
Imbalanced Fault Diagnosis of Rolling Bearing Using Data Synthesis Based on Multi-Resolution Fusion Generative Adversarial Networks

Abstract
:1. Introduction
- (1)
- A novel Multi-resolution Fusion Generative Adversarial Network (MFGAN) is proposed for fault diagnosis on unbalanced datasets. The discriminator of MFGAN is composed of three sub-discriminators, the input of each sub-discriminator is the vibration signal at different subsampling frequencies, and then the output results of the sub-discriminator are fused. MFGAN can obtain more stable training and produce high-quality synthetic data.
- (2)
- A data-enhancement method based on feature transfer and MFGAN is proposed. Specifically, we sample the input from the normal data space and then map it to the fault data space via MFGAN to obtain rich fault data, which can be used to remove data imbalances. The method reduces the difficulty of data augmentation, improves the quality of the synthetic data and can be embedded in a generative model for any similar task with good generality.
- (3)
- MFGAN is evaluated quantitatively and qualitatively through a large number of experiments, and can produce higher-quality fault data and improve the accuracy of fault diagnosis. The algorithms in the paper can be replicated using open-source code available on GitHub.
2. Related Work
2.1. Re-Sampling Method
2.2. Cost-Sensitive Learning
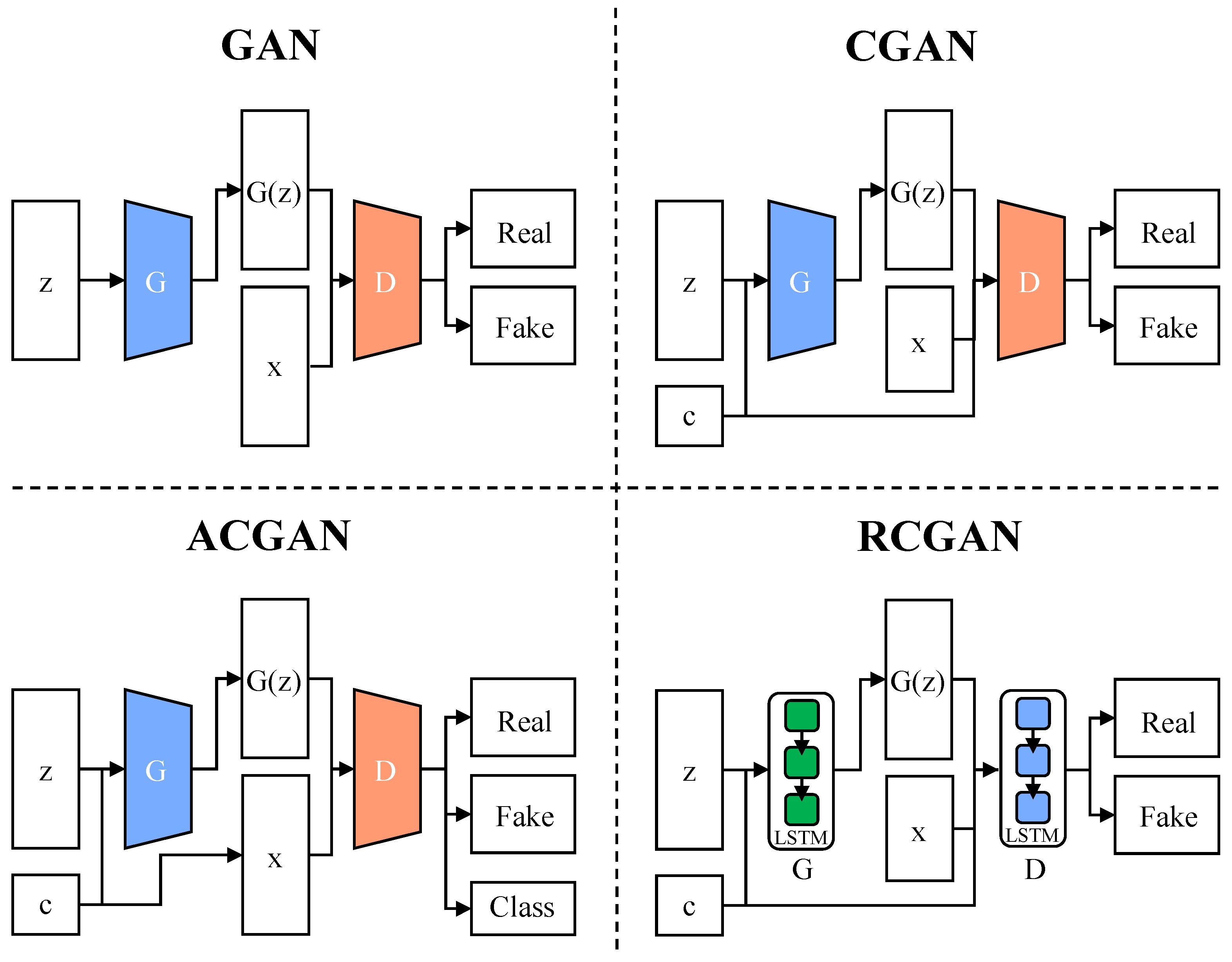
2.3. Generative Adversarial Networks
3. Model Development
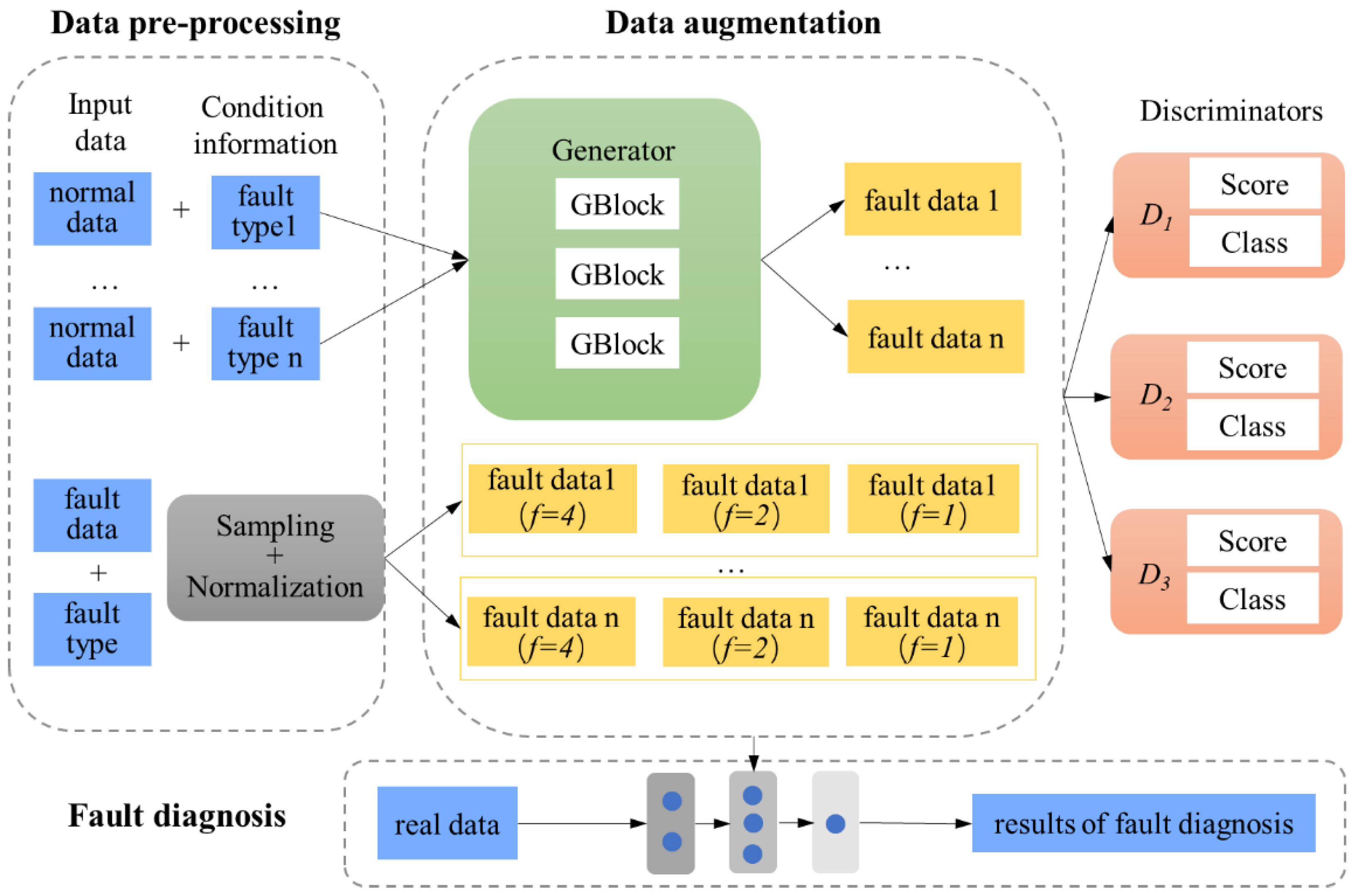
3.1. Overview
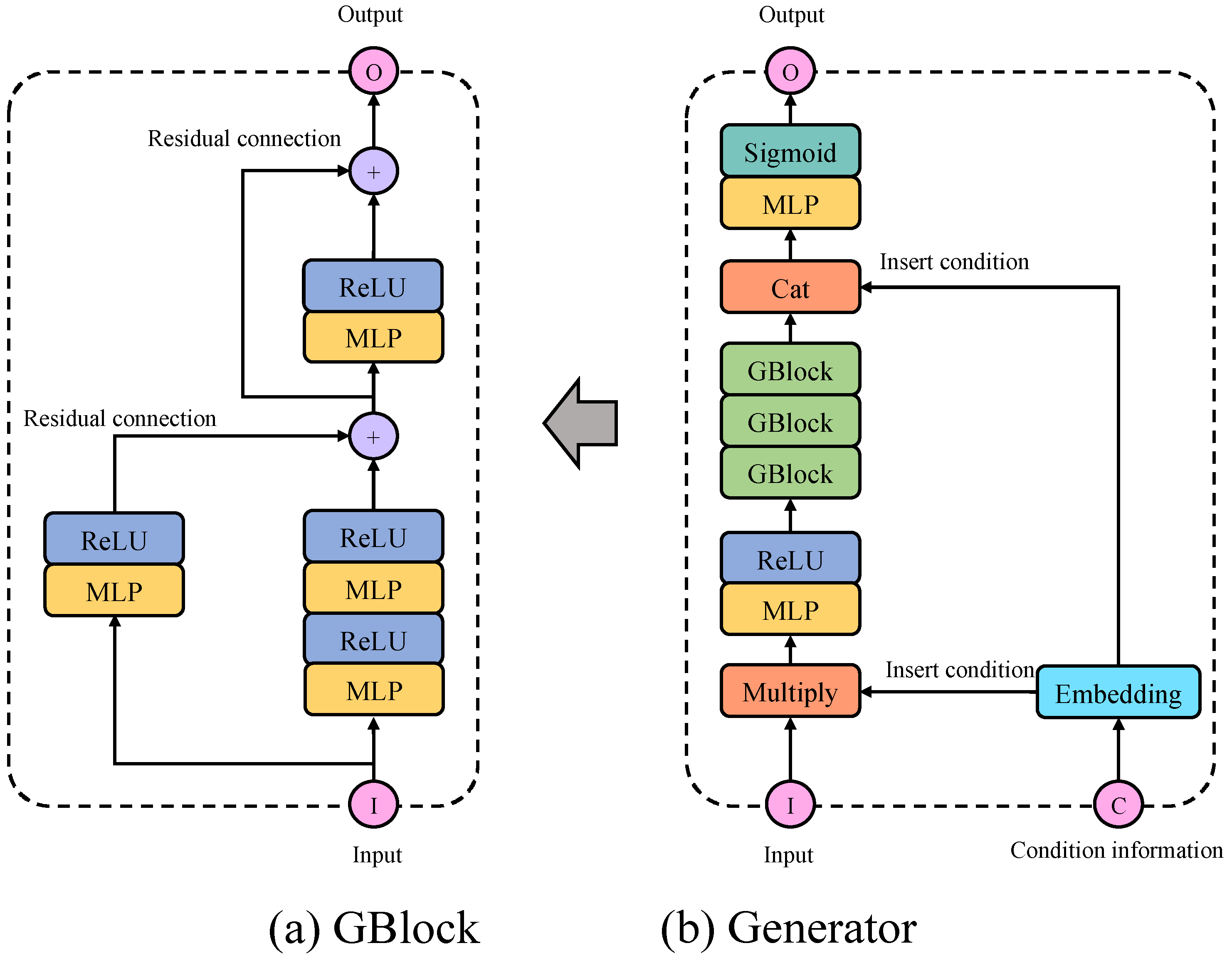
3.2. Generator Architecture
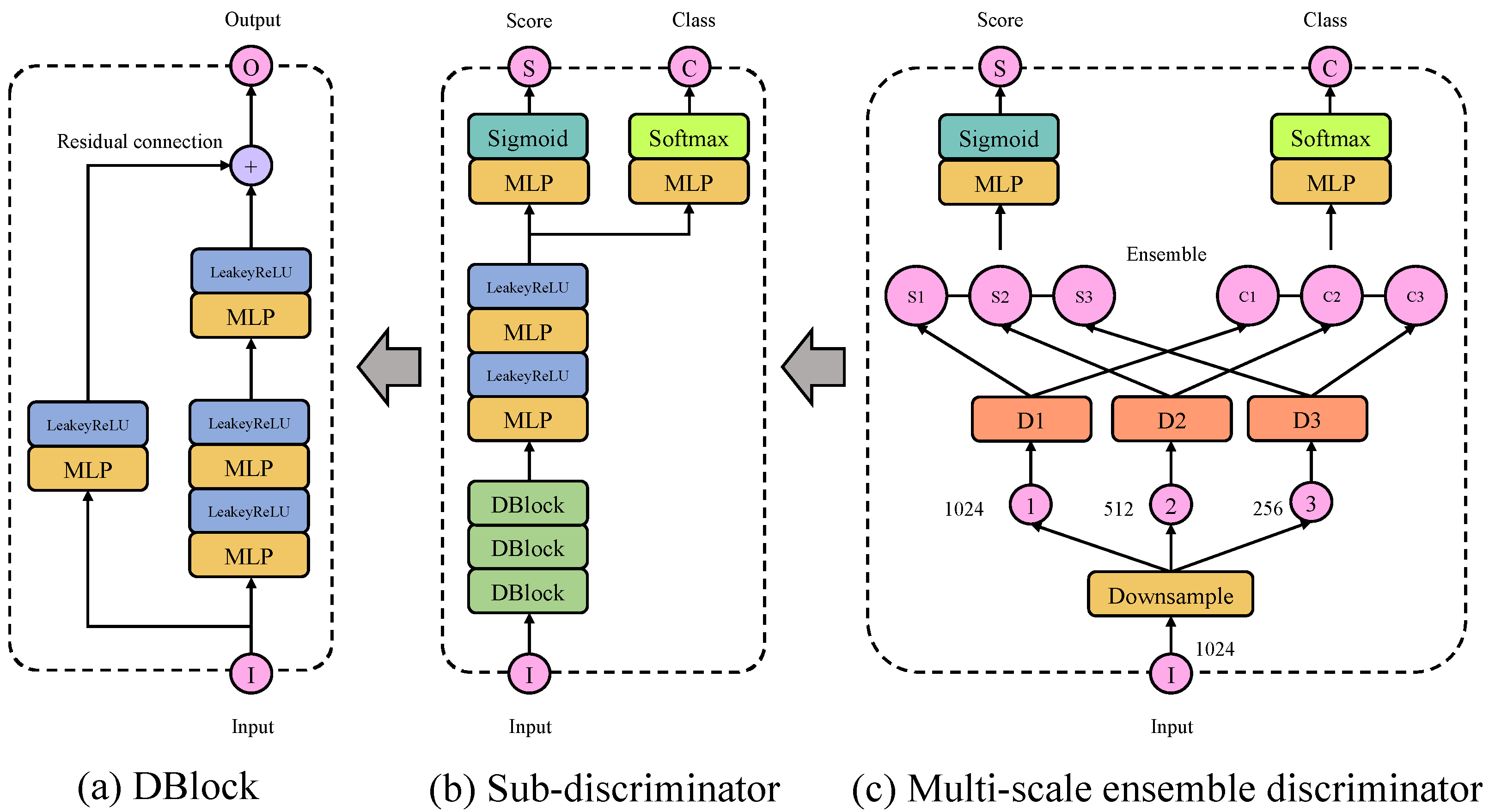
3.3. Multi-Scale Ensemble Discriminator Architecture
3.4. Training Process of MFGAN
| Algorithm 1: The algorithm for the MFGAN training process. |
| 1: Input: normal data Xn, fault data Xf, fault data label c, number of fault types K, bacthsize B, learning rate of MSED ηϕ, learning rate of generator ηθ, steps