





Dimensionality Reduction Methods of a Clustered Dataset for the Diagnosis of a SCADA-Equipped Complex Machine


Abstract
:1. Introduction
2. Test Bench and Dataset Description
3. Existing Dimensionality Reduction Methods
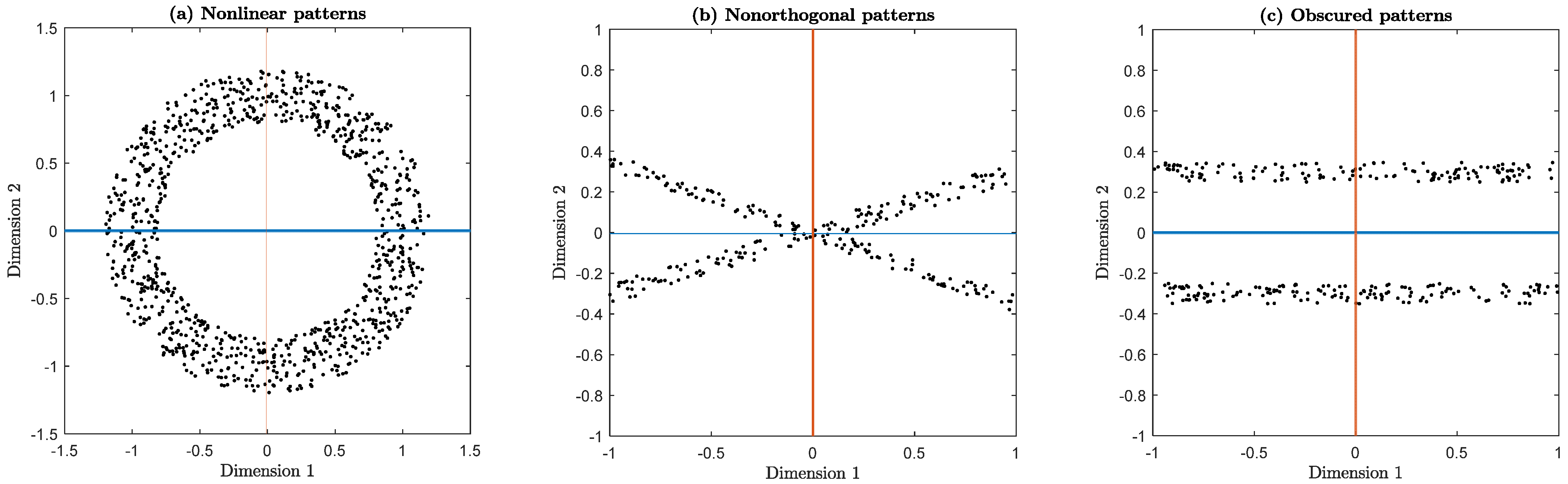
3.1. Linear DRM: Principal Component Analysis
3.2. Nonlinear DRM: Mahalanobis Distance
4. Proposed Methodology
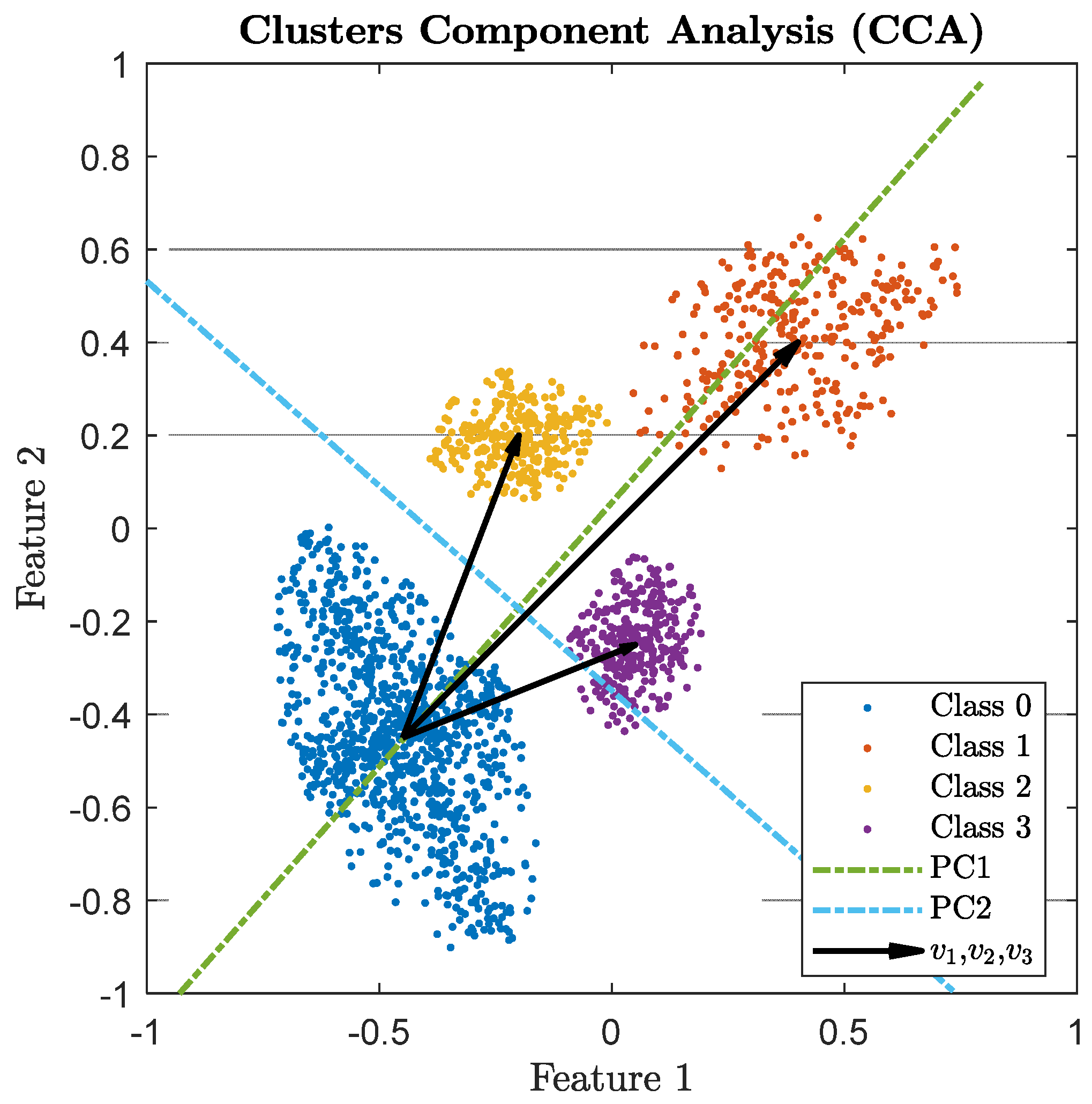
4.1. Clusters Component Analysis (CCA)
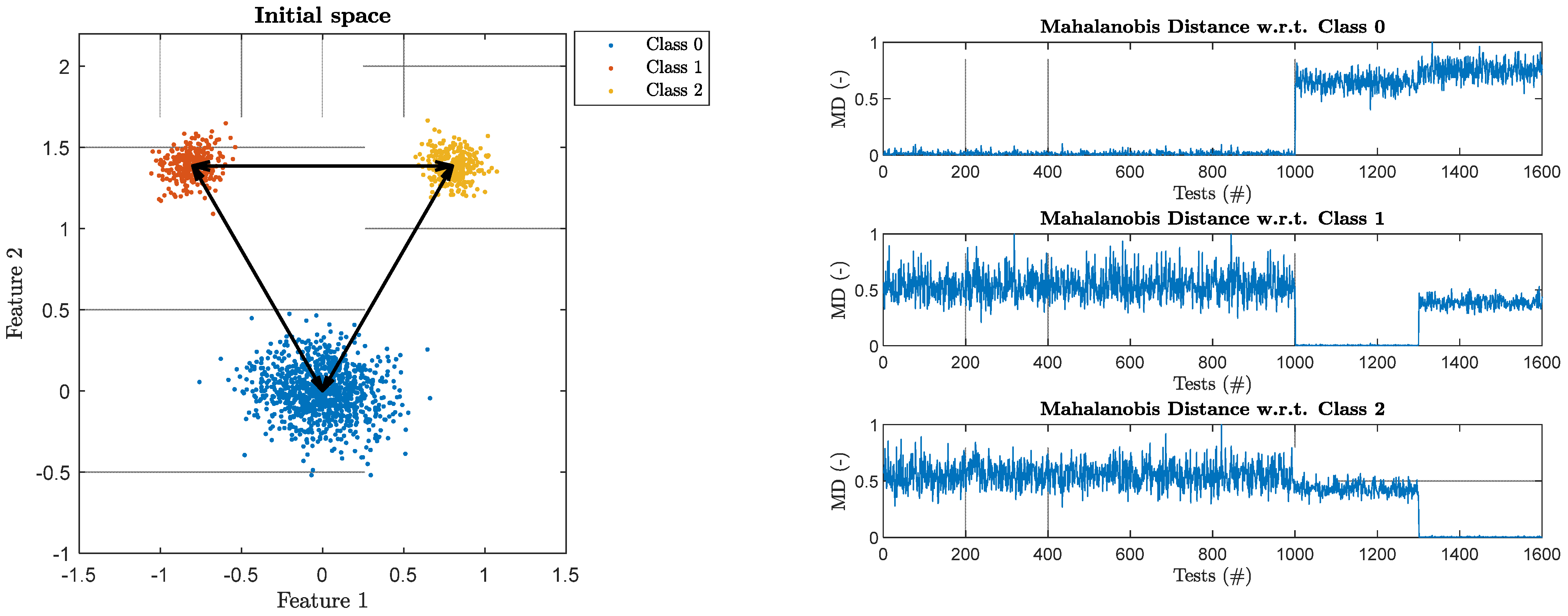
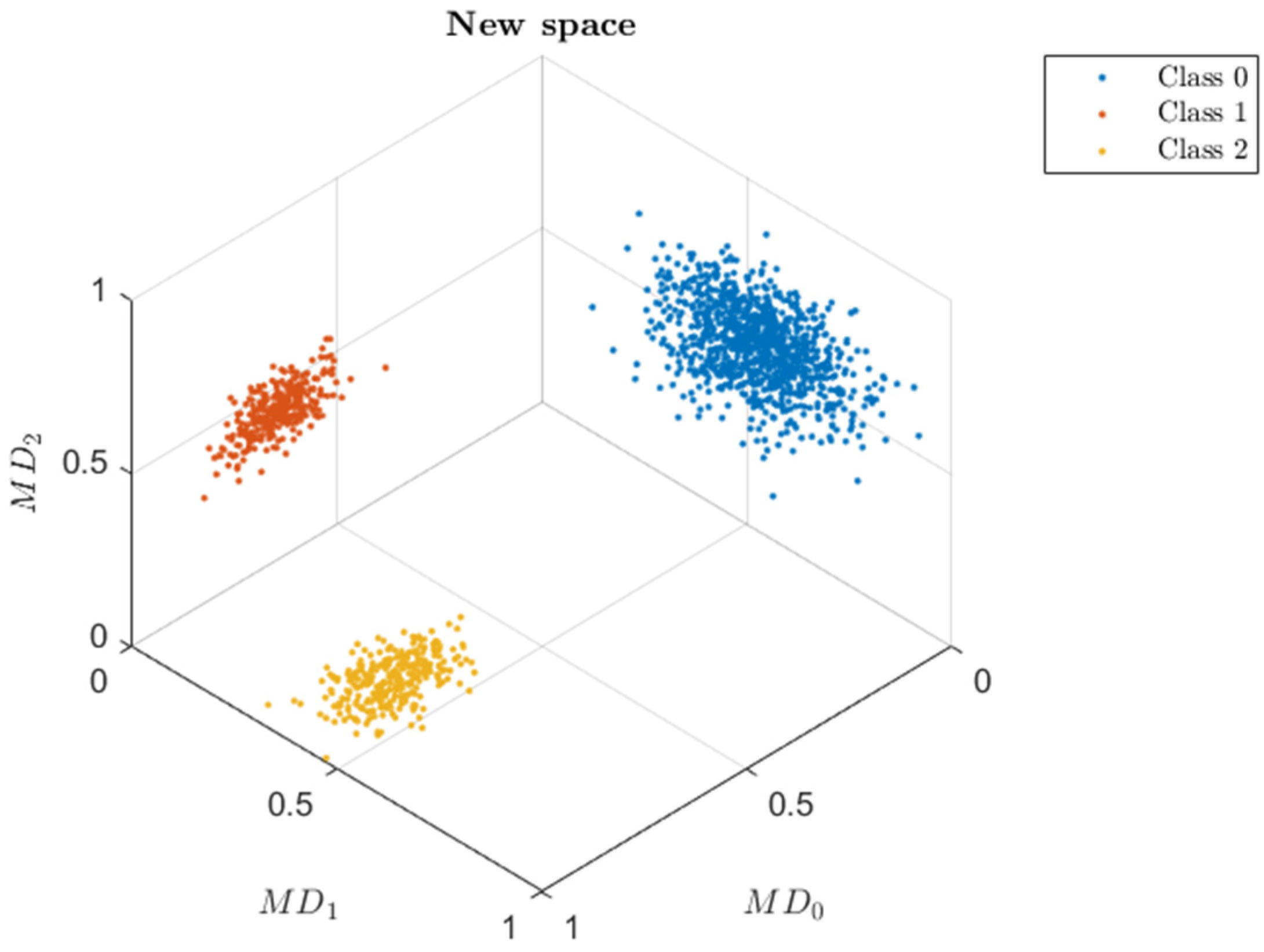
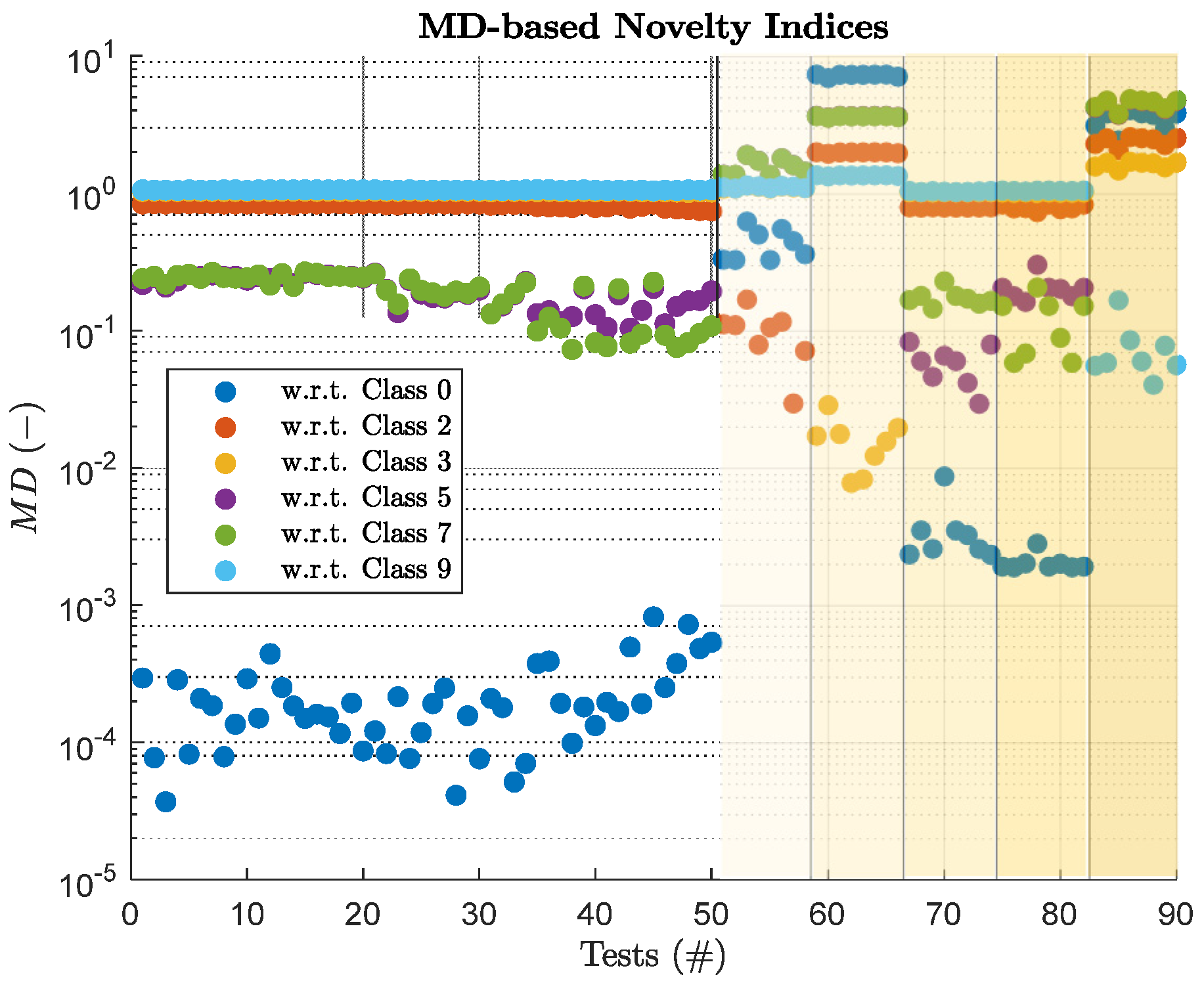
4.2. MD-Based Multi-Novelty Indices (MNI)
5. Results and Discussion
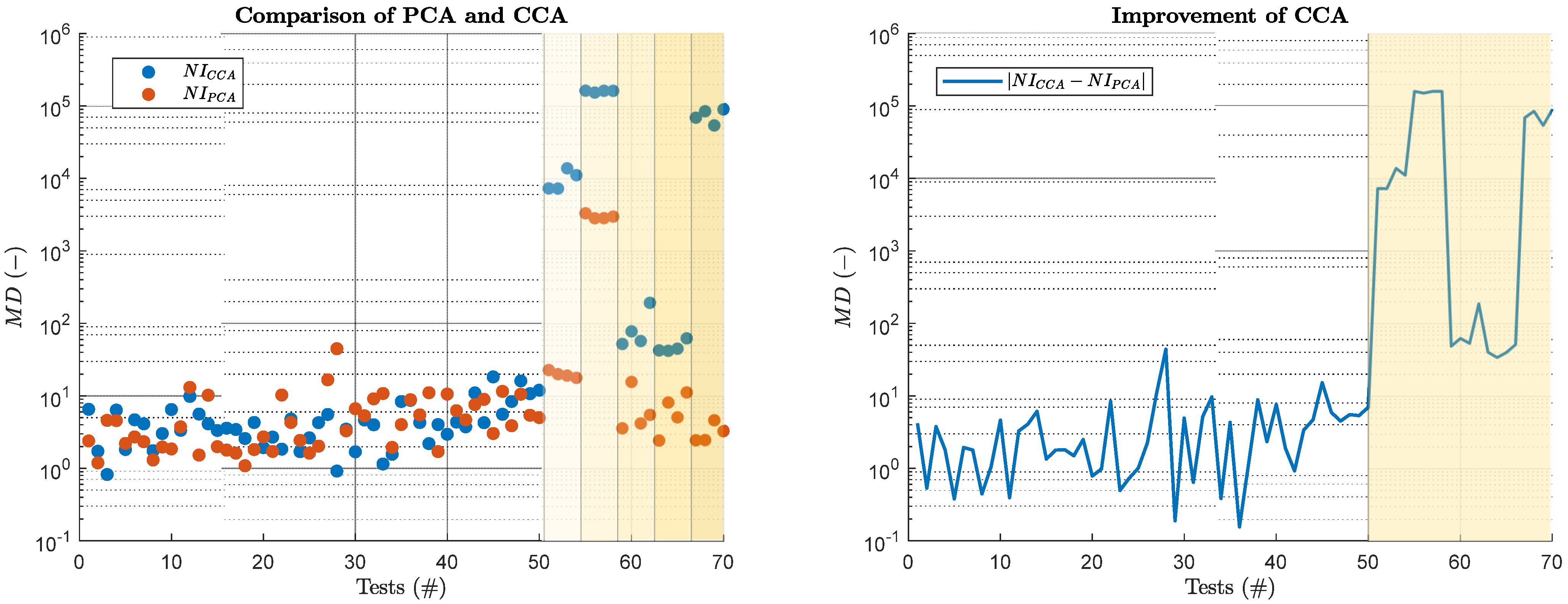
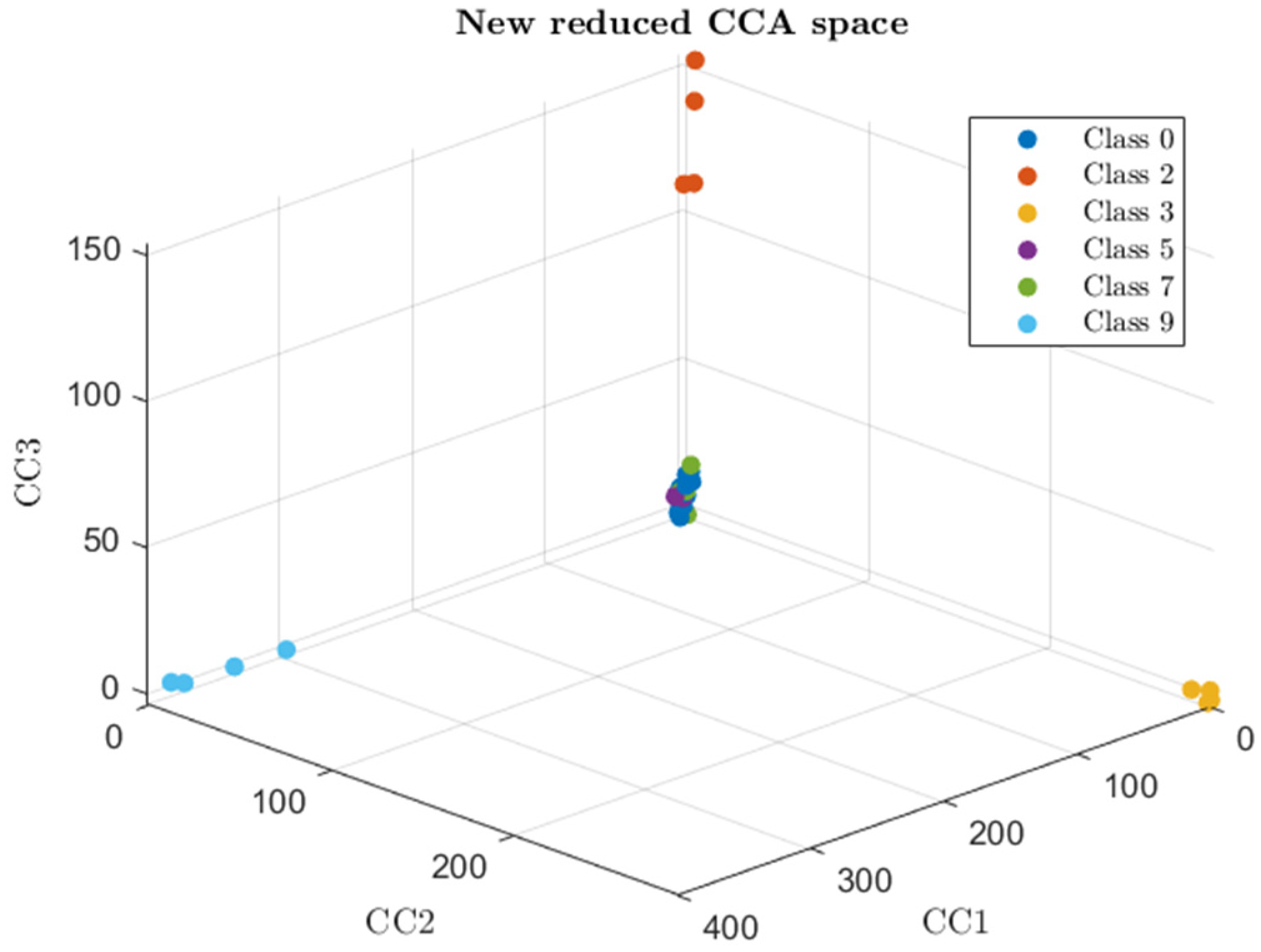
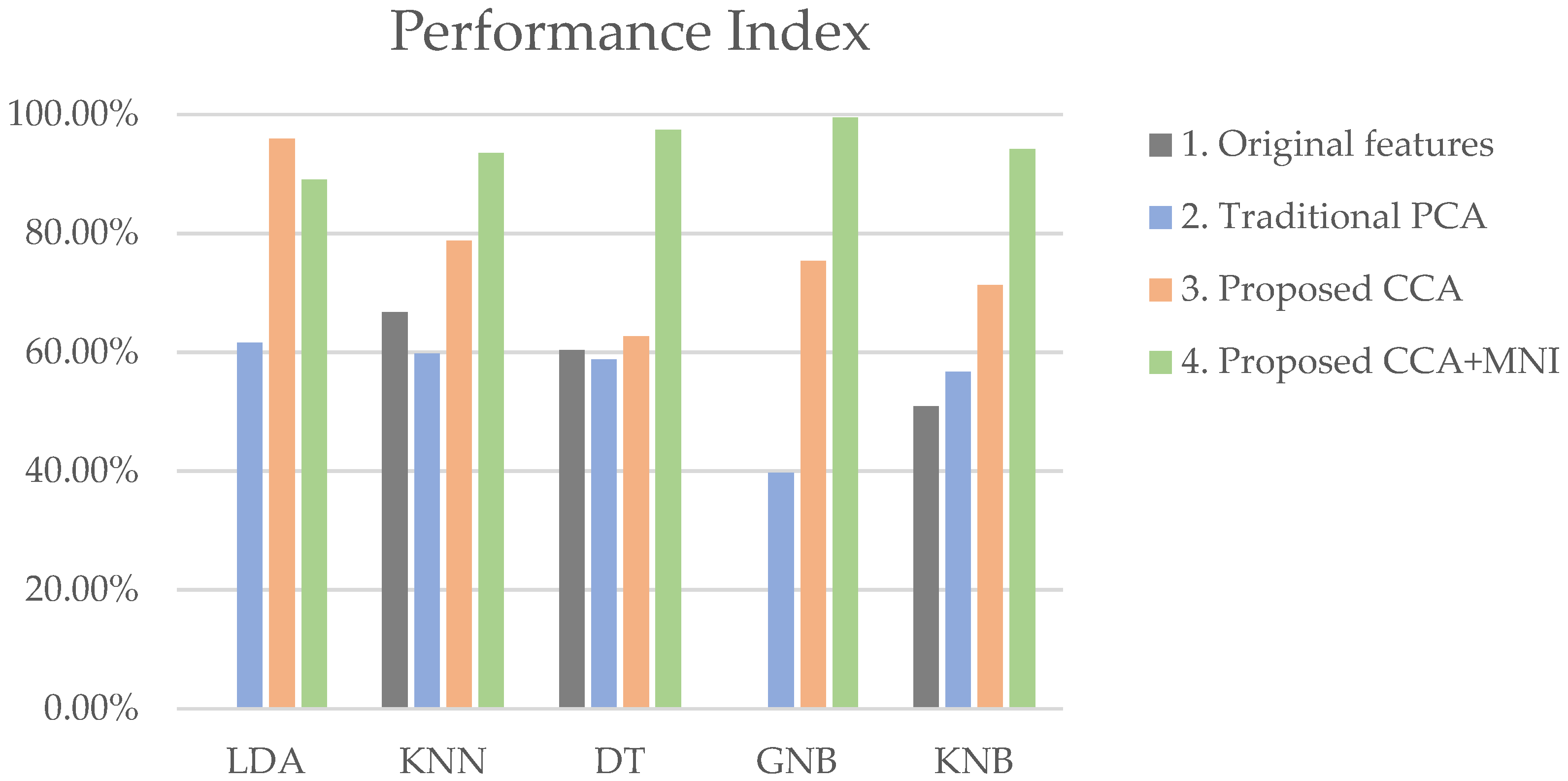
5.1. CCA Results
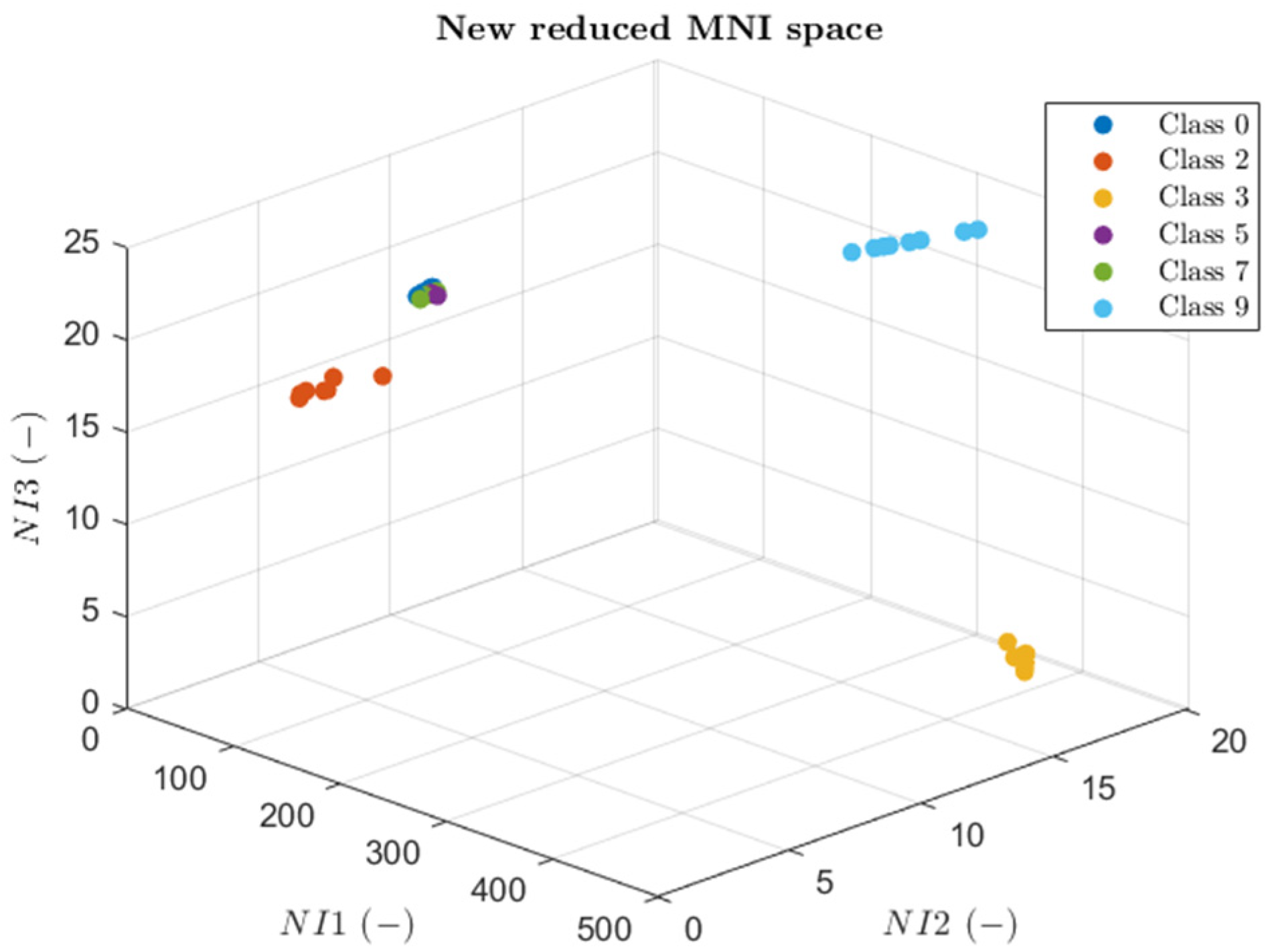
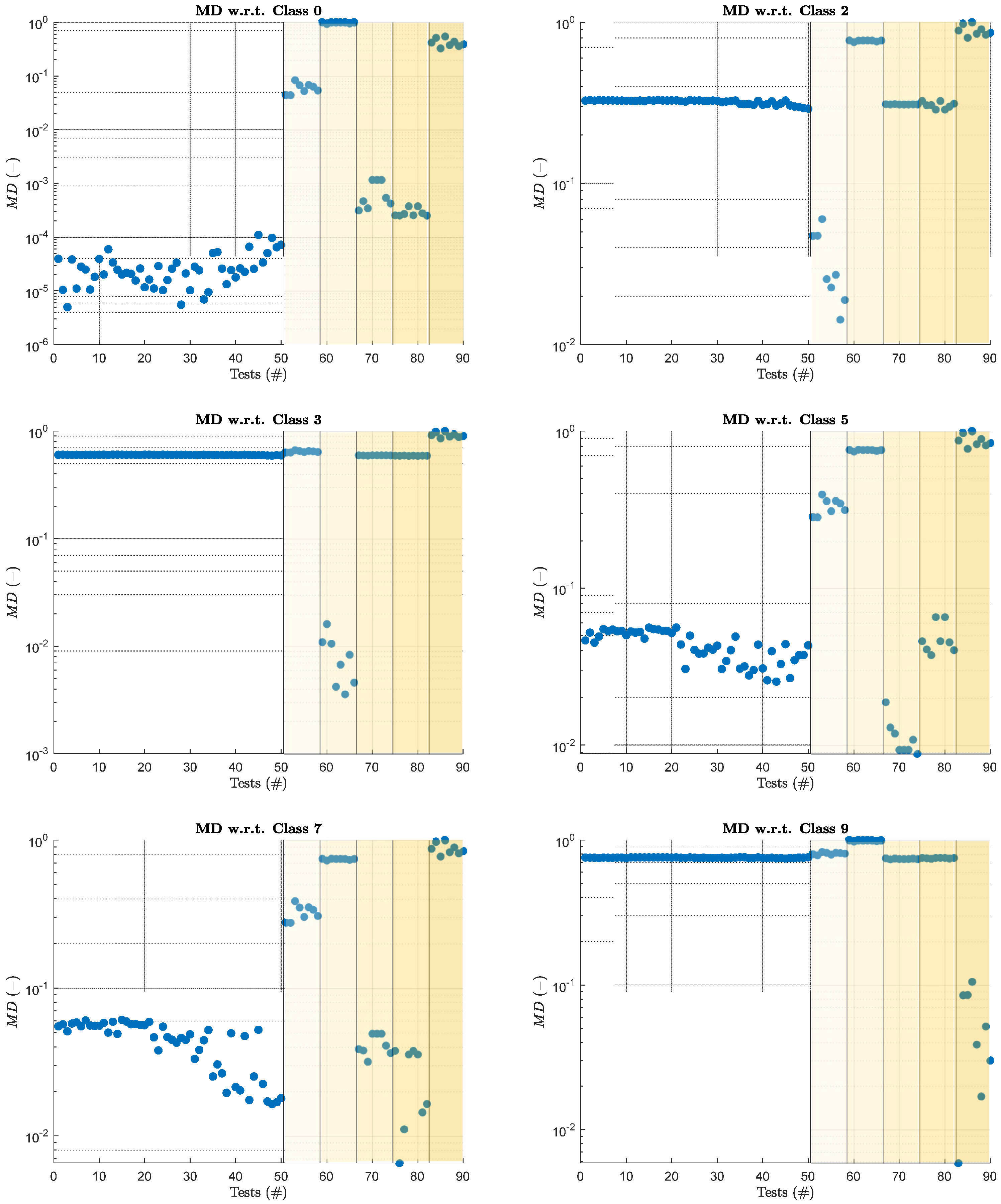
5.2. CCA+MNI Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations and Nomenclature
