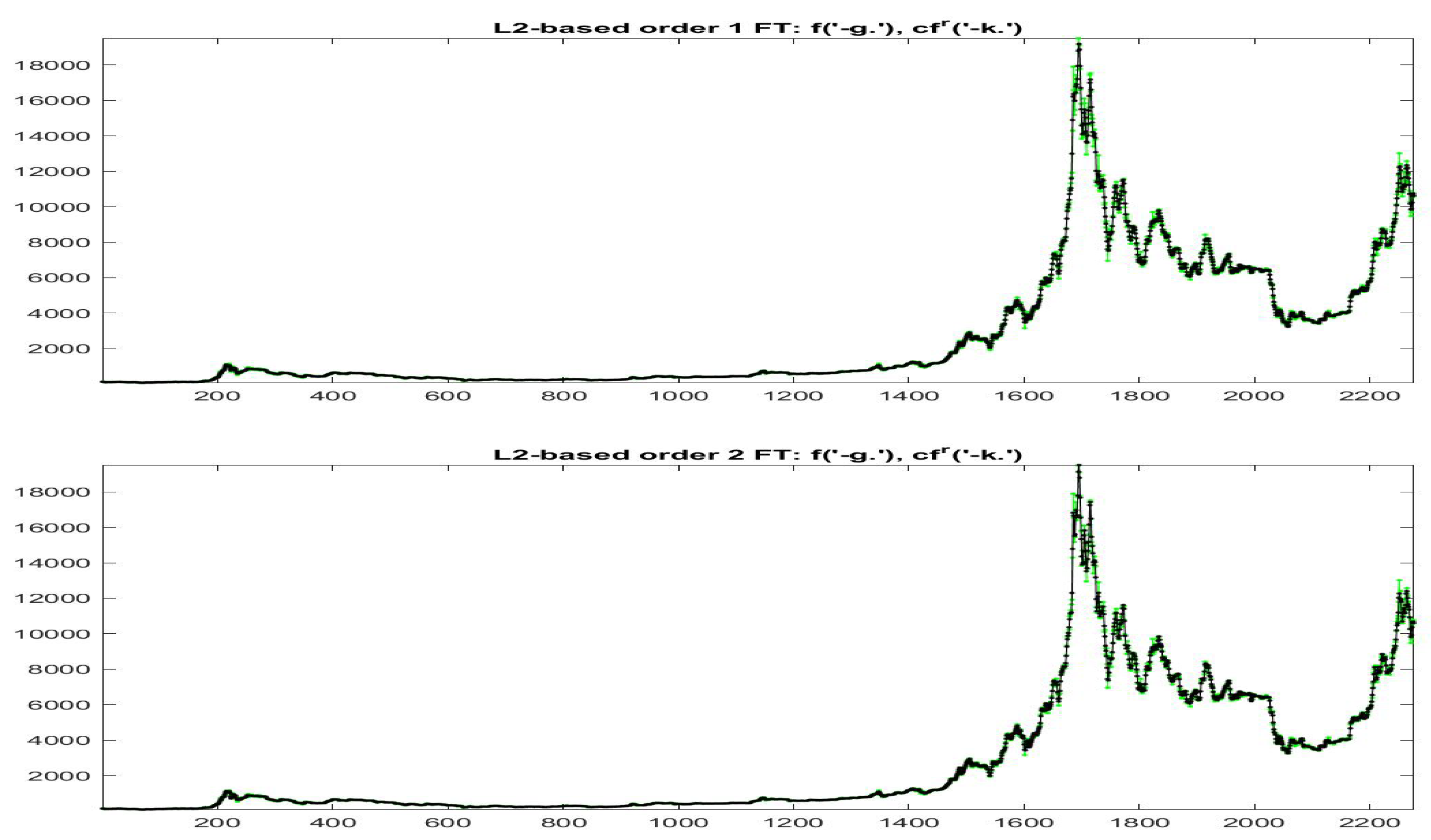
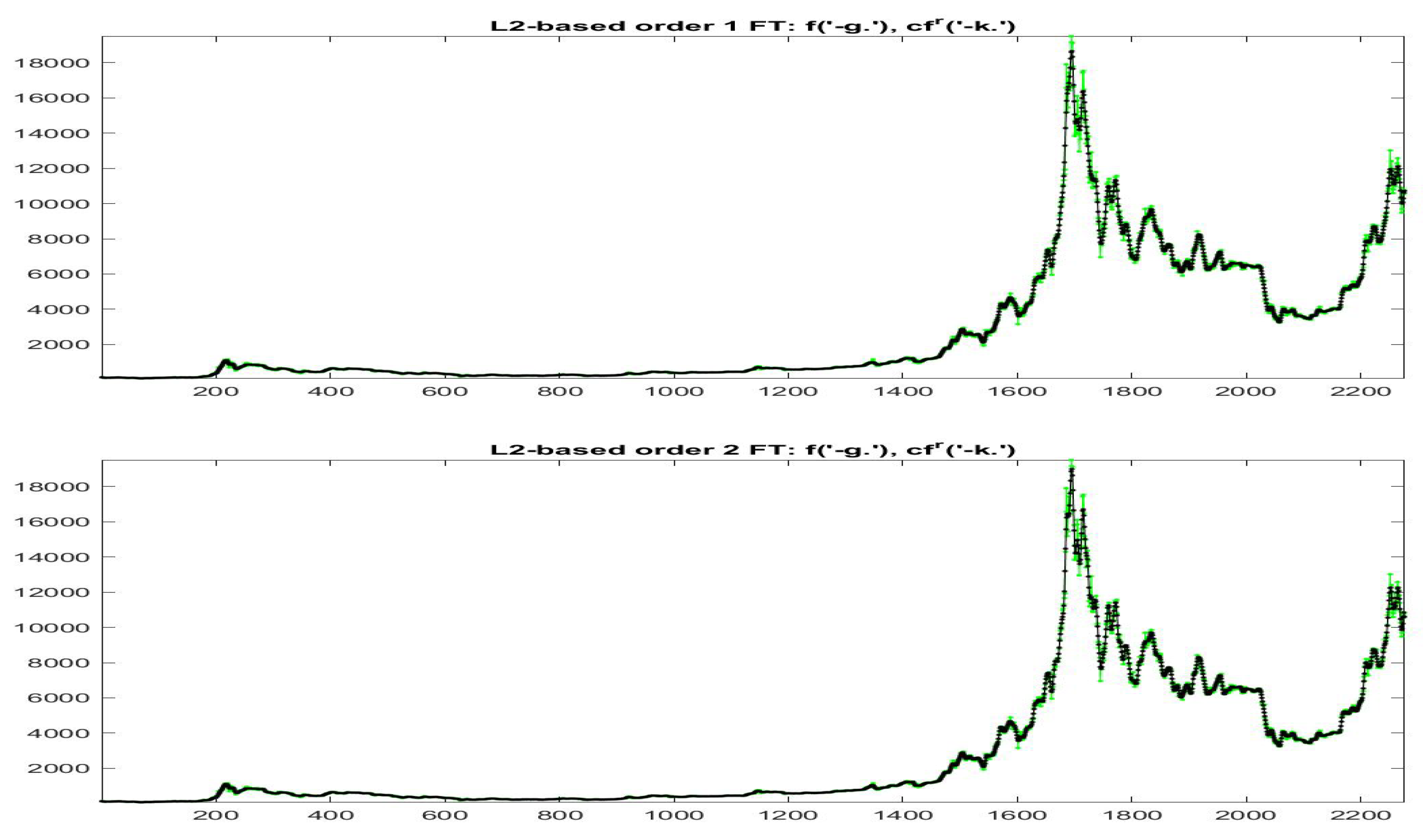
Figure 19 and
Figure 20 the data
(green colors) and
(black colors) are plotted for all the data with
and
, respectively; remark in particular that the iF-transform values and the modified values have a very high correlation and the two values are very near each other on the whole range of small and big values of observed prices.
