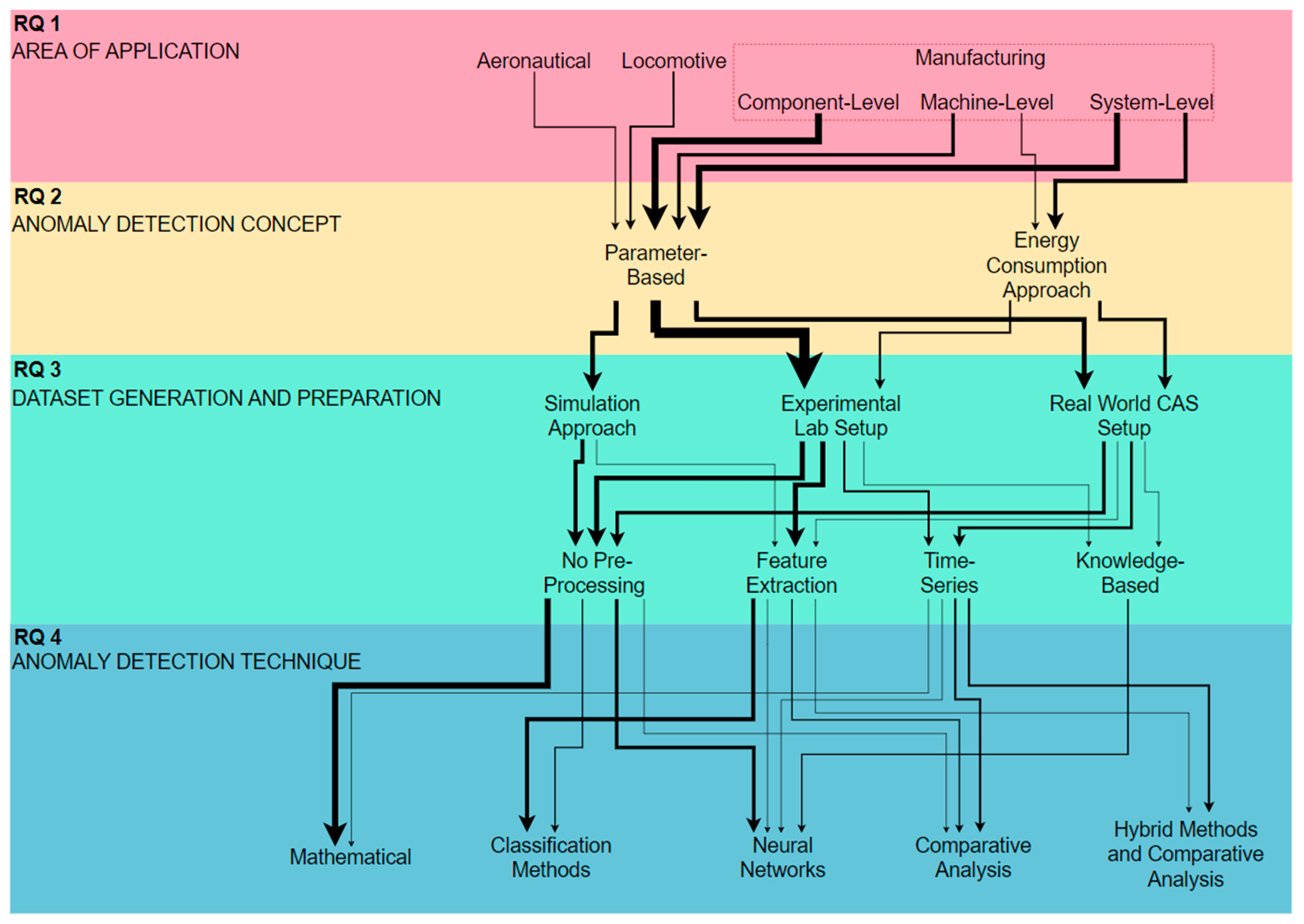
The third RQ aims to identify how the data in the various literature sources being reviewed are generated and processed for the subsequent anomaly detection techniques based on intelligent approaches. A common trait across the included publications is the involvement of both a normal fault-free operation and a single or multiple faulty condition operation. This is required for the training, testing and validation of the developed anomaly detection model. Not all the reviewed studies performed the data preparation step, and those that did based their application on the selected anomaly detection technique. Therefore, this section will discuss the dataset generation and the consequent data processing implemented.
