
Optimized Identification of High-Grade Prostate Cancer by Combining Different PSA Molecular Forms and PSA Density in a Deep Learning Model


 ,
, 
 and
and 
Abstract
:1. Introduction
2. Methods
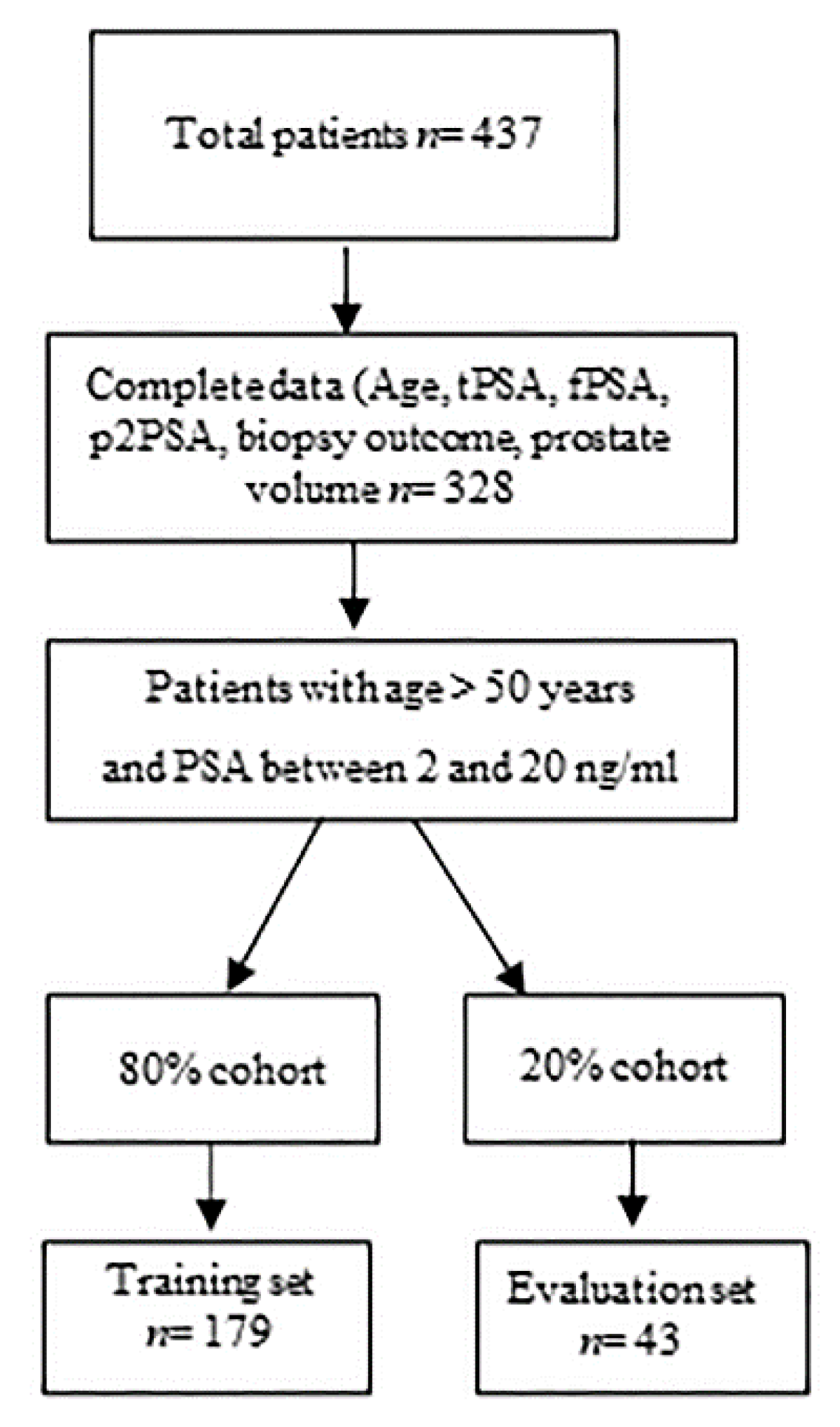
2.1. Study Population
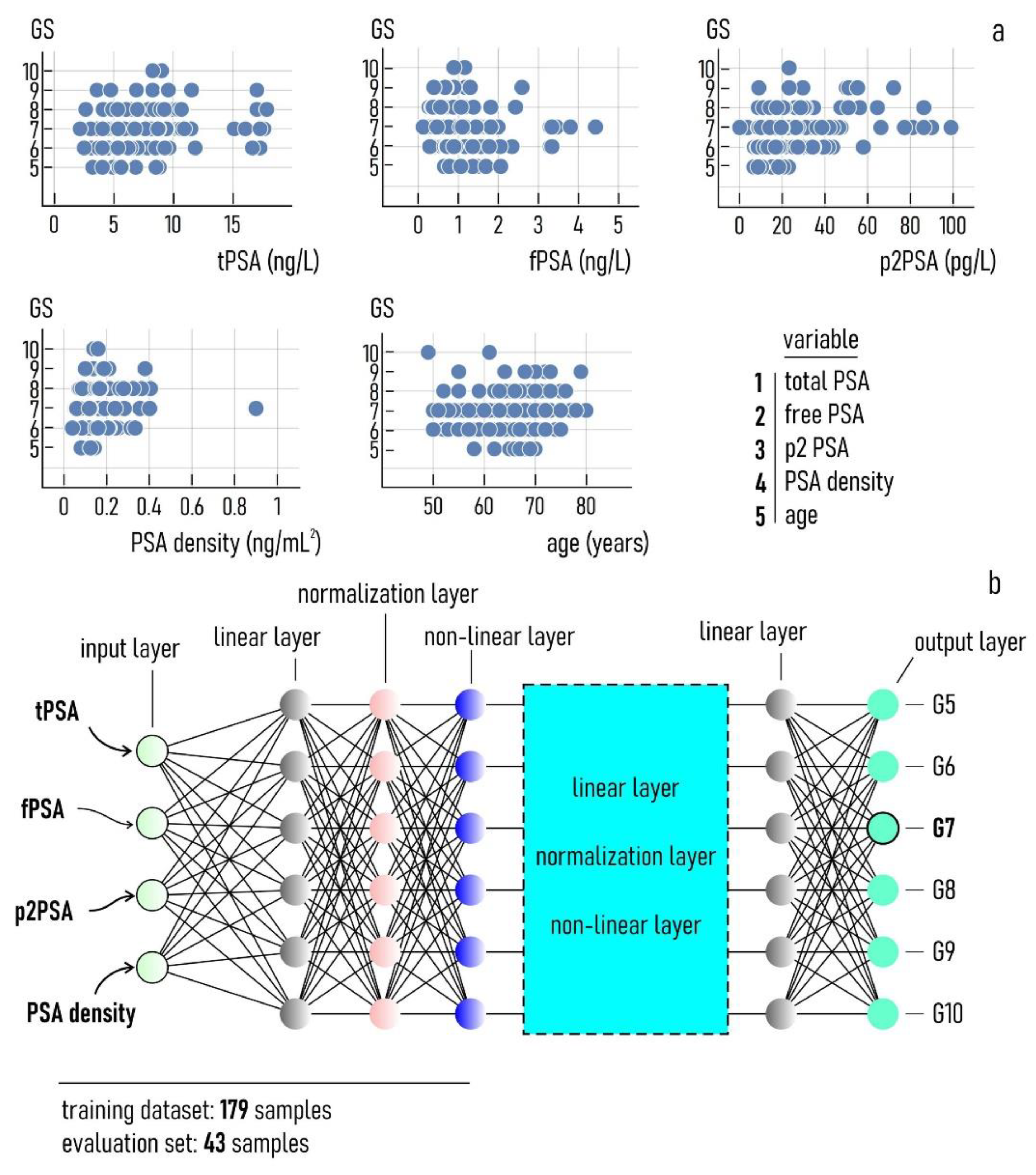
2.2. Biomarker Measurement
2.3. The Deep Learning Model
3. Results
3.1. The Deep Learning Model
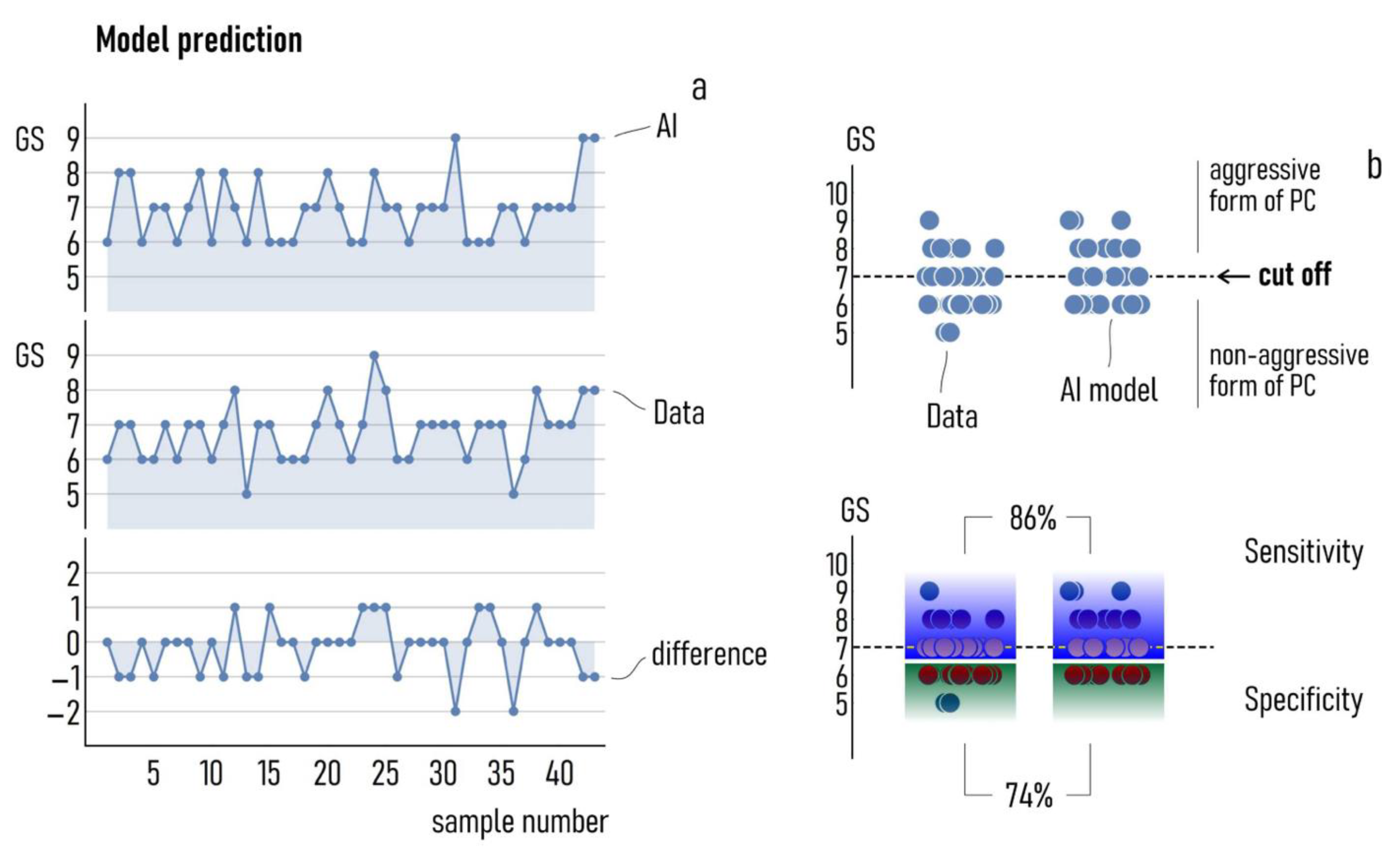
3.2. Best-Case Performance of the Model
3.3. Simulations Predict Patterns of Variables Associated with Aggressive Forms of PC
3.4. Optimizing Performance: Varying Inputs to the Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 1–41. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Fuchs, H.E.; Jemal, A. Cancer Statistics, 2021. CA Cancer J. Clin. 2021, 71, 7–33. [Google Scholar] [CrossRef] [PubMed]
- Barry, M.J. Prostate-Specific–Antigen Testing for Early Diagnosis of Prostate Cancer. N. Engl. J. Med. 2001, 344, 1373–1377. [Google Scholar] [CrossRef]
- Lilja, H.; Ulmert, D.; Vickers, A.J. Prostate-specific antigen and prostate cancer: Prediction, detection and monitoring. Nat. Rev. Cancer 2008, 8, 268–278. [Google Scholar] [CrossRef]
- Mottet, N.; van den Bergh, R.C.N.; Briers, E.; Van den Broeck, T.; Cumberbatch, M.G.; De Santis, M.; Fanti, S.; Fossati, N.; Gandaglia, G.; Gillessen, S.; et al. EAU-EANM-ESTRO-ESUR-SIOG Guidelines on Prostate Cancer-2020 Update. Part 1: Screening, Diagnosis, and Local Treatment with Curative Intent. Eur. Urol. 2020. [Google Scholar] [CrossRef]
- Dall’Era, M.A.; Albertsen, P.C.; Bangma, C.; Carroll, P.R.; Carter, H.B.; Cooperberg, M.R.; Freedland, S.J.; Klotz, L.H.; Parker, C.; Soloway, M.S. Active surveillance for prostate cancer: A systematic review of the literature. Eur. Urol. 2012, 62, 976–983. [Google Scholar] [CrossRef] [Green Version]
