
Research on an Adaptive Real-Time Scheduling Method of Dynamic Job-Shop Based on Reinforcement Learning


Abstract
:1. Introduction
2. Research Background
2.1. Static Production Scheduling Methods
2.2. Intelligent Production Scheduling Methods
3. Research Methodology
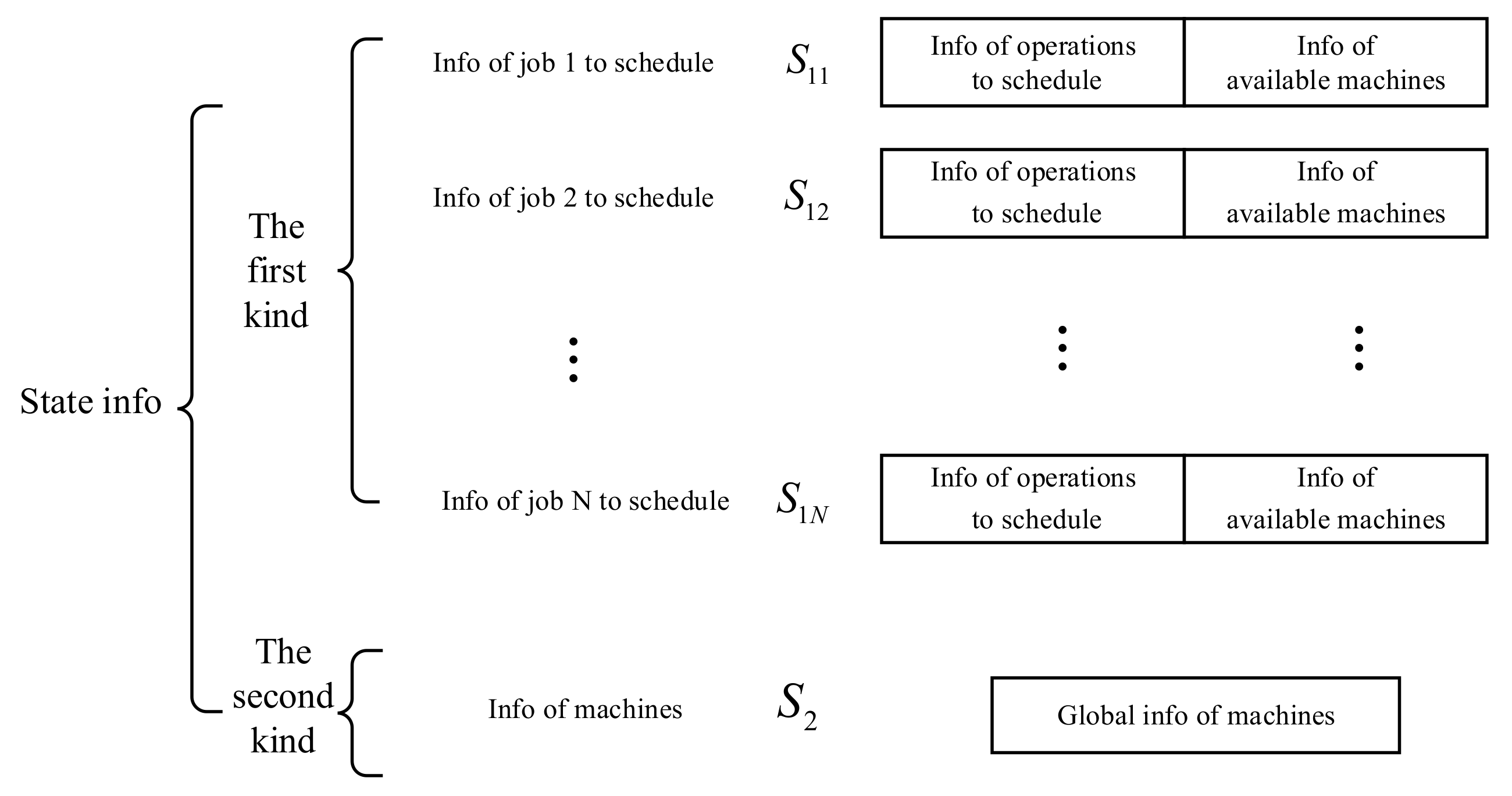
3.1. Mathematical Model
3.1.1. The Mathematical Model of FJSP
3.1.2. The Principle of Applying RL to Model FJSP
3.2. Manufacturing Neural Network
3.3. The Learning Algorithm
3.3.1. Policy Representation
3.3.2. Priority Representation in FJSP
3.3.3. Objective Function
3.3.4. Update the Policy
| Algorithm 1: The policy gradient with baseline. |
| Input: A differentiable policy Input: A differentiable value function Hyper parameters: learning rate , Initialize policy parameter and value function parameter Loop (for each episode): Run an episode according to , Loop (for each step in the episode) : |
3.3.5. Modes of Choosing Action
4. Simulation and Experiment
4.1. Simulation Environment
4.2. Experiment Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Conway, R.W.; Maxwell, W.L.; Miller, L.W. Theory of Scheduling; Addison-Wesley: Reading, MA, USA, 1967. [Google Scholar]
- Pinedo, M.; Hadavi, K. Scheduling: Theory, algorithms and systems development. In Operations Research Proceedings; Springer: Berlin, Germany, 2012. [Google Scholar]
- Ławrynowicz, A. Integration of production planning and scheduling using an expert system and a genetic algorithm. J. Oper. Res. Soc. 2008, 59, 455–463. [Google Scholar] [CrossRef]
- Yang, H.; Kumara, S.; Bukkapatnam, S.T.S.; Tsung, F. The Internet of Things for smart manufacturing: A review. IISE Trans. 2019, 51, 1190–1216. [Google Scholar] [CrossRef]
- Bagheri, A.; Zandieh, M.; Mahdavi, I.; Yazdani, M. An artificial immune algorithm for the flexible job-shop scheduling problem. Future Gener. Comput. Syst. 2010, 26, 533–541. [Google Scholar] [CrossRef]
- De Giovanni, L.; Pezzella, F. An Improved Genetic Algorithm for the Distributed and Flexible Job-shop Scheduling problem. Eur. J. Oper. Res. 2010, 200, 395–408. [Google Scholar] [CrossRef]
- Chong, C.S.; Iyer, S.A.; Gay, R. Simulation-based scheduling for dynamic discrete manufacturing. In Proceedings of the 2003 Winter Simulation Conference New Orleans, LA, USA, 7–10 December 2003; pp. 1465–1473. [Google Scholar]
