Development of a Methodology for Condition-Based Maintenance in a Large-Scale Application Field



Abstract
:1. Introduction
2. Condition-Monitoring Architecture
2.1. Data Acquisition
- Continuous Condition Monitoring; Sensors are recorded continuously. This sampling policy is recommended for those critical components with a high impact on the costs and a short time-to-failure.
- Periodic Condition Monitoring; Sensors are recorded at scheduled time intervals. This policy is particularly suitable for components with a medium–high time-to-failure.
2.1.1. On-Line Data
- Multi-purpose external sensors; They are the most used sensors for condition monitoring. They can be applied to different components (multi-purpose), measuring the effects of impacts or events in time domain and include for example accelerometers or external temperature sensors. These sensors are not usually present in the machine and represent an extra cost for maintenance.
- Specific external sensors; They are used for a specific measurements in specific parts of the machine. Sometimes multi-purpose sensors cannot be used because of the impossibility of installation, such as environmental conditions or some possible mechanical interference with moving parts during the process. Sometimes a specific measurement is needed in a very limited but critical part of the plant, for example chemical analysis. These sensors are not usually present in the machine and represent an extra cost for maintenance. Moreover, the specificity of the measurement implies a higher cost of the sensor with respect to a multi-purpose sensor.
- Embedded sensors; They are already present in specific components of the machine, since they are used by control logics for the correct operation of the machinery. They do not represent an extra cost for maintenance. For example, in the modern servomotors there is always an encoder for position measurement, an embedded amperometer (often by means of two simple Hall sensors) for the measurement of the current absorbed by the mains, and a temperature sensor (often embedded in the encoder) for the measurement of the heat inside the motor (or at least a positive temperature coefficient (PTC) thermistor in the coils for detection of over temperature).
- Accelerometers; These measure the vibrations of the mechanical components (e.g., rotating shafts), giving a picture of the inner health of the machine. Every month hundreds of scientific papers on the use of accelerometers for diagnostics purposes are published (multi-purpose external sensors) [20,21,22,23].
- Encoders; These measure the position of rotating parts (e.g., shafts), providing a flag at each complete rotation. In particular, encoders are increasingly present in electric motors, embedded in any servomotor with a high angular resolution (e.g., 4096 ticks per revolution). Together with accelerometers, they allow the diagnostics of the components in the angle-domain, that is, a reconstruction of the vibration signal based on the actual rotation of the component, providing immunity to speed fluctuation which can make the noise-to-signal ratio worse [24,25,26] (embedded sensors).
- Current/torque sensors; These are embedded sensors necessary for the correct operation of an electric motor. The current absorbed by the motor is proportional to the torque load applied to the motor shaft. It is straightforward that any change in the working conditions of the motor (e.g., an increase of the wear) increases the torque load and consequently the current requested (embedded sensors).
- Pressure sensors; In order to avoid any possible interference between the moving parts of the package forming line and the cables of the sensors, it is necessary to introduce pressure sensors for the indirect measurement of the wear on cutting knives (specific external sensors).
- Temperature sensors; These measure the temperature of specific components. In particular, servomotors can have an embedded temperature sensor to measure the heat inside the motor (embedded sensors).
2.1.2. Off-Line Data
2.2. Data Pre-Processing
- An industrial PC (iPC) for data manipulation;
- Data logger hardware for the acquisition of external sensors;
- Fieldbus (IEC 61158) network for data communication between the iPC and motor drives (or other embedded sensors).