- Tokudome, S.; Ando, R.; Koda, Y. Discoveries and application of prostate-specific antigen, and some proposals to optimize prostate cancer screening. Cancer Manag. Res. 2016, 8, 45–47. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cantiello, F.; Russo, G.I.; Ferro, M.; Cicione, A.; Cimino, S.; Favilla, V.; Perdonà, S.; Bottero, D.; Terracciano, D.; De Cobelli, O.; et al. Prognostic accuracy of Prostate Health Index and urinary Prostate Cancer Antigen 3 in predicting pathologic features after radical prostatectomy. Urol. Oncol. 2015, 33, 15–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dayyani, F.; Zurita, A.J.; Nogueras-González, G.M.; Slack, R.; Millikan, R.E.; Araujo, J.C.; Gallick, G.E.; Logothetis, C.J.; Corn, P.G. The combination of serum insulin, osteopontin, and hepatocyte growth factor predicts time to castration-resistant progression in androgen dependent metastatic prostate cancer- an exploratory study. BMC Cancer 2016, 16, 721. [Google Scholar] [CrossRef] [Green Version]
- Ferro, M.; Bruzzese, D.; Perdonà, S.; Marino, A.; Mazzarella, C.; Perruolo, G.; D’Esposito, V.; Cosimato, V.; Buonerba, C.; Di Lorenzo, G.; et al. Prostate Health Index (Phi) and Prostate Cancer Antigen 3 (PCA3) significantly improve prostate cancer detection at initial biopsy in a total PSA range of 2–10 ng/mL. PLoS ONE 2013, 8, e67687. [Google Scholar] [CrossRef]
- Ferro, M.; Bruzzese, D.; Perdonà, S.; Mazzarella, C.; Marino, A.; Sorrentino, A.; Di Carlo, A.; Autorino, R.; Di Lorenzo, G.; Buonerba, C.; et al. Predicting prostate biopsy outcome: Prostate health index (phi) and prostate cancer antigen 3 (PCA3) are useful biomarkers. Clin. Chim. Acta 2012, 413, 1274–1278. [Google Scholar] [CrossRef]
- Ferro, M.; Lucarelli, G.; Bruzzese, D.; Di Lorenzo, G.; Perdonà, S.; Autorino, R.; Cantiello, F.; La Rocca, R.; Busetto, G.M.; Cimmino, A.; et al. Low serum total testosterone level as a predictor of upstaging and upgrading in low-risk prostate cancer patients meeting the inclusion criteria for active surveillance. Oncotarget 2017, 8, 18424–18434. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferro, M.; Lucarelli, G.; Bruzzese, D.; Perdonà, S.; Mazzarella, C.; Perruolo, G.; Marino, A.; Cosimato, V.; Giorgio, E.; Tagliamonte, V.; et al. Improving the prediction of pathologic outcomes in patients undergoing radical prostatectomy: The value of prostate cancer antigen 3 (PCA3), prostate health index (phi) and sarcosine. Anticancer Res. 2015, 35, 1017–1023. [Google Scholar]
- Gong, D.; Wang, Y.; Wang, Y.; Chen, X.; Chen, S.; Wang, R.; Liu, L.; Duan, C.; Luo, S. Extensive serum cytokine analysis in patients with prostate cancer. Cytokine 2020, 125, 154810. [Google Scholar] [CrossRef] [PubMed]
- Perdonà, S.; Bruzzese, D.; Ferro, M.; Autorino, R.; Marino, A.; Mazzarella, C.; Perruolo, G.; Longo, M.; Spinelli, R.; Di Lorenzo, G.; et al. Prostate Health Index (phi) and Prostate Cancer Antigen 3 (PCA3) Significantly Improve Diagnostic Accuracy in Patients Undergoing Prostate Biopsy. Prostate 2013, 73, 227–235. [Google Scholar] [CrossRef]
- Terracciano, D.; Bruzzese, D.; Ferro, M.; Mazzarella, C.; Di Lorenzo, G.; Altieri, V.; Mariano, A.; Macchia, V.; Di Carlo, A. Preoperative insulin-like growth factor-binding protein-3 (IGFBP-3) blood level predicts gleason sum upgrading. Prostate 2012, 72, 100–107. [Google Scholar] [CrossRef]
- Barabási, A.-L. The network takeover. Nat. Phys. 2012, 8, 14–16. [Google Scholar] [CrossRef]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Tuck, M.K.; Chan, D.W.; Chia, D.; Godwin, A.K.; Grizzle, W.E.; Krueger, K.E.; Rom, W.; Sanda, M.; Sorbara, L.; Stass, S.; et al. Standard operating procedures for serum and plasma collection: Early detection research network consensus statement standard operating procedure integration working group. J. Proteome Res. 2009, 8, 113–117. [Google Scholar] [CrossRef] [Green Version]
- Semjonow, A.; Kopke, T.; Eltze, E.; Pepping-Schefers, B.; Burgel, H.; Darte, C. Pre-analytical in-vitro stability of (−2)proPSA in blood and serum. Clin. Biochem. 2010, 43, 926–928. [Google Scholar] [CrossRef] [PubMed]