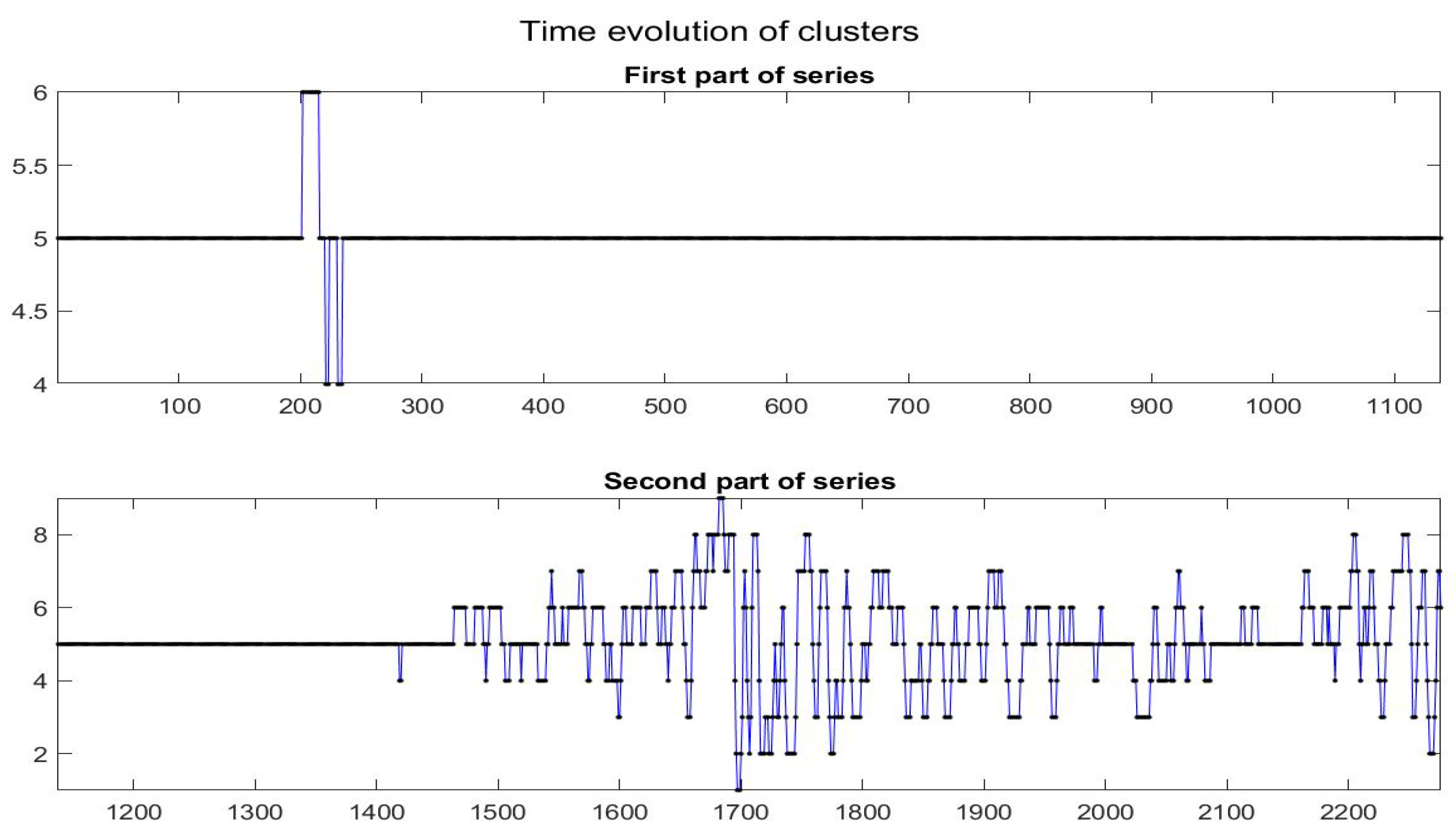
Finally, it is interesting to observe the time evolution of the different clusters (see
Figure 21).
Remark that in the first part of the time series, the data (i.e., the local trends) persist into the quasi-zero slope (quasi-constant time series); after observation 1400, frequent changes in the local trends appear evident, but changes seem to be gradual from one class to a near one and only rarely the local trends jump from a form to a very different one. This appears clearly from the transition matrix , given below ( is the probability that local trend of cluster i moves to class j): we see that matrix P is essentially tridiagonal.
| P = | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 1 | 0.57 | 0.29 | 0.14 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0.08 | 0.44 | 0.44 | 0 | 0.04 | 0 | 0 | 0 | 0 |
| 3 | 0.02 | 0.12 | 0.39 | 0.25 | 0.12 | 0.03 | 0.05 | 0.02 | 0 |
| 4 | 0 | 0.02 | 0.10 | 0.50 | 0.31 | 0.04 | 0.01 | 0.01 | 0 |
| 5 | 0 | 0 | 0 | 0.03 | 0.93 | 0.03 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0.1 | 0.04 | 0.32 | 0.53 | 0.10 | 0.01 | 0 |
| 7 | 0 | 0 | 0 | 0.03 | 0.04 | 0.27 | 0.56 | 0.10 | 0 |
| 8 | 0 | 0.05 | 0.09 | 0.05 | 0 | 0.09 | 0.18 | 0.50 | 0.05 |
| 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.50 | 0.50 |
4.2. F-Transform Fitting with Sparse r-Partition
The results obtained with the dense r-partition are confirmed when using the sparse r-partition . The computations are performed only for the bandwidth , corresponding to nodes of and data belonging to each interval .