| AUC | Area Under the Curve |
| Labels vector | |
| CCA | Clusters Component Analysis |
| DRM | Dimensionality Reduction Method |
| Orthonormal vectors obtained from | |
| Matrix containing vectors | |
| ED | Euclidean Distance |
| GA | Genetic Algorithm |
| GMM | Gaussian Mixture Model |
| Type of damage | |
| kNN | k-Nearest Neighbors |
| LDA | Linear Discriminant Analysis |
| Number of tests | |
| MCCV | Monte Carlo Cross Validation |
| MD | Mahalanobis Distance |
| MNI | Multi-Novelty Indices |
| Number of features | |
| Number of MCCV iterations | |
| ND | Novelty Detection |
| NI | Novelty Index |
| PCA | Principal Component Analysis |
| ROS | Random Over-Sampling |
| RUS | Random Under-Sampling |
| Covariance matrix | |
| SCADA | Supervisory Control and Data Acquisition |
| SMOTE | Synthetic Minority Over-sampling Technique |
| Orthogonal vectors obtained from | |
| Vectors connecting the centers of the clusters | |
| Matrix containing vectors | |
| Features matrix | |
| New features matrix (after proposed DRM via transformation) | |
| New features matrix (after proposed DRM via transformation) |
References
- Worden, K.; Dulieu-Barton, J.M. An Overview of Intelligent Fault Detection in Systems and Structures. Struct. Health Monit. 2004, 3, 85–98. [Google Scholar] [CrossRef]
- Köppen, M. The Curse of Dimensionality. In Proceedings of the 5th Online World Conference on Soft Computing in Industrial Applications (WSC5), On the Internet (World-Wide-Web), 4–18 September 2000; Volume 1, pp. 4–8. [Google Scholar]
- Huang, X.; Wu, L.; Ye, Y. A Review on Dimensionality Reduction Techniques. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1950017. [Google Scholar] [CrossRef]
- Cunningham, J.P.; Ghahramani, Z. Linear Dimensionality Reduction: Survey, Insights, and Generalizations. J. Mach. Learn. Res. 2015, 16, 2859–2900. [Google Scholar]
- Ting, D.; Jordan, M.I. On Nonlinear Dimensionality Reduction, Linear Smoothing and Autoencoding. arXiv 2018, arXiv:1803.02432. [Google Scholar]