- Epstein, J.I.; Allsbrook, W.C., Jr.; Amin, M.B.; Egevad, L.L.; Committee, I.G. The 2005 International Society of Urological Pathology (ISUP) Consensus Conference on Gleason Grading of Prostatic Carcinoma. Am. J. Surg. Pathol. 2005, 29, 1228–1242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, G.H.; Nason, G.; Ajib, K.; Woon, D.T.S.; Herrera-Caceres, J.; Alhunaidi, O.; Perlis, N. Smarter screening for prostate cancer. World, J. Urol. 2019, 37, 991–999. [Google Scholar] [CrossRef]
- Osses, D.F.; Roobol, M.J.; Schoots, I.G. Prediction Medicine: Biomarkers, Risk Calculators and Magnetic Resonance Imaging as Risk Stratification Tools in Prostate Cancer Diagnosis. Int. J. Mol. Sci. 2019, 20, 1637. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferro, M.; De Cobelli, O.; Lucarelli, G.; Porreca, A.; Busetto, G.M.; Cantiello, F.; Damiano, R.; Autorino, R.; Musi, G.; Vartolomei, M.D.; et al. Beyond PSA: The Role of Prostate Health Index (phi). Int. J. Mol. Sci. 2020, 21, 1184. [Google Scholar] [CrossRef] [Green Version]
- Trottier, G.; Roobol, M.J.; Lawrentschuk, N.; Bostrom, P.J.; Fernandes, K.A.; Finelli, A.; Chadwick, K.; Evans, A.; van der Kwast, T.H.; Toi, A.; et al. Comparison of risk calculators from the Prostate Cancer Prevention Trial and the European Randomized Study of Screening for Prostate Cancer in a contemporary Canadian cohort. Bju. Int. 2011, 108, E237–E244. [Google Scholar] [CrossRef] [PubMed]
- Wilt, T.J.; Brawer, M.K.; Jones, K.M.; Barry, M.J.; Aronson, W.J.; Fox, S.; Gingrich, J.R.; Wei, J.T.; Gilhooly, P.; Grob, B.M.; et al. Radical prostatectomy versus observation for localized prostate cancer. N. Engl. J. Med. 2012, 367, 203–213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Heidegger, I.; Klocker, H.; Pichler, R.; Pircher, A.; Prokop, W.; Steiner, E.; Ladurner, C.; Comploj, E.; Lunacek, A.; Djordjevic, D.; et al. ProPSA and the Prostate Health Index as predictive markers for aggressiveness in low-risk prostate cancer-results from an international multicenter study. Prostate Cancer Prostatic. Dis. 2017, 20, 271–275. [Google Scholar] [CrossRef]