- Removal of empty or incomplete files; The condition-monitoring system records data regularly. Only a few sensors at a time collect data so as to reduce computational efforts. It could be that specific parts of the system are not working during the time frame when the corresponding sensor is acquired, generating empty or incomplete files. These files must be removed to free memory space on the storage device.
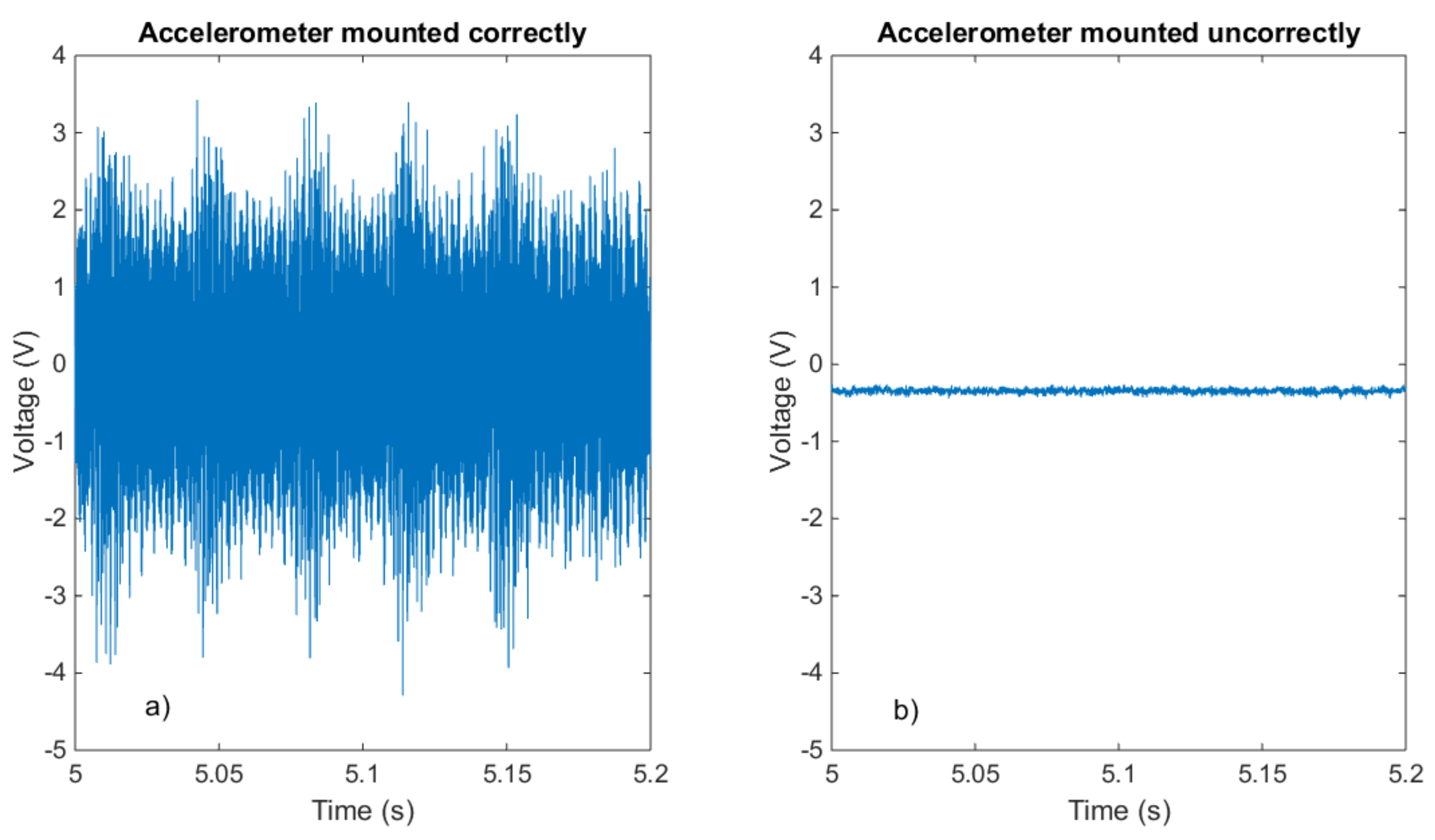
- Checking of the sensors; The measurement files are checked for inconsistency of data. Especially in manufacturing machines, processes are repeated cyclically and the expected data from sensors must contain cyclic components too (e.g., at the productivity frequency of the machine). If the data recorded by a given sensor does not show cyclic components in the spectrum, it is due to a problem on the measurement chain: the sensor, the cable, or the acquisition system. The inconsistency of the data must generate an alarm to the service engineer that will schedule a check of the sensor.
- Calculation of statistics; The computational capacity of the modern industrial personal computers allows statistical analysis on the acquired data, such as the root mean square (RMS) value, variance, kurtosis, quartiles, etc. The main advantage is data reduction; each statistic is a single scalar value compared to the thousands of points acquired by each sensor. Statistics are the features that the data-driven diagnostic method uses to make the post-processing analysis.
- Selection of specific data; If the post-processing based on data-driven analysis reports an incipient fault, a more detailed model-based analysis is performed. The performance management center can ask the local unit for specific data useful for a targeted analysis. The local unit sends those specific raw data to the cloud.
- Storage of data; The data is locally stored for a limited period of time with a backup policy (when the storage space ends the new file overwrites the oldest one). The storage is needed to provide selected raw data if asked.
- Sending of the data to the cloud; All relevant data, i.e., the statistics and the off-line data, is sent to the cloud for the post-processing step.
2.3. Data Cloud Processing
- Data-driven analysis; Statistics data from every monitored subsystem of the machine are analyzed by means of data-driven machine learning techniques, such as neural-networks, support vector machines, and clustering. The machine learning system generates alarms to the performance management center, i.e., the data-scientists, who can query the local system for a more detailed analysis on specific data.
- Data transfer; The off-line data does not need further processing. In this case, the cloud acts as a simple storage device; the analysts pick up the off-line data collected from different machines for the off-line development of condition-monitoring techniques.
2.4. Data Post-Processing
- Reporting; The condition-monitoring outputs are divided into several reports on the state of the sub-system components. The stakeholders of condition-monitoring reports are varied: service engineers, managers, consultants, and external service providers etc., and each of them needs different pieces of information.
- Decision support; The reports are used by the performance management center, i.e., a structured support service, in order to update historical data for modeling upgrade development, analyze criticality, query advance failure analysis of specific components, and manage the technical service.
- Model-based analysis; Once an alarm is received by the cloud-processing, more advanced signal processing tools can be used to assess more details on the fault, for example, if there is a fault in the inner or outer ring of a bearing.
- Service; If some problems are identified, a report of the situation is sent to the service engineers through a IoT device. In this way the service engineers can monitor the state of the plant at any time and in case of alarm they are warned promptly. Thanks to the analysis service, the service engineers are not only warned about an incipient failure but they are also informed about the procedure necessary for the maintenance, whether it is necessary to order the broken part, and whether it is available in the warehouse.
3. Condition-Monitoring Algorithms
- Data cleaning; This includes all the procedures activated to remove inconsistent data, for example, empty measurement files, corrupted files, disconnected sensors, and broken cables, etc. This is not a proper condition-monitoring technique but it is a preparation process.