k, iterations N, weights of loss functions [w1, w2, w3, w4] 2: Output: Trained generator Gθ 3: Randomly initialize parameters θ, ϕ 4: for n = 0 → N − 1 do 5: Xn ← Shuffle(Xn) 6: [Xf, c] ← Shuffle([Xf, l]) 7: for i = 0 → k − 1 do 8: [xB f,i=1, cB i=1], XB n,i=1 ← GetSample([X, c], B), GetSample(Xn, B) 9: x’B f,i=1 ← G( xB n,,i=1, cB i=1) 10: [S′, C′], [S, C] ← MSED(x’B f,i=1, cB i=1), MSED(xB n,,i=1, cB i=) 11: Ld ← w1(+) + w2/B 12: ϕ ← ϕ − ηϕ∇ϕ(Ld) 13: end for 14: x’B f,i=1 ← G( xB n,,i=1, cB i=1) 15: [S′, C′]← MSED(x’B f,i=1, cB i=1) 16: LG ← w3) + w2/B+ w4* 17: θ ← θ − ηθ∇θ(LG) 18: if n % 50 == 0 and n > 0 then 19: ηϕ ← ηϕ/2 20: ηθ ← ηθ/2 21: end if 22: end for |
4. Experimental Methodology
4.1. Benchmark Dataset
4.2. Model Evaluation
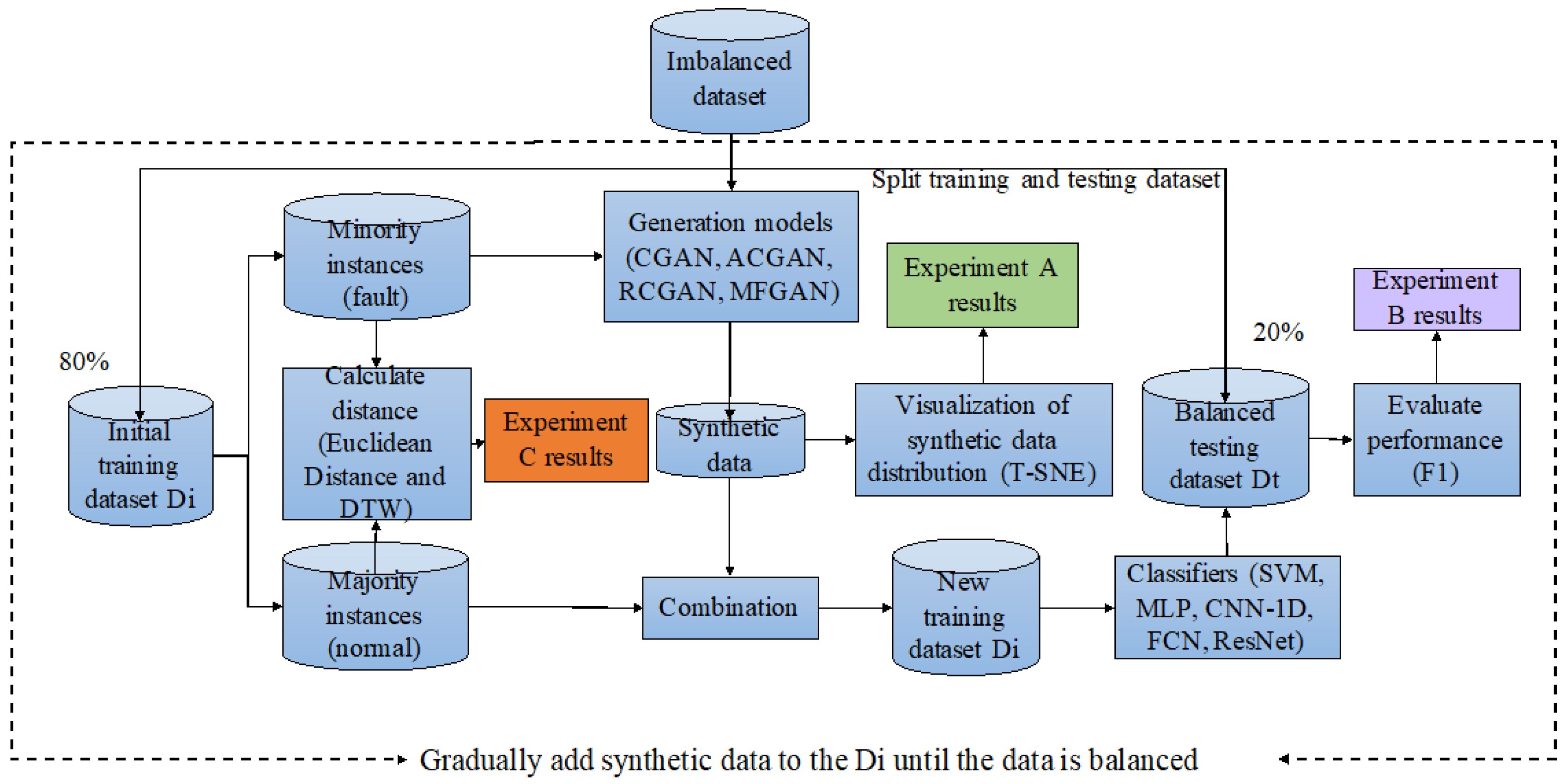
4.3. Experiment Design
4.4. Performance Evaluation and Analysis
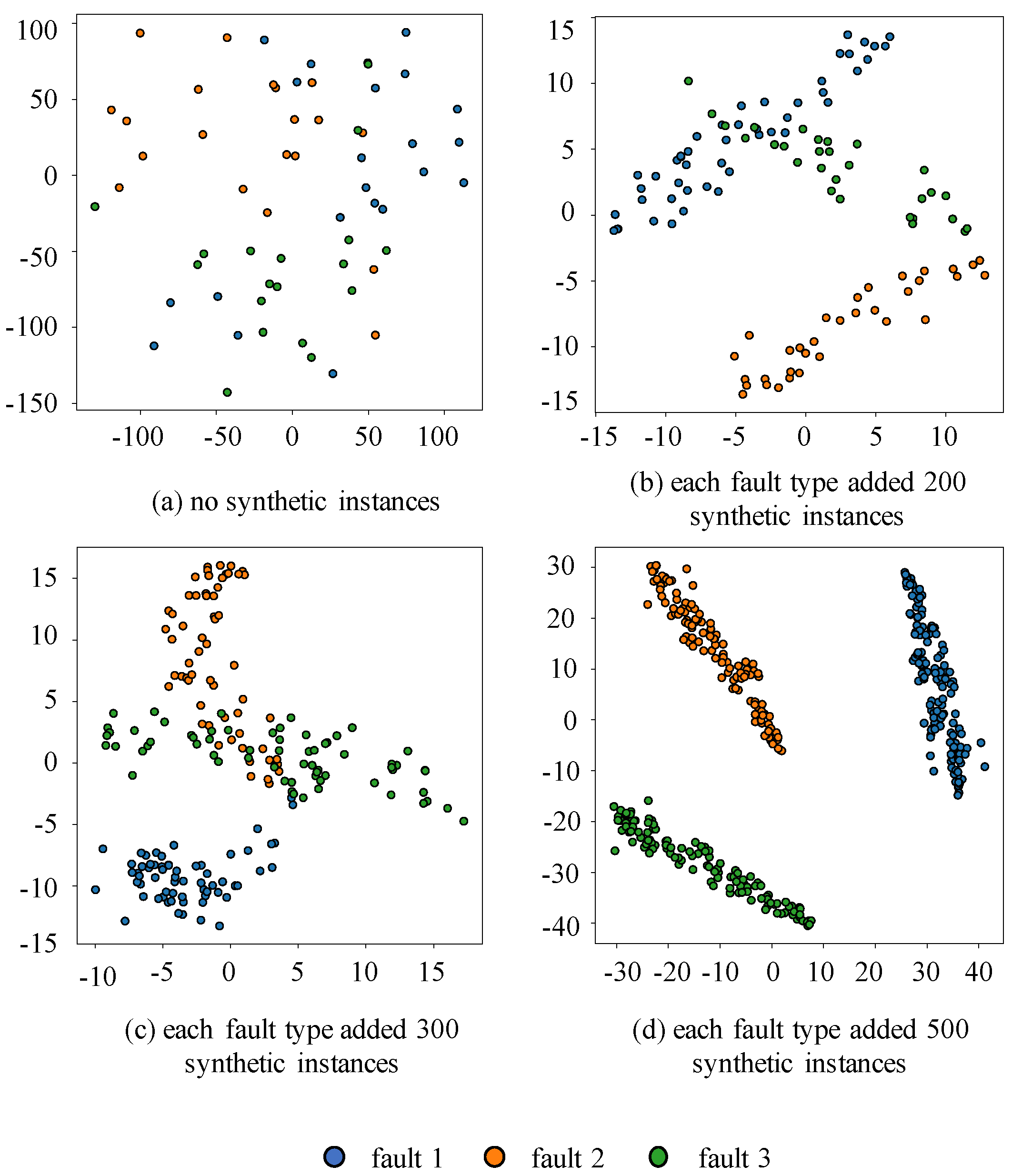
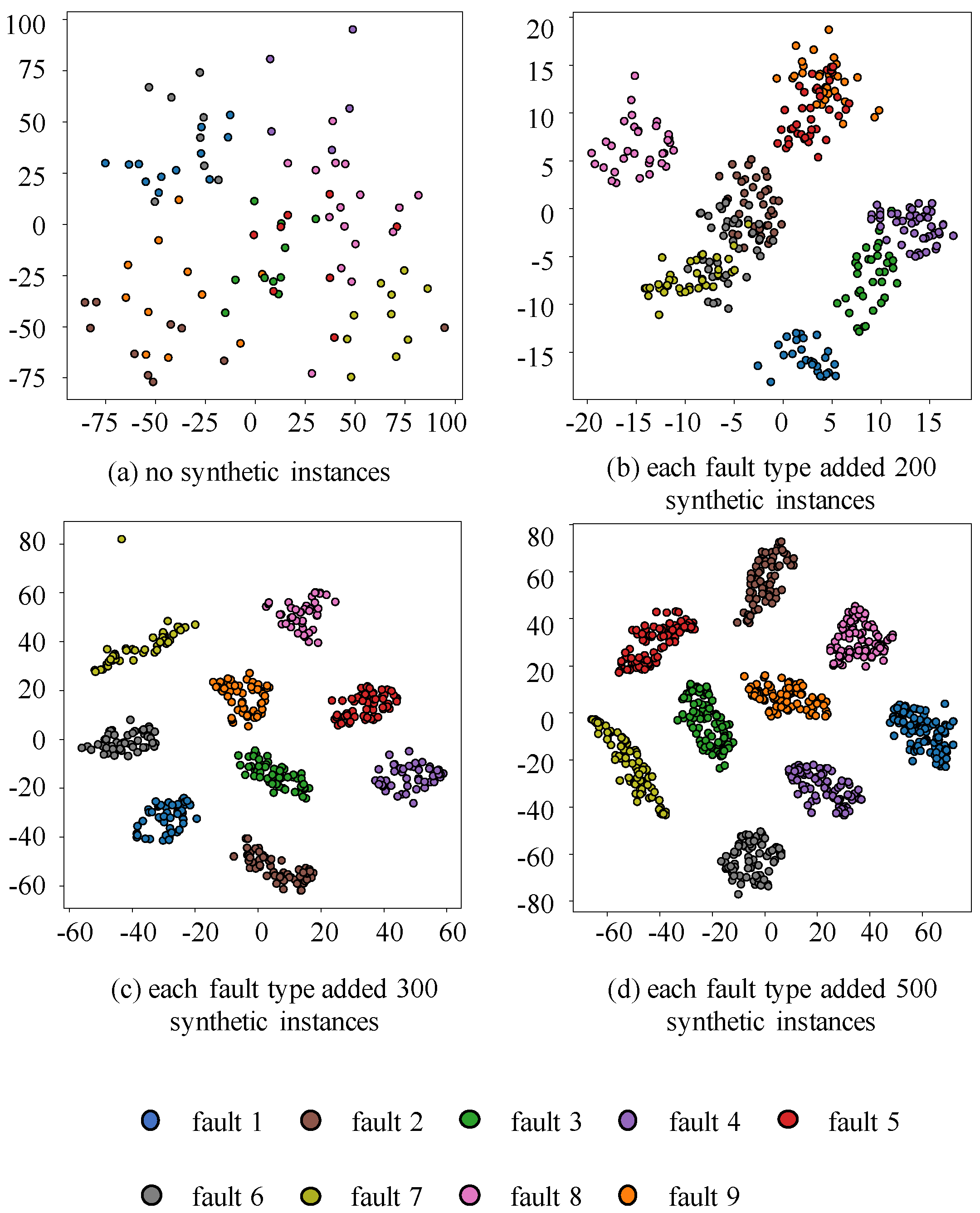
4.4.1. Synthetic Data Quality Visualization