- Benson, M.C.; Whang, I.S.; Pantuck, A.; Ring, K.; Kaplan, S.A.; Olsson, C.A.; Cooner, W.H. Prostate specific antigen density: A means of distinguishing benign prostatic hypertrophy and prostate cancer. J. Urol. 1992, 147, 815–816. [Google Scholar] [CrossRef]
- Benson, M.C.; Whang, I.S.; Olsson, C.A.; McMahon, D.J.; Cooner, W.H. The use of prostate specific antigen density to enhance the predictive value of intermediate levels of serum prostate specific antigen. J. Urol. 1992, 147, 817–821. [Google Scholar] [CrossRef]
- Filella, X.; Foj, L.; Alcover, J.; Auge, J.M.; Molina, R.; Jimenez, W. The influence of prostate volume in prostate health index performance in patients with total PSA lower than 10 mug/L. Clin. Chim. Acta 2014, 436, 303–307. [Google Scholar] [CrossRef]
- Tosoian, J.J.; Druskin, S.C.; Andreas, D.; Mullane, P.; Chappidi, M.; Joo, S.; Ghabili, K.; Mamawala, M.; Agostino, J.; Carter, H.B.; et al. Prostate Health Index density improves detection of clinically significant prostate cancer. Bju Int. 2017, 120, 793–798. [Google Scholar] [CrossRef] [Green Version]
- Druskin, S.C.; Tosoian, J.J.; Young, A.; Collica, S.; Srivastava, A.; Ghabili, K.; Macura, K.J.; Carter, H.B.; Partin, A.W.; Sokoll, L.J.; et al. Combining Prostate Health Index density, magnetic resonance imaging and prior negative biopsy status to improve the detection of clinically significant prostate cancer. Bju Int. 2018, 121, 619–626. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopes Vendrami, C.; McCarthy, R.J.; Chatterjee, A.; Casalino, D.; Schaeffer, E.M.; Catalona, W.J.; Miller, F.H. The Utility of Prostate Specific Antigen Density, Prostate Health Index, and Prostate Health Index Density in Predicting Positive Prostate Biopsy Outcome is Dependent on the Prostate Biopsy Methods. Urology 2019, 129, 153–159. [Google Scholar] [CrossRef]