- Zubova, J.; Kurasova, O.; Liutvinavičius, M. Dimensionality Reduction Methods: The Comparison Of Speed And Accuracy. Inf. Technol. Control 2018, 47, 151–160. [Google Scholar] [CrossRef]
- Nguyen, L.H.; Holmes, S. Ten Quick Tips for Effective Dimensionality Reduction. PLoS Comput. Biol. 2019, 15, e1006907. [Google Scholar] [CrossRef] [Green Version]
- Sophian, A.; Tian, G.Y.; Taylor, D.; Rudlin, J. A Feature Extraction Technique Based on Principal Component Analysis for Pulsed Eddy Current NDT. NDT Int. 2003, 36, 37–41. [Google Scholar] [CrossRef]
- Wold, S.; Geladi, P.; Esbensen, K.; Öhman, J. Multi-Way Principal Components-and PLS-Analysis. J. Chemom. 1987, 1, 41–56. [Google Scholar] [CrossRef]
- Fukumizu, K.; Bach, F.R.; Jordan, M.I. Dimensionality Reduction for Supervised Learning with Reproducing Kernel Hilbert Spaces. J. Mach. Learn. Res. 2004, 5, 73–99. [Google Scholar]
- Schölkopf, B.; Smola, A.; Müller, K.-R. Nonlinear Component Analysis as a Kernel Eigenvalue Problem. Neural Comput. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Chandrashekar, G.; Sahin, F. A Survey on Feature Selection Methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Jardine, A.K.S.; Lin, D.; Banjevic, D. A Review on Machinery Diagnostics and Prognostics Implementing Condition-Based Maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Daga, A.P.; Garibaldi, L.; Fasana, A.; Marchesiello, S. ANOVA and Other Statistical Tools for Bearing Damage Detection. In Proceedings of the International Conference Surveillance, Fez, Morocco, 23 May 2017; pp. 22–24. [Google Scholar]
- Daga, A.P.; Garibaldi, L. Machine Vibration Monitoring for Diagnostics through Hypothesis Testing. Information 2019, 10, 204. [Google Scholar] [CrossRef]
- Castellani, F.; Garibaldi, L.; Daga, A.P.; Astolfi, D.; Natili, F. Diagnosis of Faulty Wind Turbine Bearings Using Tower Vibration Measurements. Energies 2020, 13, 1474. [Google Scholar] [CrossRef] [Green Version]
