Neural Network-Based Learning from Demonstration of an Autonomous Ground Robot


Abstract
:1. Introduction
- Development of a compact robotic platform for real-time implementation of a variety of deep-neural-network-based concepts for data processing and control.
- Implementation and demonstration of a simplified concept of end-to-end imitation learning on a composite architecture of convolutional neural network (ConvNet) and Long Short Term Memory (LSTM) neural network.
2. Background: Neural Network Architecture and Related Work
2.1. Convolutional Neural Networks
2.2. Long Short-Term Memory Networks
2.3. Related Work
- Behavioral Cloning: It simply reduces the learning task to a supervised learning problem, and this technique was initially popularized by its application on helicopter acrobatics [22].
- Policy Learning with Iterative Demonstration: In practice, this sequential prediction problem of behavioral cloning sometimes leads to poor performance, and the DAgger (Dataset Aggregation) [11] algorithm is designed to improve the performance in an online iterative setting by training a stationary deterministic policy.
- Inverse reinforcement learning: The system attempts to learn a reward function given the demonstrations, and then use this reward function under the reinforcement learning framework to learn a policy. This approach was initially used in some simpler cases with given models [23], later extended to game-theoretic Inverse RL [24], maximum entropy Inverse RL [25] and more recently Deep Inverse RL [26] and Generative Adversarial Imitation Learning [27].
3. Platform Description
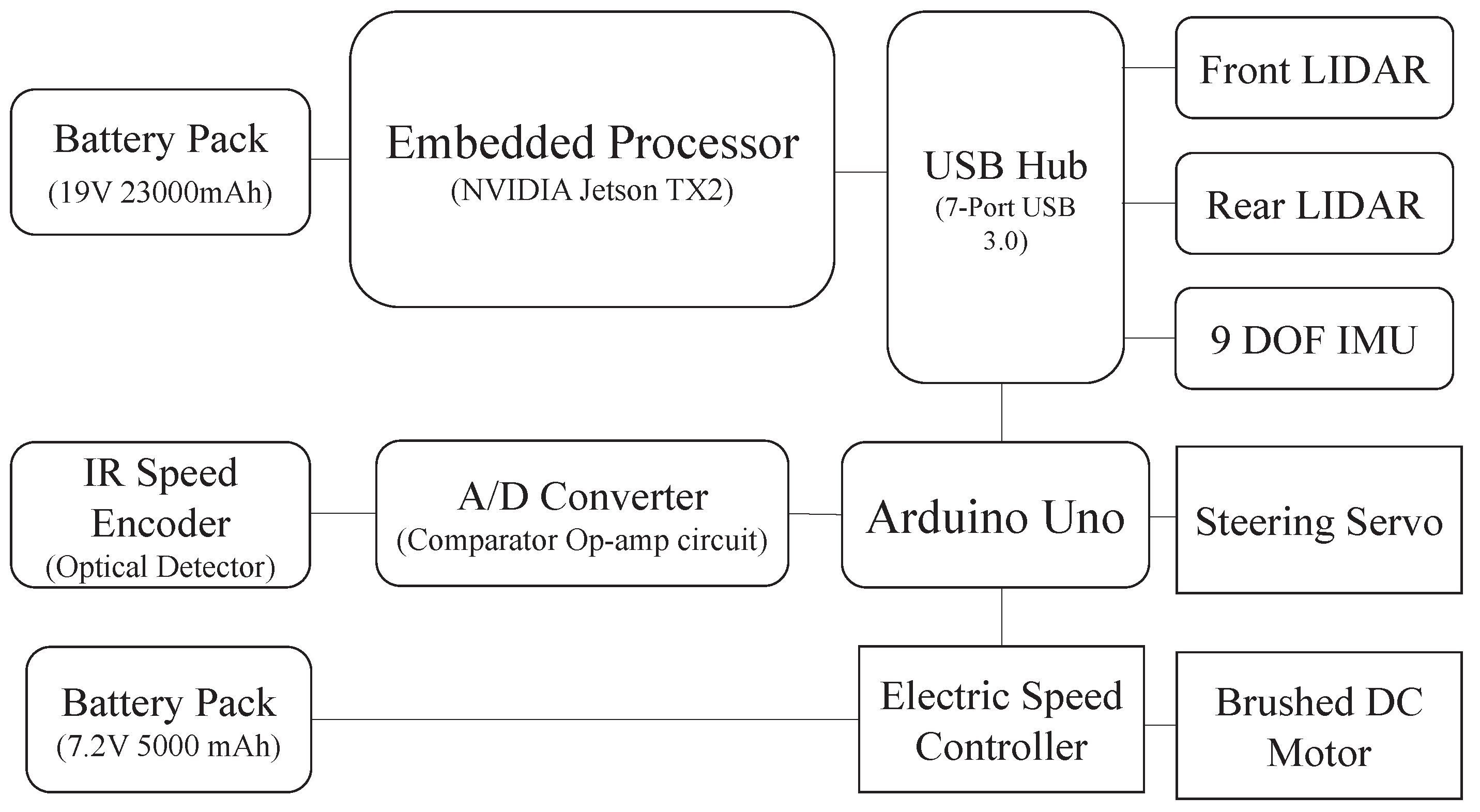
3.1. Hardware Setup
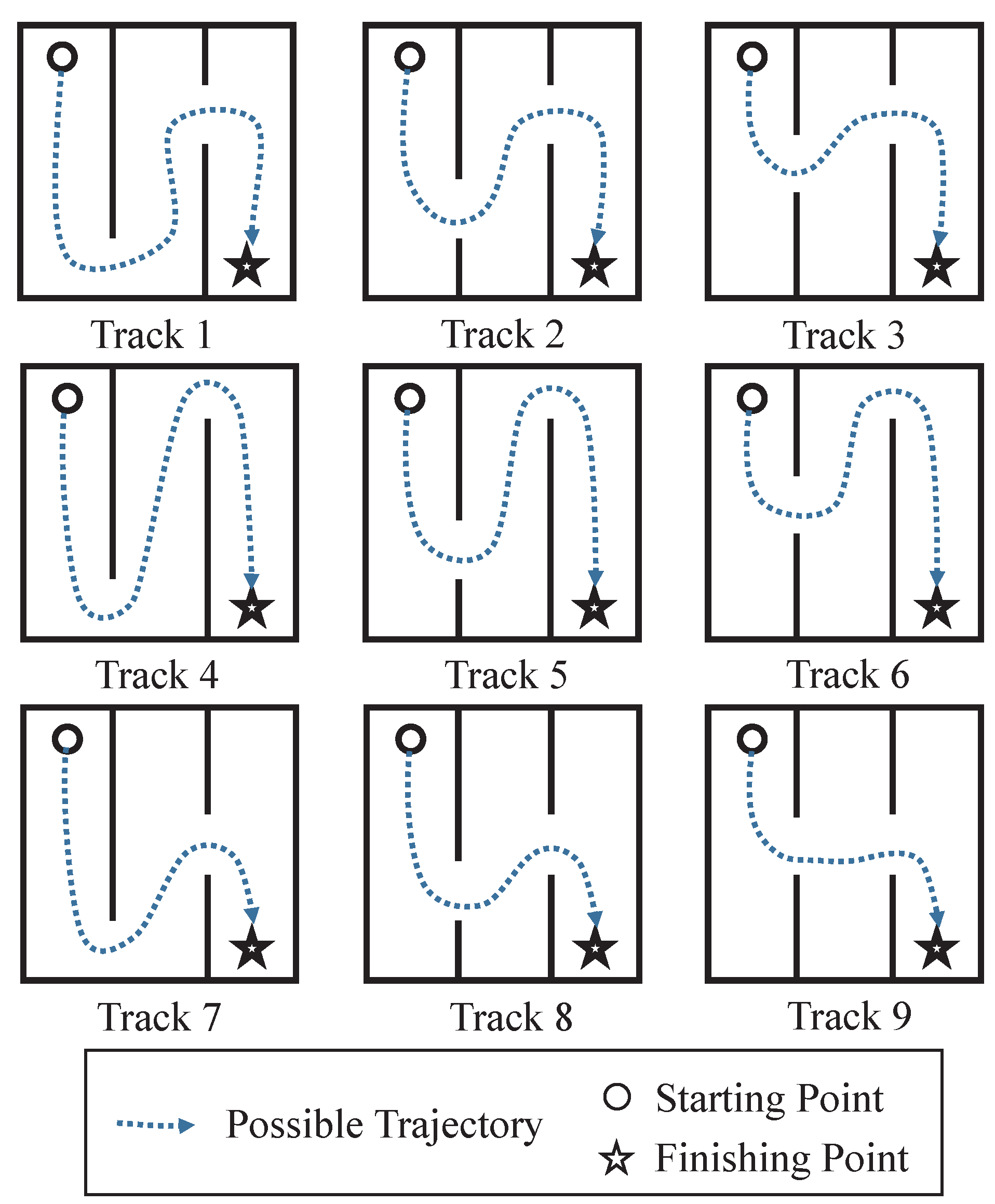
3.2. Description of Data Sets
4. Control Objectives and Proposed Algorithm
4.1. Control Objectives
4.2. Algorithm Development
- ConvNets are proven to be successful in many fields, including robotic imitation learning as described in Section 1. The properties of input sensor data in this application are similar to those of ConvNet; for example, the underlying data are high-dimensional and are arranged with spatial relationships.