- Aminsharifi, A.; Howard, L.; Wu, Y.; De Hoedt, A.; Bailey, C.; Freedland, S.J.; Polascik, T.J. Prostate Specific Antigen Density as a Predictor of Clinically Significant Prostate Cancer When the Prostate Specific Antigen is in the Diagnostic Gray Zone: Defining the Optimum Cutoff Point Stratified by Race and Body Mass Index. J. Urol. 2018, 200, 758–766. [Google Scholar] [CrossRef] [PubMed]
- Nordstrom, T.; Akre, O.; Aly, M.; Gronberg, H.; Eklund, M. Prostate-specific antigen (PSA) density in the diagnostic algorithm of prostate cancer. Prostate Cancer Prostatic Dis. 2018, 21, 57–63. [Google Scholar] [CrossRef] [PubMed]
- Jue, J.S.; Barboza, M.P.; Prakash, N.S.; Venkatramani, V.; Sinha, V.R.; Pavan, N.; Nahar, B.; Kanabur, P.; Ahdoot, M.; Dong, Y.; et al. Re-examining Prostate-specific Antigen (PSA) Density: Defining the Optimal PSA Range and Patients for Using PSA Density to Predict Prostate Cancer Using Extended Template Biopsy. Urology 2017, 105, 123–128. [Google Scholar] [CrossRef]
- Jin, B.S.; Kang, S.H.; Kim, D.Y.; Oh, H.G.; Kim, C.I.; Moon, G.H.; Kwon, T.G.; Park, J.S. Pathological upgrading in prostate cancer patients eligible for active surveillance: Does prostate-specific antigen density matter? Korean J. Urol. 2015, 56, 624–629. [Google Scholar] [CrossRef] [Green Version]
- Ha, Y.S.; Yu, J.; Salmasi, A.H.; Patel, N.; Parihar, J.; Singer, E.A.; Kim, J.H.; Kwon, T.G.; Kim, W.J.; Kim, I.Y. Prostate-specific antigen density toward a better cutoff to identify better candidates for active surveillance. Urology 2014, 84, 365–371. [Google Scholar] [CrossRef] [PubMed]
- Ecke, T.H.; Bartel, P.; Hallmann, S.; Koch, S.; Ruttloff, J.; Cammann, H.; Lein, M.; Schrader, M.; Miller, K.; Stephan, C. Outcome prediction for prostate cancer detection rate with artificial neural network (ANN) in daily routine. Urol. Oncol. 2012, 30, 139–144. [Google Scholar] [CrossRef]