- Fault detection; This includes all the procedures suitable to recognize a fault in the system. It does not usually return the specific causes of the fault, only its presence. In most cases, anomaly detection techniques are sufficient for industrial purposes. If there is a faulty bearing in an electric motor, the motor must be completely replaced regardless of whether the fault is in the outer ring rather than in the inner one.
- Fault diagnostics; This includes all the procedures suitable to characterize the fault of a specific component and the level of the damage of the component. It is also the starting point for the estimation of the residual life of the component (prognostics) [29]. Fault diagnostics techniques are useful for redesigning a component: the detailed knowledge of the fault can suggest a better design to reduce the loads in working conditions, extending the expected life of the component.
- Data-driven techniques; For the purposes of this paper, data-driven techniques are only used for fault detection.
- Model-based techniques; For the purposes of this paper, model-based techniques are used only for fault diagnostics.
3.1. Data-Driven Techniques
- Artificial neural networks (ANNs); This technique tries to mimic the biological neural networks and the way in which the pieces information are managed by the human brain. It builds a weight matrix trying to reward or penalize input features based on the error output in the training step. One or more layers, i.e., weighting matrices, can be chosen. The key component of the ANN is the backpropagation algorithm that distributes the error term back up through the layers by modifying the weights at each node. The ANN technique has been used in several research fields [36,37,38,39,40,41].
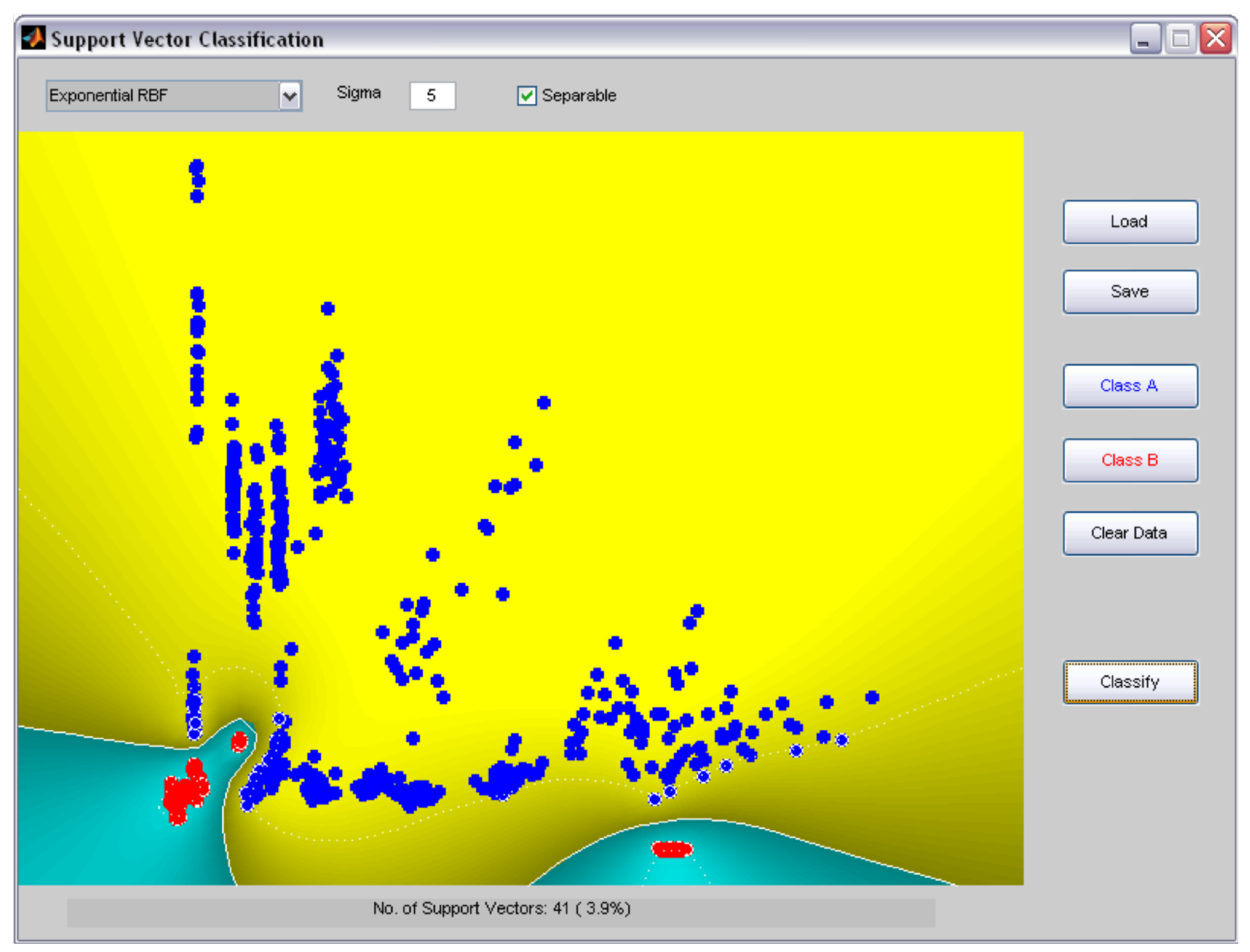
- Support vector machines (SVMs); The SVM technique [42] computes a hyperplane that divides faulty and healthy data by maximizing the distance of the hyperplane to the datasets. The dimension of the hyperplane depends on the dimension of the input data features. The key component of the SVM is the choice of kernel function, the purpose of which is to project data in a high-dimensional space where the data can be separated by the hyperplane. Once defined, the hyperplane acts as a threshold, classifying new input data into the two classes . Examples of the application of SVMs to condition monitoring can be found in [23,43,44,45,46,47].