- LSTM is capable of handling sequential data. Unlike many ConvNet applications (e.g., image classification) that make the assumption that the data are independent and identically distributed (iid), robotic sensor data are not. Therefore, LSTM takes the role of preserving past information (i.e., having memory), thus making this system more intelligent with enhanced accuracy.
- LSTM alone may not be very good for handling high-dimensional sensor data. To alleviate this difficulty, ConvNet is used here as a feature extraction tool to reduce data dimension as in Figure 4. By taking the layer just before the output layer in ConvNet and feeding it to the LSTM, this architecture takes advantage of the strengths of both ConvNet and LSTM. The procedure is used first to feed the raw data through the ConvNet and then to extract the features and feed them through the LSTM to obtain the output control command; this procedure is implemented on the robot for real-time inferencing and control.
5. Results and Discussion
5.1. Data Preprocessing and Hyperparameter Setting
- The plant dynamic model and measurement model for Kalman filtering are not available.
- The statistical assumptions on the error terms such as independence and Gaussian distribution for ML methods may not be satisfied.
5.2. Implementation
6. Conclusions
- Implementing DAgger algorithm [11] on the current platform to enable interactive and iterative policy learning, and to reduce covariate shift and to make control policies robust.
- Inverse reinforcement learning for generating proper reward functions from observed agent behaviors. This should provide a better metric for evaluating the experimental results.
- Performance enhancement of deep learning-based inference-making in combination with traditional (e.g., model predictive) control techniques.
- Development of data preprocessing techniques for high-dimensional sensor time series with missing data. This machine learning technique is also applicable to problems of missing video data, and an efficient prediction algorithm has good potential for use in related fields.
- Quantitative performance evaluation in statistical settings. An example is quantitative performance evaluation using receiver operating characteristics for a trade-off between probability of successful task completion and probability of false alarms [51]. This will require extensive experimental work to create a large data base.
Author Contributions
Funding
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 2012 Neural Information Processing Systems, Stateline, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv, 2016; arXiv:1604.07316. [Google Scholar]
- Giusti, A.; Guzzi, J.; Cireşan, D.C.; He, F.L.; Rodríguez, J.P.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Di Caro, G.; et al. A machine learning approach to visual perception of forest trails for mobile robots. IEEE Robot. Autom. Lett. 2016, 1, 661–667. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Li, F.-F.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ross, S.; Gordon, G.; Bagnell, D. A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 627–635. [Google Scholar]
- Virani, N.; Jha, D.; Yuan, Z.; Sekhawat, I.; Ray, A. Imitation of Demonstrations using Bayesian Filtering with Nonparametric Data-Driven Models. J. Dyn. Syst. Meas. Control 2018, 140, 030906. [Google Scholar] [CrossRef]
- Argall, B.D.; Chernova, S.; Veloso, M.; Browning, B. A survey of robot learning from demonstration. Robot. Auton. Syst. 2009, 57, 469–483. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.Y.; Coates, A.; Diel, M.; Ganapathi, V.; Schulte, J.; Tse, B.; Berger, E.; Liang, E. Autonomous inverted helicopter flight via reinforcement learning. In Experimental Robotics IX; Springer: Singapore, 2006; pp. 363–372. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
- Rozenberg, G.; Salomaa, A. Handbook of Formal Languages: Beyonds Words; Springer Science & Business Media: Berlin, Germany, 1997; Volume 3. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 18 November 2016).