- Daga, A.P.; Garibaldi, L.; He, C.; Antoni, J. Key-Phase-Free Blade Tip-Timing for Nonstationary Test Conditions: An Improved Algorithm for the Vibration Monitoring of a SAFRAN Turbomachine from the Surveillance 9 International Conference Contest. Machines 2021, 9, 235. [Google Scholar] [CrossRef]
- Worden, K. Structural Fault Detection Using a Novelty Measure. J. Sound Vib. 1997, 201, 85–101. [Google Scholar] [CrossRef]
- Daga, A.P.; Fasana, A.; Garibaldi, L.; Marchesiello, S. On the Use of PCA for Diagnostics via Novelty Detection: Interpretation, Practical Application Notes and Recommendation for Use. In Proceedings of the PHM Society European Conference, Turin, Italy, 1 July 2020; Volume 5, p. 13. [Google Scholar]
- Pimentel, M.A.; Clifton, D.A.; Clifton, L.; Tarassenko, L. A Review of Novelty Detection. Signal Process. 2014, 99, 215–249. [Google Scholar] [CrossRef]
- Japkowicz, N.; Myers, C.; Gluck, M. A Novelty Detection Approach to Classification. In Proceedings of the Fourteenth Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 518–523. [Google Scholar]
- Viale, L.; Daga, A.P.; Fasana, A.; Garibaldi, L. From Novelty Detection to a Genetic Algorithm Optimized Classification for the Diagnosis of a SCADA-Equipped Complex Machine. Machines 2022, 10, 270. [Google Scholar] [CrossRef]
- Ebeling, B.; Vargas, C.; Hubo, S. Combined Cluster Analysis and Principal Component Analysis to Reduce Data Complexity for Exhaust Air Purification. Open Food Sci. J. 2013, 7, 8–22. [Google Scholar] [CrossRef] [Green Version]
- Ding, C.; He, X.; Zha, H.; Simon, H.D. Adaptive Dimension Reduction for Clustering High Dimensional Data. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi City, Japan, 9–12 December 2002; pp. 147–154. [Google Scholar]
- Data Challenge-PHME21. Available online: https://github.com/PHME-Datachallenge/Data-Challenge-2021 (accessed on 22 March 2022).