- Autoassociative kernel regression (AAKR); This technique predicts the health status of a component thanks to the historical data deriving from a healthy dataset. New inputs are compared to the prediction of the healthy state. The difference between the two signals, i.e., the residual, is used as a metric to assess the health status of the component. Examples of AAKR applications to condition monitoring can be found in [48,49,50,51,52].
- RMS; This is defined as the square root of mean square;
- Variance; This is the second central moment of a real-valued random variable;
- Skewness; This is the third central moment of a real-valued random variable;
- Kurtosis; This is the fourth central moment of a real-valued random variable;
- Quartiles; These are the 25th, 50th and 75th percentiles of the input variable.
3.2. Model-Based Techniques
- White-box model; This is a model based on first principles, e.g., the Newton–Lagrange equations. It requires a deep knowledge of the system: the geometry, external loads and torques, characteristics of the materials, the type of interactions among components (e.g., friction, or impacts), masses, etc. In many cases such models will be overly complex due to the complex nature of many systems and processes. It must be noted that the development of a white-box model is not a one-shot activity but it must be continuously developed, adding more details if necessary. Examples of white-box modeling can be found in [54,55,56,57,58].
- Black-box model; No a priori model is available. The input/output relation of the system is statistically computed not considering the physics of the process at all. Most system identification algorithms focus on this type. The black-box model is similar to data-driven approaches, which are not further considered in this paper.
- Gray-box model; This model is in between the white-box and the black-box models. Although the peculiarities of what is going on inside the system are not entirely known, a certain model based on both insight into the system and experimental data is constructed [59]. The resulting model still has a number of unknown free parameters which can be estimated using system identification. An example of a gray-box is the modeling of the expected signal produced by a faulty system (i.e., the output signal of the system). In this particular case the gray-box model has been studied in depth in the literature (e.g., a ball-bearing) and it is used to simulate the expected output signal in different working conditions. The condition-monitoring analyst can use the simulated signal to develop and validate signal processing techniques. Examples of fault modeling can be found in [60,61,62,63,64,65,66,67].
4. Results
4.1. Data Acquisition
4.2. Data Pre-Processing
4.3. Data Cloud Processing
- Root mean square (RMS); This returns a measure of the mechanical and environmental noise affecting the sensor in healthy conditions. A high level of RMS may not be necessarily related to a fault, but it could be the consequence of environmental conditions. The evolution of the RMS, rather than its absolute value, is an important indicator for condition monitoring;
- Loosening of a belt; For this type of failure mode, the system is able to detect a variation in the working conditions of the machine. This generally will end with nonstandard wear of the component due to the changing of the working conditions and a failure of the applications. The time between the detection and the functional failure can be weeks, depending on the application itself and the working conditions;
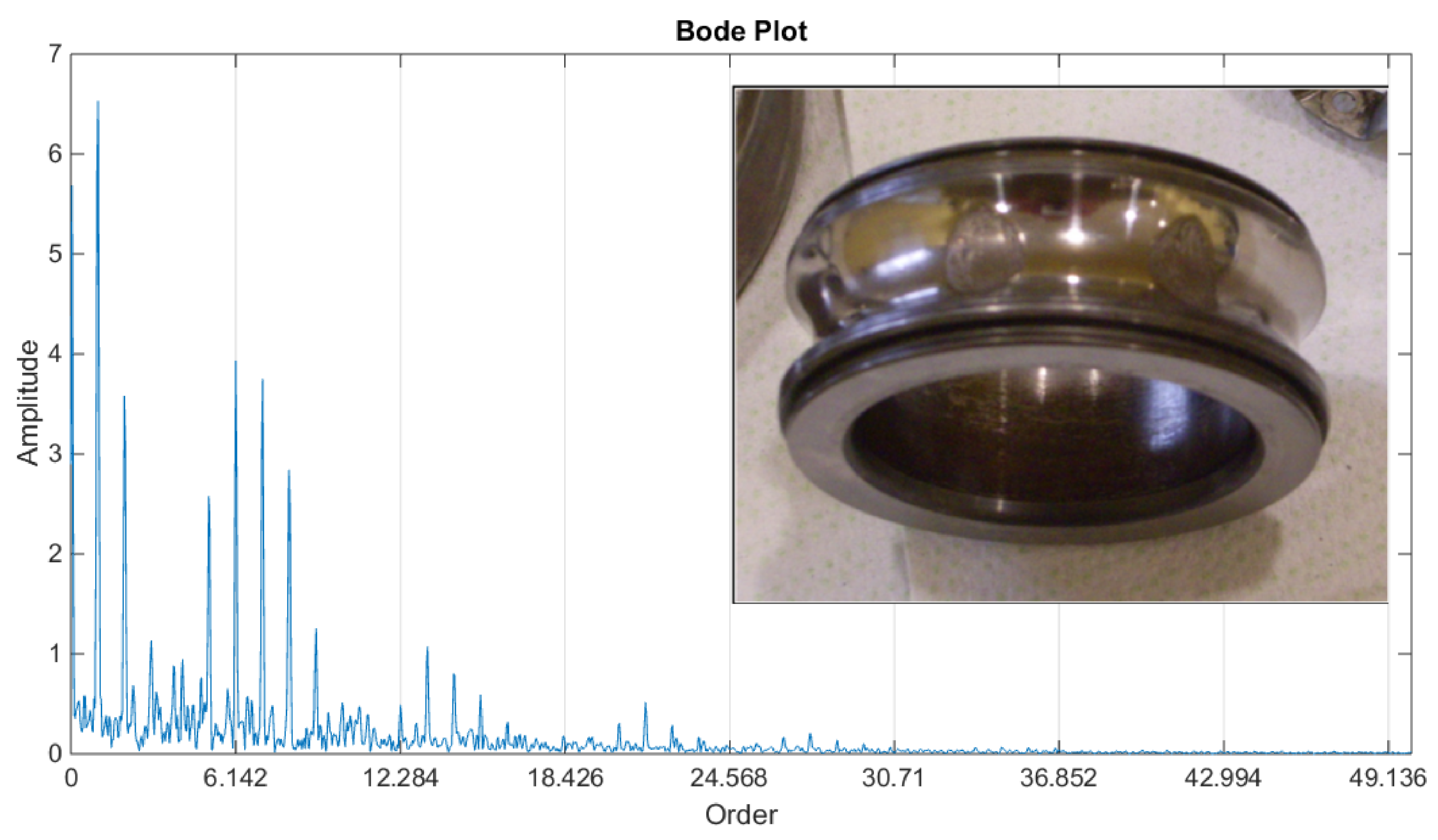
- Faulty ball bearing; This is strictly dependent on the application, motion profiles, and load condition of the bearing, but it is generally detected several weeks before catastrophic failure. This is sufficiently early to schedule the replacement intervention and avoid the unplanned stoppage of the machine;
- Poor lubrication; This depends on environmental conditions (e.g., humidity and temperature). In the case of complete missing lubrication, the degradation of mechanical components is much faster than a general wear and detection is less effective. Detection is done as soon as the point of interest is deviated from the standard working conditions and in general this is sufficient to prevent the damage of the component;
