
AI-Based Posture Control Algorithm for a 7-DOF Robot Manipulator


Abstract
:1. Introduction
2. Background
2.1. Kinematic Analysis
2.2. Artificial Inteligence Algorithm
2.2.1. Reinforcement Learning
2.2.2. Artificial Neural Network for Supervised Learning
3. 7-DOF Robot Manipulator
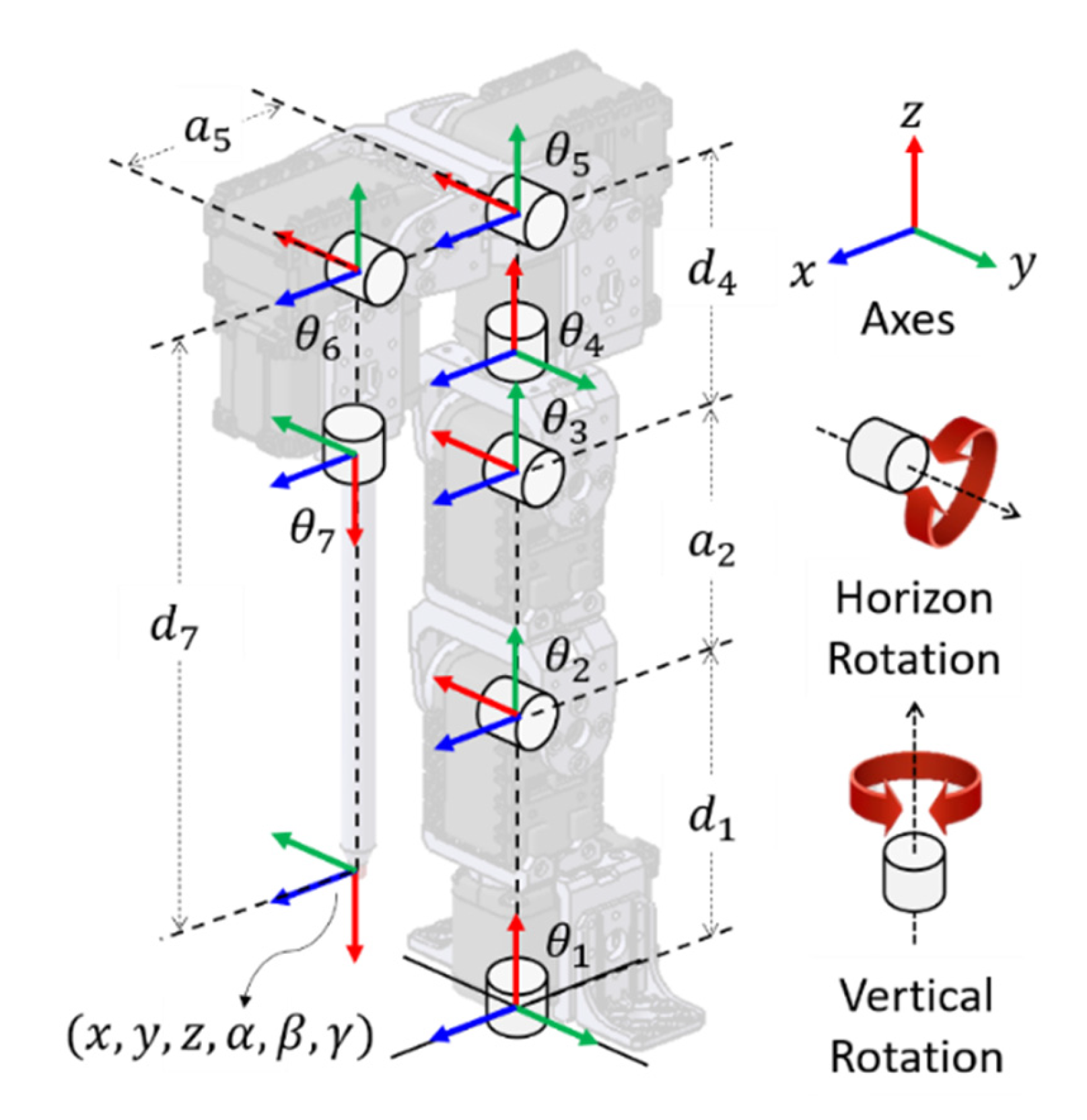
3.1. Configuration of 7-DOF Robot Manipulator
3.2. Forward Kinematics Equation via D–H Convention
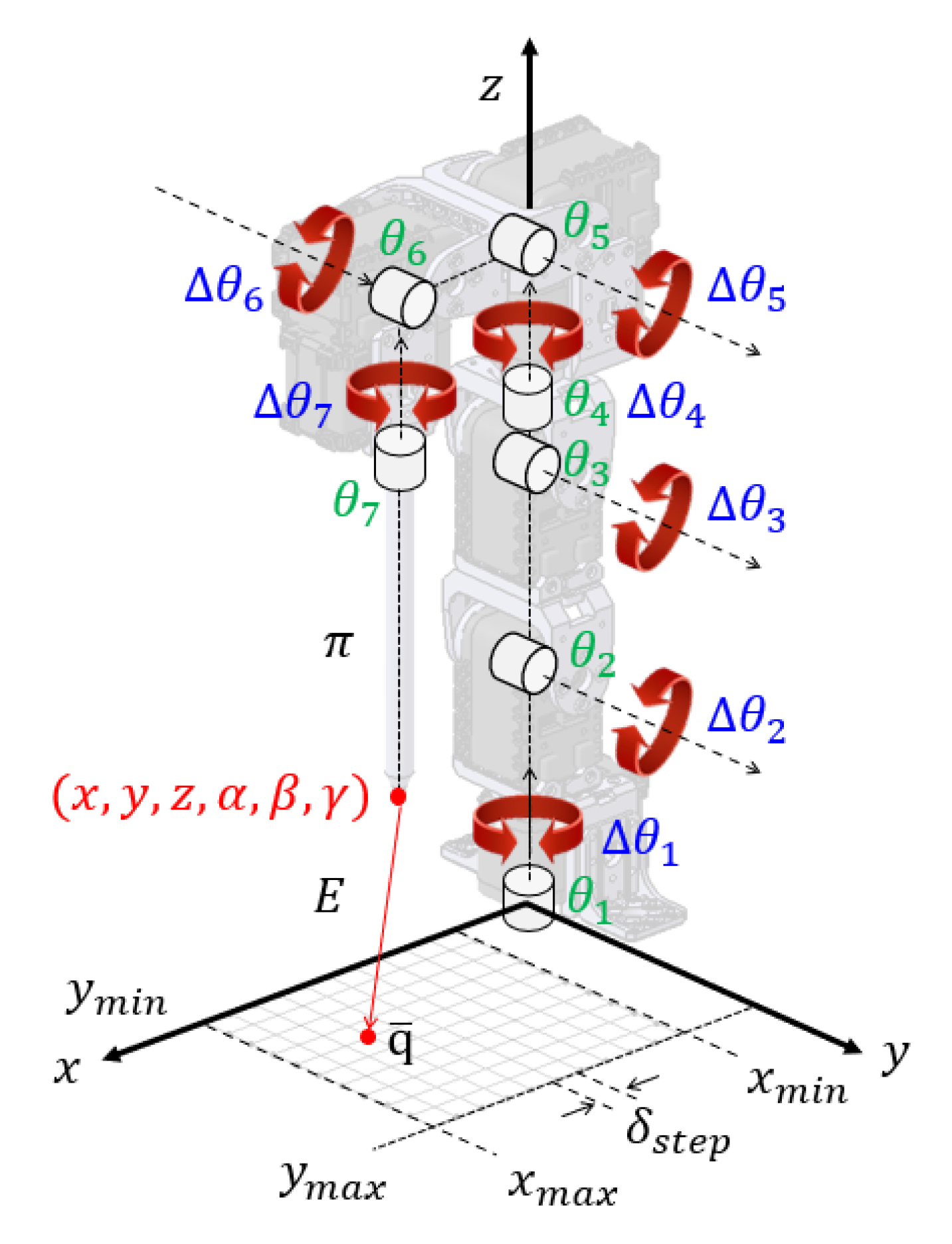
3.3. Posture Control System
4. RL-Based Posture Control Algorithm
4.1. RL Parameters
4.2. RL Training with GPI
4.3. Path Planning of the Trajectory
5. ANN-Based Posture Control Algorithm
5.1. ANN Training Data
5.2. ANN Structure
5.3. ANN Training
6. Experimental Evaluation
6.1. Experimental Results of RL
6.2. Experimental Results of ANN
6.2.1. Training Results of ANN
6.2.2. Inference Results for Test Data
6.3. Comparison of RL vs. ANN
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Initial Posture via Forward Kinematics
Appendix B. Limit of Posture Control Error
Appendix C. GPI for RL Training

References
- Elsisi, M.; Mahmoud, K.; Lehtonen, M.; Darwish, M.M. An improved neural network algorithm to efficiently track various trajectories of robot manipulator arms. IEEE Access 2021, 9, 11911–11920. [Google Scholar] [CrossRef]
- Urrea, C.; Jara, D. Design, analysis, and comparison of control strategies for an industrial robotic arm driven by a multi-level inverter. Symmetry 2021, 13, 86. [Google Scholar] [CrossRef]
- Martıín, P.; Millán, J.D.R. Robot arm reaching through neural inversions and reinforcement learning. Robot. Auton. Syst. 2000, 31, 227–246. [Google Scholar] [CrossRef]
- Azizi, A. Applications of artificial intelligence techniques to enhance sustainability of industry 4.0: Design of an artificial neural network model as dynamic behavior optimizer of robotic arms. Complexity 2020, 2020, 8564140. [Google Scholar] [CrossRef]
- Ram, R.V.; Pathak, P.M.; Junco, S.J. Inverse kinematics of mobile manipulator using bidirectional particle swarm optimization by manipulator decoupling. Mech. Mach. Theory 2019, 131, 385–405. [Google Scholar] [CrossRef]
- Boschetti, G. A novel kinematic directional index for industrial serial manipulators. Appl. Sci. 2020, 10, 5953. [Google Scholar] [CrossRef]
