1. Introduction
In this paper, deep reinforcement learning (DRL) is used to predict the disturbances of the swinging leg to the single rigid body (SRB) model, and the SRB-based model predictive control (MPC) method is transplanted to the biped robots with a non-negligible leg mass.
Compared with other types of robots, legged robots have huge application value and development prospects. At present, quadruped robots and biped robots are the research hotspots in the field of legged robots. Due to the complex nonlinear dynamics and higher degrees of freedom of biped robots, it is a challenging task to realize the stable walking of biped robots [
1]. Compared with quadruped robots, it is difficult to achieve static stability with biped robots due to their mechanical structure design. Since the rectangular foot area of biped robots is very small, some biped robots even have linear feet. This results in a small or even a non-existent support field for biped robots during static standing and locomotion. From the point of view of stability analysis, the biped robots do not have the condition of static stability, but only have the condition of dynamic stability. This means that bipedal robots can only stabilize themselves during locomotion. Therefore, the design of the locomotion controller of biped robots is much more difficult than that of quadruped robots.
At present, there are two main control methods for legged robots, namely model-based control methods and model-free control methods. DRL is the most dominant of the model-free methods. Currently, in the field of legged robots, proximal policy optimization [
2] (PPO) and deep deterministic policy gradient [
3] (DDPG) are the two most commonly used DRL methods. The DRL methods successfully realize the navigation of mobile robots [
4] and the motion control of manipulators [
5]. The DRL methods avoid the complex modeling and parameter adjustment process. Through the guidance of different reward functions, the agent can learn different target strategies, which is a more flexible control method. Recent studies have achieved many control goals on bipedal robots with the help of DRL methods, such as blindly climbing stairs [
6], adapting to rough terrains [
7], and carrying various dynamic loads [
8].
Most DRL methods learn joint positions in joint space [
9,
10] and then implement joint torque control through a low-level proportional derivative (PD) controller. However, the dimensions of observation space and action space of such methods are large, which require a long training time. The model-based control method is what we usually call the traditional control method.
To design a model-based control method, the controlled object must be modeled first. In the field of legged robots, there are many ways to model robots. These models can be roughly divided into two categories: one is full-order models and the other is reduced-order models. The main difference between them is whether the dynamic model of the robot is simplified. The full order model is to model the legged robot as accurately as possible, preserving all quantifiable dynamic properties. In physics, the full-order model of a legged robot is one of a multi-rigid-body floating-base dynamic model. The Newton–Euler method and the Lagrange method are two commonly used modeling methods for multi-rigid-body floating-base dynamic models.
Compared with the full-order model, the modeling process of the reduced-order model is much simpler. In the field of legged robots, the most classic reduced order model is the linear inverted pendulum (LIP) model [
11]. The LIP model simplifies the robot into a system consisting of a mass point and two massless links with freely varying lengths attached to it. The model assumes that the height of the center of mass remains unchanged during the movement process, which degenerates the complex nonlinear dynamic equation into a linear equation and greatly reduces the design difficulty of the controller. The simplicity and effectiveness of LIP make it widely used in the field of legged robots. Subsequently, many improved models based on LIP appeared, such as the same classical spring-loaded inverted pendulum (SLIP) model [
12]. Another commonly used model in the field of biped robots is the five-link model. The LIP model is mainly used to plan the landing point and gait cycle of the robot, and the five-link model can be used to directly solve the joint torque. The torso and legs of the biped robot are simplified into five mass-concentrated connecting links. As an approximate simplified model of the full-order models, the five-link model can also be modeled by the Newton–Euler method and Lagrange method mentioned above, and the modeling process is relatively simple. A recent study on quadruped robots [
13] proposed a reduced-order model called the SRB model. Unlike the LIP model and the five-link model, the SRB model contains only one rigid body that can move freely. Relative to the point and the link, the SRB contains the posture information of the robot, so the SRB model is a more accurate simplified model than the LIP and the five-link model. The hybrid zero dynamics (HZD) is a feedback control method based on virtual constraints. It is commonly used in the control of full-order models and five-link models [
14]. Recent research has improved the Cassie robot’s adaptability to rough terrains with the help of HZD [
15]. There are many control methods based on the LIP model, such as capture point (CP) control [
16], zero moment point (ZMP) control [
17], linear quadratic regulator (LQR), and other optimal control methods [
18]. A recent study on bipedal robots [
19] applied the SRB-based MPC method to bipedal robots. However, the popularization of the SRB-based MPC in the field of biped robots faces a major challenge. The SRB model does not consider the influence of the leg mass on the overall motion of the robot, which is a very reasonable assumption for a quadruped robot whose leg mass accounts for about 10%. At present, the mass of the legs of most biped robots accounts for a large proportion, and the influence of the mass of the legs on the overall motion cannot be ignored. Recent studies [
20,
21,
22] have combined the whole body control (WBC) based on floating-base dynamics with the SRB-based MPC and achieved good control results. However, such methods are complex and computationally intensive. Recent studies have also attempted to combine model-based and model-free approaches, such as learning foothold locations in the task space [
23] and combining DRL with HZD to achieve higher-level control objectives [
24].
Based on the above reasons, we propose an MPC method based on DRL. In this paper, we use the PPO algorithm among DRL methods to learn the prediction policy of the disturbances of the swinging leg. Since it is a very popular algorithm, it is often used as the baseline method. Its effect may not be the best, but it is a very stable and widely applicable algorithm. It is an on-policy algorithm based on the actor–critic framework. Videos of the experimental results can be found at
https://github.com/houshang1991/dsrb-mpc.git (accessed on 7 October 2020). The main contributions of this paper are as follows:
The SRB-based MPC method generally assumes that the robot’s leg mass has a negligible effect on its locomotion. However, the mass of the legs of most biped robots accounts for a large proportion of the total mass, which will disturb the locomotion of the SRB model. We describe the disturbances of the swinging leg as the centroid acceleration disturbance and the rotational acceleration disturbance. Furthermore, we use the PPO algorithm to train a policy to accurately predict the disturbances of the swinging leg.
In this paper, we improve the SRB-based MPC method by adding the disturbances of the swing leg to the SRB model. This method can give the true optimal ground reaction forces (GRFs), enabling the biped robot to resist the disturbances of the swinging leg while tracking the desired forward velocity.
In this paper, we verify the improved SRB-based MPC method through three simulation experiments. Experiments show that the disturbances of the swinging leg can be accurately predicted and resisted. We expand the scope of application of the SRB-based MPC method, and provide a robust control method for biped robots with non-negligible leg mass.