Dataset Generation
From the included publications, the main three groups of dataset generation are simulation approaches, experimental setup approaches within a lab-based environment, and real-world CAS installation in a typical industry setup. The obtained results are shown in
Figure 8, and the categorisation can be seen in
Table 5.
The simulation approach was mainly characterised by DAMADICS implementation, where only two from seven publications of this subgroup focused on other CAS elements. Assis Silva et al. [
34] generated a dataset from a validated non-linear model of a PRSOV with pneumatic feedback, resulting in 40,000 simulated samples for each of the required excitation profiles. In this study, three failure modes were simulated by modifying the chosen degradation factors. This study went a step further in considering sensors’ uncertainties within the dataset generation, and hence typical random values were included for the manifold pressure, valve angle, and engine pressure in each time step, after the simulation process [
34]. Similarly, the research conducted by Graves et al. [
35] involved dataset generation through the simulation of a validated non-linear model for a pneumatic actuator. It is worth noting that both studies are within the aeronautical industry, as identified by the first RQ. On the other hand, the research carried out by [
46,
47,
48,
49,
50] involved the use of the DAMADICS benchmark for the simulation of pneumatic control valve behaviour while generating a dataset involving a normal operation profile, with the possibility of 19 faulty operation ones.
Conversely, the investigation carried out by Han et al. [
47] validated the simulation approach by comparing the generated dataset with a real-world dataset. In this case, data were collected for 17 minutes from an installed pneumatic control valve, which included a fault-free operation and a single-fault operation by inducing one artificially generated fault within the installation [
47]. The studies performed by Mahalingam et al. [
48], Elakkiya et al. [
49], and Korablev et al. [
50] involved the same simulation procedure of Andrade et al. [
46], where these used the DAMADICS benchmark.
Experimental lab-based case studies comprised 49% of the papers. Two of the locomotive publications involved this approach, such as Wang et al. [
37] collected data from a three-cab in-lab experimental platform, while Sun et al. [
39] generated a dataset from a jig that replicated the actual pneumatic train door subsystem. Wang et al.’s [
37] work involved the use of 15 pressure sensors strategically placed within the CA brake system. Thus, the experimental platform was capable of simulating different operational conditions while inducing typical brake faults, such as brake pipe leakage [
37]. The study performed by Sun et al. [
39] involved the generation of a dataset from a pressure transducer wired to an embedded controller. In this case, four levels of leakage were artificially induced, along with a normal operation condition, during dataset generation [
39].
The study carried out by Dobossy et al. [
51] involved the use of a testbench, where twenty production process cycles were collected using a number of sensors, which were an accelerometer, airflow rate, pressure, and proximity sensors, a load cell, a microphone and a thermocouple. Data were collected for three reference processes in a separate manner. These were a drilling operation, an assembly of press-fitting parts, and the transfer of components for an assembly operation. The dataset generation and collection were handled and managed on individual NI-cDAQ modules and controlled by the NI-cDAQ 9172 chassis [
51]. Similarly, Kostkurkov et al. [
65] generated and collected two hundred operating cycles of data from an experimental setup. These data comprised a continuous measurement of airflow values for three levels of CA pressure. Additionally, discrete actuator signals were collected from the PLC module to correlate the CA flow and pressure measurements with the production system operations. In this case, leaks were artificially induced during the data collection process [
65].
In the case of both Demetgul et al. [
55,
56,
57] and Liu et al. [
72], their investigations involved a machine-level experimental setup. In [
55,
57], a servo-pneumatic positioning experimental setup built by FESTO Didactic was used for the generation of the required dataset. Experimental data were collected by using an NI-cDAQ system and control modules. The data included measurements from four analogue transducers measuring the pressures of the entire system. The airflow was controlled via a proportional directional control valve, while position measuring was performed with the use of linear potentiometers and a contactless absolute magnetostrictive linear displacement sensor. The gripper was equipped with two proximity sensors to detect whether it was in the closed or open position. The dataset was generated by operating the system with the mentioned sensors for a period of 27 seconds and for three times at each experimental condition. Thus, eleven different conditions were generated, one of which was considered the normal fault-free condition [
55,
57]. In the case of [
56], the dataset generation represented a bottle filling plant; however, the same approach was implemented for data management. The study performed by Liu et al. [
72] involved an experimental setup representing a complex CAS. This setup simulated the process of soft-landing systems within a roll grinder, which is supported and cushioned by two synchronous pistons. Faults were simulated by the manipulation of pressure variabilities [
72].