- Shahzad, A.; Gao, X.; Yasin, A.; Javed, K.; Anwar, S.M. A Vision-Based Path Planning and Object Tracking Framework for 6-DOF Robotic Manipulator. IEEE Access 2020, 8, 203158–203167. [Google Scholar] [CrossRef]
- Zhou, Z.; Guo, H.; Wang, Y.; Zhu, Z.; Wu, J.; Liu, X. Inverse kinematics solution for robotic manipulator based on extreme learning machine and sequential mutation genetic algorithm. Int. J. Adv. Robot. Syst. 2018, 15, 1729881418792992. [Google Scholar] [CrossRef]
- Pane, Y.P.; Nageshrao, S.P.; Kober, J.; Babuška, R. Reinforcement learning based compensation methods for robot manipulators. Eng. Appl. Artif. Intell. 2019, 78, 236–247. [Google Scholar] [CrossRef]
- Chiddarwar, S.S.; Babu, N.R. Comparison of RBF and MLP neural networks to solve inverse kinematic problem for 6R serial robot by a fusion approach. Eng. Appl. Artif. Intell. 2010, 23, 1083–1092. [Google Scholar] [CrossRef]
- Hasan, A.T.; Hamouda, A.M.S.; Ismail, N.; Al-Assadi, H.M.A.A. An adaptive-learning algorithm to solve the inverse kinematics problem of a 6 DOF serial robot manipulator. Adv. Eng. Softw. 2006, 37, 432–438. [Google Scholar] [CrossRef]
- de Giorgio, A.; Wang, L. Artificial intelligence control in 4D cylindrical space for industrial robotic applications. IEEE Access 2020, 8, 174833–174844. [Google Scholar] [CrossRef]
- Bagheri, M.; Naseradinmousavi, P. Analytical and experimental nonzero-sum differential game-based control of a 7-DOF robotic manipulator. J. Vib. Control. 2021, 28, 707–718. [Google Scholar] [CrossRef]
- Chen, B.C.; Cao, G.Z.; Li, W.B.; Sun, J.D.; Huang, S.D.; Zeng, J. An analytical solution of inverse kinematics for a 7-DOF redundant manipulator. In Proceedings of the 2018 IEEE 15th International Conference on Ubiquitous Robots (UR), Jeju, Korea, 28 June–1 July 2018; pp. 523–527. [Google Scholar]
- Faria, C.; Ferreira, F.; Erlhagen, W.; Monteiro, S.; Bicho, E. Position-based kinematics for 7-DoF serial manipulators with global configuration control, joint limit and singularity avoidance. Mech. Mach. Theory 2018, 121, 317–334. [Google Scholar] [CrossRef] [Green Version]