2. Control Architecture
The control method proposed in this paper consists of four parts, as shown in
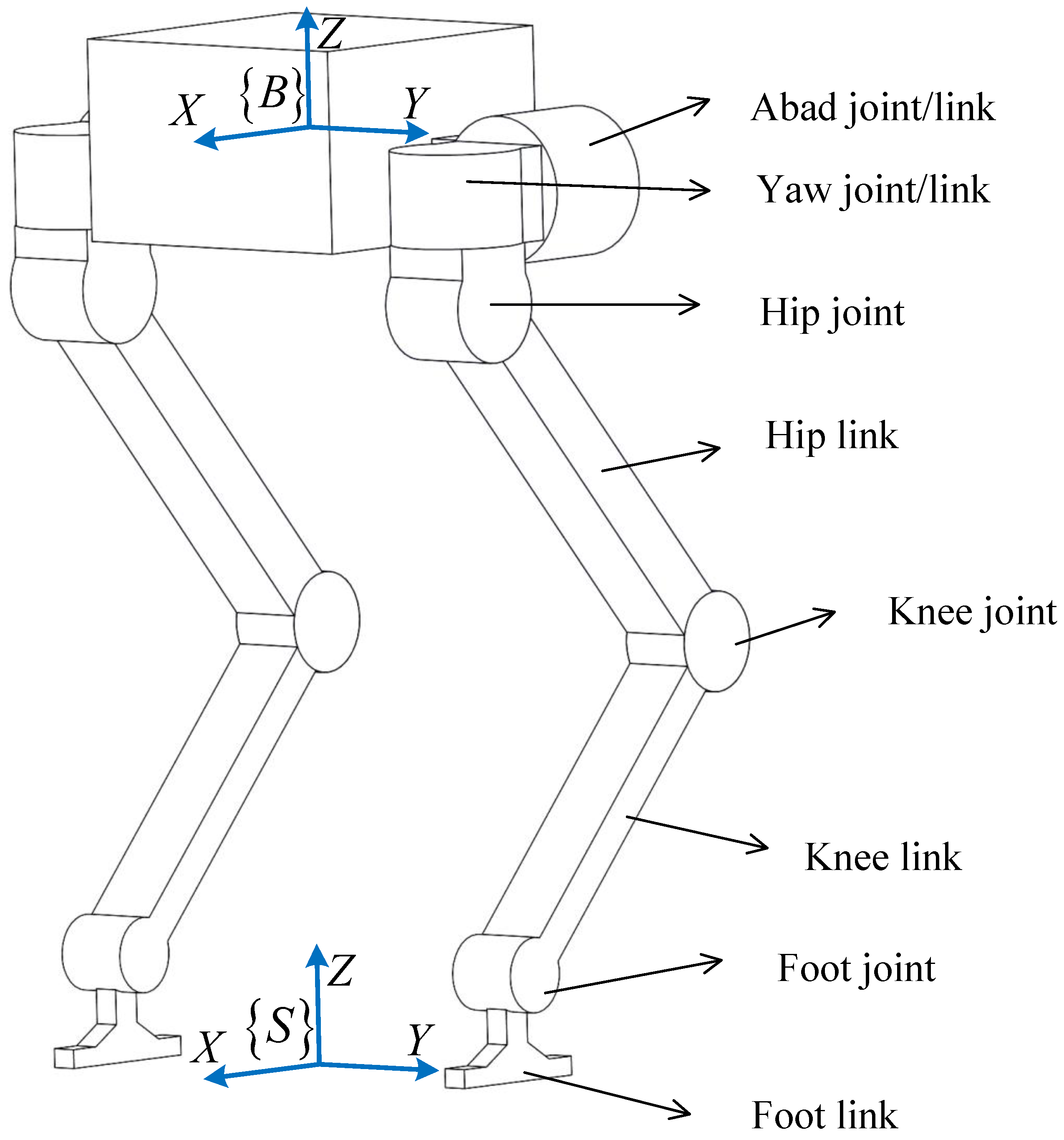
Figure 1. A finite state machine (FSM) is responsible for generating a walking gait pattern. The swing leg controller is responsible for solving the joint torque of the swing leg. The stance leg controller uses the MPC based on a modified SRB model to solve for the optimal GRFs. The trained policy is responsible for predicting the disturbances caused by the swinging leg to the SRB model. The structure of the biped robot used in this paper is shown in
Figure 2. This section mainly introduces the first three parts.
2.1. Finite State Machine
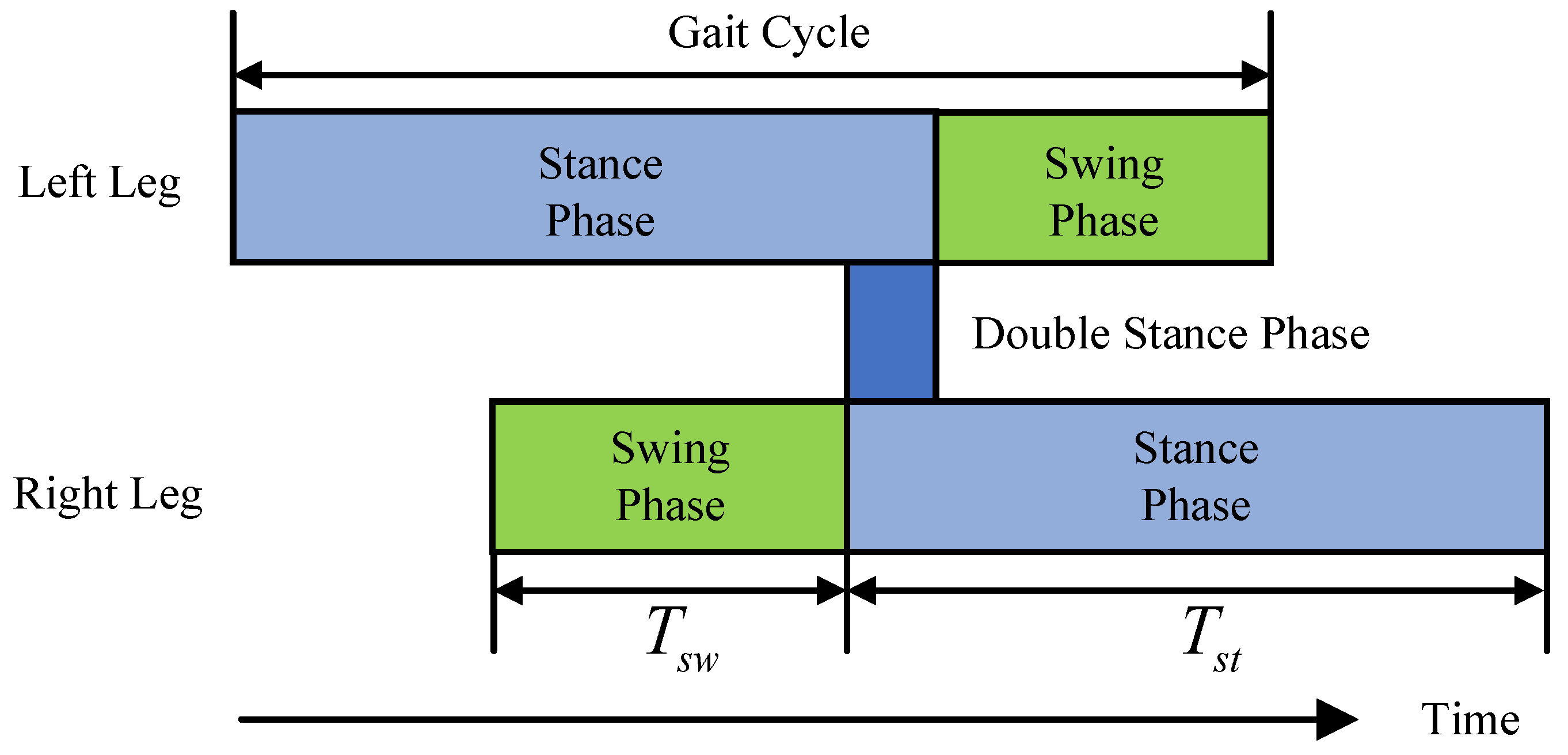
The FSM generates a walking gait pattern based on the fixed swing duration and stance duration. It gives the time phase (swing phase or stance phase) that each leg is in at the current moment and the percentage
of completion of the current time phase. The swing phase and stance phase of each leg accounted for 40% and 60% of the entire gait cycle, respectively, of which the double stance phase accounted for 10%. The walking gait pattern is shown in
Figure 3. In this paper, the swing phase duration
is equal to 0.12 s, and the stance phase duration
is equal to 0.18 s.