The studies performed by Cabrera et al. [
58] and Prashanth et al. [
66] involved a compressor-based experimental setup. In Cabrera et al. [
58], an accelerometer was vertically placed on a two-stage compressor for data collection purposes. The analogue signal was transferred by wire to a National Instrument compact data-acquisition card (NI9234 cDAQ) specifically designed for vibration measurements. The card performed the analogue-to-digital conversion at the desired sampling frequency. The cDAQ was attached to the NI9188 chassis to stream the digital signal to a laptop through an Ethernet link. During the data collection process, four anomalies were artificially induced, along with a healthy condition situation, in which a total of seventeen operational conditions were generated [
58]. Similarly, Prashanth et al. [
66] vertically mounted a triaxial piezoelectric accelerometer on the compressor’s cylinder head. Additionally, four types of faults were included by selectively assembling them within the experimental setup. The same approach for data collection was performed by interfacing the accelerometer with an NI-9174 data acquisition unit for data storage on a laptop [
66].
Conversely, the studies performed by Venkata et al. [
41], Yerra et al. [
42], and Subbaraj and Kannapiran [
43] focused on one pneumatic component, rather than the compressor system. Apart from this, all three publications featured a different approach on which data were collected. Similarly to [
58,
66], Venkata et al. [
41] generated a vibrational dataset from an accelerometer during real-time operation of a pneumatic control valve within a water system. Data acquisition was performed via an NI sound-and-vibration input module in conjunction with a wireless and Ethernet carrier. Two faults were considered, which were an insufficient supply pressure and an inflow fault, and data were binarily categorised, i.e., normal or faulty. NIMAX, which is an acquisition setup by MATLAB, was used for data processing [
41]. In contrast, the research performed by Subbaraj and Kannapiran [
43], could be considered similar to the DAMADICS-based research [
46,
47,
48,
49,
50]; however, data were collected from a test bed that involved a pneumatic servo-actuated industrial control valve. Both fault-free and faulty data were collected to generate a dataset that represented a complete range of operating conditions. For simplification purposes, this study only introduced one fault at a time, where the chosen fault conditions belonged to the same fault types of the DAMADICS benchmark. Data collection was carried out directly from the real-time system interfaced with a personal computer and a c-DAQ card [
43]. An interesting approach was used by Yerra et al. [
42], as the dataset comprised measurements from piezofilm sensors for the acquisition of valve acoustic signals through an unintrusive method. This differs from any other included publication. Two sensor positions were investigated to select the optimal data acquisition position for data analysis. A signal conditioning circuit with a preamplifier was connected to these sensors for the removal and minimisation of unwanted noise and disturbance. Additionally, the three pneumatic valves within the experimental setup were controlled by a PLC program. The investigation was based on one of these valves only, which was a pneumatically operated Burkert 2/2-way valve (Type 2100) of angle-seat type [
42].