- Stephan, C.; Buker, N.; Cammann, H.; Meyer, H.A.; Lein, M.; Jung, K. Artificial neural network (ANN) velocity better identifies benign prostatic hyperplasia but not prostate cancer compared with PSA velocity. BMC Urol. 2008, 8, 10. [Google Scholar] [CrossRef] [Green Version]
- Boegemann, M.; Stephan, C.; Cammann, H.; Vincendeau, S.; Houlgatte, A.; Jung, K.; Blanchet, J.S.; Semjonow, A. The percentage of prostate-specific antigen (PSA) isoform (−2)proPSA and the Prostate Health Index improve the diagnostic accuracy for clinically relevant prostate cancer at initial and repeat biopsy compared with total PSA and percentage free PSA in men aged ≤65 years. Bju Int. 2016, 117, 72–79. [Google Scholar] [CrossRef]
- Munteanu, V.C.; Munteanu, R.A.; Gulei, D.; Schitcu, V.H.; Petrut, B.; Berindan Neagoe, I.; Achimas Cadariu, P.; Coman, I. PSA Based Biomarkers, Imagistic Techniques and Combined Tests for a Better Diagnostic of Localized Prostate Cancer. Diagnostics 2020, 10, 806. [Google Scholar] [CrossRef] [PubMed]
- Schwarzer, G.; Schumacher, M. Artificial neural networks for diagnosis and prognosis in prostate cancer. Semin Urol. Oncol. 2002, 20, 89–95. [Google Scholar] [CrossRef] [PubMed]
- Snow, P.B.; Smith, D.S.; Catalona, W.J. Artificial neural networks in the diagnosis and prognosis of prostate cancer: A pilot study. J. Urol. 1994, 152, 1923–1926. [Google Scholar] [CrossRef]
- Shariat, S.F.; Kattan, M.W.; Vickers, A.J.; Karakiewicz, P.I.; Scardino, P.T. Critical review of prostate cancer predictive tools. Future Oncol. 2009, 5, 1555–1584. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsao, C.W.; Liu, C.Y.; Cha, T.L.; Wu, S.T.; Sun, G.H.; Yu, D.S.; Chen, H.I.; Chang, S.Y.; Chen, S.C.; Hsu, C.Y. Artificial neural network for predicting pathological stage of clinically localized prostate cancer in a Taiwanese population. J. Chin. Med. Assoc. 2014, 77, 513–518. [Google Scholar] [CrossRef] [Green Version]