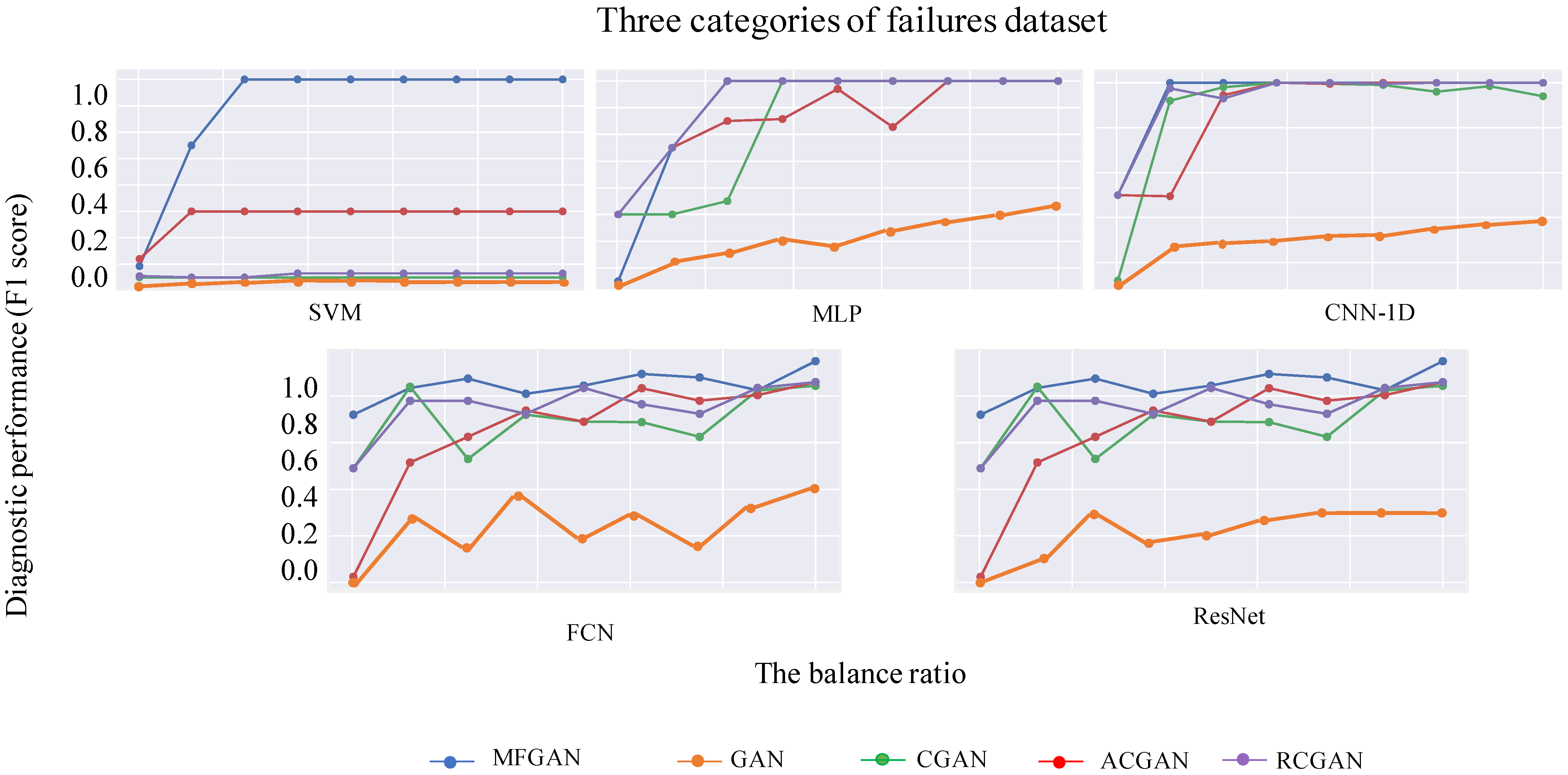
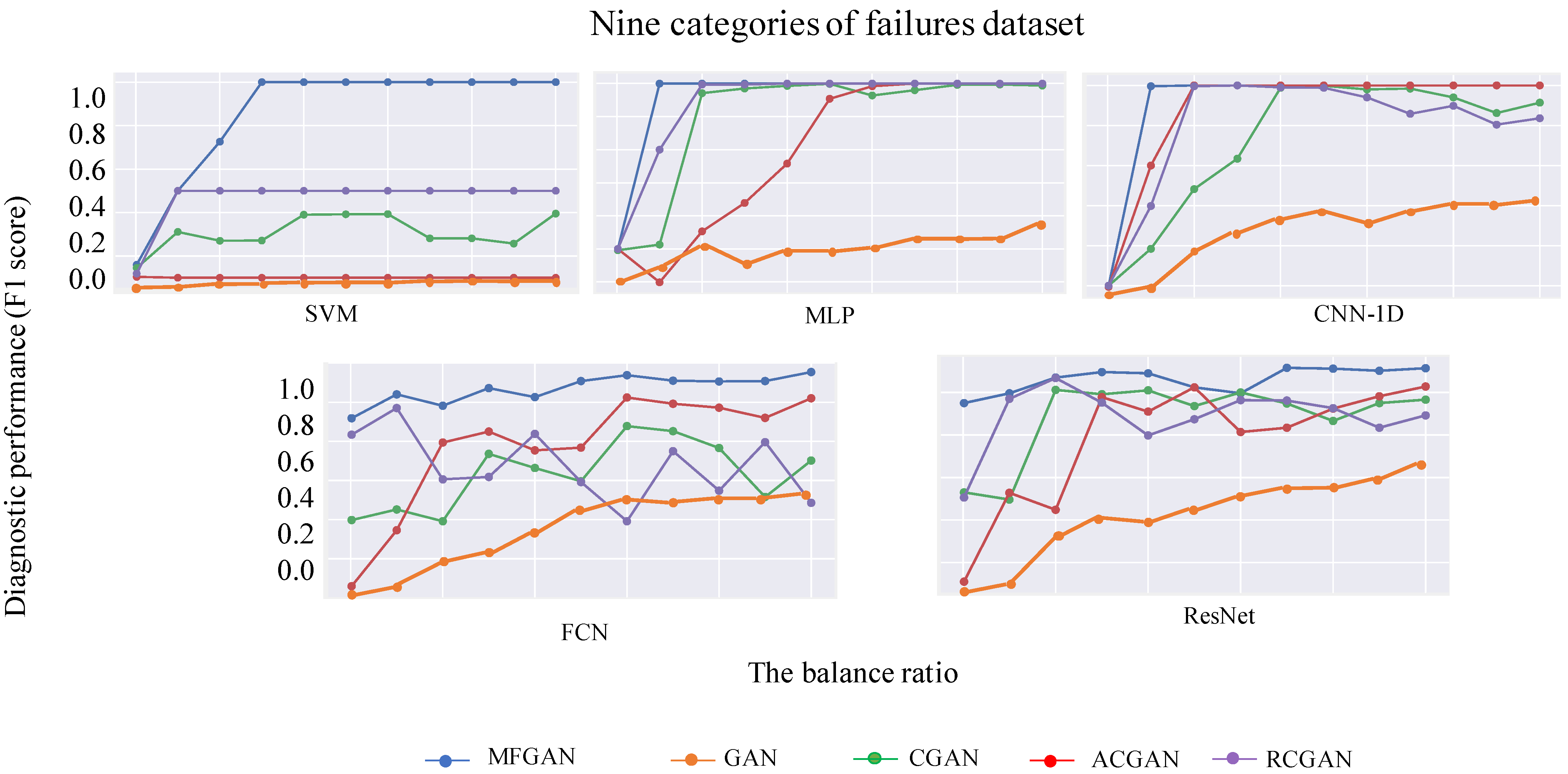
4.4.2. Performance and Generality of MFGAN
4.4.3. Effectiveness of Feature Transfer Strategies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Zhang, X.; Chen, G.; Hao, T.; He, Z. Rolling Bearing Fault Convolutional Neural Network Diagnosis Method Based on Casing Signal. J. Mech. Sci. Technol. 2020, 34, 2307–2316. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling Element Bearing Diagnostics Using the Case Western Reserve University Data: A Benchmark Study. Mech. Syst. Signal Process. 2015, 64, 100–131. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X. Multimode Process Monitoring Using Variational Bayesian Inference and Canonical Correlation Analysis. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1814–1824. [Google Scholar] [CrossRef]
- Feng, J.; Wang, J.; Zhang, H.; Han, Z. Fault Diagnosis Method of Joint Fisher Discriminant Analysis Based on the Local and Global Manifold Learning and Its Kernel Version. IEEE Trans. Autom. Sci. Eng. 2016, 13, 122–133. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B. A Review of Fault Detection and Diagnosis for the Traction System in High-Speed Trains. IEEE Trans. Intell. Transp. Syst. 2020, 21, 450–465. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning Deep Representation for Imbalanced Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Zhao, Y.; Hao, K.; Tang, X.; Chen, L.; Wei, B. A Conditional Variational Autoencoder Based Self-Transferred Algorithm for Imbalanced Classification. Knowl.-Based Syst. 2021, 218, 106756. [Google Scholar] [CrossRef]
- Chen, B.; Xia, S.; Chen, Z.; Wang, B.; Wang, G. RSMOTE: A Self-Adaptive Robust SMOTE for Imbalanced Problems with Label Noise. Inf. Sci. 2021, 553, 397–428. [Google Scholar] [CrossRef]
- Gu, X.; Angelov, P.P.; Soares, E.A. A Self-Adaptive Synthetic over-Sampling Technique for Imbalanced Classification. Int. J. Intell. Syst. 2020, 35, 923–943. [Google Scholar] [CrossRef]
- Drummond, C.; Holte, R.C. C4. 5, Class Imbalance, and Cost Sensitivity: Why Under-Sampling Beats Over-Sampling. In Proceedings of the Workshop on Learning from Imbalanced Datasets II, Washington, DC, USA, 21 August 2003; Volume 11, pp. 1–8. [Google Scholar]
- Feng, F.; Li, K.-C.; Shen, J.; Zhou, Q.; Yang, X. Using Cost-Sensitive Learning and Feature Selection Algorithms to Improve the Performance of Imbalanced Classification. IEEE Access 2020, 8, 69979–69996. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from Class-Imbalanced Data: Review of Methods and Applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kazeminia, S.; Baur, C.; Kuijper, A.; van Ginneken, B.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for Medical Image Analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef]
- Donahue, C.; McAuley, J.; Puckette, M. Synthesizing Audio with GANs. 2018. Available online: https://openreview.net/forum?id=r1RwYIJPM (accessed on 6 April 2022).