Liao et al. [
69], Cupek et al. [
53,
54,
68], and Santos et al. [
70] all focused on demand-side anomaly detection implementations. Liao et al. [
69] generated a dataset from ultrasonic sensor readings of an experimental setup, including a man-made pinhole within a CA tube piping. An Advantech data acquisition card was used to collect and feed data into an analogue-to-digital converter, which was then stored on a computer for data processing [
69]. In Cupek et al.’s [
53,
54,
68] research, a laboratory test stand that comprised typical pneumatic components by FESTO, was used for data generation. The data collected were made up of four series of fifteen cycles each, and included both cumulative air consumption from an airflow meter and component output signals from a Siemens PLC [
68]. The dataset generation procedure presented in [
53,
54] went a step further than the simple dataset generation in [
68]. A framework was set up for a mass-customised production process that consisted of a number of functional blocks to standardise dataset generation, preparation and consequent analysis. Cupek et al. [
53,
54] developed a monitoring block that directly uses the output control signals of the actuators in the Siemens PLC memory and communication co-processor that supports industrial Ethernet. The dataset included energy consumption measurements derived from the station’s CA supply input. Additionally, the system tracks the time during which pneumatic devices are supplied with air by monitoring the opening and closing time of the valves located on the pneumatic terminals from PLC signal recording. The data collected were divided into three different groups with different energy consumption profiles over time [
53,
54]. Finally, the study performed by Santos et al. [
70] involved a laboratory-based setup consisting of a galvanised iron pipeline of sixty metres length, along with a domestic-type LPG vessel used as a pressure vessel for experimentational purposes. Faults were manually triggered by the opening and closing of a quick valve installed within the CA pipeline distribution system. Similarly to [
69], data were collected from a microphone, amplified, converted by an analogue-to-digital converter, and stored on a microcomputer [
70].
The 32% of the publications discussed in this subsection collected a dataset from a real-world CAS installation. A real-world dataset was used in [
38], which was not generated by the research team, but obtained from the ECP braking system of a DK-2 locomotive from Shouhuang Railway. Within the manufacturing research field, Rajashekarappa et al. [
52] presented a real-world implementation, as opposed to the investigations carried out by [
41,
42,
43,
51,
65]. Rajashekarappa et al. [
52] generated their dataset comprising airflow, temperature, and pressure sensors from a real-world pneumatic production system. Data collection was carried out during two periods: initially during a planned shutdown and then during normal production hours. Artificial anomalies were induced in the cell of a packaging process by drilling a hole in an external plug connected to a pneumatic tee tube-to-tube adapter. During planned shutdown, a 1 mm leak was used, while during normal production hours, a 0.8 mm leak was set up. The generated dataset was collected in the form of a ‘CSV’ file and then extracted on a ‘Grafana’ visual interface [
52]. In contrast to [
41,
42,
43], Kovács et al. [
44,
45] generated a real-world dataset collected from a Hungarian multinational manufacturer of electrical components between May 2018 and February 2019. A 0–20 mV signal from a pneumatic actuator was collected and recorded as a CSV file, similarly to [
52], where it runs in a sequence of six to eight cycles under normal operating conditions.
The publications by [
59,
60,
67] generated a dataset from a supply-side system, either from a compressor or an accumulator. In the case of Cui et al. [
59], the dataset was generated from a 22 kW compressor. This dataset was collected from the compressor’s condition monitoring system (CMS), where thirteen different variables, including inlet and outlet pressure temperature and vibrational values, are measured and appended every five minutes. Thus, the process of data collection was very easy and flexible, since a direct download from the CMS was available. The dataset included 1380 groups of historical fault-free data and was divided in three groups. The first dataset was used to construct the historic memory matrix of the model, the second to verify model accuracy while determining the fault warning threshold, and the third to test the effect of the fault measure and early warning system. No faults were purposely induced during dataset generation, as a typical air compressor fault occurred during the data collection window [
59]. On the other hand, the study performed by Holstein et al. [
60] involved a different approach from [
59], but similar to those performed by [
51,
70]. This is because the dataset was generated by measurements collected from the structure-borne sound probe T10 from SONOTEC and a microphone MK301 from Microtech Gefell. Due to the nature of the data, a 24-bit c-DAQ card was required, in this case DT 9847-2-2, to be able to measure low frequencies [
60]. The research of Desmet et al. [
67] involved the generation of two datasets. The purpose of the first dataset was to be fault-free to discover the sawtooth patterns for accumulator charging and discharging and the activation of air-actuated components. The other dataset was generated to detect the anomalies from the presented algorithm, which will be identified by the fourth RQ. Fault simulation was performed by inducing a moderately leaking nozzle, where the air consumption rate increased by 25% from normal condition operations [
67].