- Dejous, C.; Krishnan, U.M. Sensors for diagnosis of prostate cancer: Looking beyond the prostate specific antigen. Biosens. Bioelectron. 2020, 173, 112790. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patients (n) | 222 |
|---|---|
| Mean (range, age, years) | 64 (50–73) |
| DRE negative/positive n (%) | 143/79 |
| Median (95% CI) prostate volume (mL) | 50 (45–60) |
| Gleason score < 7 | 96/126 |
| tPSA ng/mL | 6.35 (4.48–8.38) |
| fPSA ng/mL | 0.89 (0.7–1.3) |
| p2PSA (pg/mL) | 20.29 (14.45–29.52) |
| PSAD (ng/mL2) | 0.13 (0.09–0.17) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gentile, F.; Ferro, M.; Della Ventura, B.; La Civita, E.; Liotti, A.; Cennamo, M.; Bruzzese, D.; Velotta, R.; Terracciano, D. Optimized Identification of High-Grade Prostate Cancer by Combining Different PSA Molecular Forms and PSA Density in a Deep Learning Model. Diagnostics 2021, 11, 335. https://doi.org/10.3390/diagnostics11020335
Gentile F, Ferro M, Della Ventura B, La Civita E, Liotti A, Cennamo M, Bruzzese D, Velotta R, Terracciano D. Optimized Identification of High-Grade Prostate Cancer by Combining Different PSA Molecular Forms and PSA Density in a Deep Learning Model. Diagnostics. 2021; 11(2):335. https://doi.org/10.3390/diagnostics11020335
Chicago/Turabian StyleGentile, Francesco, Matteo Ferro, Bartolomeo Della Ventura, Evelina La Civita, Antonietta Liotti, Michele Cennamo, Dario Bruzzese, Raffaele Velotta, and Daniela Terracciano. 2021. "Optimized Identification of High-Grade Prostate Cancer by Combining Different PSA Molecular Forms and PSA Density in a Deep Learning Model" Diagnostics 11, no. 2: 335. https://doi.org/10.3390/diagnostics11020335
APA StyleGentile, F., Ferro, M., Della Ventura, B., La Civita, E., Liotti, A., Cennamo, M., Bruzzese, D., Velotta, R., & Terracciano, D. (2021). Optimized Identification of High-Grade Prostate Cancer by Combining Different PSA Molecular Forms and PSA Density in a Deep Learning Model. Diagnostics, 11(2), 335. https://doi.org/10.3390/diagnostics11020335