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Coates, A.; Abbeel, P.; Ng, A.Y. Learning for control from multiple demonstrations. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 144–151. [Google Scholar]
- Abbeel, P.; Ng, A.Y. Apprenticeship learning via inverse reinforcement learning. In Proceedings of the Twenty-First International Conference on Machine Learning, Banff, AB, Canada, 4–8 July 2004; ACM: New York, NY, USA, 2004; p. 1. [Google Scholar] [Green Version]
- Syed, U.; Schapire, R.E. A game-theoretic approach to apprenticeship learning. In Proceedings of the 2008 Neural Information Processing Systems, Vancouver, BC, Canada, 8–13 December 2008; pp. 1449–1456. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum entropy inverse reinforcement learning. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008), Chicago, IL, USA, 13–17 July 2008; Volume 8, pp. 1433–1438. [Google Scholar]
- Finn, C.; Levine, S.; Abbeel, P. Guided cost learning: Deep inverse optimal control via policy optimization. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 49–58. [Google Scholar]
- Ho, J.; Ermon, S. Generative adversarial imitation learning. In Proceedings of the 2006 Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4565–4573. [Google Scholar]
- Taylor, S.; Kim, T.; Yue, Y.; Mahler, M.; Krahe, J.; Rodriguez, A.G.; Hodgins, J.; Matthews, I. A deep learning approach for generalized speech animation. ACM Trans. Graph. (TOG) 2017, 36, 93. [Google Scholar] [CrossRef]
- Chang, K.W.; Krishnamurthy, A.; Agarwal, A.; Daume, H., III; Langford, J. Learning to search better than your teacher. arXiv, 2015; arXiv:1710.03804v3. [Google Scholar]
- Ross, S.; Zhou, J.; Yue, Y.; Dey, D.; Bagnell, J.A. Learning policies for contextual submodular prediction. arXiv, 2013; arXiv:1305.2532. [Google Scholar]
- Zhang, J.; Cho, K. Query-efficient imitation learning for end-to-end simulated driving. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Le, H.M.; Kang, A.; Yue, Y.; Carr, P. Smooth imitation learning for online sequence prediction. arXiv, 2016; arXiv:1606.00968. [Google Scholar]
- Duan, Y.; Andrychowicz, M.; Stadie, B.; Ho, O.J.; Schneider, J.; Sutskever, I.; Abbeel, P.; Zaremba, W. One-shot imitation learning. In Proceedings of the 2017 Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1087–1098. [Google Scholar]
- Finn, C.; Yu, T.; Zhang, T.; Abbeel, P.; Levine, S. One-shot visual imitation learning via meta-learning. arXiv, 2017; arXiv:1709.04905. [Google Scholar]
- Le, H.M.; Yue, Y.; Carr, P.; Lucey, P. Coordinated multi-agent imitation learning. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, Sydney, NSW, Australia, 6–11 August 2017; Microtome Publishing: Brookline, MA, USA, 2017; pp. 1995–2003. [Google Scholar]
- Zhan, E.; Zheng, S.; Yue, Y.; Sha, L.; Lucey, P. Generative multi-agent behavioral cloning. arXiv, 2018; arXiv:1803.07612. [Google Scholar]
- Li, Y.; Song, J.; Ermon, S. Infogail: Interpretable imitation learning from visual demonstrations. In Proceedings of the 2017 Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3812–3822. [Google Scholar]
- Le, H.M.; Jiang, N.; Agarwal, A.; Dudík, M.; Yue, Y.; Daumé, H., III. Hierarchical imitation and reinforcement learning. arXiv, 2018; arXiv:1803.00590. [Google Scholar]