- Dereli, S.; Köker, R. Calculation of the inverse kinematics solution of the 7-DOF redundant robot manipulator by the firefly algorithm and statistical analysis of the results in terms of speed and accuracy. Inverse Probl. Sci. Eng. 2020, 28, 601–613. [Google Scholar] [CrossRef]
- Zhang, L.; Xiao, N. A novel artificial bee colony algorithm for inverse kinematics calculation of 7-DOF serial manipulators. Soft Comput. 2019, 23, 3269–3277. [Google Scholar] [CrossRef]
- Kalakrishnan, M.; Pastor, P.; Righetti, L.; Schaal, S. Learning objective functions for manipulation. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 1331–1336. [Google Scholar]
- Bretan, M.; Oore, S.; Sanan, S.; Heck, L. Robot Learning by Collaborative Network Training: A Self-Supervised Method using Ranking. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 1333–1340. [Google Scholar]
- Peters, J.; Schaal, S. Reinforcement learning by reward-weighted regression for operational space control. In Proceedings of the 24th international conference on Machine learning, Corvalis, OG, USA, 20–24 June 2007; pp. 745–750. [Google Scholar]
- Chen, L.; Sun, H.; Zhao, W.; Yu, T. Robotic arm control system based on AI wearable acceleration sensor. Math. Probl. Eng. 2021, 2021, 5544375. [Google Scholar] [CrossRef]
- Dong, Y.; Ding, J.; Wang, C.; Liu, X. Kinematics Analysis and Optimization of a 3-DOF Planar Tensegrity Manipulator under Workspace Constraint. Machines 2011, 9, 256. [Google Scholar] [CrossRef]
- Dereli, S.; Köker, R. Simulation based calculation of the inverse kinematics solution of 7-DOF robot manipulator using artificial bee colony algorithm. SN Appl. Sci. 2020, 2, 27. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Shao, X.; Yang, L.; Liu, N. Deep learning aided dynamic parameter identification of 6-DOF robot manipulators. IEEE Access 2020, 8, 138102–138116. [Google Scholar] [CrossRef]
- la Mura, F.; Romanó, P.; Fiore, E.E.; Giberti, H. Workspace limiting strategy for 6 DOF force controlled PKMs manipulating high inertia objects. Robotics 2018, 7, 10. [Google Scholar] [CrossRef] [Green Version]
- Sandakalum, T.; Ang, M.H., Jr. Motion planning for mobile manipulators—A systematic review. Machines 2022, 10, 97. [Google Scholar] [CrossRef]