- Fu, Z.; Xian, Y.; Geng, S.; Ge, Y.; Wang, Y.; Dong, X.; Wang, G.; De Melo, G. ABSent: Cross-Lingual Sentence Representation Mapping with Bidirectional GANs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7756–7763. [Google Scholar]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines with Unlabeled Data. IEEE Trans. Ind. Electron. 2018, 66, 7316–7325. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved Training of Wasserstein Gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Le, H.L.; Landa-Silva, D.; Galar, M.; Garcia, S.; Triguero, I. EUSC: A Clustering-Based Surrogate Model to Accelerate Evolutionary Undersampling in Imbalanced Classification. Appl. Soft Comput. 2021, 101, 107033. [Google Scholar] [CrossRef]
- Liu, T.; Zhu, X.; Pedrycz, W.; Li, Z. A Design of Information Granule-Based under-Sampling Method in Imbalanced Data Classification. Soft Comput. 2020, 24, 17333–17347. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Hu, S.; Liang, Y.; Ma, L.; He, Y. MSMOTE: Improving Classification Performance When Training Data Is Imbalanced. In Proceedings of the 2009 Second International Workshop on Computer Science and Engineering, Qingdao, China, 28–30 October 2009; Volume 2, pp. 13–17. [Google Scholar]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A New over-Sampling Method in Imbalanced Data Sets Learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar]
- Sun, J.; Shang, Z.; Li, H. Imbalance-Oriented SVM Methods for Financial Distress Prediction: A Comparative Study among the New SB-SVM-Ensemble Method and Traditional Methods. J. Oper. Res. Soc. 2014, 65, 1905–1919. [Google Scholar] [CrossRef]
- Raghuwanshi, B.S.; Shukla, S. SMOTE Based Class-Specific Extreme Learning Machine for Imbalanced Learning. Knowl.-Based Syst. 2020, 187, 104814. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R.; Famili, F. Feature Selection for High-Dimensional Class-Imbalanced Data Sets Using Support Vector Machines. Inf. Sci. 2014, 286, 228–246. [Google Scholar] [CrossRef]
- Cheng, F.; Zhang, J.; Wen, C. Cost-Sensitive Large Margin Distribution Machine for Classification of Imbalanced Data. Pattern Recognit. Lett. 2016, 80, 107–112. [Google Scholar] [CrossRef]
- Ghazikhani, A.; Monsefi, R.; Sadoghi Yazdi, H. Online Cost-Sensitive Neural Network Classifiers for Non-Stationary and Imbalanced Data Streams. Neural Comput. Appl. 2013, 23, 1283–1295. [Google Scholar] [CrossRef]
- Datta, S.; Das, S. Near-Bayesian Support Vector Machines for Imbalanced Data Classification with Equal or Unequal Misclassification Costs. Neural Netw. 2015, 70, 39–52. [Google Scholar] [CrossRef] [PubMed]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier Gans. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Zheng, T.; Song, L.; Wang, J.; Teng, W.; Xu, X.; Ma, C. Data Synthesis Using Dual Discriminator Conditional Generative Adversarial Networks for Imbalanced Fault Diagnosis of Rolling Bearings. Measurement 2020, 158, 107741. [Google Scholar] [CrossRef]
- Xu, D.; Yuan, S.; Zhang, L.; Wu, X. Fairgan+: Achieving Fair Data Generation and Classification through Generative Adversarial Nets. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 1401–1406. [Google Scholar]
- Erol, B.; Gurbuz, S.Z.; Amin, M.G. Motion Classification Using Kinematically Sifted ACGAN-Synthesized Radar Micro-Doppler Signatures. IEEE Trans. Aerosp. Electron. Syst. 2020, 56, 3197–3213. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence Generative Adversarial Nets with Policy Gradient. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Lee, S.; Hwang, U.; Min, S.; Yoon, S. Polyphonic Music Generation with Sequence Generative Adversarial Networks. arXiv 2017, arXiv:1710.11418. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-Valued (Medical) Time Series Generation with Recurrent Conditional Gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Mao, Q.; Lee, H.-Y.; Tseng, H.-Y.; Ma, S.; Yang, M.-H. Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1429–1437. [Google Scholar]
- Wang, Z.; Yan, W.; Oates, T. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. arXiv 2016, arXiv:1611.06455. [Google Scholar] [CrossRef]











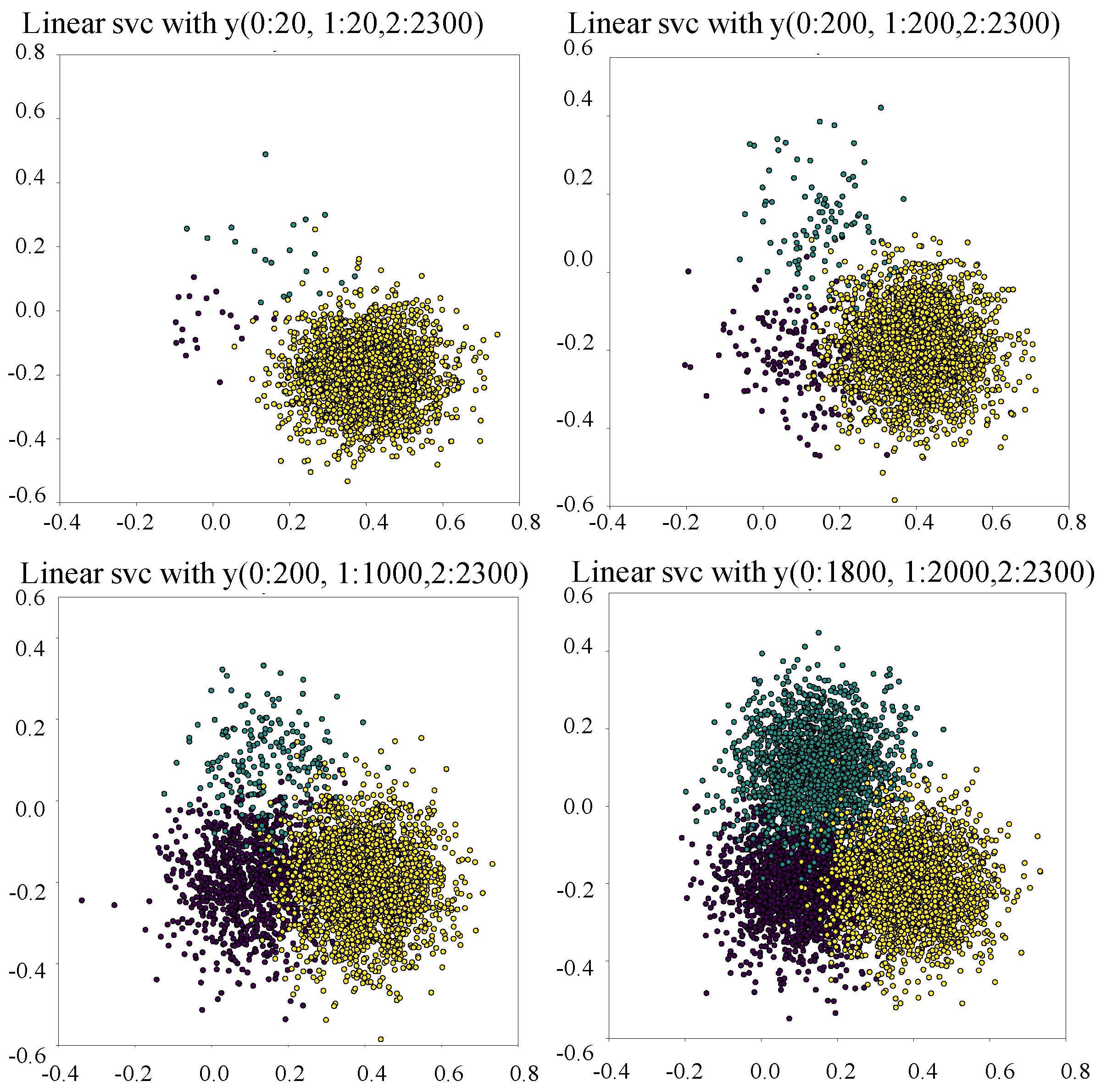{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Fault Location | Defect Diameter (Inches) | Defect Depth (Inches) | Sequence Number (Training + Testing) |
|---|---|---|---|---|
| 1-1 | Normal | -- | -- | 400 + 100 |
| 1-2 | Ball | 0.007 | 0.011 | 10 + 100 |
| 1-3 | Inner Race | 0.007 | 0.011 | 10 + 100 |