- Shen, W.; Norrie, D.H. Agent-based systems for intelligent manufacturing: A state-of-the-art survey. Knowl. Inf. Syst. 1999, 1, 129–156. [Google Scholar] [CrossRef]
- Masin, M.; Pasaogullari, M.O.; Joshi, S. Dynamic scheduling of production-assembly networks in a distributed environment. IIE Trans. 2007, 39, 395–409. [Google Scholar] [CrossRef]
- Jennings, N.R.; Wooldridge, M. Applications of intelligent agents. In Agent Technology; Springer: Berlin, Germany, 1998; pp. 3–28. [Google Scholar]
- Stecke, K.E.; Solberg, J.J. Loading and control policies for a flexible manufacturing system. Int. J. Prod. Res. 1981, 19, 481–490. [Google Scholar] [CrossRef]
- Wang, J.M. Survey on Industrial Big Data. Big Data Res. 2017, 3, 3–14. [Google Scholar] [CrossRef]
- Zhou, T.; Tang, D.; Zhu, H.; Zhang, Z. Multi-agent reinforcement learning for online scheduling in smart factories. Robot. Comput. Integr. Manuf. 2021, 72, 102202. [Google Scholar] [CrossRef]
- Giudici, P.; Figini, S. Applied Data Mining for Business and Industry; Wiley Publishing: Hoboken, JE, USA, 2009. [Google Scholar]
- Yin, S.; Kaynak, O. Big Data for Modern Industry: Challenges and Trends. Proc. IEEE 2015, 103, 143–146. [Google Scholar] [CrossRef]
- Wu, X.; Zheng, Q. Optimization of flexible Job-shop Scheduling Problem based on improved particle swarm Optimization. J. Hubei Univ. 2021, 44, 501–507. [Google Scholar]
- Tian, Y.; Tian, Y.; Liu, X.; Zhao, Y. An Improved Gray Wolf Algorithm for Solving Flexible Job-shop Scheduling Problem. Comput. Mod. 2022, 8, 78–85. [Google Scholar]
- Dong, R.; He, W. Hybrid Genetic Ant Colony Algorithm for Solving FJSP. Comput. Integr. Manuf. Syst. 2012, 11, 2492–2501. [Google Scholar]
- Sha, D.Y.; Lin, H.H. A multi-objective PSO for job-shop scheduling problems. Expert Syst. Appl. 2010, 37, 1065–1070. [Google Scholar] [CrossRef]
- Zhou, G. Research on Flexible Scheduling Problem Based on Artificial Bee Colony Algorithm; Tsinghua University: Haidian, Beijing, 2012. [Google Scholar]
- Li, Y.; Wang, A.; Zhang, S. A Batch Scheduling Technique of Flexible Job-Shop Based on Improved Genetic Algorithm. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 1463–1467. [Google Scholar] [CrossRef]
- Cheng, Z.; Wang, L.; Tang, B.; Li, H. A Hybrid Genetic Algorithm for Flexible Job Shop Scheduling Problems. In Proceedings of the 2021 Chinese Intelligent Systems Conference., Fuzhou, China, 16–17 October 2021; Jia, Y., Zhang, W., Fu, Y., Yu, Z., Zheng, S., Eds.; Lecture Notes in Electrical Engineering. Springer: Singapore, 2022; Volume 805. [Google Scholar] [CrossRef]