2.2. Swing Leg Controller
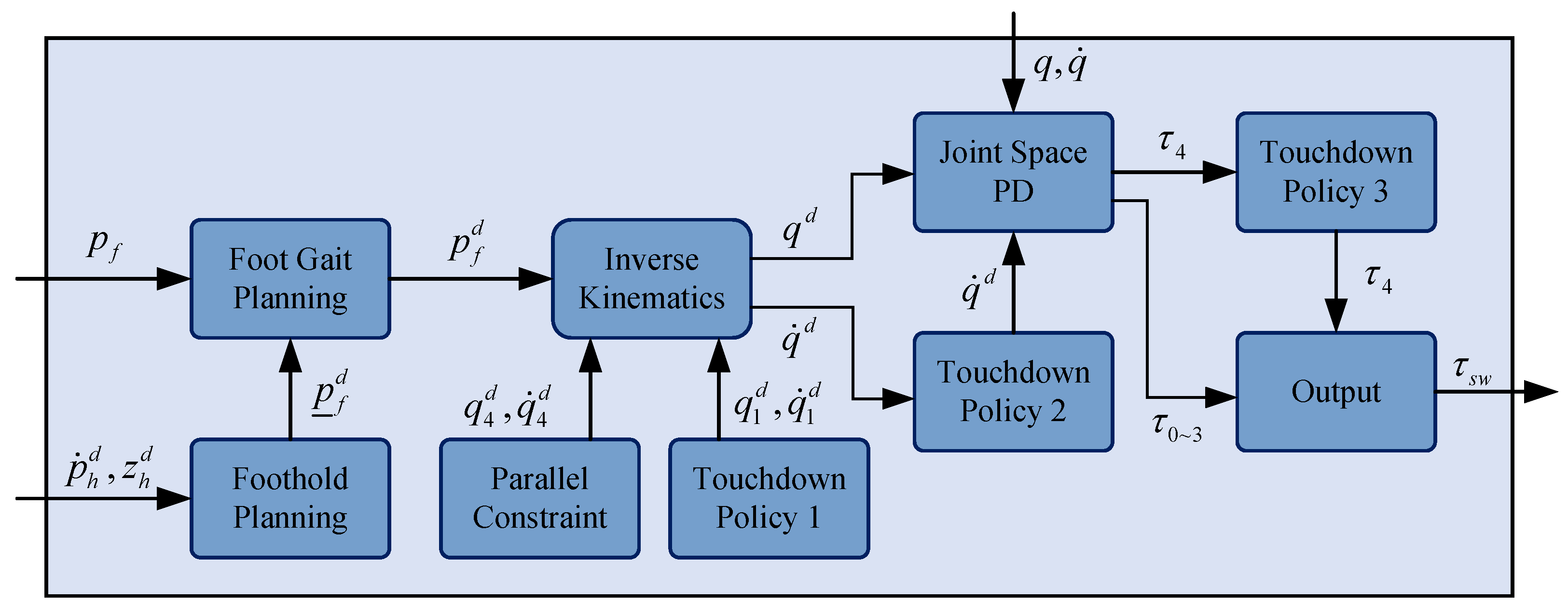
The block diagram of the swing leg controller is shown in
Figure 4. The swinging leg controller firstly solves the desired foothold point
. Then it calculates the desired foot position
according to
. Then it calculates the desired joint position
and velocity
according to the inverse kinematics of the leg. It finally calculates the joint torques
through a PD controller in the joint space. To alleviate the impact on the body when the swinging leg touches the ground, this paper applies three touchdown policies to ensure the stability of the robot’s motion.
The touchdown policy 1 is to imitate the habit of human walking and increase the lateral stability of the biped robot. It adjusts the angle of the yaw joint in real time, making the toe slightly outward. It works from the beginning to the end of the swing phase, tracking a set initial yaw joint angle in real time. In the simulation environment, the collision between the foot of the swinging leg and the ground is the elastic collision. The touchdown policy 2 sets the desired speed of each joint to 0 so that the command speed output by the PD controller is as small as possible. It can reduce the impact of elastic collision on the motion state of the robot. It works just before the foot touches the ground until the end of the swing phase. Before the foot of the swinging leg is fully in contact with the ground, the yaw joint torque output by the PD controller may cause the front or rear end of the foot to contact the ground early. As a result, unexpected elastic collisions occur, and even relative sliding between the foot and the ground occurs. The above two situations will cause significant disturbances to the motion state of the robot. The touchdown policy 3 also starts working near the end of the swing phase, and by forcing the yaw joint torque to zero, the above-mentioned accidents can be avoided to the greatest extent possible. The above three touchdown policies are run synchronously, but the start time is different, and the specific situations to be dealt with are different. However, their ultimate goal is to improve the stability of the robot’s locomotion.