- Chi, L.; Mu, Y. Deep steering: Learning end-to-end driving model from spatial and temporal visual cues. arXiv, 2017; arXiv:1708.03798. [Google Scholar]
- Eraqi, H.M.; Moustafa, M.N.; Honer, J. End-to-end deep learning for steering autonomous vehicles considering temporal dependencies. arXiv, 2017; arXiv:1710.03804. [Google Scholar]
- Pan, Y.; Cheng, C.A.; Saigol, K.; Lee, K.; Yan, X.; Theodorou, E.; Boots, B. Agile autonomous driving using end-to-end deep imitation learning. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 8–11 June 2018. [Google Scholar]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv, 2015; arXiv:1511.06448. [Google Scholar]
- Wang, J.; Yu, L.C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 2, pp. 225–230. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA 2009 Workshop on Open Source Software, Kobe, Japan, 17 May 2009; Volume 3, p. 5. [Google Scholar]
- Anava, O.; Hazan, E.; Zeevi, A. Online time series prediction with missing data. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2191–2199. [Google Scholar]
- Hauser, M.; Fu, Y.; Phoha, S.; Ray, A. Neural Probabilistic Forecasting of Symbolic Sequences with Long Short-Term Memory. J. Dyn. Syst. Meas. Control 2018, 140, 084502. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Bishop, C. Pattern Analysis and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 1. [Google Scholar]
- Poor, H. An Introduction to Signal Detection and Estimation; Springer: New York, NY, USA, 1988. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Training Set | Test Set | ||
|---|---|---|---|---|
| Accuracy | RMSE | Accuracy | RMSE | |
| Proposed Method | 82.44% | 0.7290 | 71.90% | 1.2538 |
| ConvNet Only | 82.13% | 0.8213 | 56.85% | 1.9686 |
| LSTM Only | 65.06% | 1.6753 | 49.64% | 2.7885 |
| KNN | 81.42% | 0.9470 | 59.62% | 1.7454 |
| SVM | 69.29% | 1.3648 | 63.69% | 1.9417 |
| Decision Tree | 61.26% | 1.8906 | 58.20% | 1.7970 |
| AdaBoost | 69.50% | 1.4305 | 58.70% | 2.1268 |
| Gaussian Process | 91.90% | 0.4472 | 66.33% | 1.6396 |
| Metrics | Training Set | Test Set | ||
|---|---|---|---|---|
| Accuracy | RMSE | Accuracy | RMSE | |
| Proposed Method | 81.21% | 0.5628 | 71.09% | 0.8626 |
| ConvNet Only | 82.81% | 0.4627 | 68.81% | 1.1724 |
| LSTM Only | 61.60% | 1.8553 | 62.70% | 1.7786 |
| KNN | 81.39% | 0.9852 | 67.01% | 1.3037 |
| SVM | 69.31% | 1.3589 | 66.15% | 1.4095 |
| Decision Tree | 63.80% | 1.7226 | 61.44% | 1.7557 |
| AdaBoost | 69.53% | 1.4070 | 62.60% | 1.6112 |
| Gaussian Process | 90.20% | 0.5089 | 64.31% | 1.7685 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Y.; Jha, D.K.; Zhang, Z.; Yuan, Z.; Ray, A. Neural Network-Based Learning from Demonstration of an Autonomous Ground Robot. Machines 2019, 7, 24. https://doi.org/10.3390/machines7020024
Fu Y, Jha DK, Zhang Z, Yuan Z, Ray A. Neural Network-Based Learning from Demonstration of an Autonomous Ground Robot. Machines. 2019; 7(2):24. https://doi.org/10.3390/machines7020024
Chicago/Turabian StyleFu, Yiwei, Devesh K. Jha, Zeyu Zhang, Zhenyuan Yuan, and Asok Ray. 2019. "Neural Network-Based Learning from Demonstration of an Autonomous Ground Robot" Machines 7, no. 2: 24. https://doi.org/10.3390/machines7020024
APA StyleFu, Y., Jha, D. K., Zhang, Z., Yuan, Z., & Ray, A. (2019). Neural Network-Based Learning from Demonstration of an Autonomous Ground Robot. Machines, 7(2), 24. https://doi.org/10.3390/machines7020024