- Lv, C.; Zhu, Y.; Yin, C. Negotiation Strategy in Agile Production Scheduling Based on Multi-Agent. Comput. Integr. Manuf. Syst. 2006, 4, 579–584. [Google Scholar]
- Lv, C.; Zhu, Y.; Yin, C. Research on hybrid negotiation strategy of production scheduling based on Agent. Comput. Integr. Manuf. Syst. 2006, 12, 2074–2081. [Google Scholar]
- Cai, L.; Li, W.; Luo, Y.; He, L. Real-time scheduling simulation optimisation of job shop in a production-logistics collaborative environment. Int. J. Prod. Res. 2022, 1–21. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, H.; Tang, D.; Zhou, T.; Gui, Y. Dynamic job shop scheduling based on deep reinforcement learning for multi-agent manufacturing systems. Robot. Comput. Integr. Manuf. 2022, 78, 102412. [Google Scholar] [CrossRef]
- Chang, J.; Yu, D.; Hu, Y.; He, W.; Yu, H. Deep Reinforcement Learning for Dynamic Flexible Job Shop Scheduling with Random Job Arrival. Processes 2022, 10, 760. [Google Scholar] [CrossRef]
- Johnson, D.; Chen, G.; Lu, Y. Multi-Agent Reinforcement Learning for Real-Time Dynamic Production Scheduling in a Robot Assembly Cell. IEEE Robot. Autom. Letters. 2022, 7, 7684–7691. [Google Scholar] [CrossRef]
- Waschneck, B.; Reichstaller, A.; Belzner, L.; Altenmüller, T.; Bauernhansl, T.; Knapp, A.; Kyek, A. Optimization of global production scheduling with deep reinforcement learning. Proc. CIRP 2018, 72, 1264–1269. [Google Scholar] [CrossRef]
- Khalil, E.; Dai, H.; Zhang, Y.; Dilkina, B.; Song, L. Learning combinatorial optimization algorithms over graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 6348–6358. [Google Scholar]
- Han, B.; Yang, J. A Deep Reinforcement Learning Based Solution for Flexible Job Shop Scheduling Problem. Int. J. Simul. Modelling. 2021, 20, 375–386. [Google Scholar] [CrossRef]
- Aldarmi, S.A.; Burns, A. Dynamic value-density for scheduling real-time systems. In Proceedings of the 11th Euromicro Conference on Real-Time Systems, York, UK, 9–11 June 1999; pp. 270–277. [Google Scholar] [CrossRef]
- Tseng, S.M.; Chin, Y.H.; Yang, W.P. An adaptive value-based scheduling policy for multiprocessor real-time database systems, In Proceedings of the Database and Expert Systems Applications 8th International Conference, Toulouse, France, 1–5 September 1997. pp. 254–259.