- Wear of surfaces; This is strictly dependent on the application, the motion profiles, the load condition, and environmental conditions. In particular, the monitoring system detected the loosening between a bearing and its seat. The mean time between the detection and failure is quantifiable as two months, but statistical evidence is still missing.
- Loosening of an elastic coupling; The detection depends greatly on all the kinematic chain and stress conditions of the component. The mean time between the detection and failure is quantifiable as a few days but statistical evidence is still missing.
4.4. Data Post-Processing
5. Conclusions
- Data-acquisition setup, i.e., the hardware infrastructure;
- Data pre-processing, responsible for data cleaning and quick alarm monitoring;
- Data cloud processing, responsible for data-driven analysis and high-level condition monitoring;
- Data post-processing, responsible for model-based analysis and decision support to the maintenance policy.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lee, J.; Bagheri, B.; Kao, H.A. A Cyber-Physical Systems architecture for Industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]
- Peng, Y.; Dong, M.; Zuo, M. Current status of machine prognostics in condition-based maintenance: A review. Int. J. Adv. Manuf. Technol. 2010, 50, 297–313. [Google Scholar] [CrossRef]
- Durocher, D.; Feldmeier, G. Predictive versus preventive maintenance. IEEE Ind. Appl. Mag. 2004, 10, 12–21. [Google Scholar] [CrossRef]
- Goyal, D.; Pabla, B. Condition based maintenance of machine tools-A review. CIRP J. Manuf. Sci. Technol. 2015, 10, 24–35. [Google Scholar] [CrossRef]
- Hassan, A.; Gani, A.; Ab Aziz, S. An overview on condition based monitoring by vibration analysis. Def. S T Tech. Bull. 2009, 2, 42–46. [Google Scholar]
- Fleischmann, H.; Kohl, J.; Franke, J. A Modular Architecture for the Design of Condition Monitoring Processes. Procedia CIRP 2016, 57, 410–415. [Google Scholar] [CrossRef]
- Morosini Frazzona, E.; Hartmann, J.; Makuschewitz, T.; Scholz-Reiter, B. Towards Socio-Cyber-Physical Systems in Production Networks. Procedia CIRP 2013, 7, 49–54. [Google Scholar] [CrossRef]
- Smirnov, A.; Sandkuhl, K. Context-Oriented Knowledge Management for Decision Support in Business Socio-Cyber-Physical Networks: Conceptual and Methodical Foundations. In Proceedings of the 20th Conference of Open Innovations Association FRUCT, Saint-Petersburg, Russia, 3–7 April 2017. [Google Scholar]
- Diez-Olivan, A.; Pagan, J.; Sanz, R.; Sierra, B. Data-driven prognostics using a combination of constrained K-means clustering, fuzzy modeling and LOF-based score. Neurocomputing 2017, 241, 97–107. [Google Scholar] [CrossRef]
- Zhang, X.; Kang, J.; Jin, T. Degradation modeling and maintenance decisions based on bayesian belief networks. IEEE Trans. Reliab. 2014, 63, 620–633. [Google Scholar] [CrossRef]
- Boškoski, P.; Gašperin, M.; Petelin, D.; Juričić, D. Bearing fault prognostics using Rényi entropy based features and Gaussian process models. Mech. Syst. Signal Process. 2015, 52–53, 327–337. [Google Scholar] [CrossRef]
- Youree, R.; Yalowitz, J.; Corder, A.; Ooi, T. A multivariate statistical analysis technique for on-line fault prediction. In Proceedings of the International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar] [CrossRef]
- Kruger, M.; Ding, S.; Haghani, A.; Engel, P.; Jeinsch, T. A data-driven approach for sensor fault diagnosis in gearbox of wind energy conversion system. In Proceedings of the 2013 10th IEEE International Conference on Control and Automation (ICCA), Hangzhou, China, 12–14 June 2013; pp. 227–232. [Google Scholar] [CrossRef]
- Langone, R.; Alzate, C.; Ketelaere, B.D.; Vlasselaer, J.; Meert, W.; Suykens, J.A. LS-SVM based spectral clustering and regression for predicting maintenance of industrial machines. Eng. Appl. Artif. Intell. 2015, 37, 268–278. [Google Scholar] [CrossRef]
- Yan, J.; Lee, J. A hybrid method for on-line performance assessment and life prediction in drilling operations. In Proceedings of the 2007 IEEE International Conference on Automation and Logistics, Jinan, China, 18–21 August 2007; pp. 2500–2505. [Google Scholar] [CrossRef]
- Alpay, B.; Garcia, H.; Yoo, T.S. A Hybrid Model Combining First-Principles and Data-Driven Models for On-Line Condition Monitoring; American Nuclear Society: La Grange Park, IL, USA, 2006; Volume 2006, pp. 822–827. [Google Scholar]