The remaining publications within this subsection are associated with the investigations performed by the research team of F. Bonfa, M. Benedetti, and A. Santolamazza et al. [
61,
62,
63,
64]. The dataset generation for these studies stemmed from the measurement of potential parameters collected from five compressors within an Italian pharmaceutical manufacturing company. One of the compressors served as the master, and hence this was working continuously, while the other four compressors served as slaves to top up when the manufacturing demand increased. The energy and CA production data were collected at an interval of 15 min, and included pressure, temperature and external air humidity. The number of running hours for each compressor was available weekly in a cumulative format [
61,
62]. In addition to this, Santolamazza et al. [
63,
64] chose particular energy drivers for analysis, which were low-pressure flow rate of 3 bar, medium-pressure flow rate of 8 bar, the external air temperature from which the external air humidity could be derived from, and the binary state of the single compressors. This meant that the state is ‘0′ when energy consumption of the associated compressor is less than 1 kWh/15 min, while if the compressor’s energy consumption is more than 1 kWh/15 min, the state is equal to ‘1′ [
63,
64].
Dataset Preparation
In addition to dataset generation, RQ3 seeks to understand the data processing techniques, if any are performed. It can be deduced that preprocessing was not performed for almost half of the reviewed studies, where 46% of the selected publications did not manipulate the data prior to analysis.
Figure 9 provides a visual representation of the results obtained for the analysis of dataset preparation techniques identified in response to RQ3.
Table 6 shows the categorisation of studies based on the selected dataset preprocessing technique.
The first category groups included publications that did not involve any specific preprocessing technique on the generated dataset. For this group of publications, the anomaly detection development is directly based on the dataset collected, where no specific relationships are required beforehand. It was noticed that only one of the publications that adopted a simulation-based approach [
34] performed a preprocessing technique. The other publications did not. including the studies using the DAMADICS benchmark [
46,
47,
48,
49,
50] and one of the aeronautical applications [
35]. A different approach was implemented by Kostkurkov et al. [
65]. This was purely a time-series one, as the research team decided to implement a direct analysis of CA supply flow rate with time-series diagrams. This was then developed for the anomaly detection process, which is discussed when answering RQ4. The studies performed by Bonfa et al. [
61], Benedetti et al. [
62], and Santolamazza et al. [
63,
64] did not involve any particular data preprocessing techniques either. However, it was still ensured that high-quality data were obtained through a manual or automated data handling process, depending on the dataset size and complexity. Measurement data inaccuracies were also considered and checked for [
61,
62,
63,
64]. Additionally, in [
64], data cleaning of unwanted data was performed due to the nature of the selected anomaly detection methodology. Similarly, Demetgul et al. [
56] did not perform any data processing, which was also observed in the mathematical-based research studies by [
55,
57,
68,
69,
70].
Feature extraction is a process of reducing data dimensionality through methods that combine variables into features while still accurately representing the original dataset. This process helps in reducing computational time due to the reduction in dataset complexity, though without losing any relevant information within the dataset [
73,
74]. Assis Silva et al. [
34], defined a set of hysteresis envelopes to obtain a range of degradation factors. Thus, features were obtained by the generation of predetermined behaviour of the pneumatic valve, along with consequent analysis of the collected dataset [
34]. It is important to consider that this is a specific area of research, and such implementation cannot be adapted to a manufacturing CAS implementation. The studies carried out by Cui et al. [
59] and Venkata et al. [
41] involved a window approach to preprocess their datasets. Both data filtering and preprocessing were involved in the investigation by Cui et al. [
59], with the aim of creating a high-quality dataset that consequently aids in obtaining better model accuracy and reliability for anomaly detection. The procedure included the separation of abnormal data vectors in two, where dynamic operating points, such as the sudden opening of a valve or during an abrupt decrease in load, and outliers were identified. For the former, steady operating vectors were required and obtained with the implementation of a sliding window method to select such steady-state vectors. In this case, these were chosen as the motor current and motor power. On the other hand, the outliers, which were characterised as abnormal samples caused by electromagnetic interferences and sensor failures, were eliminated by implementing a k-means algorithm for classification purposes [
59]. On the other hand, Venkata et al. [
41] implemented the NIMAX approach, which processed the vibrational data as sine waves, and hence kept them in the frequency domain. This was performed as it was more complex to obtain the time-domain features due to the requirement of sinusoidal waveform summation. Since digital inputs were used, a discrete Fourier transform was implemented, along with power spectrum density analysis. The latter produced better results, as the acquired vibrational data were random and had no prior knowledge of the vibration mode. To minimise the effect of having data discontinuity, a window function was adopted, which is similar to the approach implemented by Cui et al. [
59]. The ‘Hanning’ window concept was selected, and resulted in better division of the raw dataset frequency. This was performed for both the Fourier transform and the power spectrum density function [
41].