- Burns, A.; Prasad, D.; Bondavalli, A.; Di Giandomenico, F.; Ramamritham, K.; Stankovic, J.; Strigini, L. The meaning and role of value in scheduling flexible real-time systems. J. Syst. Archit. 2000, 46, 305–325. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MDP | FJSP |
|---|---|
| Agent | Scheduler |
| Environment | Production job-shop system |
| Trail | Scheduling route of single order |
| Action node | Scheduling moment |
| State | Dynamic properties of the job-shop environment |
| Action | Assigning the operation to the corresponding machine |
| State transition Reward | Completion time or other goals |
| Equipment Number | Equipment Type |
|---|---|
| M1 | Lathe |
| M2 | Lathe |
| M3 | Milling machine |
| M4 | Milling machine |
| M5 | Carving machine |
| M6 | Carving machine |
| Jobs | Operations | Processing Time/s | |||||
|---|---|---|---|---|---|---|---|
| M1 | M2 | M3 | M4 | M5 | M6 | ||
| 9 | 7 | — | — | — | — | ||
| — | — | 11 | 9 | — | — | ||
| — | — | — | — | 4 | 5 | ||
| 8 | 10 | — | — | — | — | ||
| — | — | — | — | 5 | 3 | ||
| — | — | 12 | 10 | — | — | ||
| 8 | 6 | — | — | — | — | ||
| — | — | — | — | 5 | 7 | ||
| — | — | 5 | 8 | — | — | ||
| — | — | — | — | 7 | 9 | ||
| 7 | 9 | — | — | — | — | ||
| — | — | 6 | 8 | — | — | ||
| 9 | 5 | — | — | — | — | ||
| — | — | — | — | 2 | 3 | ||
| — | — | 6 | 4 | — | — | ||
| 10 | 12 | — | — | — | — | ||
| — | — | — | — | 7 | 5 | ||
| 10 | 8 | — | — | — | — | ||
| — | — | 6 | 8 | — | — | ||
| — | — | — | — | 5 | 7 | ||
| 13 | 11 | — | — | — | — | ||
| — | — | 3 | 5 | — | — | ||
| — | — | — | — | 6 | 8 | ||
| 9 | 6 | — | — | — | — | ||
| — | — | 8 | 7 | — | — | ||
| — | — | — | — | 8 | 7 | ||
| — | — | 3 | 8 | — | — | ||
| 9 | 5 | — | — | — | — | ||
| — | — | — | — | 5 | 8 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Tao, S.; Gui, Y.; Cai, Q. Research on an Adaptive Real-Time Scheduling Method of Dynamic Job-Shop Based on Reinforcement Learning. Machines 2022, 10, 1078. https://doi.org/10.3390/machines10111078
Zhu H, Tao S, Gui Y, Cai Q. Research on an Adaptive Real-Time Scheduling Method of Dynamic Job-Shop Based on Reinforcement Learning. Machines. 2022; 10(11):1078. https://doi.org/10.3390/machines10111078
Chicago/Turabian StyleZhu, Haihua, Shuai Tao, Yong Gui, and Qixiang Cai. 2022. "Research on an Adaptive Real-Time Scheduling Method of Dynamic Job-Shop Based on Reinforcement Learning" Machines 10, no. 11: 1078. https://doi.org/10.3390/machines10111078
APA StyleZhu, H., Tao, S., Gui, Y., & Cai, Q. (2022). Research on an Adaptive Real-Time Scheduling Method of Dynamic Job-Shop Based on Reinforcement Learning. Machines, 10(11), 1078. https://doi.org/10.3390/machines10111078