Figure 22 and
Figure 23 plot the local trends of orders
and
, respectively (we have plotted only the second part of the Bitcoin time series).
The local trends are clustered into
groups when
and
groups when
, pictured in
Figure 24 and
Figure 25. It appears that , for
, clusters 8 and 9 (and clusters 1, 13, 14, 15, when
) contain very few elements and possibly, in this sparse case, the number of clusters should be reduced to 7 and 11.
The substitution of estimated local trends with the ones obtained from centroids of each cluster, produces the smooth reconstructions represented in
Figure 26 and
Figure 27, respectively; the scatter-plots of the data and their smoothing with standard F-transform and the modified versions, are plotted in
Figure 28 and
Figure 29. We remark that corresponding to a stronger smoothing effect obtained with a smaller number of nodes in the decomposition (now it is sparse) the quality of the fitting is reduced.
5. Forecasting Bitcoin Prices with Gt100 Index
As described in the Introduction, there is empirical evidence that causal relationship between Bitcoin prices/returns and Google Trend scores is bi-directional and, we expect, this will be useful in designing short-term models that relate to for small values of lag . Clearly, as illustrated in sections three and four, the type of functional relationship will change with time and, in particular, the form of local polynomials is expected to persist only for short times around the actual time t and we can estimate their form (coefficients) from the data up to the last available observations.
In the setting of
-norm F-transform, we suggest using the (polynomial) direct F-transform components
such as
where
,
is the
k-th local trend function (
k-th direct F-transform component) and
are delayed versions of the Google Trends
and/or
series.
We are interested to a forecasting model by which, with available observations of
and
at times
up to time
T, we like to construct a forecast of
for
l steps ahead. To do this, we estimate the direct F-transform components (
39) with appropriate
q,