In foothold planning, we use the following formula to calculate the real-time desired foothold position:
where
is the desired foot landing point on the horizontal ground represented in
;
is the projection of the actual position of the hip joint on the horizontal ground represented in
;
is the projection of the desired speed of the hip on the horizontal ground represented in
;
is the projection of the actual speed of the hip on the horizontal ground represented in
;
is the desired height of the hip from the ground;
is the duration of the swing phase; and
g is the acceleration of gravity.
In foot-gait planning, the desired foot position in the joint space is generated by fitting a 6th-order Bezier curve. Note that the joint positions and velocities mentioned below are representations in the joint space. To imitate the toe outstretching behavior of human walking and enhance the stability of dynamic walking, touchdown policy 1 adjusts the desired position and desired speed of the yaw joint of the biped robot in real-time. For the foot to be in full contact with the ground at the end of the swing phase, we add a horizontal constraint with the foot parallel to the ground. According to this constraint, the desired position and desired velocity of the foot joint can be solved.
Except for the yaw joint and the foot joint, each leg of the biped robot has 3 degrees of freedom, and the inverse kinematics happens to have a unique solution. According to the desired foot joint position, the desired position and velocity of the abad, hip, and knee joints can be solved. To reduce the impact on the ground, when , touchdown policy 2 sets the desired velocity of all joints of the swinging leg to 0 . Touchdown policy 2 further improves the stability of the biped robot when the leg transitions from the swing phase to the stance phase.
After solving for the desired positions and velocities of all joints, we filter the actual joint velocities using a first-order digital low-pass filter with a cutoff frequency lower than the operating frequency of the swing leg controller. Then, this paper uses a PD controller in joint space to calculate the torque of each joint according to the actual joint position errors and joint velocity errors:
where
q and
are the actual joint position and velocity vector, respectively;
and
are the desired joint position and velocity vector, respectively; and
and
are the error gain matrices of the PD controller, respectively.
When , touchdown policy 3 sets the foot joint torque to 0 . When the foot touches the ground, touchdown policy 3 can reduce the impact caused by the fluctuation of the foot joint torque.
2.3. Stance Leg Controller
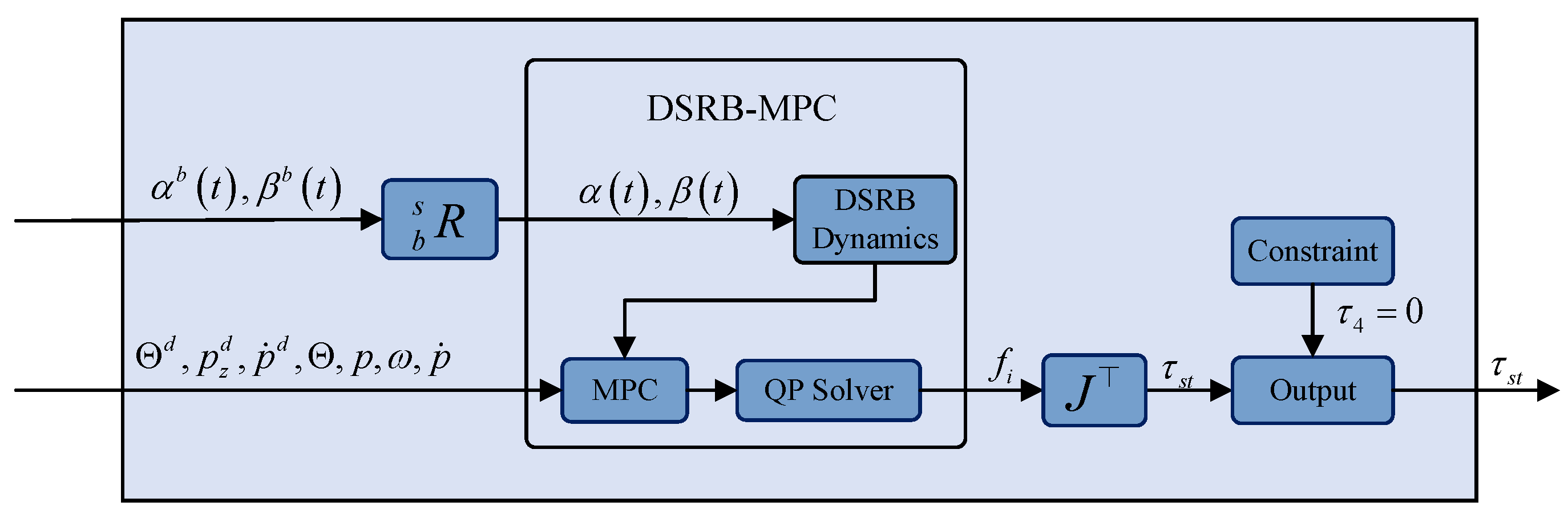
The block diagram of the support leg controller is shown in
Figure 5. We treat the body of the biped robot as the SRB model that can move and rotate freely in 3D space. We add external disturbances to the centroid acceleration and rotational acceleration of the model, and call the new model the disturbed single rigid body (DSRB) model. Unlike the original SRB-based MPC (SRB-MPC) method, we treat the effect of swinging the leg on the locomotion of the body as two predictable bounded disturbances. Then, the optimal GRFs at the foot of the stance leg can be solved by the DSRB-based MPC (DSRB-MPC) method.
The approximate linear dynamics of the DSRB model are as follows:
where
p is the position of the center of mass of the body;
is the acceleration of the center of mass of the body;
is the rotational angular velocity of the body;
is the rotational acceleration of the body;
m is the mass of the body;
is the reaction force exerted by the ground on the center of mass of the body through the
ith foot;
is the moment arm of
;
I is the inertia tensor of the body;
and
are the uncertain centroid acceleration and rotational acceleration disturbances imposed by the outside on the body expressed in
, respectively; and
n is the number of legs of the robot.
Equations (
3) and (
4) can be rewritten as the following equation of state:
where
is the Euler angles in ZYX order, representing the orientation of the body;
is the rotation matrix, which transforms from
to
;
is the zero matrix;
is the identity matrix; and
is the skew-symmetric matrix generated by the vector
d.
We take the discrete form of the state Equation (
5) as the equality constraint, the friction cone constraints of the GRFs as the inequality constraint, and the quadratic form of the state error and input as the objective function. The problem of solving the optimal GRFs can be written in the following standard MPC form:
where
k is the horizon length;
is the predicted state of the system at the
ith moment;
is the reference state of the system at the next time after the
ith moment;
is the input of the system at the
ith moment;
is the discrete form of Equation (
5) at the
ith moment;
is the friction cone constraints at the
ith moment; and
Q and
R are diagonal positive semi-definite matrices of weights.