- Jie, W.; Yudong, Z.; Yulong, B.; Kim, H.H.; Lee, M.C. Trajectory tracking control using fractional-order terminal sliding mode control with sliding perturbation observer for a 7-DOF robot manipulator. IEEE/ASME Trans. Mechatron. 2020, 25, 1886–1893. [Google Scholar] [CrossRef]
- Lim, Z.Y.; Quan, N.Y. Convolutional Neural Network Based Electroencephalogram Controlled Robotic Arm. In Proceedings of the 2021 IEEE International Conference on Automatic Control & Intelligent Systems (I2CACIS), Online, 26–28 June 2021; pp. 26–31. [Google Scholar]
- Wang, J.; Li, Y.; Zhao, X. Inverse kinematics and control of a 7-DOF redundant manipulator based on the closed-loop algorithm. Int. J. Adv. Robot. Syst. 2010, 7, 37. [Google Scholar] [CrossRef]
- Gong, M.; Li, X.; Zhang, L. Analytical Inverse Kinematics and Self-Motion Application for 7-DOF Redundant Manipulator. IEEE Access 2019, 7, 18662–18674. [Google Scholar] [CrossRef]
- Huang, H.C.; Chen, C.P.; Wang, P.R. Particle swarm optimization for solving the inverse kinematics of 7-DOF robotic manipulators. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; pp. 3105–3110. [Google Scholar]
- Dereli, S.; Köker, R. A meta-heuristic proposal for inverse kinematics solution of 7-DOF serial robotic manipulator: Quantum behaved particle swarm algorithm. Artif. Intell. Rev. 2019, 53, 949–964. [Google Scholar] [CrossRef]
- Jiménez-López, E.; de la Mora-Pulido, D.S.; Reyes-Ávila, L.A.; de la Mora-Pulido, R.S.; Melendez-Campos, J.; López-Martínez, A.A. Modeling of inverse kinematic of 3-DOF robot, using unit quaternions and artificial neural network. Robotica 2021, 39, 1230–1250. [Google Scholar] [CrossRef]
- Kramar, V.; Kramar, O.; Kabanov, A. An Artificial Neural Network Approach for Solving Inverse Kinematics Problem for an Anthropomorphic Manipulator of Robot SAR-401. Machines 2022, 10, 241. [Google Scholar] [CrossRef]
- Lee, C.; An, D. Reinforcement learning and neural network-based artificial intelligence control algorithm for self-balancing quadruped robot. J. Mech. Sci. Technol. 2021, 35, 307–322. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- University College London. Course on RL. Available online: https://www.davidsilver.uk/teaching/ (accessed on 3 July 2022).