s and values
, obtained from observed values of
and/or
for
; then, e.g., using the last estimated trend function
we approximate
with
. This is always possible if the fuzzy
r-partition is such that
. Alternatively, if
, we can approximate
by computing the inverse F-transform at time
as the combination of local trends
that have positive weights
, the basic functions active at time
.
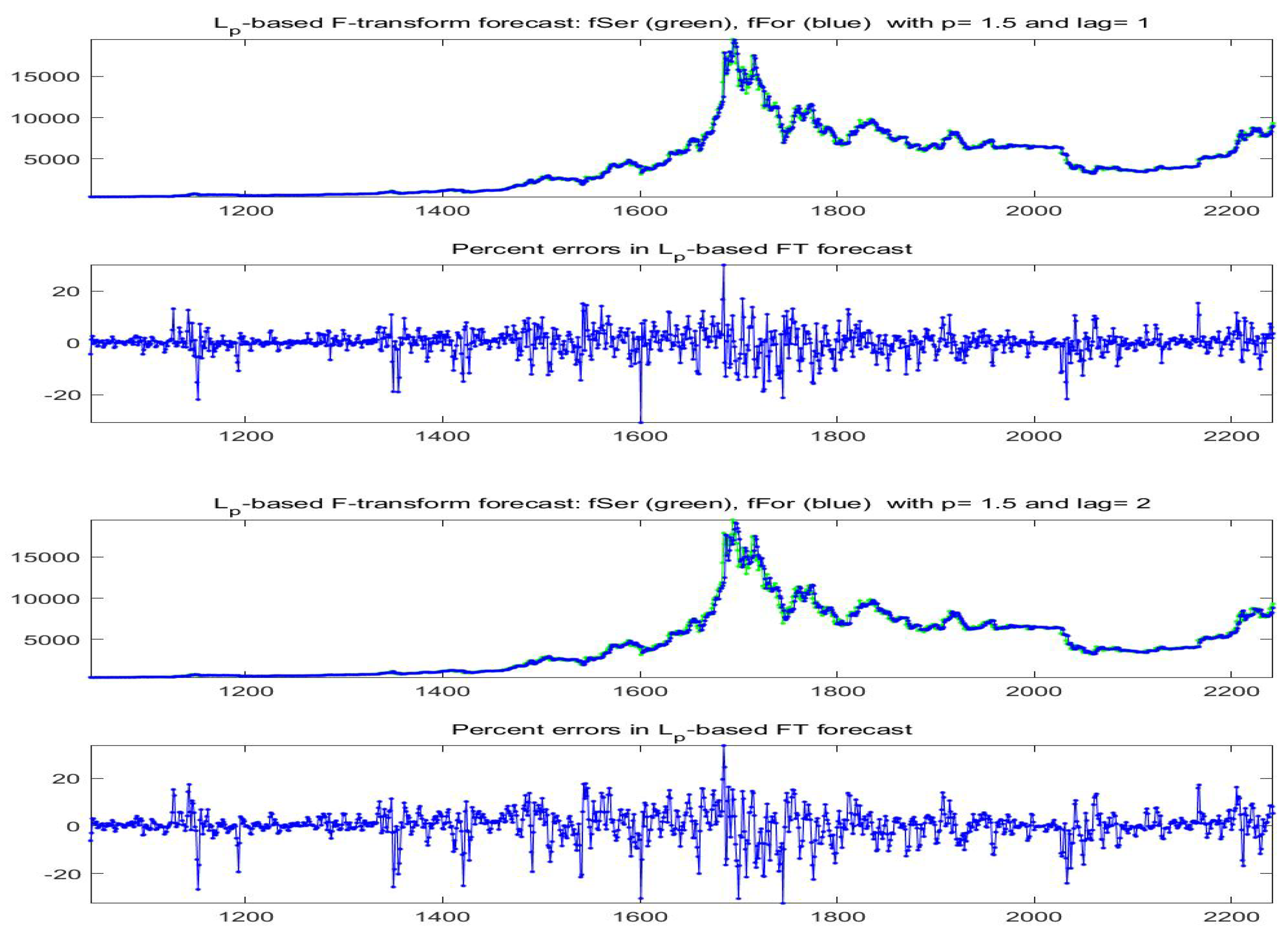
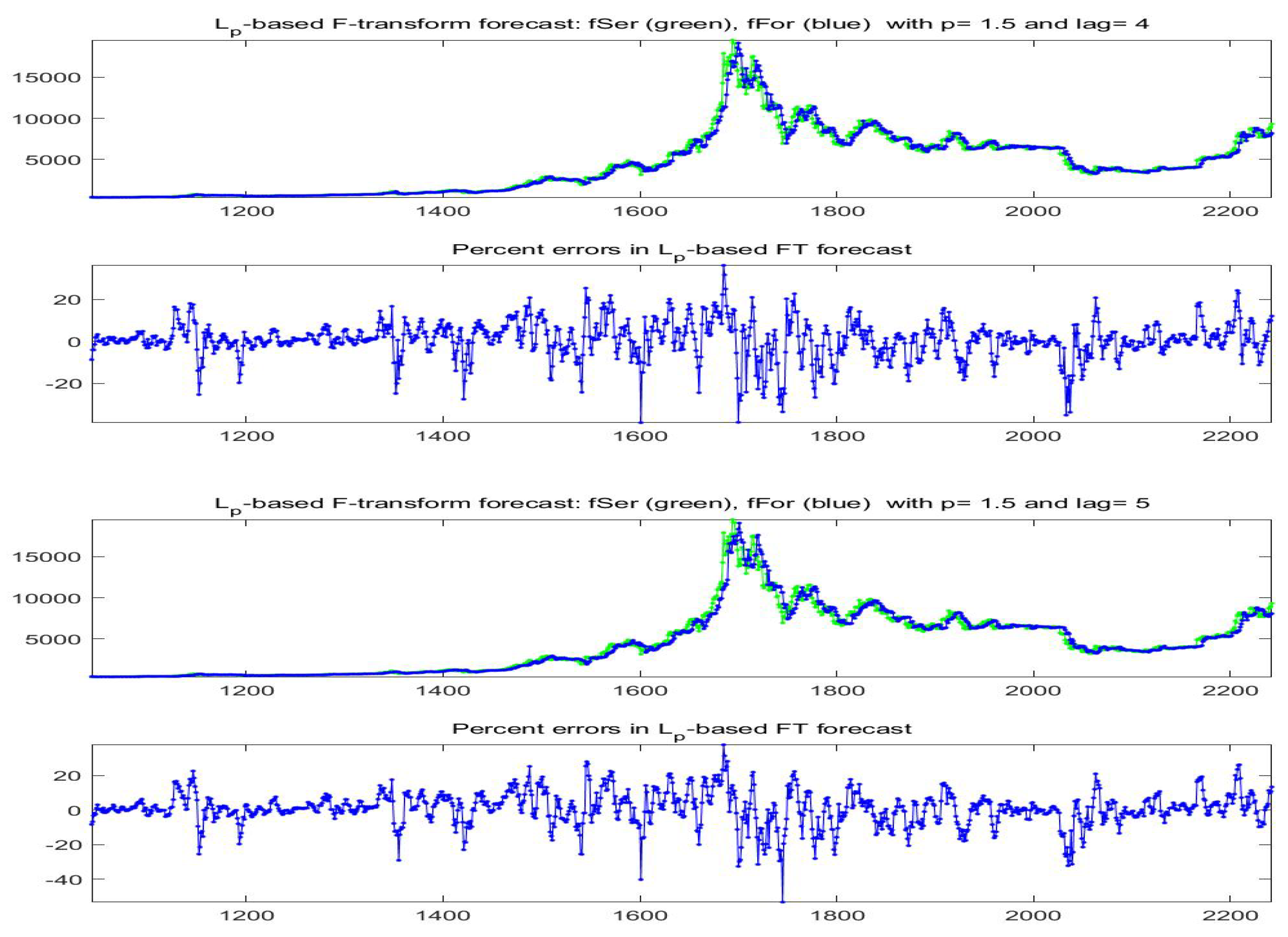
Clearly, this construction may be good and reasonable only for short-term forecasting. In our experiments we have used the first approximation only to forecast Bitcoin prices with . The reported results are given for the last 1200 values of the available time series. We have used , and two cases of functions :
Model A: and ;
Model B: and , , i.e., by adding an autoregressive term.
Our simple forecasting model is obtained by the following three steps:
Step 1. We start with one of the fitting model obtained in the analysis in previous sections and we chose the pair of values where is the bandwidth of the r-partition and the associated value is the number of time observations used to estimate the parameters of local trend functions . We have found that observations on each subinterval of the partition, in the range , produces in general the best fitting results: two or three weeks of data are sufficient to obtain the forecast.
Step 2. The parameters in are estimated using the Lp-norm-based criterion: we assume as a good intermediate value between quantile () and expectile () estimators.
Step 3. Each l-steps ahead forecast value for the last more recent 1200 available observations ending at time is obtained from , where is the number on intervals in the partition covering data that terminate at time T: forecast is then estimated from data , for and, in Model B, for . In this way, we can compute as the needed values and are available from observations.
For the fitting (i.e., with ) and forecasting models (with ) we report the mean square error ( ), the mean absolute percentage error () and the well-known Kendall rank correlation (a measure of ordinal association between and ).