Equation (7) can be rewritten as the following compact form:
where
is the state trajectory of the system in the horizon;
is the input sequence of the system in the horizon.
Finally, we put Equation (
9) into Formula (
6), and the standard MPC problem can be simplified as the following standard QP problem:
where
is a block diagonal matrix composed of
Q;
is a block diagonal matrix composed of
R;
is a block diagonal matrix composed of
;
is made up of stacks of
;
is made up of stacks of
; and
is the state reference trajectory of the system in the horizon.
Considering that the output torque of the actuator at the foot joint of most biped robots is small, we take the foot joint as a passive joint and constrain the output torque of this joint to 0
. Under the above assumptions, the biped robot cannot achieve static stability, but can only achieve dynamic stability, and its control difficulty increases. The output torque of each joint except the foot joint is given by
where
J is the foot joint Jacobian.
To improve stability, we also perform first-order low-pass filtering on the centroid velocity and rotation velocity of the body in the stance leg controller. The cutoff frequency of the filter is lower than the operating frequency of the stance leg controller.
4. Simulation and Experimental Results
In this work, we choose PyBullet as the physics simulation engine and use Gym to build the reinforcement learning environment. We choose the Blackbird robot as the platform for our simulation experiments. The mass parameters of the model 2 used in the simulation are shown in in
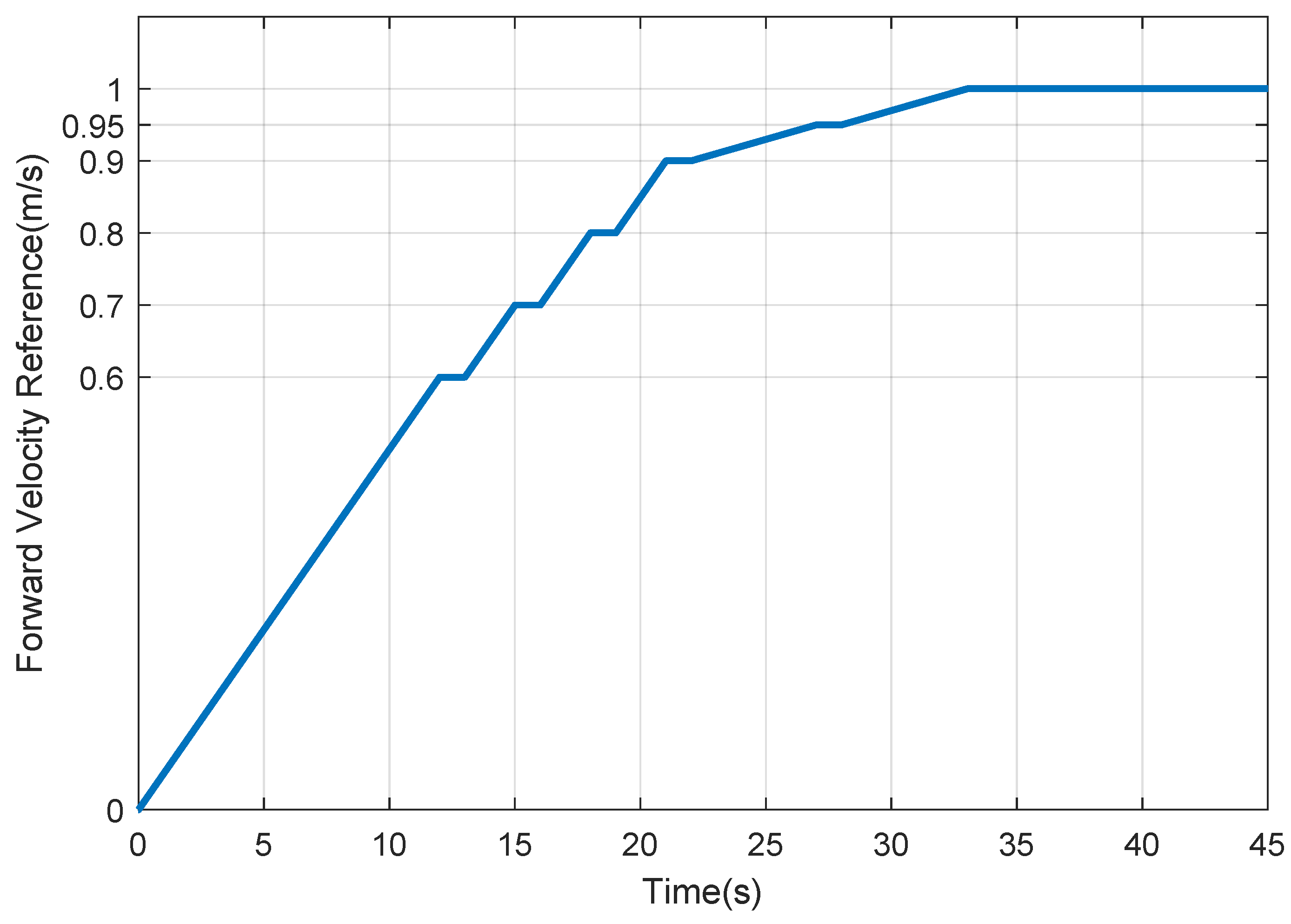
Table 1, where it can be seen that the mass of the two legs accounts for 30.5% of the total mass. The forward reference velocity used is shown in
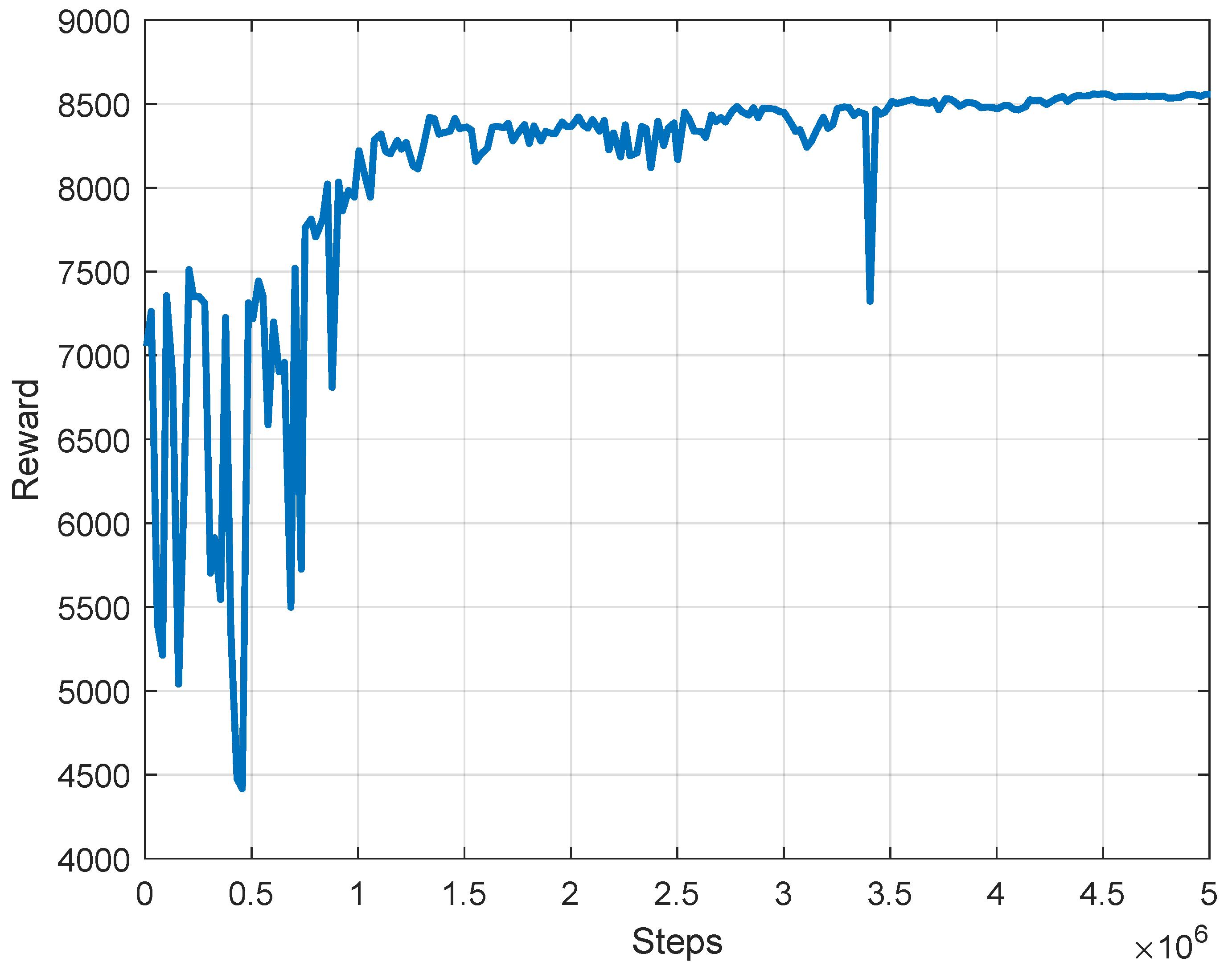
Figure 6. After 5 million steps of learning, we obtained the target policy
for predicting the disturbance of the swinging leg, and the reward curve of the learning process is shown in
Figure 7. The initial reward value fluctuates greatly, and after 1 million steps of learning, the reward value fluctuates less. After 4 million steps of learning, the reward value converges.
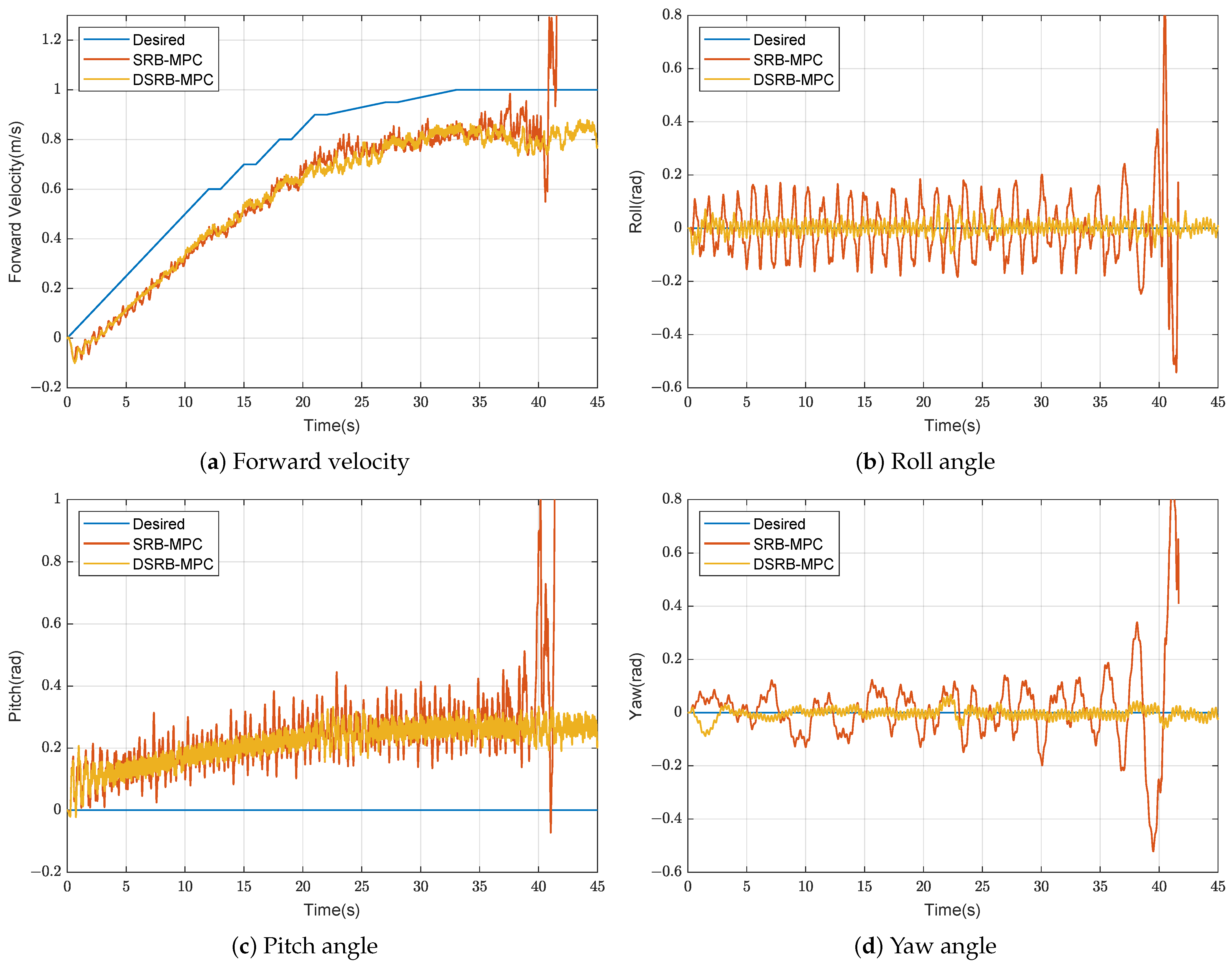
We use the trained target policy
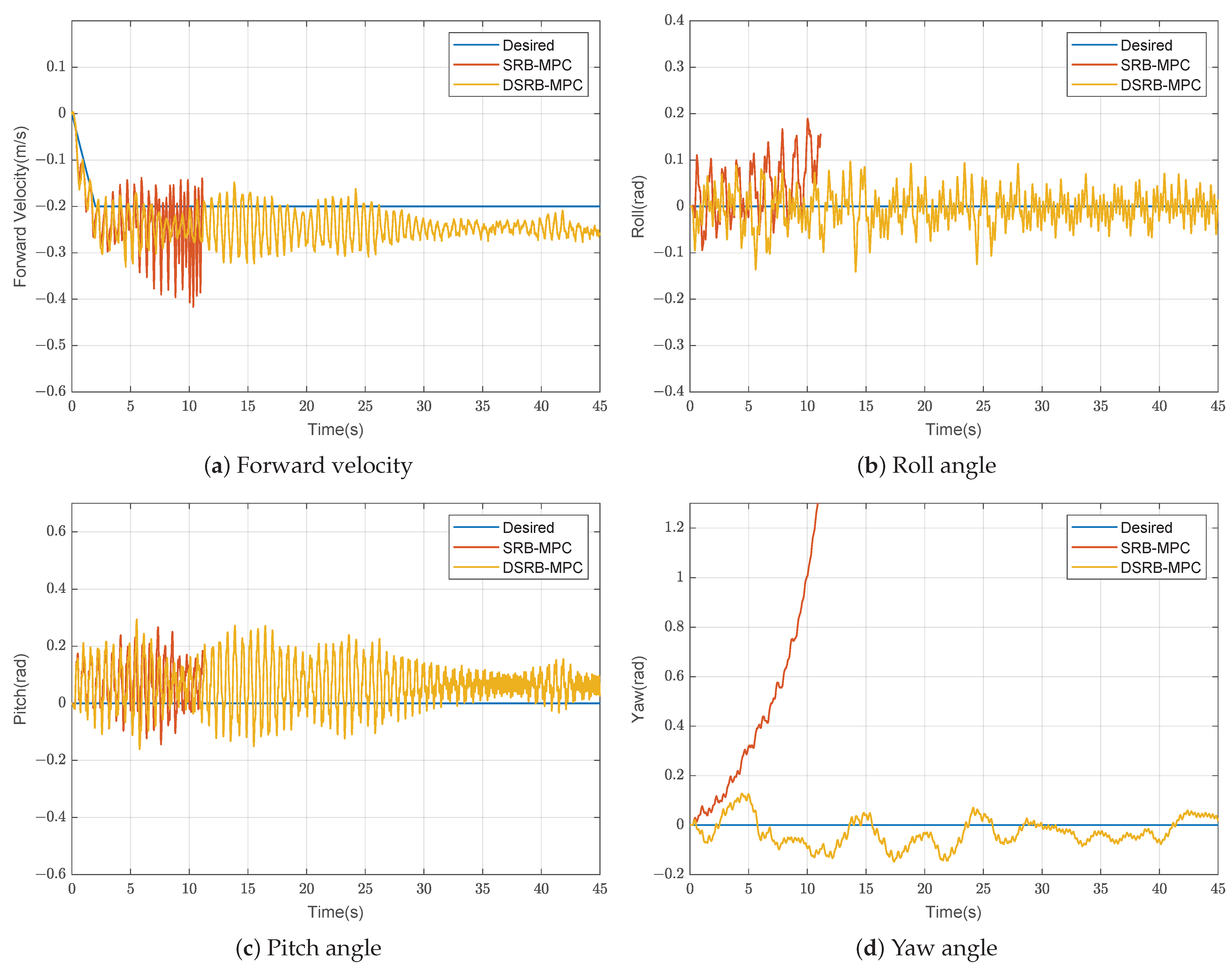
as the external disturbances input of the DSRB-MPC method, and compare it with the SRB-MPC method. The results are shown in
Figure 8. The results showed that the swinging leg has a larger effect on the Euler angles of the robot relative to the velocity of the center of mass. As the velocity of the center of mass increases, the SRB-MPC method cannot suppress the fluctuation of the Euler angles, especially the yaw angle. Due to the violent oscillation of Euler angles, the stance leg controller does not work properly. As a result, the center of mass velocity increases rapidly, and finally the robot falls at 40 s. It can be seen from the training results that the fluctuation of the Euler angles of the DSRB-MPC method is much smaller than that of the SRB-MPC method. The centroid velocity of the DSRB-MPC method is also slightly smoother than that of SRB-MPC method. It is further proved that the policy
learned by the PPO method can accurately predict the disturbances of the swinging leg to the biped robot during the forward locomotion. The disturbances consist of the centroid acceleration disturbance and the rotational acceleration disturbance.