- Stanford University. Reinforcement Learning CS234. Available online: https://web.stanford.edu/class/cs234/index.html (accessed on 3 July 2022).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Spong, M.W.; Vidyasagar, M. Robot Dynamics and Control; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- MathWorks. Levenberg-Marquardt. Available online: https://kr.mathworks.com/help/deeplearning/ref/trainlm.html (accessed on 3 July 2022).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Link Number | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 81.50 | 0.00 | 90.00 | −150.00 | to | 150.00 | |
| 2 | 0.00 | 67.50 | 0.00 | −20.00 | to | 180.00 | |
| 3 | 0.00 | 0.00 | −90.00 | −180.00 | to | 20.00 | |
| 4 | 79.00 | 0.00 | 90.00 | −150.00 | to | 150.00 | |
| 5 | 0.00 | 52.00 | 0.00 | −20.00 | to | 90.00 | |
| 6 | 0.00 | 0.00 | 90.00 | −20.00 | to | 90.00 | |
| 7 | 175.00 | 0.00 | 0.00 | , fully rotate | |||
| Actions | The Rotational Variations of Seven Servo Motors | ||||||
|---|---|---|---|---|---|---|---|
| CW | CW | CW | CW | CW | CW | CW | |
| CW | CW | CW | CW | CW | CW | PAUSE | |
| CW | CW | CW | CW | CW | CW | CCW | |
| … | … | … | … | … | … | … | … |
| PAUSE | PAUSE | PAUSE | PAUSE | PAUSE | PAUSE | CW | |
| PAUSE | PAUSE | PAUSE | PAUSE | PAUSE | PAUSE | CCW | |
| … | … | … | … | … | … | … | … |
| CCW | CCW | CCW | CCW | CCW | CCW | CW | |
| CCW | CCW | CCW | CCW | CCW | CCW | PAUSE | |
| CCW | CCW | CCW | CCW | CCW | CCW | CCW | |
| Layer Type | Node | |||
|---|---|---|---|---|
| Input layer | 6 | - | - | - |
| Hidden layer 1 | 8 | Tangent sigmoid | ||
| Hidden layer 2 | 8 | Tangent sigmoid | ||
| Hidden layer 3 | 8 | Tangent sigmoid | ||
| Hidden layer 4 | 8 | Tangent sigmoid | ||
| Hidden layer 5 | 8 | Tangent sigmoid | ||
| Hidden layer 6 | 8 | Tangent sigmoid | ||
| Hidden layer 7 | 8 | Tangent sigmoid | ||
| Hidden layer 8 | 5 | Tangent sigmoid | ||
| Output layer | 7 | Pure linear |
| Metrics | Results of RL Training | Results of ANN Training (95 Models) | Results of ANN Testing (7 Models) |
|---|---|---|---|
| Max. | 0.0814 | 0.2534 | 0.2761 |
| Median | 0.0096 | 0.0198 | 0.0356 |
| Mean | 0.0118 | 0.0243 | 0.0455 |
| Std. | 0.0095 | 0.0025 | 0.0158 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.; An, D. AI-Based Posture Control Algorithm for a 7-DOF Robot Manipulator. Machines 2022, 10, 651. https://doi.org/10.3390/machines10080651
Lee C, An D. AI-Based Posture Control Algorithm for a 7-DOF Robot Manipulator. Machines. 2022; 10(8):651. https://doi.org/10.3390/machines10080651
Chicago/Turabian StyleLee, Cheonghwa, and Dawn An. 2022. "AI-Based Posture Control Algorithm for a 7-DOF Robot Manipulator" Machines 10, no. 8: 651. https://doi.org/10.3390/machines10080651
APA StyleLee, C., & An, D. (2022). AI-Based Posture Control Algorithm for a 7-DOF Robot Manipulator. Machines, 10(8), 651. https://doi.org/10.3390/machines10080651