- Biggio, L.; Russi, M.; Bigdeli, S.; Kastanis, I.; Giordano, D.; Gagar, D. PHME Data Challenge. In Proceedings of the European Conference of the Prognostics and Health Management Society, Virtual Event, 28 June–2 July 2021. [Google Scholar]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- MacKay, D.J.; Mac Kay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Natili, F.; Daga, A.P.; Castellani, F.; Garibaldi, L. Multi-Scale Wind Turbine Bearings Supervision Techniques Using Industrial SCADA and Vibration Data. Appl. Sci. 2021, 11, 6785. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal Component Analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Lever, J.; Krzywinski, M.; Altman, N. Points of Significance: Principal Component Analysis. Nat. Methods 2017, 14, 641–643. [Google Scholar] [CrossRef] [Green Version]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis Distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Pearson, R.K. Outliers in Process Modeling and Identification. IEEE Trans. Control. Syst. Technol. 2002, 10, 55–63. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, E. Zur Theorie Der Linearen Und Nichtlinearen Integralgleichungen. In Integralgleichungen und Gleichungen mit Unendlich Vielen Unbekannten; Springer: Berlin/Heidelberg, Germany, 1989; pp. 190–233. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Elhassan, T.; Aljurf, M. Classification of Imbalance Data Using Tomek Link (t-Link) Combined with Random under-Sampling (Rus) as a Data Reduction Method. Glob. J. Technol. Optim. S 2016, 1, 1–11. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Tomek, I. Two Modifications of CNN. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 769–772. [Google Scholar]
- Tharwat, A.; Gaber, T.; Ibrahim, A.; Hassanien, A.E. Linear Discriminant Analysis: A Detailed Tutorial. AI Commun. 2017, 30, 169–190. [Google Scholar] [CrossRef] [Green Version]
- Kataria, A.; Singh, M.D. A Review of Data Classification Using K-Nearest Neighbour Algorithm. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 354–360. [Google Scholar]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An Introduction to Decision Tree Modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Wickramasinghe, I.; Kalutarage, H. Naive Bayes: Applications, Variations and Vulnerabilities: A Review of Literature with Code Snippets for Implementation. Soft Comput. 2021, 25, 2277–2293. [Google Scholar] [CrossRef]
- Xu, Q.-S.; Liang, Y.-Z. Monte Carlo Cross Validation. Chemom. Intell. Lab. Syst. 2001, 56, 1–11. [Google Scholar] [CrossRef]
- Torra, V.; Narukawa, Y. On a Comparison between Mahalanobis Distance and Choquet Integral: The Choquet–Mahalanobis Operator. Inf. Sci. 2012, 190, 56–63. [Google Scholar] [CrossRef]
- Li, X.Q.; King, I. Gaussian Mixture Distance for Information Retrieval. In Proceedings of the IJCNN’99. International Joint Conference on Neural Networks. Proceedings (Cat. No. 99CH36339), Washington, DC, USA, 10–16 July 1999; Volume 4, pp. 2544–2549. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | LDA | KNN | Decision Tree | Gaussian N.B. | Kernel N.B. |
|---|---|---|---|---|---|
| Accuracy | - | 81.5% | 76.9% | - | 71.4% |
| Missed Alarms | - | 15.5% | 6.5% | - | 28.6% |
| False Alarms | - | 1.5% | 7.1% | - | 0.1% |
| Class Errors | - | 1.5% | 9.6% | - | 0.0% |
| P.I. | - | 66.79% | 60.39% | - | 50.95% |
| Frobenius N. | - | 2.35 | 2.04 | - | 3.16 |
| AUC | - | 0.99 | 1.00 | - | 1.00 |
| Index | LDA | KNN | Decision Tree | Gaussian N.B. | Kernel N.B. |
|---|---|---|---|---|---|
| Accuracy | 78.2% | 76.7% | 74.6% | 60.0% | 74.3% |
| Missed Alarms | 14.1% | 13.3% | 16.2% | 10.2% | 13.6% |
| False Alarms | 7.2% | 6.5% | 6.3% | 22.8% | 6.6% |
| Class Errors | 0.5% | 3.5% | 3.0% | 7.0% | 5.5% |
| P.I. | 62.0% | 60.0% | 56.8% | 38.7% | 56.7% |
| Frobenius N. | 2.10 | 2.08 | 2.34 | 1.97 | 2.13 |
| AUC | 0.85 | 0.97 | 0.90 | 0.89 | 0.99 |
| Index | LDA | KNN | Decision Tree | Gaussian N.B. | Kernel N.B. | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 98.4% | (+20.3%) | 94.2% | (+17.5%) | 80.9% | (+6.3%) | 89.4% | (+29.4%) | 86.6% | (+12.3%) |
| Missed Alarms | 1.3% | (−12.8%) | 5.7% | (−7.6%) | 5.0% | (−11.1%) | 2.1% | (−8.1%) | 6.6% | (−7.0%) |
| False Alarms | 0.2% | (−7.0%) | 0.1% | (−6.4%) | 4.3% | (−2.0%) | 7.1% | (−15.7%) | 4.4% | (−2.2%) |
| Class Errors | 0.0% | (−0.5%) | 0.0% | (−3.5%) | 9.8% | (+6.8%) | 1.4% | (−5.5%) | 2.4% | (−3.1%) |
| P.I. | 96.9% | (+34.9%) | 88.7% | (+28.7%) | 66.3% | (+9.5%) | 80.2% | (+41.5%) | 75.4% | (+18.7%) |
| Frobenius N. | 0.33 | (−1.8) | 1.12 | (−1.0) | 1.91 | (−0.4) | 0.59 | (−1.4) | 1.38 | (−0.8) |
| AUC | 1.00 | (+0.2) | 1.00 | (0.0) | 0.97 | (+0.1) | 0.99 | (+0.1) | 0.99 | (0.0) |
| Index | LDA | KNN | Decision Tree | Gaussian N.B. | Kernel N.B. | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 97.6% | (−0.8%) | 97.3% | (+3.1%) | 98.2% | (+17.3%) | 98.3% | (+8.9%) | 97.8% | (+11.2%) |
| Missed Alarms | 1.1% | (−0.2%) | 2.4% | (−3.3%) | 0.0% | (−5.0%) | 0.0% | (−2.1%) | 0.6% | (−5.9%) |
| False Alarms | 1.3% | (+1.0%) | 0.3% | (+0.2%) | 0.0% | (−4.3%) | 1.2% | (−5.8%) | 0.0% | (−4.4%) |
| Class Errors | 0.0% | (0.0%) | 0.0% | (0.0%) | 1.8% | (−8.0%) | 0.5% | (−0.9%) | 1.6% | (−0.9%) |
| P.I. | 95.3% | (−1.6%) | 94.7% | (+6.0%) | 96.4% | (+30.1%) | 96.6% | (+16.4%) | 95.6% | (+20.2%) |
| Frobenius N. | 0.18 | (−0.2) | 0.38 | (−0.7) | 0.27 | (−1.6) | 0.10 | (−0.5) | 0.29 | (−1.1) |
| AUC | 1.00 | (0.0) | 1.00 | (0.0) | 1.00 | (0.0) | 1.00 | (0.0) | 1.00 | (0.0) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viale, L.; Daga, A.P.; Fasana, A.; Garibaldi, L. Dimensionality Reduction Methods of a Clustered Dataset for the Diagnosis of a SCADA-Equipped Complex Machine. Machines 2023, 11, 36. https://doi.org/10.3390/machines11010036
Viale L, Daga AP, Fasana A, Garibaldi L. Dimensionality Reduction Methods of a Clustered Dataset for the Diagnosis of a SCADA-Equipped Complex Machine. Machines. 2023; 11(1):36. https://doi.org/10.3390/machines11010036
Chicago/Turabian StyleViale, Luca, Alessandro Paolo Daga, Alessandro Fasana, and Luigi Garibaldi. 2023. "Dimensionality Reduction Methods of a Clustered Dataset for the Diagnosis of a SCADA-Equipped Complex Machine" Machines 11, no. 1: 36. https://doi.org/10.3390/machines11010036
APA StyleViale, L., Daga, A. P., Fasana, A., & Garibaldi, L. (2023). Dimensionality Reduction Methods of a Clustered Dataset for the Diagnosis of a SCADA-Equipped Complex Machine. Machines, 11(1), 36. https://doi.org/10.3390/machines11010036