- Park, S.; Kim, Y.; Won, J. Application of IoT for the maintaining rolling stocks. Qual. Innov. Prosper. 2017, 21, 71–83. [Google Scholar] [CrossRef]
- Birolini, A. Reliability Engineering, 8th ed.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- O’Connor, P.; Kleyner, A. Practical Reliability Engineering; Wiley & Sons: Hoboken, NY, USA, 2012. [Google Scholar]
- Heng, A.; Zhang, S.; Tan, A.C.C.; Mathew, J. Rotating machinery prognostics: State of the art, challenges and opportunities. Mech. Syst. Signal Process. 2009, 23, 724–739. [Google Scholar] [CrossRef]
- Hameed, Z.; Hong, Y.S.; Cho, Y.; Ahn, S.; Song, C. Condition monitoring and fault detection of wind turbines and related algorithms: A review. Renew. Sustain. Energy Rev. 2009, 13, 1–39. [Google Scholar] [CrossRef]
- Carden, E.P.; Fanning, P. Vibration based condition monitoring: A review. Struct. Health Monit. 2004, 3, 355–377. [Google Scholar] [CrossRef]
- Ruiz-Gonzalez, R.; Gomez-Gil, J.; Gomez-Gil, F.J.; Martínez-Martínez, V. An SVM-Based Classifier for Estimating the State of Various Rotating Components in Agro-Industrial Machinery with a Vibration Signal Acquired from a Single Point on the Machine Chassis. Sensors 2014, 14, 20713–20735. [Google Scholar] [CrossRef] [PubMed]
- Potter, R. A new order tracking method for rotating machinery. Sound Vib. 1990, 24, 30–34. [Google Scholar]
- Fyfe, K.; Munck, E. Analysis of computed order tracking. Mech. Syst. Signal Process. 1997, 11, 187–202. [Google Scholar] [CrossRef]
- Bossley, K.; McKendrick, R.; Harris, C.; Mercer, C. Hybrid computed order tracking. Mech. Syst. Signal Process. 1999, 13, 627–641. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin, Germany, 2009. [Google Scholar]
- Albalate, A.; Minker, W. Semi-Supervised and Unsupervised Machine Learning: Novel Strategies; Iste/Hermes Science Pub.: London, UK, 2010. [Google Scholar]
- Randall, R. Vibration-Based Condition Monitoring: Industrial, Aerospace and Automotive Applications; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar] [CrossRef]
- Shin, H.; Eom, D.H.; Kim, S.S. One-class support vector machines—An application in machine fault detection and classification. Comput. Ind. Eng. 2005, 48, 395–408. [Google Scholar] [CrossRef]
- Dasgupta, D.; Forrest, S. Artificial immune systems in industrial applications. In Proceedings of the Second International Conference on Intelligent Processing and Manufacturing of Materials, Honolulu, HI, USA, 10–15 July 1999; Volume 1, pp. 257–267. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.; Xie, X.; Luo, H. A review on basic data-driven approaches for industrial process monitoring. IEEE Trans. Ind. Electron. 2014, 61, 6414–6428. [Google Scholar] [CrossRef]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Cerrada, M.; Sánchez, R.V.; Li, C.; Pacheco, F.; Cabrera, D.; Valente de Oliveira, J.; Vásquez, R. A review on data-driven fault severity assessment in rolling bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Samanta, B.; Al-Balushi, K. Artificial neural network based fault diagnostics of rolling element bearings using time-domain features. Mech. Syst. Signal Process. 2003, 17, 317–328. [Google Scholar] [CrossRef]
- Paya, B.; Esat, I.; Badi, M. Artificial neural network based fault diagnostics of rotating machinery using wavelet transforms as a preprocessor. Mech. Syst. Signal Process. 1997, 11, 751–765. [Google Scholar] [CrossRef]
- Moosavian, A.; Ahmadi, H.; Tabatabaeefar, A.; Khazaee, M. Comparison of two classifiers; K-nearest neighbor and artificial neural network, for fault diagnosis on a main engine journal-bearing. Shock Vib. 2013, 20, 263–272. [Google Scholar] [CrossRef]
- Li, N.; Mechefske, C. Induction motor fault detection and diagnosis using artificial neural networks. Int. J. COMADEM 2006, 9, 15–23. [Google Scholar]
- Patel, J.; Upadhyay, S. Comparison between Artificial Neural Network and Support Vector Method for a Fault Diagnostics in Rolling Element Bearings. Procedia Eng. 2016, 144, 390–397. [Google Scholar] [CrossRef]
- Cocconcelli, M.; Rubini, R.; Zimroz, R.; Bartelmus, W. Diagnostics of ball bearings in varying-speed motors by means of Artificial Neural Networks. In Proceedings of the Eight International Conference on Condition Monitoring and Machinery Failure Prevention Technologies, Cardiff, UK, 20–22 June 2011; Volume 2, pp. 760–771. [Google Scholar]
