1. Introduction
A complex system, for instance, control system [
1], servo system [
2], energy storage system [
3], is widely used in aviation, aerospace, electronics and other fields. Due to the complex structure and poor working environment, the system performance can be degraded, which affects the operation reliability of the system. Therefore, it is crucial to assess the health status of the complex system to provide decisions for management and maintenance [
4].
In the current research of health assessment, there are mainly three methods called the data-based method, the qualitative knowledge-based method, and the semi-quantitative information-based method. The data-based methods assess the system performance by fitting the nonlinear relationship between the input and output of the system based on observation data, such as deep learning, neural network [
5,
6,
7]. Since it is a pure black-box modelling, the assessment results cannot be explained, and there is a problem of overfitting. The qualitative knowledge-based methods provide interpretable assessment progress based on the operation mechanism of the system and expert knowledge, for example, fuzzy reasoning, belief rule base [
8,
9]. Due to the subjectivity of expert knowledge, the model assessment accuracy is poor. The semi-quantitative information-based methods provide both qualitative knowledge and quantitative data concurrently, providing interpretable and accurate assessment results [
10]. Therefore, the health assessment based on semi-quantitative information is basically concentrated in this paper.
The evidential reasoning (ER) rule [
11], as a representative semi-quantitative information-based method, originated from the Dempster-Shafer (DS) evidence theory [
12], and is regard as a generalized Bayesian inference process [
11]. DS evidence theory is regarded as a special case of ER, when the indicator reliability is equal to 1 [
13]. In the ER rule, the quantitative data and qualitative knowledge can be effectively integrated by adopting the orthogonal operations. Reference value is introduced to divide the input information status, then the initial evidence can be generated. To deal with the data uncertainty, the evidence weight and reliability are introduced. Particularly, the weight reflects the relative importance of multiple pieces of evidence in the aggregation of evidence. The reliability reflects the ability of the information sources to provide correct information. The reliability is influenced by the performance of the information source and external noise [
14]. By clearly differentiating the two concepts, the ER rule is widely used in many fields, such as multi-attribute decision-making [
15], fault diagnosis [
16], health assessment [
17], etc.
When using the ER rule to assess the health status of a complex system, a set of mutually exclusive and collectively exhaustive assessment result grades need to be settled in advance. First, health assessment indicators are selected, and the indicators are equivalent to evidence. Then, input indicator reference grades are introduced to conveniently collect the initial evidence pointed to the assessment grades. Finally, the initial evidence, evidence weight and reliability are integrated based on the ER rule, and the health assessment results of the complex system can be obtained. Therefore, as an important part of the assessment, indicator reference grades determine the belief distribution of initial evidence, which directly affected the assessment results.
The above assessment process determines that the input indicator reference grades and output assessment result grades strictly correspond to each other. However, in practice, the assessment result grades are determined in advance, which leads to the disaccord with input indicator reference grades. For example, the input indicator reference grades can be easily divided into “normal” and “fault” based on industry-standard, but health assessment result grades are predetermined as “health”, “subhealth”, “fault”.
In the process of health assessment, the relationship between input indicator references grades and assessment result grades does not exactly correspond to each other. Therefore, for the sake of dealing with this problem, there are two methods to solve it. First, regarding the relationship as a one-to-one correspondence [
18,
19], then the input indicator references grades can be matched with assessment result grades. Second, based on expert knowledge, adding the reference grades to realize an input and output in accordance [
4,
8]. However, the first method neglects the consistent relationship in engineering practice, and the accuracy of the assessment results is influenced. The second method violates the prior mapping relationship, resulting in randomness and no standard of the assessment result.