| 1-4 | Outer Race | 0.007 | 0.011 | 10 + 100 |
| Category | Fault Location | Defect Diameter (Inches) | Defect Depth (Inches) | Sequence Number (Training + Testing) |
|---|---|---|---|---|
| 2-1 | Normal | -- | -- | 500 + 100 |
| 2-2 | Ball | 0.007 | 0.011 | 10 + 100 |
| 2-3 | Ball | 0.014 | 0.011 | 10 + 100 |
| 2-4 | Ball | 0.021 | 0.011 | 10 + 100 |
| 2-5 | Inner Race | 0.007 | 0.011 | 10 + 100 |
| 2-6 | Inner Race | 0.014 | 0.011 | 10 + 100 |
| 2-7 | Inner Race | 0.021 | 0.011 | 10 + 100 |
| 2-8 | Outer Race | 0.007 | 0.011 | 10 + 100 |
| 2-9 | Outer Race | 0.014 | 0.011 | 10 + 100 |
| 2-10 | Outer Race | 0.021 | 0.011 | 10 + 100 |
| Algorithms | Input of Generator | Input of Discrimination |
|---|---|---|
| GAN | and | |
| CGAN | and | , and |
| ACGAN | and | and |
| RCGAN | and | , and |
| MFGAN | and | and |
| Number of Augmented Instances | Fault Diagnosis Performance (F1 Score) | ||||
|---|---|---|---|---|---|
| SVM | MLP | CNN-1D | FCN | ResNet | |
| 0 | 0.293 | 0.500 | 0.750 | 0.860 | 0.878 |
| 50 | 0.710 | 0.750 | 1.000 | 0.918 | 0.918 |
| 100 | 1.000 | 1.000 | 0.990 | 0.938 | 0.978 |
| 150 | 1.000 | 1.000 | 1.000 | 0.905 | 0.980 |
| 200 | 1.000 | 1.000 | 1.000 | 0.923 | 0.988 |
| 250 | 1.000 | 1.000 | 1.000 | 0.948 | 0.980 |
| 300 | 1.000 | 1.000 | 1.000 | 0.940 | 0.983 |
| 350 | 1.000 | 1.000 | 1.000 | 0.913 | 0.985 |
| 400 | 1.000 | 1.000 | 1.000 | 0.975 | 0.975 |
| Number of Augmented Instances | Fault Diagnosis Performance (F1 Score) | ||||
|---|---|---|---|---|---|
| SVM | MLP | CNN-1D | FCN | ResNet | |
| 0 | 0.160 | 0.500 | 0.500 | 0.859 | 0.875 |
| 50 | 0.500 | 1.00 | 0.998 | 0.920 | 0.898 |
| 100 | 0.726 | 1.000 | 1.000 | 0.891 | 0.935 |
| 150 | 1.000 | 1.000 | 1.000 | 0.936 | 0.948 |
| 200 | 1.000 | 1.000 | 1.000 | 0.913 | 0.945 |
| 250 | 1.000 | 1.000 | 1.000 | 0.954 | 0.912 |
| 300 | 1.000 | 1.000 | 1.000 | 0.969 | 0.898 |
| 350 | 1.000 | 1.000 | 1.000 | 0.955 | 0.958 |
| 400 | 1.000 | 1.000 | 1.000 | 0.953 | 0.956 |
| 450 | 1.000 | 1.000 | 1.000 | 0.954 | 0.951 |
| 500 | 1.000 | 1.000 | 1.000 | 0.977 | 0.957 |
| Category | Normal Data | Uniformly Distributed Noise | Standard Normal Distribution Noise |
|---|---|---|---|
| fault1 | 76.898 | 97.778 | 241.768 |
| fault2 | 43.474 | 111.567 | 231.037 |
| fault3 | 87.655 | 91.972 | 244.148 |
| Category | Normal Data | Uniformly Distributed Noise | Standard Normal Distribution Noise |
|---|---|---|---|
| fault1 | 543.605 | 691.220 | 1709.199 |
| fault2 | 307.282 | 788.811 | 1633.360 |
| fault3 | 619.165 | 650.098 | 1725.932 |
| Category | Normal Data | Uniformly Distributed Noise | Standard Normal Distribution Noise |
|---|---|---|---|
| fault1 | 47.611 | 164.854 | 322.914 |
| fault2 | 51.878 | 162.893 | 324.005 |
| fault3 | 49.324 | 165.693 | 323.005 |
| fault4 | 88.812 | 145.785 | 333.944 |
| fault5 | 55.535 | 156.932 | 324.238 |
| fault6 | 89.096 | 144.817 | 334.050 |
| fault7 | 102.261 | 138.275 | 336.858 |
| fault8 | 49.456 | 165.121 | 322.866 |
| fault9 | 116.670 | 130.526 | 343.236 |
| Category | Normal Data | Uniformly Distributed Noise | Standard Normal Distribution Noise |
|---|---|---|---|
| fault1 | 475.846 | 1648.304 | 3228.351 |
| fault2 | 516.868 | 1628.181 | 3239.231 |
| fault3 | 492.986 | 1656.742 | 3229.276 |
| fault4 | 887.850 | 1457.344 | 3338.659 |
| fault5 | 554.594 | 1568.904 | 3241.597 |
| fault6 | 890.105 | 1447.650 | 3339.695 |
| fault7 | 1022.121 | 1382.086 | 3367.754 |
| fault8 | 494.281 | 1651.009 | 3227.906 |
| fault9 | 1165.438 | 1304.594 | 3431.442 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, C.; Du, J.; Liang, H. Imbalanced Fault Diagnosis of Rolling Bearing Using Data Synthesis Based on Multi-Resolution Fusion Generative Adversarial Networks. Machines 2022, 10, 295. https://doi.org/10.3390/machines10050295
Hao C, Du J, Liang H. Imbalanced Fault Diagnosis of Rolling Bearing Using Data Synthesis Based on Multi-Resolution Fusion Generative Adversarial Networks. Machines. 2022; 10(5):295. https://doi.org/10.3390/machines10050295
Chicago/Turabian StyleHao, Chuanzhu, Junrong Du, and Haoran Liang. 2022. "Imbalanced Fault Diagnosis of Rolling Bearing Using Data Synthesis Based on Multi-Resolution Fusion Generative Adversarial Networks" Machines 10, no. 5: 295. https://doi.org/10.3390/machines10050295
APA StyleHao, C., Du, J., & Liang, H. (2022). Imbalanced Fault Diagnosis of Rolling Bearing Using Data Synthesis Based on Multi-Resolution Fusion Generative Adversarial Networks. Machines, 10(5), 295. https://doi.org/10.3390/machines10050295