- Widodo, A.; Yang, B.S. Support vector machine in machine condition monitoring and fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 2560–2574. [Google Scholar] [CrossRef]
- Cocconcelli, M.; Rubini, R. Support Vector Machines for condition monitoring of bearings in a varying-speed machinery. In Proceedings of the 8th International Conference on Condition Monitoring, Cardiff, UK, 20–22 June 2011. [Google Scholar]
- Sugumaran, V.; Muralidharan, V.; Ramachandran, K. Feature selection using Decision Tree and classification through Proximal Support Vector Machine for fault diagnostics of roller bearing. Mech. Syst. Signal Process. 2007, 21, 930–942. [Google Scholar] [CrossRef]
- Sugumaran, V.; Sabareesh, G.; Ramachandran, K. Fault diagnostics of roller bearing using kernel based neighborhood score multi-class support vector machine. Expert Syst. Appl. 2008, 34, 3090–3098. [Google Scholar] [CrossRef]
- Guo, L.; Chen, J.; Li, X. Rolling bearing fault classification based on envelope spectrum and support vector machine. J. Vib. Control 2009, 15, 1349–1363. [Google Scholar] [CrossRef]
- Jiang, L.L.; Yin, H.K.; Li, X.J.; Tang, S.W. Fault diagnosis of rotating machinery based on multisensor information fusion using SVM and time-domain features. Shock Vib. 2014, 2014. [Google Scholar] [CrossRef]
- Di Maio, F.; Baraldi, P.; Zio, E.; Seraoui, R. Fault detection in nuclear power plants components by a combination of statistical methods. IEEE Trans. Reliab. 2013, 62, 833–845. [Google Scholar] [CrossRef] [Green Version]
- Niu, G.; Zhao, Y.; Defoort, M.; Pecht, M. Fault diagnosis of locomotive electro-pneumatic brake through uncertain bond graph modeling and robust online monitoring. Mech. Syst. Signal Process. 2015, 50–51, 676–691. [Google Scholar] [CrossRef]
- Baraldi, P.; Di Maio, F.; Genini, D.; Zio, E. Comparison of Data-Driven Reconstruction Methods for Fault Detection. IEEE Trans. Reliab. 2015, 64, 852–860. [Google Scholar] [CrossRef]
- Baraldi, P.; Di Maio, F.; Turati, P.; Zio, E. Robust signal reconstruction for condition monitoring of industrial components via a modified Auto Associative Kernel Regression method. Mech. Syst. Signal Process. 2015, 60, 29–44. [Google Scholar] [CrossRef] [Green Version]
- Baraldi, P.; Bonfanti, G.; Zio, E. Differential evolution-based multi-objective optimization for the definition of a health indicator for fault diagnostics and prognostics. Mech. Syst. Signal Process. 2018, 102, 382–400. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Kerst, S.; Shyrokau, B.; Holweg, E. A semi-analytical bearing model considering outer race flexibility for model based bearing load monitoring. Mech. Syst. Signal Process. 2018, 104, 384–397. [Google Scholar] [CrossRef]
- Heikkinen, J.; Ghalamchi, B.; Viitala, R.; Sopanen, J.; Juhanko, J.; Mikkola, A.; Kuosmanen, P. Vibration analysis of paper machine’s asymmetric tube roll supported by spherical roller bearings. Mech. Syst. Signal Process. 2018, 104, 688–704. [Google Scholar] [CrossRef]
- Cao, H.; Niu, L.; Xi, S.; Chen, X. Mechanical model development of rolling bearing-rotor systems: A review. Mech. Syst. Signal Process. 2018, 102, 37–58. [Google Scholar] [CrossRef]
- Xi, S.; Cao, H.; Chen, X.; Niu, L. A Dynamic Modeling Approach for Spindle Bearing System Supported by Both Angular Contact Ball Bearing and Floating Displacement Bearing. J. Manuf. Sci. Eng. Trans. ASME 2018, 140. [Google Scholar] [CrossRef]
- Moshrefzadeh, A.; Fasana, A. Planetary gearbox with localised bearings and gears faults: Simulation and time/frequency analysis. Meccanica 2017, 52, 3759–3779. [Google Scholar] [CrossRef]
- Silva Souza, V.E.; Lapouchnian, A.; Mylopoulos, J. System Identification for Adaptive Software Systems: A Requirements Engineering Perspective. In International Conference on Conceptual Modeling; Jeusfeld, M., Delcambre, L., Ling, T.W., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 346–361. [Google Scholar]
- Shahriar, M.; Borghesani, P.; Tan, A. Electrical Signature Analysis-based Detection of External Bearing Fault in Electromechanical Drivetrains. IEEE Trans. Ind. Electron. 2017. [Google Scholar] [CrossRef]
- Abboud, D.; Elbadaoui, M.; Becquerelle, S.; Lalmi, M. The application of the cyclic coherence for distributed planet fault detection in planetary gears. In Proceedings of the 1st World Congress on Condition Monitoring (WCCM 2017), London, UK, 13–16 June 2017. [Google Scholar]