We see from
Table 3 that the fitting of Bitcoin and GT100 time series become significantly better by increasing the order
q; it is also interesting to remark that GT100 fitting is much less precise that Bitcoin fitting (with the same
p and
q). On the other hand, polynomials of orders
are not useful for extrapolation as they tend to be highly oscillating for a lag
.
For these reasons, only three pairs
as in
Table 4 and
Table 5 are considered and we see that for forecasting,
gives good results for small lag
l while
is better for higher lags.
The forecast Bitcoin time series for lags
obtained with model A are pictured in
Figure 30; for lags
and model B are plotted in
Figure 31.
To conclude this section on forecasting Bitcoin time series, we shortly explore the statistical significance of the proposed models A and B. Following some ideas in [
28], we compare our forecast estimates with the so-called random walk model, assumed as a benchmark for single step forecasting, i.e., with lag
. Defining the return series as
, the random walk forecast
of the returns at time
T is defined in terms of a fixed time horizon of
s observations
,
ending at time
T by
Then, considering that the return values are known up to time T, the random walk forecast of at time is simply the average , we can estimate the random walk forecast of from the definition of return at time and obtain . This calculations are performed for T being each of the last 730 available observations (two years).
As in [
28], the Diebold–Mariano (DM) test statistics is applied to test the significance of the
measures for our forecasts (with models A and B) in comparison with the random walk forecast. The results are reported in
Table 6.
Table 6 (in particular the small
p-value) confirm that Bitcoin prices can be forecasted using F-transform of order
, as indeed both (simple) short-term models A and B outperform the random walk model.




































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}