To deal with the mentioned issues, a new health assessment model for a complex system based on the ER rule is proposed. First, the transformation matrix is determined according to the expert’s knowledge. The input information can be converted into the initial belief distribution with regard to assessment result grades by using the rule-based information transformation technique. Thus, a general information transformation framework is constructed. Second, the evidence weight and reliability are determined by expert knowledge and the synthesis of static and dynamic characteristics separately. Then, the health assessment model of a complex system based on ER rule is constituted. Finally, to further enhance the model precision, an objective function is established to optimize the model parameters. In this paper, there are two innovations as follows:
(1) Based on transformation matrix, the mapping relationship between the antecedents and the consequent of the assessment model is established, which solves the inconsistent problem between the indicators reference grades and pre-defined assessment result grades in the engineering practice. Due to the subjectivity and limitations of the expert’s knowledge, the initial values of transformation matrix may deviate from real status, hence the need to build a optimization model to further optimize the values of transformation matrix.
(2) On the basis of parameters calculation, the optimization algorithm is employed to enhance the assessment result accuracy. Then, a complete health assessment model for complex system is constituted.
This paper is organized as follows. The framework and related problems of the health assessment model are described in
Section 2. In
Section 3, the health assessment model based on ER for a complex system is proposed. The optimization of model parameters is presented in
Section 4. In
Section 5, the bus of control system and the engines are taken as examples to validate the effectiveness of the proposed model. Conclusions and future work are defined in
Section 6.
2. Problem Formulation
The status of a complex system is mainly reflected by some indicators, called health status indicators. The observation information of these indicators can be obtained by placing the corresponding sensors or simulating them in the computers. Here, the health assessment of the complex system model is constructed as shown in
Figure 1.
It can be seen from
Figure 1 that the model mainly includes three parts: the first part establishes the mapping function to transform the input information into the initial evidence. The second part constitutes a complete assessment framework based on the calculation of parameters. Finally, the assessment model parameters need to be optimized in the third part.
The specific parameters of
Figure 1 are as follows:
(1) denotes the th health status indicator of the complex system, where ;
(2) denotes the number of assessment indicators;
(3) denotes the mapping function between the th input indicator reference grades and assessment grades;
(4) denotes the weight of the th indicator;
(5) denotes the reliability of the th indicator;
(6) denotes the initial evidence of the th indicator.
According to the model established in
Figure 1, the following two problems need to be solved in the health assessment of complex system:
(1) When assessing the health status of a complex system, the input indicators reference grades do not correspond to the assessment results grades. Therefore, Formula (1) is mainly to establish the following mapping relationship.
where
denotes
assessment result grades,
denotes
th input indicators
reference grades.
(2) The assessment model part parameters, such as indicator reference value and weight, are given by experts, which may decrease the accuracy of the assessment. Therefore, it is necessary to build an optimization model to improve the accuracy of assessment results as follows.
where
denote the indicator weight, indicator reference, transformation matrix, and assessment result grades respectively.
6. Conclusions
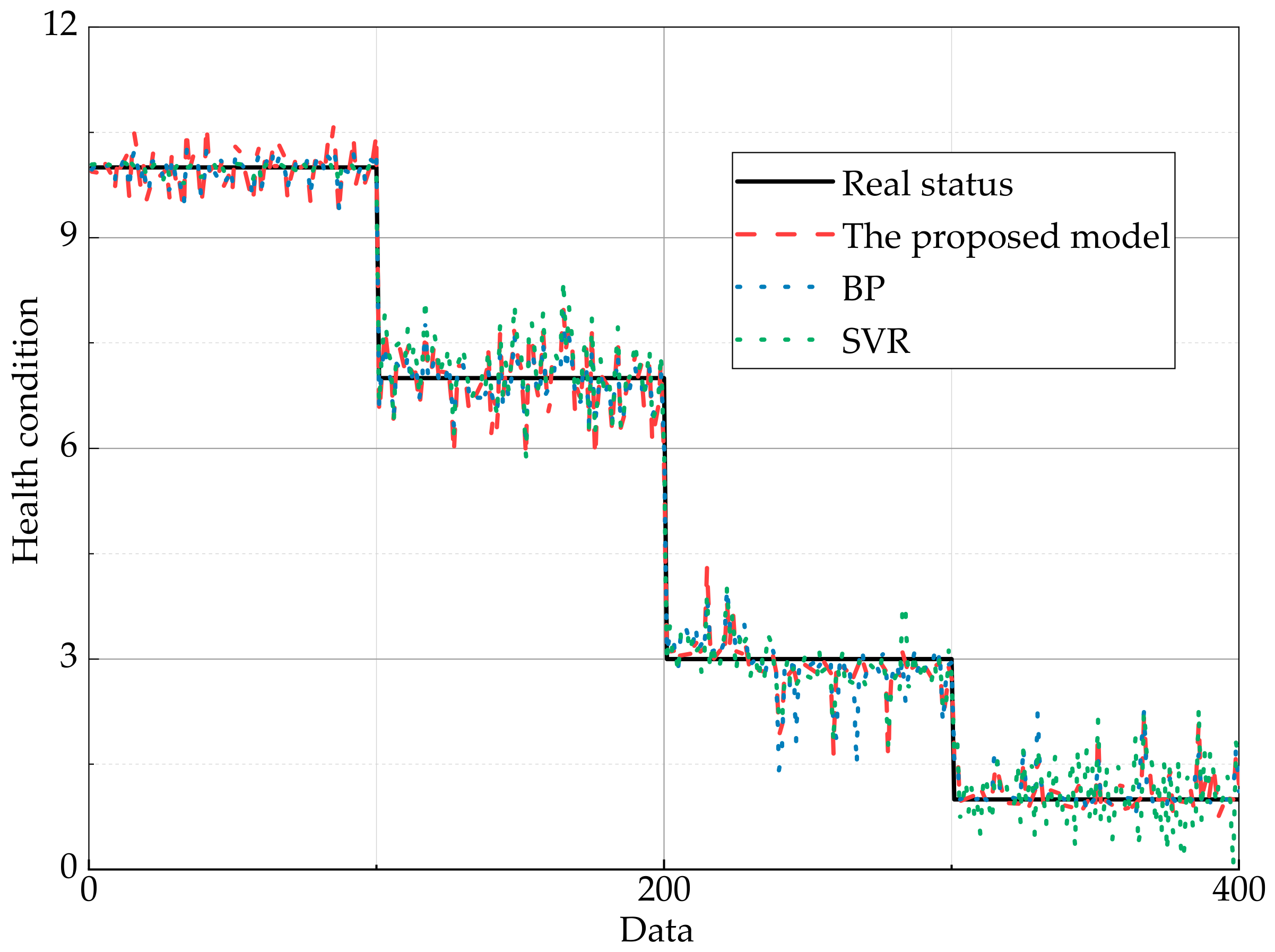
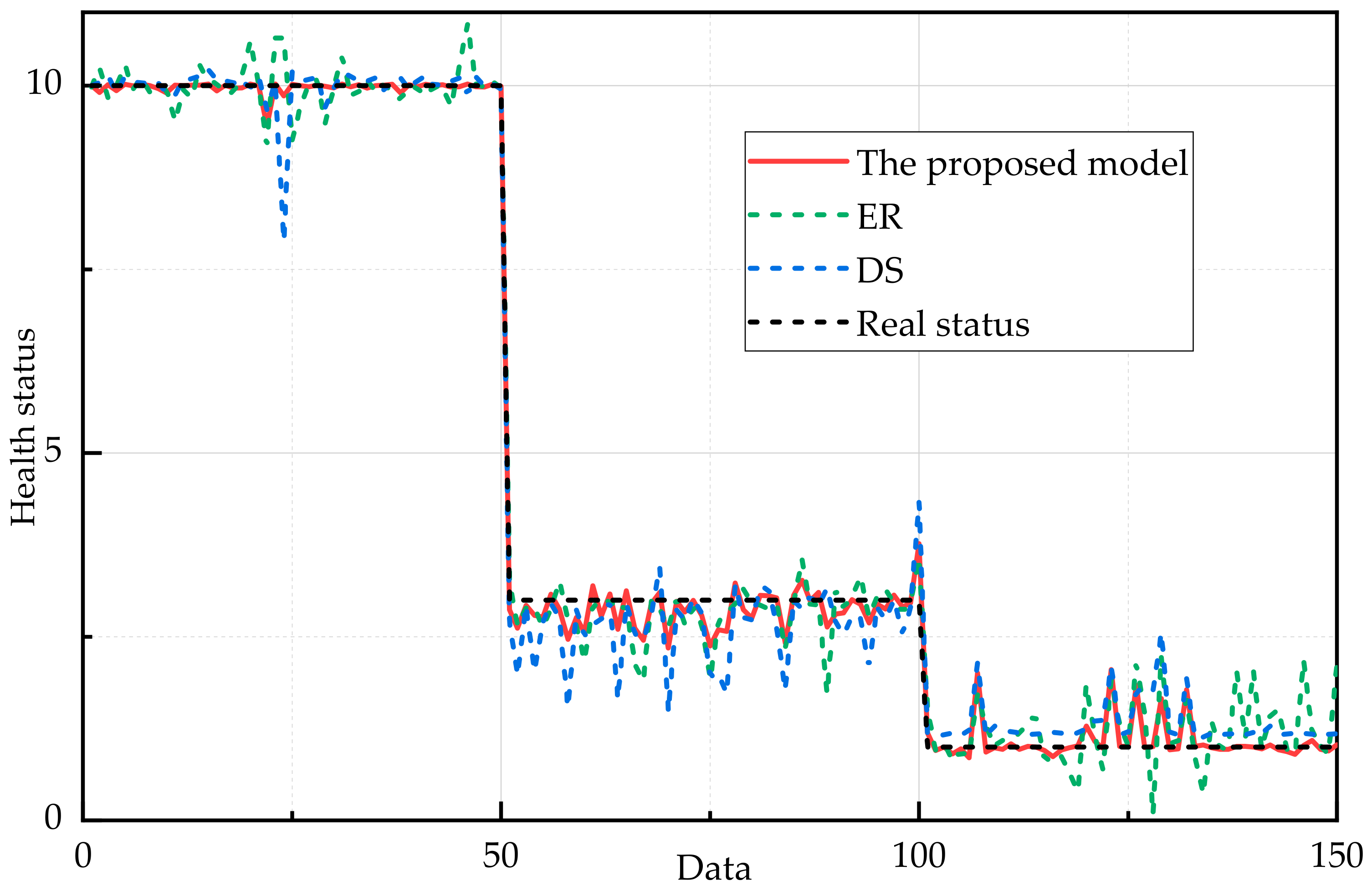
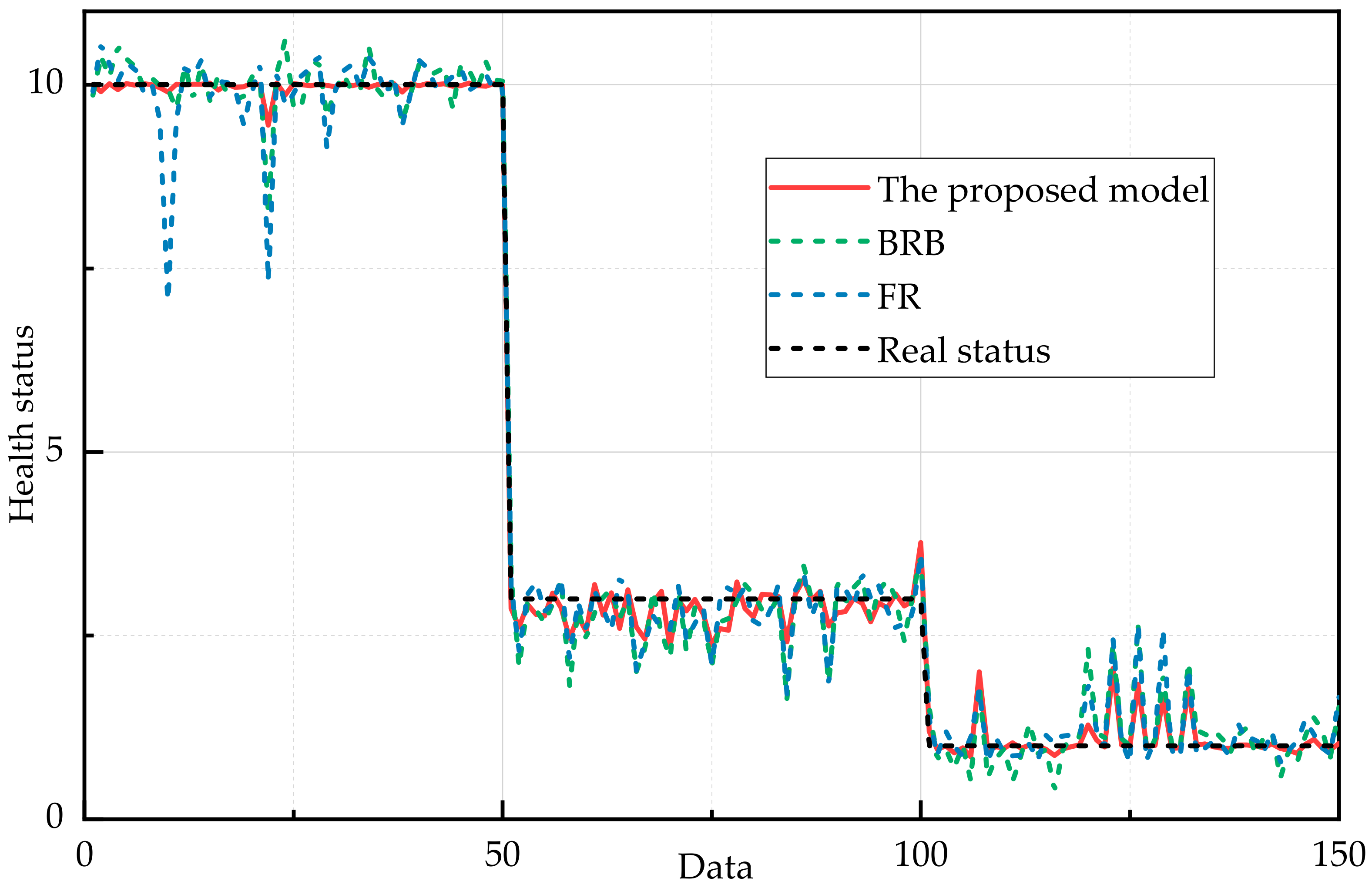
An ER rule-based health assessment model for a complex system is proposed, where the transformation matrix is considered. In addition, case study of the bus of control system and the engine is investigated to demonstrate the validity and practicality of the proposed method.
There are mainly two contributions of this paper. First, the transformation matrix is employed to solve the disaccord problem between the input indicator reference grades and assessment result grades, which keeps the consistency and completeness of the possession of the input information transformation. Second, the calculation methods of indicator weight and reliability are conducted, where the qualitative knowledge and quantitative information are fully used. Then, the optimization method of the model is conducted, and a complete health assessment model is constructed.
According to the proposed model, the future research work can be summarized into the following two points:
(1) In engineering practice, the forms of health status threshold can be various, and the forms are not only numerical, but can also be in interval form or normal distribution form. Therefore, how to solve the disaccord problem between the indicators reference grades and assessment result grades under the different forms of threshold should be addressed.
(2) The integration model between deep learning and ER rule can be established based on the good uncertainty processing ability and interpretability of ER rule.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}