In the research of Cupek et al. [
53,
54], pre-analysis of the data identified a number of observations. These included: (i) the speed of data collection, where the actual production stand was replaced by an experimental one to minimise the number of controlled components; (ii) the parallelism of processes, where analysis was conducted on sequential states; and (iii) the consideration of how to distinguish energy consumed according to the setup activity, which means to filter out passive energy consumption components that are uncommon for pneumatic systems. Then, dimensionality reduction for the generated dataset was carried out by using diffusion maps (DMs), local linear embedding (LLE) and AE methods. DMs use eigenfunctions of Markov matrices to consider effective representation of data geometry descriptions of the original dataset to obtain coordinates. On the other hand, the LLE technique is purely for dimensionality reduction, similar to an ‘Isomap’, as it constructs a graph representation of the datapoints. In this research, the data were embedded in five dimensions [
53,
54]. A similar approach was adopted by Demetgul et al. [
57], where an intelligent approach was used for data reduction. Similarly, the dataset was subjected to three different methods, being DMs, LLE, and AE. These were purposely selected and implemented to reduce the dimensionality of the data, while obtaining useful properties for the consequent anomaly detection techniques [
55]. Prashanth et al. [
66] performed feature extraction and dimensionality reduction to save computational time. The extracted features were statistical and subjected to the J48 algorithm based on decision trees (DTs). Such a method prioritised the extracted statistical features most relevant to the generated dataset [
66]. Wang et al. [
37] performed feature extraction and dimensionality reduction through an AI process. Phase partitioning and classification was carried out, identifying the braking operations of a pneumatic air brake system for locomotive application. In this case, a modified reinforcement learning-based algorithm was adopted to execute feature selection, and this approach was selected to minimise overfitting and computational complexity. Due to the nature of the implementation, it was possible to extract features that could be further divided into statistical and time-domain spaces. Contrast features were also derived from the generated dataset to provide complementary information for fault diagnosis simplification. Both the divided and contrast features were grouped together to produce integrated features for the classification of faulty component types within the abnormal conditions of the locomotive application [
37].
Both Dobossy et al. [
51] and Rajashekarappa et al. [
52] implemented feature selection by extracting the required condition indicators. In the case of Dobossy et al. [
51], a condition indicator extraction was performed to extract and select signal-based condition indicators. Such feature extraction was performed in both the time and frequency domains, and included mean, standard deviation, RMS, and shape factor, amongst others, for the time-domain dataset, along with peak amplitude, peak frequency and band power for the frequency-domain dataset. This was followed by the integration of the relief-F algorithm for the required feature selection to reduce data dimensionality, as it tends to improve the quality of the selected classification model for anomaly detection. This algorithm was chosen after comparing a number of feature selection techniques on synthetic data, as it produced the best results [
51]. Therefore, Dobossy et al. [
51] removed any correlated and redundant features, while minimising non-linearity and feature noise. In the case of Rajashekarappa et al. [
52], the required data cleaning and dataset preparation was initially performed, which involved outlier removal with the use of a box plot for airflow, along with idle time removal. Then, data points corresponding to normal and abnormal conditions were extracted separately, followed by binary data labelling. Before implementing feature extraction, the new set of data was regrouped based on a newly defined time dimension, known as ‘processing time’. This represented the time in which the machine was in its working status. Thus, feature extraction was then performed with the same tool used by [
51]. In this case, only the time-domain features were extracted for the dataset variables, including pressure, temperature and airflow. Additionally, a Kruskal–Wallis test was performed, since an assumption of normal distribution could not be made for the generated dataset [
52].