- Feng, Z.; Ma, H.; Zuo, M. Vibration signal models for fault diagnosis of planet bearings. J. Sound Vib. 2016, 370, 372–393. [Google Scholar] [CrossRef]
- Delvecchio, S.; D’Elia, G.; Dalpiaz, G. On the use of cyclostationary indicators in IC engine quality control by cold tests. Mech. Syst. Signal Process. 2015, 60, 208–228. [Google Scholar] [CrossRef]
- Cong, F.; Chen, J.; Dong, G.; Pecht, M. Vibration model of rolling element bearings in a rotor-bearing system for fault diagnosis. J. Sound Vib. 2013, 332, 2081–2097. [Google Scholar] [CrossRef]
- Tóth, L.; Tóth, T. Construction of a realistic signal model of transients for a ball bearing with inner race fault. Acta Polytech. Hung. 2013, 10, 63–80. [Google Scholar]
- Stack, J.; Habetler, T.; Harley, R. Fault-signature modeling and detection of inner-race bearing faults. IEEE Trans. Ind. Appl. 2006, 42, 61–68. [Google Scholar] [CrossRef]
- Ericsson, S.; Grip, N.; Johansson, E.; Persson, L.E.; Sjöberg, R.; Strömberg, J.O. Towards automatic detection of local bearing defects in rotating machines. Mech. Syst. Signal Process. 2005, 19, 509–535. [Google Scholar] [CrossRef]
- Antoni, J. The spectral kurtosis: A useful tool for characterising non-stationary signals. Mech. Syst. Signal Process. 2006, 20, 282–307. [Google Scholar] [CrossRef]
- Antoni, J.; Randall, R. The Spectral Kurtosis: application to the vibratory surveillance and diagnostics of rotating machines. Mech. Syst. Signal Process. 2006, 20, 308–331. [Google Scholar] [CrossRef]
- Zimroz, R.; Bartelmus, W.; Barszcz, T.; Urbanek, J. Diagnostics of bearings in presence of strong operating conditions non-stationarity—A procedure of load-dependent features processing with application to wind turbine bearings. Mech. Syst. Signal Process. 2014, 46, 16–27. [Google Scholar] [CrossRef]
- Cotogno, M.; Pedrazzi, E.; Cocconcelli, M.; Rubini, R. Non-linear elasto-dynamic model of faulty rolling elements bearing. Mech. Mach. Sci. 2015, 21, 443–454. [Google Scholar] [CrossRef]
- Bartelmus, W.; Chaari, F.; Zimroz, R.; Haddar, M. Modelling of gearbox dynamics under time-varying nonstationary load for distributed fault detection and diagnosis. Eur. J. Mech. A/Solids 2010, 29, 637–646. [Google Scholar] [CrossRef]
- Gryllias, K.; Moschini, S.; Antoni, J. Application of Cyclo-Nonstationary Indicators for Bearing Monitoring under Varying Operating Conditions. J. Eng. Gas Turbines Power 2018, 140. [Google Scholar] [CrossRef]
- D’Elia, G.; Cocconcelli, M.; Mucchi, E. An algorithm for the simulation of faulted bearings in non-stationary conditions. Meccanica 2018, 53, 1147–1166. [Google Scholar] [CrossRef]
- Cocconcelli, M.; Bassi, L.; Secchi, C.; Fantuzzi, C.; Rubini, R. An algorithm to diagnose ball bearing faults in servomotors running arbitrary motion profiles. Mech. Syst. Signal Process. 2012, 27, 667–682. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Sensor | Number of Sensors | Classification |
|---|---|---|
| Accelerometer | 20 | Multi-purpose external sensor |
| Encoder | 18 | Embedded sensor |
| Current sensor | 25 | Embedded sensor |
| Pressure sensor | 2 | Specific external sensor |
| Temperature sensor | 27 | Embedded sensor |
| Position sensor | 2 | Specific external sensor |
| Digital sensor | 49 | Embedded sensor |
| Actual | ||||
|---|---|---|---|---|
| Healthy | Faulty | |||
| (a) | Predicted | Healthy | 864 | 0 |
| Faulty | 0 | 720 | ||
| (b) | Predicted | Healthy | 729 | 0 |
| Faulty | 135 | 720 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cocconcelli, M.; Capelli, L.; Cavalaglio Camargo Molano, J.; Borghi, D. Development of a Methodology for Condition-Based Maintenance in a Large-Scale Application Field. Machines 2018, 6, 17. https://doi.org/10.3390/machines6020017
Cocconcelli M, Capelli L, Cavalaglio Camargo Molano J, Borghi D. Development of a Methodology for Condition-Based Maintenance in a Large-Scale Application Field. Machines. 2018; 6(2):17. https://doi.org/10.3390/machines6020017
Chicago/Turabian StyleCocconcelli, Marco, Luca Capelli, Jacopo Cavalaglio Camargo Molano, and Davide Borghi. 2018. "Development of a Methodology for Condition-Based Maintenance in a Large-Scale Application Field" Machines 6, no. 2: 17. https://doi.org/10.3390/machines6020017
APA StyleCocconcelli, M., Capelli, L., Cavalaglio Camargo Molano, J., & Borghi, D. (2018). Development of a Methodology for Condition-Based Maintenance in a Large-Scale Application Field. Machines, 6(2), 17. https://doi.org/10.3390/machines6020017