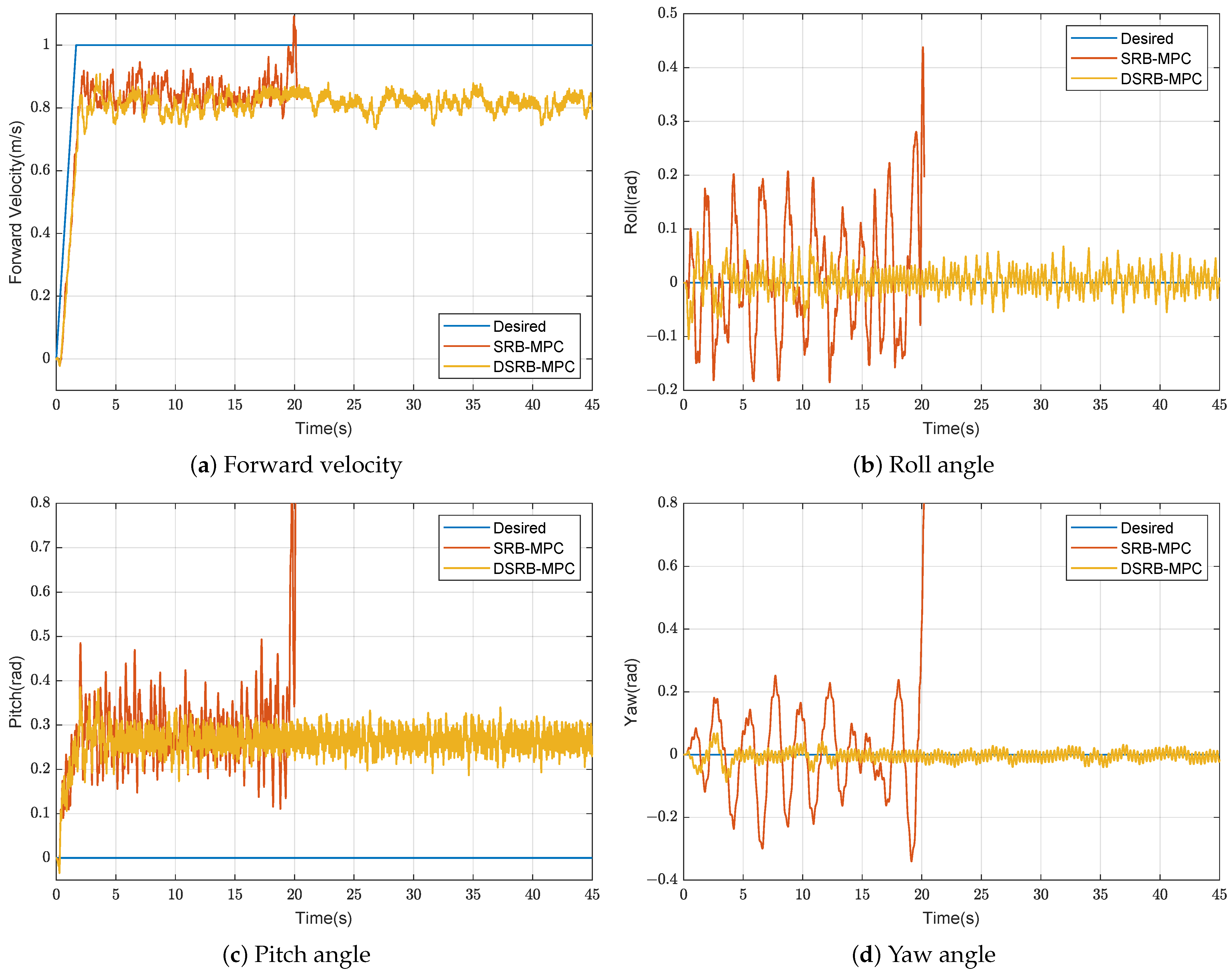
In order to verify the robustness of the DSRB-MPC under the higher acceleration, we tested the performance of the method under the extreme acceleration
, as shown in
Figure 9. The SRB-MPC method falls at 20 s earlier than the previous experiment. From the performance of the SRB-MPC method, it can be seen that the fluctuation of the Euler angles is larger than that of the previous experiment, which indicates that the disturbances of the swinging leg are related to the commanded centroid acceleration. As the command acceleration increases, the centroid acceleration disturbance and the rotational acceleration disturbance are also larger. However, the centroid velocity and Euler angles fluctuations of the DSRM-MPC method are still small. The policy
still predicts the disturbances of the swinging leg accurately.
Through experiments, we found that the DSRB-MPC method can also control the robot to move in the opposite direction at a smaller speed about
as shown in
Figure 10. The SRB-MPC method falls at 10 s, earlier than the fall time in the forward locomotion experiment. From the results of the SRB-MPC method, it can be seen that the opposite locomotion is more difficult than the forward. The specific phenomenon is that during the locomotion of the robot, the yaw angle continues to increase, resulting in self-rotation. Although the fluctuations of the Euler angles and the centroid velocity of the DSRB-MPC method are larger than those of the previous two experiments, this method can still control the stable walking of the robot, and the fluctuations tend to decrease gradually.
5. Discussion
In this paper, we propose the DSRB-MPC method based on an improved SRB-MPC method and the DRL method. The new method takes into account the disturbances of the swinging leg, which enables the MPC method to be applied to bipedal robots with non-negligible leg mass. First, we add the external disturbances to the SRB model to further increase the anti-disturbance capability of the SRB-MPC method. Subsequently, we consider the effect of the swinging leg on the SRB model as the centroid acceleration disturbance and the rotational acceleration disturbance. We use the PPO method to train a policy to predict the disturbances of the swinging leg. Finally, we verify the effectiveness and robustness of the DSRB-MPC method through three experiments. The above experiments show that the SRB-MPC method has non-negligible robustness, and it does not require very high accuracy of the SRB model. The SRB-MPC method can resist a part of the disturbances causing by the swing leg and does not immediately make the robot fall. Therefore, it is meaningful for us to improve and research the SRB-MPC method and expand its application range. The above experiments also demonstrate that the policy obtained by the DRL method can accurately predict the disturbances of the swinging leg. The disturbances include two components, which are the disturbance of the centroid acceleration and the disturbance of the rotational acceleration. Based on the predicted swing leg disturbances, the DSRB-MPC method can give the truly optimal GRFs, enabling the biped robot to accurately track the forward velocity reference while resisting the disturbances. Therefore, the DSRB-MPC method is suitable for biped robots with non-negligible leg mass.
Our method is equally applicable to quadrupeds, as the SRB-MPC method is applicable to quadrupeds, and our method is an improvement on it. Some quadruped robots also have the problem that the portion of leg mass is relatively large. Our method can also alleviate the influence of the swing leg on the overall motion of the robot, thereby improving the stability. However, due to the structural characteristics of the quadruped robot itself, it has the better stability than the biped robot. Therefore, the improvement of this method for quadruped robots will not be as significant as that for biped robots.
However, this method also has some shortcomings. First, the larger the proportion of the leg mass to total mass, the more difficult it is to predict the disturbances. When the proportion exceeds 30%, the method cannot guarantee the stability of the biped robot. Second, it does not eliminate the static velocity error.
In the future, we consider to continue to enhance the robustness of the DSRB-MPC method to break through the limitation that the leg mass accounts for 30% of the total mass. We plan to take the following approaches to predict the disturbances caused by the larger proportion of leg mass. Improve the reward function so that it better reflects the relationship between disturbances and the state of the swinging leg. Replacing the existing actor and critic network with a long-short-term memory network; combining the current state of the swinging leg with the state of the previous moment can give a more accurate prediction of disturbances. Increasing the execution frequency of the disturbances prediction policy can predict the change of disturbances more quickly. We also consider eliminating the static velocity error of this method and realizing the stable walking of the biped robot in complex environments. We plan to take the following approaches to eliminate the static velocity error. By designing an adaptive algorithm, the weight coefficients and prediction horizon of MPC can be dynamically adjusted according to the desired velocity and the actual velocity. Since increasing the weight coefficient of the velocity error as much as possible can reduce the static velocity error, by increasing the running frequency of the MPC as much as possible, the influence of the model errors on the controlled object can be reduced, thereby reducing the static velocity error. We would add a feedback controller before MPC to output the compensated desired velocity according to the given desired velocity and actual velocity, and use the compensated desired velocity as the input of MPC.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}