Time-series data include a lot of information regarding system behaviour; however, it is tedious to extract certain details without the required preprocessing. The study performed by Cabrera et al. [
58] involved the manipulation of time-domain raw vibration signal data. A set of condition indicators were computed through time, followed by mathematical scaling. Thus, the resulting dataset included scaled condition indicators which are adapted into subsignals for anomaly detection implementation [
58].
Wavelet transformation, as part of a time-series analysis, was carried out by both Desmet et al. [
67] and Liu et al. [
38]. Desmet et al. [
67] filtered and cleansed their datasets from any unnecessary noise that could make it difficult to visualise the accumulator’s behaviour. Preprocessing involved feature derivation, where the raw time-series pressure signal was transformed to form a set of inputs. This was followed by the implementation of the wavelet transform, in which case the Morlet wavelet was selected [
67]. This decision was based on literature, as Desmet et al. [
67] found several applications of it for anomaly detection purposes. Similarly, Liu et al. [
38] filtered out useless information from the acquired dataset and performed a correlation analysis to identify the most significant relationships between the measured variables. Liu et al. [
38] made sure that all values within the dataset were positive integers, while the time values were uniformly converted into a standard time-stamp conversion. This was followed by feature extraction of the time and frequency domains, extraction of correlation features, and wavelet packet decomposition. Thus, this research implemented more than one feature selection process for a multidimensional approach [
38]. Another time-series preprocessing implementation was carried out by Holstein et al. [
60]. Calculation of the statistical values of RMS, crest, and kurtosis values for the collected acoustical data, including ultrasound ones, was combined with both spectral and filter operations. The former can be described by means of Fourier forward transform (FFT) spectra, or derived time-domain filtered presentations [
60].
In their investigation, Kovács et al. [
44,
45] prepared a high-quality and balanced dataset where any unnecessary data were removed. This was followed by down-sampling through interpolation for the required pneumatic actuator’s signal preprocessing. The preprocessing was initiated by data format conversion from ‘.csv’ to ‘xts’ time-series objects so that time-series functions and analysis could be carried out within the R environment. Additionally, each datapoint was assigned a time stamp, while removing any duplicate or erratic data. The inclusion of a threshold indicator based on the average of the rolling standard deviation was also performed. Sequences were then split into individual signals for each reciprocating cycle of the actuator [
44,
45]. For Kovács et al. [
44,
45], the signal shape was important, as it is capable of carrying and identifying specific conditions of the pneumatic actuator. A peak detection method was also implemented to identify the beginning of a signal, which finds the earliest local maximum above a set threshold. Cycle time issues were managed by a cut-off point set at a constant time period less than the average cycle time. The split and processed signals were stored in a ‘csv’ file once again, along with developing ‘png’ files to continuously observe the cycle pattern [
44,
45].
In Sun et al.’s [
39] research, the collected pressure data were transformed into a 2D dimension space. Thus, after mean filtering and normalisation, the CA pressure data were segmented, where for each segment, they are divided into equal parts that contain a number of sampling points. Then, these parts were taken as a line of the 2D image [
39]. Finally, the research by Yerra et al. [
42] involved acoustic signals similar to [
60]. Signals were first normalised to compensate possible gains that could have been introduced by the analogue signals conditioning circuits, used to assist sensors. The resulting dataset was then subjected to a computation of short-term energy profiles and a moving average calculation, which acted as a low-pass filter to reduce any random data fluctuations. It was ensured that during the latter preprocessing implementation, no profile features were lost. Quantisation was performed by predefining six different levels with a minimum and maximum value. This made it easier for consequent pattern categorisation during anomaly detection implementation [
42].
The studies performed by Thabet et al. [
71] and Subbaraj and Kannapiran [
43] involved a knowledge-based approach, which will be delved into when answering the final RQ. These differ from the other studies, as the implemented data preprocessing is specific to the approach selected for anomaly detection. Thabet et al. [
71] specified that data processing will be an intelligent one, i.e., with the use of ML methods, where an AI model based on knowledge management will then be able to act on it. On the other hand, Subbaraj and Kannapiran [
43] normalised the data collected for the required knowledge-based anomaly detection implementation. This means that all the input variable data were compressed in the range between ‘0’ and ‘1’ [
43].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














